




Was ist der K-Nearest-Neighbors-(KNN)-Algorithmus im Machine Learning?
Letzte Aktualisierung: 1. März 2025
Am Ende dieses Artikels werden Sie in der Lage sein:
Die grundlegenden Prinzipien hinter KNN zu erklären und wie es funktioniert
Geeignete Distanzmetriken für verschiedene Datentypen auszuwählen
KNN sowohl für Klassifikations- als auch für Regressionsaufgaben zu implementieren
KNN-Modelle durch die Auswahl des idealen Werts von k zu optimieren
Die Einschränkungen von KNN zu verstehen und zu wissen, wann alternative Ansätze verwendet werden sollten
KNN mit Python auf reale Probleme anzuwenden
Einführung: Ähnlichkeit bei der alltäglichen Entscheidungsfindung
Stellen Sie sich vor, Sie versuchen zu entscheiden, welches Restaurant Sie in einer neuen Stadt besuchen sollen. Was tun Sie normalerweise? Sie könnten Freunde mit ähnlichem Geschmack wie Ihrem um Empfehlungen bitten und darauf vertrauen, dass Sie ein Restaurant wahrscheinlich ebenfalls mögen werden, wenn Menschen mit ähnlichen Vorlieben wie Ihren es genossen haben.
Dieses intuitive Konzept – dass Dinge oder Entitäten, die einander ähnlich sind, oft wichtige Eigenschaften teilen – ist genau das, was den K-Nearest Neighbors (KNN)-Algorithmus antreibt. KNN formalisiert diese Intuition zu einer leistungsstarken Machine-Learning-Technik, die in zahlreichen Bereichen Anwendung findet, von Empfehlungssystemen bis hin zur medizinischen Diagnose.
Der knn-Algorithmus ist ein überwachter Machine-Learning-Algorithmus, der sowohl Klassifikations- als auch Regressionsprobleme lösen kann. Er schätzt die Wahrscheinlichkeit, dass ein Datenpunkt zu einer Gruppe oder einer anderen gehört, basierend darauf, welche vorhandenen Datenpunkte ihm am nächsten liegen. Im Gegensatz zu vielen ml-Algorithmen, die komplexe Modelle erstellen, liegt die Eleganz von KNN in seiner Einfachheit: Der Algorithmus speichert einfach die Trainingsdaten und trifft Vorhersagen, indem er die ähnlichsten Beispiele findet.
Definition von KNN
Der K-nearest neighbor-Algorithmus ist ein überwachter Machine-Learning-Algorithmus, der Nähe nutzt, um Klassifikationen oder Vorhersagen über die Gruppierung eines einzelnen Datenpunkts zu treffen. Als nichtparametrischer Lazy-Learning-Algorithmus speichert KNN den gesamten Trainingsdatensatz und führt Berechnungen erst zum Zeitpunkt der Klassifikation durch. Das bedeutet, dass KNN, anstatt während einer Trainingsphase ein Modell zu erstellen, Vorhersagen trifft, indem neue Datenpunkte direkt mit den gespeicherten Trainingsdaten verglichen werden. Der Algorithmus ist vielseitig und wird sowohl für Klassifikations- als auch für Regressionsaufgaben eingesetzt, und seine Leistung wird durch die Wahl von K (der Anzahl der berücksichtigten nächsten Nachbarn) und der Distanzmetrik beeinflusst, die zur Messung der Ähnlichkeit verwendet wird.
Bedeutung von KNN in Data Science
Der KNN-Algorithmus nimmt im Bereich von ml und Data Science aufgrund seiner Einfachheit, leichten Interpretierbarkeit und relativ geringen Rechenkosten für kleine bis mittelgroße Datensätze einen bedeutenden Platz ein. Sein unkomplizierter Ansatz macht ihn zu einem ausgezeichneten Ausgangspunkt für Einsteiger in Data Science, während seine Wirksamkeit sicherstellt, dass er auch für erfahrene Fachleute ein wertvolles Werkzeug bleibt. KNN wird in verschiedenen Bereichen breit eingesetzt, darunter Bildklassifikation, Textklassifikation und Empfehlungssysteme. Beispielsweise kann er die Nutzerabwanderung bei einem Streaming-Dienst vorhersagen, bei der medizinischen Diagnose unterstützen und bei Finanzprognosen helfen. Seine Fähigkeit, nichtlineare Beziehungen zu handhaben, und seine Robustheit gegenüber Ausreißern erhöhen seine Attraktivität zusätzlich und machen ihn zu einer beliebten Wahl in der Branche.
Grundlegende Konzepte
Überwachtes vs. unüberwachtes Lernen
KNN gehört zur Familie der überwachten Lernalgorithmen, was bedeutet, dass er gelabelte Trainingsdaten benötigt, um Vorhersagen zu treffen. Beim überwachten Lernen lernt der Algorithmus aus Beispielen, bei denen die richtigen Antworten (Labels) bereitgestellt werden, im Gegensatz zum unüberwachten Lernen, bei dem der Algorithmus Muster in ungelabelten Daten finden muss.
Lazy vs. Eager Learning
Was KNN unter vielen ml-Algorithmen einzigartig macht, ist, dass er als "lazy learner" gilt. Die meisten Algorithmen durchlaufen eine explizite Trainingsphase, um ein Modell zu erstellen, bevor sie Vorhersagen treffen. KNN hat jedoch keine eigenständige Trainingsphase – er speichert einfach den Trainingsdatensatz und verschiebt alle Berechnungen bis zum Zeitpunkt der Vorhersage. Deshalb wird KNN auch bezeichnet als:
Instance-based learning
Speicherbasiertes Lernen
Nichtparametrisches Lernen
Da KNN keine Annahmen über die zugrunde liegende Datenverteilung trifft (nichtparametrisch) und die Trainingsdaten nicht zu einem kompakten Modell zusammenfasst, kann es komplexe Entscheidungsgrenzen erfassen, die parametrische Modelle möglicherweise übersehen.
Klassifikation vs. Regression mit KNN
KNN kann sowohl für Klassifikations- als auch für Regressionsaufgaben verwendet werden:
KNN-Klassifikation: Sagt das Klassenlabel einer neuen Instanz voraus, indem die häufigste Klasse unter ihren k nächsten Nachbarn ermittelt wird. Die Klassifikation eines neuen Datenpunkts basiert auf der häufigsten Klasse unter seinen k nächsten Nachbarn (KNN).
KNN-Regression: Sagt den numerischen Wert einer neuen Instanz voraus, indem die Werte ihrer k nächsten Nachbarn gemittelt werden.
Merkmalsraum und Ähnlichkeit
Der Eckpfeiler von KNN ist das Konzept der Ähnlichkeit oder Distanz im Merkmalsraum. Jeder Datenpunkt wird als Vektor in einem mehrdimensionalen Raum dargestellt, wobei jede Dimension einem Merkmal entspricht. Die Ähnlichkeit zwischen zwei Datenpunkten steht in umgekehrtem Verhältnis zur Distanz zwischen ihnen in diesem Merkmalsraum – je näher zwei Punkte beieinanderliegen, desto ähnlicher werden sie betrachtet.
Distanzmetriken im Detail
Die Wahl der Distanzmetrik ist bei KNN entscheidend, da sie direkt beeinflusst, welche Punkte als „nächste“ zueinander betrachtet werden. Unterschiedliche Distanzmetriken eignen sich für unterschiedliche Datentypen und Problemdomänen.

Euklidische Distanz
Die euklidische Distanz ist die tatsächliche geradlinige Entfernung zwischen zwei Punkten im euklidischen Raum. Sie ist die am häufigsten verwendete Distanzmetrik in KNN.
Mathematische Formel:
Wobei x und y zwei Punkte im n-dimensionalen Raum sind.
Wann verwenden: Die euklidische Distanz funktioniert gut, wenn die Daten kontinuierlich sind und in allen Dimensionen sinnvolle Beziehungen aufweisen. Sie ist besonders geeignet, wenn Merkmale auf ähnlichen Skalen gemessen werden.
Manhattan-Distanz
Auch als City-Block- oder L1-Distanz bekannt, berechnet die Manhattan-Distanz die Summe der absoluten Differenzen zwischen den Koordinaten zweier Punkte. Im KNN-Algorithmus werden Manhattan-Distanzen verwendet, um die Nähe von Datenpunkten in gitterartigen Strukturen zu messen, was sie für solche Umgebungen besonders geeignet macht.
Mathematische Formel:
Wann verwenden: Die Manhattan-Distanz ist nützlich, wenn Merkmale diskrete oder binäre Attribute darstellen oder wenn der Merkmalsraum gitterartig ist. Sie kann weniger empfindlich gegenüber Ausreißern sein als die euklidische Distanz.
Kosinus-Ähnlichkeit
Kosinus-Ähnlichkeit misst den Kosinus des Winkels zwischen zwei Vektoren und konzentriert sich dabei auf die Ausrichtung statt auf die Größe.
Mathematische Formel:
Wann verwenden: Die Kosinus-Ähnlichkeit ist besonders nützlich für Textanalyse und hochdimensionale spärliche Daten, bei denen die Größe der Vektoren möglicherweise nicht so wichtig ist wie ihre Richtung.
Hamming-Distanz
Die Hamming-Distanz zählt die Anzahl der Positionen, an denen sich entsprechende Elemente in zwei Sequenzen gleicher Länge unterscheiden.
Mathematische Formel: Für zwei Zeichenketten gleicher Länge ist die Hamming-Distanz die Anzahl der Positionen, an denen sich die entsprechenden Symbole unterscheiden.
Wann verwenden: Die Hamming-Distanz ist ideal für kategoriale Daten oder bei der Arbeit mit binären Merkmalen. Sie wird häufig in der Informationstheorie, Codierungstheorie und zum Vergleichen von Zeichenketten oder Bitvektoren verwendet.
Richtlinien zur Auswahl von Distanzmetriken
Euklidische Distanz: Kontinuierliche Daten mit ähnlichen Skalen
Manhattan-Distanz: Gitterartige Räume, Unabhängigkeit von Merkmalen
Kosinus-Ähnlichkeit: Textdaten, dünnbesetzte hochdimensionale Daten
Hamming-Distanz: Kategoriale Daten, binäre Merkmale
Denken Sie daran, dass unabhängig davon, welche Distanzmetrik Sie wählen, eine Merkmalsskalierung oft notwendig ist, um zu verhindern, dass Merkmale mit größeren Skalen die Distanzberechnungen dominieren.
Der KNN-Algorithmus: Schritt für Schritt
Nachdem wir nun das Konzept der Distanz verstanden haben, gehen wir den KNN-Algorithmus Schritt für Schritt durch.
Anforderungen an die Datenvorverarbeitung
Bevor KNN angewendet wird, sind mehrere Vorverarbeitungsschritte unerlässlich:
Merkmalsskalierung: Da Distanzberechnungen direkt von der Skala der Merkmale beeinflusst werden, ist Normalisierung oder Standardisierung entscheidend. Typischerweise werden Merkmale auf den Bereich [0, 1] skaliert oder standardisiert, sodass sie einen Mittelwert von 0 und eine Standardabweichung von 1 haben.
Umgang mit fehlenden Werten: KNN kann fehlende Werte nicht direkt verarbeiten, daher sollten Imputationstechniken angewendet werden.
Dimensionsreduktion: Hochdimensionale Daten können unter dem „Fluch der Dimensionalität“ leiden, bei dem Distanzmetriken weniger aussagekräftig werden. Techniken wie PCA können helfen, die Dimensionalität zu reduzieren.
Parameterauswahl
Der wichtigste Parameter bei KNN ist k, die Anzahl der zu berücksichtigenden Nachbarn. Die Wahl von k hat einen erheblichen Einfluss auf die Leistung des Modells:
Kleines k (z. B. k=1 oder k=3): Das Modell kann eine hohe Varianz aufweisen (Overfitting) und empfindlich gegenüber Rauschen in den Trainingsdaten sein.
Großes k (z. B. k=20): Das Modell kann einen hohen Bias aufweisen (Underfitting) und möglicherweise wichtige Muster in den Daten übersehen.
Der optimale Wert von k wird typischerweise durch Kreuzvalidierung bestimmt, häufig unter Verwendung von Techniken wie der Elbow-Methode oder Grid Search, die wir später ausführlicher besprechen werden.
Trainingsphase (oder deren Fehlen)
Wie bereits erwähnt, hat KNN keine traditionelle Trainingsphase. Stattdessen speichert es einfach den gesamten Trainingsdatensatz im Speicher. Diese Eigenschaft macht KNN schnell im „Training“, aber potenziell langsam bei der Vorhersage, insbesondere bei großen Datensätzen.
Vorhersageprozess
So berechnet man den K-Nearest-Neighbor-Algorithmus
Um die Klasse eines unbeobachteten Datenpunkts auf Grundlage von Beobachtungen zu bestimmen, verwendet der K-Nearest Neighbor im Wesentlichen einen Mehrheitsabstimmungsmechanismus. Mehrheitsabstimmung ist ein grundlegender Prozess in KNN, bei dem der Algorithmus einen Datenpunkt klassifiziert, indem er die Kategorie bestimmt, der die meisten seiner nächsten Nachbarn angehören. Dies bedeutet, dass die Klasse, die die meisten Stimmen erhält, die Klasse für den betreffenden Datenpunkt sein wird. Der KNN-Algorithmus klassifiziert einen gegebenen Datenpunkt anhand der Nähe seiner nächsten Nachbarn.
Wenn K gleich 1 ist, berücksichtigen wir nur den nächsten Nachbarn eines Datenpunkts, wenn wir seine Klasse bestimmen. Die 10 nächsten Nachbarn werden verwendet, wenn K gleich 10 ist, und so weiter. Der Testpunkt wird basierend auf dem Wert von 'k' und der Nähe zu Trainingsdatenpunkten klassifiziert.
Betrachten wir zwei Klassen: A und B. Der Algorithmus untersucht die Zustände benachbarter Datenpunkte, um festzustellen, ob ein Datenpunkt zu Klasse A oder Klasse B gehört. Wenn die meisten Datenpunkte in Gruppe A sind, ist es nahezu sicher, dass der betreffende Datenpunkt zu Gruppe A gehört.
Für Klassifikationsaufgaben trifft KNN Vorhersagen mithilfe dieser Schritte:
Berechnen Sie die Distanz zwischen der neuen Instanz und allen Instanzen im Trainingsdatensatz.
Wählen Sie die k Instanzen aus dem Trainingsdatensatz aus, die der neuen Instanz am nächsten liegen.
Für die Klassifikation: Führen Sie eine Mehrheitsabstimmung der knn durch, um die Klasse der neuen Instanz zu bestimmen.
Für die Regression: Berechnen Sie den Durchschnitt (oder gewichteten Durchschnitt) der Werte der k nächsten Nachbarn.
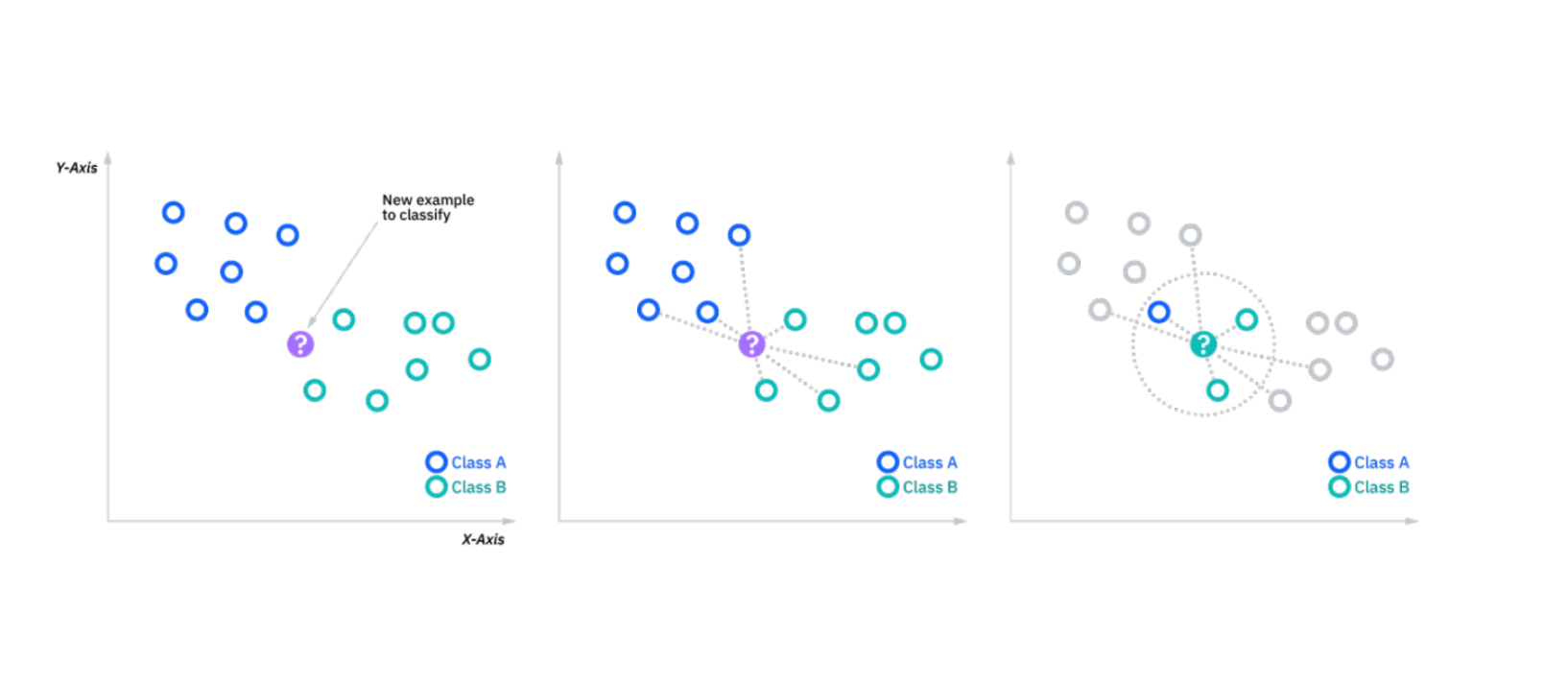 Wie KNN zwischen zwei Klassen funktioniert. Quelle: https://www.ibm.com/in-en/topics/knn
Wie KNN zwischen zwei Klassen funktioniert. Quelle: https://www.ibm.com/in-en/topics/knn
Beispiel für KNN in Aktion
Ein klassisches Beispiel für KNN in Aktion ist ein Empfehlungssystem für einen Movie-Streaming-Dienst. Stellen Sie sich eine Plattform vor, die den KNN-Algorithmus verwendet, um Nutzern Filme basierend auf ihrem bisherigen Sehverlauf und ihren Bewertungen vorzuschlagen. Der Algorithmus identifiziert die K nächsten Nachbarn zu einem bestimmten Nutzer, wobei die Nachbarn andere Nutzer mit ähnlichen Sehgewohnheiten sind. Durch die Analyse der Präferenzen dieser Nachbarn kann das System Filme empfehlen, die von ihnen hoch bewertet wurden, aber vom Zielnutzer noch nicht angesehen wurden. Dieser Ansatz der personalisierten Empfehlung verbessert nicht nur die Nutzererfahrung, sondern erhöht auch das Nutzerengagement und die Zufriedenheit und zeigt damit die praktische Leistungsfähigkeit des KNN-Algorithmus.
Gewichtete KNN-Varianten
Standard-KNN behandelt alle Nachbarn gleich, aber das ist möglicherweise nicht ideal, da nähere Nachbarn logischerweise mehr Einfluss auf Vorhersagen haben sollten. Gewichtetes KNN adressiert dies, indem es Nachbarn basierend auf ihrer Entfernung Gewichte zuweist:
Das Gewicht jedes Nachbarn ist typischerweise der Kehrwert seiner Entfernung vom Abfragepunkt.
Für die Klassifikation wird gewichtetes Voting durchgeführt.
Für die Regression wird ein gewichteter Durchschnitt berechnet.
Die Formel für einen einfachen entfernungsgewichteten Ansatz könnte wie folgt aussehen:
weighti=1d(x,xi)2\text{weight}_i = \frac{1}{d(x, x_i)^2}weighti=d(x,xi)21
Wobei d(x, xi) die Entfernung zwischen dem Abfragepunkt x und dem Nachbarn xi ist.
Optimierung der KNN-Leistung
Cross-Validation-Strategien zur Bestimmung des optimalen k
K-fold-Cross-Validation wird häufig verwendet, um den optimalen Wert von k zu bestimmen. Der Prozess umfasst:
Aufteilen des Datensatzes in k Folds (nicht zu verwechseln mit dem k in KNN).
Für jeden Wert von k in KNN (z. B. k=1 bis k=20):
Trainieren und Evaluieren des Modells k-mal, wobei jedes Mal ein anderer Fold als Testdatensatz verwendet wird.
Berechnen der durchschnittlichen Leistung über alle k Folds hinweg.
Auswählen des k-Werts, der die beste durchschnittliche Leistung liefert.
Ellbogenmethode
Die Ellbogenmethode umfasst das Plotten der Modellleistung (z. B. Genauigkeit oder Fehlerrate) gegen verschiedene Werte von k und das Suchen nach einem „Ellbogenpunkt“, an dem die Verbesserungsrate deutlich abnimmt. Dieser Punkt weist oft auf einen guten Kompromiss zwischen Bias und Varianz hin.
Grid-Search-Implementierung
Grid Search ist eine systematische Methode, um verschiedene Kombinationen von Hyperparametern (einschließlich k und möglicherweise Ähnlichkeitsmetriken) auszuprobieren und die Kombination auszuwählen, die auf einem Validierungsdatensatz die beste Leistung liefert.
Umgang mit Klassenungleichgewicht
KNN kann empfindlich auf Klassenungleichgewicht reagieren, bei dem einige Klassen viel mehr Beispiele haben als andere. Strategien zur Behandlung dieses Problems umfassen:
Resampling: Oversampling von Minderheitsklassen oder Undersampling von Mehrheitsklassen.
Verschiedene Evaluationsmetriken: Verwendung von Metriken wie F1-score oder AUC anstelle von Genauigkeit.
Gewichtetes Voting: Zuweisen unterschiedlicher Gewichte zu Klassen basierend auf ihrer Häufigkeit.
Dimensionalitätsüberlegungen und der Fluch der Dimensionalität
Mit zunehmender Anzahl von Dimensionen (Features) nimmt das Volumen des Raums exponentiell zu. Dieses Phänomen, bekannt als der „Fluch der Dimensionalität“, kann Distanzmetriken weniger aussagekräftig und KNN weniger effektiv machen. In hochdimensionalen Räumen:
Datenpunkte neigen dazu, gleich weit voneinander entfernt zu sein.
Das Konzept von „nächstgelegen“ wird weniger klar.
Das Modell benötigt exponentiell mehr Daten.
Um dem entgegenzuwirken, sollten Sie Folgendes in Betracht ziehen:
Feature-Selektion zum Entfernen irrelevanter Features
Dimensionalitätsreduktionstechniken wie PCA
Verwendung spezialisierter Datenstrukturen wie KD-trees für eine effiziente Suche nach nächsten Nachbarn
Praktische Implementierung
Implementieren wir KNN für eine Klassifikationsaufgabe mit Python und scikit-learn.
Importieren der Module
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
Datensatz
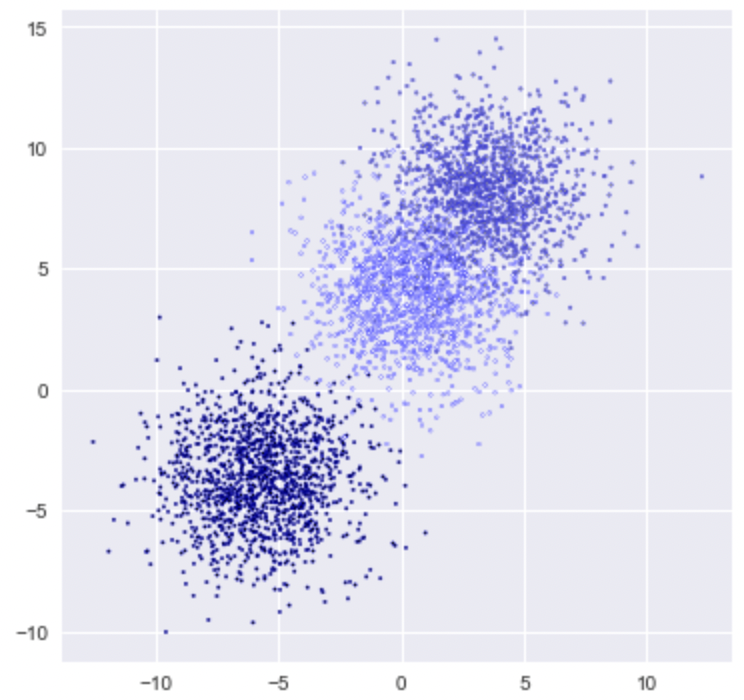
Scikit-learn kann zum Erstellen synthetischer Datensätze für Trainingsbeispiele verwendet werden, die sich hervorragend für Demonstrationszwecke eignen.
X, y = make_blobs(n_samples = 4000, n_features = 3, centers = 3 ,cluster_std = 2, random_state = 80)
X
array([[ 7.60190561, 4.86336321, 6.97616573],
[ 5.97809745, 7.69910922, 2.77419701],
[-4.36024844, -2.23247572, -5.29113293],
...,
[-8.22252297, -6.88609334, -6.52102135],
[-3.96254707, -5.27559922, -2.70880022],
[-4.25865881, -1.67791521, -3.70523373]])
y
array([1, 1, 2, ..., 2, 2, 2])
Diagramm
plt.figure(figsize = (6,6))
plt.scatter(X[:,0], X[:,1], c=y, marker= '.', s=10, edgecolors='blue')
plt.show()
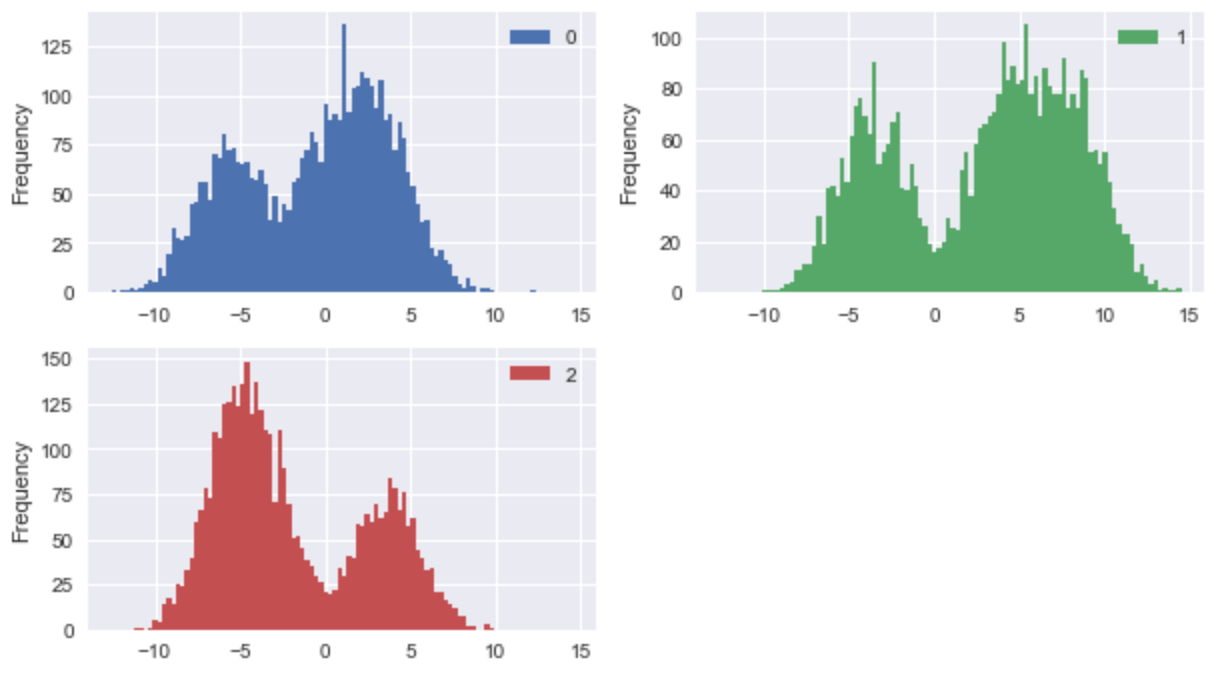
df = pd.DataFrame(X)
df.head()
plt.rcParams['figure.figsize']=(10,15)
df.plot(kind='hist', bins=100, subplots=True, layout=(5,2), sharex=False, sharey=False)
plt.show()
Die Implementierung des K-Nearest-Neighbors-Klassifikators
Der erste Schritt besteht darin, den optimalen Wert für k zu ermitteln. Die Berechnung des K-Werts variiert je nach Situation stark. Der Standardwert von K bei Verwendung der Scikit-Learn-Bibliothek ist 5, und die standardmäßig verwendete Distanzmetrik ist euklidisch.
Abstimmung des Modells zur Erzielung einer hohen K-Nearest-Neighbor-Genauigkeit
from sklearn.model_selection import GridSearchCV
param_grid = {'n_neighbors':np.arange(1,4)}
knn = KNeighborsClassifier()
knn_cv= GridSearchCV(knn,param_grid,cv=5)
knn_cv.fit(X,y)
print(knn_cv.best_params_)
print(knn_cv.best_score_)
{'n_neighbors': 3}
0.9887499999999999
#train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 80)
# instantiate the model
knn = KNeighborsClassifier(n_neighbors=3)
# fit the model to the training set
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
print('Model accuracy score: {0:0.4f}'. format(accuracy_score(y_test, y_pred)))
Modellgenauigkeitswert: 0.9890.
Wir haben eine Genauigkeitsrate von 98.90% erreicht, was als sehr gut gilt. Wir haben die Anzahl der Nachbarn von 1 auf 4 erhöht, und das Modell erzielte bei k=3 die beste Leistung.
Das K-Nearest-Neighbor-Modell umfasst keine Trainingsphase, da die Daten selbst ein Modell sind, das als Referenz für zukünftige Vorhersagen in der Trainingsphase dient. Dadurch ist es zeiteffizient und ermöglicht eine schnelle Improvisation für zufällige Modellierung auf den verfügbaren Daten.
KNN benötigt nur zwei Hyperparameter, einen K-Wert und eine Distanzmetrik, wodurch es einfacher abzustimmen ist als andere Machine-Learning-Algorithmen.
Die meisten Klassifikatoralgorithmen sind für binäre Klassifikationsprobleme einfach zu implementieren, erfordern jedoch zusätzlichen Aufwand bei der Implementierung für Mehrklassenprobleme. Im Gegensatz dazu passt sich KNN ohne zusätzlichen Aufwand an Mehrklassenprobleme an.
Hauptmechanismus
Der Hauptmechanismus des KNN-Algorithmus besteht darin, die K nächsten Nachbarn zu einem gegebenen Datenpunkt zu identifizieren und deren Klassenlabels zur Erstellung einer Vorhersage zu verwenden. Bei Klassifikationsaufgaben weist der Algorithmus die Klasse zu, die unter den K nächsten Nachbarn am häufigsten vorkommt. Bei Regressionsaufgaben mittelt er die Werte der K nächsten Nachbarn, um den Wert des neuen Datenpunkts vorherzusagen. Dieser Ansatz wird aufgrund seiner Einfachheit und Effektivität in verschiedenen Bereichen weit verbreitet eingesetzt und ermöglicht es, sowohl Klassifikations- als auch Regressionsprobleme mühelos zu behandeln.
Bewertung von Leistungsmetriken
Bei der Bewertung von KNN-Modellen sollten mehrere Metriken über die reine Genauigkeit hinaus berücksichtigt werden:
Genauigkeit: Der Anteil korrekter Vorhersagen.
Präzision: Der Anteil der positiven Identifikationen, die tatsächlich korrekt waren.
Recall: Der Anteil der tatsächlichen Positiven, die korrekt identifiziert wurden.
F1-Score: Das harmonische Mittel aus Präzision und Recall.
Konfusionsmatrix: Eine Tabelle, die korrekte und inkorrekte Klassifizierungen für jede Klasse zeigt.
ROC-Kurve und AUC: Für binäre Klassifikation, zeigt den Kompromiss zwischen der True-Positive-Rate und der False-Positive-Rate.
Tipps zur Skalierung auf größere Datensätze
KNN kann bei großen Datensätzen rechenintensiv werden. Hier sind einige Strategien zur Verbesserung der Effizienz:
Verwenden Sie Approximate-Nearest-Neighbor-Algorithmen: Algorithmen wie Locality-Sensitive Hashing (LSH) können approximative nächste Nachbarn deutlich schneller finden als exakte Methoden.
Implementieren Sie KNN-Varianten für mehr Effizienz: Datenstrukturen wie KD-Bäume und Ball Trees organisieren die Daten, um die Suche nach nächsten Nachbarn effizienter zu machen:
KD-Bäume: Partitionieren den Raum mithilfe von Hyperebenen und ermöglichen so die schnelle Eliminierung großer Teile des Suchraums.
Ball Trees: Partitionieren den Raum mithilfe von Hypersphären, was in hochdimensionalen Räumen effektiver sein kann als KD-Bäume.
Stichproben aus den Trainingsdaten ziehen: Bei sehr großen Datensätzen kann die Verwendung einer repräsentativen Stichprobe die Rechenzeit erheblich reduzieren, bei minimalem Einfluss auf die Genauigkeit.
Parallele Verarbeitung: Nutzen Sie Mehrkernprozessoren oder verteiltes Rechnen, um Distanzberechnungen zu beschleunigen.
Praxisanwendungen
KNN wird aufgrund seiner Einfachheit und Effektivität in verschiedenen Bereichen häufig eingesetzt:
Empfehlungssysteme
KNN bildet die Grundlage für kollaboratives Filtern in Empfehlungssystemen. Indem Benutzer mit ähnlichen Präferenzen (nächste Nachbarn) gefunden werden, kann das System Elemente empfehlen, die diesen ähnlichen Benutzern gefallen haben, die der Zielbenutzer aber noch nicht gesehen hat.
Fallstudie: Filmempfehlung
Ein Streaming-Dienst könnte KNN verwenden, um Benutzern basierend auf ihrem Wiedergabeverlauf Filme zu empfehlen. Der Algorithmus würde Benutzer mit ähnlichen Sehgewohnheiten finden und Filme empfehlen, die diesen ähnlichen Benutzern gefallen haben, die der Zielbenutzer aber noch nicht angesehen hat.
Medizinische Diagnose
KNN kann bei der medizinischen Diagnose helfen, indem Patienten mit ähnlichen Symptomen oder Testergebnissen gefunden und deren Diagnosen verwendet werden, um die Diagnose für einen neuen Patienten vorherzusagen.
Fallstudie: Diabetes-Vorhersage
Mithilfe von Merkmalen wie Glukosespiegel, BMI, Alter und Blutdruck kann KNN klassifizieren, ob ein Patient wahrscheinlich Diabetes hat, indem seine Messwerte mit denen von Patienten mit bekannten Diagnosen verglichen werden.
Bilderkennung
In der Computer Vision kann KNN zur Bildklassifikation verwendet werden, indem aus Bildern extrahierte Merkmalsvektoren verglichen werden.
Beispielprojekt: Erkennung handschriftlicher Ziffern
Mithilfe des MNIST-Datensatzes können wir KNN implementieren, um handschriftliche Ziffern zu erkennen. Jedes Bild wird als Vektor von Pixelwerten dargestellt, und der Algorithmus klassifiziert neue Bilder basierend auf ihrer Ähnlichkeit zu Trainingsbildern.
Anomalieerkennung
KNN kann Anomalien oder Ausreißer identifizieren, indem Punkte gefunden werden, die weit von ihren nächsten Nachbarn entfernt sind.
Implementierungsbeispiel: Kreditkartenbetrugserkennung
Durch Berechnung der durchschnittlichen Entfernung zu den knn für jede Transaktion können jene mit ungewöhnlich großen Entfernungen als potenzieller Betrug markiert werden.
Vektorähnlichkeitssuche
In hochdimensionalen Vektorräumen, wie sie in NLP und Computer Vision verwendet werden, kann KNN ähnliche Elemente effizient finden. Dies ist besonders wertvoll in Anwendungen wie:
Bild-Ähnlichkeitssuche
Dokument-Clustering
Entitätsabgleich
Für diese Anwendungen können spezialisierte Vektordatenbanken die Leistung im Vergleich zu traditionellen Datenbanken erheblich verbessern, insbesondere beim Umgang mit hochdimensionalen Daten, bei denen die Berechnung von Ähnlichkeit rechenintensiv ist.
Einschränkungen und Alternativen
Wann KNN versagt
Trotz seiner Einfachheit und Wirksamkeit hat KNN mehrere Einschränkungen:
Rechenintensiv: Bei großen Datensätzen kann die Berechnung der Distanzen zwischen allen Punktpaaren unverhältnismäßig teuer sein.
Der Fluch der Dimensionalität: In hochdimensionalen Räumen wird das Konzept der Distanz weniger aussagekräftig, wodurch KNN weniger effektiv wird.
Unausgewogene Daten: KNN kann in unausgewogenen Datensätzen zugunsten der Mehrheitsklasse verzerrt sein.
Empfindlich gegenüber Rauschen und irrelevanten Merkmalen: Da KNN auf Distanzberechnungen beruht, können verrauschte oder irrelevante Merkmale seine Leistung erheblich beeinträchtigen.
Speicherintensiv: KNN erfordert, dass der gesamte Trainingsdatensatz im Speicher abgelegt wird.
Vorteile von KNN
Trotz dieser Einschränkungen bietet KNN mehrere Vorteile:
Keine Trainingsphase: Das KNN-Modell umfasst keine Trainingsphase, da die Daten selbst das Modell sind. Dadurch ist es zeiteffizient und ermöglicht schnelle Improvisation für zufällige Modellierung auf verfügbaren Daten.
Einfache Hyperparameter-Abstimmung: KNN erfordert nur zwei Haupt-Hyperparameter — einen k-Wert und eine Ähnlichkeitsmetrik — und ist dadurch einfacher abzustimmen als viele andere Algorithmen des maschinellen Lernens.
Natürliche Unterstützung mehrerer Klassen: Im Gegensatz zu vielen Klassifikationsalgorithmen, die zusätzlichen Aufwand erfordern, um für Mehrklassenprobleme implementiert zu werden, passt sich KNN ohne zusätzliche Komplexität an Mehrklassenprobleme an.
Nichtparametrische Natur: KNN trifft keine Annahmen über die zugrunde liegende Datenverteilung, wodurch es komplexe Muster erfassen kann, die parametrische Modelle möglicherweise übersehen.
Überlegungen zur rechnerischen Komplexität
Zeitkomplexität für die Vorhersage: O(MN log(k)) für jede Vorhersage, wobei M die Dimension der Daten (Anzahl der Merkmale) und N die Größe bzw. Anzahl der Instanzen im Trainingsdatensatz ist. Dies liegt daran, dass:
Berechnung der Distanzen zwischen dem Abfragepunkt und allen Trainingspunkten: O(MN)
Finden der knn (typischerweise mithilfe einer partiellen Sortierung): O(N log(k))
Speicherkomplexität: O(MN) zum Speichern des Trainingsdatensatzes.
Diese rechnerische Komplexität kann KNN ohne Optimierung für große Datensätze unpraktisch machen. Es gibt jedoch spezialisierte Datenstrukturen und Algorithmen, die KNN selbst für große Datensätze effizienter machen können.
Alternative Algorithmen
Wenn KNN nicht geeignet ist, sollten diese Alternativen in Betracht gezogen werden:
Entscheidungsbäume und Random Forests: Können irrelevante Merkmale besser handhaben und Merkmalswichtigkeit bereitstellen.
Support Vector Machines (SVM): Effektiver in hochdimensionalen Räumen und bei komplexen Entscheidungsgrenzen.
Naive Bayes: Recheneffizient und funktioniert gut mit hochdimensionalen Daten.
Neuronale Netze: Können komplexe Muster lernen, benötigen jedoch mehr Daten und Rechenressourcen.
Hybride Ansätze
Die Kombination von KNN mit anderen Algorithmen kann einige seiner Einschränkungen überwinden:
KNN mit Merkmalsauswahl/-extraktion: Wenden Sie Merkmalsauswahltechniken an, bevor KNN verwendet wird, um die Dimensionalität zu reduzieren.
Ensemble-Methoden: Kombinieren Sie KNN mit anderen Algorithmen durch Voting oder Stacking.
Lokale gewichtete Regression: Verwenden Sie KNN, um lokale Nachbarschaften zu identifizieren, und wenden Sie dann innerhalb jeder Nachbarschaft Regression an.
Fazit und weiterführende Ressourcen
K-Nearest Neighbors ist ein leistungsfähiger und intuitiver Algorithmus, der das einfache Konzept nutzt, dass ähnliche Instanzen tendenziell ähnliche Ergebnisse haben. Trotz seiner Einfachheit kann KNN bei korrekter Implementierung mit geeigneter Vorverarbeitung, Parameterauswahl und Optimierungstechniken äußerst effektiv sein.
Wichtigste Erkenntnisse
KNN ist ein nichtparametrischer, instanzbasierter Lernalgorithmus, der sowohl für Klassifikations- als auch für Regressionsaufgaben verwendet werden kann.
Die Wahl der Ähnlichkeitsmetrik und der Wert von k sind entscheidend für die Leistung von KNN.
Die Merkmalskalierung ist vor der Anwendung von KNN unerlässlich, um sicherzustellen, dass alle Merkmale gleichermaßen zu den Distanzberechnungen beitragen.
KNN kann unter dem Fluch der Dimensionalität leiden und bei großen Datensätzen rechenintensiv sein.
Effiziente Implementierungen unter Verwendung von KD-Bäumen oder Ball Trees können die Leistung erheblich verbessern.
Zukünftige Forschungsrichtungen für KNN
Trotz seiner Einfachheit und Effektivität weist der KNN-Algorithmus mehrere Einschränkungen auf, wie etwa Empfindlichkeit gegenüber Rauschen und Ausreißern, hohe Rechenkosten und den Bedarf an erheblichem Speicherplatz zum Speichern der Trainingsdaten. Zukünftige Forschungsrichtungen für KNN umfassen die Entwicklung effizienterer Algorithmen zur Verarbeitung großer Datensätze, die Verbesserung der Robustheit gegenüber Rauschen und Ausreißern sowie die Erforschung neuer Ähnlichkeitsmaße und Gewichtungsschemata. Darüber hinaus untersuchen Forschende die Integration von KNN mit aufkommenden Technologien wie Deep Learning, Natural Language Processing und Computer Vision. Durch die Bewältigung dieser Herausforderungen und die Erweiterung seiner Anwendungen wird die fortlaufende Entwicklung des KNN-Algorithmus das Gebiet der Datenwissenschaft erheblich beeinflussen und seine Relevanz und Nützlichkeit bei der Lösung komplexer Probleme sicherstellen.
Wissenschaftliche Arbeiten und Ressourcen
Für diejenigen, die tiefer in KNN und seine Varianten eintauchen möchten, sind diese Ressourcen empfehlenswert:
Cover, T. M., & Hart, P. E. (1967). "Nearest neighbor pattern classification." IEEE Transactions on Information Theory, 13(1), 21-27.
Altman, N. S. (1992). "An introduction to kernel and nearest-neighbor nonparametric regression." The American Statistician, 46(3), 175-185.
Weinberger, K. Q., & Saul, L. K. (2009). "Distance metric learning for large margin nearest neighbor classification." Journal of Machine Learning Research, 10, 207-244.
Online-Kurse und Tutorials
Coursera: Machine Learning by Andrew Ng
Kaggle: Feature Engineering and KNN
scikit-learn Documentation: Nearest Neighbors
Durch ein gründliches Verständnis des KNN-Algorithmus, der Implementierungsdetails und der Optimierungstechniken erweitern Sie Ihr Machine-Learning-Toolkit um ein vielseitiges und leistungsstarkes Werkzeug, das in zahlreichen Bereichen eingesetzt werden kann.
Weiterlesen

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.