




Unseren Chat auf Data-Science-Ergebnisse ausrichten
Dies ist der dritte Teil einer Serie. Die ersten beiden Beiträge stellen eine grundlegende, ausschließlich auf einer Vektordatenbank basierende Implementierung eines Chatbots mit Milvus sowie eine LlamaIndex-Implementierung des Chatbots vor. In dieser Ausgabe verwenden wir weiterhin LlamaIndex, fügen jedoch etwas hinzu, um unsere Ergebnisse zu „verankern“. TruEra hat einen großartigen Kommentar zur Groundedness sowie eine kurze Beschreibung in einem ihrer RAG-Evaluierungsblogs.
In diesem Artikel behandeln wir in drei Abschnitten, wie wir unsere RAG-Ergebnisse für Towards Data Science über LlamaIndex verankern:
Einrichtung zur Verankerung unserer RAG-Ergebnisse
Definition der Parameter unseres Towards-Data-Science-Chatbots
Verankerung unserer Ergebnisse über Zitate
Einrichtung zur Verankerung unserer RAG-Ergebnisse
Wie bei jeder App besteht der erste Schritt darin, die Voraussetzungen einzurichten. Für dieses Beispiel beginnen wir mit der Installation von vier verschiedenen Bibliotheken. Wir benötigen llama-index, python-dotenv, pymilvus und openai. Diese vier Bibliotheken helfen uns jeweils dabei, unser LLM mit Retrieval zu orchestrieren, unsere Umgebungsvariablen zu verwalten, mit einer Vektordatenbank zu arbeiten und mit OpenAI zu arbeiten.
! pip install llama-index python-dotenv openai pymilvus
Der nächste Codeblock richtet OpenAI und Zilliz (die verwaltete Milvus-Vektordatenbank) ein. Wir verwenden die Funktion load_dotenv, um unsere Umgebungsvariablen abzurufen, die typischerweise in der Datei '.env' gespeichert sind. Anschließend übergeben wir die erforderlichen Variablennamen mithilfe von os, um die Werte zu erhalten. OpenAI ist unser LLM, und Zilliz ist unsere Vektordatenbank. In diesem Beispiel verwenden wir Zilliz und eine in der Cloud gespeicherte Collection, um unsere Daten über mehrere App-Versionen hinweg persistent zu halten.
import os
from dotenv import load_dotenv
import openai
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
zilliz_uri = os.getenv("ZILLIZ_URI")
zilliz_token = os.getenv("ZILLIZ_TOKEN")
Definition der Parameter für unseren Towards-Data-Science-Chatbot
Als Nächstes definieren wir die Parameter unseres RAG-Chatbots. Wir müssen drei Elemente einrichten: das Embeddings-Modell, die Milvus-Vektordatenbank und die Datenübergabe-Abstraktionen von LlamaIndex. Zuerst richten wir unser Embedding-Modell ein. Für dieses Beispiel verwenden wir das Embedding-Modell, das wir in meinem vorherigen Blog zum Scrapen und Einbetten der Daten verwendet haben, nämlich das HuggingFace MiniLM L12-Modell. Wir können diese Daten über LlamaIndex mithilfe des Moduls HuggingFaceEmbedding laden.
from llama_index.embeddings import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(model_name="sentence-transformers/all-MiniLM-L12-v2")
Zweitens richten wir die Vektordatenbank ein. Da Zilliz Cloud eine vollständig verwaltete und optimierte Version von Milvus ist, können wir sie mithilfe des Moduls MilvusVectorStore verbinden. Wir geben die URI, das Token, den Collection-Namen, die Ähnlichkeitsmetrik und den Textschlüssel an, um eine Verbindung zu unserer in Zilliz Cloud gehosteten Milvus-Instanz herzustellen.
Unsere Zilliz-URI und Token haben wir zuvor aus unseren Umgebungsvariablen erhalten. Der Collection-Name, die Ähnlichkeitsmetrik und der Textschlüssel werden aus dem ersten Teil dieser Blogserie übernommen, in dem wir die Collection während der Ingestion erstellt haben.
from llama_index.vector_stores import MilvusVectorStore
vdb = MilvusVectorStore(
uri = zilliz_uri,
token = zilliz_token,
collection_name = "tds_articles",
similarity_metric = "L2",
text_key="paragraph"
)
Zuletzt führen wir unsere LlamaIndex-Datenabstraktionen zusammen. Die zwei nativen Komponenten, die wir benötigen, sind der Service-Kontext, der einige vordefinierte Services übergibt, und der Vector Store Index, der aus einem Vector Store einen LlamaIndex-„Index“ erstellt. In diesem Fall verwenden wir den Service-Kontext, um unser Embed-Modell zu übergeben. Anschließend übergeben wir die bestehende Milvus-Vektordatenbank und den erstellten Service-Kontext, um unseren Vektorindex zu erstellen.
from llama_index import VectorStoreIndex, ServiceContext
service_context = ServiceContext.from_defaults(embed_model=embed_model)
vector_index = VectorStoreIndex.from_vector_store(vector_store=vdb, service_context=service_context)
Verankerung unserer Ergebnisse über Zitate in LlamaIndex
Zitate und Quellenangaben sind eine wichtige Ergänzung für dein RAG. Sie ermöglichen dir zu wissen, woher die Antworten in deinem Dokumentenkorpus stammen, und zu bewerten, wie gut deine RAG-Ergebnisse verankert sind.
LlamaIndex bietet mit seinem Modul CitationQueryEngine eine einfache Möglichkeit, Zitate zu implementieren. Der Einstieg in dieses Modul ist super einfach. Mit from_args und der Übergabe des Vektorindex können wir eine Citation Query Engine instanziieren. Wir haben das Textfeld im Vektorindex zuvor definiert, daher müssen wir nichts hinzufügen.
from llama_index.query_engine import CitationQueryEngine
query_engine = CitationQueryEngine.from_args(
vector_index
)
Sobald wir eine Query Engine haben, müssen wir nur noch eine Anfrage senden. Für dieses Beispiel habe ich gefragt: „What is a large language model?“ Dies ist eine Antwort, von der wir erwarten, dass wir sie von Towards Data Science erhalten können. Außerdem habe ich pprint hinzugefügt, um die Ausgabe schön formatiert auszugeben.
res = query_engine.query("What is a large language model?")
from pprint import pprint
pprint(res)
Das folgende Bild zeigt ein Beispiel dafür, wie eine Antwort aussehen würde. Sie enthält die Antwort und zitiert ihre Quellen im Text. Dadurch wissen wir, dass die Antwort verankert ist und woher sie stammt.
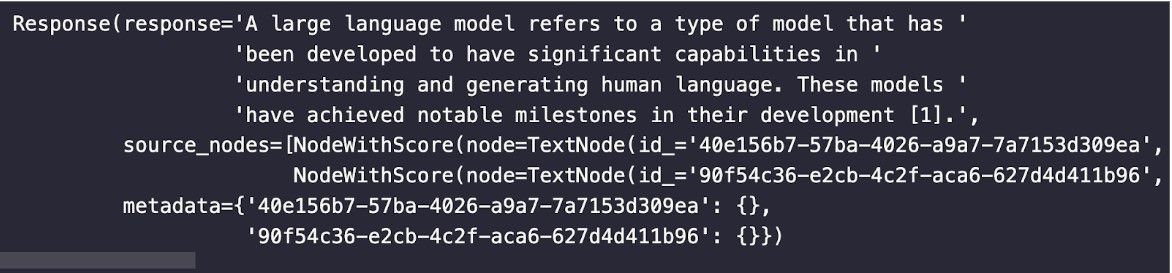
Zusammenfassung zur Verankerung von RAG-Ergebnissen über Zitate und Quellenangaben
Dieses Tutorial ist das dritte in einer Reihe, die sich um die Erstellung eines Chatbots mithilfe von RAG dreht. Wir verwenden für all diese Tutorials dieselben Daten von Towards Data Science. Dieses Tutorial nutzt Zitate und Quellenangaben, um sicherzustellen, dass deine Ergebnisse verankert sind.
Zitate und Quellenangaben lösen zwei Probleme, die RAG traditionell hat. Erstens ermöglichen sie uns zu wissen, woher wir Daten abrufen. Zweitens ermöglichen sie uns zu sehen, wie „wahr“ unsere Antworten gemäß den Daten sind. Dieses Konzept wird auch „Groundedness“ genannt.
Wir haben LlamaIndex und Zilliz Cloud verwendet, um dieses RAG-Tutorial zu erstellen. LlamaIndex ermöglicht es uns, ganz einfach eine Engine aufzusetzen, die die Zitate abruft, solange sie im Vector Store vorhanden sind. Zilliz Cloud ermöglicht es uns, Daten problemlos über mehrere Projekte hinweg zu persistieren.
Um die gesamte Chat Towards Data Science-Reihe noch einmal zu lesen, findest du hier die Links:

Weiterlesen

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

VDBBench Adds Cost-Aware Benchmarking for Vector Databases
Compare Zilliz Cloud, Pinecone, and turbopuffer with VDBBench cost-aware vector database benchmarks across latency, freshness, multitenancy, and cold starts.

DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Discover DeepRAG, an advanced retrieval-augmented generation (RAG) model that improves LLM accuracy by retrieving only essential data through step-by-step reasoning.