




Brauchen wir mit der Veröffentlichung der integrierten Retrieval-Funktion von OpenAI noch Vektordatenbanken für RAG?
OpenAI sorgte während seines DevDay erneut für Schlagzeilen mit einer ganzen Reihe von Veröffentlichungen und stellte das GPT-4 Turbo-Modell, die neue Assistants API sowie eine Reihe von Verbesserungen vor. Die Assistants API erweist sich als leistungsstarkes Tool, das Entwicklern hilft, maßgeschneiderte KI-Anwendungen für spezifische Anforderungen zu erstellen. Außerdem ermöglicht sie ihnen den Zugriff auf zusätzliches Wissen, längere Prompt-Längen und Tools für verschiedene Aufgaben.
Während OpenAI Assistants über eine integrierte Retrieval-Funktion verfügen, ist sie nicht perfekt — man denke an Einschränkungen bei der Datenskalierung und fehlende Möglichkeiten zur Anpassung. Genau hier kommt ein benutzerdefinierter Retriever ins Spiel. Durch die Nutzung der Function-Calling-Funktionen von OpenAI können Entwickler nahtlos einen angepassten Retriever integrieren, den Umfang des zusätzlichen Wissens erweitern und unterschiedliche Anwendungsfälle besser abdecken. In diesem Blogbeitrag gehen wir auf die Einschränkungen des integrierten Retrievals von OpenAI ein und zeigen Ihnen, wie Sie mithilfe der Milvus Vektordatenbank einen benutzerdefinierten Retriever erstellen.
Einschränkungen des OpenAI-Retrievals in Assistants und die Rolle benutzerdefinierter Retrieval-Lösungen
Die integrierte Retrieval-Funktion von OpenAI stellt einen Sprung über das inhärente Wissen des Modells hinaus dar und ermöglicht es Nutzern, es mit zusätzlichen Daten wie proprietären Produktinformationen oder von Nutzern bereitgestellten Dokumenten zu erweitern. Allerdings hat sie mit bemerkenswerten Einschränkungen zu kämpfen.
Skalierbarkeitsbeschränkung
OpenAI Retrieval legt Datei- und Gesamtspeicherbeschränkungen fest, die für umfangreiche Dokumenten-Repositories möglicherweise nicht ausreichen:
Maximal 20 Dateien pro Assistant
Eine Obergrenze von 512 MB pro Datei
Eine verborgene Beschränkung von 2 Millionen Tokens pro Datei, die wir während unserer Tests festgestellt haben
Eine Gesamtgrößenbeschränkung von weniger als 100 GB pro Organisation
Für Organisationen mit umfangreichen Daten-Repositories stellen diese Einschränkungen Herausforderungen dar. Eine skalierbare Lösung, die nahtlos wächst, ohne an Speichergrenzen zu stoßen, wird unerlässlich. Die Integration eines benutzerdefinierten Retrievers, der von einer Vektordatenbank wie Milvus oder Zilliz Cloud (dem verwalteten Milvus) betrieben wird, bietet einen Workaround für die Dateibeschränkungen, die dem integrierten Retrieval von OpenAI innewohnen.
Fehlende Anpassungsmöglichkeiten
Während OpenAI Retrieval eine praktische Out-of-the-box-Lösung bietet, kann es nicht durchgängig auf die spezifischen Anforderungen jeder Anwendung abgestimmt werden, insbesondere im Hinblick auf Latenz und die Anpassung von Suchalgorithmen. Die Nutzung einer Drittanbieter-Vektordatenbank gibt Entwicklern die Flexibilität, den Retrieval-Prozess zu optimieren und zu konfigurieren, um Produktionsanforderungen zu erfüllen und die Gesamteffizienz zu steigern.
Fehlende Mandantenfähigkeit
Retrieval ist eine integrierte Funktion in OpenAI Assistants, die nur die Nutzung durch einzelne Nutzer unterstützt. Wenn Sie jedoch ein Entwickler sind, der Millionen von Nutzern sowohl mit gemeinsamen Dokumenten als auch mit privaten Informationen der Nutzer bedienen möchte, kann die integrierte Retrieval-Funktion nicht helfen. Das Replizieren gemeinsamer Dokumente in den Assistant jedes Nutzers treibt die Speicherkosten in die Höhe, während es Herausforderungen mit sich bringt, wenn alle Nutzer denselben Assistant teilen, um nutzerspezifische private Dokumente zu unterstützen.
Die folgende Grafik zeigt, dass das Speichern von Dokumenten in OpenAI Assistants teuer ist ($6 pro GB und Monat; zum Vergleich: AWS S3 berechnet $0.023), wodurch das Speichern doppelter Dokumente auf OpenAI unglaublich verschwenderisch ist.
 Assistants API Pricing from https://openai.com/pricing
Assistants API Pricing from https://openai.com/pricing
Für Organisationen mit umfangreichen Datensätzen ist ein skalierbarer, effizienter und kostengünstiger Retriever, der auf spezifische betriebliche Anforderungen abgestimmt ist, unerlässlich. Glücklicherweise können Entwickler dank der flexiblen Function-Calling-Funktion von OpenAI nahtlos einen benutzerdefinierten Retriever in OpenAI Assistants integrieren. Diese Lösung stellt sicher, dass Unternehmen die besten von OpenAI bereitgestellten KI-Funktionen nutzen können, während sie gleichzeitig Skalierbarkeit und Flexibilität für ihre einzigartigen Anforderungen bewahren.
Milvus für die angepasste OpenAI-Abfrage nutzen
Milvus ist eine Open-Source-Vektordatenbank, die Milliarden von Vektoren innerhalb von Millisekunden speichern und abrufen kann. Sie ist außerdem hoch skalierbar, um den schnell wachsenden Geschäftsanforderungen der Nutzer gerecht zu werden. Mit schneller Skalierung und extrem niedriger Latenz gehört die Milvus-Vektordatenbank zu den Top-Optionen für den Aufbau eines hoch skalierbaren und effizienteren Retrievers für Ihren OpenAI-Assistenten.
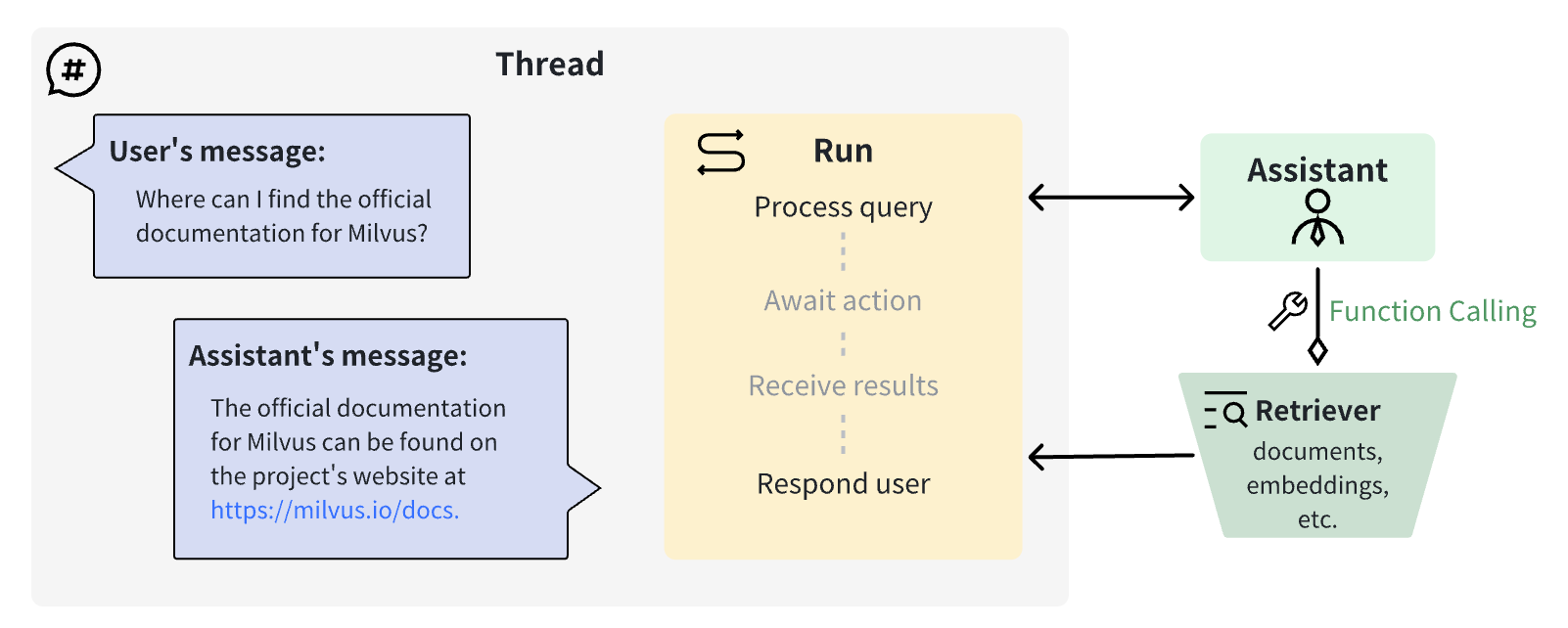 Wie ein benutzerdefinierter OpenAI-Retriever funktioniert
Wie ein benutzerdefinierter OpenAI-Retriever funktioniert
Aufbau eines benutzerdefinierten Retrievers mit OpenAI Function Calling und der Milvus-Vektordatenbank
Beginnen wir mit dem Aufbau des benutzerdefinierten Retrievers und integrieren ihn in OpenAI, indem wir der Schritt-für-Schritt-Anleitung folgen.
- Richten Sie die Umgebung ein.
pip install openai==1.2.0
pip install langchain==0.0.333
pip install pymilvus
export OPENAI_API_KEY=xxxx # Geben Sie hier Ihren OpenAI-API-Schlüssel ein
- Erstellen Sie einen benutzerdefinierten Retriever mit einer Vektordatenbank. Diese Anleitung verwendet Milvus als Vektordatenbank und LangChain als Wrapper.
from langchain.vectorstores import Milvus
from langchain.embeddings import OpenAIEmbeddings
# Retriever vorbereiten
vector_db = Milvus(
embedding_function=OpenAIEmbeddings(),
connection_args = {'host': 'localhost', 'port': '19530'}
)
retriever = vector_db.as_retriever(search_kwargs={'k': 5}) # top_k hier ändern
- Nehmen Sie zusätzliche Dokumente in Milvus auf. Dokumente werden geparst, in Chunks unterteilt und anschließend in Embeddings umgewandelt, bevor sie in die Vektordatenbank aufgenommen werden. Entwickler können jeden Schritt anpassen, um die Qualität der Abfrage zu verbessern.
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Parsen und Chunking des Dokuments.
filepath = 'path/to/your/file'
doc_data = TextLoader(filepath).load_and_split(
RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
)
# Embedding und Einfügen der Chunks in die Vektordatenbank.
vector_db.add_texts([doc.page_content for doc in doc_data])
Jetzt haben Sie erfolgreich einen benutzerdefinierten Retriever erstellt, der eine semantische Suche auf Basis Ihrer privaten oder proprietären Daten durchführen kann. Als Nächstes müssen Sie diesen Retriever mit OpenAI Assistants integrieren, um die Inhaltserstellung zu ermöglichen.
- Erstellen Sie einen Assistant mit OpenAIs Function-Calling-Funktion. Der Assistant wird angewiesen, bei der Beantwortung von Anfragen ein Function-Tool namens
CustomRetrieverzu verwenden.
import os
from openai import OpenAI
# OpenAI-Client einrichten.
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
# Einen Assistant erstellen.
my_assistant = client.beta.assistants.create(
name='Chat with a custom retriever',
instructions='You will search for relevant information via retriever and answer questions based on retrieved information.',
tools=[
{
'type': 'function',
'function': {
'name': 'CustomRetriever',
'description': 'Retrieve relevant information from provided documents.',
'parameters': {
'type': 'object',
'properties': {'query': {'type': 'string', 'description': 'The user query'}},
'required': ['query']
},
}
}
],
model='gpt-4-1106-preview', # OpenAI-Modell hier wechseln
)
- Der Assistant führt Frage-Antwort-Aufgaben asynchron aus.
Runist ein Aufruf eines Assistant während eines Thread. Während des Run-Vorgangs entscheidet der Assistant, ob eine FunktionCustomRetrieveraufrufen muss, und wartet auf das Ergebnis des Funktionsaufrufs.
QUERY = 'ENTER YOUR QUESTION HERE'
# Einen Thread erstellen.
my_thread = client.beta.threads.create(
messages=[
{
'role': 'user',
'content': QUERY,
}
]
)
# Invoke a run of my_assistant on my_thread.
my_run = client.beta.threads.runs.create(
thread_id=my_thread.id,
assistant_id=my_assistant.id
)
# Wait until my_thread halts.
while True:
my_run = client.beta.threads.runs.retrieve(thread_id=thread.id, run_id=my_run.id)
if my_run.status != 'queued':
break
- Jetzt wartet der Assistant auf das Ergebnis des Funktionsaufrufs. Führen Sie eine Vektorsuche für die Abfrage durch und übermitteln Sie das Ergebnis.
# Conduct vector search and parse results when OpenAI Run ready for the next action
if my_run.status == 'requires_action':
tool_outputs = []
for tool_call in my_run.required_action.submit_tool_outputs.tool_calls:
if tool_call.function.name == 'Custom Retriever':
search_res = retriever.get_relevant_documents(QUERY)
tool_outputs.append({
'tool_call_id': tool_call.id,
'output': ('\n\n').join([res.page_content for res in search_res])
})
# Send retrieval results to your Run service
client.beta.threads.runs.submit_tool_outputs(
thread_id=my_thread.id,
run_id=my_run.id,
tool_outputs=tool_outputs
)
- Extrahieren und parsen Sie die vollständige Konversation mit OpenAI.
messages = client.beta.threads.messages.list(
thread_id=my_thread.id
)
for m in messages:
print(f'{m.role}: {m.content[0].text.value}\n')
Geschafft! Sie haben erfolgreich mit Ihrem OpenAI Assistant über das bereitgestellte Wissen gechattet, indem Sie einen benutzerdefinierten Retriever genutzt haben, der von Milvus unterstützt wird.

Fazit
Das integrierte Retrieval-Tool von OpenAI Assistants ist zwar beeindruckend, hat jedoch mit Einschränkungen wie Speicherbegrenzungen, Skalierbarkeitsproblemen und mangelnder Anpassbarkeit für unterschiedliche Nutzeranforderungen zu kämpfen. Es ist nur auf einzelne Nutzer ausgelegt, was Anwendungen mit Millionen von Nutzern sowie sowohl gemeinsam genutzten als auch privaten Dokumenten vor Herausforderungen stellt.
Die Erstellung eines benutzerdefinierten Retrievers mithilfe einer robusten Vektordatenbank wie Milvus oder Zilliz Cloud (der vollständig verwalteten Version von Milvus) erweist sich als hilfreich, um die oben genannten Herausforderungen zu bewältigen. Dieser Ansatz bietet durch die Integration der OpenAI Assistant API mehr Flexibilität und Kontrolle über die Dateiverwaltung.
In unseren nächsten Beiträgen vergleichen wir die Leistung, die Kosten und die Fähigkeiten von OpenAI Retrieval und einem benutzerdefinierten Retriever. Außerdem werden wir Benchmark-Ergebnisse vorstellen und wertvolle Einblicke für Entwickler liefern, die nach optimalen Lösungen zur Verbesserung der Retrieval-Qualität suchen. Bleiben Sie dran!

Weiterlesen

Zilliz Cloud On-Demand Compute: Pay Only for What You Use
The customer case behind Zilliz Cloud On-Demand: how a $10K vector search bill came down to under $500, and the engineering changes that made it possible.

Introducing Business Critical Plan: Enterprise-Grade Security and Compliance for Mission-Critical AI Applications
Discover Zilliz Cloud’s Business Critical Plan—offering advanced security, compliance, and uptime for mission-critical AI and vector database workloads.

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.