




ColPali: Verbesserte Dokumentensuche mit visuellen Sprachmodellen und ColBERT-Einbettungsstrategie
Retrieval Augmented Generation (RAG) ist eine Technik, die die Fähigkeiten von großen Sprachmodellen (LLMs) mit externen Wissensquellen kombiniert, um die Antwortgenauigkeit und Relevanz zu verbessern. Eine häufige Anwendung von RAG ist die Extraktion von Inhalten aus Quellen wie PDFs, da diese Dateien oft wertvolle Daten enthalten, aber schwierig zu durchsuchen und zu indizieren sind. Die Schwierigkeit besteht darin, dass je nach dem für die Extraktion verwendeten Tool wichtige Informationen übersehen werden können. So kann es beispielsweise vorkommen, dass in Bilder eingebetteter Text bei der Extraktion nicht erkannt wird, so dass er später nicht mehr abgerufen werden kann.
ColPali, ein Modell zur Dokumentensuche, geht dieses Problem mit seiner neuartigen Architektur an, die auf Vision Language Models (VLMs) basiert. Es indiziert Dokumente anhand ihrer visuellen Merkmale, wobei textuelle und visuelle Elemente erfasst werden. Durch die Erzeugung von Multi-Vektor-Darstellungen von Text und Bildern im Stil von ColBERT kodiert ColPali die Bilder von Dokumenten direkt in einen einheitlichen Einbettungsraum, wodurch die herkömmliche Textextraktion und Segmentierung entfällt.
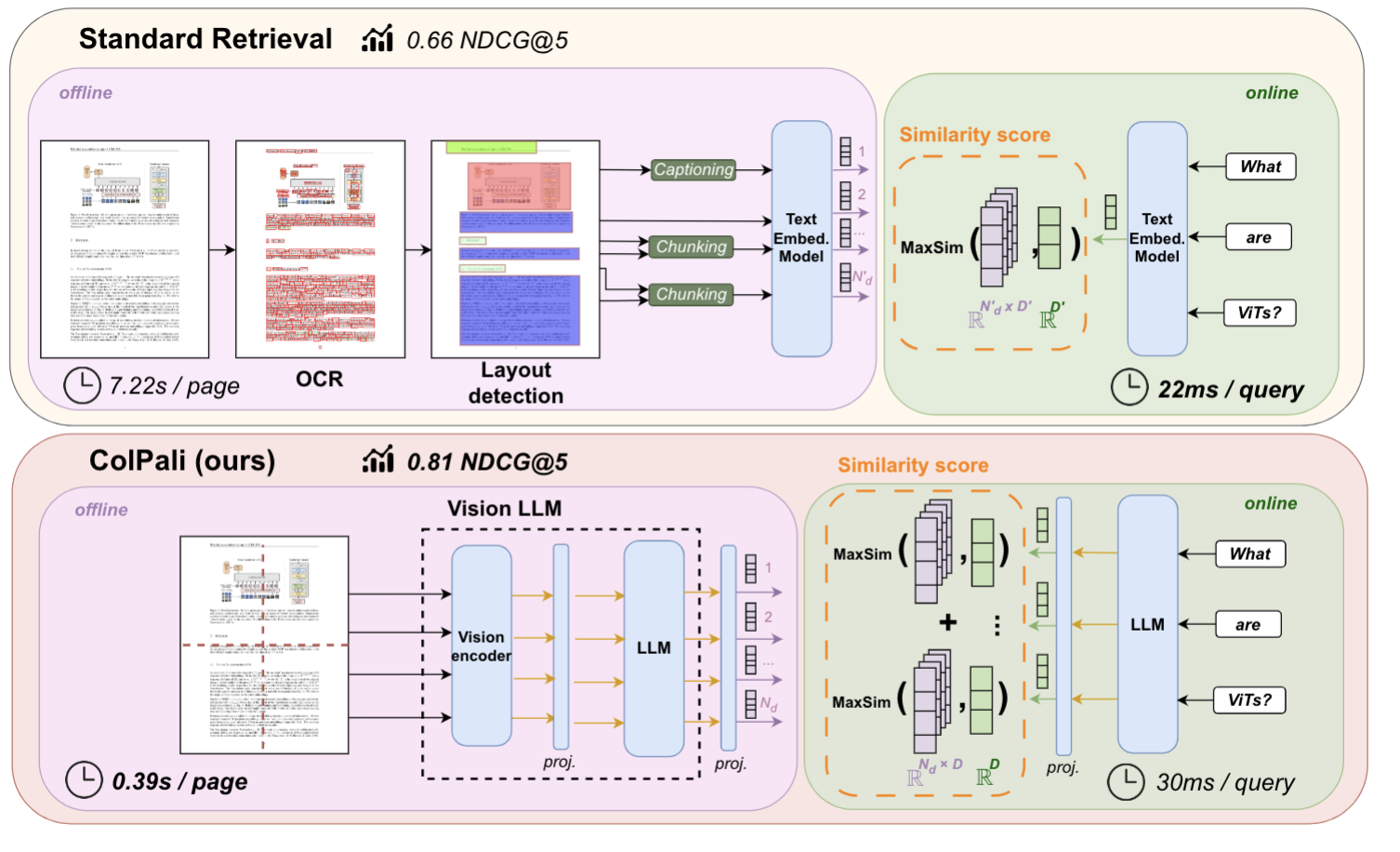 Abbildung: Standard Retrieval Pipeline vs. ColPali Pipeline für PDF Retrieval
Abbildung: Standard Retrieval Pipeline vs. ColPali Pipeline für PDF Retrieval
Die obige Abbildung stammt aus dem ColPali-Papier, in dem die Autoren argumentieren, dass eine reguläre PDF-Retrieval-Pipeline in der Regel mehrere Schritte umfasst: Textextraktion mittels OCR, Layout-Erkennung, Chunking und Embedding. ColPali vereinfacht diesen Prozess durch ein einziges Vision Language Model (VLM), das einen Screenshot der Seite als Eingabe verwendet.
ColPali integriert Werkzeuge, die über die traditionellen RAG-Systeme hinausgehen, daher ist es wichtig, zunächst einige dieser Konzepte zu verstehen. Bevor wir auf die Details von ColPali eingehen, sollten wir uns mit Vision Language Models und Late Interaction Models vertraut machen.
Was sind Vision Language Models (VLMs)?
Vision Language Models (VLMs) sind [multimodale Modelle] (https://zilliz.com/learn/top-10-best-multimodal-ai-models-you-should-know), die gleichzeitig aus Bildern und Text lernen. Sie nehmen Bild- und Texteingaben und erzeugen Textausgaben und sind Teil der breiteren Kategorie der generativen Modelle.
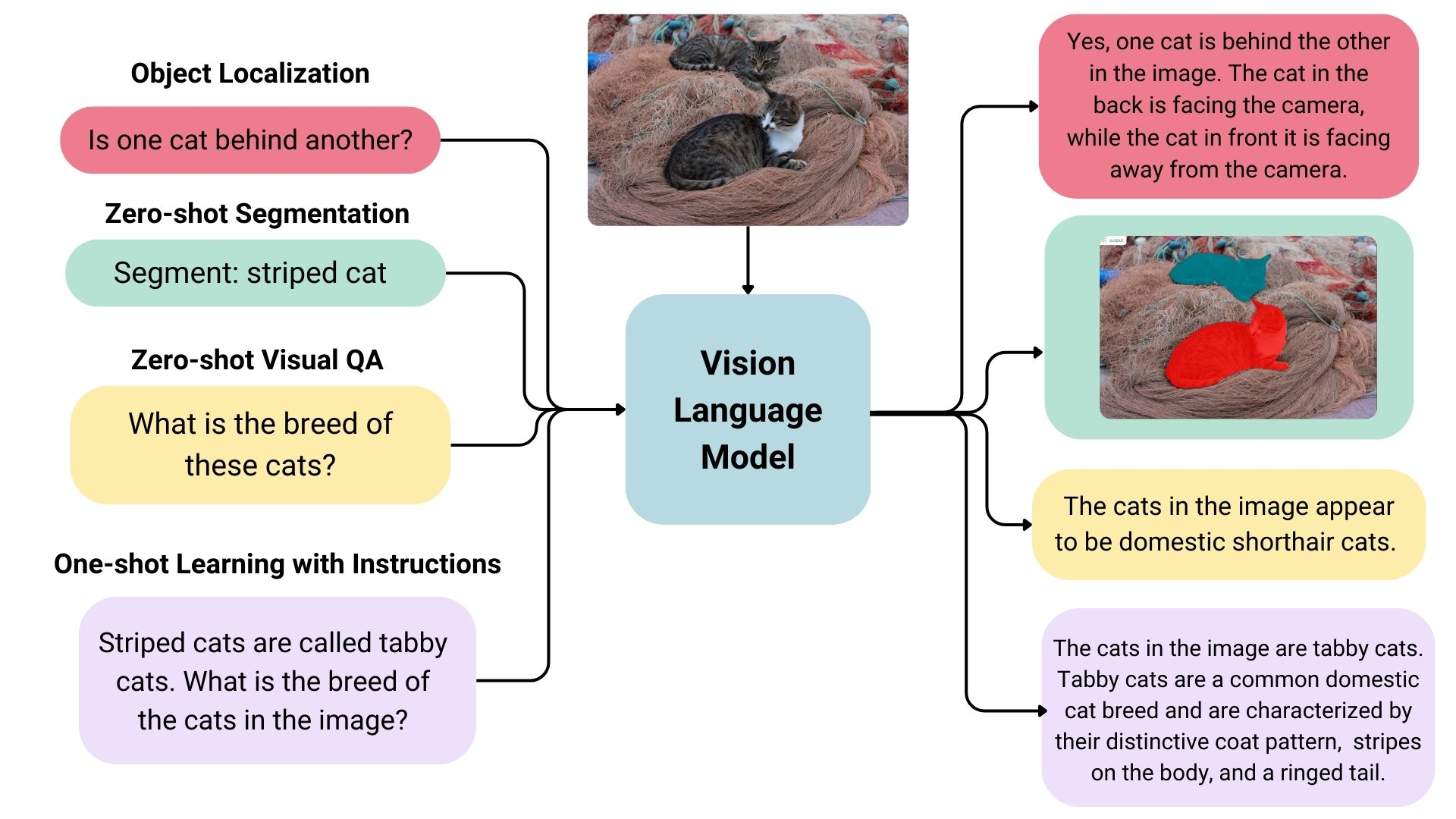 Beispiel für ein VLM
Beispiel für ein VLM
ColPali nutzt VLMs, um Einbettungen von Text- und Bild-Token abzugleichen, die während der multimodalen Feinabstimmung erfasst wurden. Konkret wird eine erweiterte Version des Modells PaliGemma-3B verwendet, um ColBERT-ähnliche Multi-Vektor-Darstellungen zu erzeugen. Die Autoren haben sich für dieses Modell entschieden, weil es über eine Vielzahl von Kontrollpunkten verfügt, die für verschiedene Bildauflösungen und Aufgaben, einschließlich OCR zum Lesen von Text aus Bildern, fein abgestimmt sind.
ColPali basiert auf dem Modell PaliGemma-3B von Google, das mit offenen Gewichten veröffentlicht wurde. Dieses Modell wurde anhand eines vielfältigen Datensatzes trainiert, der zu 63 % aus akademischen und zu 37 % aus synthetischen Daten von im Internet gecrawlten PDF-Seiten besteht und mit VLM-generierten Pseudofragen angereichert wurde.
Was sind Late Interaction Models?
Late Interaction-Modelle sind für Retrieval-Aufgaben konzipiert. Sie konzentrieren sich auf die Ähnlichkeit zwischen Dokumenten auf Token-Ebene, anstatt eine einzelne Vektordarstellung zu verwenden. Durch die Darstellung von Text als eine Reihe von Token-Einbettungen bieten diese Modelle die Detailtreue und Genauigkeit von Cross-Codierern und profitieren gleichzeitig von der Effizienz der Offline-Dokumentenspeicherung.
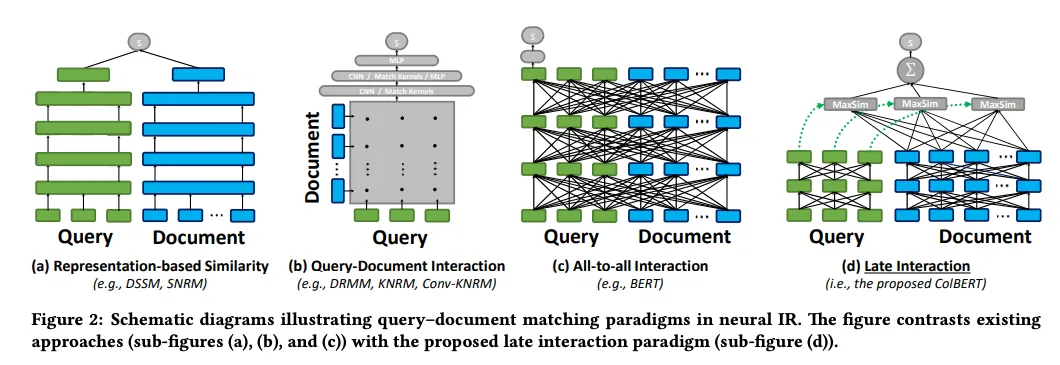 Abbildung 2: Schematische Diagramme zur Veranschaulichung der Paradigmen des Abfrage-Dokumenten-Abgleichs im neuronalen IR
Abbildung 2: Schematische Diagramme zur Veranschaulichung der Paradigmen des Abfrage-Dokumenten-Abgleichs im neuronalen IR
Abbildung 2: Schematische Diagramme zur Veranschaulichung von Paradigmen für den Abfrage-Dokumentenabgleich im neuronalen IR. | Quelle_
Mit diesem Verständnis von Spätinteraktionsmodellen und Bildsprachmodellen können wir nun untersuchen, wie ColPali diese Elemente für eine verbesserte Dokumentensuche kombiniert.
Was ist ColPali und wie funktioniert es?
ColPali ist ein fortschrittliches Modell zur Dokumentensuche, das entwickelt wurde, um Informationen direkt aus den visuellen Merkmalen von Dokumenten, insbesondere PDFs, zu indizieren und abzurufen. Im Gegensatz zu herkömmlichen Methoden, die sich auf OCR (Optical Character Recognition) und Textsegmentierung stützen, erfasst ColPali Screenshots von jeder Seite und bettet ganze Dokumentseiten in einen einheitlichen Vektorraum unter Verwendung von VLMs ein. Mit diesem Ansatz umgeht ColPali komplexe Extraktionsprozesse und verbessert die Abrufgenauigkeit und Effizienz.
Nachfolgend sind die wichtigsten Schritte des Arbeitsablaufs aufgeführt:
Verarbeitung der Dokumente
- Erstellung von Bildern aus PDFs: Anstatt Text zu extrahieren, Stücke zu erstellen und diese dann einzubetten, bettet ColPali den Screenshot einer PDF-Seite direkt in eine Vektordarstellung ein. Dieser Schritt ist so, als würde man ein Foto von jeder Seite machen, anstatt zu versuchen, den Inhalt zu extrahieren.
- Bilder in Raster aufteilen: Jede Seite wird dann in ein Raster aus gleichförmigen Teilen, den so genannten Patches, unterteilt. Standardmäßig wird es in ein 32x32-Gitter unterteilt, was 1024 Felder pro Bild ergibt. Jedes Feld wird als 128-dimensionaler Vektor dargestellt. Man kann es sich als ein Bild mit 1024 "Wörtern" vorstellen, die diese Flecken beschreiben.
Erzeugung von Einbettungen
- Verarbeitung der Bildfelder: ColPali transformiert diese visuellen Flecken in Einbettungen durch einen Vision Transformer (ViT), der jeden Fleck verarbeitet, um eine detaillierte Vektordarstellung zu erstellen.
- Abgleich von Bild- und Texteinbettungen: Um die visuellen Informationen mit der Suchanfrage abzugleichen, konvertiert ColPali den Abfragetext in Einbettungen im gleichen Vektorraum wie die Bildfelder. Diese Ausrichtung ermöglicht es dem Modell, visuelle und textuelle Inhalte direkt zu vergleichen und abzugleichen.
- Anfrageverarbeitung: Das Modell tokenisiert die Anfrage und ordnet jedem Token einen 128-dimensionalen Vektor zu. Es verwendet Aufforderungen wie "Beschreiben Sie dieses Bild
", um sicherzustellen, dass sich das Modell auf die visuellen Elemente konzentriert und eine nahtlose Integration von Text und visuellen Daten ermöglicht.
Abrufmechanismus
ColPali verwendet einen Spätinteraktionsähnlichkeitsmechanismus, um die Abfrage und die Dokumenteneinbettung zum Zeitpunkt der Abfrage zu vergleichen. Dieser Ansatz ermöglicht eine detaillierte Interaktion zwischen allen Vektoren der Bildrasterzellen und den Token-Vektoren des Abfragetextes und gewährleistet so einen umfassenden Vergleich.
Die Ähnlichkeit wird mit einem "Summe der maximalen Ähnlichkeiten"-Ansatz errechnet:
- Berechnung von Ähnlichkeitswerten zwischen jedem Abfrage-Token und jedem Patch-Token im Bild.
- Aggregieren Sie diese Werte, um einen Relevanzwert für jedes Dokument zu erhalten.
- Sortieren Sie die Dokumente nach der Punktzahl in absteigender Reihenfolge, wobei die Punktzahl als Relevanzmaß verwendet wird.
Diese Methode ermöglicht es ColPali, Benutzeranfragen effektiv mit relevanten Dokumenten abzugleichen, indem es sich auf die Bildbereiche konzentriert, die am besten mit dem Abfragetext übereinstimmen. Auf diese Weise werden die relevantesten Teile des Dokuments hervorgehoben und textliche und visuelle Inhalte für eine präzise Suche kombiniert.
Modell-Trainingsverfahren
ColPali basiert auf dem PaliGemma-3B-Modell, einem von Google entwickelten Vision Language Model. Bei der Implementierung von ColPali werden die Gewichte des Modells während des Trainings eingefroren, um das vortrainierte Wissen des VLM beizubehalten und sich gleichzeitig auf die Optimierung für Dokumentenabrufaufgaben zu konzentrieren.
Der Schlüssel zur Anpassung dieses Allzweck-VLMs für die Dokumentensuche liegt in einer kleinen, aber entscheidenden Komponente: einem Retrieval-spezifischen Adapter. Dieser Adapter wird auf das PaliGemma-3B-Modell aufgesetzt und so trainiert, dass er auf Retrieval-Aufgaben zugeschnittene Repräsentationen lernt.
Der Trainingsprozess für diesen Adapter basiert auf einem Triplett-Lernansatz:
- Eine Textabfrage
- Ein Bild einer für die Abfrage relevanten Seite
- Ein Bild einer Seite, die für die Abfrage irrelevant ist
Diese Methode ermöglicht es dem Modell, feinkörnige Unterscheidungen zwischen relevanten und irrelevanten Inhalten zu erlernen, was die Abfragegenauigkeit erhöht.
ColPali Vorteile
- Wegfall der komplexen Vorverarbeitung**: ColPali ersetzt die herkömmliche Pipeline aus Textextraktion, OCR, Layouterkennung und Chunking durch ein einziges VLM, das einen Screenshot der Seite als Input nimmt.
- Erfassen von visuellen und textlichen Informationen: Durch die direkte Verarbeitung von Seitenbildern kann ColPali sowohl Textinhalte als auch das visuelle Layout in sein Verständnis von Dokumenten einbeziehen.
- Effiziente Abfrage von visuell reichhaltigen Dokumenten: Der Mechanismus der späten Interaktion ermöglicht einen feinkörnigen Abgleich zwischen Abfragen und Dokumentinhalt und damit eine effiziente Suche nach relevanten Informationen in komplexen, visuell reichhaltigen Dokumenten.
- Erhaltung des Kontexts: Da ColPali mit Bildern ganzer Seiten arbeitet, bleibt der vollständige Kontext des Dokuments erhalten, der bei herkömmlichen Text-Chunking-Ansätzen verloren gehen kann.
ColPali Herausforderungen
Wie jedes groß angelegte Retrievalsystem steht auch ColPali vor erheblichen Herausforderungen in Bezug auf Rechenkomplexität und Speicherbedarf.
Berechnungskomplexität: Die Rechenanforderungen für ColPali wachsen quadratisch mit der Anzahl der Abfrage-Token und Patch-Vektoren. Das bedeutet, dass mit zunehmender Komplexität der Abfragen oder der Auflösung der Dokumentenbilder der Rechenaufwand rapide ansteigt.
Speicherbedarf: Die Speicherkosten von ColBERT-ähnlichen Ansätzen betragen das 10- bis 100-fache der dichten Vektoreinbettung, da für jedes Token ein Vektor benötigt wird. Der Speicherbedarf des Systems skaliert linear mit drei Faktoren:
Anzahl der Dokumente
Anzahl der Patches pro Dokument
[Dimensionalität] (https://zilliz.com/glossary/curse-of-dimensionality-in-machine-learning) der Vektorrepräsentationen.
Diese Skalierung kann bei großen Dokumentensammlungen zu erheblichen Speicheranforderungen führen.
Optimierungsstrategie - Präzisionsreduzierung
Zur Bewältigung dieser Skalierungsprobleme schlagen wir die Strategie der Präzisionsreduzierung vor.
- Präzisionsreduzierung: Der Wechsel von Darstellungen mit höherer Genauigkeit (z. B. 32-Bit-Gleitkommazahlen) zu Formaten mit geringerer Genauigkeit (z. B. 8-Bit-Ganzzahlen) kann die Speicheranforderungen drastisch reduzieren, wobei die Abrufqualität oft nur minimal beeinträchtigt wird.
Zusammenfassung
ColPali hat ein erhebliches Potenzial, die Art und Weise zu verändern, wie wir visuell reichhaltige Inhalte mit textuellem Kontext in RAG-Systemen abrufen. Durch die Nutzung von Vision Language Models ermöglicht es die Suche nach Dokumenten nicht nur auf der Basis von Text, sondern auch von visuellen Elementen.
Trotz seiner beeindruckenden Ergebnisse steht ColPali jedoch aufgrund seines hohen Speicherbedarfs und seiner Rechenkomplexität vor Herausforderungen, die einer breiten Anwendung im Wege stehen könnten. Zukünftige Optimierungen könnten diese Einschränkungen beheben und das Verfahren praktikabler machen. Mit der Weiterentwicklung der RAG-Methoden werden Retrieval-Methoden wie ColPali, die visuelles und textuelles Verständnis integrieren, wahrscheinlich eine immer wichtigere Rolle im Information Retrieval über verschiedene Dokumenttypen hinweg spielen.
Wir würden gerne hören, was Sie denken!
Wenn Ihnen dieser Blogbeitrag gefällt, würden wir uns freuen, wenn Sie uns auf GitHub einen Stern geben würden! Sie sind auch herzlich eingeladen, unserer Milvus-Community auf Discord beizutreten, um Ihre Erfahrungen zu teilen. Wenn Sie mehr erfahren möchten, schauen Sie sich unser Bootcamp Repository auf GitHub oder unsere notebooks an. Wir würden uns auch freuen zu hören, ob Sie ColPali in Zukunft ausprobieren möchten!
Weitere Lektüre
- ColPali Papier: [2407.01449] ColPali: Efficient Document Retrieval with Vision Language Models
- ColPali GitHub: https://github.com/illuin-tech/colpali
- ColBERT: Ein Einbettungs- und Ranking-Modell auf Token-Ebene](https://zilliz.com/learn/explore-colbert-token-level-embedding-and-ranking-model-for-similarity-search)
- ColPali: Dokumentensuche mit visuellen Sprachmodellen
- Was ist RAG?
- Was sind Vektordatenbanken und wie funktionieren sie?](https://zilliz.com/learn/what-is-vector-database)

Weiterlesen

Zilliz Cloud On-Demand Compute: Pay Only for What You Use
The customer case behind Zilliz Cloud On-Demand: how a $10K vector search bill came down to under $500, and the engineering changes that made it possible.

How Zilliz Ended Up at the Center of NVIDIA’s Unstructured Data Story at GTC 2026
If unstructured data is the context of AI, then the ceiling of AI applications will be set not just by models, but by how mature the infrastructure for unstructured data becomes.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.