




Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Key takeaways
This is a long, in-depth engineering dive, so here are the key points before we get into the details.
- AI datasets are not static tables. The same rows keep changing as teams replace embedding models, add sparse vectors, revise captions, backfill labels, rebuild indexes, and run offline analysis.
- Traditional storage layouts break down in three ways: long vector columns make backfills expensive, a single file format cannot serve both scans and point reads well, and private database storage forces external pipelines to create extra copies of the truth.
- Loon is the new storage engine for Milvus and Zilliz Vector Lakebase. It is built around hybrid file formats, row ID alignment, and a Manifest that defines the dataset’s versioned state.
- The goal is to enable a single vector dataset to support online search, offline analysis, backfills, compaction, and external compute without constantly copying, rewriting, or reimporting data.
Introduction
For a while, there was one argument against vector databases that sounded reasonable.
Traditional databases already store integers, strings, JSON, blobs, and indexes. Why not add a _vector_ type, build an ANN index beside it, and call it a day?
For early semantic search, that works well enough. A vector column plus an index can support a demo, a small RAG application, or an internal search feature. The problem shows up later, when the dataset starts behaving less like a table and more like an AI data system.
A production vector dataset has rows, primary keys, scalar fields, and queryable columns. In that sense, it looks like a database table. But it also has the scale and workflow shape of a data lake. It may contain hundreds of millions of records. It is repeatedly read and rewritten by Spark, Ray, DuckDB, training pipelines, evaluation jobs, and data quality systems.
It also depends on object storage. The source objects are often videos, images, PDFs, audio files, or web documents that remain in S3, GCS, OSS, or another object store. The database stores references, metadata, derived features, and indexes. Then it adds things traditional storage models were not built to manage as first-class objects: dense embeddings, sparse vectors, captions, vector indexes, text indexes, delete logs, statistics, model versions, parser versions, external blob references, and the version relationships between all of them.
That is where “just add a vector column” starts to break down. The issue is not whether a database can store vector bytes. Many systems can. The harder question is whether the storage model can handle how vector data changes, how it is queried, and how it is shared across the AI data stack.
This is why we built Loon, the new storage engine for Milvus and Zilliz Vector Lakebase (the next evolution of Zilliz Cloud).
Loon is designed with three ideas:
- Use different physical formats for different kinds of columns.
- Align those columns through a shared row ID space.
- Use a Manifest to define the dataset's versioned state.
To see why those pieces matter, let's start with a common multimodal workflow.
A vector dataset is never really finished.
Imagine an AI team building a video dataset for multimodal training.
A long video is uploaded to object storage. A pipeline cuts it into clips based on scene changes, shot boundaries, or time windows. Clips that are too long or too short, blurry, duplicated, or low-quality are filtered out. The remaining clips are scored by an aesthetic model, captioned by another model, embedded by a vision-language model, and stored in a vector database for search, deduplication, and training-data filtering.
At a high level, the workflow looks simple:
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
But the dataset does not arrive fully formed.
- In the first week, the table may only contain
clip_id,video_id,start_offset, andduration. - In the second week, the team adds
aesthetic_score. - In the third week, a captioning model runs, and each clip gets a
caption. - In the fourth week, the first embedding model goes online, and each clip gets a 768-dimensional CLIP embedding.
- A month later, the team switches models and backfills
embedding_v2, now with 1024 dimensions. - Two months later, hybrid search becomes a requirement, so the team adds a sparse vector column.
- Three months later, captions undergo human review and must be corrected in place.
The dataset was never completed. It kept accumulating new interpretations of the same underlying rows.
That is one of the core differences between vector data and traditional business data. The same row gets reprocessed again and again. And scale turns this from an inconvenience into a storage problem: multimodal datasets are often not millions of records but hundreds of millions or billions. LAION-5B is a useful reference for the shape — billions of image-text pairs, each with metadata, captions, and embeddings. So the hard part is not the first insert. The hard part is everything that happens after the dataset starts evolving. That evolution exposes three problems.
The first problem: long columns make write amplification expensive
Columnar formats such as Parquet are excellent for many analytical workloads. They work well when schemas are fairly stable, data is read more often than rewritten, scans only touch a subset of columns, and compression matters. That is the world for which many analytical formats were optimized.
Vector rows are much wider than analytical rows
TPC-H lineitem is a good baseline. It has 16 columns: integer keys, decimal values, dates, short strings, and a small comment field. One uncompressed row is roughly 150 bytes. After compression, it may be much smaller. With a 64 MB row group, a storage system can pack hundreds of thousands of rows into one group.
Vector datasets do not look like that.
A LAION-style image-text dataset is much closer to what many AI pipelines produce today. Each row still has ordinary metadata: a URL, a caption, width, height, quality scores, labels, and so on. But once the embedding is added, the row's physical shape changes.
A 768-dimensional CLIP vector takes about 1.5 KB in fp16 or 3 KB in fp32. That one column can be much larger than an entire TPC-H lineitem row.
And 768 dimensions are not unusual or large by today’s standards. A 1024- or 2048-dimensional embedding is common in multimodal pipelines. OpenAI’s text-embedding-3-large goes up to 3072 dimensions, which is about 12 KB per vector in fp32.
The comparison is stark:
| Dataset shape | Approximate row size | Dominant field |
|---|---|---|
| TPC-H lineitem | ~150 bytes uncompressed | scalar and short strings |
| LAION-style row with 768-dim fp16 vector | ~1.5 KB+ | embedding |
| LAION-style row with 768-dim fp32 vector | ~3 KB+ | embedding |
| Row with 3072-dim fp32 vector | ~12 KB+ for the vector alone | embedding |
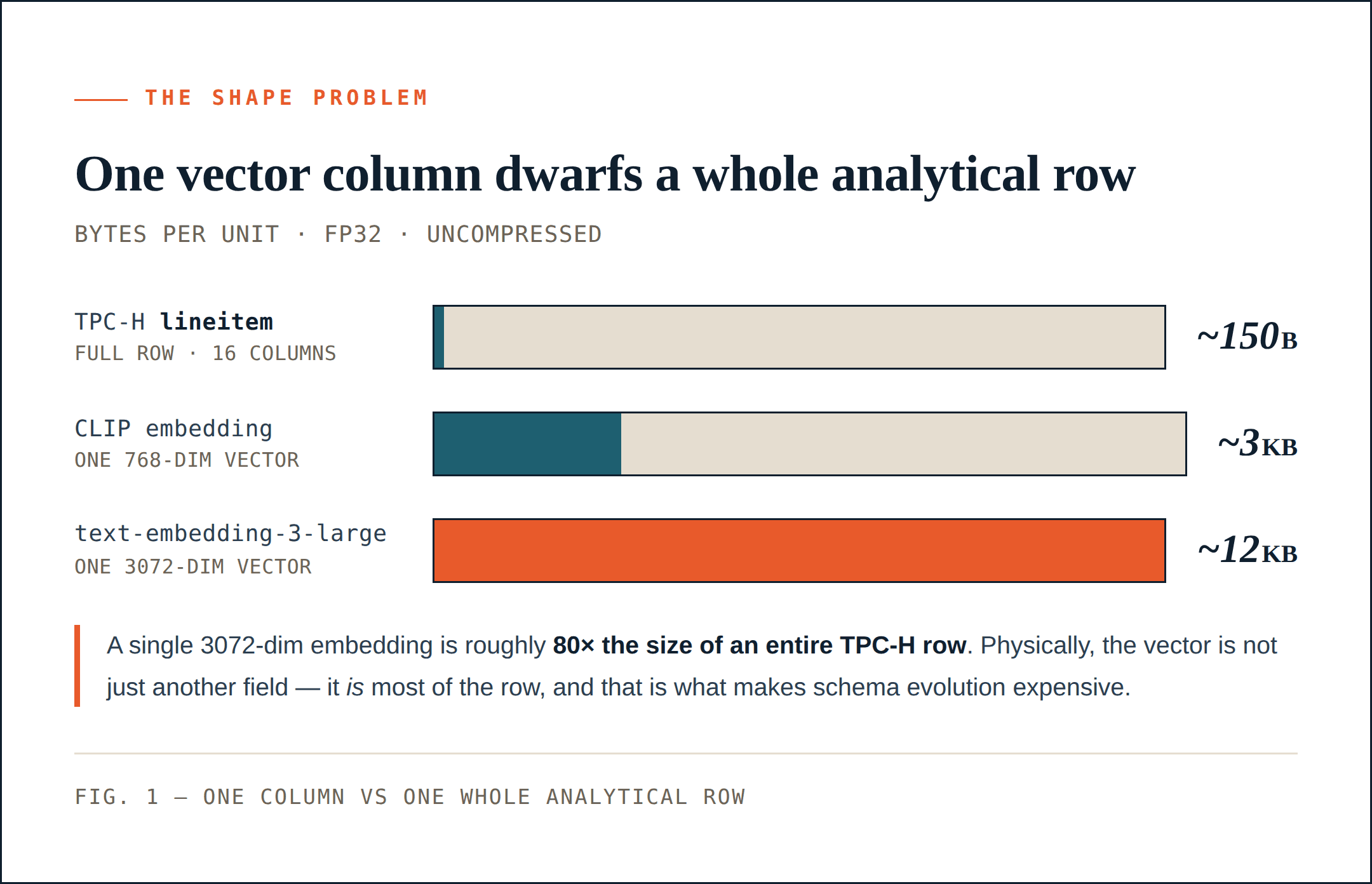
In many AI datasets, the vector column is not just another field. Physically, it is most of the row. That changes the cost of schema evolution.
Adding one vector column can mean hundreds of gigabytes
Suppose a dataset has 100 million video clips. Adding a new 1024-dimensional fp32 embedding column means writing roughly 400 GB of raw vector data. That does not include statistics, indexes, metadata updates, object storage overhead, validation, or serving-path integration.

If the team adds one or two vector-like columns every month, such as embedding_v2, sparse_vector, or rerank features, schema evolution becomes a recurring data engineering job measured in hundreds of gigabytes or terabytes.
Small logical updates can trigger large physical rewrites
Updates are just as important.
In columnar systems, old data is usually not updated in place. A delete log records what changed, and compaction later rewrites live rows into new files. That model is manageable when rows are small.
With vector data, a small logical update can trigger a large physical rewrite.
A human review job may only correct a few hundred bytes in a caption. But if the caption, dense vector, sparse vector, and other derived features share the same physical file lifecycle, the system may end up rewriting the vectors too. The logical change is small. The physical I/O can be huge.
This is the write amplification problem in vector storage. The expensive part is not only that vectors are large. It is that large derived fields and small mutable fields often get tied together by a storage layout that treats them as one unit.
For AI datasets, backfill is a routine workload
For traditional analytical tables, schema evolution may occur only occasionally. For AI datasets, it is routine. Caption models are upgraded. Embedding models are replaced. Sparse vectors are added later. Rerank features appear. Human labels are corrected. Governance tags are backfilled. Indexes are rebuilt.
These operations are not simple appends. They frequently modify or extend existing rows.
That is why vector storage cannot only optimize for scan throughput. It also has to make backfills and partial updates cheaper.
The second problem: the same data must support scans and point reads
After the data is written, the read path splits. The same vector dataset typically has two distinct access patterns: analytical scanning and point reads.

Analytical workloads want wide, compressed scans
A pipeline may run filters such as:
WHERE aesthetic_score > 0.8 AND duration > 5
Or it may run offline analysis, full embedding evaluation, BM25 statistics, bitmap construction, data quality checks, counts, and group-bys.
This pattern reads many rows but only a few columns. It likes sequential I/O, larger row groups, compression, column pruning, batch decoding, and vectorized execution.
Large row groups help here. They let a single I/O request pull a large amount of useful data, improve compression efficiency, and provide the execution engine with enough contiguous data to amortize overhead. When multiple columns are read together, keeping them organized for scan throughput also helps reduce cache misses during vectorized execution.
Parquet is strong on this path.
ANN results need narrow, row-level lookups
After the ANN search returns candidate row IDs, the system often needs to fetch fields such as:
caption
embedding
rerank feature
video_uri
metadata
This pattern reads fewer rows, often hundreds or thousands, but it needs precise access by row ID. It wants to locate a specific row and column, fetch only the required byte range, and avoid pulling an entire row group just to retrieve a few records.
Point lookup has almost the opposite preference for scanning. It wants a smaller read granularity. Ideally, the storage layer can find the relevant segment or byte range by row ID, read only that range, and decode only the data needed for the result.
Compression also has a different tradeoff. For scans, heavier compression is often worth it because the system reads a lot of data and saves I/O. For point lookup, compression can become a liability if retrieving one row requires decoding a much larger compressed block.
One layout cannot optimize for both paths
This is the core conflict. Scalar filtering and analytics want wide, compressed, scan-friendly layouts. Vector lookup wants narrow, precise, row-addressable layouts.
A single file format can support both to some degree, but it cannot be optimal for both simultaneously.
If all columns live in Parquet, scalar scans are comfortable. But ANN lookup after recall becomes harder. The system may only need a few hundred vectors, captions, or metadata records, while the storage layer may have to read large row groups that contain mostly irrelevant rows.
On a local SSD, cache and mmap can hide part of this cost. Once the data is stored in object storage, the cost becomes more visible. Every cache miss can become a remote range read. If candidate rows are scattered across many row groups, a single query can trigger multiple reads, each pulling more data than the query needs. In a poorly laid out layout, fetching 1,000 candidate rows can easily result in tens or hundreds of megabytes of unnecessary I/O, and in extreme cases, much more.
Making row groups smaller helps point lookup, but it hurts scans. Too many small fragments reduce compression efficiency, increase metadata overhead, and break the long sequential reads that analytical engines depend on.
So the problem is not about finding a single magic row group size. The problem is that the same dataset is being asked to behave like two different storage systems.
Hybrid search forces both paths into one query
Hybrid search makes the conflict harder to ignore. A single query may first apply scalar filters:
aesthetic_score > 0.8 AND duration > 5
Then it runs ANN search.
Then it fetches caption, vector, and metadata by row ID.
To the user, this is one search request. To the storage layer, it is both an analytical scan and a low-latency random lookup.
That is why vector storage needs more than a better Parquet setting. It needs a way to place different columns according to how they are actually read.
The third problem: the dataset does not live inside one engine
The first two problems happen inside the database. The third happens at the boundary between systems.

AI data pipelines span many systems
In the video workflow, very little happens within the vector database itself.
The raw videos live in object storage. Clip generation may run in Spark or Ray. Aesthetic scoring may run in a GPU service. Captioning may run in an LLM inference pipeline. Embeddings may be generated by another GPU job. Sparse vectors may come from a SPLADE service. Offline evaluation, training data filtering, human review, and governance jobs may all run elsewhere.
The vector database serves online search, but the dataset is produced, corrected, evaluated, and extended by many systems.
Private storage formats create multiple copies of the truth
If the database uses a private physical format that only it can read and write, every external job needs an export, a conversion, a copy, and an import. The same collection may exist in the database, in a Spark temporary directory, in an evaluation output, and in a local backfill directory. Then the real question becomes:
- Which copy is the source of truth?
- Which one contains the caption model from last month?
- Which rows have already been corrected by human review?
- Which sparse vector column was generated by which model?
- Which vector index is still valid after the backfill?
- Which original video object does this row refer to?
On a small scale, teams can sometimes survive with naming conventions and manual checks. With hundreds of millions of rows and terabytes of embeddings, this becomes a consistency problem.
Vector datasets need a shared versioned state
Lakehouse systems addressed a version of this problem for structured data. Iceberg, Delta Lake, and Hudi are not just about storing files. Their core contribution is letting multiple engines coordinate around the same table state.
Vector databases now need a similar capability, but the state is more complex. It must include not only table files and partitions, but also vector indexes, text indexes, sparse features, delete logs, statistics, row ID ranges, and references to external blobs.
The question is not simply, “Can Spark read Milvus files?”
The question is, after Spark backfills a sparse vector column, how does Milvus know which version that column belongs to, which rows it covers, which model produced it, and when can online queries safely use it?
The answer has to live in the storage model.
Why patches are not enough
It is tempting to treat these as three separate engineering problems.
- Write amplification? Add batching.
- Point reads? Add a cache.
- External systems? Add export and import tools.
Those patches can help, but they do not address the underlying issue: a vector dataset is physically heterogeneous.

In the video example, clip_id, video_id, duration, and aesthetic_score are short scalar fields. They are useful for filtering and analysis.
captionis text. It may be used for BM25, review, correction, and backfill.embeddingis a long, dense vector. It is used for ANN recall and later for row-level lookup or reranking.embedding_v2is a new model output, often backfilled long after the original data was inserted.sparse_vectorsupports hybrid search and has its own access pattern.- The raw video should stay in object storage. The database should store a reference, a checksum, a MIME type, a parser version, and a row-level relationship.
- Vector indexes, text indexes, statistics, and delete logs are derived objects with their own version semantics.
These objects share a logical row, but they should not all share the same physical layout or lifecycle.
- If they are forced into one ordinary table layout, updates become expensive.
- If they are forced into one columnar file format, point reads become expensive.
- If they are treated as unrelated object files, version management becomes fragile.
So the storage model has to start from the fact that the dataset is heterogeneous.
That leads to three design requirements:
- First, different column groups should be stored in different physical formats.
- Second, those column groups need a shared row ID space, so they can still behave as a single logical table.
- Third, the dataset needs a versioned Manifest that declares which files, indexes, logs, statistics, and object references belong to the current view.
This is the design behind Loon, our new storage engine behind Milvus and Zilliz Cloud.
Loon: a storage engine behind Milvus and Zilliz Cloud for evolving vector datasets
To solve all the above problems, we built Loon, the new storage engine for Milvus and Zilliz Vector Lakebase (the next evolution of Zilliz Cloud), designed for evolving vector datasets.
The name follows Zilliz’s bird-naming tradition. A loon is a diving bird that lives on lakes, which maps well to the goal of the system: a vector database should not have to move, scan, or rewrite an entire lake of data every time it runs a query, backfills a column, or builds an index. It should first understand the current dataset version, including its columns, indexes, statistics, delete logs, and object references, then read only the part it actually needs.
Hybrid file formats, row ID alignment, and Manifest are not three separate features. They stem from the same design assumption: a vector dataset is inherently heterogeneous.
Three pieces, one storage model
Hybrid file formats acknowledge that different columns have different access patterns. Scalar fields are good for scans and filters. Vector fields need efficient row-level lookup. Raw objects such as videos, PDFs, images, and audio files belong in object storage, not inside database data files.
Row ID alignment acknowledges that these columns may be physically separated, but they still describe the same logical rows. A caption, an embedding, a sparse vector, and a video URI may reside in different files and formats, but they still need to be brought back together as a single result.
The Manifest acknowledges that the dataset is not written once and left alone. It will be modified by multiple systems, across multiple versions, for multiple tasks. Indexes, statistics, delete logs, external object references, and column groups must all appear in the same versioned view.
This is why Loon is not just a faster vector file format. A faster format helps point lookup, but it does not solve schema evolution or multi-engine coordination. Row ID alignment lets split columns behave as a single table, but it does not specify which files belong to the current version. A Manifest can describe a dataset state, but without column groups and row ID alignment, it cannot cleanly represent different physical layouts inside one logical collection.
The storage model needs all three: different formats for different column groups, a shared row ID space to reconstruct rows, and a versioned Manifest that tells every reader and writer what the dataset currently is.
Where Loon fits in Milvus and Zilliz Vector Lakebase
In Milvus, it replaces the old segment binlog storage layer with a model built around Manifest, ColumnGroup, file format, and filesystem abstractions. In Zilliz Vector Lakebase (the next evolution of Zilliz Cloud), the same direction applies to Vector Lakebase architecture: keep the vector database serving path fast while making the underlying data easier to evolve, analyze, and coordinate with external systems.
The upper-level Milvus components still keep their familiar roles. Proxy handles routing. QueryCoord and DataCoord handle scheduling. IndexNode builds indexes. The application-facing APIs for collections, inserts, searches, and hybrid searches do not need to expose Manifest files or ColumnGroups.
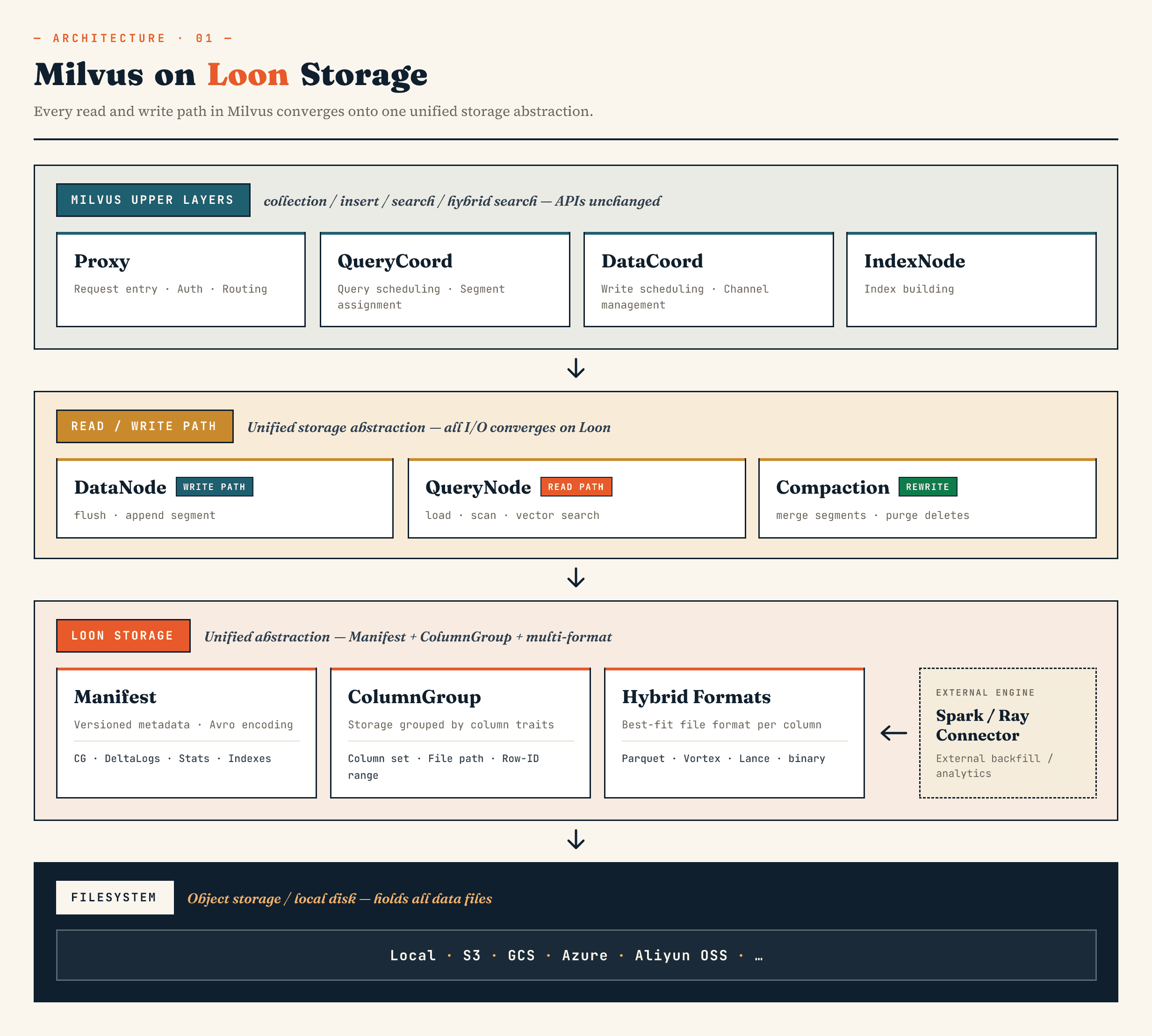
The change is underneath.
DataNode, QueryNode, segcore, compaction, and external connectors can operate through the same storage abstraction. That matters because the dataset is no longer written and read only by the database. It may be extended by external computing systems and consumed by online search simultaneously.
At a high level, the layers look like this:
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
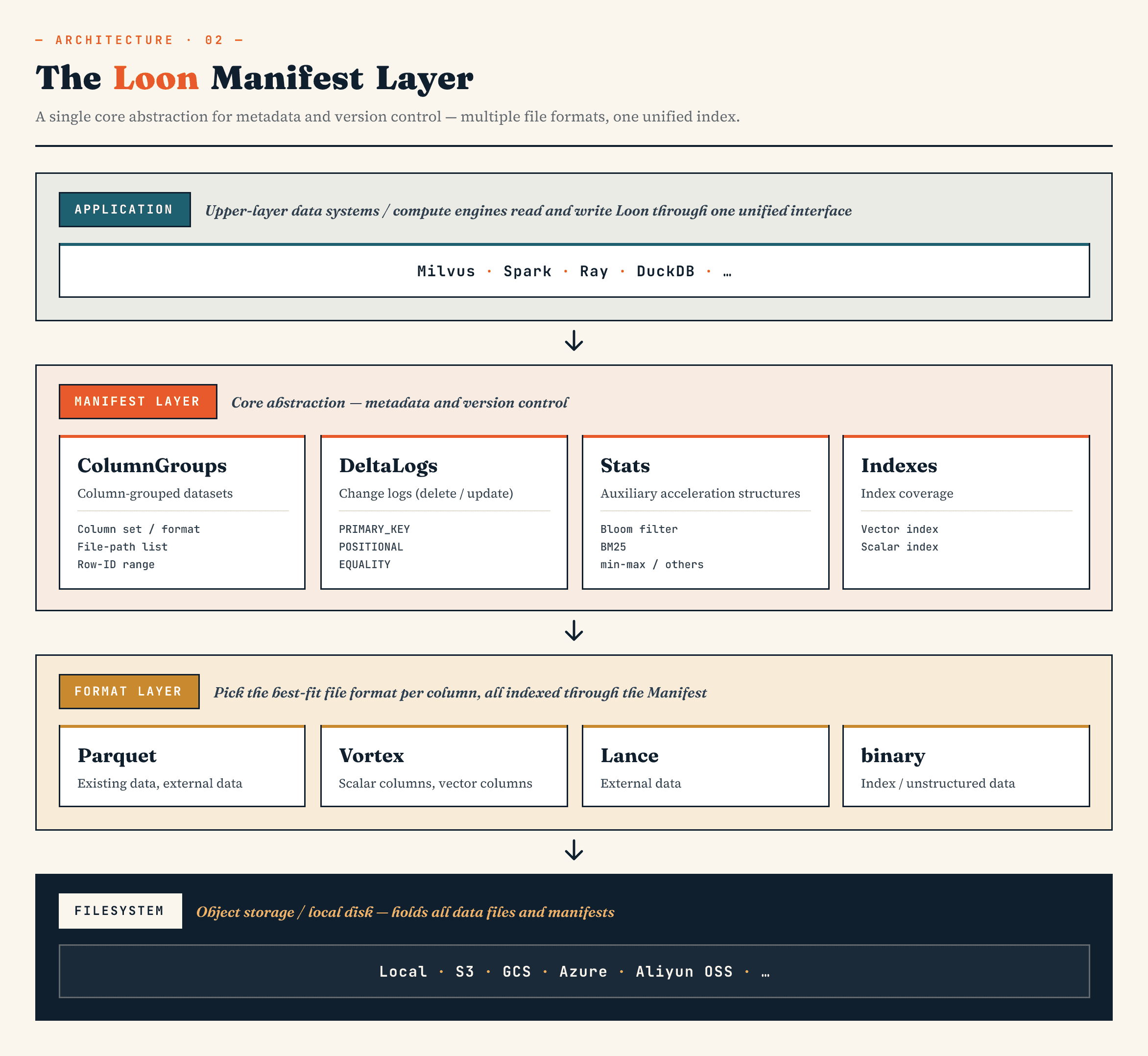
The Manifest describes the versioned state of the dataset. ColumnGroups map a logical collection into physical groups of columns. The file format layer lets each ColumnGroup choose an appropriate format. The filesystem abstraction works across object storage and local storage.
The important point is that hybrid file formats, row ID alignment, and Manifest are not separate features. Together, they define the storage model.
With that model in place, we can look at the three design choices one by one: how Loon stores different ColumnGroups, how it aligns them back into rows, and how the Manifest turns those files into a versioned dataset.
Design 1: use the right file format for the right column group
Different columns have different access patterns. They should not be forced into the same file format.
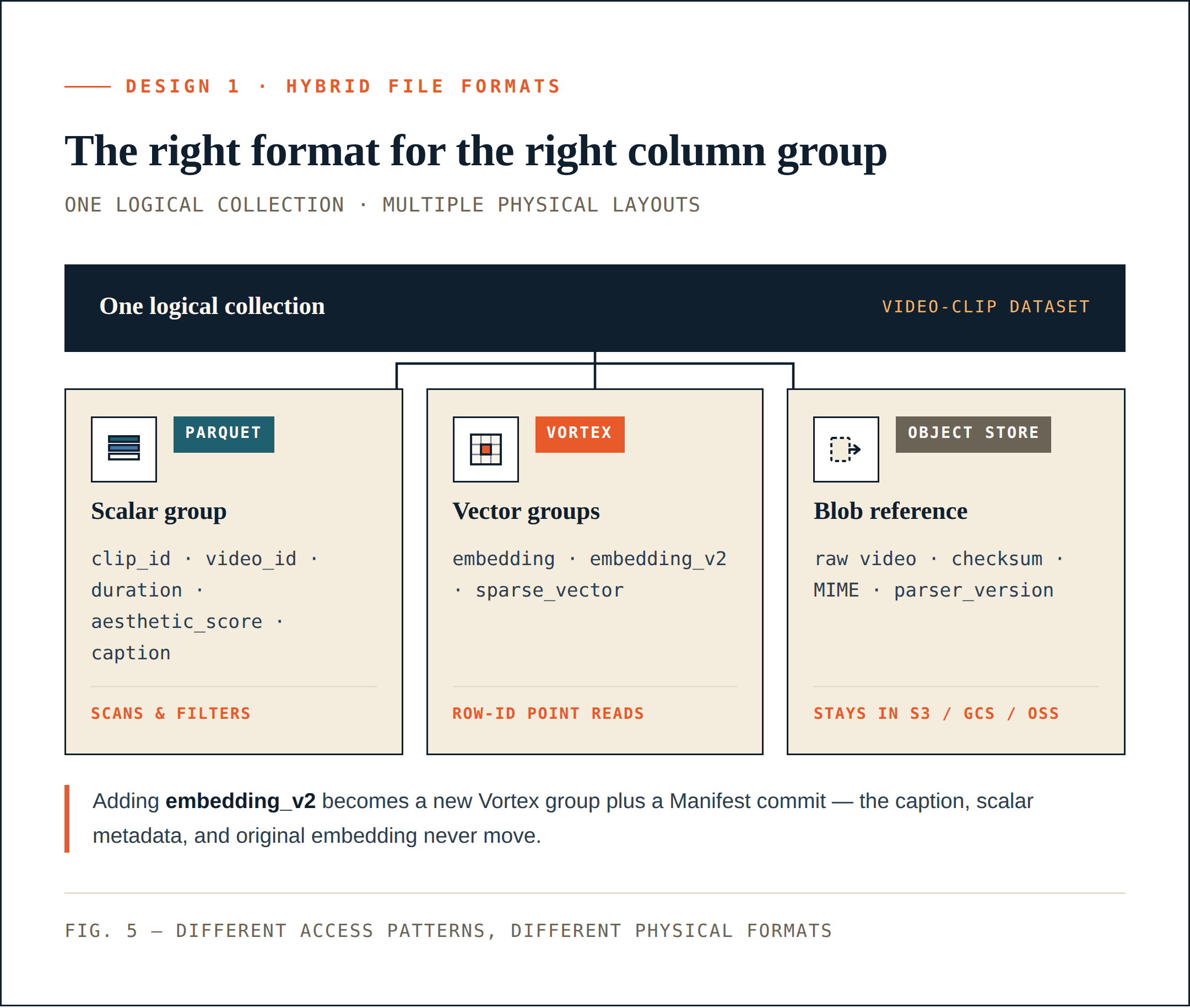
Loon separates a logical collection into ColumnGroups.
- Scalar fields, filter fields, business keys, and statistical fields are often scanned, filtered, aggregated, or used for query planning. They benefit from compression, column pruning, and ecosystem compatibility. Parquet is a good fit for these columns.
- Dense vectors, sparse vectors, and rerank features are often read after ANN recall by row ID. They need low-latency random access, precise byte-range reads, and selective decoding. A segment-oriented layout is a better fit. Loon uses Vortex in this direction.
- Raw objects such as videos, PDFs, images, and audio files should not be embedded into the vector database’s data files. They should remain in object storage. The database records references, checksums, MIME types, parser versions, and row-level relationships.
For the video example, a physical layout might look like this:
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
For the application, this is still one collection. To the storage layer, different parts of that collection use different physical formats. This directly reduces unnecessary rewrites. Adding embedding_v2 can become a new vector ColumnGroup plus a Manifest commit. It does not require rewriting the caption column, scalar metadata, or the existing embedding column.
The same idea applies to sparse vectors, rerank features, or other derived fields. If a new column can be physically independent and aligned by row ID, it does not have to drag unrelated columns through the same rewrite path.
Loon also adapts the use of file formats.
For Parquet, default settings are not always ideal for vector-heavy data. A 64 MB row group can be too large for point lookup because a small random read may pull far more data than needed. Loon tightens row groups to 1 MB in relevant paths and disables encodings, such as dictionary encoding on vector columns, when they do not help random-looking vector data.
For Vortex, the more important work is layout. Loon uses a layout that balances scan efficiency and point lookup. Within a row group, segments from related columns can be placed close together to support scanning. To perform operations, sub-segment reads allow the system to fetch only the relevant bytes rather than pulling an entire segment.
Loon also supports read-only Lance integration, so existing Lance datasets can be mounted as ColumnGroups when compatibility matters.
What the benchmark shows
In one local test, using a single file with 40,000 rows and the schema {id: int64, name: utf8, value: float64, vector: list<float32>[128]}, Vortex showed these results against Parquet with 1 MB row groups:
| Operation | Vortex | Parquet | Difference |
|---|---|---|---|
| Take, K=1000 random rows | 5.8 ms | 144 ms | 25x faster |
| Full vector-column scan | 21 ms | 142 ms | 6.76x faster |
| File size, ~21 MB raw data | 6.62 MB | 7.16 MB | 7% smaller |
The take result comes from reducing the amount of irrelevant data that must be read and decoded. The scan result comes from compression and implementation choices.
These numbers should stay attached to their setup: 8 vCPU Ubuntu 22.04 KVM, local filesystem, one file, 40,000 rows, 1 MB row groups, and the schema above. On object storage, network I/O can dominate, so reducing read amplification can matter even more. Actual results depend on dataset shape, object storage behavior, cache state, and query pattern.
The broader point is not that every column should use Vortex.
The point is that vector datasets need a file format choice at the ColumnGroup level.

Design 2: align physical files through row IDs
Hybrid file formats solve one problem: different columns can now live in the formats that fit them best.
But that creates a second problem. If scalar fields live in Parquet, vectors live in Vortex, and raw objects live in object storage, how does the system still treat them as one collection?
Loon solves this with row ID alignment.
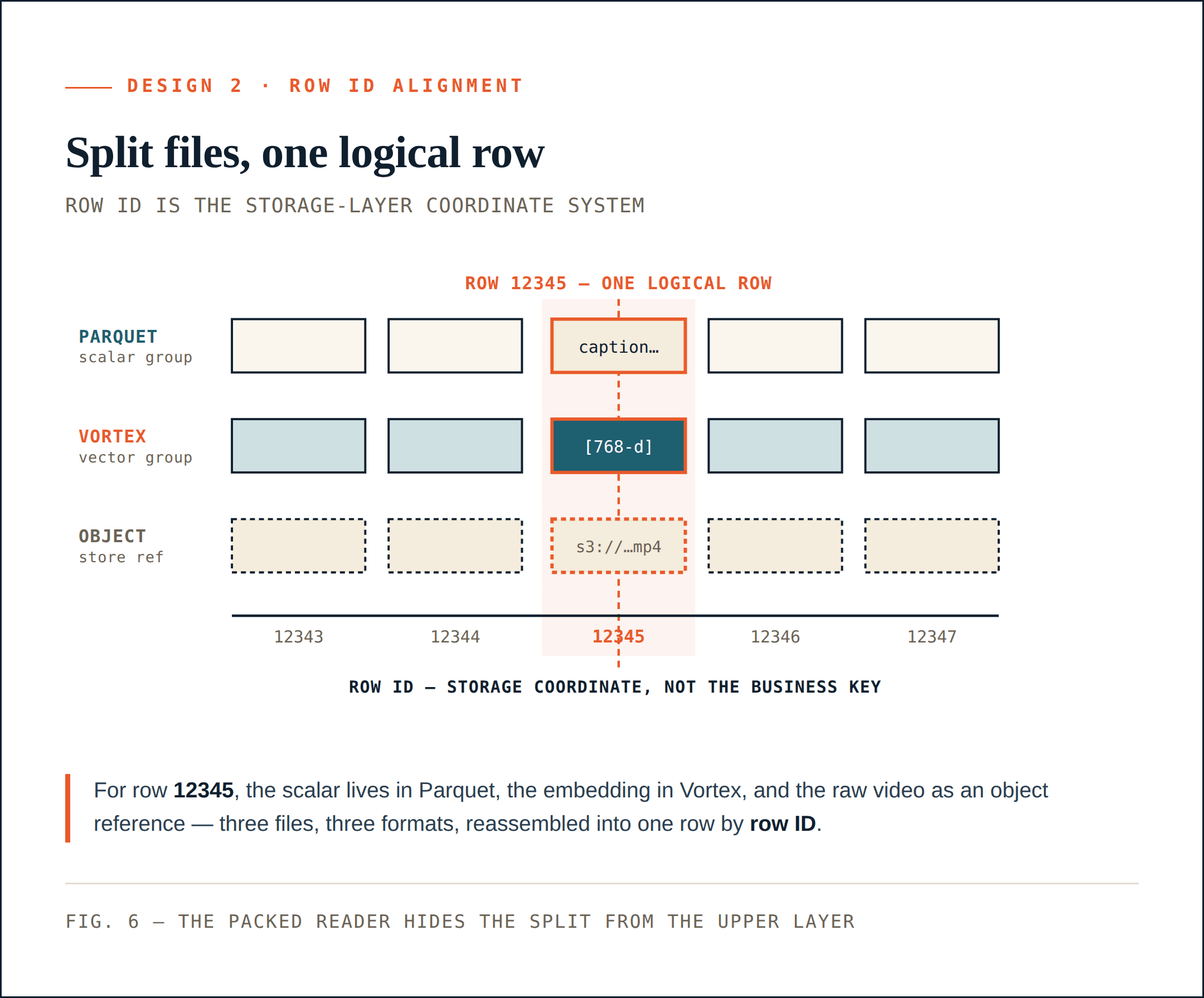
Row ID is the storage-layer coordinate system
Each physical ColumnGroupFile records the file path and the row ID range it covers:
path
start_index
end_index
Different ColumnGroups can cover the same row ID space even if they live in different files and formats.
For row ID 12345, the scalar metadata may be in a Parquet ColumnGroup, the embedding may be in a Vortex ColumnGroup, and the raw video may be represented by an object storage reference. Logically, they are still one row. This gives the storage layer a stable coordinate system.
Row ID is not the business primary key. It is the storage-layer coordinate system that lets Loon split a collection physically without losing the ability to reconstruct it logically.
New columns do not have to rewrite old columns
Adding embedding_v2 does not require rewriting the original caption, metadata, or embedding_v1 ColumnGroups. Loon can write a new vector ColumnGroup, record the row ID range it covers, and commit that change through the Manifest.
The same applies to sparse vectors, rerank features, or other derived fields that arrive later.
As long as the new ColumnGroup covers the right row ID range, it can join the same logical collection without forcing unrelated data to move.
Deletes and compaction can be more targeted
Row ID alignment also helps with deletes.
A delete can first be expressed through a delete log. The row becomes invisible at the logical level, while physical cleanup is delayed until compaction. When compaction eventually runs, it does not always need to rewrite every ColumnGroup tied to the affected rows. It can focus on the ColumnGroups that need cleanup.
This matters because not every column has the same cost profile. Rewriting a short scalar ColumnGroup is very different from rewriting hundreds of gigabytes of dense vectors.
Hybrid search can fetch only the columns it needs
Row ID alignment is also what makes hybrid search practical on top of hybrid file formats.
After ANN search returns candidate row IDs, the system can fetch only the fields needed for the final result: captions, metadata, vectors, rerank features, or object references.
For example, a query may need:
caption
embedding
video_uri
Those fields may live in different ColumnGroups. Loon can locate the relevant files by row ID range, read the necessary byte ranges, and assemble the result.
Without row ID alignment, hybrid formats would just be separate files sitting side by side. With row ID alignment, they behave as a single logical collection.
Packed Reader hides the split from the upper layer
The runtime component that makes this usable is the Packed Reader.
The upper layer sees a unified Arrow RecordBatch stream. Underneath, data may come from multiple ColumnGroups in different file formats. The Packed Reader hides those differences, aligns data by row-ID ranges, and schedules multi-file I/O with controlled memory usage.
It also supports direct take by row ID. Given a set of row IDs, it locates the relevant ColumnGroupFiles, issues range reads, and returns the requested fields.
For the video workflow, an ANN query may need caption, embedding, and video_uri. The Packed Reader can fetch the scalar ColumnGroup and the vector ColumnGroup without touching unrelated columns.
That is the difference between “separate files” and “a table with multiple physical layouts.”
Design 3: make the Manifest the source of truth
Hybrid file formats define how data is physically stored. Row ID alignment determines how separated ColumnGroups still form a single logical table. But the system still needs to answer a larger question: which files, logs, statistics, indexes, and object references belong to the current version of the dataset? That is the job of the Manifest.

Object storage directories are not enough
Object storage is not a database catalog. A directory may contain old files, new files, failed job outputs, temporary files, delete logs, files still referenced by older snapshots, and files waiting for cleanup. The fact that a file exists does not mean it belongs to the current dataset version.
A Loon dataset may be organized into directories such as:
_metadata/
_data/
_delta/
_stats/
_index/
But the directory structure is not the source of truth. The Manifest is. Readers should not list directories and infer state from whatever files happen to exist. They should read the current Manifest and follow the versioned view it declares.
The Manifest defines one versioned view of the dataset
The Manifest defines the dataset in a given version. It records:
- which ColumnGroups exist
- which row ID ranges they cover
- which physical format each ColumnGroup uses
- where the files live
- which delete logs are active
- which statistics are available
- which indexes exist
- which external blobs are referenced
- which columns and row ranges those stats or indexes cover
Each update writes a new Manifest version. A reader who opens version N sees a stable view of the dataset at version N. A writer can prepare version N+1 without disrupting readers who are still using version N.
The Manifest tracks more than table files
In Loon, the Manifest body is encoded with Apache Avro and organized around four major sections.
- ColumnGroups describe the columns, formats, files, and row ID ranges.
- DeltaLogs describe deletes. Different delete types cover different sources of change, such as primary-key deletes from clients, positional deletes from internal compaction, or equality deletes from external engines.
- Stats include planning metadata such as bloom filters, BM25 statistics, and min/max values.
- Indexes describe index type, parameters, covered columns, and row ID ranges. This can include vector indexes such as HNSW or IVF, text indexes, inverted indexes, bitmap indexes, and related structures.
This is where Loon differs from a traditional table manifest.
A vector dataset needs to track not only data files and partitions. It also needs to track vector indexes, text indexes, sparse features, delete logs, statistics, external object references, and the row ID ranges that connect them.
The Manifest must be writable by more than the database
The most important part is not only what the Manifest contains. It is who can write it.
- If only the database can write the Manifest, it remains internal metadata. Cleaner metadata, but still private to one engine.
- If external engines can generate new ColumnGroups, stats, and Manifest entries, the Manifest becomes a coordination interface.
- A Spark job, for example, can backfill a sparse vector column. It writes a new ColumnGroup, records row coverage and statistics, and commits a new Manifest. Online queries can keep reading the old version during the job. Once the commit succeeds, the new version becomes visible.
This is similar in spirit to Iceberg and Delta Lake, but the object model is broader. A vector dataset needs to track vector indexes, text indexes, sparse features, delete logs, stats, blob references, and row ID ranges, not just table files and partitions.
Optimistic commits keep version updates simple
Each commit writes a new Manifest version. A writer can build new content based on version N, then attempt to write manifest-{N+1}.avro. Object storage conditional write or generation-match semantics can make the commit fail if that version already exists. The writer can then retry against the newer version.
This gives Loon optimistic concurrency without forcing every update through a heavy, strongly consistent coordination path. Without a Manifest, multi-format and multi-engine storage eventually turns into naming conventions and manual reconciliation. That may work for small datasets. It does not work for TB-scale vector data.
The Manifest is what turns heterogeneous files into a dataset that multiple systems can safely read and update.
What changes for users when storage becomes versioned
For application developers, Loon should not become a new API burden.
Users should still work with familiar Milvus concepts: collections, inserts, search, and hybrid search. They should not need to think about Manifest files, ColumnGroups, row ID ranges, or file layout during normal application development.
The change is underneath. Storage becomes more aware of how AI datasets actually evolve.
Adding a new embedding should not move the old data
Previously, adding embedding_v2 to an existing collection often required exporting data, training a new model, generating vectors, and then reimporting or bulk-updating the collection via the SDK. That path creates a lot of operational work: version tracking, failed job retries, index rebuilds, serving impact, and consistency checks.
With Loon, this can become a schema evolution plus a new ColumnGroup commit. The new embedding column can be written as its own physical ColumnGroup, aligned by row ID, and made visible through the Manifest. The old caption column, scalar metadata column, and original embedding column do not need to be moved.
Backfills should not require a client-side update loop
Many AI data updates are backfills. A team may add sparse vectors after hybrid search becomes important. It may add rerank features after a new model is trained. It may correct captions after human review. It may add governance tags after a policy update.
In a traditional layout, these changes often occur via client SDK updates or database-only write paths, even when the data is produced by Spark, Ray, or another external engine.
With Loon, external compute systems can produce new ColumnGroups and commit them through the Manifest. The database no longer has to be the only entry point for every rewrite.
Offline analysis should not require another copy of the truth
Previously, teams often dumped an online collection into Parquet for offline evaluation or analysis. That creates two versions of the same dataset: the online collection and the analysis copy. Once captions are corrected, embeddings are regenerated, delete logs are applied, or indexes are rebuilt, the team has to ask which copy is current.
With a Manifest-based storage model, analysis engines can read the same versioned dataset view as the serving system. They can project only the columns they need, scan only the relevant row ranges, and work against a declared dataset version instead of a manually exported snapshot.
Deletes and corrections should touch only what changed
Deletes, caption corrections, label fixes, and governance updates are routine in AI datasets. They should not force every long vector column through the same rewrite path.
With Loon, deleting logs can first be treated as logical deletion. Later compaction can clean up the affected ColumnGroups without rewriting unrelated data. If a short text field changes, the storage layer should not have to rewrite hundreds of gigabytes of dense vectors just because they share the same logical row.
External engines become part of the workflow, not an escape hatch
The larger shift is that external engines are no longer treated as systems outside the vector database.
Spark, Ray, evaluation jobs, labeling systems, and governance pipelines already produce and modify much of the data. The storage layer should enable them to collaborate around a single source of truth rather than constantly exporting, copying, and reimporting.
That is what a version of Manifest makes possible. It gives online serving, offline analysis, backfill jobs, and compaction a shared view of the dataset.
These may sound like internal storage details, but they affect how quickly teams can iterate on AI datasets. Every model change, feature backfill, caption correction, quality filter, and index rebuild depends on the same question: "Can the system update the dataset without moving data it does not need to move? "
That is the practical value of the storage model.
Loon is available in Milvus 3.0 beta and Zilliz Vector Lakebase
Loon is available in Milvus 3.0 beta and is also part of the storage layer in Zilliz Vector Lakebase, the next evolution of Zilliz Cloud. And this release focuses on three core areas:
- The Manifest. The goal is for writes, backfills, deletes, statistics, and index updates to produce versioned dataset views that readers can open consistently. For readers, this means a query can open a specific Manifest version and see a stable view of the dataset. For writers, this means that new data files, delete logs, statistics, or index files can be prepared first and then made visible through a versioned commit.
- The ColumnGroup and format support. Parquet supports scalar and ecosystem-friendly columns. Vortex supports vector-heavy access patterns. Lance can be integrated in read-only mode for compatibility with existing Lance datasets.
- The Index on Lake. Scalar stats, filtering indexes, and text inverted indexes can participate in Manifest-based planning by row range. Lake-native vector indexes are more involved. HNSW and IVF have different behavior on object storage, and HNSW in particular is sensitive to random access and cache locality. It cannot simply reuse a layout designed for a local SSD and expect the same result.
There is still work ahead
- External write paths matter because Spark and Ray should be able to produce ColumnGroups and Manifest commits without forcing every backfill through a client SDK loop.
- Lakehouse interoperability matters because many teams already use catalogs and query engines such as Iceberg, Delta Lake, Trino, DuckDB, and Athena. Vector data should be able to participate in that ecosystem without losing vector search performance.
- Index layout matters because graph indexes and inverted structures have different access patterns on object storage.
- Large-object semantics matter because raw videos, PDFs, images, and audio files require reference management, versioning, and deletion behavior that align with the derived vector dataset.
The exact release behavior, default settings, and migration path should follow the relevant Milvus and Zilliz Cloud release notes. The storage direction, however, is clear: vector databases need a versioned, lake-native foundation underneath the serving layer.
Try Loon under Zilliz Vector Lakebase
If your current stack separates online serving, offline analysis, backfills, and external data lake workflows into different systems, Zilliz Vector Lakebase is worth a look. You can try it in Zilliz Cloud. New work email signups get $100 free credits. You are also welcome to talk to us about your use case.
You can also follow the Milvus 3.0 release to see how Loon evolves in the open-source engine.
Zilliz Vector Lakebase brings together:
- Tiered serving for different real-time performance and cost trade-offs
- On-demand search for large-scale or exploratory workloads without always-on compute
- External data lake search, so you can index and search directly over existing lake data
- Full-spectrum search across vectors, text, JSON, and geospatial data, with hybrid retrieval and reranking
- Unified lake-native storage built on Vortex, an open format designed for faster, lower-cost random reads over vector-heavy data
Keep Reading

Zilliz Cloud BYOC Now Available Across AWS, GCP, and Azure
Zilliz Cloud BYOC is now generally available on all three major clouds. Deploy fully managed vector search in your own AWS, GCP, or Azure account — your data never leaves your VPC.

Why Context Engineering Is Becoming the Full Stack of AI Agents
Discover how context engineering unifies prompts, RAG, and tools to build smarter, production-ready AI agents powered by Milvus.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.