




Top 10 Context Engineering Techniques You Should Know for Production RAG
When we first build a RAG or agent demo, things usually work well. With a small dataset, a few prompts, and simple retrieval, we can often get a prototype running in a few hours.
The real challenge appears when we try to run the system in production. As usage grows, problems show up quickly. Retrieval becomes slower, answers become less reliable, latency increases, and costs go up. What worked in a small demo often breaks when real data, real users, and longer contexts are involved.
At this point, we usually realize the issue is not just the model. It’s also about how context is prepared and passed to the model. This is where context engineering comes in. It focuses on retrieving, organizing, refining, and managing the information that a language model uses to generate answers.
In this article, we explain how context engineering works in practice. We look at recent approaches for building context, processing it efficiently, and managing it over time. These techniques help turn simple demos into systems that can run reliably in production.
Note: This article is mainly based on the paper https://arxiv.org/html/2507.13334v1.
What is Context Engineering?
Context engineering focuses on assembling the information a large language model needs to answer a question well. This information is not limited to the prompt. It also includes the user’s query, retrieved documents, conversation history, and other relevant data. The aim is to improve accuracy, reduce response time, and control costs.
This work is mostly done automatically through algorithms. Context engineering combines prompt engineering, retrieval-augmented generation (RAG), and multi-agent techniques into one system, instead of using them separately.
In practice, a context engineering setup has two parts. The first consists of foundational components that handle data retrieval, processing, and orchestration. The second layer is made up of more complex systems that combine these components into complete applications. Teams can mix and reuse these parts to fit different production scenarios.
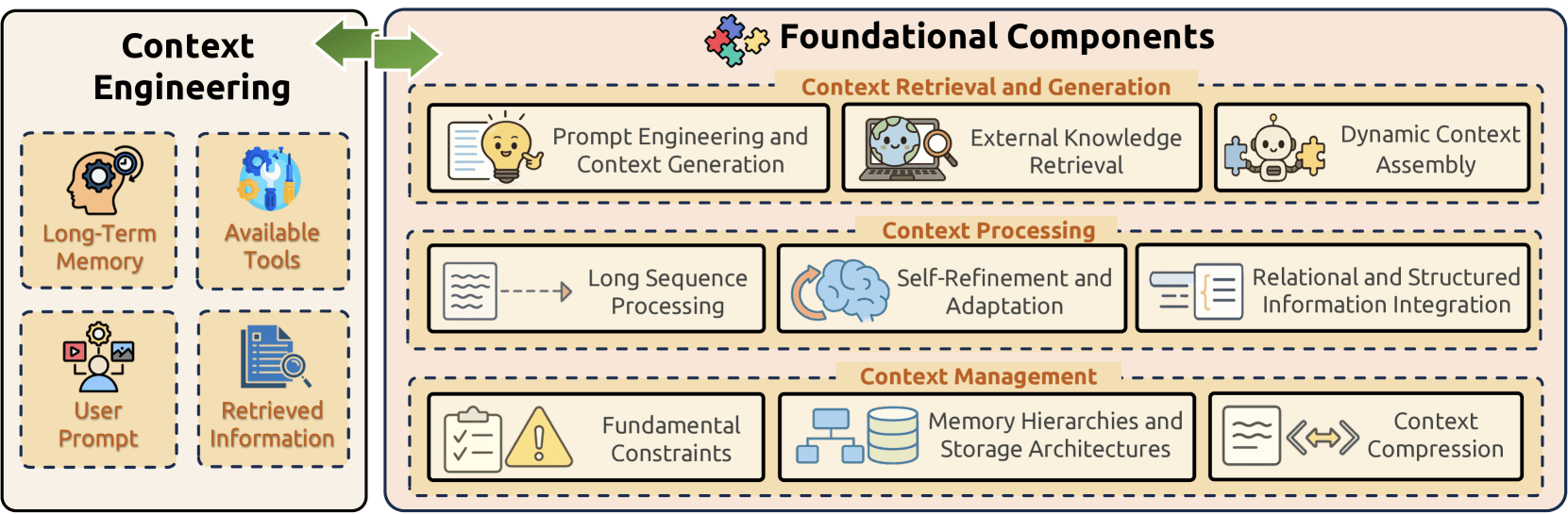
Foundational Components
Context Engineering is built upon three fundamental components that collectively address the core challenges of information management in large language models:
- Context Retrieval and Generation sources appropriate contextual information through prompt engineering, external knowledge retrieval, and dynamic context assembly;
- Context Processing transforms and optimizes acquired information through long sequence processing, self-refinement mechanisms, and structured data integration;
- Context Management tackles efficient organization and utilization of contextual information through addressing fundamental constraints, implementing sophisticated memory hierarchies, and developing compression techniques.
Complex Systems in Practice
On top of these foundational components, context engineering is applied through several common types of complex systems.
Retrieval-augmented generation (RAG) lets a model look up information in a knowledge base before answering a question. This helps ensure the answer is based on real, current data instead of the model guessing. In practice, RAG can be built as simple modular pipelines, driven by agents that control retrieval, or combined with knowledge graphs for richer context.
Memory systems allow models to keep track of information across interactions. Short-term memory holds details from the current conversation, while long-term memory stores past conversations and learned knowledge. This makes multi-turn conversations more consistent and helps the system improve over time.
Tool-integrated reasoning allows models to use external tools such as calculators, search engines, or APIs instead of relying only on text reasoning. An important part of this setup is inserting tool results back into the context at the right moment so the model can use them effectively.
Multi-agent systems use multiple models that work together to handle complex tasks. Each agent has a specific role, and the system coordinates how they communicate, share information, and stay in sync to produce a consistent result.
Context Processing
Earlier, we introduced the three main parts of context engineering: context retrieval and generation, context processing, and context management. These form the basic building blocks of a practical context system.
Context processing is especially important. It takes raw retrieved information and cleans it up, reshapes it, and organizes it so the model can understand and use it more efficiently.
In this section, we look at how context processing is done in real systems and which approaches are commonly used.
Long Context Processing
Processing very long contexts is expensive because transformer models use self-attention, which scales poorly as input length grows. As the sequence gets longer, computation and memory usage increase quickly, creating real bottlenecks in production systems.
For example, expanding Mistral-7B’s input length from 4K to 128K tokens increases compute cost by about 122×. Memory usage also rises sharply during both prefilling and decoding. In practice, models like Llama 3.1 8B can require up to 16 GB of memory for a single 128K-token request.
To get around these limits, researchers mainly use three approaches.
One is to build new model architectures, such as Mamba, that are cheaper to run by design. Another is to use techniques like positional interpolation to let existing models handle much longer inputs. The third approach improves how computation is done, by avoiding redundant work and using memory more efficiently, so long-context processing is faster and uses fewer resources.
(1) Architectural Innovations for Long Context
To deal with the quadratic cost of Transformers, researchers have developed new model architectures that make long-sequence processing cheaper and more efficient.
- State Space Models (SSMs) maintain linear computational complexity and constant memory requirements through fixed-size hidden states, with models like Mamba offering efficient recurrent computation mechanisms that scale more effectively than traditional transformers.
- Dilated attention approaches like LongNet employ exponentially expanding attentive fields as token distance grows, achieving linear computational complexity while maintaining logarithmic dependency between tokens, making it possible to process sequences longer than one billion tokens.
- Toeplitz Neural Networks (TNNs) model sequences with relative position encoded Toeplitz matrices, reducing space-time complexity to log-linear and enabling extrapolation from 512 training tokens to 14,000 inference tokens.
- Linear attention mechanisms reduce complexity from O(N²) to O(N) by expressing self-attention as linear dot-products of kernel feature maps, achieving up to 4000× speedup when processing very long sequences.
Alternative approaches like non-attention LLMs break quadratic barriers by employing recursive memory transformers and other architectural innovations.
(2) Position Interpolation and Context Extension
Position interpolation techniques enable models to process sequences beyond original context window limitations by intelligently rescaling position indices rather than extrapolating to unseen positions.
- Neural Tangent Kernel (NTK) approaches provide mathematically grounded frameworks for context extension, with YaRN (Yet another RoPE-based Interpolation method) combining NTK interpolation with linear interpolation and attention distribution correction.
- Two-stage approaches: LongRoPE achieves 2048K token context windows through two-stage approaches: first fine-tuning models to 256K length, then conducting positional interpolation to reach maximum context length.
- Position Sequence Tuning (PoSE) demonstrates impressive sequence length extensions up to 128K tokens by combining multiple positional interpolation strategies.
- Self-Extend techniques enable LLMs to process long contexts without fine-tuning by employing bi-level attention strategies—grouped attention and neighbor attention—to capture dependencies among distant and adjacent tokens.
(3) Optimization Techniques for Efficient Processing
Without changing the core model architecture, researchers have also developed a range of optimization techniques to make long-context processing more efficient.
Grouped-Query Attention (GQA) partitions query heads into groups that share key and value heads, striking a balance between multi-query attention and multi-head attention while reducing memory requirements during decoding.
FlashAttention exploits asymmetric GPU memory hierarchy to achieve linear memory scaling instead of quadratic requirements, with FlashAttention-2 providing approximately twice the speed through reduced non-matrix multiplication operations and optimized work distribution.
Ring Attention with Blockwise Transformers enables handling extremely long sequences by distributing computation across multiple devices, leveraging blockwise computation while overlapping communication with attention computation.
Sparse attention techniques include Shifted sparse attention (S²-Attn) in LongLoRA and SinkLoRA with SF-Attn, which achieve 92% of full attention perplexity improvement with significant computation savings.
Memory management and context compression reduce the cost of long inputs. Rolling Buffer Cache limits the attention window to shrink KV cache memory, while StreamingLLM supports long sequences by keeping only key tokens and recent context. Other methods like Infini-attention and H2O improve efficiency through compressive memory and smarter cache eviction.
Contextual Self-Refinement and Adaptation
Self-refinement enables LLMs to improve outputs through cyclical feedback mechanisms mirroring human revision processes, leveraging self-evaluation through conversational self-interaction via prompt engineering distinct from reinforcement learning approaches.
The idea is simple: for complex tasks, it’s easier to write a first version and then fix it than to get everything right at once. When models learn to check their own work and improve it step by step, they perform better at reasoning, writing code, and creative tasks, and adapt more easily to new situations.
(1) Foundational Self-Refinement Frameworks
- The Self-Refine framework uses the same model as generator, feedback provider, and refiner, demonstrating that identifying and fixing errors is often easier than producing perfect initial solutions.
- Reflexion maintains reflective text in episodic memory buffers for future decision-making through linguistic feedback, while structured guidance proves essential as simplistic prompting often fails to enable reliable self-correction.
- The N-CRITICS framework implements ensemble-based evaluation where initial outputs are assessed by both generating LLMs and other models, with compiled feedback guiding refinement until task-specific stopping criteria are fulfilled.
(2) Meta-Learning and Autonomous Evolution
At a more advanced stage, context self-refinement focuses on meta-learning and autonomous improvement. The goal is to help the model not only solve tasks, but also learn how to learn better over time.
SELF teaches LLMs meta-skills (self-feedback, self-refinement) with limited examples, then has the model continuously self-evolve by generating and filtering its own training data. Self-rewarding mechanisms enable models to improve autonomously through iterative self-judgment, where a single model adopts dual roles as performer and judge, maximizing rewards it assigns itself.
The Creator framework extends this paradigm by enabling LLMs to create and use their own tools through a four-module process encompassing creation, decision-making, execution, and recognition.
The Self-Developing framework represents the most autonomous approach, enabling LLMs to discover, implement, and refine their own improvement algorithms through iterative cycles generating algorithmic candidates as executable code.
Multimodal Context
Multimodal large language models (MLLMs) go beyond text by working with inputs like images, audio, and 3D data. They combine these different types of information into a single context the model can reason over.
This makes more advanced applications possible, but also brings new challenges, such as integrating different modalities, reasoning across them, and handling long, complex inputs.
(1) Multimodal Context Integration
Context integration is the core of multimodal context processing. It aims to combine information from different modalities, such as images, text, and audio, into a single representation that a model can reason with.
A basic approach turns images into tokens using encoders like CLIP and then appends them to text tokens before sending everything to the language model. This is easy to implement, but the different modalities often remain loosely connected.
More advanced methods improve integration. Cross-modal attention lets the model learn direct relationships between visual and text tokens inside the model, which is important for tasks like image editing and visual reasoning.
To scale to long or complex inputs, hierarchical designs process each modality in stages. Some systems also merge information from multiple images or inputs before passing them to the model, instead of handling each one separately.
Other work avoids adapting text-only models altogether by training on multimodal data and text together from the start. Cross-modal reasoning builds on this, requiring the model to understand not just each modality on its own, but also the meaning that emerges when they are combined, such as sarcasm expressed through both an image and text.
(2) External Multimodal Encoders and Alignment Modules
Multimodal context integration is built on two main parts: external multimodal encoders and the alignment modules that connect them to the language model.
In most current systems, each type of data is handled by a dedicated encoder. For example, images are processed by models like CLIP, and audio is handled by models such as CLAP. These encoders turn raw inputs, like pixels or sound waves, into feature vectors.
Alignment modules then convert these features into the language model’s embedding space so they can work together with text tokens. Some systems use simple mappings like MLPs, while others use Q-Former, which selects the visual features most relevant to the text using learnable query tokens.
This modular setup makes systems easier to maintain. Encoders can be updated or swapped out without retraining the entire language model, which is important for real-world deployment.
Relational and Structured Context
Large language models face fundamental constraints processing relational and structured data including tables, databases, and knowledge graphs due to text-based input requirements and sequential architecture limitations.
Linearization often fails to preserve complex relationships and structural properties, with performance degrading when information is dispersed throughout contexts.
To solve this problem, researchers have looked for ways to represent structured data in a form that language models can use. The goal is to help models perform better on tasks that involve complex reasoning and fact checking.
(1) Knowledge Graph Embeddings and Neural Integration
Advanced encoding strategies address structural limitations through knowledge graph embeddings that transform entities and relationships into numerical vectors, enabling efficient processing within language model architectures.
Graph neural networks capture complex relationships between entities, facilitating multi-hop reasoning across knowledge graph structures through specialized architectures like GraphFormers that nest GNN components alongside transformer blocks.
(2) Verbalization
One common approach is to turn structured data—such as knowledge graphs, tables, or database records—into natural language text, so it can be used directly by existing language models without changing their architecture. Other methods reorganize input text into structured layers based on linguistic relationships, or extract key information and represent it explicitly as graphs, tables, or relational schemas.
In some cases, representing structured data using programming languages works better than natural language. For example, using Python code for knowledge graphs or SQL for databases often leads to stronger performance on complex reasoning tasks, because these formats preserve structure more clearly. There are also resource-efficient approaches that use compact matrix representations to handle structured data with fewer parameters while maintaining good performance.
(3) Hybrid Architectures
To handle structured data with complex relationships, such as tables and knowledge graphs, researchers have explored hybrid architectures that combine large language models with components designed for graph-structured data, such as graph neural networks.
Several practical approaches are used. GraphToken makes relationships explicit by adding special tokens, which helps models reason over graphs. Heterformer processes text and graph structure together in one framework, keeping relationship information while controlling compute cost.
Other methods integrate knowledge in different ways. K-BERT adds knowledge graph information during training so the model learns these relationships in advance. KAPING retrieves relevant knowledge at inference time, without retraining. More advanced designs use adapters and attention to blend graph information directly into the model, leading to tighter integration.
Conclusion
Context engineering offers a useful way to understand how LLM systems work in production. In general, it involves three main processes: context retrieval and generation, context processing, and context management. Together, these steps determine how information is collected, prepared, and passed to the model.
Among them, context processing is especially important because it decides how retrieved information is cleaned, organized, and compressed before reaching the model. Because of space limits, this article mainly focused on this part and reviewed several approaches used in real systems. Retrieval and context management are also important areas and can be explored further in future discussions.
If you’re building RAG or agent systems and running into production issues with context, cost, or latency, join our Slack Channel to discuss context engineering with other engineers. You can also book a short one-on-one session to get practical guidance on moving from demos to production-ready systems through Milvus Office Hours.
Keep Reading

Migrating Self-Managed Milvus to Zilliz Cloud for >99% Latency Reduction
Step-by-step guide to migrating 50M vectors from self-managed Milvus to Zilliz Cloud using milvus-backup. Achieve >99% query latency reduction with zero data loss.

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.