




The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Cloud regions fail. It's not a question of if — it's a question of when and how bad.
Last week, two AWS regions in the Middle East went offline due to physical damage to the data center infrastructure. Two of three availability zones in AWS's UAE region (ME-CENTRAL-1) were knocked out, and a facility in Bahrain (ME-SOUTH-1) was damaged. Over 60 AWS services were impacted, including Lambda, EKS, VPC, S3, and CloudWatch. Careem, the region's largest ride-hailing platform, lost service. Alaan, a leading payments provider, went dark. AWS advised customers to shift workloads to other regions—but this wasn't a reboot-and-recover incident. With hardware replacement and facility repair, recovery can take weeks.
And physical damage is only one failure mode. Over the past 12 months, a faulty configuration change took down Azure's Central US region for 14.5 hours. A bug in Google Cloud knocked out Cloud Run, GKE, and Firebase simultaneously for 8 hours. A flawed CrowdStrike software update — not even a cloud provider issue — cascaded through Azure-hosted infrastructure, costing Fortune 500 companies an estimated $5.4 billion.
The Uptime Institute's 2025 report puts the median cost of a high-impact outage at $2 million per hour, roughly double the figure three years ago. Yet Veeam's 2024 Data Protection Trends Report found that only 13% of organizations can actually orchestrate recovery during a real disaster.
These numbers were already alarming. Then AI raised the stakes.
When AI Goes Down, Teams Don't Slow Down — They Stop
Five years ago, a regional cloud failure mainly hurt customer-facing apps. Painful, but most teams could still function internally. Today, AI has absorbed work that spans entire departments—code review, documentation, support triage, and even routine analysis. With nearly 60% of employees using AI in daily workflows, outages don't cause a gradual slowdown. Productivity drops off a cliff.
We've seen this play out already — ChatGPT and Claude both suffered significant outages in early 2026, leaving millions of users and enterprise teams without the AI tools they'd built their workflows around.
But here's what most teams overlook. Model outages are disruptive, yet models are largely stateless: providers can often reroute inference traffic to healthy regions relatively quickly. The harder problem is the data layer underneath—the databases, object stores, and vector indexes that supply memory and context. That layer is stateful, region-bound, and far more difficult to recover. When it goes down, your LLM may still generate text—but without the right context, it defaults to generic, hallucination-prone output. AI doesn't just go offline. It becomes unreliable.
The Vector Database is Your AI's LongTerm Memory — and it's Probably Single-Region
Vector databases have become the backbone of enterprise AI. RAG pipelines and AI agents retrieve context from them. Recommendation engines query them. Semantic search runs against them. When this layer is unavailable, every application built on top of it breaks — not partially, but completely.
And unlike stateless services, recovery isn't simple:
- Index rebuilds are slow. Vector search depends on index structures like HNSW graphs, where rebuild time scales non-linearly with dataset size. Rebuilding an index over 100M+ vectors can take 18+ hours on standard compute.
- Connection strings are everywhere. Every application that connected to the old cluster needs its endpoint updated — across configs, environment variables, CI/CD pipelines, often managed by different teams.
- Embedding model drift. If you can't locate the exact embedding model version that generated your current vectors, you may need to re-embed your entire dataset.
For a software outage, you wait for a restart. But when a data center is physically damaged, recovery takes weeks. The only viable strategy is to already have a live, indexed, query-ready replica serving from another region — with traffic rerouting that requires zero code changes.
Zilliz Cloud: The World's First Vector Database with Native Cross-Region Disaster Recovery
Zilliz Cloud is the world's first vector database to offer native cross-region disaster recovery — with automated failover, real-time replication, and a global endpoint that requires zero application changes during region transitions.
We provide two complementary capabilities: Global Cluster for real-time failover, and Cross-Region Backup for cost-effective disaster recovery.
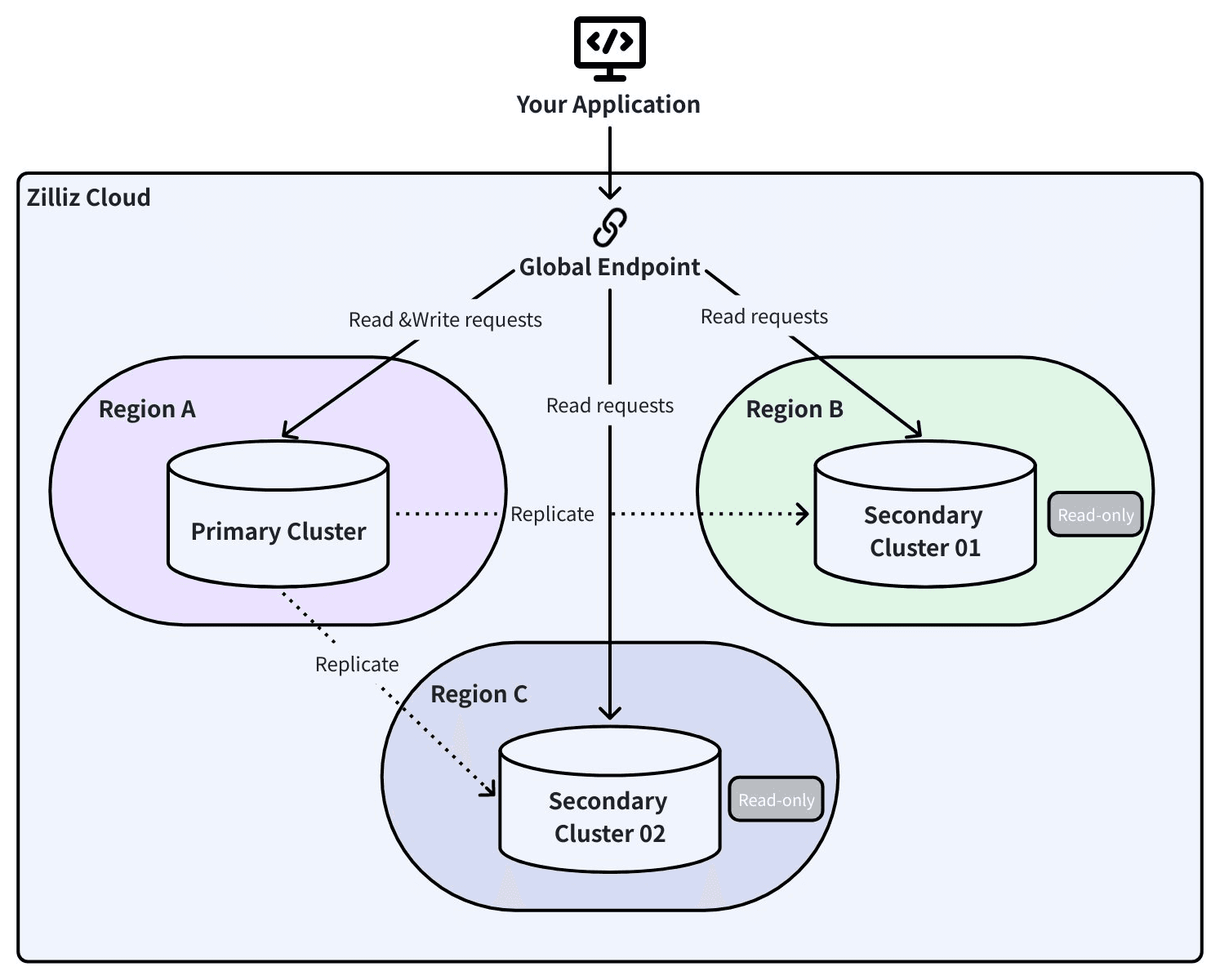
Global Cluster: Live Replication with Automatic Failover
Global Cluster uses Change Data Capture (CDC) to replicate data continuously between a primary cluster and a secondary in a different region. Not periodic snapshots — every insert, update, and delete propagates in real time.
- Planned switchover (maintenance, migration, compliance): The system drains in-flight CDC messages, confirms full synchronization, then swaps roles. RPO is zero. RTO is under 30 seconds.
- Automatic failover (unexpected region failure): The secondary automatically promotes itself. RPO equals the CDC lag at the moment of failure — typically a few seconds. RTO is under 60 seconds.
One unique capability: after a failover, the old primary doesn't just disappear. It goes to a recycle bin with 7-day retention, and a streaming API called DumpMessages lets you pull any writes that landed on the old primary but hadn't replicated yet. Instead of accepting data loss, you get a window to recover it.
Global Endpoint: One Connection, Every Region
This is where architecture pays off in a physical disaster scenario.
Your application connects to a single global endpoint. Behind it, SRV DNS records track which cluster is primary and which is secondary. When a failover happens, the SDK detects the topology change and reroutes traffic automatically. No connection string updates. No application restarts. No code changes.
Think about what this means during a prolonged regional outage. Without a global endpoint, recovery requires someone to find a runbook, manually reconfigure clients, update connection strings, and coordinate across teams — at 3 AM, under pressure. Your RTO isn't measured in seconds; it's measured in however long it takes to page the right engineer.
With Global Endpoint, your RAG pipeline queries the replica in another region within 60 seconds, without changing a single line of code.
Cross-Region Backup: Resilience Without the Cost of a Live Replica
Not every workload justifies running a secondary cluster. Cross-Region Backup replicates backup data to one or more target regions, each with its own retention policy. When a region-level failure hits, you spin up a new cluster from any backup point in the target region — no cross-region data transfer needed during the crisis, because the data is already there.
The trade-off:
- Global Cluster → RPO in seconds, RTO under 60 seconds. For workloads that can't tolerate any downtime.
- Cross-Region Backup → RPO and RTO in hours. For workloads where data survival matters more than instant recovery.
Many teams start with Cross-Region Backup for the critical guarantee — your data survives a region failure — and upgrade to Global Cluster as their AI workloads become mission-critical.
How Other Vector Databases Handle Cross-Region DR
Most vector databases offer high availability within a single region through replica sets and node redundancy. That handles node failures — not region failures. Zilliz Cloud is the only vector database offering native automated cross-region failover with a global cluster and global endpoint — zero-downtime, zero-code-change region transitions.
| Capability | Zilliz Cloud | Pinecone | Weaviate | Qdrant | turbopuffer |
|---|---|---|---|---|---|
| Cross-region replication | ✅ CDC-based, real-time | ❌ | ❌ | ❌ | ❌ |
| Unplanned failover | ✅ RPO ≈ seconds, RTO<= 30s | ❌ | ❌ | ❌ | ❌ |
| Planned switchover | ✅ RPO=0, RTO=0 | ❌ | ❌ | ❌ | ❌ |
| Data salvage post-failover | ✅ Automatic salvage data that unsynced. | ❌ | ❌ | ❌ | ❌ |
| Global Endpoint | ✅ One Global endpoint, auto-rerouting with zero code changes | ❌ | ❌ | ❌ | ❌ |
| Regional failure RPO/RTO | ✅ RPO ≈ seconds, RTO < 30s | ❌ | ❌ | ❌ | ❌ |
| Automatic Cross-region backup | ✅ ANY region with per-region retention | ❌ | ❌ | ❌ | ❌ |
Beyond Disaster Recovery
Teams also use Global Cluster for operational scenarios that have nothing to do with outages:
- Latency optimization: Add a secondary region closer to your users for sub-100ms query response times.
- Region migration: Move workloads between regions with zero downtime during infrastructure consolidation.
- Data residency compliance: Keep data within specific geographic borders to meet regulatory requirements.
The same CDC pipeline that protects against outages also gives you a read-capable replica closer to your users — DR capability as a side effect of performance optimization.
Getting Started
Global Cluster and Cross-Region Backup are available on Zilliz Cloud for dedicated clusters.
- If you’ve already had a Zilliz Cloud account, simply sign in and start using the new features right away—no upgrades or migrations required.
- New to Zilliz Cloud? Sign up for free and get \$100 in credits to experience the world’s leading managed vector database.
- Have questions about any of the updates? Check out the latest documentation or reach out to Zilliz Support—we’re here to help.
Build Without Limits: A Closer Look at Zilliz Cloud's Enterprise-Ready Capabilities
Global Cluster is one piece of a broader platform built for production-scale AI. Zilliz Cloud also delivers:
- Elastic scaling & cost efficiency – One-click deployment, serverless autoscaling, and pay-as-you-go pricing.
- Advanced AI search – Vector, full-text, and hybrid (sparse + dense) search with metadata filtering, dynamic schema, and multi-tenancy.
- Enterprise-grade security – 99.95% SLA, SOC 2 Type II and ISO 27001 certifications, GDPR compliance, HIPAA readiness, RBAC, BYOC, and audit logs. See our trust center for more.
- Global availability – Deployments across AWS, GCP, and Azure with sub-100ms latency worldwide.
- Seamless migration – Built-in tools to move from Pinecone, Qdrant, Elasticsearch, PostgreSQL, OpenSearch, Weaviate, or on-prem Milvus.
- Natural language querying – MCP server support for intuitive queries without complex APIs.
- And more!

Keep Reading

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.