




Агентный RAG: более умный поиск ИИ с автономными агентами
Агентный RAG: более умный поиск ИИ с автономными агентами
Представьте себе ассистента-исследователя, который, когда вы задаете вопрос, не просто ищет в одной базе данных, а интеллектуально решает, к каким источникам обратиться, проверяет найденную информацию и даже при необходимости переформулирует ваш вопрос, чтобы добиться лучших результатов. Именно это агентный RAG привносит в системы искусственного интеллекта.
Хотя традиционные системы Retrieval-Augmented Generation (RAG) значительно улучшили то, как ИИ-приложения получают доступ к внешним знаниям, они работают как одноколейное мышление, ограниченное одним источником знаний и одной попыткой поиска. Агентный RAG превращает этот линейный подход в интеллектуальную, адаптивную систему, которая может думать, планировать и действовать в нескольких источниках информации, чтобы предоставлять более точные и исчерпывающие ответы.
Что такое агентный RAG?
Агентный RAG — это улучшенная реализация Retrieval-Augmented Generation, которая включает ИИ-агентов для оркестрации сложных рабочих процессов поиска и генерации информации. В отличие от традиционных RAG-систем, которые следуют фиксированной последовательности поиска и генерации, агентный RAG использует интеллектуальных агентов, способных рассуждать, планировать и принимать решения о том, как лучше всего отвечать на пользовательские запросы.
В своей основе агентный RAG использует ИИ-агентов для поддержки retrieval-augmented generation, повышая адаптивность и точность RAG-конвейера и позволяя большим языковым моделям выполнять поиск информации из нескольких источников и обрабатывать более сложные рабочие процессы.
Эти системы превращают LLM в ИИ-агентов, наделяя их возможностью использовать инструменты, функции и внешние источники знаний, тем самым создавая более сложный подход к обработке информации, чем стандартные реализации RAG.
Ключевые особенности агентного RAG
Многоисточниковый интеллект: Система может подключаться к нескольким базам данных, включая векторные базы данных, такие как Milvus и Zilliz Cloud, а также традиционные SQL-базы данных. Агенты могут одновременно получать доступ к внутренним документам, внешним API, веб-поиску и специализированным базам данных в зависимости от требований запроса.
Адаптивная обработка запросов: ИИ-агенты могут итеративно улучшать предыдущие процессы, чтобы со временем оптимизировать результаты. Когда первоначальные результаты недостаточны, агенты могут переформулировать запросы, пробовать разные источники или разбивать сложные вопросы на управляемые подзапросы.
Интеллектуальное планирование и оркестрация: Агенты в этом подходе могут планировать и рассуждать над задачами, которые требуют нескольких шагов и логического мышления. Координирующий агент может назначать специализированные задачи разным агентам поиска, каждый из которых оптимизирован для конкретных типов данных или доменов.
Проверка качества: В отличие от традиционных систем, агентный RAG включает встроенные механизмы оценки извлеченного контента. ИИ-агенты могут итеративно улучшать предыдущие процессы, чтобы со временем оптимизировать результаты. Этот уровень проверки значительно снижает галлюцинации и повышает точность ответов.
Интеграция инструментов: Агенты поиска с доступом к различным инструментам поиска, таким как: векторная поисковая система (также называемая query engine), которая выполняет векторный поиск по векторному индексу (как в типичных RAG-конвейерах), веб-поиск, калькулятор, любой API для программного доступа к программному обеспечению, например к email или chat-программам, обеспечивают комплексный сбор информации за пределами простого извлечения документов.
Как работает агентный RAG
Агентный RAG работает через сложную архитектуру, которая объединяет нескольких ИИ-агентов с продвинутыми возможностями рассуждения. Вот как система обрабатывает запросы от начала до конца:
Пошаговый рабочий процесс
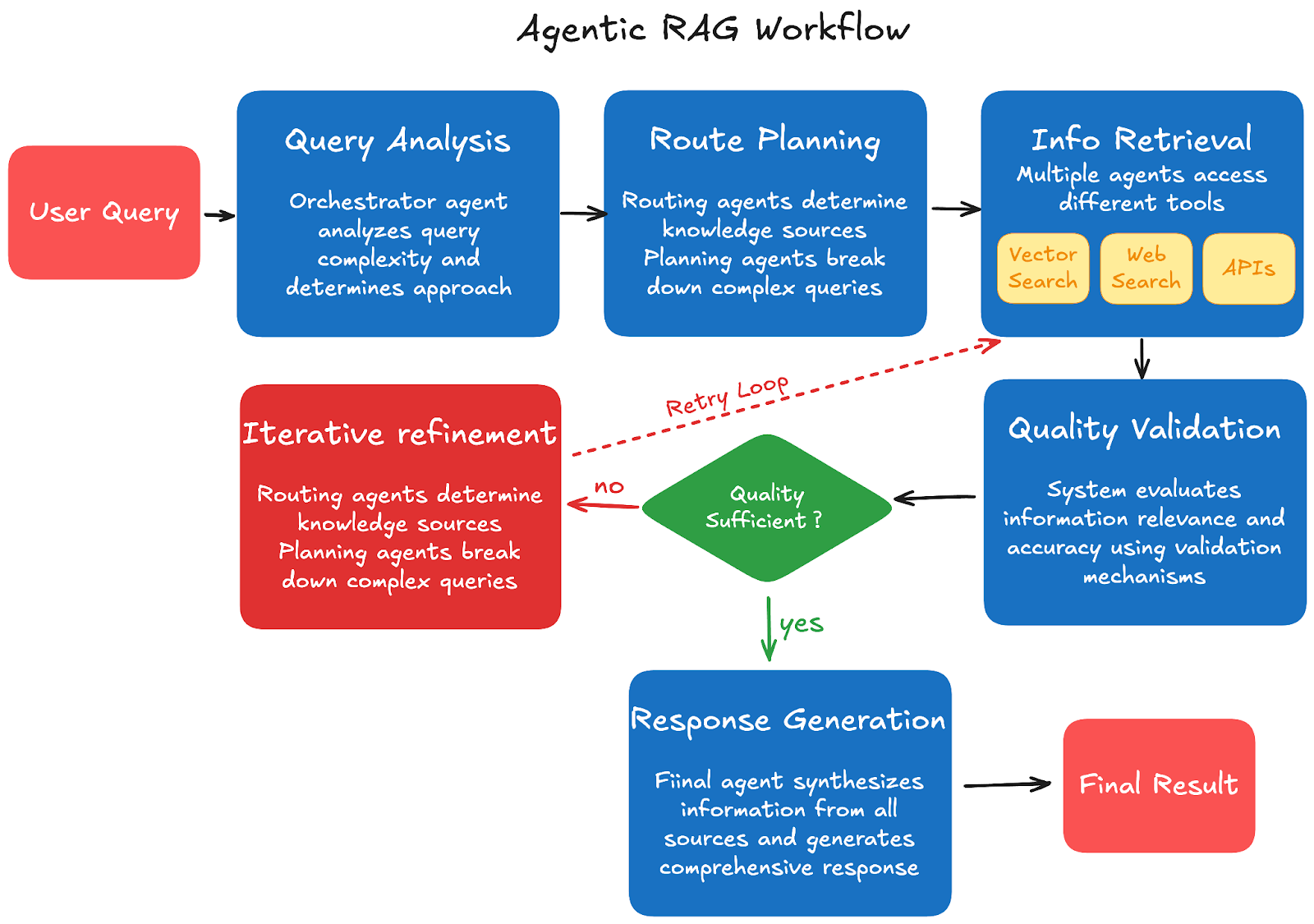
Шаг 1: Анализ запроса: Пользователь отправляет запрос основному агенту-оркестратору, который анализирует сложность запроса и определяет необходимый подход. Система решает, нужны ли один или несколько шагов поиска, исходя из охвата и сложности запроса.
Шаг 2: Планирование маршрута: Маршрутизирующие агенты определяют, какие внешние источники знаний и инструменты использовать, в то время как агенты планирования запросов разбивают сложные запросы на управляемые подзадачи. Система создает план выполнения на основе доступных ресурсов и наиболее эффективного пути для сбора исчерпывающей информации.
Шаг 3: Извлечение информации: Агенты извлечения обращаются к различным инструментам на основе плана выполнения, включая векторные поисковые системы для баз данных документов, веб-поиск для актуальной информации, API для данных конкретного программного обеспечения или сервисов, а также калькуляторы для вычислительных задач. Несколько агентов могут одновременно работать с разными источниками, чтобы максимизировать эффективность и охват.
Шаг 4: Проверка качества: Система оценивает извлеченную информацию на релевантность и точность с помощью встроенных механизмов валидации. Если содержимое недостаточно или нерелевантно, агенты переформулируют запросы, а механизмы валидации проверяют согласованность между несколькими источниками, чтобы обеспечить надежное качество информации.
Шаг 5: Итеративное уточнение: Система определяет, необходимо ли дополнительное извлечение, исходя из качества и полноты собранной информации. Агенты могут повторно выполнять запросы с уточненными поисковыми терминами, и этот процесс повторяется до тех пор, пока не будет собрано достаточно качественной информации для предоставления исчерпывающего ответа.
Шаг 6: Генерация ответа: Финальный агент синтезирует информацию из всех источников в связный ответ. Он генерирует исчерпывающие ответы, используя проверенный контекст, и предоставляет цитаты и указание источников, когда это применимо, чтобы поддерживать прозрачность и достоверность.
Типы агентов и роли
Маршрутизирующие агенты: Определяют, какие внешние источники знаний и инструменты используются для обработки пользовательских запросов
Агенты планирования запросов: Обрабатывают сложные запросы и разбивают их на пошаговые процессы
ReAct Agents: Объединяют возможности рассуждения и действия для динамической адаптации рабочего процесса
Plan-and-Execute Agents: Самостоятельно обрабатывают многоэтапные рабочие процессы без постоянной координации
 Agentic RAG workflow.png
Agentic RAG workflow.png
Преимущества и сложности Agentic RAG
Agentic RAG предлагает значительные преимущества по сравнению с традиционными подходами, одновременно вводя некоторые операционные аспекты, которые необходимо учитывать.
Преимущества
Повышенная точность: Валидация по нескольким источникам и перекрестная проверка значительно снижают количество галлюцинаций и повышают надежность ответов. Способность системы проверять информацию по нескольким базам знаний создает надежный механизм фактчекинга, с которым традиционный RAG не может сравниться.
Интеграция нескольких источников: Доступ к разнообразным базам знаний, API и внешним инструментам позволяет осуществлять комплексный сбор информации из структурированных баз данных, веб-поиска, калькуляторов и специализированного программного обеспечения. Такая универсальность позволяет системе обрабатывать сложные запросы, требующие информации из нескольких доменов.
Итеративное уточнение: Непрерывное улучшение качества ответов через несколько циклов извлечения и валидации гарантирует, что неоптимальные первоначальные результаты могут быть улучшены. Система обучается на каждой итерации, переформулируя запросы и улучшая поисковые стратегии до тех пор, пока не будет достигнуто удовлетворительное качество информации.
Адаптивное решение задач: Проактивный подход к сложным запросам с интеллектуальной маршрутизацией и динамической корректировкой рабочего процесса. Система может автономно определять лучшую стратегию извлечения, адаптироваться к изменяющимся контекстам и обрабатывать неожиданные сценарии без необходимости ручного вмешательства или обширного prompt engineering.
Сложности
Более высокие затраты: Большее количество агентов и итеративные процессы требуют больше вычислительных ресурсов и использования токенов, потенциально увеличивая операционные расходы в 2-3 раза по сравнению с традиционным RAG. Многоагентная архитектура требует большего количества вызовов API, более длительного времени обработки и дополнительной инфраструктуры для поддержки сложных рабочих процессов.
Повышенная задержка: Множественные взаимодействия агентов, этапы проверки и потенциальные циклы итераций могут значительно замедлять время ответа. Сложные запросы могут требовать нескольких раундов извлечения и уточнения, что делает систему менее подходящей для приложений реального времени, которым нужны немедленные ответы.
Проблемы надежности: Агенты могут испытывать трудности или не справляться с выполнением сложных задач, создавая точки отказа в рабочем процессе. Координация между несколькими агентами может становиться нестабильной, приводя к неполным ответам, бесконечным циклам или противоречивым решениям, требующим сложных механизмов обработки ошибок.
Сложность интеграции: Подключение разнообразных инструментов, источников знаний и управление координацией нескольких агентов требуют сложной оркестрации и обширного тестирования. Архитектура системы становится значительно более сложной, чем у традиционного RAG, требуя специализированной экспертизы для развертывания, обслуживания и устранения неполадок.
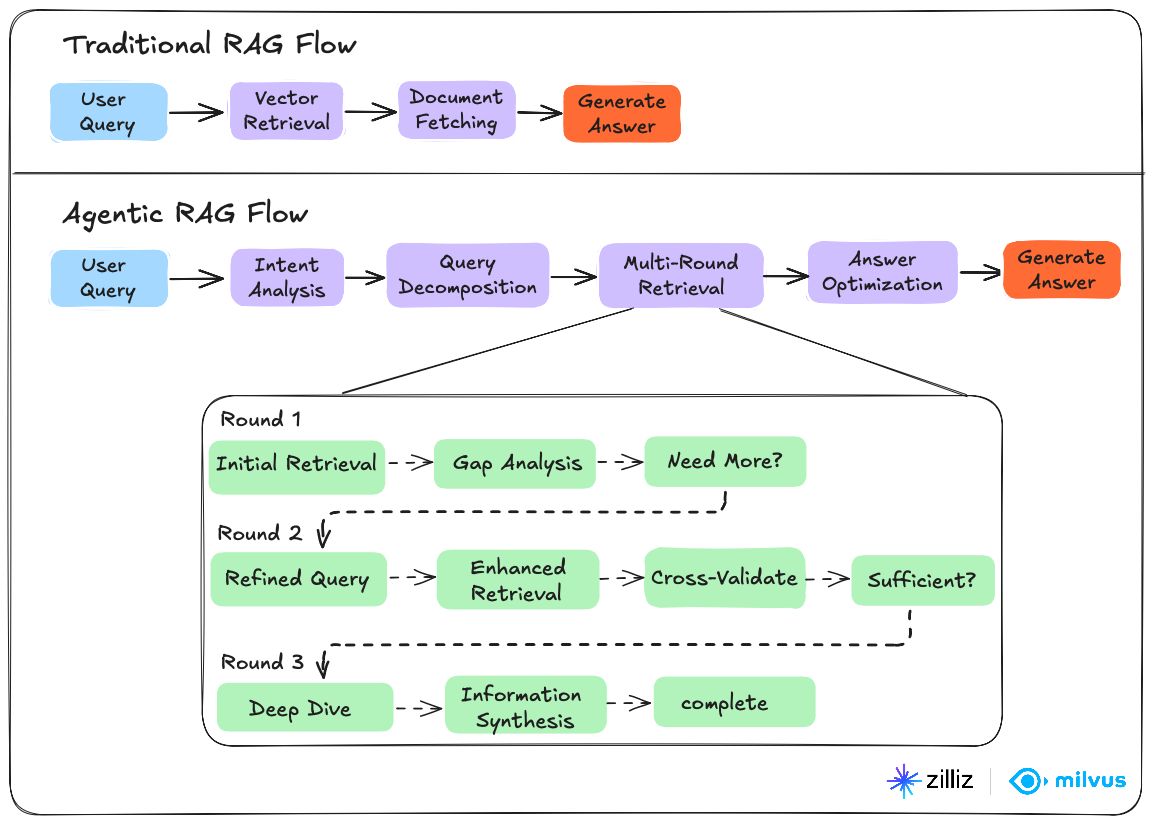
Сравнение Agentic RAG с традиционным RAG
 Agentic RAG vs Traditional RAG.jpg
Agentic RAG vs Traditional RAG.jpg
| Характеристика | Традиционный RAG | Agentic RAG |
|---|---|---|
| Источники данных | Единая база знаний | Несколько источников и внешние инструменты |
| Обработка запросов | Одноразовое извлечение | Многоэтапный, итеративный подход |
| Проверка | Нет встроенной проверки | Автоматизированная оценка качества |
| Адаптивность | Статическая, основанная на правилах | Динамическое, интеллектуальное принятие решений |
| Доступ к инструментам | Ограничен векторной базой данных | API, веб-поиск, калькуляторы, внешние сервисы |
| Возможности планирования | Простое извлечение и генерация | Сложное рассуждение и декомпозиция задач |
| Обработка ошибок | Требуется ручное вмешательство | Механизмы самокоррекции и повторных попыток |
| Масштабируемость | Ограничена одним источником | Масштабируется за счет дополнительных агентов и источников |
| Стоимость | Меньшее использование токенов | Более высокие вычислительные накладные расходы |
| Скорость ответа | Более быстрый первоначальный ответ | Переменная, в зависимости от сложности |
Сценарии использования Agentic RAG
Управление знаниями предприятия: RAG-системы на базе агентов отлично подходят для анализа и извлечения информации из разнородных корпоративных данных. Компании могут развертывать системы, которые автоматически выполняют поиск по внутренним документам, базам данных, электронным письмам и внешней рыночной аналитике, чтобы отвечать на сложные бизнес-вопросы.
Автоматизация поддержки клиентов: Компании, стремящиеся оптимизировать службы поддержки клиентов, могут использовать автоматизированные RAG-системы для обработки более простых обращений клиентов. Система agentic RAG может передавать более сложные запросы поддержки сотрудникам. Система может получать доступ к руководствам по продуктам, базам данных FAQ, истории клиентов и информации о статусе в реальном времени, чтобы предоставлять комплексную поддержку.
Информационные системы здравоохранения: Медицинские специалисты могут использовать agentic RAG для одновременного доступа к медицинским картам пациентов, медицинской литературе, базам данных лекарственных препаратов и клиническим рекомендациям, что позволяет принимать более обоснованные решения при соблюдении конфиденциальности данных и нормативных стандартов.
Поддержка финансовых решений: Несколько RAG-агентов могут выполнять вычисления, находить информацию о погоде, рекомендовать акции и рыночные тренды, анализировать данные и многое другое. Финансовые аналитики могут запрашивать системы, которые объединяют внутренние данные портфеля с внешней рыночной информацией, регуляторной отчетностью и экономическими индикаторами.
Часто задаваемые вопросы
В: Может ли agentic RAG получать доступ к нескольким документам одновременно?
A: Агент RAG может получать доступ к данным, извлекать и сравнивать их в нескольких предоставленных документах. Система превосходно справляется с синтезом информации из различных источников в одном ответе.
Q: Чем агентный RAG отличается от стандартного RAG?
A: Классический RAG может извлекать информацию из одного источника, тогда как агентный RAG использует несколько агентов для доступа к данным из различных источников и их оркестрации. Традиционный RAG является реактивным, в то время как агентный RAG — проактивный и интеллектуальный.
Q: Какие фреймворки можно использовать для создания агентных RAG-приложений?
A: Доступно несколько Python-фреймворков с готовыми к использованию компонентами и инструментами для аналитики и мониторинга агентов RAG. К таким фреймворкам относятся Phidata, LangGraph, Swarm, Microsoft Autogen и т. д.
Q: Всегда ли агентный RAG лучше традиционного RAG?
A: Не обязательно. Хотя агентный RAG оптимизирует результаты с помощью вызова функций, многошагового рассуждения и многоагентных систем, он не всегда является лучшим выбором. Для простых запросов к одному источнику традиционный RAG может быть более эффективным и экономически выгодным.
Q: Может ли агентный RAG работать с разными типами данных?
A: Да, современные агентные RAG-системы поддерживают мультимодальную обработку, работая с текстом, изображениями, аудио и другими форматами структурированных и неструктурированных данных.
- Что такое агентный RAG?
- Ключевые особенности агентного RAG
- Как работает агентный RAG
- Преимущества и сложности Agentic RAG
- Сравнение Agentic RAG с традиционным RAG
- Сценарии использования Agentic RAG
- Часто задаваемые вопросы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно