




Как ведущая мировая платформа GPU и ИИ использует Milvus для масштабирования мультимодального интеллектуального анализа данных в своей системе автономного вождения

-30% стоимости
Сокращение объёма используемой памяти и хранилища благодаря первичным ключам на диске и оптимизированной компоновке сегментов в Milvus 2.5.
Масштаб 10×
Доказанный запас для масштабирования еще на порядок без перепроектирования или неожиданных затрат.y без архитектурных изменений или неожиданных затрат.
Надёжность корпоративного уровня
Непрерывное производство в огромных масштабах без серьезных инцидентов.
Гибридный поиск
Единый векторный поиск и фильтрация метаданных для поддержки сложных запросов.
From a system stability perspective, it's really quite good. Over the year-plus that we've been using it—from version 2.4.3 to now 2.5.8—I honestly haven't encountered many issues. The system can just run there for months, with new data being written every day and users searching every day, without any problems. I don't need to worry about it.
Team Lead
О компании
Заказчик — мировой лидер в области ускоренных вычислений и искусственного интеллекта с десятилетиями опыта создания GPU и программных платформ, используемых в играх, робототехнике, центрах обработки данных и автомобильных приложениях. Одной из его флагманских инициатив является комплексная платформа для передовых систем помощи водителю и автономного вождения. Эта платформа поддерживает полный жизненный цикл разработки систем самоуправления — от крупномасштабного сбора данных и обучения моделей ИИ до инференса в автомобиле и принятия решений в реальном времени.
За этой платформой стоит подразделение компании Autonomous Vehicle (AV) Data Engineering, отвечающее за инфраструктуру данных, которая обеспечивает работу ее технологии самоуправляемого вождения. Каждый час реального вождения генерирует терабайты мультимодальных сенсорных данных, включая синхронизированные потоки с камер, облака точек LiDAR, измерения радаров, данные высокоточной локализации и подробные метаданные состояния автомобиля. Миссия команды — сделать этот огромный и постоянно растущий набор данных доступным для поиска, обнаружения и операционного использования сотнями инженеров, которым необходимо находить сценарии из «длинного хвоста», выявлять редкие пограничные случаи и проверять поведение моделей в реальных условиях.
Чтобы выполнить эти требования, команда построила систему мультимодального интеллектуального анализа данных, способную выполнять поиск по десяткам миллиардов проиндексированных точек сенсорных данных, собранных тестовыми автопарками. Система преобразует необработанные сенсорные данные в векторные эмбеддинги, чтобы инженеры могли выполнять глубокие, контекстно-зависимые запросы, например: «автомобили, перестраивающиеся справа в сильный дождь», «пешеходы, переходящие дорогу в сумерках на нерегулируемых перекрестках» или «двухполосные круговые развязки с ограниченной видимостью».
Изначально система работала на FAISS, но по мере роста объема данных и операционных требований команда перешла на Milvus, чтобы добиться более высокой масштабируемости, снизить трудозатраты на обслуживание и повысить надежность в production. Milvus предоставил понятный путь к поддержке на порядок большего объема данных, снижению операционных накладных расходов и повышению эффективности кластеризации, индексирования и хранения по мере дальнейшего расширения парка автономных автомобилей.
Проблема: FAISS не мог масштабироваться
Узкое место в управлении данными
Ранняя архитектура этой системы интеллектуального анализа данных была намеренно простой. Каждая сессия автономного вождения — обычно поездка продолжительностью около часа — обрабатывалась в кадры, преобразовывалась в векторные эмбеддинги с помощью собственных моделей компании и группировалась в индексные файлы FAISS, обычно по одному на день.
Поначалу такая структура работала хорошо, но она не масштабировалась. По мере стремительного роста набора данных росло и количество индексных файлов — в итоге оно достигло сотен тысяч. Каждый из них представлял собой небольшой изолированный фрагмент информации. Поиск по ним существенно усложнялся: дневные индексы часто содержали пересекающиеся данные, что требовало сложной логики для фильтрации и объединения метаданных. На практике это означало, что, хотя поиск в пределах одного дня работал нормально, большинству пользователей нужно было выполнять запросы по более широким условиям — например, по конкретным сценариям вождения, охватывающим несколько дней или регионов. Такие поиски должны были обращаться сразу ко множеству отдельных индексных файлов, что было вычислительно затратно. Инженерам часто приходилось вручную сужать область поиска, предполагая, какие файлы могут содержать релевантные данные, прежде чем запустить запрос. Эти догадки делали процесс поиска медленным и ненадежным.
Недостаток гибкости
FAISS — это не база данных, а библиотека. Она подходит для поиска ближайших соседей для заданного вектора, но production-системам поиска требуется гораздо больше, чем просто быстрое сопоставление по сходству.
На практике инженеры не хотели выполнять поиск сразу по всему корпусу. Им требовалась контекстная фильтрация — чтобы находить, например, «кадры с фронтальной камеры, снятые во время слабого дождя на городских дорогах», или «ночные поездки по автомагистралям Калифорнии». Для достижения такого уровня точности требовалось сочетать векторный поиск с фильтрами по метаданным, таким как тип камеры, время, местоположение, погода и версия модели. Но FAISS не предоставлял такие возможности из коробки. Чтобы закрыть этот пробел, команде пришлось построить сложный стек пользовательской логики: отдельные базы данных метаданных, специализированные планировщики запросов, решающие, какие индексы FAISS сканировать, и ручную постфильтрацию результатов после извлечения.
Со временем эти доработки создали серьезную проблему масштабирования. Разные ракурсы камер, несколько моделей эмбеддингов и версионированные конвейеры предобработки — все это требовало отдельных стратегий управления. Не было встроенного понятия коллекций, разделов или логической группировки данных — только индексные файлы. Каждый уровень организации, от версионирования данных до фильтрации запросов, приходилось писать и поддерживать в пользовательском коде. Система работала — но ценой гибкости, сопровождаемости и долгосрочной масштабируемости.
Проблема масштабируемости
Система уже испытывала нагрузку из-за миллиардов векторов, а тестовые автомобили компании каждый день генерировали новые данные. Тем временем исследовательские команды внедряли новые модели эмбеддингов, каждая из которых требовала масштабной переиндексации исторических данных. Было лишь вопросом времени, когда рабочие нагрузки вырастут в десять раз, но у файловой конфигурации FAISS не было практического способа масштабироваться до такого уровня.
Хуже того, каждый новый набор данных означал больше индексных файлов и больше ручных обновлений хранилища метаданных. Не было автоматического шардинга, встроенной балансировки нагрузки и возможности добавлять емкость по требованию. Архитектура стала устаревшей — статичной, трудоемкой и плохо приспособленной к росту.
Скрытые инженерные затраты
Помимо облачных затрат, самой большой проблемой были скрытые инженерные накладные расходы на поддержку FAISS. Инженерам приходилось управлять сложными системами метаданных, проектировать пользовательскую логику распределения данных и вручную обновлять миллионы индексных файлов. Со временем эти накладные расходы замедлили инновации: производительность поиска ухудшалась, циклы разработки становились длиннее, а новые идеи так и не выходили за пределы доски. По мере дальнейшего роста объемов данных система становилась все более жесткой и хрупкой. Стало ясно, что попытки модернизировать унаследованную конфигурацию больше не являются устойчивым подходом.
Решение: переархитектирование для масштабирования с помощью Milvus
Чтобы преодолеть эти трудности, команде AV Data требовалась система, способная уже сегодня обрабатывать десятки миллиардов векторов, с понятным путем к 10-кратному росту и beyond. Она должна была обеспечивать надежную фильтрацию, операционную простоту и — прежде всего — производственную надежность при минимальном обслуживании.
Процесс оценки
Вместо того чтобы проводить широкое сравнительное тестирование всех новых векторных баз данных, команда сосредоточилась на популярной Milvus Vector Database, запустив proof-of-concept с 400–500 миллионами векторов — достаточно крупный, чтобы выявить реальные узкие места. В ходе тестирования инженеры воспроизвели весь свой рабочий процесс с данными: индексировали наборы данных с разными типами индексов, чтобы сравнить компромиссы, измеряли время индексации для оценки ежедневных пакетных обновлений и проводили бенчмаркинг задержки при реалистичных комбинациях фильтров и шаблонах запросов. Они намеренно доводили Milvus до предела, выполняя сложные поиски с несколькими условиями и масштабируя объемы данных для проверки стабильности.
Почему Milvus?
Результаты proof-of-concept сделали Milvus очевидным выбором для команды AV Data.
Приемлемая производительность запросов: Milvus стабильно обеспечивал задержки запросов на уровне секунд даже для самых сложных поисков с большим количеством фильтров — полностью в рамках требований для внутренних рабочих нагрузок по интеллектуальному анализу данных.
Нативная фильтрация и гибкость запросов: Инженеры теперь могли объединять поиск по векторному сходству с фильтрами по метаданным в одном запросе — возможности, которые ранее требовали обширного кастомного кода в FAISS.
Организованная структура данных: Векторные эмбеддинги из разных моделей хранились в отдельных коллекциях, каждая из которых была разделена по таким атрибутам, как дата съемки или регион. Milvus автоматически управлял распределением данных по сегментам, снимая необходимость ручного управления файлами.
Бесшовная масштабируемость: По мере роста объема данных команда добавляла больше узлов для расширения емкости. Распределенная архитектура Milvus масштабировалась линейно без необходимости перепроектирования системы.
Активное open-source-сообщество: Во время тестирования инженеры AV Data получали оперативную практическую поддержку от команды Milvus и участников сообщества, что укрепило уверенность в Milvus как в надежной, готовой к production экосистеме.
Реализация новой архитектуры с Milvus
В своей основе архитектура этой мультимодальной системы интеллектуального анализа данных проста, но ее реализация в огромном масштабе требует тщательной инженерной проработки и точности. Сырые видеоданные из поездок автономных автомобилей — часы непрерывной съемки с нескольких камер — поступают в конвейер обработки, который извлекает отдельные кадры или короткие клипы, обычно длиной в несколько секунд.
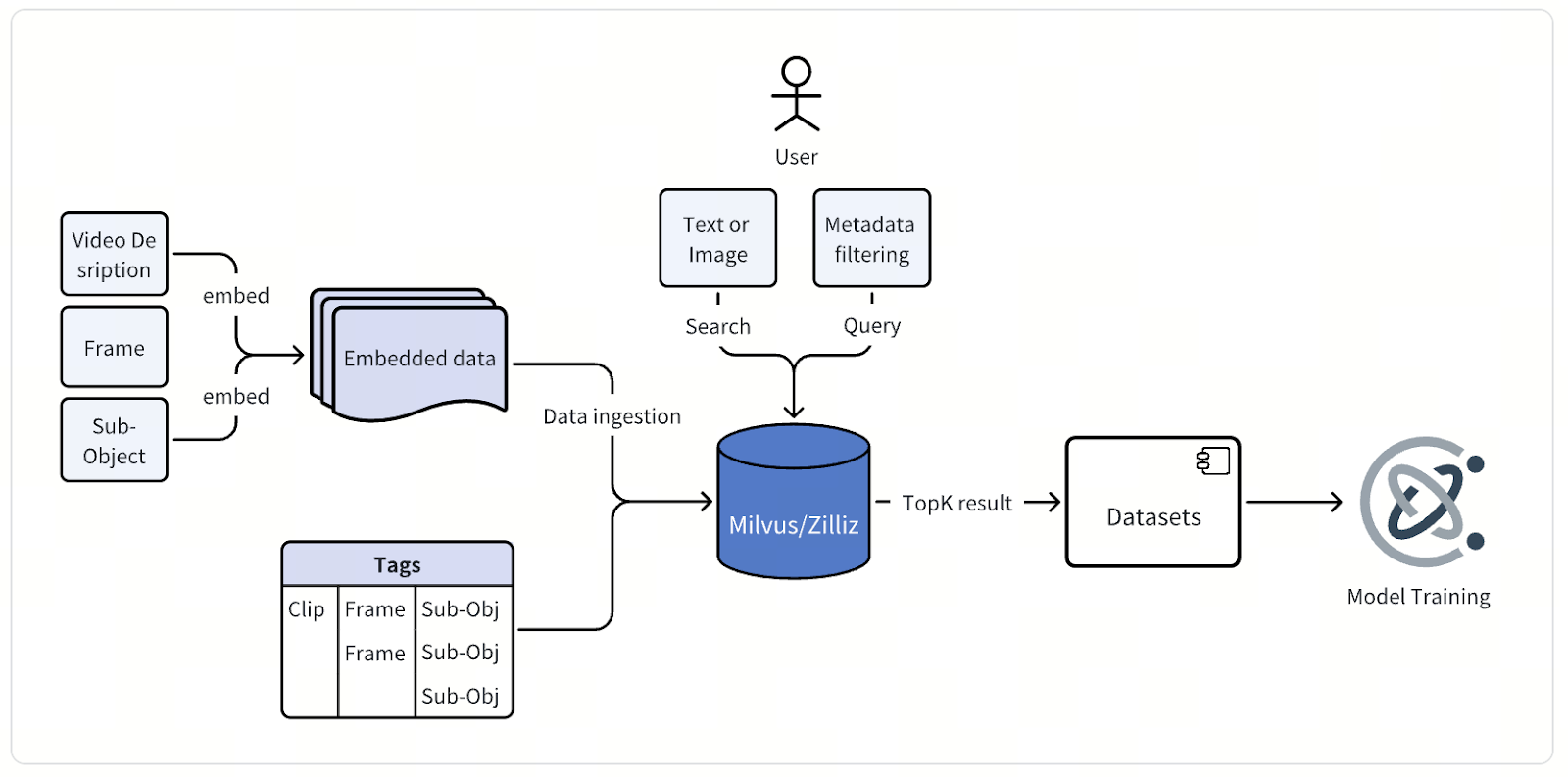
Затем каждый кадр или клип проходит через собственные модели эмбеддингов компании, специально созданные для автономного вождения. Для данных изображений команда использует модели, производные от архитектуры CLIP, кастомизированные и дообученные для захвата семантики, специфичной для дорожной среды. Для видеоданных они полагаются на собственные внутренние модели — семейство foundation models для приложений физического AI. Вместе эти модели преобразуют визуальные данные в высокоразмерные векторные эмбеддинги, кодирующие богатый контекстный смысл.
После генерации эти векторные эмбеддинги — вместе с подробными метаданными — сохраняются и индексируются в Milvus Vector Database. Каждая точка данных содержит атрибуты, описывающие сессию поездки, положение камеры, временную метку, состояние автомобиля, местоположение и погодные условия, среди прочего. Эти метаданные также индексируются, чтобы обеспечить быстрый и точный поиск с фильтрацией по массивным наборам данных.
Через единый интерфейс запросов инженеры могут искать данные несколькими способами. Они могут ввести текстовое описание, загрузить эталонное изображение или видео либо объединить векторный поиск с фильтрами по метаданным, чтобы точно определить, что им нужно. Например, один запрос может звучать так: «городские перекрестки ночью с переходящими пешеходами», и Milvus вернет наиболее релевантные кадры или клипы для просмотра, анализа и улучшения модели.
Преимущества: экономическая эффективность, стабильность и масштаб
После более чем года непрерывной эксплуатации Milvus доказал свою состоятельность не только технически, но и с точки зрения операционной трансформации. Следующие результаты показывают, как его архитектура и экосистема превратились в реальную эффективность в масштабе.
Более простые операции, меньше проблем и более быстрая разработка
Миграция с сотен тысяч файлов FAISS на Milvus устранила целый слой операционных накладных расходов. Больше нет ручного управления индексными файлами, ad-hoc-скриптов и кастомной логики запросов. Распределение данных, управление сегментами и маршрутизация запросов теперь выполняются автоматически. Обновления стали простыми, мониторинг — единым, а метрики дают ясную картину. В результате меньше времени уходит на поддержание систем и больше — на интеллектуальный анализ данных для получения инсайтов.
Снижение инженерных затрат плюс дополнительное сокращение расходов на 30% после обновления до Milvus 2.5
Внедрение Milvus сразу же снизило как инфраструктурные, так и инженерные затраты. Переход от файловой системы FAISS устранил необходимость в ручном управлении файлами и сложном отслеживании метаданных, сэкономив значительное время разработчиков и операционные усилия. Последующее обновление с Milvus 2.4 до Milvus 2.5 обеспечило дополнительное снижение инфраструктурных затрат на 30% благодаря более продуманному отображению памяти, хранению первичных ключей на диске и более эффективному управлению сегментами.
В совокупности эти улучшения позволяют команде AV Data запускать те же рабочие нагрузки на меньших инстансах AWS — или индексировать гораздо больше данных — без увеличения расходов или затрат на обслуживание. Воодушевленная этими результатами, команда планирует протестировать Milvus 2.6, в котором представлены новые типы индексов, такие как RaBitQ, а также дальнейшие оптимизации, которые, как ожидается, еще больше повысят производительность и экономическую эффективность. Для крупных офлайн-пакетных нагрузок скорость построения индекса остается ключевой проблемой. Благодаря вкладу команды NVIDIA cuVS Milvus теперь поддерживает построение индексов с ускорением на GPU и обслуживание на CPU (GPU-build, CPU-serve). Этот подход значительно ускоряет построение индексов, сохраняя экономическую эффективность, и, как ожидается, еще больше усилит преимущество Milvus по соотношению цены и производительности в нагрузках автономного вождения.
Встроенная масштабируемость, подтвержденная на практике
Теперь платформа индексирует десятки миллиардов векторов и ежедневно без затруднений принимает новые данные. Внутреннее моделирование подтверждает, что она может масштабироваться еще в 10 раз без переработки архитектуры или неожиданных затрат, превращая то, что когда-то было ограничением емкости, в долгосрочное стратегическое преимущество. Благодаря этому запасу команда может перейти от индексирования двух лет недавних данных о вождении к охвату всего исторического архива, обеспечивая поиск по каждой когда-либо записанной сессии вождения. Они также могут параллельно запускать несколько моделей эмбеддингов, чтобы оптимизировать поиск для разных типов запросов, и даже хранить данные бессрочно, вместо того чтобы удалять их по мере устаревания. Масштабируемость здесь означает не просто обработку большего объема данных, а обеспечение непрерывного обучения и более быстрого прогресса на пути к более безопасному автономному вождению.
Корпоративная надежность в огромном масштабе
За более чем год непрерывной эксплуатации в продакшене Milvus спокойно обрабатывал десятки миллиардов векторов с ежедневной загрузкой и запросами — без единого серьезного инцидента. Система стабильно работает в фоновом режиме, требуя минимального надзора. Никаких сбоев по выходным, никаких экстренных патчей — только стабильная, предсказуемая производительность. Такая надежность в подобном масштабе означает меньше операционных рисков, меньше аврального устранения проблем и больше внимания к созданию ценности, а не к управлению инфраструктурой.
Более богатый поиск, более умные рабочие процессы
Milvus сочетает векторный поиск с фильтрацией по метаданным, предоставляя инженерам компании новые способы анализа сложных данных о вождении. Например, они могут находить все изображения строительных зон, полученные с фронтальных камер при дневном освещении, или фильтровать по времени и местоположению, чтобы сравнивать поведение модели в разных обновлениях и регионах. Разные коллекции хранят эмбеддинги из разных моделей, позволяя командам тестировать новые архитектуры без влияния на продакшен. Эти возможности ускоряют эксперименты и помогают выявлять инсайты, которые раньше требовали значительного объема специализированной инженерной разработки.
Сильное сообщество, усиливающее эффект
Помимо технологии, open-source-сообщество Milvus стало важной частью успеха компании. Во время тестирования и развертывания инженеры получали оперативную поддержку напрямую от участников и мейнтейнеров Milvus. Такая отзывчивость сокращала простои, ускоряла отладку и помогала сохранять темп работы. Со временем активное сообщество продолжило приносить пользу, помогая проверять новые идеи, сглаживать обновления и делиться лучшими практиками. Для этого заказчика Milvus — это не просто надежное программное обеспечение, а совместная экосистема, которая усиливает платформу и обеспечивает долгосрочную эффективность.
Уроки из Production
Выбор правильного индекса: баланс между масштабом, стоимостью и точностью
Выбор индекса — одно из самых важных практических решений при создании системы векторного поиска. Milvus поддерживает множество типов индексов, каждый из которых имеет свои компромиссы по скорости, использованию памяти и точности. Для команды AV Data цель заключалась в том, чтобы найти баланс между масштабом данных, стоимостью инфраструктуры и точностью поиска, а не просто выбрать самый быстрый вариант.
После тестирования нескольких конфигураций они выбрали IVF_FLAT, который группирует векторы в кластеры и выполняет точный поиск внутри релевантных из них. Это не самый быстрый и не самый компактный вариант, но для десятков миллиардов векторов и умеренных требований к задержке он обеспечил правильное сочетание производительности и точности, оставаясь при этом эффективным.
Команда обнаружила, что, когда индекс хорошо соответствует рабочей нагрузке, редко возникает необходимость переходить на что-то более новое. На практике удачно подобранный индекс экономит больше времени и ресурсов, чем погоня за небольшими приростами производительности. Для крупномасштабных систем именно стабильная и предсказуемая производительность обеспечивает бесперебойность операций.
Memory Mapping: обмен задержки на стоимость в масштабе
Одним из самых эффективных технических решений команды стало использование memory mapping (Mmap) для контроля затрат на инфраструктуру. В традиционных конфигурациях хранение всех векторных данных в RAM потребовало бы огромных и дорогостоящих инстансов. Благодаря memory mapping в Milvus большая часть данных остается на диске, а операционная система автоматически удерживает часто используемые фрагменты в памяти. Такая архитектура добавляет некоторую задержку — чтение с диска медленнее, чем из RAM, — но поддерживает предсказуемую производительность и эффективное использование ресурсов. Для рабочей нагрузки компании такой компромисс был совершенно оправдан. Их пользователи — инженеры, выполняющие аналитические запросы, а не конечные пользователи, ожидающие мгновенных ответов, и уровень конкурентности остается низким.
Операции удаления: когда небольшие допущения ломаются в масштабе
Один из самых важных уроков команда получила из того, что казалось простым: удаления данных. В append-only-архитектуре Milvus удаленные векторы не удаляются сразу — они помечаются для удаления и позже очищаются через фоновую компакцию. Во время тестирования удаление миллионов векторов неожиданно вызвало переиндексацию миллиардов, поскольку фильтры Bloom давали ложноположительные срабатывания по тысячам сегментов. То, что казалось обычной очисткой, в итоге перегрузило data nodes и остановило задания.
Решение пришло благодаря пониманию того, как Milvus управляет данными, и корректировке рабочего процесса — настройке фильтров Bloom, использованию ключей партиционирования для точного нацеливания удалений и переходу на insert-only bulk loading. Вывод: в масштабе даже простые операции могут вести себя иначе, и понимание внутреннего устройства системы — ключ к поддержанию предсказуемой производительности.
Взгляд в будущее
Команда готовится перейти на Milvus 2.6 вскоре после релиза, будучи уверенной, что новые типы индексов и архитектурные оптимизации обеспечат еще один скачок эффективности. Ранние обсуждения с инженерной командой Milvus указывают на дальнейшее снижение затрат и улучшение использования ресурсов, что компания планирует проверить с помощью полномасштабных бенчмарков.
Заглядывая дальше в будущее, команда видит захватывающие возможности для расширения функциональности и масштабирования. Такие функции, как гибридный поиск, сочетающий текстовые и векторные запросы, могут открыть новые способы исследования мультимодальных данных, а расширенные фильтры в стиле баз данных упростят сложные рабочие процессы. Предстоящий релиз Milvus 3.0 также открывает перспективы для многоуровневых архитектур, позволяя компании сохранять быстрый доступ к свежим данным и при этом эффективно хранить весь исторический архив. В совокупности эти усовершенствования дадут компании платформу данных, которая легко масштабируется, поддерживает более глубокие поисковые возможности и растет более эффективно.
Кроме того, ожидается, что внедрение и развитие ускоренных на GPU построений индексов на базе NVIDIA cuVS с обслуживанием на CPU (GPU-build, CPU-serve) в Milvus обеспечит качественный скачок в производительности офлайн-индексации. Используя GPU NVIDIA и высокооптимизированные библиотеки cuVS, Milvus может строить крупномасштабные векторные индексы значительно быстрее, чем конвейеры, работающие только на CPU, при этом продолжая экономично обслуживать запросы на CPU. Это существенно сокращает время от данных до запроса, позволяет чаще обновлять индексы и еще больше усиливает преимущество Milvus по соотношению цены и производительности для автономного вождения и других крупномасштабных мультимодальных рабочих нагрузок, где критически важны быстрая итерация и свежие данные.
Заключение
Команда AV Data клиента построила мощную платформу для интеллектуального анализа данных, которая ускоряет разработку автономного вождения, делая огромные объемы мультимодальных данных доступными для поиска и практического использования. Миграция с FAISS на Milvus решила критические проблемы масштабируемости, гибкости и операционной сложности, одновременно обеспечив измеримую экономию затрат и выдающуюся стабильность в production.
После более чем года непрерывной работы и десятков миллиардов проиндексированных векторов платформа доказала, что Milvus может служить production-grade основой для крупномасштабного, предметно-ориентированного векторного поиска. Система ежедневно загружает новые данные, поддерживает инженеров во всех программах компании по автономному вождению и предлагает ясный путь к дальнейшему масштабированию в 10 раз без переархитектурирования.
Для организаций, создающих системы векторного поиска с огромным масштабом данных, важна экономическая эффективность, а стабильность перевешивает субмиллисекундную задержку. Опыт компании показателен. Milvus демонстрирует, что open-source векторная база данных может не только соответствовать требованиям production, но и продолжать улучшаться со временем, обеспечивая надежную, масштабируемую и готовую к будущему основу для реальной AI-инфраструктуры.
- О компании
- Проблема: FAISS не мог масштабироваться
- Решение: переархитектирование для масштабирования с помощью Milvus
- Преимущества: экономическая эффективность, стабильность и масштаб
- Уроки из Production
- Взгляд в будущее
- Заключение
Контент
Пример использования
Отрасль
Автомобильная отрасль
Используемая технология