




Оптимизация разговорного ИИ в FARFETCH

15x
ускоренное время индексирования
5x
более быстрое время выполнения запросов
Повышение конверсии
благодаря более релевантным рекомендациям продуктов
Несколько типов метрик
для поддержки различных вариантов использования
Milvus consistently outperformed Weaviate, emphasizing the indexing time for scenario S9, closely resembling the FARFETCH product catalog's dimensions.
PEDRO MOREIRA COSTA
О ФАРФЕТКЕ
Компания FARFETCH, лидер в области онлайн-ритейла модной одежды, расширяет границы цифрового шопинга благодаря своей последней инновации - iFetch. Эта система разговорного искусственного интеллекта призвана привнести в цифровую сферу персонализированное обслуживание высокого класса, которое обычно встречается в роскошных физических магазинах. В рамках этой инициативы FARFETCH Chat R&D разрабатывает специализированную разговорную рекомендательную систему. Этот чат-бот, интегрированный в iFetch, позволяет пользователям взаимодействовать с каталогом товаров FARFETCH с помощью естественного языка и изображений. Например, пользователь может загрузить фотографию понравившегося ему пиджака, и чатбот в ответ предложит ему подборку похожих пиджаков. Благодаря органичному сочетанию передовых технологий искусственного интеллекта и внимания к пользовательскому опыту, FARFETCH стремится переосмыслить то, что покупатели могут ожидать от онлайн-покупок.
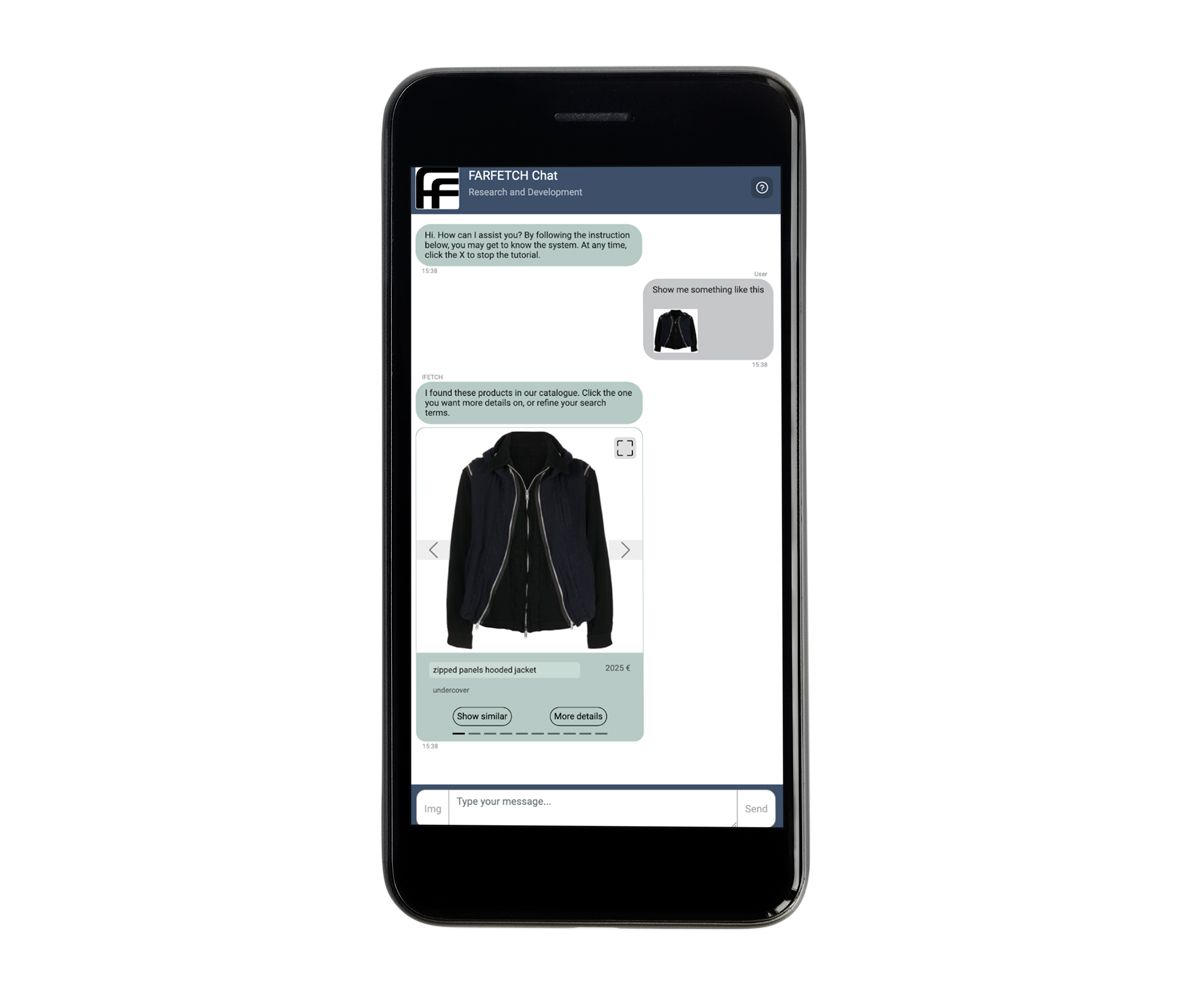 Чат FARFETCH показывает похожую витрину
Чат FARFETCH показывает похожую витрину
Однако они столкнулись с серьезной проблемой: традиционные каталоги товаров с их ограниченными метаданными не могли отразить сложную взаимосвязь и нюансы широкого ассортимента товаров. Чтобы решить эту проблему, они использовали алгоритмы машинного обучения для создания вкраплений товаров - высокоразмерных точек данных, которые служат надежным языком для системы искусственного интеллекта. Это позволяет чатботу понимать и рекомендовать продукты с беспрецедентной точностью. Однако хранение и поиск этих вкраплений в режиме реального времени представляли собой еще одно препятствие, требующее специализированного решения для хранения данных, способного эффективно работать с высокоразмерными данными.
Важность векторных баз данных
Векторные базы данных, также известные как Vector Similarity Engines (VSE), - это специализированные базы данных, разработанные для обработки сложных, высокоразмерных данных, называемых векторными вкраплениями. В этих базах данных используются алгоритмы приближенных ближайших соседей (ANN), которые незаменимы для быстрого и точного поиска данных. Эта функция особенно важна для iFetch, которая требует взаимодействия с клиентами в режиме реального времени, чтобы мгновенно предоставлять рекомендации по товарам и отвечать на их запросы. Выбор векторной базы данных - это не просто технический момент, а стратегическое решение, которое напрямую влияет на производительность, надежность и эффективность iFetch. Для того чтобы выбрать наиболее подходящую VSE, компания провела комплексное сравнительное исследование. В ходе бенчмарка оценивались различные базы данных, включая Vespa, Milvus, Qdrant, Weaviate, Vald и Pinecone, по таким критериям, как скорость индексирования, скорость выполнения запросов и масштабируемость. Бенчмаркинг также включал стресс-тесты для оценки работы каждой VSE при пиковых нагрузках, а также сценарии обхода отказа и восстановления для оценки устойчивости.
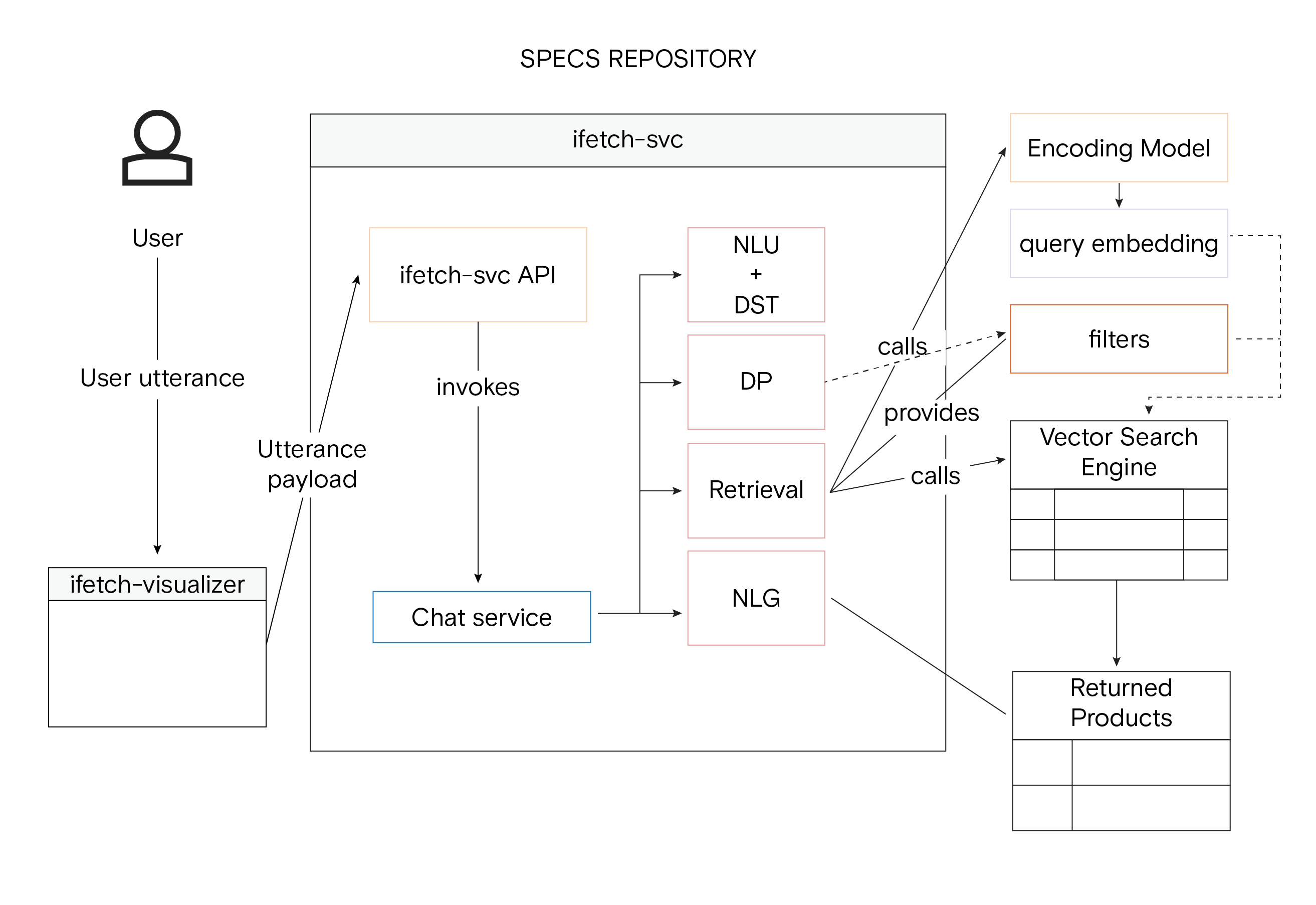 Холистическое представление архитектуры системы iFetch с помощью Vector Similarity Searc
Холистическое представление архитектуры системы iFetch с помощью Vector Similarity Searc
Критерии и выбор эталонов
Процесс бенчмаркинга, проведенный командой Farfetch, был исчерпывающим и методичным, охватывая широкий спектр факторов, имеющих решающее значение для долгосрочного успеха iFetch. В их число входило разнообразие типов индексов, типов метрик, возможностей обслуживания моделей и принятия сообществом. Также учитывались качество документации и доступность поддержки, поскольку эти факторы влияют на простоту внедрения и текущее сопровождение.
| Feature | Qdrant | Milvus | Weaviate | Vespa | Vald | Pinecone | |||
|---|---|---|---|---|---|---|---|---|---|
| Модель согласованности | N/A | Strong Consistency | Eventual Consistency | Eventual Consistency | N/A | Eventual Consistency | |||
| Поддержка GraphQL | N/A | N/A | Yes | N/A | N/A | N/A | N/A | N/A | |
| Sharding | Нет (будет рассмотрено дата неизвестна) | Да | Да | Да | Да | Да | N/A | N/A | N/A |
| Пагинация | N/A | Нет (Ожидается в версии 2.2 в 2022.3) | Да | Да | Да | N/A | N/A | N/A | |
| Metric Types | Inner Product Cosine similarity Euclidean (L2) | L2 Inner Product Hamming Jaccard Tanimoto Superstructure Substructure | Cosine | Euclidean Угловое внутреннее произведение Geo degrees Hamming | L1 L2 Angle Hamming Cosine Normailized Angle Normalized Cosine Jaccard | Euclidean Cosine Inner Product | |||
| Max vector dim | N/A | N/A | 32 768 | N/A | max.MaxInt64 | N/A | |||
| Max index size | N/A | N/A | Unlimited | N/A | N/A | N/A | N/A | N/A | |
| Типы индексов | HNSW | ANNOY HNSW IVF_PQ IVF_SQ8 IVF_FLAT FLAT IVF_SQ8_H RNSG | NHSW | HNSW BM25 | N/A | Proprietary | |||
| Model Serving | N/A | N/A | text2vec-contextionary Собственный векторизатор языка от Weaviate; модуль векторизации Weighted Mean of Word Embeddings (WMOWE), который работает с такими популярными моделями, как fastText и GloVe. Самая последняя модель text2vec - contextionary обучена с помощью fastText на данных Wiki и CommonCrawl. text2vec- transformers Модели Transfomer отличаются от Contextionary тем, что позволяют подключить предварительно обученный модуль NLP, специфичный для вашего случая использования. |
После тщательного анализа для углубленного бенчмаркинга были выбраны две VSE - Milvus и Weaviate. Эти платформы полностью соответствовали жестким требованиям к надежности, эффективности и масштабируемости. На окончательный выбор также повлияли дорожные карты платформ, поскольку компании требовалось решение, которое будет постоянно развиваться и адаптироваться к ее растущим потребностям.
Экспериментальная установка
Для обеспечения справедливой и всесторонней оценки использовались стандартные аппаратные и программные средства.
- Аппаратное обеспечение: процессор Intel Xeon E5-2690 v4, 112 ГБ оперативной памяти, 1024 ГБ жесткого диска
- Программное обеспечение: Linux 16.04-LTS, Anaconda 4.8.3 с Python 3.8.12.
- Набор данных: Команда Farfetch использовала публичный набор данных с сайта startups-list.com, состоящий из 40 474 записей. Набор данных включал предварительно вычисленные вкрапления для описаний компаний.
Сценарии и алгоритм индексации
Они разработали несколько тестовых сценариев, чтобы оценить производительность этих VSE в различных условиях. В этих сценариях варьировалось количество записей и количество кодировок для каждой сущности. Для индексации использовался алгоритм Hierarchical Navigable Small World (HNSW), известный своей эффективностью в высокоразмерных пространствах данных.
Окончательный список сценариев приведен ниже.
| Сценарий | Количество сущностей | Количество кодировок на одну сущность |
|---|---|---|
| Сценарий №1 (S1) | 1.000 | 1 |
| Сценарий №2 (S2) | 10.000 | 1 |
| Сценарий № 3 (S3) | 40.474 | 1 |
| Сценарий №4 (S4) | 1.000 | 2 |
| Сценарий №5 (S5) | 10.000 | 2 |
| Сценарий №6 (S6) | 40.474 | 2 |
| Сценарий №7 (S7) | 1.000 | 5 |
| Сценарий №8 (S8) | 10.000 | 5 |
| Сценарий №9 (S9) | 40.474 | 5 |
Анализ производительности
Индексирование
Weaviate: Позволяет явно объявлять параметры индекса при создании схемы класса. Однако он ограничивает именование классов, например, не позволяет использовать цифры или специальные символы.
Milvus: Предлагает более широкий спектр алгоритмов индексирования и типов метрик. Он также позволяет определять размеры индексных файлов, что позволяет оптимизировать пакетные операции.
Результат: Milvus получил преимущество по среднему времени индексирования во всех сценариях. Он был заметно быстрее в самом ресурсоемком сценарии, S9.
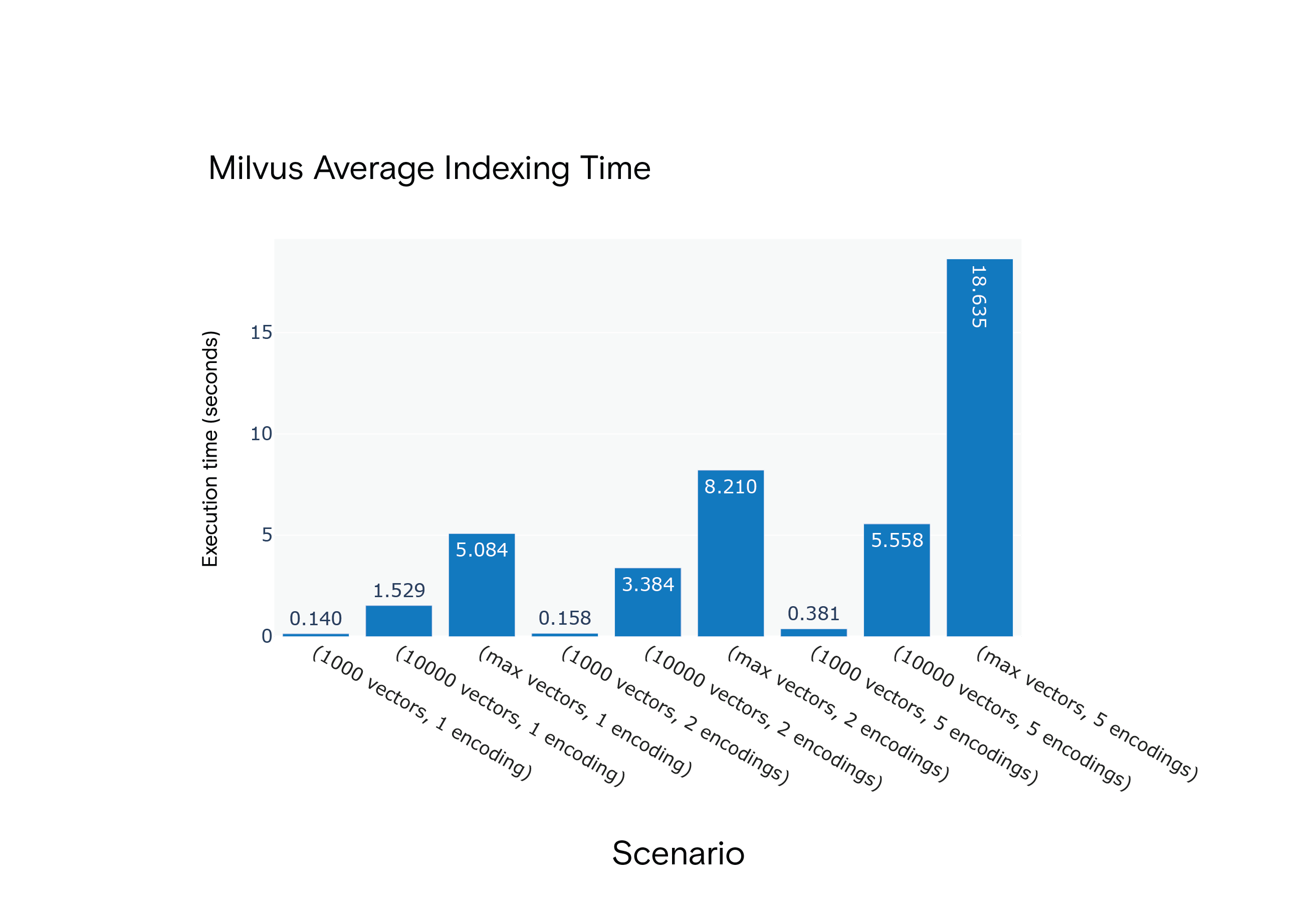 Среднее время индексирования Milvus 1.1.1 для сценариев с S1 по S9
Среднее время индексирования Milvus 1.1.1 для сценариев с S1 по S9
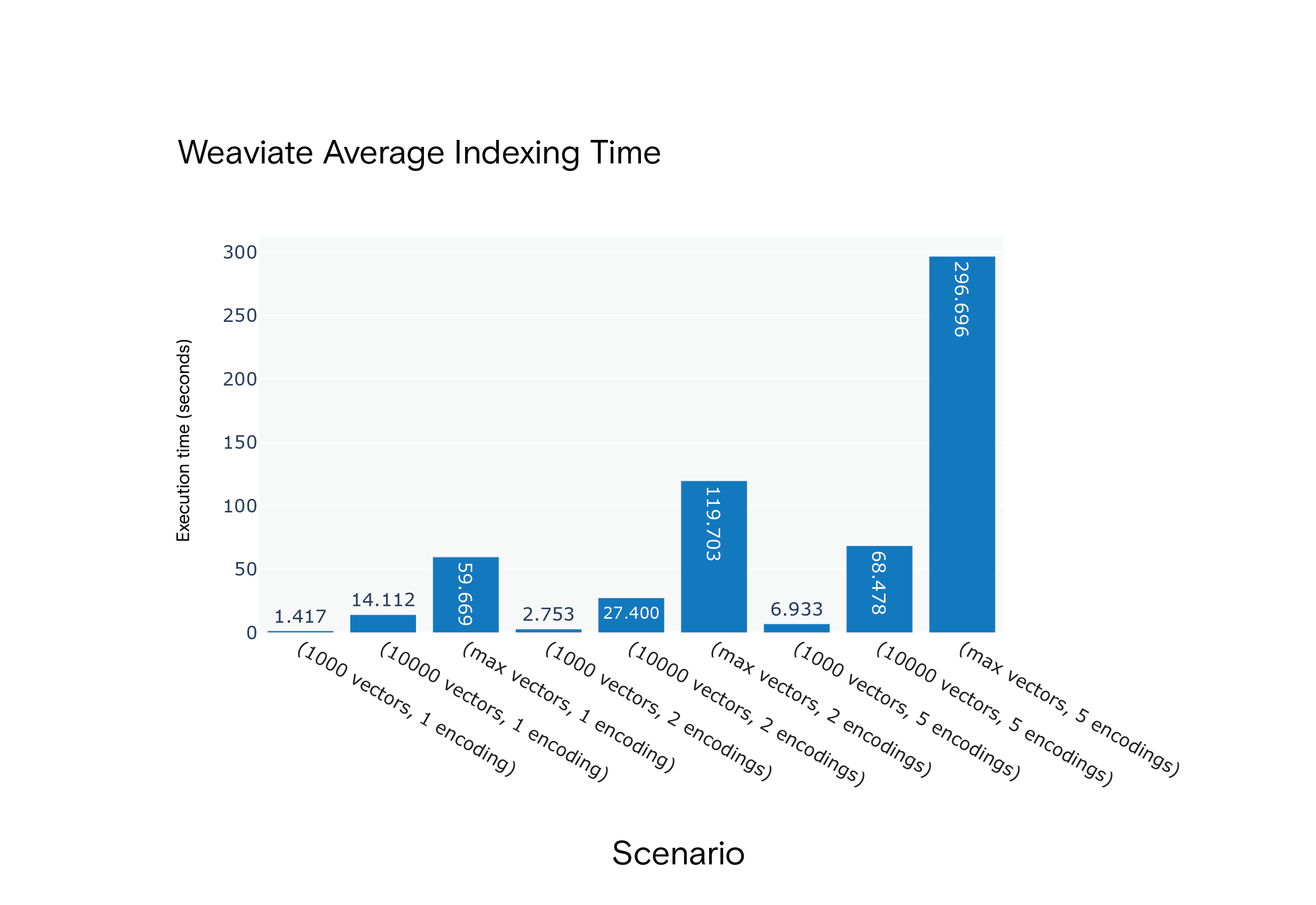 Среднее время индексирования Weaviate для сценариев с S1 по S9
Среднее время индексирования Weaviate для сценариев с S1 по S9
Запрос
Weaviate: Python-клиент поддерживает векторный поиск, но только для одного вектора за раз.
Milvus: Предлагает более гибкий метод поиска, который может работать со списком векторов, облегчая многовекторный запрос.
Результат: Milvus показал более низкое среднее время выполнения запросов во всех сценариях, хотя для достижения оптимальной производительности ему потребовалась фаза "разогрева".
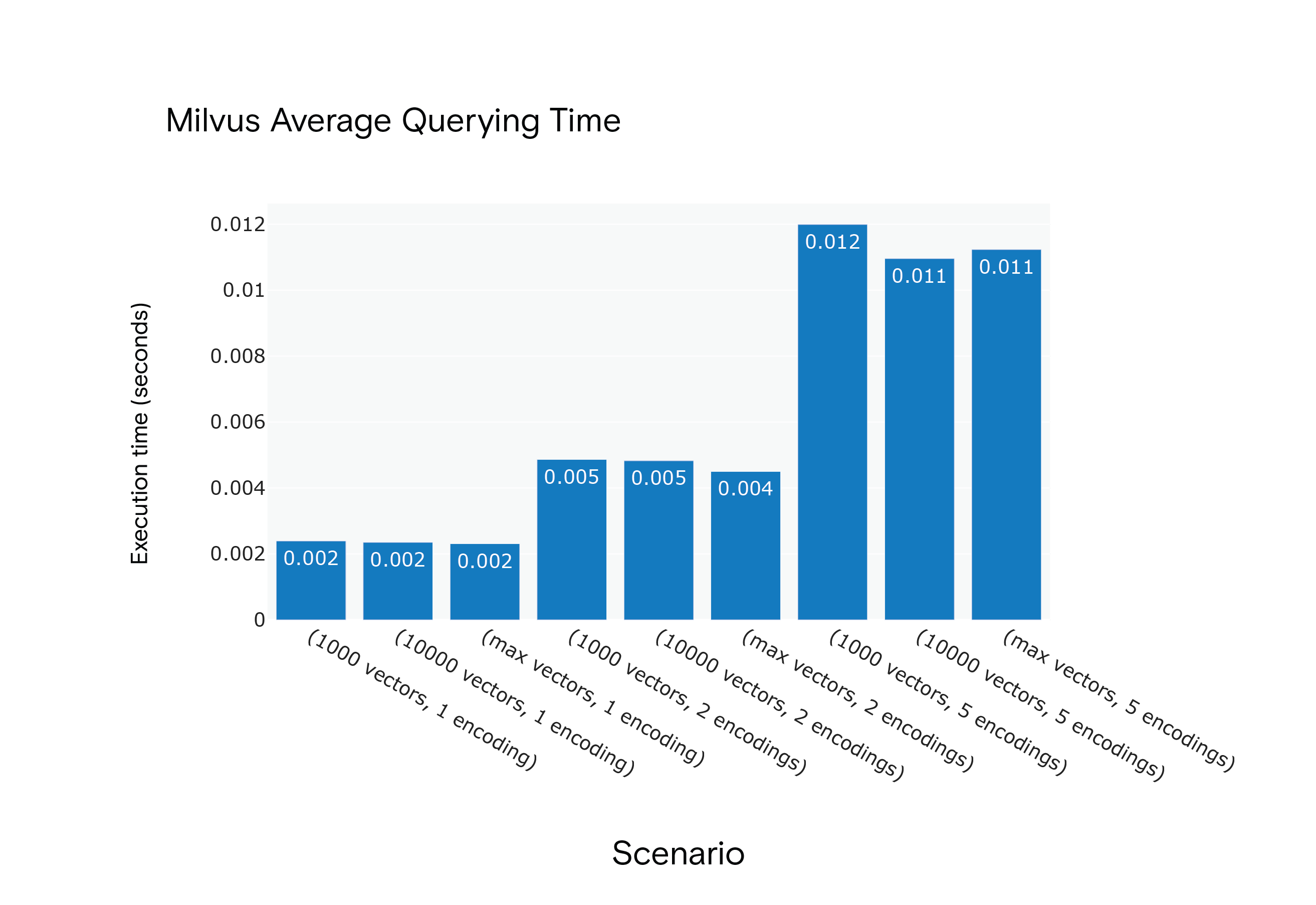 Среднее время выполнения запросов Milvus 1.1.1 для сценариев с S1 по S9
Среднее время выполнения запросов Milvus 1.1.1 для сценариев с S1 по S9
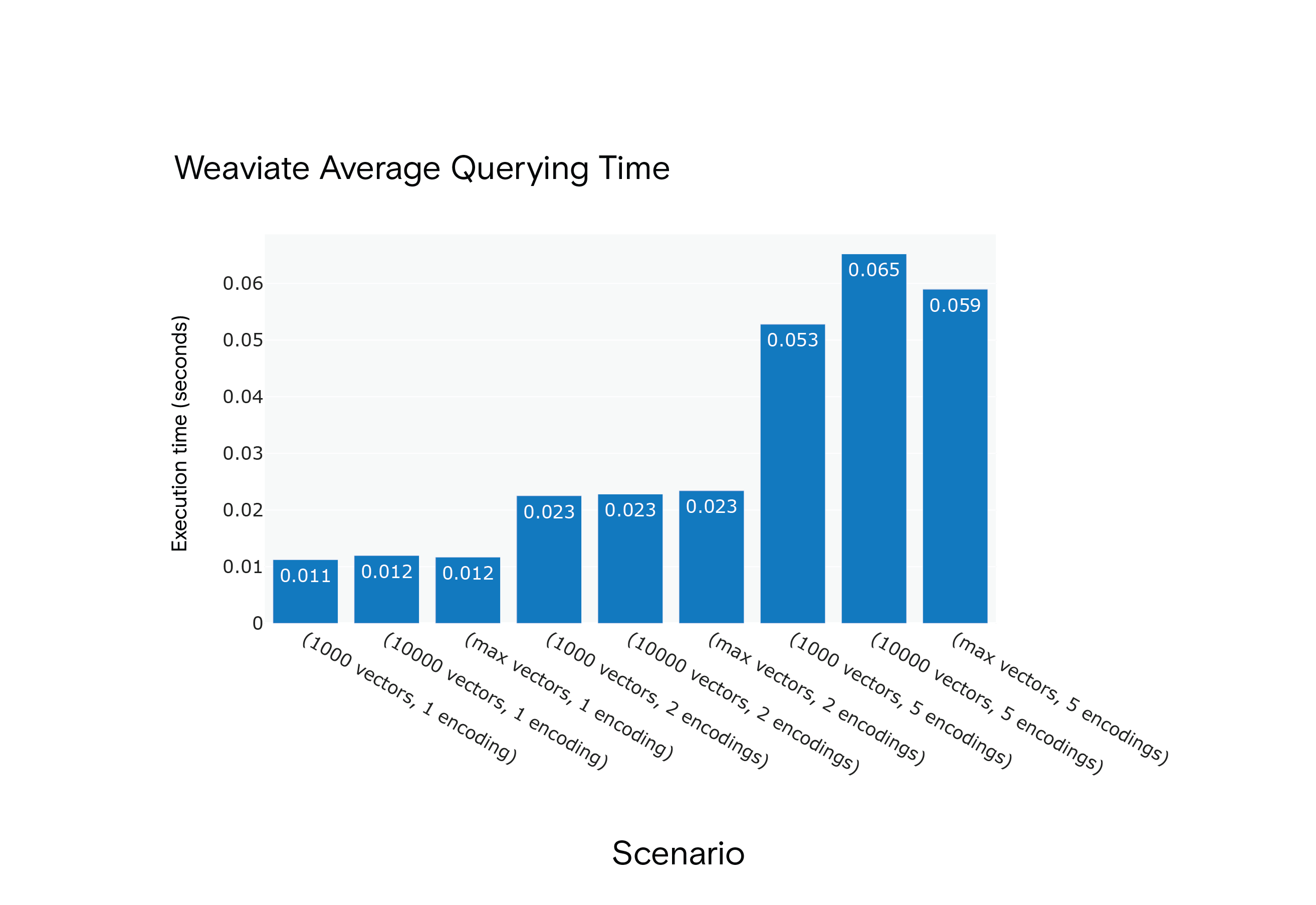 Weaviate Среднее время выполнения запросов для сценариев с S1 по S9
Weaviate Среднее время выполнения запросов для сценариев с S1 по S9
Команда Farfetch считает, что Milvus и Weaviate многообещающи, но все еще развиваются. Такие функции, как горизонтальное масштабирование, шардинг и поддержка GPU, находятся в дорожной карте. Для FARFETCH, которая планирует обрабатывать каталог продукции от 300 тыс. до 5 млн товаров, идеальная VSE должна предлагать:
- высококачественные и точные результаты
- Эффективные возможности индексирования
- Быстрое выполнение запросов
- Функции масштабируемости, такие как балансировка нагрузки и репликация данных
Эксперименты показали, что Milvus постоянно превосходит Weaviate по времени индексирования и выполнения запросов. Однако стоит отметить, что обе платформы имеют определенные ограничения, такие как отсутствие поддержки нескольких кодировок. В своей будущей работе они будут внимательно следить за развитием этих платформ и, возможно, переоценивать их по мере появления новых возможностей.
Это тематическое исследование является сокращенной версией подробного блога о бенчмаркинге векторных баз данных, первоначально опубликованного Педро МОРЕЙРА КОСТА (PEDRO MOREIRA COSTA) из Farfetch. Для более детального анализа и понимания ситуации, пожалуйста, обратитесь к оригинальным записям в блоге: POWERING AI WITH VECTOR DATABASES: A BENCHMARK - PART I и POWERING AI WITH VECTOR DATABASES: A BENCHMARK - PART II.
- О ФАРФЕТКЕ
- Важность векторных баз данных
- Критерии и выбор эталонов
- Экспериментальная установка
- Сценарии и алгоритм индексации
- Анализ производительности
Контент
Пример использования
Отрасль
Электронная коммерция