




Вызов функций с помощью Ollama, Llama 3.2 и Milvus
Обновлено 25 сентября 2024 года с версией Llama 3.2.
Вызов функций с помощью LLM - это все равно что дать вашему ИИ возможность общаться с миром. Интегрируя LLM с внешними инструментами, такими как пользовательские функции или API, вы можете создавать приложения, которые решают реальные проблемы.
В этой статье мы рассмотрим, как интегрировать Llama 3.2 с внешними инструментами, такими как Milvus и API, для создания мощных приложений, учитывающих контекст.
Введение в вызов функций
LLM, такие как GPT-4, Mistral Nemo и Llama 3.2, теперь могут определять, когда им нужно вызвать функцию, а затем выводить JSON с аргументами для вызова этой функции. Это делает ваши приложения искусственного интеллекта более универсальными и мощными.
Функциональные вызовы позволяют разработчикам создавать:
Решения на базе LLM для извлечения и маркировки данных (например, извлечение имен людей из статьи Википедии)
приложения, позволяющие преобразовывать естественный язык в вызовы API или корректные запросы к базам данных
разговорные системы поиска знаний, которые взаимодействуют с базой знаний
Инструменты
Ollama: Переносит мощь LLM на ваш ноутбук, упрощая локальную работу.
Milvus: Наша лучшая векторная база данных для эффективного хранения и поиска данных.
Llama 3.2-3B: Усовершенствованная версия модели 3.1, многоязычная, со значительно большей длиной контекста (128 К) и возможностью использования инструментов.
Использование Llama 3.2 и Ollama
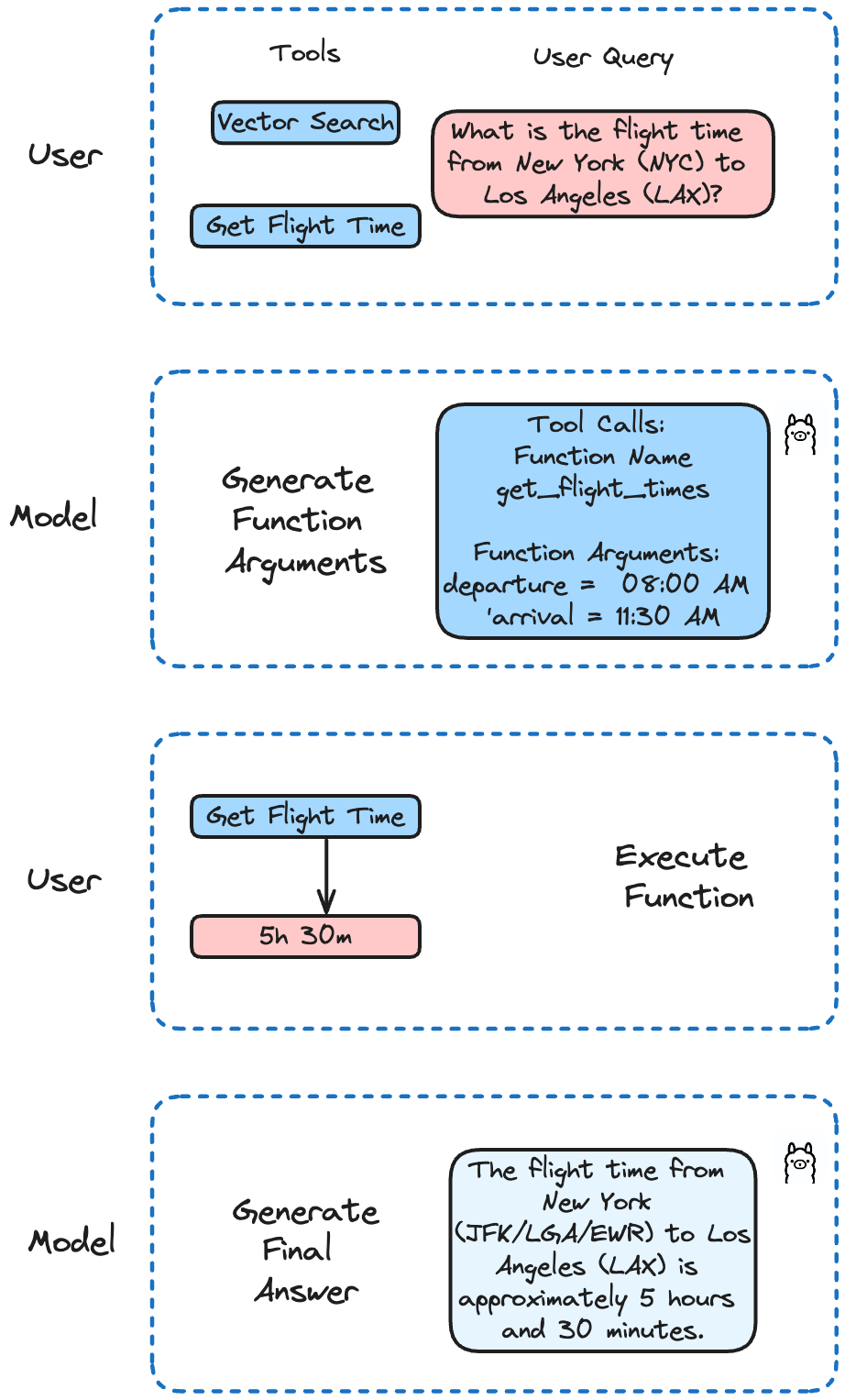
В Llama 3.2 была произведена тонкая настройка вызова функций. Она поддерживает одиночный, вложенный и параллельный вызов функций, а также многооборотный вызов функций. Это означает, что ваш ИИ сможет решать сложные задачи, включающие несколько шагов или параллельных процессов.
В нашем примере мы реализуем различные функции, чтобы смоделировать вызов API для получения информации о времени рейсов и выполнения поиска в Milvus. Llama 3.2 будет решать, какую функцию вызвать, исходя из запроса пользователя.
Установка зависимостей
Сначала давайте все установим. Загрузите Llama 3.2 с помощью Ollama:
ollama run llama3.2
Это загрузит модель на ваш ноутбук и сделает ее готовой к использованию с Ollama. Далее установите необходимые зависимости:
! pip install ollama openai "pymilvus[model]"
Мы устанавливаем Milvus Lite с расширением model, которое позволяет внедрять данные с помощью моделей, доступных в Milvus.
Вставка данных в Milvus
Теперь давайте вставим некоторые данные в Milvus. Это данные, которые Llama 3.2 решит поискать позже, если сочтет их нужными!
Создание и вставка данных
из pymilvus import MilvusClient, model
embedding_fn = model.DefaultEmbeddingFunction()
docs = [
"Искусственный интеллект был основан как академическая дисциплина в 1956 году",
"Алан Тьюринг был первым человеком, который провел серьезные исследования в области искусственного интеллекта",
"Тьюринг родился в Майда-Вейл, Лондон, и вырос на юге Англии",
]
vectors = embedding_fn.encode_documents(docs)
# Выходной вектор имеет 768 измерений, что соответствует коллекции, которую мы только что создали.
print("Dim:", embedding_fn.dim, vectors[0].shape) # Dim: 768 (768,)
# У каждой сущности есть идентификатор, векторное представление, необработанный текст и метка субъекта.
data = [
{ "id": i, "vector": vectors[i], "text": docs[i], "subject": "история"}
for i in range(len(vectors))
]
print("В данных есть", len(data), "сущности, каждая из которых имеет поля: ", data[0].keys())
print("Вектор dim:", len(data[0]["vector"]))
# Создайте коллекцию и вставьте данные
client = MilvusClient('./milvus_local.db')
client.create_collection(
collection_name="demo_collection",
dimension=768, # Векторы, которые мы будем использовать в этой демонстрации, имеют 768 измерений
)
client.insert(collection_name="demo_collection", data=data)
В новой коллекции должно быть 3 элемента.
Определите функции, которые будут использоваться
В этом примере мы определяем две функции. Первая имитирует вызов API для получения информации о времени рейсов. Вторая запускает поисковый запрос в Milvus.
from pymilvus import model
импорт json
import ollama
embedding_fn = model.DefaultEmbeddingFunction()
# Имитирует вызов API для получения данных о времени полетов.
# В реальном приложении это будет получение данных из живой базы данных или API
def get_flight_times(departure: str, arrival: str) -> str:
рейсы = {
'NYC-LAX': { 'отправление': '08:00 AM', 'прибытие': '11:30 AM', 'продолжительность': '5h 30m'},
'LAX-NYC': {'отправление':'02:00 PM','прибытие':'10:30 PM','продолжительность':'5ч 30м'},
'LHR-JFK': {'отправление':'10:00 AM','прибытие':'01:00 PM','продолжительность':'8ч 00м'},
'JFK-LHR': {'отправление':'09:00 PM','прибытие':'09:00 AM','продолжительность':'7ч 00м'},
'CDG-DXB': {'отправление':'11:00 AM','прибытие':'08:00 PM','продолжительность':'6h 00m'},
'DXB-CDG': { 'отправление': '03:00 AM', 'прибытие': '07:30 AM', 'продолжительность': '7ч 30м'}
}
key = f'{departure}-{arrival}'.upper()
return json.dumps(flights.get(key, {'error': 'Flight not found'}))
# Поиск данных, связанных с искусственным интеллектом, в векторной базе данных
def search_data_in_vector_db(query: str) -> str:
query_vectors = embedding_fn.encode_queries([query])
res = client.search(
имя_коллекции="демо_коллекция",
data=query_vectors,
limit=2,
output_fields=["text", "subject"], # задает поля, которые будут возвращены
)
print(res)
return json.dumps(res)
Дайте инструкции LLM, чтобы он мог использовать эти функции
Теперь давайте дадим инструкции LLM, чтобы он мог использовать функции, которые мы определили.
def run(model: str, question: str):
client = ollama.Client()
# Инициализация беседы с пользовательским запросом
messages = [{"role": "user", "content": question}]
# Первый вызов API: Отправляем запрос и описание функции в модель
response = client.chat(
model=model,
messages=messages,
инструменты=[
{
"type": "function",
"function": {
"name": "get_flight_times",
"description": "Получить время перелета между двумя городами",
"parameters": {
"type": "object",
"properties": {
"departure": {
"type": "string",
"description": "Город отправления (код аэропорта)",
},
"arrival": {
"type": "string",
"description": "Город прибытия (код аэропорта)",
},
},
"required": ["отправление", "прибытие"],
},
},
},
{
"type": "function",
"function": {
"name": "search_data_in_vector_db",
"description": "Поиск данных об искусственном интеллекте в векторной базе данных",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Поисковый запрос",
},
},
"required": ["query"],
},
},
},
],
)
# Добавьте ответ модели в историю беседы
messages.append(response["message"])
# Проверьте, решила ли модель использовать предоставленную функцию
if not response["message"].get("tool_calls"):
print("Модель не использовала функцию. Ее ответ был:")
print(response["message"]["content"])
return
# Обработка вызовов функций, выполненных моделью
if response["message"].get("tool_calls"):
available_functions = {
"get_flight_times": get_flight_times,
"search_data_in_vector_db": search_data_in_vector_db,
}
for tool in response["message"]["tool_calls"]:
function_to_call = available_functions[tool["function"]["name"]]
function_args = tool["function"]["arguments"]
function_response = function_to_call(**function_args)
# Добавьте ответ функции в разговор
messages.append(
{
"role": "tool",
"content": function_response,
}
)
# Второй вызов API: Получение окончательного ответа от модели
final_response = client.chat(model=model, messages=messages)
print(final_response["message"]["content"])
Пример использования
Давайте проверим, можем ли мы получить время для конкретного рейса:
question = "Каково время полета из Нью-Йорка (NYC) в Лос-Анджелес (LAX)?"
run('llama3.2', question)
В результате получаем:
Время перелета из Нью-Йорка (JFK/LGA/EWR) в Лос-Анджелес (LAX) составляет примерно 5 часов 30 минут. Однако обратите внимание, что это время может меняться в зависимости от авиакомпании, расписания рейсов и возможных пересадок или задержек. Всегда лучше уточнять самую свежую и точную информацию о рейсе у своей авиакомпании.
Теперь давайте посмотрим, умеет ли Llama 3.2 выполнять векторный поиск с помощью Milvus.
вопрос = "Когда был основан искусственный интеллект?"
run("llama3.2", question)
Что возвращает поиск Milvus:
данные: ["[{'id': 0, 'distance': 0.5738513469696045, 'entity': {'text': 'Искусственный интеллект был основан как академическая дисциплина в 1956 г.', 'subject': 'history'}}, {'id': 1, 'distance': 0.4090226888656616, 'entity': {'text':'Алан Тьюринг был первым человеком, который провел значительные исследования в области искусственного интеллекта.', 'subject':'history'}}]"].
Искусственный интеллект был основан как академическая дисциплина в 1956 году.
Заключение
Вызов функций с помощью LLM открывает мир возможностей. Интегрируя Llama 3.2 с внешними инструментами, такими как Milvus и API, вы можете создавать мощные, контекстно-ориентированные приложения, ориентированные на конкретные случаи использования и практические проблемы.
Не стесняйтесь знакомиться с Milvus, кодом на Github и делиться своим опытом с сообществом, присоединившись к нашему Discord.

Читать далее

Migrating Self-Managed Milvus to Zilliz Cloud for >99% Latency Reduction
Step-by-step guide to migrating 50M vectors from self-managed Milvus to Zilliz Cloud using milvus-backup. Achieve >99% query latency reduction with zero data loss.

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.