




Como a Inkeep e a Milvus criaram um assistente de IA baseado em RAG para uma interação mais inteligente
Enquanto programadores, a pesquisa na documentação técnica de várias plataformas ou serviços pode ser entediante. A documentação técnica típica contém inúmeras secções e hierarquias que podem ser confusas ou difíceis de navegar. Consequentemente, é frequente perdermos muito tempo à procura das respostas de que necessitamos. Adicionar um assistente de IA à documentação técnica pode ser uma poupança de tempo para muitos programadores, uma vez que podemos simplesmente perguntar à IA sobre as nossas questões, e ela fornecerá respostas ou redirecionar-nos-á para as páginas e artigos relevantes.
Num recente Unstructured Data Meetup organizado pela Zilliz, Robert Tran, o cofundador e CTO da Inkeep, discutiu como a Inkeep e a Zilliz criaram um assistente com IA para o seu site de documentação. Podemos agora ver este assistente de IA em ação nos sites de documentação Zilliz e Milvus.
Neste artigo, vamos explorar os pormenores técnicos apresentados por Robert Tran. Assim, sem mais demoras, comecemos pela motivação subjacente à integração de um assistente de IA nas páginas de documentação técnica.
A motivação por trás do assistente de IA na documentação técnica
A documentação técnica é uma fonte essencial de informação que todas as plataformas devem fornecer para ajudar os seus utilizadores ou programadores. Deve ser intuitiva, abrangente e útil para orientar os programadores de todos os níveis de experiência na utilização das caraterísticas e funcionalidades disponíveis nas plataformas.
No entanto, à medida que as plataformas introduzem inúmeras novas funcionalidades, a sua documentação técnica pode tornar-se demasiado complexa. Esta complexidade pode confundir muitos programadores ao navegarem na documentação técnica de uma plataforma. Os programadores são frequentemente pressionados a apresentar resultados rapidamente e o tempo gasto na procura de informações na documentação técnica pode distraí-los do trabalho real de codificação e desenvolvimento.
Muitas plataformas oferecem funcionalidades básicas de pesquisa na sua documentação técnica para ajudar os programadores a encontrar rapidamente o conteúdo de que necessitam, à semelhança da forma como pesquisamos no Google (https://zilliz.com/learn/evolution-of-search-from-traditional-keyword-matching-to-vetor-search-and-genai). Os utilizadores podem digitar palavras-chave e a plataforma fornecerá uma lista de páginas potencialmente relevantes para responder às suas perguntas. No entanto, estas funções básicas de pesquisa muitas vezes não compreendem o contexto da consulta do utilizador, o que leva a resultados de pesquisa irrelevantes ou incompletos.
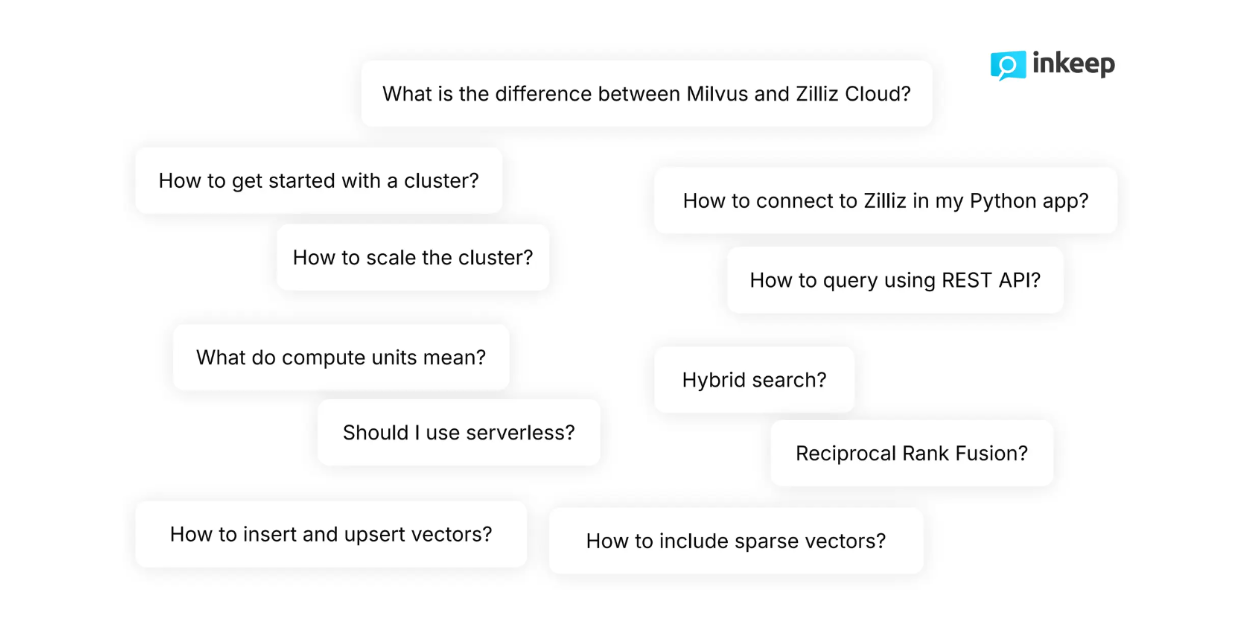 Figura - Perguntas típicas feitas pelos programadores sobre Milvus .png
Figura - Perguntas típicas feitas pelos programadores sobre Milvus .png
Figura: Perguntas típicas feitas pelos programadores sobre o Milvus
Como programadores, sabemos que as nossas perguntas são frequentemente mais matizadas e por vezes demasiado complexas para as funcionalidades básicas de pesquisa. Por exemplo, ao navegar na documentação técnica do Zilliz, os programadores fazem normalmente perguntas altamente técnicas como "Como incluir vectores esparsos juntamente com vectores densos durante o processo de recuperação?" ou "Como escalar o cluster dinamicamente?" As funcionalidades básicas de pesquisa muitas vezes não respondem satisfatoriamente a perguntas tão complexas e matizadas.
A adição de um assistente de IA resolve estes problemas. Um assistente de IA pode compreender a intenção dos programadores e o significado semântico das suas consultas, permitindo que os programadores obtenham as informações de que necessitam em segundos. Os programadores podem simplesmente escrever a sua consulta e o assistente de IA dá-lhes uma resposta ou redirecciona-os para a página relevante exacta, em vez de terem de procurar em muitos conteúdos, o que é aborrecido e demorado.
Além disso, os assistentes de IA são normalmente alimentados pelos mais recentes avanços no domínio do processamento da linguagem natural (PNL), como os modelos de linguagem de grande dimensão (LLMs, pesquisa vetorial e geração aumentada de recuperação (RAG). De facto, a abordagem RAG está no cerne deste assistente de IA, permitindo-lhe compreender as nuances por detrás das perguntas dos utilizadores e devolver respostas precisas e relevantes em segundos.
Na próxima secção, discutiremos os métodos subjacentes a um assistente de IA.
O conceito de Geração Aumentada de Recuperação (RAG)
A Retrieval Augmented Generation (RAG) é um método que combina técnicas avançadas de PNL, como a pesquisa vetorial e os LLMs, para gerar respostas precisas às perguntas dos utilizadores.
Figura - Fluxo de trabalho RAG.png](https://assets.zilliz.com/Figure_RAG_workflow_5bfbcccddf.png)
Figura: Fluxo de trabalho do RAG.
Em poucas palavras, o fluxo de trabalho de um método RAG é bastante simples. Primeiro, nós, enquanto utilizadores, fazemos uma pergunta. De seguida, o método RAG vai buscar documentos relevantes que possivelmente contêm a resposta à nossa pergunta. Depois, a nossa pergunta e os documentos relevantes são combinados num único pedido coerente antes de serem enviados para um LLM. Por fim, o LLM gera a resposta à nossa consulta utilizando os documentos relevantes fornecidos.
Como podemos ver, o conceito principal do RAG é fornecer a um LLM o contexto relevante para responder à nossa consulta. Esta abordagem tem, pelo menos, duas vantagens: em primeiro lugar, reduz o risco de o MLT [alucinação] (https://zilliz.com/glossary/ai-hallucination), ou seja, de gerar respostas inexactas e falsas. Em segundo lugar, a resposta gerada pelo LLM será mais contextualizada e adaptada à nossa pergunta. Isso é particularmente útil quando fazemos perguntas ao LLM sobre o conteúdo de documentos internos.
Há quatro etapas do RAG que precisamos considerar ao implementar o RAG: ingestão, indexação, recuperação e geração.
Ingestão: envolve a recolha e o pré-processamento dos dados. A informação relevante e os metadados de cada registo podem também ser recolhidos.
Indexação: envolve o processo de armazenamento de dados com um método de indexação optimizado para uma recuperação rápida. Nesta etapa, os dados pré-processados são transformados em embeddings vectoriais utilizando um modelo de embedding e depois armazenados numa base de dados vetorial como Milvus com algoritmos de indexação avançados como FLAT, FAISS, ou HNSW.
Recuperação: envolve operações de pesquisa vetorial para fazer corresponder a consulta dos utilizadores aos dados armazenados. Neste processo, a consulta do utilizador é primeiro transformada numa incorporação vetorial utilizando o mesmo modelo de incorporação utilizado para transformar os dados armazenados. Em seguida, é efectuada uma pesquisa de semelhanças entre a consulta do utilizador e os dados armazenados para encontrar as informações mais relevantes na base de dados vetorial.
Geração: envolve a utilização de um LLM para produzir a resposta final. Primeiro, a consulta do utilizador e o contexto mais relevante da etapa de recuperação são combinados num pedido. Em seguida, o LLM gera uma resposta à consulta do utilizador com base no contexto fornecido no prompt.
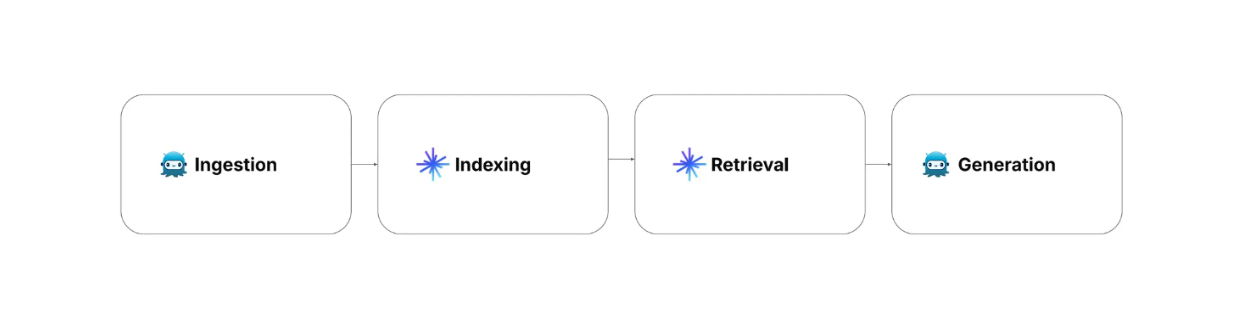 Figura- Etapas do RAG..png
Figura- Etapas do RAG..png
Figura: Etapas do RAG.
Há vários factores a ter em conta ao implementar cada uma das etapas acima mencionadas. Por exemplo, durante a fase de ingestão, é necessário refletir sobre a origem dos dados, a abordagem de limpeza dos dados e o método de fragmentação. Entretanto, durante a fase de indexação, temos de considerar o modelo de incorporação e a base de dados de vectores que queremos utilizar, bem como os algoritmos de indexação adequados ao nosso caso de utilização.
Na próxima secção, discutiremos as implementações detalhadas do RAG feitas pelo Inkeep e pelo Zilliz para criar um assistente de IA para as páginas de documentação do Zilliz e do Milvus.
Métodos usados por Inkeep e Zilliz para construir um assistente de IA
Para construir um assistente de IA, o Inkeep e o Zilliz usam uma combinação de diferentes técnicas para a implementação do RAG. A Inkeep trata das partes de ingestão e geração, enquanto a Zilliz fornece apoio à Inkeep nas etapas de indexação e recuperação.
Como mencionado na secção anterior, a primeira etapa da implementação do RAG é a etapa de ingestão. Neste passo, o Inkeep recolhe dados textuais relacionados com o Zilliz e o Milvus de várias fontes, tais como documentação, suporte e FAQs, e repositórios GitHub. Estes dados textuais são depois limpos e divididos em pedaços para garantir que cada pedaço de informação não é nem demasiado amplo nem demasiado granular.
Os metadados de cada registo fragmentado são também recolhidos antes de passar à etapa seguinte. Estes metadados incluem:
Tipo de fonte: se os dados são retirados de um repositório GitHub, documentação técnica, página de suporte e FAQ, etc.
Tipo de registo: como a versão dos dados, se é texto ou código. Se for código, a linguagem de programação também é registada.
Referências hierárquicas: incluindo os filhos, pais e irmãos de cada ponto de dados. Isto é importante, uma vez que os dados são recolhidos dos sítios Web da Zilliz.
URLs, etiquetas, caminhos: tais como os URLs de onde os dados são retirados. Estes metadados são muito úteis para fornecer ligações a citações ou fontes na resposta gerada pelo LLM.
Datas: como a data de publicação de cada dado.
Depois de a Inkeep ter recolhido os dados e os seus metadados, o passo seguinte é o método de indexação.
No método de indexação, os dados pré-processados têm de ser transformados em vectores incorporados para permitir a pesquisa de semelhanças na etapa de recuperação. Para transformar cada ponto de dados numa incorporação vetorial, Inkeep e Zilliz utilizam três métodos de incorporação diferentes: um modelo de incorporação esparso tradicional, um modelo de incorporação esparso baseado na aprendizagem profunda e um modelo de incorporação denso.
 Figura- Embeddings esparsos e densos..png
Figura- Embeddings esparsos e densos..png
Figura: Embeddings esparsos e densos.
[A incorporação esparsa (Sparse embedding) (https://zilliz.com/learn/sparse-and-dense-embeddings) é particularmente útil para processos de correspondência simples, baseados em palavras-chave e [booleanos] (https://zilliz.com/learn/understanding-boolean-retrieval-models-in-information-retrieval). Assim, os documentos relevantes obtidos a partir de uma incorporação esparsa contêm normalmente as palavras-chave da sua consulta. Entretanto, dense embedding é mais útil para captar a nuance ou o significado semântico da sua consulta. Os documentos obtidos a partir da incorporação densa podem ou não conter as palavras-chave da sua consulta, mas o conteúdo será altamente relevante para a mesma.
Existem dois tipos diferentes de modelos que podem ser utilizados para transformar dados em incorporação esparsa: modelos tradicionais/estatísticos e modelos baseados em aprendizagem profunda. Para o assistente de IA, Inkeep e Zilliz utilizam BM25 como modelo de base tradicional e SPLADE/BGE-M3 como modelo de base de aprendizagem profunda.
Para transformar os dados numa incorporação densa, existem muitos modelos de aprendizagem profunda à escolha, como os modelos de incorporação de OpenAI, Sentence-Transformers, VoyageAI, etc. Para o assistente de IA, Inkeep e Zilliz utilizam três modelos de incorporação diferentes: MS-MARCO, MPNET e BGE-M3.
Depois de todos os dados serem transformados nas suas representações esparsas e densas de incorporação, as incrustações são armazenadas numa base de dados vetorial para permitir uma recuperação rápida. Para construir o assistente de IA, Inkeep e Zilliz utilizam o Milvus como base de dados vetorial. A questão que se coloca agora é a seguinte: porque é que precisamos de utilizar uma combinação de incrustações esparsas e densas quando a escolha de uma delas pode ser suficiente?
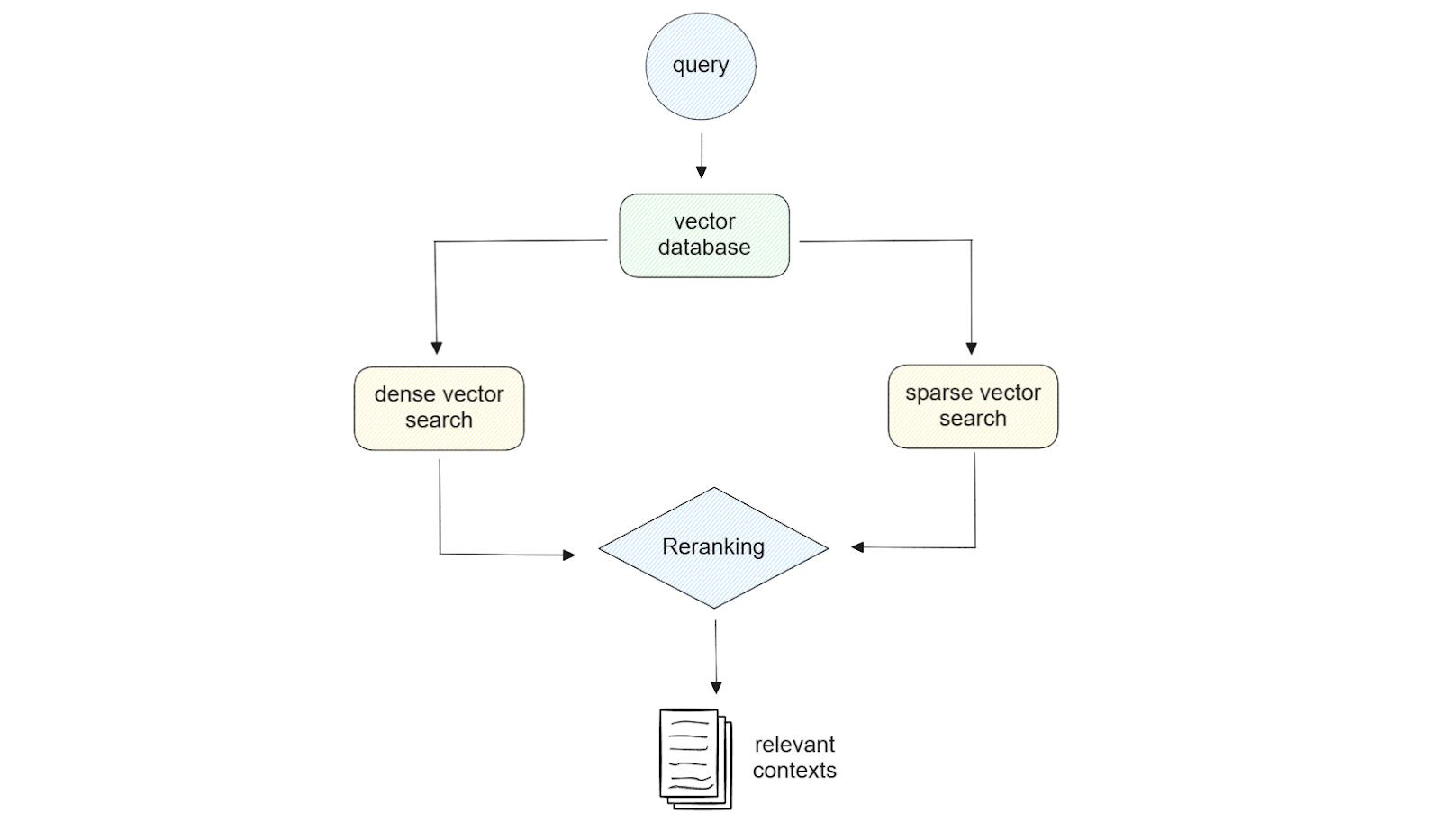 Figura - Ilustração da pesquisa híbrida..png
Figura - Ilustração da pesquisa híbrida..png
_Figura: Ilustração da pesquisa híbrida.
A utilização tanto da incorporação esparsa como da incorporação densa proporciona flexibilidade na etapa de recuperação. Por exemplo, se a nossa consulta for curta (menos de 5 palavras), a utilização da incorporação esparsa pode ser suficiente. Entretanto, se a nossa consulta for longa, a utilização da incorporação densa dar-nos-á, na maioria dos casos, uma melhor qualidade de resultados. Além disso, se utilizarmos Milvus como base de dados vetorial, podemos tirar partido do poder da pesquisa híbrida, ou seja, a pesquisa por semelhança utilizando uma combinação de incorporação esparsa e densa. Também podemos efetuar uma pesquisa de semelhanças com incorporação densa ou esparsa com filtragem de metadados, se desejado.
Ao implementar a pesquisa híbrida para encontrar o conteúdo mais relevante para a nossa consulta, também precisamos de considerar o método de reranking. Isto porque obteremos resultados de semelhança de dois métodos diferentes e precisamos de uma abordagem para combinar estes resultados. Para o fazer, Inkeep e Zilliz implementaram dois métodos diferentes de classificação: pontuação ponderada e fusão de classificação recíproca (RRF).
O conceito por detrás da pontuação ponderada é simples: atribuímos um peso a cada método. Por exemplo, podemos atribuir 60% de peso ao resultado da similaridade da incorporação densa e 40% da incorporação esparsa. Entretanto, na RRF, as pontuações dos contextos são calculadas através da soma das suas classificações recíprocas em dois métodos diferentes, muitas vezes com uma pequena constante adicional k para evitar a divisão por zero.
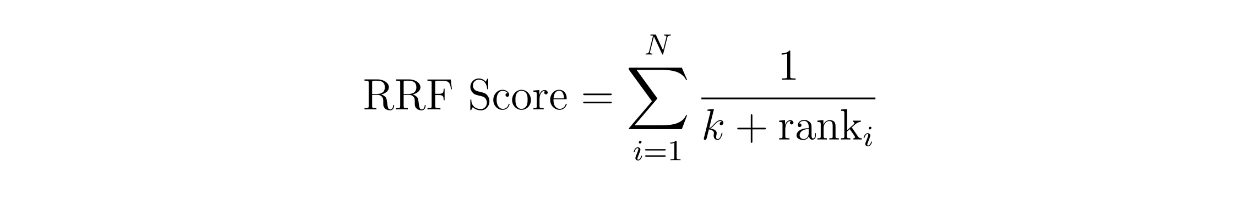 function rrf score.png
function rrf score.png
onde N é o número de métodos, que deve ser dois, uma vez que estamos a implementar uma pesquisa híbrida entre uma incorporação esparsa e uma incorporação densa. A variável 'rank' é a classificação de um contexto no método i, e k é uma constante.
Utilizando a equação RRF acima, podemos calcular a pontuação RRF para cada contexto. O contexto com a pontuação RRF mais elevada será selecionado como o contexto mais relevante para uma consulta.
Uma vez obtido o contexto relevante, a consulta original e o contexto mais relevante são combinados num pedido coerente. Esta mensagem é então enviada para um LLM para gerar a resposta final. Para o LLM, a Inkeep utiliza modelos da OpenAI e da Anthropic.
Demo do assistente de IA Milvus
Nesta secção, faremos uma breve introdução sobre como utilizar o assistente de IA criado pelo Inkeep e pelo Zilliz. Se quiser acompanhar, pode consultá-lo nas páginas de documentação do Zilliz ou do Milvus. Para esta demonstração, vamos utilizar o assistente de IA na página de documentação do Milvus.
Quando abrir a página de documentação do Milvus, verá o botão "Ask AI" (Perguntar à IA) no canto inferior direito do ecrã. Clique neste botão para aceder ao assistente de IA.
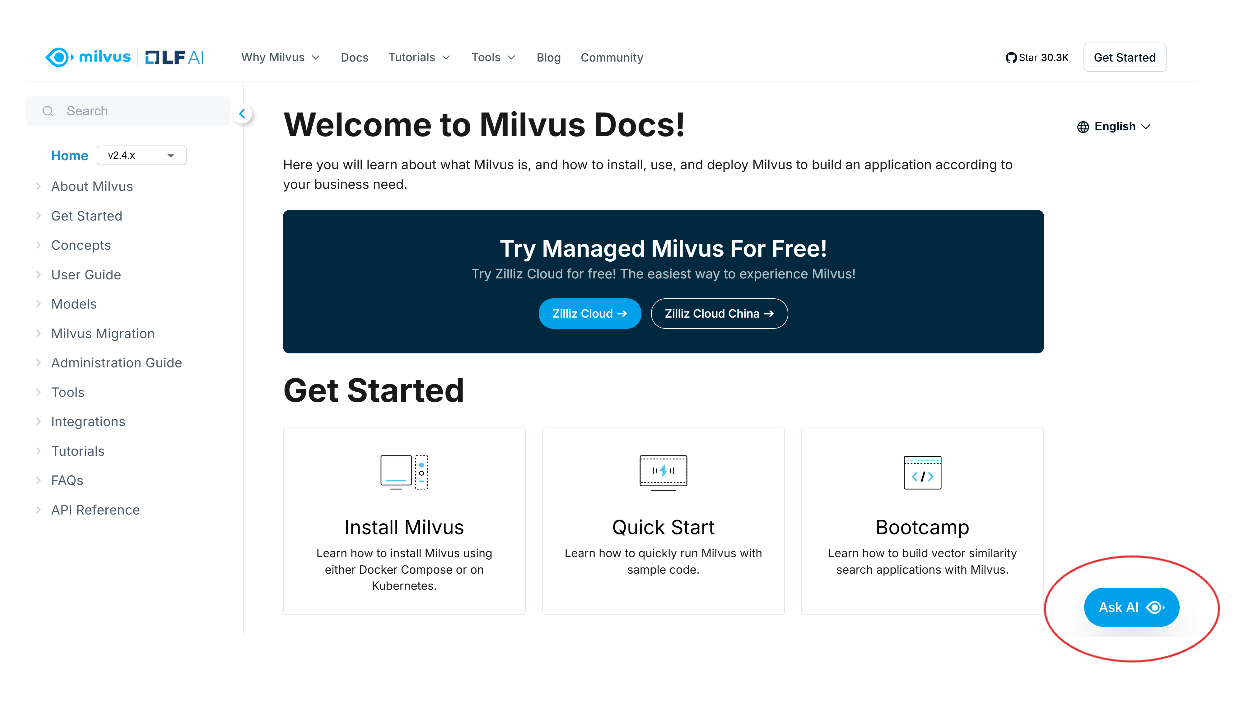 captura de ecrã 1.png
captura de ecrã 1.png
Em seguida, aparece um ecrã emergente que lhe pede para perguntar o que pretende encontrar na documentação do Milvus. Opcionalmente, pode também efetuar uma pesquisa básica, clicando na opção "Search" (Pesquisar) no canto superior direito do ecrã pop-up.
Imaginemos que queremos saber como transformar os nossos dados em embeddings vectoriais utilizando a BGE-M3 com o Milvus Python SDK. Podemos simplesmente escrever a nossa pergunta e o assistente de IA dar-nos-á uma resposta.
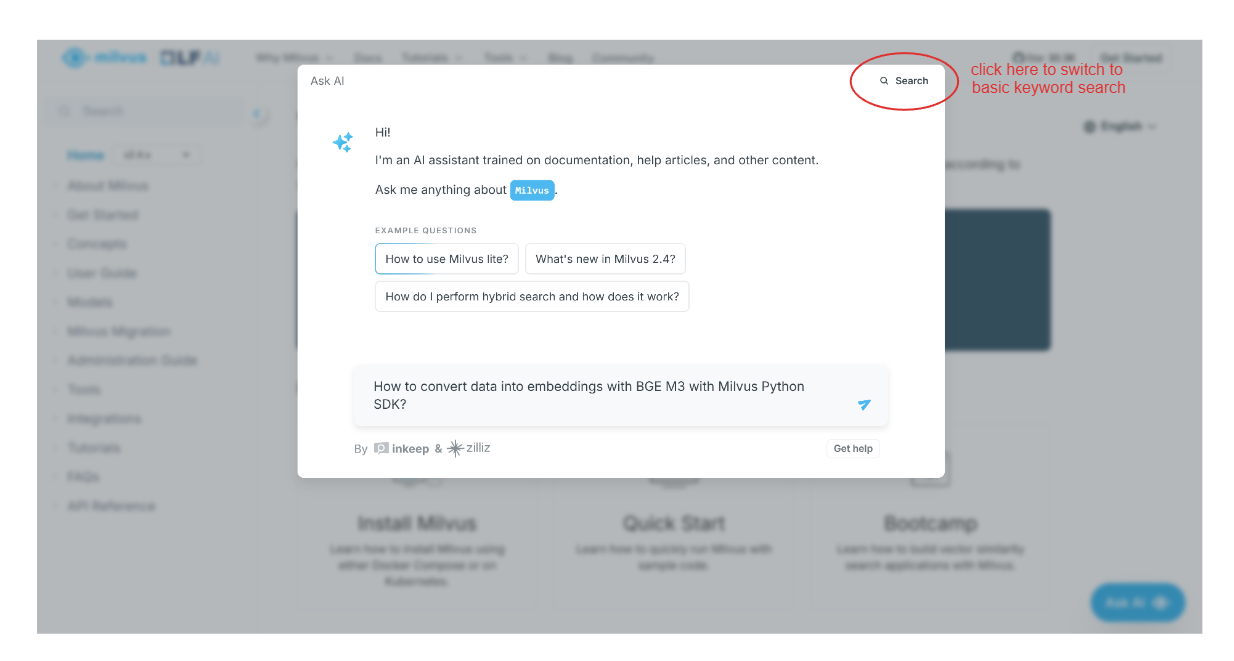 captura de ecrã 2.png
captura de ecrã 2.png
Para além de dar uma resposta, o assistente de IA também nos dá citações ou páginas relevantes onde podemos encontrar mais informações relacionadas com a resposta gerada.
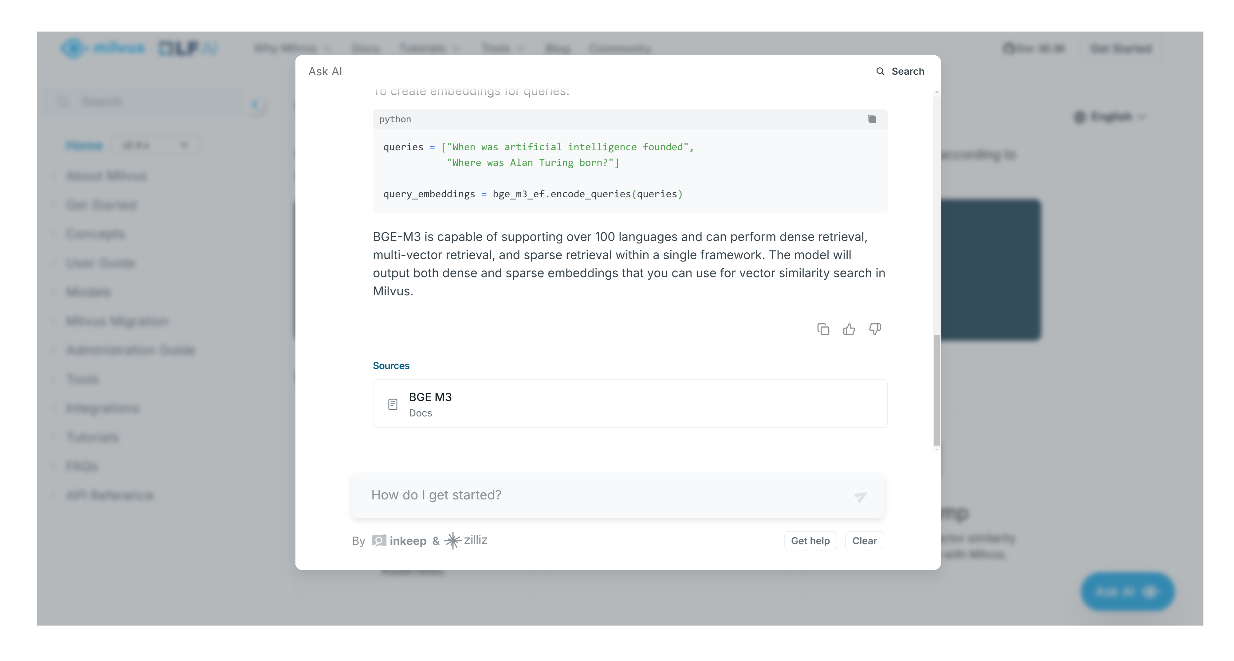 captura de ecrã 3.png
captura de ecrã 3.png
Conclusão
A integração de um assistente de IA na documentação técnica, construída pela Inkeep e pela Zilliz, demonstra como as soluções avançadas de IA podem melhorar a produtividade dos programadores e a experiência do utilizador. O RAG é o componente principal por trás desse assistente de IA, pois esse método ajuda o LLM a fornecer respostas mais precisas e contextualizadas para consultas complexas e com nuances.
O RAG consiste em quatro etapas principais: ingestão, indexação, recuperação e geração. As bases de dados vectoriais, como o Milvus, são um componente essencial do processo RAG, realizando as etapas de indexação e recuperação. Os métodos utilizados em cada passo têm de ser cuidadosamente considerados de acordo com o caso de utilização específico. Neste artigo, vimos também um exemplo de como a Inkeep e a Zilliz implementaram várias estratégias em cada passo das RAG para criar um assistente de IA sofisticado.
Para saber mais sobre como Milvus e Inkeep criaram este assistente de IA, veja a [repetição da palestra de Robert no YouTube] (https://youtu.be/35JdjmiDvWI?list=PLPg7_faNDlT7SC3HxWShxKT-t-u7uKr--&t=2879).
Leitura adicional
Modelos de IA com melhor desempenho para seus aplicativos GenAI | Zilliz](https://zilliz.com/ai-models)
Construir aplicações de IA com Milvus: tutoriais e cadernos de notas
Junte-se à comunidade Milvus de programadores de IA](https://zilliz.com/community)
Continue lendo

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

Data Deduplication at Trillion Scale: How to Solve the Biggest Bottleneck of LLM Training
Explore how MinHash LSH and Milvus handle data deduplication at the trillion-scale level, solving key bottlenecks in LLM training for improved AI model performance.

Zilliz Cloud Delivers Better Performance and Lower Costs with Arm Neoverse-based AWS Graviton
Zilliz Cloud adopts Arm-based AWS Graviton3 CPUs to cut costs, speed up AI vector search, and power billion-scale RAG and semantic search workloads.