




Zilliz Cloud 온디맨드 컴퓨팅: 사용한 만큼만 지불
지난 분기 저희는 자율주행 고객사와 함께 과금 사례를 검토했습니다. 해당 고객사의 분석 팀은 10억 행 컬렉션에 대한 벡터 검색이 필요했습니다. 이를 Dedicated cluster로 산정했을 때는 월 $7,000였습니다. Serverless도 시도해 보니 $10,800였습니다. 실제 분석 작업은 한 달에 몇 시간에 불과했습니다.
두 청구서는 모두 정확했습니다. 두 제품 모두 설계된 대로 정확히 동작하고 있었습니다. 문제는 이 고객의 워크로드 — 두 개의 다른 프로덕션 워크로드와 데이터셋을 공유하는 드문드문 발생하는 분석 작업 — 가 어느 제품의 설계 의도와도 맞지 않았다는 점이었습니다.
이 사례가 바로 저희가 Zilliz Cloud On-Demand Search를 만든 이유입니다 — Zilliz Vector Lakebase 출시와 함께 제공한 새로운 기능 중 하나입니다. 동일한 워크로드를 월 $500 미만으로 처리할 수 있습니다. 아래에서는 무엇이 맞지 않았는지, 무엇을 바꾸었는지, 어떤 경우에 On-Demand가 잘못된 도구인지, 그리고 마지막으로 이것이 Vector Lakebase에 어떻게 다시 연결되는지 설명합니다.
고객 사례
해당 컬렉션 — 약 10억 개 레코드 — 은 이미 두 개의 프로덕션 워크로드에서 사용 중이었습니다.
- 실시간 트래픽을 처리하는 온라인 검색 서비스.
- 회귀 작업을 위해 시나리오 데이터를 가져오는 모델 학습 파이프라인(별도 팀에서 운영).
분석은 동일한 데이터 위에 추가되는 세 번째 워크로드였습니다. 접근 패턴은 다음과 같았습니다. 분석가들은 특정 질문이 있을 때만, 현재 조사에 의해 주도되는 짧은 반복 작업으로 검색을 실행했습니다. 그 외 시간에는 클러스터에 분석 쿼리가 전혀 들어오지 않았습니다.
이는 꽤 일반적인 데이터 규모에서 꽤 흔한 Zilliz 사용 사례입니다. 어려웠던 점은 세 워크로드 모두 동일한 기본 컬렉션을 읽어야 했고, 각 워크로드의 실행 주기가 매우 달랐다는 것입니다.
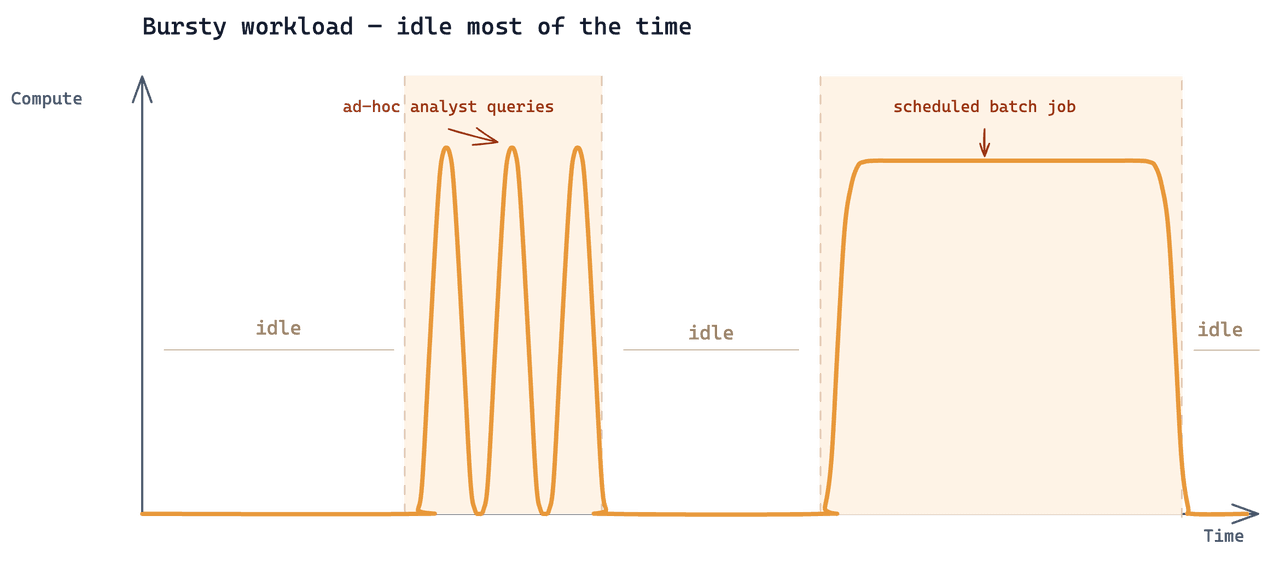
Dedicated Cluster가 맞지 않았던 이유
기존 설정은 24 CU의 Zilliz Cloud Tiered 클러스터였습니다. 여기에 분석 워크로드를 추가하면 월 약 $7,000의 비용이 들었습니다. 클러스터는 존재하는 모든 시간에 대해 과금됩니다: 24 × 30 = 월 720시간. 실제 분석 작업은 2–3시간을 소비했습니다. 나머지 717시간은 유휴 상태로 앉아 있는 데 과금되었습니다 — 전체 지출의 99.6%가 아무도 사용하지 않는 용량에 쓰인 것입니다.
유휴 시간을 피하기 위해 세션 사이에 Dedicated 클러스터를 중지할 수는 있습니다. 저희도 검토했습니다. 하지만 두 가지 이유로 작동하지 않습니다.
첫째, 이 규모의 데이터셋에서 분석용 콜드 쿼리를 처리할 때 Dedicated의 콜드 스타트는 10분 이상 걸립니다. Dedicated의 사고방식은 쿼리가 실행되기 전에 필요한 모든 데이터가 로컬 메모리에 있어야 한다는 것이므로, 전체 작업 집합을 미리 로드합니다 — 일반적으로 단일 콜드 쿼리가 실제로 접근하는 데이터의 수십 배에서 수백 배에 달합니다. 동일한 로드 과정에서는 DDL 및 삭제처럼 클러스터가 지원하는 비쿼리 작업을 위한 상태도 올려야 합니다. 이러한 오버헤드는 다음 쿼리에 필요하든 그렇지 않든 발생합니다.
둘째, 과금은 시간 단위로 올림 처리됩니다. 따라서 분석가가 클러스터가 워밍업될 때까지 10분 이상 기다릴 의향이 있더라도, 단일 쿼리에 대한 청구는 여전히 로드 시간을 포함해 한 시간입니다. 분석가들이 짧은 반복 작업으로 실행하는 경우, 시작/중지 규율을 아무리 철저히 지켜도 유용한 쿼리당 비용은 계속 높게 유지됩니다.
Serverless Cluster가 맞지 않았던 이유
Serverless는 저희가 다음으로 시도한 옵션이었습니다. 표면적으로는 이 접근 패턴에 맞는 형태입니다: 상태 없음, 쿼리당 과금, 유휴 컴퓨팅 없음. 분석 워크로드 자체만 놓고 보면 작동할 수도 있었습니다.
문제는 이 데이터셋에서 Serverless가 분석 워크로드만 분리해서 가격을 매기지 않는다는 점입니다. 컬렉션에 접근하는 모든 것에 대해 가격을 매깁니다. 기존 워크로드까지 포함하자 세 가지 항목이 계산을 깨뜨렸습니다:
- 쿼리: 월 약 $6,000. 대부분은 모델 트레이닝 팀의 격주 회귀 작업에서 발생했습니다 — 2주마다 3시간 동안 100 QPS. Serverless 단가는 쿼리가 이미 핫한 경우에도 모든 쿼리에 지불되는 콜드 쿼리 프리미엄을 포함합니다. 쿼리 볼륨이 아주 낮은 수준이 아니게 되면, 더 이상 계산이 맞지 않습니다.
- 스토리지: 월 $1,700. Serverless에는 스토리지를 포함시킬 컴퓨트 시간 요금이 없기 때문에 별도로 계량됩니다.
- 쓰기: 월 $3,000. 같은 이유입니다 — 포함시킬 컴퓨트 시간이 없습니다.
합계: 월 $10,784, 우리가 벗어나려 했던 Dedicated 클러스터보다 더 높았습니다.
이러한 프리미엄 각각에는 구조적인 이유가 있습니다.
쿼리에는 콜드 쿼리 프리미엄이 붙습니다. 사용자 입장에서 Serverless는 상태 비저장입니다. 플랫폼 입장에서는 실행을 위해 데이터가 여전히 특정 머신에 로드되어야 합니다. 쿼리는 핫(데이터가 이미 머신에 있음)과 콜드(먼저 오브젝트 스토리지에서 가져와야 함)로 나뉩니다. 핫 쿼리는 저렴하고, 콜드 쿼리는 비쌉니다. 플랫폼은 특정 사용자의 어떤 쿼리가 콜드일지 예측할 수 없기 때문에, 모든 쿼리 단가에 콜드 쿼리 비용을 분산시킵니다. 대부분이 핫 쿼리인 워크로드는 결국 다른 모든 사람의 콜드 쿼리 비용을 부담하게 됩니다.
스토리지는 한계 비용보다 높게 가격이 책정됩니다. Dedicated에서는 스토리지와 쓰기 비용이 컴퓨트 시간 요금에 보이지 않게 포함됩니다. Serverless에는 이러한 비용이 숨어들 컴퓨트 시간 요금이 없기 때문에, 스토리지가 명시적으로 과금됩니다. 그 명시적인 가격은 저장되어 있지만 전혀 쿼리되지 않는 데이터까지 커버해야 합니다 — 데이터는 언제든 쿼리 가능 상태로 유지되어야 하므로 플랫폼이 이를 딥 콜드 스토리지로 내릴 수 없습니다. 그 준비 상태를 유지하려면 추가 상태가 필요하고, 그 비용은 결국 스토리지 크기에 상각되지만, 스토리지 크기는 실제 소비와 정확히 대응하지 않습니다.
쓰기 또한 한계 비용보다 높게 가격이 책정됩니다. 쓰기는 별도로 계량되는데, 이는 사용자가 데이터셋을 늘리지 않으면서 많은 쓰기 비용을 발생시키는 고빈도 업데이트를 수행하지 못하게 하기 위해서입니다(그렇지 않으면 플랫폼이 그 비용을 떠안게 됩니다). 스토리지와 같은 동학입니다. 준비 상태의 비용이 쓰기당 단가에 반영됩니다.
더 근본적인 문제는 Serverless가 사용자에게서 "컴퓨트 리소스" 추상화를 숨긴다는 것입니다. 사용자는 상태 비저장 인터페이스를 봅니다. 플랫폼은 그 뒤에서 여전히 예측 불가능한 액세스 패턴 — 핫/콜드 데이터, 버스트성 트래픽, 쿼리 가능 상태로 유지되어야 하는 유휴 스토리지 — 에 대한 비용을 지불해야 합니다. 이러한 비용은 특정 사용자에게 정확히 귀속될 수 없기 때문에, 쿼리, 스토리지, 쓰기의 단가에 상각됩니다. 모든 과금 가능한 액션은 결국 실제 한계 비용보다 한 단계 높은 가격이 됩니다.
이는 "공유 리스크" 모델입니다. 모든 항목에는 다른 누군가의 콜드 쿼리, 버스트, 또는 유휴 스토리지를 커버하기 위한 추가 요금이 붙습니다. 그 변동성에 가장 덜 책임이 있는 워크로드 — 안정적이고, 고빈도이며, 예측 가능한 핫 쿼리 — 가 가장 큰 프리미엄 비중을 지불합니다. 워크로드가 안정적일수록 더 많이 보조하게 됩니다.
고객이 실제로 필요로 했던 것
한발 물러서서 보면, 고객의 요구는 특별한 것이 아니었습니다. 하나의 데이터셋, 여러 액세스 주기, 그리고 각 주기가 실제로 사용한 컴퓨트에만 따라가는 청구서.
- 온라인 검색: 지속적이고, 낮은 지연 시간이며, 예측 가능함. Dedicated가 이에 적합합니다.
- 모델 트레이닝: 버스트성이 있지만 예측 가능함 — 2주마다 3시간.
- 분석: 드물고 예측 불가능함 — 한 번에 몇 분, 긴 공백 포함.
Dedicated는 이를 제공할 수 없었습니다. 사용량이 아니라 프로비저닝된 용량에 대해 과금하기 때문입니다. Serverless도 제공할 수 없었습니다. 쿼리당 단가가 플랫폼의 모든 사용자에 걸쳐 콜드 쿼리, 유휴 스토리지, 버스트 여유 용량을 보조해야 하므로, 안정적인 워크로드는 자신이 만들어내지 않는 변동성에 대해 비용을 지불하게 됩니다.
우리에게 필요했던 것은 세 번째 컴퓨트 모델이었습니다 — Dedicated와 동일한 데이터에 연결할 수 있고, 쿼리당 과금이 현실적일 만큼 빠르게 기동되며, 실제로 실행 중일 때만 과금되는 모델입니다.
우리가 바꾼 것
On-Demand는 Zilliz Cloud에서 Dedicated 및 Serverless와 함께 존재하는 별도의 컴퓨트 모델입니다. 이 모델은 둘 중 어느 것과 비교해도 세 가지를 바꿉니다:
- 콜드 스타트. 전체 워킹 세트가 아니라 현재 쿼리가 건드리는 청크만 로드합니다. 10분 이상에서 몇 초로 줄어듭니다.
- 과금. 실제 컴퓨트 가동 시간 기준 분 단위 과금입니다. 쓰기도 포함됩니다. 최소 1시간도, 쿼리별 콜드/핫 프리미엄도 없습니다.
- 격리. 각 워크로드는 자체 컴퓨트 리소스 그룹을 통해 컬렉션에 연결됩니다. 같은 데이터이지만 경합은 없습니다.
다음 세 섹션에서는 각각을 살펴봅니다.
더 적은 데이터를 더 빠르게 로드
Dedicated에서 10분의 콜드 스타트가 존재하는 이유는 클러스터가 쿼리를 처리하기 전에 전체 워킹 세트를 로컬 메모리로 가져와야 하기 때문입니다. 10억 행 컬렉션에서는, 이는 단일 쿼리가 실제로 필요로 하는 데이터보다 수십 배에서 수백 배 더 많은 데이터입니다. 콜드 스타트를 몇 초로 압축한다는 것은 그 가정을 버린다는 뜻입니다: 현재 쿼리가 건드리는 것만 로드합니다.
한 문장으로는 간단해 보이지만, 실제로는 세 계층을 재설계해야 했습니다 — 무엇을 읽을지, 어디에 둘지, 어떻게 가져올지입니다.
부분적으로 로드되는 인덱스.
스칼라 측면에서 predicate pushdown은 표준 관행입니다. 엔진은 predicate와 일치할 수 없는 블록을 제거하고 해당 블록 가져오기를 건너뜁니다. 우리는 이를 inverted indexes에 사용합니다: 각 posting list는 블록으로 로드되고, 각 리스트는 엔진이 가져오기 전에 확인할 수 있는 min/max 통계를 가지고 있습니다.
더 어려웠던 부분은 벡터 측면에 비슷한 "부분 집합 읽기" 기능을 제공하는 것이었습니다. Graph indexes — 정상 상태 QPS에서 더 높은 성능을 제공하는 옵션 — 는 부분 로딩에서 우아하게 성능 저하가 일어나지 않습니다: 유용하려면 구조 전체가 로드되어야 하므로 콜드 로드 비용이 높습니다.
On-Demand는 대신 IVF family를 사용합니다. IVF는 인덱스 생성 시 벡터를 버킷으로 클러스터링하고, 쿼리 시에는 쿼리에 가장 가까운 버킷만 가져옵니다. 이를 통해 벡터 측면에서도 predicate-pushdown 의미론에 가까운 것을 제공합니다: 콜드 쿼리는 전체가 아니라 인덱스의 작은 일부만 가져옵니다.
이는 의도적인 트레이드오프입니다. 우리는 graph indexes의 정상 상태 성능을 잃게 되며, 이것이 On-Demand가 고QPS 서빙에 적합하지 않은 주된 이유입니다(이에 대해서는 아래에서 더 설명합니다). 희소하고 버스트성 있는 워크로드의 경우, 이 트레이드오프는 가치가 있습니다.
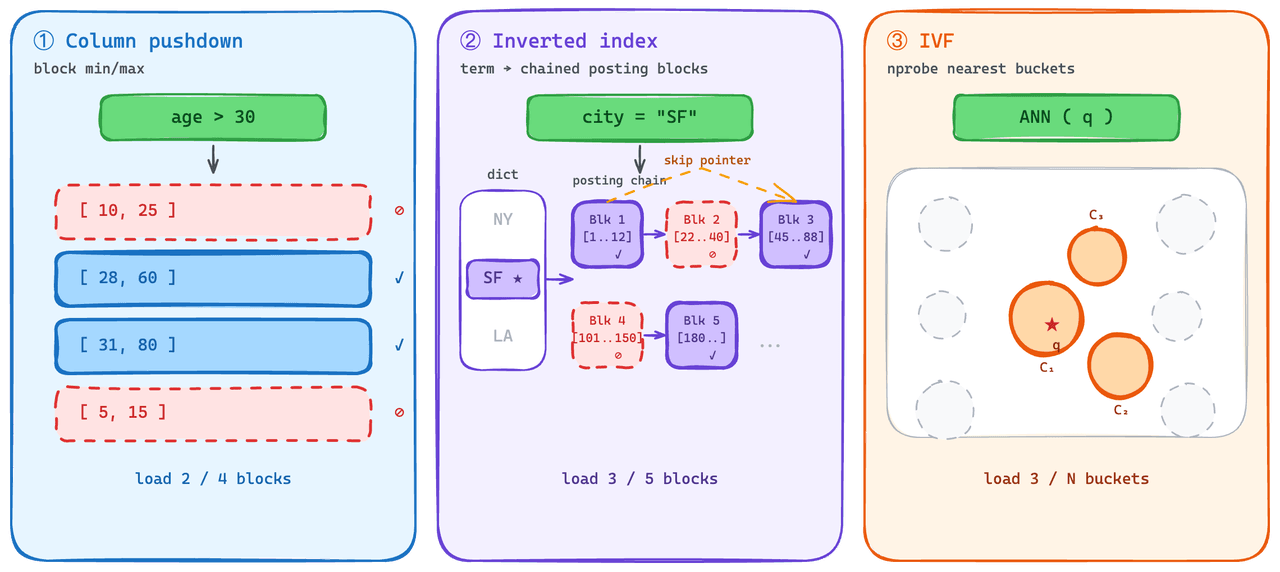
3계층 데이터 경로.
무엇을 읽을지 알게 되면, 다음 질문은 그것을 어디에 보관할지입니다. 청크는 S3, 로컬 디스크, 메모리 사이를 자유롭게 이동하며, 캐시 수명 주기는 쿼리 간에 청크 단위로 관리됩니다: 현재 쿼리에 필요한 청크는 위로 끌어올려지고, 충분히 오래 유휴 상태인 청크는 제거됩니다. 같은 데이터셋도 매우 다른 주기로 쿼리될 수 있으며, 어느 경우에도 건드리지 않는 데이터를 로드하는 비용을 지불하지 않습니다.
각 계층은 매체의 IO 특성에 맞춰 조정된 자체 데이터 레이아웃과 세분성을 가집니다 — 객체 스토리지에 적합한 정렬은 로컬 디스크에 적합한 정렬이 아니며, 둘 다 엔진이 메모리에서 실행 대상으로 삼는 것과도 일치하지 않습니다.
엔드투엔드 비동기 IO.
IO 체인은 완전히 비동기입니다. 컴퓨트와 IO는 전체 과정에서 파이프라인화되어 있어 CPU가 가져오기를 기다리며 멈춰 있지 않고, IO 대역폭도 컴퓨트를 기다리며 멈춰 있지 않습니다.
종합하면, 청크화 + 계층화 + 비동기는 콜드 쿼리 페이로드를 전체 데이터셋의 1–2% 미만으로, 엔드투엔드 콜드 경로를 몇 초로 줄입니다.
분 단위 과금
콜드 스타트가 초 단위로 내려가면, "쿼리가 도착하면 컴퓨트를 띄우고, 끝나면 해제한다"가 단순한 설계 지향점이 아니라 실제 제품 메커니즘으로 작동합니다. 컨트롤 플레인의 두 요소가 핵심 역할을 합니다.
대기 노드 풀. 이미지 풀은 새 노드를 띄울 때 지연 시간을 추가합니다. 우리는 미리 풀링된 노드의 작은 풀을 준비해 두어, 스핀업이 처음부터 시작하는 대신 이 풀에서 가져오도록 합니다.
TTL 기반 해제. 각 세션에는 구성 가능한 유휴 제한 시간이 있습니다. 제한 시간이 트리거되거나, 쿼리 워크로드가 종료되거나, 세션이 닫히면 컴퓨트가 자동으로 해제됩니다. 전체 라이프사이클은 플랫폼에서 스케줄링됩니다 — "클러스터 중지를 깜박했다" 모드도, 수동 운영도 없습니다.
라이프사이클이 세분화되어 있기 때문에 과금 단위도 그에 맞춰 낮아집니다. 컴퓨트는 실제 가동 시간 기준으로 분 단위 과금됩니다 — 최소 1시간도, 쿼리당 최소 요금도 없습니다. 쓰기도 같은 방식으로 계량됩니다: 실제 리소스 사용량을 분 단위로 측정합니다.
이러한 비용 귀속의 정밀성 덕분에 On-Demand는 Serverless가 부과해야 하는 스토리지 프리미엄을 피할 수 있습니다. Serverless는 컴퓨트 계층이 귀속되지 않은 비용을 흡수할 방법이 없기 때문에 스토리지를 한계 비용보다 높게 책정합니다 — 플랫폼이 지출하는 모든 달러는 청구서 어딘가에 반영되어야 하므로, 스토리지와 쓰기가 다른 곳에 귀속할 수 없는 비용의 처리장이 됩니다. On-Demand가 컴퓨트의 매분을 특정 세션에 과금하면 귀속되지 않은 풀이 없습니다. On-Demand의 스토리지는 Dedicated 요율로 Zilliz Cloud pricing을 따릅니다 — 일반적인 Serverless 스토리지의 약 1/10입니다.
공유 데이터에서의 워크로드 격리
세 번째 변화는 컴퓨트 계층을 명시적으로 만드는 것입니다. Dedicated에서 컴퓨트 계층은 클러스터입니다 — 단일 크기 조정 매개변수로만 사용자에게 보일 뿐입니다. Serverless에서는 컴퓨트 계층이 완전히 숨겨져 있습니다. On-Demand는 이를 노출합니다.
각 워크로드는 컴퓨트 리소스 그룹을 통해 컬렉션에 연결됩니다. 새 그룹은 세션을 통해 생성되거나 기존 그룹이 재사용됩니다. 서로 다른 그룹은 서로 격리되며, 각 그룹의 청구서는 자체 소비량만 반영합니다.
자율주행 사례에서는 이렇게 분석 워크로드가 데이터에 대한 자체 연결을 갖게 됩니다: 애드혹 쿼리를 위해 시작되고 유휴 상태에서 해제되는 On-Demand 리소스 그룹이 기존 온라인 검색 및 모델 학습 워크로드와 동일한 Milvus collection, 동일한 인덱스, 동일한 메타데이터에서 실행됩니다. 스토리지-컴퓨트 분리는 이들 중 어느 것도 데이터를 사용하기 위해 복사하거나 동기화할 필요가 없게 합니다. 교차 보조금도, 스케줄링 경합도, 클러스터 형태에 대한 팀 간 운영 조율도 없습니다.
이는 벡터 검색에 적용된 데이터 레이크와 동일한 아키텍처 패턴입니다: 스토리지는 공유 기반이고, 컴퓨트는 각 워크로드가 필요로 하는 형태로 연결됩니다.
이후의 청구서
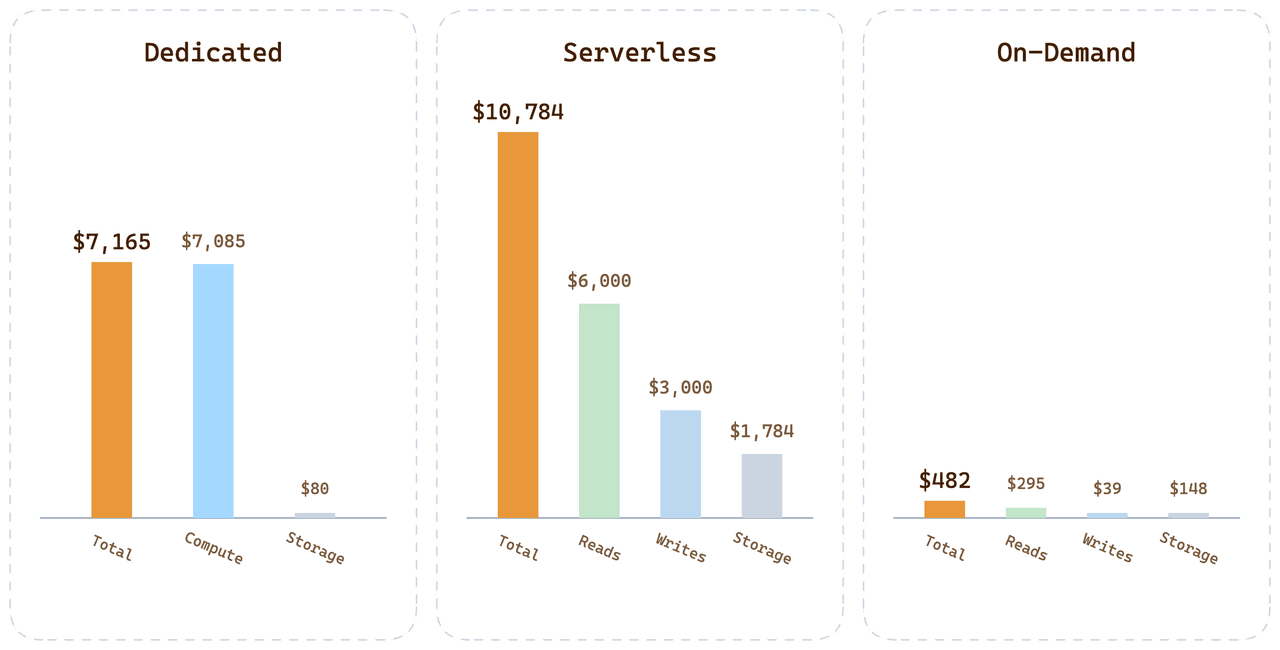
세 가지 옵션 모두에서 동일한 고객 워크로드에 대해:
| 옵션 | 월별 청구액 | 비용이 쓰이는 곳 |
|---|---|---|
| Dedicated (24 CU Tiered) | $7,165 | 비용을 지불했지만 유휴 상태인 컴퓨트 99.6% |
| Serverless | $10,784 | 쿼리 프리미엄 + $1,700 스토리지 + $3,000 쓰기 |
| On-Demand | < $500 | 분 단위 컴퓨트 + Dedicated 요율 스토리지 |
이 워크로드의 On-Demand 비용은 Serverless 청구액의 1/20 미만입니다. 이 차이는 가격 책정 꼼수가 아니라, 다른 사용자의 변동성을 모든 단가에 상각하는 대신 실제 소비에 비용을 귀속한 직접적인 결과입니다.
On-Demand가 잘못된 도구인 경우
On-Demand는 Dedicated나 Serverless의 범용 대체재가 아닙니다. 희소하고 버스트성 있는 워크로드에 저렴하게 만드는 동일한 설계 선택이 다른 워크로드에는 맞지 않게 만듭니다. 아래 차트는 이 고객의 워크로드에 대해 세 가지 옵션 모두에서 쿼리 압력에 따른 월별 비용을 나타냅니다.
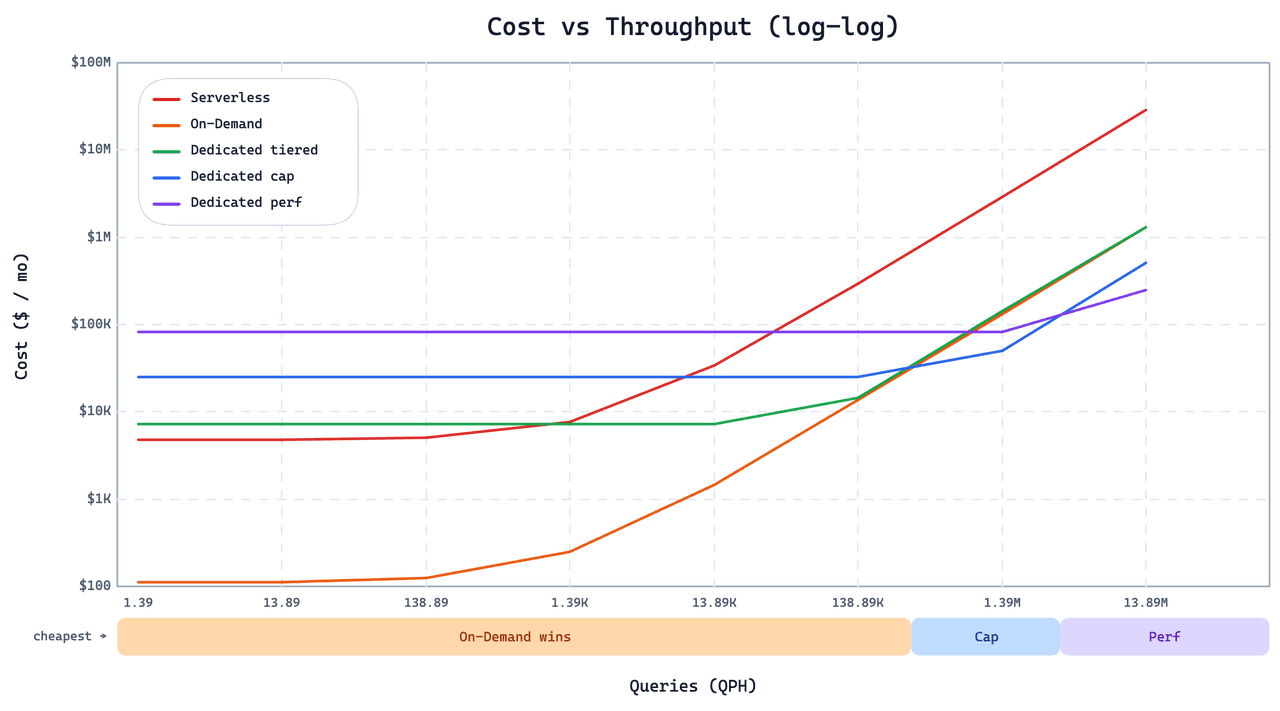
교차점 아래에서는 On-Demand가 훨씬 저렴합니다. QPS가 수십 단위에 들어서면 Dedicated Cap or Perf instances가 더 저렴하면서도 더 빨라집니다. 두 가지 설계 결정이 이 교차점을 설명합니다:
그래프 인덱스 없음. 콜드 쿼리 로딩 비용을 낮게 유지하기 위해 On-Demand는 그래프 인덱스 대신 IVF를 사용합니다. 그래프 인덱스는 대규모 환경에서 더 높은 정상 상태 QPS를 제공하지만, 콜드 로드 비용이 높습니다. 수십 QPS를 넘어서면 정상 상태에서의 이점이 결정적으로 앞섭니다. 높은 QPS 서빙에는 Dedicated를 사용하세요.
콜드 쿼리에서 더 높은 꼬리 지연 시간. On-Demand는 데이터를 미리 로드하지 않으므로, 콜드 쿼리는 실행되기 전에 추가 fetch 비용을 지불합니다. 웜 쿼리는 빠르지만, 콜드 쿼리는 눈에 띄게 느리며 꼬리 지연 시간 분포가 Dedicated나 Serverless보다 더 넓습니다. 애플리케이션이 간헐적인 초 단위(또는 더 나쁘게는 분 단위) 응답을 허용할 수 없다면 On-Demand는 적합하지 않습니다. 이러한 워크로드에는 Smart Autoscaling on Dedicated가 웜 상태 지연 시간을 희생하지 않으면서 유휴 용량을 줄여줍니다.
On-Demand가 적합한 도구인 경우: 희소한 액세스, 분석적 반복, 대규모 데이터셋에 대한 배치 마이닝 — 높은 동시성과 엄격한 지연 시간 일관성이 주요 요구사항이 아닌 워크로드입니다.
이것이 Zilliz Vector Lakebase에서 자리하는 위치
이 글의 고객 사례는 더 큰 패턴의 한 단면입니다. 동일한 데이터셋을 서로 다른 워크로드가 서로 다른 주기로 접근하며, 각 워크로드가 실제로 필요한 컴퓨트 형태를 받을 때에만 올바르게 크기가 조정됩니다. On-Demand는 이러한 컴퓨트 형태 중 하나입니다. Zilliz Vector Lakebase는 나머지를 가능하게 하는 아키텍처입니다.
Vector Lakebase는 AI 워크로드를 위한 레이크 네이티브 데이터 플랫폼입니다. 데이터는 S3에 있고, 인덱스는 컴퓨트와 분리되며, 서로 다른 컴퓨트 형태가 zero-copy access를 통해 동일한 컬렉션에 연결됩니다. 실시간 검색, 반복적 발견, 배치 분석이라는 세 가지 워크로드 모드를 일급 기능으로 처리하며, 각 모드는 접근 패턴에 맞는 컴퓨트 형태로 제공됩니다. 벡터 검색은 Zilliz Cloud에서 항상 일급 워크로드였습니다. Vector Lakebase 출시와 함께 반복적 발견 및 배치 분석 컴퓨트 형태가 동일한 데이터 기반 위에 합류합니다.
On-Demand는 분석적이고 버스티한 워크로드를 위해 구축된 컴퓨트 형태입니다. 나머지 네 가지 기능은 다른 모드들을 포괄합니다:
- Tiered Serving Solutions for real-time retrieval — Performance-Optimized(1000+ QPS, 한 자릿수 ms 지연 시간, 모두 메모리 내), Capacity-Optimized(메모리 + 로컬 NVMe에서 100 ms 미만 지연 시간으로 100–500 QPS), Tiered-Storage(메모리, NVMe, object store 전반에서 ~100 ms 지연 시간으로 10–50 QPS). 성능/비용 곡선상의 서로 다른 지점이지만, 동일한 서빙 모드입니다.
- External Data Lake Search for indexing and searching data already sitting in Lance, Iceberg, or other lake formats — 별도의 저장소로 복사하지 않고 수행합니다.
- Full-Spectrum Search for vectors, text, JSON, and geospatial on one query plane, with hybrid retrieval, filtering, and reranking on a wide-table data model.
- Unified Lake-Native Storage built on Vortex, Lance나 Parquet보다 더 빠른 랜덤 읽기를 제공하는 차세대 오픈 컬럼형 포맷이며, 컬럼별 포맷 유연성도 제공합니다.
Zilliz Vector Lakebase는 현재 Zilliz Cloud에서 public preview로 제공됩니다. 전체 아키텍처와 나머지 기능에 대해서는 Vector Lakebase deep-dive가 표준 참고 자료입니다.
자체 워크로드에서 On-Demand를 사용해 보려면 Zilliz Cloud에 가입하고 콘솔 또는 CLI에서 On-Demand 클러스터를 시작하세요. 이 글의 수치가 현재 운영 중인 것과 맞아떨어진다면, 구축하기 전에 Zilliz team이 워크로드를 함께 검토해 드릴 수 있습니다.

계속 읽기

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.