




FivetranとMilvusであらゆるデータソース向けのAI搭載検索を構築
このウェビナーについて
Fivetran は現在、Milvus ベクトルデータベースを宛先としてサポートしており、RAG や AI 搭載検索のためにあらゆるデータソースを取り込むことがより簡単になりました。Fivetran は、さまざまなソースと宛先の間でデータを抽出、ロード、変換することを容易にするクラウドベースのデータ移動プラットフォームです。Fivetran は、データベース/ウェアハウス、SaaS アプリケーション、ERP、ファイルなど、500 以上のソースに接続します。新たに導入された Fivetran の Milvus Destination は、データランドスケープをさらに拡張し、あらゆるデータソースをセマンティック検索可能にします。多様なデータベース/ウェアハウスやビジネスアプリからソースデータを Milvus ベクトルデータベースに取り込むことで、この統合により AI ワークフローの開発が容易になります。
このウェビナーでは、Fivetran の Milvus Destination を紹介し、シンプルな設定で GitHub issues 向けの Retrieval-Augmented Generation (RAG) チャットボットを構築するためにコネクタを使用する方法をライブデモでご紹介します。
取り上げるトピック:
- Fivetran の Milvus Destination コネクタのローンチを発表
- さまざまなビジネスアプリのデータを検索可能にする方法のデモ
- RAG などの AI アプリケーションで情報を活用
本日は、Five Tran と Mil による「Build AI powered search for every data source」のセッションをご紹介できることを大変うれしく思います。そして、この統合の立役者である Tran のゲストスピーカー、Aja をお招きできることを光栄に思います。ようこそ、Aja。はい、お招きいただきありがとうございます、Jang。はい。
ええと、それでは私のほうから VUS についてごく簡単に紹介し、その後 Aja にお渡しします。そこからはあなたのステージです。いいですね。わかりました。ええと、私の名前は Jang です。私はエコシステムとデベロッパーリレーションズを担当しています。
そのため、この統合では Five Trend と密接に連携してきました。ええと、私たちが vus というオープンソースのベクトルデータベース製品を始めたのは、検索、つまり検索とデータ全体のパラダイムに変化があったからです。過去20年間、検索は主にキーワードマッピングに関するものでした。しかし、これは非常に限られています。なぜなら、自然言語の意味や、それを構成するキーワードの背後にあるセマンティックや本質を実際には考慮できないからです。たとえば、キーワード検索を、たとえば画像検索に使うことは実際には難しく、また、見た目は非常に異なっていても、実際には同じセマンティックを持っていたり、たとえば、チャートやメニュー、さらにはそこに表示される単語のような視覚コンテンツから伝わる情報を考慮できないことがあります。
つまり、これは非常に限られており、ニューラルネットワークとディープラーニングの急速な進歩のおかげで、今では inviting model と呼ばれる優れたツールがあります。これは、画像やテキスト、その他あらゆるモダリティから本質を抽出できるため、embedding model の出力、つまりベクトルを使って、あらゆる非構造化データの背後にあるセマンティックを表現できます。そしてこれは非常に有用です。なぜなら、今日の非構造化データは、世界で増加しているデータの中でますます大きな割合を占めているからです。そして 2025 年に新たに生成されるデータの 80% 以上が非構造化データになるとされています。したがって、あらゆる種類の AI アプリケーションのために、非構造化データを処理し、理解し、活用するための体系的で効率的な方法を持つことは、私たちにとって非常に重要です。
VUS は、この、この、ええと、この背景をもとに設計されました。そして、ええと、mine side として、私たちは開発者が非常に効率的でスケーラブルなベクトル検索を構築できるようにしたいと考えています。それによって、たとえば、検索拡張生成アプリケーション、画像検索、製品レコメンデーションが支えられます。そして私たちは mailbu を完全に分散されたクラウドネイティブアーキテクチャとして設計し、あらゆるワークロードによって生成される膨大な数の inviting vectors を保存、インデックス化、管理、利用できるようにしました。ええと、そして私たちは、開発者がその背後にあるインフラについてあまり心配するのではなく、自分たちのビジネスロジックだけに集中できるようにできます。現在、VUS は幸運にも GitHub で 29K を超える starts と、6,600 万を超える docker posts を獲得しています。
このプロジェクトの背後にある素晴らしい研究成果と、ええと、そうした優秀なエンジニアの皆さんに大いに感謝しています。ええと、VUS は現在、最も高性能でスケーラブルなベクトル検索エンジン、ええと、ベクトル検索エンジンを備えており、VLDB のようなトップティアのデータベース会議でいくつかの論文を発表し、その歩みや、私たちが背後で開発してきた技術について共有し、また、高性能でスケーラブルなベクトル検索システムを構築する方法についての学びも共有してきました。そして、ええと、感謝、ええと、また、あらゆる種類の業界や分野でベクトル検索の採用が拡大しているため、mailbox は何千もの企業や開発者のユースケースで利用されています。ここではその一例を示していますが、これは、ええと、開発者から非常に高く評価され、愛されています。なぜなら、従来のデータベースに単にプラグインを追加するのではなく、目的、専用のベクトルデータベースとして設計されているためであり、その結果、他のプラグイン可能なベクトル検索ライブラリよりも 3 倍高速で低コストになっているからです。
ええと、それから、ストレージシステムに対する、あの、慎重な設計のおかげで、階層型ストレージを備えています。データのうち、あの、最も重要で、かつ有用なデータだけを、ええと、メモリのような高価なストレージに置くことができます。そして、ベクトルインデックス構造やメモリマッピングのようなものを使って、あまり頻繁にアクセスされないデータを、あの、他のより安価なストレージに置いておきます。また、mul はクラウドネイティブであり、ES ネイティブでもあります。そのため、実際にさまざまなデプロイメントモードをサポートしています。
そのうちの 1 つが Kubernetes で、これは簡単に、ええと、数百億のベクトルまでスケールできます。ええと、それから ware はもちろんベクトルネイティブで、このベクトル検索のユースケース向けに設計されています。ええと、ただしこれに加えて、ベクトル検索以外にも多くのユースケースや、そして機能をサポートしているため、実際のアプリケーションでこれを使うのに便利です。たとえば、VU はスパースベクトルと密ベクトルによるハイブリッド検索をサポートしています。動的スキーマをサポートしていますし、あるいは JN をそのまま内部に保存することもできます。
ええと、グリッドのセキュリティおよびプライバシー機能、たとえば、ええと、あの、rba や、アクセス制御、そして、あの、データの暗号化も備えています。また、ええと、便利なツールもあり、ええと、たとえばバルクデータインポートを行うことができます。ただし今日は、ええと、データをインポートし、ストリーミング方式でデータを抽出する方法について、より詳しく話します。そして、そこが Fiver が非常に重要な役割を果たせるところです。また、mill はさまざまな形態でデプロイできます。
あの、mill light があり、これは、あの、ローカルでの実験やプロトタイピングに最適です。単に ping install するだけで、ええと、ラップトップやノートブックで、あの、使用できます。また Docker 上のものもあるので、軽量で小規模な本番デプロイメントを行いたいが、get、get touch、あの、Kubernetes には触れたくない場合は、Docker デプロイメントを使えます。もちろん、Kubernetes と Zeus cloud 上のクラウドデプロイメントもあり、これは Millis の中で最も高性能でスケーラブルな選択肢です。そしてこれらすべての選択肢は、同じクライアント co、あの、クライアント側コードで動作するため、クライアント側では、デプロイメントの形態を変更したというだけで、別の、いわば、ビジネスロジックを開発する必要はありません。単に、ええと、ネットワークエンドポイントを古いデプロイメントから新しいデプロイメントへ置き換えるだけでよいのです。
そのため、ええと、アプリケーション開発ライフサイクルのさまざまな段階から、ものを移行するのが非常に便利になります。そして、ええと、まあ、私たちは、ええと、私は、現在ベクトル検索の最も人気のあるユースケースは検索拡張生成だと言わなければなりません。そしてそれは今日の中心的な、あの、中心的なトピックでもあります。ええと、ご覧になったことがあるかもしれませんが、検索拡張生成は通常 2 つの部分で構成されます。1 つは下の部分で、オフラインインデックス作成です。そこでは、あらゆる種類の非構造化データが、ええと、皆さんの、いわばデータベース、ビジネスアプリ、データウェアハウスに存在しており、それらを深層ニューラルネットワークからベクトル埋め込みを生成することで活用したいわけです。
そしてベクトルが得られたら、それらをベクトルデータベースにインポートして保存し、効率的な検索を行えます。そして上の部分がサービングスタックです。これはサービングワークフローで、ユーザーが何らかの質問をするかもしれません。そして、ええと、オフラインインデックス作成に使用したのと同じ埋め込みモデルを使って、検索クエリのベクトル埋め込みを生成します。そして検索クエリを使って、あの、検索クエリを使って、あの、検索ベクトルを使って、ベクトルデータベース上で検索を行うことができます。そうすると、意味的に類似したコンテンツが得られます。
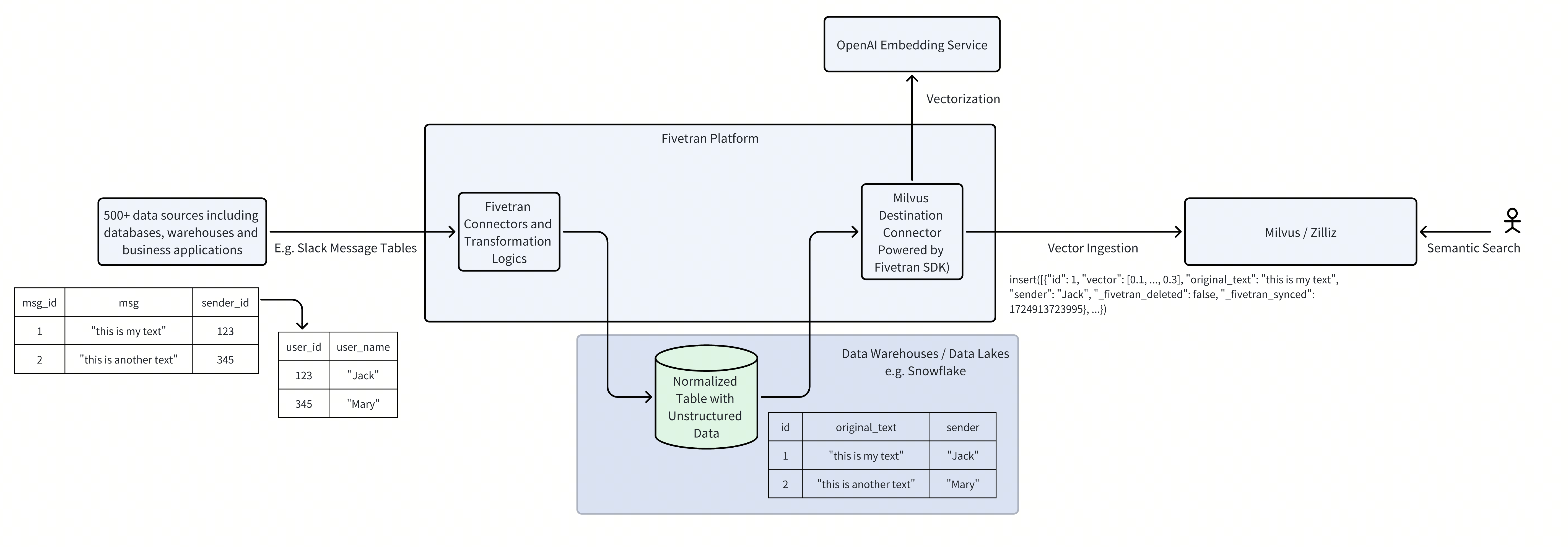
そしてこのコンテンツを使って、コンテキストとユーザーの質問を埋めることで、プロンプトを準備できます。そうすれば、大規模言語モデルは、はるかに根拠のある生成を自動的に行い、信頼できる回答を提供できます。これは単純に見えるかもしれませんが、オフラインのインデックス作成部分には多くの重い処理があります。ええと、たとえば、さまざまなデータソースからデータをどのように抽出するのか?それらを、ええと、あるデータソースから、ええと、つまり別のベクターデータベースへ、どのように確実に移動するのか?そして、このプロセスから合理化されたベクトル埋め込み生成をどのように行うのか?つまり、多くの技術的課題があり、そこで Fivetran は多くの価値を提供できます。Fivetran は 500 を超えるデータソースに接続でき、たとえばすべてのビジネスアプリやデータソース、データウェアハウスなどを含み、それらを Fivetran にインポートでき、Fiver はこれをストリーミング形式で自動的に移動できます。ええと、そして今日、Fivetran と vus の統合により、すべてのデータをベクターデータベースの宛先に移植できます。ええと、つまり、さらに、ええと、このソリューションはベクトル埋め込み生成も合理化できるため、これを処理し、失敗やリトライを考慮するためのビジネスロジックを実装する必要がありません。
それでは早速、Fiver から objects をお迎えして、これについてより深掘りした、ええと、概要を、ええと、より、ええと、詳細な概要を説明していただき、その後、この背後にある技術に深く入っていただきましょう。そして最後には、GitHub の検索、GitHub の issue 向けの検索を five Tri と Milless で構築する方法を示すライブデモを行います。ありがとうございます、Jang。ええと、紹介がとても良かったです。また、BU が行っている、クールで素晴らしいことの数々を見るのも非常に興味深かったです。
私の、ええと、この統合を構築した経験を通して言うと、私は milus のごく薄い一層、つまり Milless がどのようにデータを保存するかしか見ていなかったように感じますが、内部にはもっと多くのものがあり、検索や利用のために非常に機能が充実しているのを見るのは本当に興味深いです。素晴らしいです、その紹介ができてよかった、よかったです。ええと、ここで何人かにお会いできてうれしいです。ええと、私の名前は Abijit です。
ええと、私はここ Five Tran のスタッフ R&D エンジニアです。そして今日は、ええと、Jiang が言ったように、ええと、AI を活用した検索についてお話しします。これは最近、fiveTran partner, SDK を使用して構築された Vis と Five Tran の統合を通じて実現したものです。私について、少し、ええと、簡単に紹介します。私は Five Tran に、ええと、約5年間、断続的に在籍しています。ええと、CTO オフィスで研究開発チームの一員として働いています。
そして、ええと、CTO オフィスでの私の仕事は主に、社内チームを支援するために社内向けの rag アプリケーションを構築することに関わっています。つまり、サポートエージェント、人事チーム、ええと、営業チームが、日々の業務に必要な知識を非常に簡単に見つけられるようにするためです。ええと、今日は、Five Tran とは何か、なぜ優れたデータアーキテクチャが RAG アプリの構築に重要なのか、ええと、VIS が今どのように five Tran に接続できるのか、そして、ビジネスデータ上で fiveTran、Millis、その他のツールを使って、検索または rag アプリケーションを自分で構築する方法についてのデモを調整してお話しします。Five Tran は自動データ移動の会社です。ええと、私たちがしていることは、データをポイントAからポイントBへ移動することです。ええと、それだけのシンプルなことです。
では、なぜ私たちは、なぜ皆さんは five Tran が必要なのでしょうか?ええと、ビジネス分析を行おうとしている企業の多くは、つまりダッシュボードを構築したり、レポートを作成したり、あるいは機械学習モデルをトレーニングしたり、ええと、AI モデルをトレーニングしたりしています。そして、今ではより最近では、rag アプリケーションを構築する場合、まずさまざまな、ええと、ソースストレージからすべてのデータを中央のストレージレイヤーへ取得する必要があります。通常、ソースはさまざまなビジネスアプリケーションです。たとえば Jang が先ほど挙げた例のいくつか、Salesforce や HubSpot などです。ええと、GitHub は今日のデモで使用する一例です。
あなたのデータは、ええと、他の場所にも存在し得ます。PDF や Google Docs、Google Drive のようなファイルです。Postgres や MySQL のような運用データベースにも存在し得ます。ええと、Kafka のようなストリームにさえ存在し得ます。ええと、また Snowflake や BigQuery のように、ウェアハウス自体にも存在し得ます。そして通常、BI や AI モデルを構築する前に、これらすべてのデータを置きたい、つまりこのすべてのデータを集中管理したい宛先は、たいていデータウェアハウスかデータレイクです。
ビジネス分析を行う場合は、データウェアハウスのほうがより適しています。機械学習や、ええと、AI アプリケーション構築を行う場合は、データレイクのほうがより適しています。そして最近では、ええと、宛先として Vector databases もサポートしています。Zillow は、Fiver が宛先としてサポートする最初の専用ベクトルデータベースであり、つまり Five Tran を使えば非常に簡単に、下流でセマンティック検索や RAG アプリケーションを構築できるということです。ええと、すでに Five Tran のことを聞いたことがあるなら、ええと、驚きません。
ええと、私たちはもうしばらくここでやってきました。2012 年に始まりました。数年後に、ええと、設立されました。それ以来、私たちは、ええと、たくさんのクールなことをしてきました。ええと、たくさんのコネクタ、たくさんのソースコネクタを追加してきました。
さまざまな宛先サポートもたくさん追加してきました。私たちは、ええと、また、これらのソースから宛先へデータを取り込めるようにするための複数の戦略も追加してきました。ええと、昨年 11 月には、サポートするコネクタ数が 400 の大台を超えたと思います。そして今年の初めには非常にすぐに、500 の大台を超えました。そして昨年末にローンチしたものの 1 つが、ええと、partner SDK であり、この partner SDK によって VIS とのこの統合全体が実現しました。ええと、つまり partner SDK によって、Five Cran の顧客やパートナーが five Cran に来て、私たちの GRPC インターフェースを使って独自のコネクタを構築できるようになります。
そしてそれを Zeus が行いました。Zillow は、mil update 操作や create tables、create collections、create in operations を、five Tran が通常データを出力するリレーショナル操作に非常に密接にマッピングする mil コネクタを構築しました。そのため、この GRPC インターフェースを使って、ええと、Millis は five Tran 向けの mil 宛先を作成することに成功しました。ええと、そして私が話すトピックの大部分は、良い RAG アプリケーションを構築するには優れたデータアーキテクチャが必要だ、ということです。ええと、もしかするとこの言葉を耳にしたことがあるかもしれません。つまり、ゴミデータ、クソ AI です。これは、膨大な量のデータを維持し、RAG アプリに送り込み始める必要があるようなエンタープライズレベルのワークロードを扱い始めると、非常に真実になります。
そして、下流アプリケーションをソースアプリケーションと同期させ続ける必要もあります。ええと、というのもソースでの変更は非常に速い可能性があるからです。そして今や、データだけでなく変更も下流アプリケーション全体に伝播させる必要があります。そうすることで、あなたの、ええと、下流のチャットボットや copilot、あるいは構築しているものが何であれ、それが維持する必要のあるすべての知識で最新の状態に保たれるようになります。ええと、今年の初めに、ええと、私はあるプロジェクトに取り組んでいて、私たちの、ええと、顧客向けサポートフォームの自動化を構築しようとしていました。これが、five front ダッシュボード上でのサポートの、ええと、見た目です。
もし five front を見たことがない場合ですが、左側が私たちのダッシュボードの見た目です。設定できるコネクタがたくさんあります。変換機能があり、five front を登録して、要件に基づいてデータを変更したり、データをモデル化したりできます。ええと、私たちのコネクタや変換で何か問題に直面した場合は、右下の角にある小さな、ええと、チャットアイコンをクリックできます。そうすると、あなたのためにチャットウィンドウがポップアップします。
つまり現在、このチャットは完全に人が対応しています。ええと、そこには、サポート、または営業担当者が裏側にいて、さまざまな顧客からの質問に答えようとしています。そしてこれは、私たちのサポートプロセスが、本来可能なほど速くないということを意味します。ええと、ダウンタイムもあります。つまり、サポート担当者が眠っている一方で、顧客は別のタイムゾーンで作業している、というような場合です。そして私たちは、サポート担当者により良いツールを提供するだけで、知識全体を簡単に検索できるようにし、彼らがより効率的になれるようにする方法を探っています。
Five Trend にはそれが含まれており、これは Five Trend にとって特に重要です。というのも、Five Trend が持つ Connectors の範囲は非常に広いため、ええと、たった一人の担当者が、私たちがサポートしているこれらすべての異なるコネクタ、あるいはソースおよび宛先の統合すべての専門家になることは、人間的に不可能に近いからです。ですから、私たちの知識の大部分は、左側に見えているこれらのアプリケーション内に存在しています。つまり、内部コミュニケーションを含む Slack のようなチャットアプリケーションや、five cran の従業員と外部とのコミュニケーションを含む Zendesk や Salesforce に存在しています。ええと、あるいは Height にもあります。Height はプロジェクト管理ツールのようなもので、エンジニアが、製品、営業、サポートなどの他部門とコミュニケーションを取る場所です。
ええと、私たちには社内の VP もあり、さらに技術設計ドキュメントやアーキテクチャ図などが Google Docs や Slab に存在しています。また、私たち自身の公開 Web サイト、つまり tran. com/docs もあり、そこには公開向けのトラブルシューティング手順が多数含まれています。そして GitHub には、私たちのコードすべて、つまり issue や pull request などが含まれており、それらは発生したさまざまな問題を説明し、またさまざまな問題に対する解決策の詳細も含んでいます。
したがって、このすべての知識は、サポート担当者が簡単に検索できる必要があります。ええと、それによって迅速に、つまり答えを見つけて顧客に返答できるようにするためです。そしてこれを行うことで、私たちのサポートワークフローははるかに効率的になり、ええと、存在しているダウンタイムの量を削減し、あるいは顧客への応答にかかる時間が、もともとよりもはるかに短くなります。そしてこの過程で、私はこのアプリケーションを社内で構築していました。ええと、同時に外部のいくつかの企業も評価していました。ええと、それらは同じ問題を解決しており、複数のデータソースを取り込める RAG アプリを構築していました。そしてこれらの議論の中で、これらのアプリケーションを構築している企業のほとんどは、ええと、内部をのぞいてみるとこのように見えることが分かりました。ええと、つまり、車を走らせようとしている Pringle scan がある、という感じです。
それは、かなり脆く、かなり壊れています。ええと、車を動かすことはできますが、長くは走りません。問題は、データ、ええと、その量に追随し続けること、変更に追随し続けること、異なるソースからのデータモデルを統一しようとすること、データ移動において I potency があることを確認することです。そしてまた、データを移動するためのインフラをどうするか、ということも考えなければなりませんよね。これらはすべて、スケールしたデータを扱い始めると非常に難しい課題であり、最終的には、それらの問題、つまり大規模なデータ移動の問題を解決するために、大規模なエンジニアリングチームを雇う必要が出てくることになります。
でも、ええと、こうした、まあ、こうしたAIアプリケーションを構築している企業は、まあ、こういうもののためのソリューション構築に慣れているデータスキルを持つデータエンジニアのような人たちではありません。つまり彼らは、下流でAI関連のものを構築することにもっと時間を使いたいのです。つまり、実際にGPTや、ええと、PyTorchや、そうした下流のツールを使って、非常に優れたアプリケーションを構築し、データの取得のようなことについてはあまり気にしなくて済むようにしたいのです。なぜなら、それは下流の、つまりAIの問題を解くことこそが本当に難しい問題だからです。そしてデータを取得すること自体は、ただ、実際にはそれほど難しくありません。ただ、とても、ええと、面倒なのです。そこには多くの労力を注ぐ必要があります。
そして、これらのアプリケーションのほとんどは、ええと、今画面でお見せしているようなアーキテクチャを持っています。データがもともと存在する多数のソースがあり、それらの場所からデータを取得して、ええと、データウェアハウスまたはデータレイクに集約します。ええと、そしてそこにデータが入ったら、皆さんの、つまり、クリーニング、前処理、RAGアプリケーション向けのあらゆる変換を行うことができます。具体的には、連結とチャンク化です。RAGを行えるようにするために実行する最も一般的な操作はこれらだと思います。そしてデータを変換し、アプリケーションに適したデータモデルを構築したら、そのデータを専用のベクトルストアに移動できます。
その間に、データをベクトル化する必要があります。つまり、何らかの埋め込みモデルプロバイダーを使うか、あるいは、自分でオープンソースの埋め込みモデルをダウンロードして実行することもできますが、VUや、ええと、Zillowのようなホスト型VUSなどのベクトルストアに入る前に、ベクトルを生成する必要があります。そしてそこに入れば、まあそれで終わりです。必要なストレージレイヤーにデータがあり、その後、その下流で検索やRAG、分析も実行できます。そしてそれこそが、これらすべての企業、すべての企業が労力を費やして解決しなければならない中核的な問題です。ですから、私たちがfive trend partner, SDKを使って構築したvis destination connectorは、このアーキテクチャ全体を可能にします。
そして、ほんの数クリックでこのアーキテクチャを自分で設定することが非常に簡単になります。ええと、もう少し詳細に踏み込むと、つまり、これを設定するために使用する必要があるさまざまな、ええと、ツールは何でしょうか?データソースは、ええと、さまざまな場所にあります。ええと、まずこれらのソースからデータを取り出して、データリポジトリに入れる必要があります。そして、five Tranのようなツール、データ移動ツールを使ってデータを抽出し、それをウェアハウスまたはデータレイクにロードできます。Five tranは、ええと、Snowflake、BigQuery、Redshift、ええと、DA Databricksなど、複数のデータウェアハウスをサポートしています。
そして、オープンテーブル形式のデータレイクもサポートしています。これらのマネージドデータウェアハウスのいずれかを使いたくない場合は、AWSアカウントやAzureアカウントのようなものを持ち込むだけで、私たちは引き続き、これらのデータレイク内にオープンテーブル形式でテーブルを配置できます。このデータがデータリポジトリまたはデータプラットフォームに存在するようになったら、その上で変換をトリガーできます。ええと、Pythonスクリプトのようなものを使うだけでも構いません。sqlを実行することもできますし、CoalesceやDBTのようなフレームワークやツールを使って、そうした変換を簡単に構築することもできます。
そしてデータモデルの準備ができたら、次のステップはそれをVector databaseに移すことですよね?Open AirやCohereのようなembedding serviceを使ってデータをベクトル化し、それからVector databaseに移します。問題は、ええと、私たちが評価したすべての企業では、まあ、その、後半部分がある意味で寄せ集めになっていることです。ええと、実現するためにさまざまな部品をつなぎ合わせていて、そのため非常に壊れやすいのです。つまり、POCフェーズを乗り切ることはできますが、実際にアプリケーションを本番対応にするには、そのパズルの小さな1ピースを解決するためだけに、巨大なエンジニアリングチームを雇うことになってしまいます。幸い、ええと、私たちにはdestination connectorがあります。
今では、partner SDKを使って構築された部分を使用することで、データリポジトリから自動的にデータを抽出し、転送中にベクトル化し、それからVector database、たとえばVUSor hosted Mils on Zillowに自動的に投入します。そして、このパイプラインを設定するために必要なのは、ほんの数クリックだけです。ええと、five trend dashboardに行って、ここ、ここ、ここ、と2、3個のボタンをクリックすれば、それで終わりです。これで、データを抽出し、さらにvector databaseをソースアプリケーションと同期し続けるパイプラインができあがります。ええと、はい、それだけです。semantic search applicationをエンドツーエンドで構築するために必要なのはそれだけです。
ええと、もしさらに一歩進めたいなら、Giangが言及したアーキテクチャのように、RAGアプリケーションも構築できます。Ragは、情報全体をより人間らしい形式で検索するのに役立ちます。LLMが、関連するドキュメントを読み、それからそれをある程度処理し、ええと、そこに存在するデータについて推論し、それを質問と関連付けようとし、そしてエンドユーザーにより人間らしい応答を提供する、ということです。なので、ええと、これが、さまざまな企業に最も適したアーキテクチャです。そして今では、このプロセスをさまざまなビジネスでシームレスに実現するために、2つのconnectorと、その間にあるさまざまなtoolがエンドツーエンドで接続されています。
そして、ええと、このwebinarの残りでは、このアーキテクチャを使って構築されたデモアプリケーションの紹介に焦点を当てます。そして、このアプリケーションを実現するために、各種類のtoolから1つずつ選びます。sourceにはGitHubを選びました。ええと、GitHubは、多くの企業が使用しているcode managementおよびcode collaborationのtoolです。そしてGitHubには、単なるcode以外にも、ユーザーの共同作業を助けるいくつかのartifactが含まれています。たとえば、codeで何がうまくいっていないかに関する情報や、人々が持っている質問、あるいは製品に求める機能を表すissueです。
そして、issueではissue commentを作成できるため、さまざまなユーザーがcode collaboration tool上で直接会話に参加できます。ですので、この例ではGitHubをsourceとして使います。これにより、さまざまな、まあ、d answers、製品に関するさまざまな質問に答えることができます。ええと、より技術的な観点からです。ええと、最初のステップとして、GitHubからデータを取り出し、Snowflakeに入れるためにfive tran connectorを設定します。
ええと、five Tranはデータをそのwrongformのまま、いくつものrelational tableに取り込みます。ええと、このデモでは、issueエンティティ周辺の特定のtableに焦点を当てます。たとえば、さまざまなissueのcomment、さまざまなissueのassignee、ええと、issueに追加されたさまざまなtag、そしてそのissueがどのrepositoryに属しているか、ですよね?この情報について扱い、GitHub Wikiやcode、またpullrequestなどには踏み込みません。issueにも焦点を絞ります。このデモをシンプルにするためです。
Snowflake に生のテーブルを取り込んだら、ええと、DBT のようなデータ変換ツールを使ってこれをデータモデル化できます。ええと、その、関連するすべての情報を連結し、このデータ全体で join を行い、その後、検索可能なフラットテーブルを構築します。フラットテーブルは、ええと、検索アプリケーションを構築するための要件の 1 つです。なぜなら通常、その、rec ベクトルを構築したいわけで、1 つのベクトルが各行に対応することになるからです。そしてそれはまた、その、ベクトルデータベース、たとえば、その、vis のようなものに対する、厳密に具体的に定義された入力形式でもあります。つまり DBT 変換は、テーブルをこの形式にするのに役立ちます。そしてその形式になったら、その、partner SDK を使って構築された第 2 段階のコネクタを使い、このデータを、ええと、vis または flight の orus に取り込むことができます。
ええと、現在このコネクタは open AI embedding service の使用をサポートしています。ええと、需要が増えるにつれて、ご存じのように、この提供内容をさらに拡張して、ええと、より多くの embedding service に対応する計画があります。ただ現時点では、多くのお客様は、まあ、open eyes embedding service だけを使うことで問題ないと思います。というのも、まあ、これまでの私たちの経験では、かなり品質が良いからです。それに、ええと、自分でモデルをホストする方法を考えるのに比べて、それほど高価というわけでもありません。データを簡単に埋め込むための API を提供してくれます。
つまり、その、2 つの five D パイプラインと DBT モデルを Snowflake にセットアップすれば、ええと、準備完了です。その後、すべてのデータが、ええと、vis に入ります。そしてこの例では、繰り返しになりますが、Zillow 上の hosted VIS を使用します。なぜなら、Vector database を管理し、その機能をデモするのが非常に簡単になるからです。ただ、Jang が述べたように、VUS は複数の異なる方法でホストできます。ええと、ビジネスユースケースに適した方法で構いません。そして最後に、検索機能をデモするために、semantic search バックエンドを使って回答を生成する、まあ、とてもシンプルなチャットアプリケーションを構築しました。
このデモ中にこのチャットアプリケーションを構築することはありませんが、これは、ええと、end-to-end の Semanticsearch ソリューションをセットアップした後に何ができるかを示すためのものです。システムを起動して実行するには、ええと、5 つのステップがあります。ええと、まず five Trend アカウントに行き、Snowflake destination をセットアップします。これは 3 ステップだけです。
Add Destination をクリックし、Snowflake connector を作成し、その後 credentials を入力します。次に GitHub to Snowflake connector を作成します。ええと、add connector をクリックし、その後 credentials を入力します。繰り返しになりますが、すべてのデータを取り込みたくない場合は、特定の repositories を指定することもできます。そしてそれが完了したら、3 つ目のステップは DBT transformation です。ええと、これもいくつかの設定が必要なだけです。
credentials を入力し、さらに DBT model が、ええと、記述され保存されている GitHub repository も指定します。これについては、ええと、後ほどライブデモで少し詳しく説明します。そして、その、モデルがどのようなものかをお見せしますが、Snowflake destination、connector、そして DBT setup ができたら、第 2 段階のパイプラインをセットアップする準備が整います。その後、VUS destination を作成できます。これも以前と同じくらい簡単で、five Tran に行き、add destination をクリックし、credentials を入力すれば、準備完了です。
これで 2 つの destinations ができました。1 つの connector があり、もう 1 つの connector、つまり vectorize を抽出して flight にデータをロードする第 2 段階の connector をセットアップします。そして再び、fiver に行き、add connector をクリックし、source の credentials を入力すれば、はい、準備完了です。システムを end to end で稼働させるために必要なのは、5 つの異なる設定ステップだけです。大量のコードを書く必要は、まあ、ありません。
ええと、おそらくカスタム設定が必要になる唯一の場所は、DBT のステップで、ビジネスアプリケーションに合わせてデータを適切にモデル化する必要があるところです。ですが、このシステムが何を、何を助けてくれるかというと、ソース、API、つまり GitHub の REST API や Webhook API、あるいは VU の GRPC インターフェースをラップするコードを自分で書く必要を取り除いてくれるということです。それらすべてをプログラムする必要があります。そうしたものはこれ以上標準化され、あなたは下流のアプリケーション向けにデータをデータモデリングすることにより集中できます。では、はい、ええと、これからライブデモに切り替えます。
ええと、先ほど紹介した、さまざまな、たださまざまな画面をお見せします。ええと、ウェビナー中の時間を節約するために事前にやっておいたことの一つは、これらのコネクタのいくつかをすでにセットアップし、同期させておいたことです。そうすることで、ここでセットアップ情報やセットアップ設定にあまり時間をかけずに済みます。こちらが five front のダッシュボードです。ご覧のとおり、ええと、2 つのコネクタを設定しています。最初のコネクタは GitHub から Snowflake へデータを同期しています。
ええと、そして 2 つ目のコネクタは Snowflake から Zillow へ同期しています。繰り返しになりますが、これを自分でどのように設定できるか気になる場合は、add connector をクリックして、ここに移動し、必要なソースの種類を選択します。たとえば GitHub として、それから setup をクリックし、ええと、setup してここに認証情報を入力します。すでにコネクタを設定してあるので、これはもう一度はやりません。宛先を設定するには、左側の destinations に移動して add destination をクリックするか、ええと、ここに宛先の一覧がすべてあり、VIS が利用可能で、現在プレビュー中であることがわかります。
それで、vis の宛先を設定できます。ええと、まず宛先に名前を付ける必要があるので、desk destination と呼びましょう。そして、ええと、ここでは認証情報を入力するだけです。今日はインターネットが少し、少し遅いかもしれないので、表示されるまで数秒かかるかもしれませんが、他のシステム部分を設定するのと同じくらい簡単です。つまり、ここに来て認証情報を入力するだけです。ええと、この宛先について、他の宛先と比べて追加で提供する必要があるものの一つは、open AI トークンが必要だということです。
それは主に、cloud では現在、ベクトルをインフライトで生成するための埋め込みサービスとして open AI のみをサポートしているためです。ただし、いずれ、時間が経つにつれて、これはローカルでも実行できる他のモデルにも拡張されるかもしれません。そして、このコネクタには vu と書かれていますが、どこにデプロイされた VU でも使用できます。そして、ええと、VU はローカルにデプロイできます。Kubernetes にデプロイすることもできます。
また、Zillow を使った hosted mil を使用している場合もあります。ですので、ここに来て Zillow URL、Zillow API キー、そして open AI トークンを入力すれば、準備完了です。その後、コネクタを設定できます。現在、これら 2 つのコネクタが、ええと、同期中です。GitHub コネクタは、常に、ええと、GitHub ソースからデータを取得します。ソースアプリケーションに更新があるたびに、ええと、データを下流アプリケーションに取り込みます。
ああ、ちなみに、この例では、tahi というオープンソースリポジトリの一つを使用しています。Tahi は、ええと、非構造化データを非常にシームレスに処理し、エンコードできるオープンソースの、ええと、機械学習フレームワークです。そして、これは完全にオープンソースなので、私が選びました。それが、このサンプルアプリケーションにこれを使うことにした理由です。これには多くの issue があります。open issue は 5 件あるようで、それから、ええと、多くの closed issue があり、それぞれに、顧客や、ええと、ユーザーが遭遇したさまざまな例外や、ユーザーが望むさまざまな機能について話し合う会話があり、そしていくつかのラベルが割り当てられています。
何を、何の課題として適切にタグ付けできるか。そして課題上の会話、解決策の提供または課題に関する更新の提供も含まれます。つまり、GitHub から Snowflake へ同期する five tran コネクタをセットアップすると、ええと、Snowflake アカウント内ですぐにデータを確認できるはずです。ここで見てわかるように、各同期には約35秒かかります。そして、ええと、これらは増分同期です。
そのため、最初の同期には数分かかるかもしれませんが、その後の増分同期は、ほら、非常に短く、とても高速で、前回の同期以降に更新されたデータだけをウェアハウスに取り込みます。そして、ほら、ウェアハウス内のデータにパッチを当てます。なので、このコネクタをセットアップしているので、Snowflake に行き、ええと、自分のデータに行き、そして、ほら、ええと、自分のデータベースで、ああ、テーブルが存在している、と確認できます。GitHub から抽出できるさまざまなテーブルがすべてあります。そしてこの、ほら、この例では、issues 周りのいくつかのテーブルだけに焦点を当てます。
なので、行って確認すると、ほら、私たちの issue テーブルを見ると、issue テーブルにデータが存在していることがわかります。結果として、ええと、約 2. 7 K の issues または行があり、ほら、ええと、おそらく正規化された、ええと、issues のバージョンです。そして、open の issues、closed の issues、特定の issue に関連するすべての詳細があります。同様に、issue comments のようなものもあり、各、ええと、issue に対して、各 issue comment に、その comment の ID があります。
しかしその後、ほら、元のissueを参照する外部キーがあり、それによってこれらのデータセット間で join ができます。そして、ええと、rag を構築するために実際に重要な詳細、つまり body、または issue comment の実際の内容があります。そして、issue の body、issue に対するcomment といくつかの他の metadata を使って、その上に vectors を構築します。そうですね、この connector が動作していて、ええと、これが warehouse に同期されており、各 sync が発生するたびに、ええと、transformation がセットアップされています。つまり、ここで、ええと、私は issue Extended という table を作成する transformation を登録しました。five trend は、ほら、GitHub repository Air Code Restore をアタッチすることで独自の transformation を持ち込むことをサポートしています。
しかし、ええと、quick start data models を提供するだけでもサポートしています。quick starts は Five Trend が構築したこれらさまざまな transformations の templates です。ええと、私たちの repository でそれらを見ることができます。現在 open source ですが、models を使うことも、自分で models を構築することもできます。data DBT model が何か気になる場合、それは単なる SQL、単なる SQL command です。なので、私の GitHubrepository にいくつか SQL commands が書かれており、これも open source です。
必要であればこれを確認できます。私がやっていることの1つは、GitHub data から異なる fields、たとえば、ほら、issue id、issue number、issue の state、それが closed か open か、body、つまり issue の実際の内容、そして issue を作成した user や issue が assigned されている user など他の tables からの metadata を取得していることです。そしてこれらすべてを取り、非常に markdown 風の document に押し込んでいます。これを行っている理由は、これが downstream の、ほら、vector embedding、ええと、models や large language models にとって最も理解しやすいデータ形式だからです。それらはこの種の長い text を非常によく理解できます。
そのため、私たちは semi-structured data を取り、それを unstructured document に変換します。そして、ほら、SQL query を書いて five に登録すると、five は syn Chrons のたびにそれをトリガーします。つまり GitHub schema には、可能な限り raw な形式の source data が含まれており、非常に軽い加工がいくらかされています。そして GitHub for RAG は私が登録した DBT model です。そして、ここに concatenated data が存在していることがわかります。
つまり、idがあり、それから、その内容があります。これは私がこのすべての情報で作成したカラムです。ええと、これを、もう少し拡張された内容として表示できるか見てみましょう。ええと、データベースから戻ってきます。はい。Okay。Logstar issue。
Okay、では今、より完全な形のissueがあります。これは、人間がGitHub上のissueを見たり理解したりする方法と非常によく似ています。メタデータがあり、いくつかのメタデータがあり、エンドユーザーが提示したissueの説明があります。そしてコメントがある場合には、たぶんコメントもあります。なので、これはいくつかコメントがあると思います。
はい、ここにはissueとともにいくつかのコメントがあり、特定の1つのオブジェクトに関するすべての情報が1つのドキュメントに圧縮されていることがわかります。なので、そのような形でデータを持てたら、five tranに戻ることができます。そして、そのデータを、snowflakeや使用している任意のデータリポジトリから、Zillowまたはvusへ、好きな場所にホストされたものへ移動する第2段階のパイプラインを設定できます。必要なのは、認証情報を入力してこのconnectorを設定するだけです。schemaタブでは、どのテーブルをvectorizeしてvuにロードするかを選択できます。
私のSnowflakeインスタンスには、さまざまなテーブルがたくさんありましたが、vectorizeしたいのはこのテーブル、issue extended tableだけです。なので、schemaタブでここに登録しました。そして注意すべき重要な点が1つあります。現在、VUまたはmilli connectorでは、source tableに特定のカラムが存在している必要があります。ええと、そのカラム名は何だったか見てみましょう。Issue extended。
ええと、はい、これらがそのtableのカラムです。そしてMillis connectorは特に、original textという名前のカラムが存在することを必要とします。そしてそれが、vectorsが構築されるカラムです。そして、five front側でテーブルを選択するときに、そのテーブルにそのカラムが存在していることを確認する必要があります。また、それは、ハッシュ化されておらず、ブロックされておらず、string型である必要があります。
もう1つ要件があります。なので、はい、第2のconnectorを設定して、それがモデル化され圧縮されたすべてのGitHubデータをZillowに同期していれば、準備は完了です。semantic searchアプリケーションがすぐ使える状態になります。ではここで私のZillowインスタンスに切り替えます。すると、Zillow上にホストされたVUS clusterを見ることができます。現在はGCP上にホストされていますが、別のcloudにホストするようにも設定できると思います。そしてcollectionがあります。これはfive Tranによって自動的に作成されたcollectionです。
これはSnowflake内のtableと同じschemaを持っています。つまり、source GitHub entityに存在するすべてのカラムが含まれています。そして、ここにすべてのデータが存在しているのがわかります。issue number、issue title、issue bodyなど、issuesに関するすべての詳細があります。そして、vector searchだけ、またはsemantic searchだけをしたい場合は、Zillow dashboard自体からすぐここで実行できます。検索する前にvectorを生成する必要はあります。
そして、Open Eyes embed modelを使っているので、それを生成するための簡単なscriptを書きました。では、Tauに関連する質問をします。ええと、質問してみます。t he supportmultiple GPUs。以前repositoryでその質問を読んだ記憶があります。では、これのvectorを生成してみましょう。
ちなみに、このvectorを生成するためにOpenAI embedding modelを使っています。そしてtext largeを使っています。OpenAIは3つのembedding model、ada、small、largeをサポートしています。この例ではtext largeを使っただけです。ただし、コストを節約する必要がある場合は、多少の品質低下を許容できるなら、より小さいmodelを使うこともできます。
はい、埋め込みが作成されたので、ここに入れて、ええと、検索を押せます。すると今、ええ、私の質問に関連する、上位の検索結果が表示されています。ご覧のとおり、私の質問はGPUに関連していたので、このデータセット内のさまざまな課題の中から、ええ、たとえば、私の質問、つまり、複数のグラフィックカードをサポートしているか、といった内容に関連するものを引き出しています。私のモデルには、ええ、URLもあります。なので、そのURLに行くと、つまり、そこにアクセスするだけで、見たい元のドキュメントが表示されます。つまり、この、ええ、ドキュメントはユーザーの質問について述べています。
この issue は、Tahi で複数のGPUをサポートできるかどうかを尋ねているユーザーの質問について述べています。はい、これで、エンドツーエンドのセマンティック検索アプリケーションを、ええ、数回クリックするだけで構築できました。必要だったクリックコーディングはごくわずかです。データモデリングは自分で行う必要がありましたが、必要なのはそれだけです。そしてそれが、つまり、それが最も重要な部分で、構築しているアプリケーションの種類に対して、ダウンストリームアプリケーションに適した正しいモデルを見極められること、そしてデータモデルに固定されないことです。
ええと、このデータ全体を検索できるようにするために、ソースから見つけることになります。ええ、そして今、可能性は無限です。このセマンティック検索アプリケーションを使って、rag アプリケーションを構築できますし、チャットボットを構築できますし、copi を構築できますし、よりエージェント的なものも構築できます。はい、データがあり、そして、この適切なストレージレイヤーが完全にインデックス化されていれば、その後段でできることは本当にたくさんあります。つまりそれが、ええ、私たちがコネクタを構築し、システムを有効化するために行った作業の大部分であり、ええ、システムがどこまで行けるかというさらなる機能を示すためのものです。
私は、オープンソースの、ええ、stream lit や long chain のようなフレームワークだけを使って、チャットボットを構築しました。このチャットボットは、ええと、Zillow の認証情報を受け取ります。そこには vis がホストされていて、そして、five trying がデータを同期している場所です。では Zillow の認証情報を入力しましょう。ええ、必要なのはエンドポイント、ええ、APIキーで、Zillow のウェブサイトからとても簡単にコピーできます。open AI キーも必要です。
ここに私の open AI キーがあります。ええと、ちなみに、これらの認証情報を入力すると、このアプリケーションは、five Tran を使って同期された Zillow 内のコレクションを自動的に検出します。なので、これらのソースを指定するために追加の設定をする必要は本当にありません。ここに来て、どのソースと、つまり、チャットしたいかを選択するだけでいいです。ええと、私は小さいものではなく、大きいモデルを使います。
そして open AI キーはここにあります。これを入力すると、今、ええと、チャットアプリケーションの準備が整いました。自分の、つまり、TAHI リポジトリに関連する質問をしに行けます。ええと、では、たとえば、one state に質問してみましょう、ええと、どんな質問をすればいいでしょうか?はい、これは、tahi ユーザーによって尋ねられた具体的な質問の別の例です。彼は、ええ、clip model はローカルモデルパスをサポートできますか、と言いました。ええと、結果として、つまり、ええ、それはローカルモデルパスをサポートでき、この、ええと、パラメータを使うことでサポートできます。
ええ、そして、この回答が得られるのは、提供されたナレッジベースからこの情報を見つけることができたからです。そして、ええ、この情報は GitHub 上のこれらの異なる、ええ、チケットの1つに存在しているようなので、最も関連性の高いものを見てみましょう。はい、つまり、最も関連性の高いものは、ユーザーがこの質問、つまり、ローカルモデルパスの使い方を尋ねているもののようです。そして、リポジトリのメンテナーの1人が、それは checkpoint path をポートするものだ、と回答しているのが見えます。つまり、製品に関する会話を通じて、製品について具体的な質問をすることができます。
これにより、さまざまな課題を見に行ったり、さまざまなナレッジソースを見たりする必要がなくなり、自然言語インターフェースだけで、会社のデータ全体を簡単に、本当に簡単に検索できるようになります。ええと、興味があれば、別の質問をしてもいいです。えー、リポジトリには他にどんな面白いものがあるでしょうか?おお、なるほど、メモリリークに関する質問です。メモリリークはいつも興味深いですね。Outof effects、ええと、すみません、outof effects、ええと、メモリリークとオーディオ、そして embed と pipeline です。
また、このアプリケーションでは、ソースを5つだけに制限しています。ええと、というのも、比較的小さな GPT モデルの1つを使っているからです。ただし、使用しているモデルの性能や、どれだけお金を使ってもよいかに応じて、アプリケーションに参照させたいソースの数を増やすことができます。つまり、私は、ええと、メモリリークの修正方法について尋ねたところ、いくつもの手順を返してくれました。それらの手順を理解するために、さまざまなソースを調べていました。そして、最も関連性の高いソースを見てみると、ええと、これはメモリリークと完全に関連しているわけではないかもしれませんが、ここからいくつかの、いくつかの情報を拾ったのだと思います。というのも、ええと、memory のようなものがあるからです。なので、memory、それからもしかすると別の何かが、この後のどこかにあるのかもしれませんが、ああ、そうです、これが私が探していたものです。
つまり、これが実際に質問に関連している issue で、ここではオーディオ埋め込みパイプラインと、メモリリークを防ぐ方法について尋ねています。そして、その会話の中には、ええと、この問題を解決するのに役立つ手順があり、この情報すべてを拾い上げて、それに基づいた自然言語の回答を提供できていました。なので、そうですね、アプリケーションを構築したい対象のデータさえあれば、RAG アプリやチャットアプリを構築する可能性は無限にあります。そして、ええと、最新の Five trend connector が、ええと、mill に同期することで、企業にとってこれがはるかにシームレスに可能になります。もし、これを自分で、このパイプラインを構築して、動作しているか確認したい場合は、このチャットアプリを自分でも試すことができます。
ええと、これはこの URL、five Friends do Streamlet app でホストされています。ええと、ここにアクセスして、Zillow の認証情報を入力するだけです。つまり、これらの Five trend パイプラインをどこに設定した場合でもです。そして、それを設定できれば、ええと、すぐに自分のデータとチャットできるようになり、さらに、これらのアプリケーションが回答内でソースとして引用しているソースにも移動できます。はい、以上です。ええと、私からは以上です。
ええと、このプロジェクトに取り組むのは本当に楽しかったです。ええと、企業が自社データ全体を検索することが、今ではどれほど、どれほど簡単になっているのかを見るのは、私にとってとても興味深いことでした。私たち自身も含めてです。ええと、Five Tran は、社内で RAG アプリを最も活用しているパワーユーザーの1つだと思います。それは、私たちが持っている知識の幅広さによるものです。そして今、Zillow との統合と、VUS Vector database によって、私たちや他の企業がこのようなアプリケーションを構築することが、はるかに簡単になります。ですので、Jang さん、この取り組みの機会をくださって本当にありがとうございます。そして、ええと、今後これをどのように、どのようにさらに拡張していくのかを見るのを楽しみにしています。
ええと、素晴らしい講演をしてくださったABJ、本当にありがとうございました。最後のデモには本当に感銘を受けました。ええと、そして私は、この技術によって、チャットボット、社内向けのナレッジベースのようなものなど、AI、ええと、AIと検索技術を活用した多くの興味深いアプリケーションが可能になると思います。ええと、聴衆の皆さんからいくつか質問をいただいています。ええと、最初の質問は、Five Tranは無料クレジットを提供していますか?というものです。Five Tranは、実際には最初の14日間は無料です。セルフサービスでサインアップして、試すことができます。ええと、最初の、初回同期は無料で、その後アカウント全体で14日間無料になると思います。ええと、その後は、営業チームに相談して、Five Tranで何を構築しようとしているのかを話し合えば、無料クレジットを取得できる可能性があると思います。
でも最初の14日間は完全にセルフサービスです。Five Tranに来て、ええと、クレジットカードを入力する必要があるかどうかさえ、私にはわかりません。たぶんクレジットカードを入力する必要すらないかもしれません。ただ試してみて、自分のニーズに合うかどうか確認できます。はい。
素晴らしいですね。よさそうです。皆さん、ぜひ試してみてください。ええと、2つ目の質問は何ですか?チャットアプリとは何ですか?ええと、聴衆の方はチャットアプリのリンクを求めていたのだと思います。ああ、そうですね。
リンクはこちらです。Five TrendzRag Stream appです。ええと、すでにデプロイされているので、試すことができます。ええと、このアプリケーションの下流にデータを供給できるようにするには、まずそれらのパイプラインを設定する必要があります。そうですね、もしあなたが、もしあなたが、もしすでにFive Frontのお客様であれば、とても馴染みがあるはずです。そうでなければ、ええと、このプレゼンテーションで説明した手順に従って、それらのパイプラインを設定できます。
はい、では、ええと、ではその、ええと、実際には私が、チャットにリンクを送ることができます。では、どうぞ。ええと、聴衆からの質問はこれですべてだと思いますし、時間もちょうどです。では改めて、ABJ、この素晴らしい統合と、そしてここでの見事なデモを発表してくださり、ありがとうございました。ええと、そして、これに興味のある方のために、チャットにリンクを載せています。ええと、ABJがここで先ほど紹介したチャットアプリに関する統合についてのリンクです。
ええと、また、もしこの技術についてもっと知りたい方がいれば、ZIのcontact salesまたはDemo five 20を通じて、私たちの営業チームにお気軽にお問い合わせください。私たちは、ええと、その技術のセットアップを支援し、そして、あなたの、あなたのバスを、ええと、あなたのビジネスをAIとVector Searchで強化するお手伝いを喜んでいたします。では改めてありがとうございます、ab just、ええと、このウェビナーではそれがすべてになると思います。皆さん、ご参加ありがとうございました。ええと、私たちと一緒に、皆さんからご連絡をいただけることを願っています。
ええと、また、今後のイベント、リンク、リソースもぜひご確認ください。ええと、今後のウェビナーへのご参加も歓迎します。では皆さん、ありがとうございました。良い一日を。どうもありがとうございました。バイバイ。

Join the Webinar
Loading...
Meet the Speaker
Join the session for live Q&A with the speaker

Abhijeeth Padarthi
Staff Research and Development Engineer, Fivetran
Abhijeeth Padarthi is a member of the CTO's Office at Fivetran, with over 5 years of experience in building data pipelines and data lakes. He focuses on leveraging AI to help businesses easily search across their datasets, driving innovation in data accessibility and integration.