




Osservabilità: Tracciare oltre il monitoraggio
Osservabilità: Tracciare oltre il monitoraggio
Che cos'è l'osservabilità?
Osservabilità significa capire cosa sta accadendo all'interno di un sistema in base ai dati che produce. Si tratta della capacità di "guardare dentro" un sistema software e di comprenderne lo stato e il comportamento. Aiuta a rispondere a domande come: "Tutto funziona come previsto?" o "Perché qualcosa va storto?". Invece di tirare a indovinare la causa dei problemi, l'osservabilità fornisce chiari approfondimenti attraverso dati come log, metriche e tracce.
Perché l'osservabilità è importante?
I sistemi software moderni stanno diventando sempre più complessi. Con l'avvento di tecnologie come i microservizi, il cloud computing e la containerizzazione, i sistemi sono ora costituiti da molte parti interconnesse che possono essere sparse in luoghi diversi. Questo rende difficile il monitoraggio e la risoluzione dei problemi.
Gli strumenti di monitoraggio tradizionali spesso non sono all'altezza: possono dire che qualcosa non va, ma non perché. Observability colma questa lacuna fornendo visibilità sullo stato interno dei sistemi per identificare rapidamente i problemi.
I pilastri fondamentali di Observability
Observability ha tre pilastri che lavorano insieme per fornire un quadro chiaro di ciò che accade all'interno di un sistema. Vediamo di suddividerli:
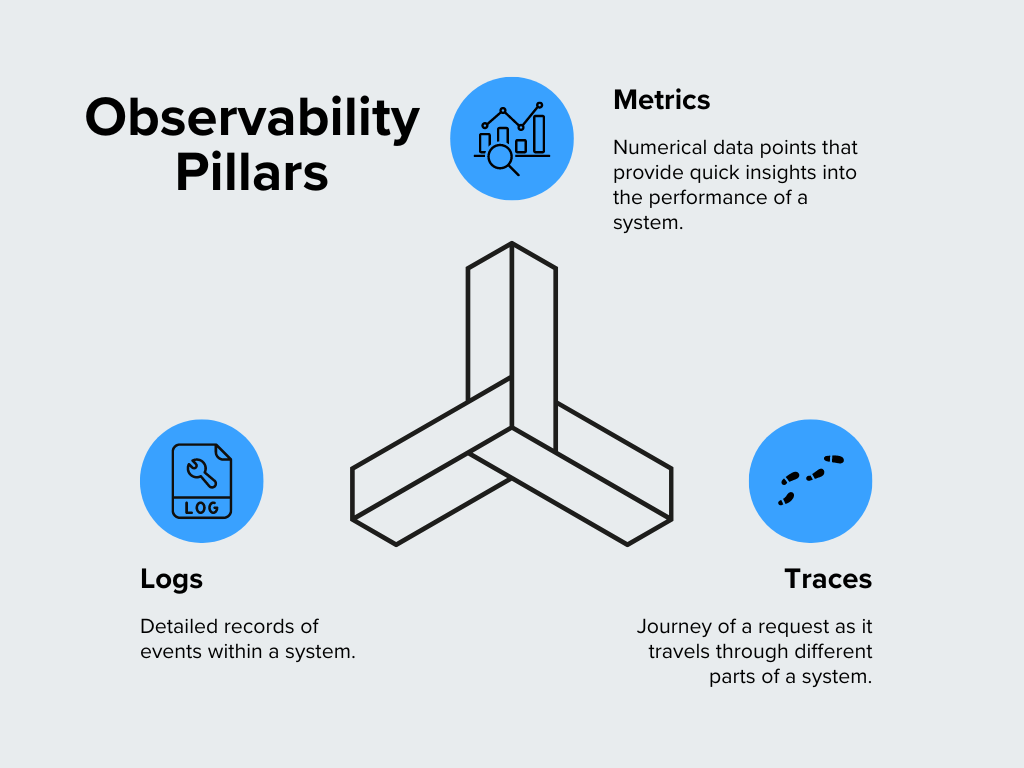 Figura- Pilastri dell'Osservabilità.png
Figura- Pilastri dell'Osservabilità.png
Figura: Pilastri dell'osservabilità
Metriche
**Le metriche sono punti di dati numerici che forniscono una rapida visione delle prestazioni di un sistema ** Sono i segni vitali del sistema che mostrano il suo funzionamento. Le metriche più comuni includono l'uso della CPU, il consumo di memoria, la velocità di richiesta e i tempi di risposta. Ad esempio, se si nota un picco insolito nell'utilizzo della CPU, questo può indicare un problema che richiede attenzione. Le metriche sono ottime per identificare le tendenze e vedere come si comporta un sistema nel tempo.
Registri
**I log sono registri dettagliati degli eventi all'interno di un sistema ** Pensate a loro come a un diario che cattura ciò che accade all'interno del vostro software. Ogni volta che si verifica un errore, un utente si collega o una transazione viene elaborata, di solito viene registrato in un log. I registri forniscono un contesto per la diagnosi dei problemi e la comprensione del comportamento del sistema. Ad esempio, quando qualcosa va storto, i registri possono aiutare a individuare ciò che è accaduto subito prima e dopo il problema.
Tracce
**In una configurazione complessa con più servizi che lavorano insieme, una traccia mostra il percorso di una singola richiesta e quanto tempo trascorre in ogni servizio. Le tracce identificano i colli di bottiglia o i ritardi nel processo. Se una richiesta impiega più tempo del previsto, le tracce possono aiutare a capire dove si verifica il rallentamento.
Come funziona l'osservabilità?
L'osservabilità segue alcune fasi importanti. Ecco come funziona:
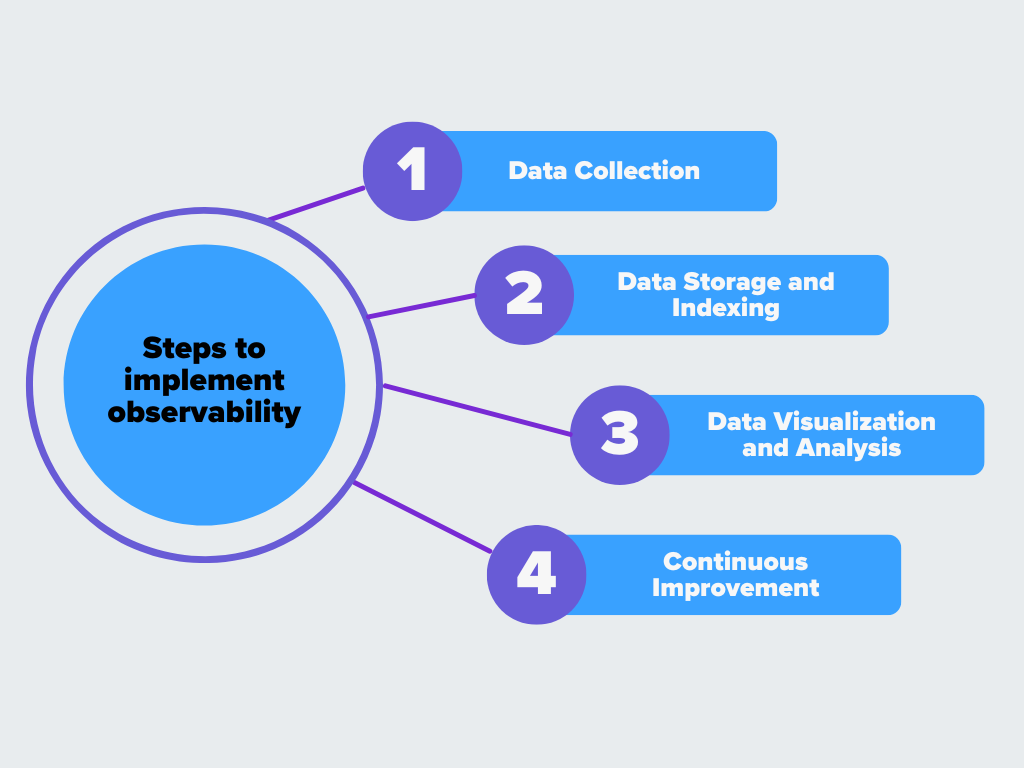 Figura- Passi per implementare l'osservabilità.png
Figura- Passi per implementare l'osservabilità.png
Figura: Passi per implementare l'osservabilità
Raccolta dei dati
Il primo passo è la raccolta di dati da tutte le parti del sistema. Questo include la raccolta di metriche (come
utilizzo della CPU), log (registrazioni dettagliate degli eventi) e tracce (il percorso delle richieste attraverso i servizi). L'obiettivo è catturare tutto ciò che può offrire informazioni sulle prestazioni, sui problemi o sul comportamento generale del sistema. Questi dati provengono da varie fonti, come server, applicazioni, database e interazioni degli utenti.
Archiviazione e indicizzazione dei dati
Una volta raccolti, i dati devono essere archiviati in modo efficiente. Un'archiviazione adeguata consente di trovare e utilizzare rapidamente i dati quando servono. L'indicizzazione dei dati aiuta a cercare e recuperare più rapidamente informazioni specifiche. Ad esempio, quando si verifica un problema, i tecnici devono essere in grado di recuperare facilmente i log o le metriche relative all'incidente senza ritardi. Le buone pratiche di archiviazione sono fondamentali per mantenere i dati organizzati e accessibili.
Visualizzazione e analisi dei dati
Raccogliere i dati è una cosa, ma dargli un senso è un'altra. Gli strumenti di visualizzazione e i dashboard svolgono un ruolo fondamentale in questo senso. Trasformano i dati grezzi in grafici, diagrammi e avvisi di facile comprensione. La visualizzazione aiuta i team a vedere rapidamente le tendenze, gli schemi o qualsiasi comportamento insolito nel sistema. I cruscotti consentono di individuare facilmente i problemi di prestazioni e di approfondire i dettagli se qualcosa non quadra. I sistemi di allerta possono anche notificare ai team in tempo reale quando le metriche superano determinate soglie o si verificano errori.
Miglioramento continuo
I dati provenienti dall'osservabilità non servono solo a risolvere i problemi, ma anche a migliorare il sistema. Esaminando regolarmente i dati raccolti, i team possono identificare le aree da migliorare o ottimizzare. Il ciclo di feedback continuo incorpora miglioramenti in modo che il sistema funzioni in modo più efficiente. I dati di osservabilità possono guidare le decisioni sul ridimensionamento delle risorse, migliorando l'esperienza dell'utente e prevenendo problemi futuri.
Casi d'uso dell'Osservabilità
L'osservabilità ha un forte impatto sulle applicazioni del mondo reale. Ecco alcuni casi d'uso pratici che mostrano come l'osservabilità faccia la differenza:
Monitoraggio delle prestazioni nei sistemi distribuiti
I problemi di prestazioni possono essere difficili da identificare in un sistema distribuito con più servizi che lavorano insieme. Observability aiuta fornendo metriche, log e tracce che forniscono un quadro chiaro di come interagiscono i diversi servizi. Ad esempio, se un singolo microservizio rallenta l'intera applicazione, gli strumenti di observability possono evidenziare rapidamente quale servizio sta causando il ritardo.
Debug e risoluzione dei guasti
Quando un sistema si rompe, i team devono capire cosa è andato storto. Observability rende questo processo molto più semplice, fornendo log e tracce dettagliate degli eventi. Per esempio, se un server si blocca o una richiesta non va a buon fine, i log possono mostrare esattamente cosa è successo prima del guasto. Le tracce aiutano i team a vedere come il problema si sposta tra i diversi servizi.
Affidabilità e disponibilità
L'osservabilità svolge un ruolo importante nel raggiungimento degli obiettivi di livello di servizio (SLO) e degli accordi di livello di servizio (SLA). Si tratta di impegni relativi all'affidabilità e alla disponibilità di un sistema. Tenendo traccia dello stato di salute del sistema attraverso metriche e avvisi, i team possono raggiungere questi obiettivi. Ad esempio, se i tempi di risposta iniziano a rallentare, l'osservabilità aiuta i team ad agire prima che gli utenti ne risentano, mantenendo un servizio affidabile.
Pianificazione e scalabilità della capacità
Quando i sistemi crescono, hanno bisogno di più risorse, come i server o la memoria. L'osservabilità aiuta a pianificare la capacità tracciando le metriche che mostrano come viene utilizzato il sistema. Ad esempio, il monitoraggio dell'uso della CPU o del carico del database nel tempo può aiutare a prevedere quando è necessaria una maggiore capacità. Con la pianificazione e la scalabilità della capacità, il sistema funziona bene senza sorprese.
Rilevamento proattivo dei problemi
Uno dei migliori usi dell'osservabilità è quello di individuare i problemi prima che diventino gravi. Il monitoraggio e gli avvisi in tempo reale consentono ai team di rilevare modelli o picchi insoliti, come l'aumento dei tassi di errore o dei tempi di risposta. L'approccio proattivo può prevenire i tempi di inattività e mantenere un'esperienza utente fluida. Ad esempio, se gli strumenti di osservabilità rilevano tempestivamente una perdita di memoria, i team possono risolverla prima che il sistema si blocchi.
Monitoraggio dell'esperienza utente
L'osservabilità non riguarda solo il backend; può anche tracciare le interazioni e il comportamento degli utenti. Il monitoraggio delle metriche relative all'esperienza utente, come i tempi di caricamento delle pagine, i tempi di risposta dei pulsanti e i messaggi di errore, aiuta i team a identificare e risolvere rapidamente i problemi legati all'utente. Ad esempio, se una nuova funzionalità causa un rallentamento del caricamento delle pagine, i dati di Observability lo mostreranno subito.
Ottimizzazione dei costi negli ambienti cloud
Gli ambienti cloud spesso prevedono una tariffazione pay-as-you-go, ovvero vengono addebitate le risorse utilizzate. L'osservabilità può aiutare i team a ottimizzare i costi tracciando quali parti del sistema utilizzano la maggior parte delle risorse. Ad esempio, se un determinato microservizio consuma una grande quantità di larghezza di banda, gli strumenti di osservabilità possono individuarlo, consentendo al team di ottimizzare o rifattorizzare il servizio per ridurre i costi.
Strumenti e tecnologie per l'osservabilità
Prometheus](https://prometheus.io/) è uno strumento di monitoraggio open-source che raccoglie e memorizza le metriche come serie di dati temporali. È ampiamente utilizzato per il monitoraggio delle prestazioni di sistemi e applicazioni grazie alle sue flessibili capacità di interrogazione.
Grafana](https://grafana.com/) è uno strumento di visualizzazione spesso abbinato a Prometheus. Crea dashboard interattivi che aiutano a visualizzare le metriche di Prometheus, a interpretare facilmente i dati, a monitorare le tendenze e a impostare avvisi per il comportamento del sistema.
Jaeger](https://www.jaegertracing.io/) è uno strumento di tracciamento distribuito che aiuta a tracciare le richieste mentre scorrono attraverso i microservizi. Aiuta anche a tracciare le latenze e a identificare i colli di bottiglia in sistemi complessi e distribuiti.
AWS CloudWatch](https://aws.amazon.com/cloudwatch/) è lo strumento di monitoraggio e osservabilità di Amazon che tiene traccia delle metriche, raccoglie i log e fornisce avvisi per le risorse cloud AWS. Si integra bene con altri servizi AWS per monitorare e gestire l'infrastruttura.
Google Cloud Monitoring offre visibilità sulle applicazioni e sui servizi in esecuzione su Google Cloud. Offre metriche, dashboard e avvisi per monitorare lo stato e le prestazioni delle risorse cloud.
Azure Monitor](https://azure.microsoft.com/en-us/products/monitor) è uno strumento che fornisce un'osservazione completa delle risorse e delle applicazioni cloud di Azure. Raccoglie metriche, registri e tracce per aiutare i team ad analizzare le prestazioni e a risolvere rapidamente i problemi.
I moderni strumenti di osservabilità utilizzano l'intelligenza artificiale e l'apprendimento automatico per rilevare le anomalie e prevedere i problemi futuri. Questi strumenti avanzati possono identificare automaticamente gli schemi e avvisare i team di comportamenti insoliti.
Sfide dell'osservabilità
Scalabilità e volume dei dati
La raccolta, l'archiviazione e l'elaborazione di grandi quantità di metriche, log e tracce può diventare impegnativa in un sistema in crescita. Una gestione efficiente dei dati e soluzioni di archiviazione scalabili sono fondamentali per gestire questa crescita.
Sovraccarico di dati
Una quantità eccessiva di dati può sopraffare i team e rendere difficile trovare spunti utili. Per evitare il rumore, è importante filtrare e concentrarsi sui dati utilizzabili che aiutano direttamente a diagnosticare e risolvere i problemi, piuttosto che tenere traccia di ogni dettaglio minore.
Integrazione tra i servizi
I sistemi moderni utilizzano spesso più strumenti e componenti. Un'adeguata integrazione è necessaria per mantenere la perfetta osservabilità tra questi diversi servizi. Senza di essa, si possono perdere informazioni critiche e si può perdere tempo a passare da uno strumento all'altro.
Migliori pratiche di osservabilità
Per sfruttare al meglio i vantaggi dell'osservabilità, assicuratevi di seguire le migliori pratiche come:
Costruire pensando all'osservabilità
Fin dall'inizio, progettate i sistemi in modo che siano facilmente osservabili. Incorporate metriche, log e tracce nella vostra architettura per facilitare il monitoraggio e la comprensione del comportamento del sistema. Questo approccio proattivo semplifica la risoluzione dei problemi e la messa a punto delle prestazioni.
Visione unificata tra i sistemi
Consolidate tutti i dati di osservabilità in un'unica piattaforma o dashboard. Una vista unificata aiuta i team a identificare rapidamente i problemi e a ottenere una comprensione olistica di come interagiscono i diversi servizi, riducendo il tempo speso per mettere insieme le informazioni provenienti da più fonti.
Strategie di allerta e notifica
Impostate avvisi che siano chiari, significativi e perseguibili. Evitate la stanchezza degli avvisi, concentrandovi solo su eventi critici legati ad azioni specifiche e necessarie. L'obiettivo è informare efficacemente il team, non sommergerlo di rumore.
Osservabilità vs. Monitoraggio
Anche se spesso vengono citati insieme, osservabilità e monitoraggio non sono la stessa cosa. La tabella seguente evidenzia le principali differenze tra i due:
| Aspetto | Osservabilità | Monitoraggio |
|---|---|---|
| Scopo | Fornisce una comprensione più approfondita dello stato interno del sistema. | Traccia metriche specifiche per rilevare problemi o anomalie. |
| Dati raccolti | Raccoglie metriche, registri e tracce per un'analisi dettagliata. | Raccoglie metriche predefinite come l'uso della CPU, la memoria e gli errori. |
| Approccio | Esplorativo; aiuta a capire "perché" si è verificato un problema. | Reattivo; notifica quando si verifica un problema noto. |
| Ambito di applicazione | Si concentra sul comportamento generale del sistema e sulle prestazioni. | Si concentra sulle singole metriche per misurare la salute del sistema. |
| Risoluzione dei problemi | Aiuta a identificare rapidamente i problemi sconosciuti e le cause principali. | Avverte di problemi noti, ma può mancare il contesto per un'analisi più approfondita. |
| Analisi in tempo reale | Supporta l'analisi dei dati in tempo reale per monitorare il comportamento del sistema. | Si basa su controlli e soglie preimpostati, spesso con un contesto ritardato. |
| Flessibilità dei dati | Consente un'esplorazione flessibile e approfondita dei dati al di là delle metriche predefinite. | Monitora metriche specifiche e preselezionate senza un contesto più ampio. |
Differenze di osservabilità e monitoraggio
Osservabilità in Milvus e Zilliz Cloud: Tracciare le prestazioni del database vettoriale
Milvus è un database vettoriale open-source progettato per gestire in modo efficiente dati non strutturati su scala miliardaria. È ideale per applicazioni di ricerca semantica, ricerca di similarità e GenAI. L'osservabilità svolge un ruolo cruciale nella gestione e nell'ottimizzazione delle prestazioni di Milvus. Utilizzando le pratiche di osservabilità, potete assicurarvi che il vostro database vettoriale funzioni in modo fluido ed efficace, sia che si tratti di raccomandazioni in tempo reale o di attività di retrieval-augmented generation (RAG) .
L'open-source Milvus integra Prometheus per monitorare le sue prestazioni e Grafana per visualizzare tutte le metriche. Milvus si integra perfettamente con Prometheus attraverso:
Prometheus Endpoint: Raccoglie i dati da vari esportatori.
Operatore Prometheus: Semplifica la gestione delle impostazioni di monitoraggio di Prometheus.
Kube-Prometheus: Semplifica il monitoraggio completo del cluster Kubernetes per un funzionamento robusto.
Con Prometheus, è possibile monitorare le metriche critiche delle prestazioni di Milvus, come i tempi di risposta delle query e l'utilizzo delle risorse (CPU, GPU e memoria), consentendo la risoluzione proattiva dei problemi e l'ottimizzazione del sistema. Inoltre, l'integrazione di Prometheus con Grafana migliora ulteriormente il quadro di monitoraggio, fornendo cruscotti dettagliati per un'analisi approfondita e una manutenzione efficiente delle implementazioni Milvus personalizzate per le applicazioni GenAI e similarity search.
Per una guida completa sulla configurazione di Prometheus per Milvus e sulla visualizzazione delle metriche con Grafana, esplorate le risorse qui sotto:
Zilliz Cloud è la versione gestita di Milvus con funzioni più avanzate e prestazioni 10 volte superiori. Offre funzionalità di monitoraggio e osservabilità ancora più chiare e semplici. Zilliz Cloud ha recentemente introdotto solide funzionalità di monitoraggio e osservabilità per aiutare gli utenti a monitorare le prestazioni dei database vettoriali. Il dashboard Metrics fornisce una panoramica della salute del cluster, compreso l'utilizzo delle risorse (CPU, memoria, storage), le prestazioni (QPS, VPS, latenze) e le metriche dei dati (raccolta e conteggio delle entità), tutte personalizzabili per un'analisi più approfondita. La dashboard presenta le metriche in modo molto intuitivo per una rapida comprensione.
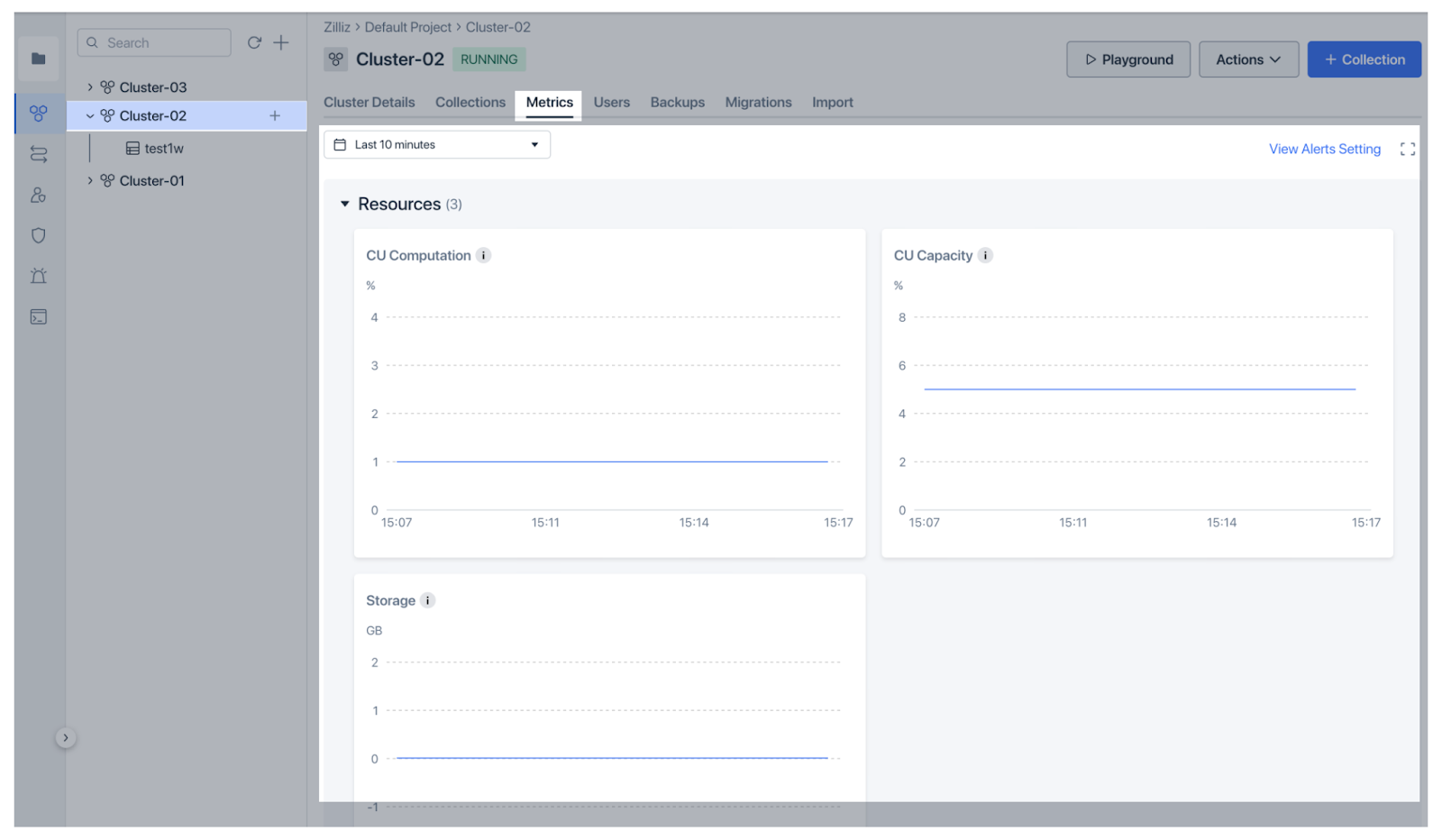 Figura: Metriche di monitoraggio del cloud di Zilliz
Figura: Metriche di monitoraggio del cloud di Zilliz
Figura: Metriche di monitoraggio del cloud di Zilliz
Per individuare tempestivamente i problemi, Zilliz Cloud offre Avvisi di organizzazione per questioni di fatturazione e Avvisi di progetto per fattori operativi come l'utilizzo della CU e la latenza, con soglie e impostazioni di gravità flessibili.
Figura: Avvisi di organizzazione in Zilliz Cloud](https://assets.zilliz.com/Figure_2_Screenshot_of_Organization_Alerts_493efb0dbc.png)
Figura: Avvisi dell'organizzazione in Zilliz Cloud
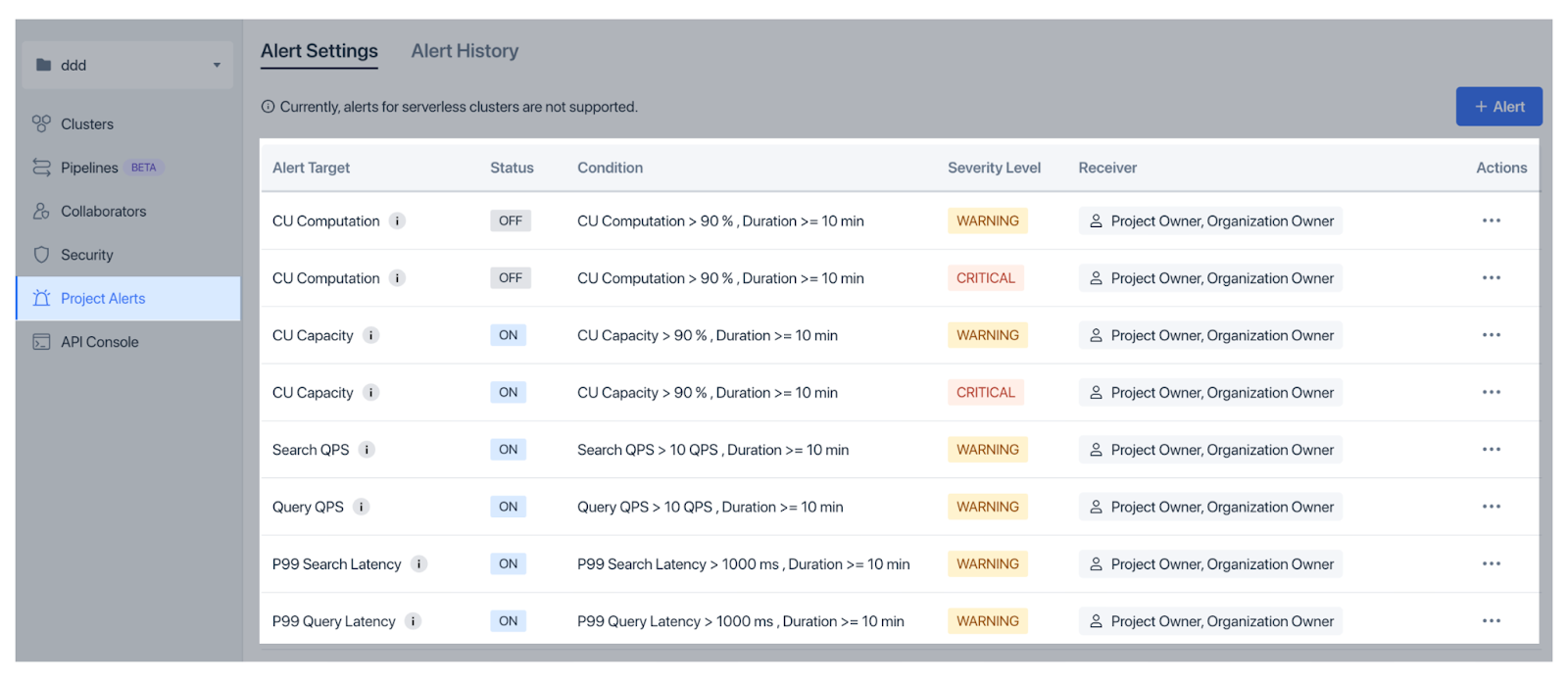 Figura: Avvisi di progetto in Zilliz Cloud
Figura: Avvisi di progetto in Zilliz Cloud
Figura: Avvisi di progetto in Zilliz Cloud
Caratteristiche principali
Monitoraggio in tempo reale** per un feedback immediato sulle prestazioni del cluster.
Dashboard personalizzabili** su misura per le vostre metriche chiave.
Avvisi flessibili** per il rilevamento tempestivo di potenziali problemi.
Canali di notifica multipli** (e-mail, Slack, PagerDuty).
Dati storici** per analizzare le tendenze delle prestazioni e pianificare a lungo termine.
Conclusione
L'osservabilità è un approccio per comprendere e mantenere la salute dei sistemi moderni e complessi. Utilizzando metriche, log e tracce, i team possono garantire prestazioni affidabili, risolvere rapidamente i problemi e migliorare l'esperienza degli utenti. Con la crescita e l'evoluzione dei sistemi, l'adozione delle migliori pratiche di osservabilità è importante per prevenire i problemi e scalare in modo efficiente. Sia che si gestiscano microservizi distribuiti o che si costruiscano applicazioni guidate dall'intelligenza artificiale con strumenti come Milvus, l'osservabilità fornisce la visibilità necessaria per far funzionare tutto in modo fluido e affidabile.
Domande frequenti sull'osservabilità
L'osservabilità è la pratica di comprendere lo stato interno di un sistema raccogliendo e analizzando dati come metriche, log e tracce. È importante per diagnosticare i problemi, monitorare le prestazioni e mantenere l'affidabilità del sistema, soprattutto nelle moderne configurazioni complesse come i microservizi e le applicazioni cloud-native.
Mentre il monitoraggio tiene traccia di metriche specifiche per rilevare i problemi, l'osservabilità va più in profondità fornendo approfondimenti sul "perché" di tali problemi. Il monitoraggio è come una lista di controllo, mentre l'osservabilità è come un'indagine completa sul comportamento e sullo stato del sistema.
I tre pilastri dell'osservabilità sono le metriche (dati numerici sulle prestazioni del sistema), i log (registrazioni dettagliate degli eventi) e le tracce (percorsi delle richieste attraverso i servizi). L'insieme di questi elementi offre una visione completa della salute e delle prestazioni di un sistema.
Perché l'osservabilità è essenziale per i sistemi distribuiti? ** I sistemi distribuiti, come quelli costruiti su microservizi o piattaforme cloud, hanno più componenti che interagiscono tra loro. L'osservabilità aiuta a monitorare e a eseguire il debug dei problemi tra questi componenti, rendendo più facile tracciare i problemi di prestazioni, identificare i colli di bottiglia e mantenere la salute del sistema.
Risorse aggiuntive
- Che cos'è l'osservabilità?
- Perché l'osservabilità è importante?
- I pilastri fondamentali di Observability
- Come funziona l'osservabilità?
- Casi d'uso dell'Osservabilità
- Strumenti e tecnologie per l'osservabilità
- Sfide dell'osservabilità
- Migliori pratiche di osservabilità
- Osservabilità vs. Monitoraggio
- Osservabilità in Milvus e Zilliz Cloud: Tracciare le prestazioni del database vettoriale
- Conclusione
- Domande frequenti sull'osservabilità
- Risorse aggiuntive
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente