




Fuzz Testing Explained: Scoprire le falle nascoste nel software

TL; DR: Il fuzz testing (o fuzzing) è una tecnica di test del software che immette grandi quantità di dati casuali o inaspettati ("fuzz") in un programma per identificare bug, crash o vulnerabilità. Mostrando come il sistema si comporta in condizioni inaspettate, il fuzz testing aiuta a scoprire casi limite, falle di sicurezza e punti deboli che i test tradizionali potrebbero ignorare. È comunemente usato per migliorare l'affidabilità e la sicurezza del software, in particolare nei sistemi che elaborano input complessi come i servizi web, i parser di file e le API.
Fuzz Testing Explained: Scoprire le falle nascoste nel software
Cos'è il Fuzz Testing?
Il Fuzz Testing è un metodo di test del software che trova bug nascosti inserendo dati inaspettati o casuali in un programma per vedere come risponde. Provocando deliberatamente situazioni insolite o "confuse", questa tecnica di test scopre vulnerabilità che i normali test potrebbero non notare, soprattutto in software complessi o sensibili alla sicurezza.
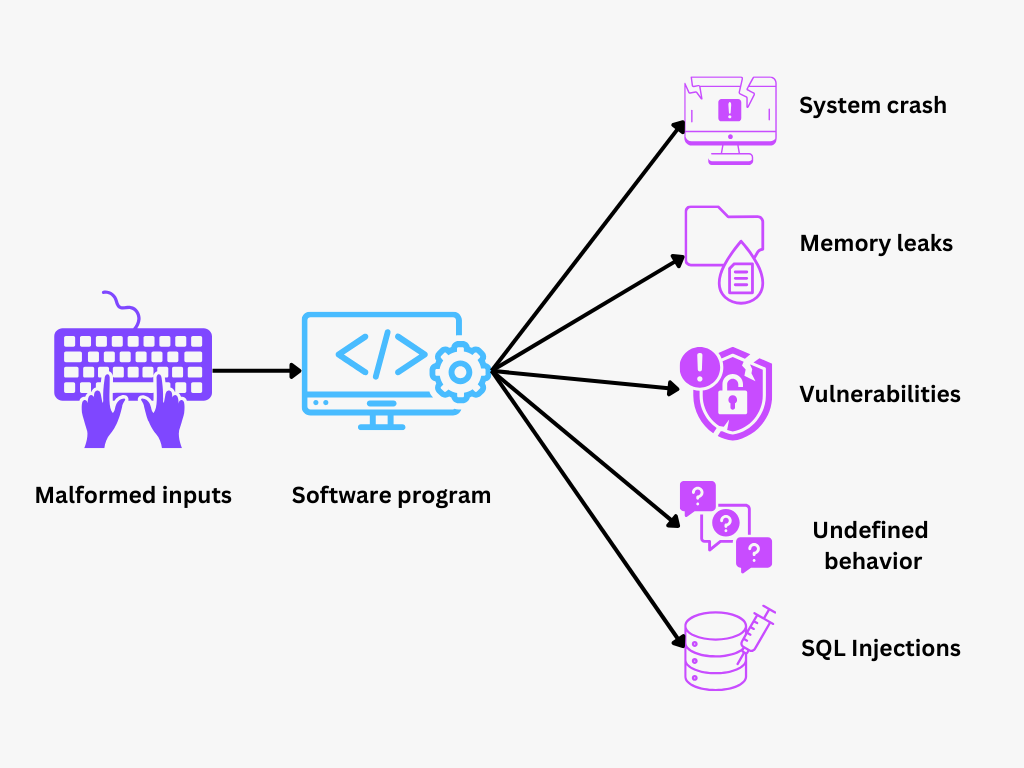 Figura- Fuzz Testing.png
Figura- Fuzz Testing.png
Figura: Test Fuzz
Storia del Fuzz Testing
Il Fuzz testing è nato come una scoperta accidentale alla fine degli anni '80. Il professor Barton Miller dell'Università del Wisconsin stava sperimentando programmi informatici in rete quando notò dei crash inaspettati causati da un rumore casuale in ingresso. Questo lo portò a indagare ulteriormente, inserendo intenzionalmente dati casuali in vari programmi per osservarne le reazioni. Trovò molte applicazioni vulnerabili a questi input casuali, rivelando debolezze di sicurezza e problemi di stabilità. Il lavoro di Miller ha gettato le basi del fuzz testing, affermandolo come metodo efficace per scoprire bug e vulnerabilità del software.
Come funziona il Fuzz Testing?
Il fuzz testing immette dati casuali, inaspettati o non validi (input "fuzzati") in un programma per valutarne il comportamento e scoprire potenziali bug. Questo approccio forza il programma in stati imprevedibili, spesso rivelando bug o vulnerabilità che i test tradizionali potrebbero non notare. L'idea è quella di vedere come un software sano resista alle sollecitazioni di input inattesi, senza bloccarsi o comportarsi in modo inaspettato.
Fasi del Fuzz Testing
Il processo di fuzz testing consiste in fasi che guidano l'identificazione, il test e l'analisi dei problemi all'interno di un sistema target.
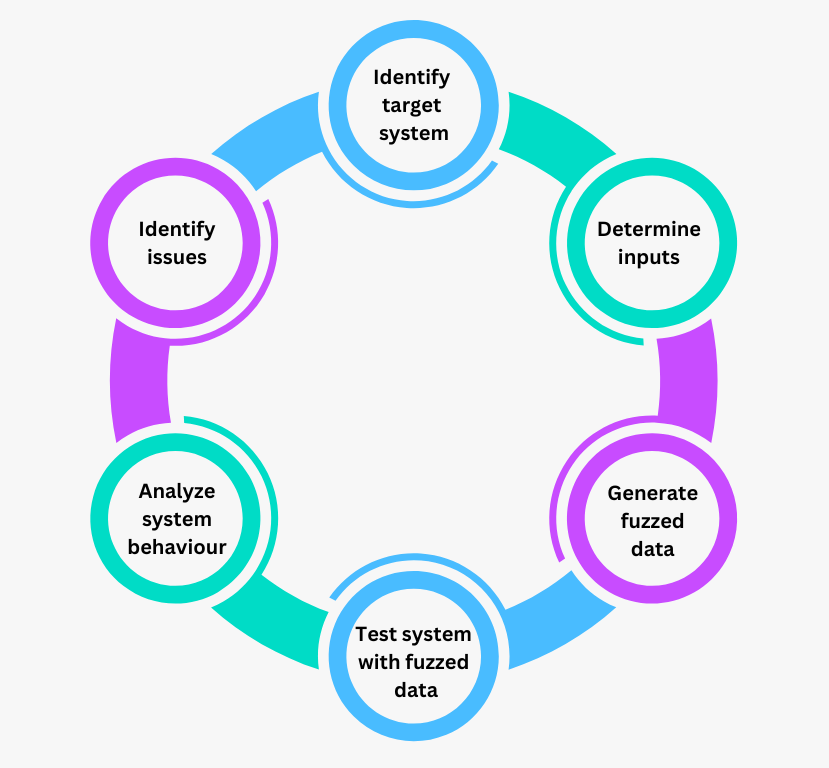 Figura- Fasi del Fuzz testing.png
Figura- Fasi del Fuzz testing.png
Figura: Fasi del test Fuzz
Identificare il sistema di destinazione
Il primo passo del fuzz testing consiste nello scegliere il programma o il componente che si desidera testare. Può trattarsi di un'applicazione, di una funzione all'interno di un sistema più ampio o anche di un campo di input specifico.
Determinare gli input
Una volta identificato il sistema di destinazione, il passo successivo consiste nel decidere il tipo di input da testare. Ciò implica la comprensione dei formati di dati o dei tipi di input che il sistema tipicamente gestisce. Ad esempio, se il sistema di destinazione elabora pacchetti di rete, gli input potrebbero essere costituiti da varie strutture di pacchetti. I tester gettano le basi per la creazione di dati fuzzy rilevanti definendo gli input pertinenti.
Generare dati fuzzy
In questa fase, il motore di fuzzing crea una serie di input inattesi o non validi. Questi input possono essere generati casualmente, forme mutate di dati validi o sequenze create ad arte per simulare casi limite. L'obiettivo è produrre input che possano mettere alla prova i limiti del sistema di destinazione per individuare eventuali punti deboli nella gestione dei dati inattesi.
Sistema di test con dati fuzzy
A questo punto, i dati fuzzati generati vengono immessi nel sistema di destinazione. Durante questa fase, il sistema interagisce con ogni ingresso e risponde a dati insoliti o non validi. Grazie all'esposizione ripetuta del sistema a diversi input, il fuzz testing rivela i punti in cui il sistema non risponde correttamente o si blocca.
Analizzare il comportamento del sistema
Mentre il sistema elabora ogni input, il suo comportamento viene monitorato attentamente. I tester cercano segni di attività anomala, come arresti anomali, comportamenti non reattivi o messaggi di errore inaspettati. Questa fase aiuta a identificare le vulnerabilità o le potenziali debolezze che potrebbero essere sfruttate in uno scenario reale.
Identificare i problemi
Infine, tutte le anomalie rilevate durante i test vengono esaminate per determinare se indicano problemi reali. I tester analizzano il comportamento osservato utilizzando strumenti di debug, per identificare la causa principale di ogni guasto.
Tipi di Fuzz Testing
Il fuzz testing si presenta in varie forme, ciascuna con strategie e applicazioni distinte. Ecco una panoramica dei principali tipi e categorie di fuzz testing:
1. Fuzzing basato sull'input
Questo tipo di fuzzing si concentra sulla generazione di vari input per verificare come un programma gestisce dati diversi. Comprende due approcci principali:
Questo metodo altera i campioni di dati esistenti apportando modifiche casuali. Ad esempio, il fuzzing basato su mutazioni potrebbe aggiungere caratteri inaspettati, scambiare sezioni o cambiare valori se l'input è un file di testo. L'idea è quella di prendere input noti e validi e creare nuove versioni leggermente "mutate", che possono rivelare le vulnerabilità mantenendo una certa somiglianza con i dati realistici.
A differenza del fuzzing basato sulla mutazione, il fuzzing basato sulla generazione costruisce gli input da zero. Utilizza regole e strutture predefinite per creare nuovi dati che imitano formati o protocolli specifici. Ad esempio, il fuzzing basato sulla generazione potrebbe costruire file XML con varie strutture, tag e valori di attributi per testare un parser XML.
2. Fuzzing consapevole della struttura
Il fuzzing structure-aware comprende la struttura sottostante dei dati da testare. Invece di fornire dati casuali o mutati, mantiene il formato corretto o la struttura del protocollo pur variando il contenuto.
- Un'applicazione tipica del fuzzing strutturato, il fuzzing di protocollo viene utilizzato per testare i protocolli di rete generando input conformi a standard di comunicazione specifici (come HTTP o TCP/IP).
3. Fuzzing guidato dalla copertura
Il fuzzing guidato dalla copertura utilizza il feedback dell'esecuzione del programma per generare nuovi input. Traccia le metriche di copertura del codice per identificare quali parti del codice sono state eseguite con ogni input, quindi crea input che mirano a coprire percorsi di codice non testati. Questo approccio è molto efficace per ottenere test approfonditi, in quanto massimizza la copertura del codice, aumentando le possibilità di scoprire bug e vulnerabilità nascoste.
4. Fuzzing black-box, white-box e gray-box
Queste categorie si differenziano in base alla quantità di informazioni che il tester ha sul software di destinazione:
Nel fuzzing black-box il tester non ha alcuna conoscenza interna del programma. Gli input sono generati in modo casuale e inseriti nel software senza considerare la struttura o il codice del programma. Il fuzzing black-box è semplice da configurare e non richiede il codice sorgente. Aiuta a testare le applicazioni closed-source, anche se potrebbe non scoprire tanti problemi come altri metodi.
Il tester ha pieno accesso al codice sorgente del programma nel fuzzing white-box. Ciò consente al processo di fuzzing di indirizzare parti specifiche del codice, utilizzando tecniche come l'analisi statica e il tracciamento del flusso di controllo per guidare la generazione degli input. Il fuzzing white-box è più preciso e può scoprire bug complessi, ma richiede una conoscenza dettagliata del codice, il che lo rende più dispendioso in termini di risorse.
Il fuzzing gray-box rappresenta un equilibrio tra gli approcci black-box e white-box. I tester hanno un accesso parziale al funzionamento interno del programma, in genere attraverso una strumentazione che fornisce un feedback sulla copertura del codice. Questo approccio beneficia dell'efficienza del fuzzing black-box con l'aggiunta della guida della copertura del codice.
5. Fuzzing ibrido
Il fuzzing ibrido combina più strategie di fuzzing per migliorare la profondità e l'efficienza dei test. Ad esempio, potrebbe fondere il fuzzing basato sulle mutazioni con tecniche guidate dalla copertura per massimizzare la copertura del codice ed esplorare una gamma più ampia di variazioni di input. In questo modo, i tester possono analizzare software complessi con maggiore accuratezza per trovare vulnerabilità che potrebbero non essere individuate da un singolo metodo di fuzzing.
Casi d'uso del Fuzz Testing
Il fuzz testing trova diverse applicazioni in tutti i settori industriali, soprattutto in quelli in cui la sicurezza, la stabilità e la resilienza sono fondamentali. Ecco alcuni dei principali casi d'uso del fuzz testing:
1. Test di sicurezza
Una delle applicazioni più comuni dei fuzz test è quella dei test di sicurezza. Inserendo in un programma input casuali o malformati, il fuzz testing può rivelare vulnerabilità che gli hacker potrebbero sfruttare, come buffer overflow, difetti di validazione degli input e vulnerabilità di iniezione.
2. Robustezza del software
I test fuzz migliorano anche la robustezza del software, assicurando che le applicazioni siano in grado di gestire dati imprevisti o malformati senza bloccarsi. Molti programmi sono progettati con specifiche aspettative di input, ma i dati del mondo reale non sono sempre prevedibili. Eseguendo test con vari input inaspettati, il fuzz testing può rivelare le aree in cui il software potrebbe fallire sotto stress, soprattutto per le applicazioni che vengono eseguite in ambienti imprevedibili o che gestiscono dati diversi.
3. Test del protocollo
Il fuzzing di protocollo è ampiamente utilizzato per testare la resilienza dei protocolli di rete. I protocolli di rete definiscono le regole per lo scambio di dati tra i dispositivi e qualsiasi punto debole in questi protocolli può portare a violazioni o interruzioni della sicurezza. Attraverso il fuzz testing dei protocolli di rete, i tester possono valutare la capacità di questi protocolli di gestire pacchetti inattesi o malformati per identificare le vulnerabilità che potrebbero compromettere l'integrità dei dati, la sicurezza o l'affidabilità della comunicazione.
4. Test automotive e IoT
Nei sistemi automobilistici, il fuzz testing è in grado di rivelare le vulnerabilità nella comunicazione tra i sottosistemi dell'auto, per assicurarsi che rimangano operativi e sicuri. Allo stesso modo, per i dispositivi IoT, il fuzz testing è essenziale per confermare che questi dispositivi possono gestire una serie di condizioni di rete e di input di dati senza compromettere la funzionalità o la sicurezza.
Vantaggi dei test fuzz
**I Fuzz test rivelano bug che i metodi di test tradizionali potrebbero non notare, soprattutto quelli innescati da scenari di input rari o inaspettati.
**Esponendo il software a vari input, compresi dati malformati o inaspettati, il fuzz testing aiuta gli sviluppatori a identificare i punti deboli e a rendere il software più resistente alle condizioni del mondo reale.
Misure di sicurezza migliorate: Il fuzz testing individua le vulnerabilità che potrebbero essere sfruttate per attacchi, come buffer overflow, memory leak e falle di iniezione. Pertanto, consente ai team di sicurezza di affrontare in modo proattivo questi punti deboli per proteggere il software da potenziali attacchi informatici e accessi non autorizzati.
**Il fuzzing guidato dalla copertura assicura che vengano testate anche le parti del codice utilizzate meno frequentemente, scoprendo i bug nei percorsi eseguiti di rado. Questo approccio di testing ad ampio raggio migliora la qualità complessiva e la stabilità del software, esplorando percorsi di codice che altrimenti potrebbero essere trascurati.
Sfide e limiti del Fuzz Testing
**Il fuzz testing si scontra con programmi complessi e statici che si basano su formati di dati intricati, il che rende difficile generare input adeguati senza rompere la struttura dei dati. Ad esempio, nei test dei protocolli o dei formati di file, il fuzzing richiede la conoscenza della struttura, il che aggiunge complessità e richiede tecniche di fuzzing avanzate.
Costrizioni di tempo e risorse: Il fuzzing su larga scala può consumare una potenza di elaborazione e una memoria significative, il che lo rende ad alta intensità di risorse. Spesso sono necessari lunghi tempi di esecuzione per produrre risultati significativi, soprattutto per le applicazioni complesse, il che può ritardare il processo di test e sviluppo.
**I fuzz test si basano su input casuali o semi-casuali, che non sempre raggiungono le parti più profonde del codice, soprattutto in programmi complessi con logica o dipendenze intricate. Inoltre, il fuzzing puramente casuale non ha l'attenzione necessaria per individuare vulnerabilità specifiche, per cui i bug in alcuni percorsi del codice potrebbero rimanere non rilevati.
**Il fuzz testing può rivelare bug oscuri, ma riprodurre le condizioni esatte che hanno innescato questi bug può essere difficile. Il debug diventa più complicato quando l'input specifico o la sequenza di eventi che hanno causato il problema non possono essere facilmente replicati.
**I Fuzz test possono produrre un elevato volume di dati, con alcuni risultati che indicano problemi che non sono vere e proprie vulnerabilità, noti come falsi positivi. Filtrare i falsi positivi e concentrarsi sulle vulnerabilità reali può richiedere tempo e competenze.
**Il fuzz testing non è un processo che si svolge una sola volta, ma richiede un monitoraggio continuo. Inoltre, un fuzzing efficace richiede l'interpretazione di registri e risultati estesi e richiede personale qualificato per analizzare e risolvere i problemi rilevati.
Strumenti e strutture per i test fuzz
AFL (American Fuzzy Lop): Conosciuto per la sua efficienza nel fuzzing basato sulla mutazione, AFL utilizza una combinazione di mutazione intelligente degli input e feedback sulla copertura del codice per scoprire le vulnerabilità.
libFuzzer: Fuzzer guidato dalla copertura progettato per librerie e applicazioni, libFuzzer genera input che mirano alla copertura del codice per scoprire bug nascosti in software complessi.
OSS-Fuzz: Una piattaforma di fuzzing su larga scala, pensata per i progetti open-source, OSS-Fuzz fornisce test fuzz continui e automatizzati per migliorare la sicurezza e la stabilità del software open-source ampiamente utilizzato.
Peach: Un framework di fuzzing completo che supporta una serie di protocolli e formati di dati per testare software e protocolli di comunicazione complessi, compresi i test generazionali e basati sulle mutazioni.
Sulley: Utilizzato principalmente per il fuzzing dei protocolli di rete, Sulley è apprezzato per la sua capacità di simulare un'ampia varietà di input di rete ed è spesso utilizzato nella ricerca sulla sicurezza.
Radamsa: Un fuzzer leggero basato sulla mutazione, semplice da usare ed efficace per generare input inaspettati per testare la resilienza e la robustezza del software.
Fuzz Testing per database vettoriali e applicazioni AI
I test fuzz sono molto importanti nei database vettoriali come Milvus (creato da Zilliz) e nelle applicazioni GenAI, poiché queste tecnologie gestiscono grandi volumi di dati diversi e complessi. Nelle soluzioni basate sull'IA, come Retrieval-Augmented Generation (RAG) e altri modelli di apprendimento automatico, i fuzz test sono fondamentali per mantenere l'integrità dei dati, la stabilità del sistema e la sicurezza, soprattutto quando si tratta di dati non strutturati. Ecco come i fuzz test sono utili:
Garantire una gestione robusta dei dati nei database vettoriali: Poiché i database vettoriali spesso supportano query e filtri complessi, i fuzz test possono rivelare quanto bene gestiscono i casi limite negli input delle query. Quindi, identifica potenziali fallimenti o inefficienze nell'indicizzazione e nel recupero dei dati.
Test di resilienza in applicazioni AI come RAG:** RAG e modelli AI simili si basano sul recupero di informazioni rilevanti da database esterni per generare risposte o eseguire compiti specifici. Questi modelli sono sensibili alla qualità e alla struttura dei dati recuperati. I test fuzz possono simulare input di dati corrotti o inaspettati per vedere come reagisce il modello a recuperi insoliti.
Proteggere i database vettoriali e le pipeline di intelligenza artificiale da potenziali attacchi: i test Fuzz possono simulare input di dati ostili, come esempi avversari progettati per manipolare il comportamento del modello di intelligenza artificiale. In questo modo si identificano i punti deboli che gli aggressori potrebbero sfruttare, consentendo agli sviluppatori di rafforzare la sicurezza.
Migliorare l'affidabilità delle architetture di IA distribuite: Molte applicazioni di IA, in particolare quelle alimentate da Grandi modelli linguistici (LLM) o da sistemi di riconoscimento delle immagini, sono distribuite su più nodi e sistemi. I test fuzz possono rivelare problemi nel processo di sincronizzazione dei dati tra i nodi di un database vettoriale distribuito, per verificare se tutte le istanze del database possono gestire senza problemi input incoerenti o inaspettati.
Migliori pratiche per i test Fuzz
L'implementazione efficace del fuzz testing richiede un'attenta pianificazione e il rispetto delle migliori pratiche. Ecco alcuni consigli essenziali per ottimizzare il fuzz testing:
Ottimizzare la generazione di input
Utilizzate il fuzzing basato sulla mutazione e sulla generazione per garantire un'ampia gamma di input, che copra casi limite comuni e rari.
Adattare la generazione degli input in modo che corrispondano ai formati di dati o ai protocolli previsti dal software di destinazione, per evitare errori irrilevanti e concentrarsi sui problemi significativi.
Utilizzate il fuzzing strutturato o guidato dalla copertura per i tipi di dati complessi per massimizzare la copertura del codice e trovare i bug più profondi.
Impostare un monitoraggio e un feedback completi
Implementate una registrazione dettagliata per catturare il comportamento del programma durante i test, compresi i crash, le perdite di memoria e le uscite anomale.
Strumenti di monitoraggio come Prometheus possono essere utilizzati per tracciare l'utilizzo della memoria, il carico della CPU e i percorsi di esecuzione per ottenere informazioni sulle prestazioni del software in presenza di input fuzzy.
Attivare strumenti di segnalazione e debug degli arresti anomali per aiutare a rintracciare la causa principale di qualsiasi problema rilevato, rendendo più facile la riproduzione e la correzione dei bug.
Selezionare gli strumenti giusti
Scegliete gli strumenti di fuzzing in base ai requisiti specifici del progetto. Ad esempio, AFL può essere utilizzato per il fuzzing basato sulle mutazioni, libFuzzer per le librerie e OSS-Fuzz per i progetti open-source.
Assicuratevi che lo strumento si integri bene con l'ambiente di sviluppo e di test, consentendo di incorporarlo senza problemi nelle pipeline CI/CD.
Sperimentate con più strumenti e combinate diverse strategie di fuzzing per ottenere una copertura e risultati migliori.
Progettare un ambiente di test efficace
Create un ambiente di test controllato che isoli il software fuzzed dai sistemi critici per evitare danni accidentali o perdite di dati.
Allocare risorse informatiche sufficienti, poiché i test fuzz possono richiedere molte risorse. Considerate la possibilità di eseguire i test in una macchina virtuale o in un container per gestire efficacemente l'allocazione delle risorse.
Aggiornare regolarmente l'ambiente di test per includere le dipendenze e le patch più recenti, in quanto i componenti obsoleti possono introdurre problemi indesiderati.
Evitare le insidie più comuni
Pregiudizio: ** Affidarsi esclusivamente a input casuali senza mirare ad aree specifiche. **Soluzione: ** Usare il fuzzing guidato dalla copertura o dalla struttura per indirizzare il test verso i percorsi di codice più importanti.
**Pitfall: ** Ignorare i falsi positivi, che possono sovraccaricare i risultati. Soluzione: Esaminare e filtrare regolarmente i risultati per concentrarsi sui problemi autentici, utilizzando strumenti o script per aiutare a classificare l'output.
Problemi: ** Non riuscire a riprodurre i problemi riscontrati durante i fuzz test. Soluzione: Registrare tutti gli input e i percorsi di esecuzione fuzzati, in modo che i problemi rilevati possano essere riprodotti e risolti con precisione.
Rendere i test fuzz continui
Integrate il fuzz testing nella vostra pipeline CI/CD per garantire che le nuove modifiche al codice siano costantemente testate per individuare potenziali vulnerabilità.
Pianificate fuzz test regolari, soprattutto per i componenti software critici, come parte del processo di sviluppo continuo. Il fuzzing continuo aumenta la probabilità di individuare tempestivamente i problemi.
Conclusione
In sintesi, il fuzz testing è un metodo potente per scoprire bug e vulnerabilità nascoste in varie applicazioni software, compresi database vettoriali e sistemi di intelligenza artificiale. Il fuzz testing aiuta a migliorare la robustezza, la sicurezza e l'affidabilità fornendo input casuali o malformati a un programma. Anche se comporta delle sfide, l'adozione delle migliori pratiche e l'utilizzo degli strumenti giusti possono massimizzarne l'efficacia.
Domande frequenti sul Fuzz Testing
- Che cos'è il fuzz testing e perché è importante?
Il fuzz testing è un metodo di test del software che immette dati casuali o inaspettati in un programma per trovare bug e vulnerabilità. Migliora la sicurezza, la robustezza e l'affidabilità del software scoprendo problemi che i metodi di test tradizionali potrebbero ignorare.
- Come funziona il fuzz testing nella pratica?
Il fuzz testing prevede diverse fasi: l'identificazione del sistema target, la determinazione dei tipi di input da testare, la generazione di dati fuzzati, l'esecuzione del programma con questi dati, l'analisi del comportamento del programma e l'identificazione di eventuali problemi. Questo processo rivela la capacità del software di gestire input inattesi o malformati.
- Quali sono alcuni tipi comuni di fuzz testing?
I tipi più comuni includono il fuzzing basato sulla mutazione (alterando i dati esistenti), il fuzzing basato sulla generazione (creando input da zero), il fuzzing guidato dalla copertura (massimizzando la copertura del codice) e il fuzzing di protocollo (testando formati di dati specifici o standard di comunicazione).
- Il fuzz testing può essere applicato alle applicazioni di intelligenza artificiale e ai database vettoriali?
Sì, il fuzz testing è molto importante per l'IA e i database vettoriali. Aiuta questi sistemi a gestire input imprevedibili, a migliorare l'integrità dei dati e a mantenere la sicurezza, soprattutto in applicazioni come Retrieval-Augmented Generation (RAG) e nella gestione di dati complessi nelle pipeline di IA.
- Quali sono le principali sfide del fuzz testing?
Le sfide principali includono la gestione di strutture di dati complesse, la natura ad alta intensità di risorse del fuzzing su larga scala, i limiti della generazione di input casuali e la difficoltà di riprodurre i problemi. Seguire le best practice e selezionare gli strumenti giusti può aiutare ad affrontare queste sfide.
Risorse correlate
Come valutare le applicazioni RAG](https://zilliz.com/learn/How-To-Evaluate-RAG-Applications)
Introduzione al monitoraggio e all'osservabilità completi in Zilliz Cloud
Prometheus Metrics: monitorare le prestazioni della vostra applicazione
Come individuare i colli di bottiglia delle prestazioni di ricerca nei database vettoriali
- Cos'è il Fuzz Testing?
- Storia del Fuzz Testing
- Come funziona il Fuzz Testing?
- Tipi di Fuzz Testing
- Casi d'uso del Fuzz Testing
- Vantaggi dei test fuzz
- Sfide e limiti del Fuzz Testing
- Strumenti e strutture per i test fuzz
- Fuzz Testing per database vettoriali e applicazioni AI
- Migliori pratiche per i test Fuzz
- Conclusione
- Domande frequenti sul Fuzz Testing
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente