




Classificazione nell'apprendimento automatico: Tutto quello che dovreste sapere

Classificazione nell'apprendimento automatico: Tutto quello che dovreste sapere
Che cos'è la classificazione?
La classificazione è un approccio di apprendimento automatico supervisionato che categorizza i dati in classi predefinite. Dato un input, un modello di classificazione predice la categoria o l'etichetta a cui appartiene l'input. È uno dei compiti più comuni dell'apprendimento automatico e viene utilizzato in molte applicazioni reali, dal rilevamento dello spam nelle e-mail alle diagnosi mediche.
Ad esempio, se si dispone di un insieme di e-mail, un modello di classificazione può imparare a etichettare ogni e-mail come "spam" o "non spam".
Come funziona la classificazione?
Nella classificazione, un modello di apprendimento automatico viene addestrato su un set di dati per classificare i dati in classi predefinite in base alle caratteristiche di input. Il modello viene addestrato utilizzando un set di dati etichettati, in cui ogni input è associato a un'etichetta di output. Il modello apprende gli schemi presenti nei dati durante l'addestramento e li utilizza per prevedere le etichette di nuovi dati non visti.
Ad esempio, immaginiamo di dover classificare se un'e-mail è spam. Durante la fase di addestramento, il modello viene alimentato con le e-mail e le loro etichette ("spam" o "non spam"). Analizza caratteristiche come la presenza di determinate parole chiave o l'indirizzo del mittente per identificare i modelli. Dopo l'addestramento, il modello analizza le stesse caratteristiche e prevede l'appartenenza alla categoria "spam" o "non spam" quando arriva una nuova e-mail.
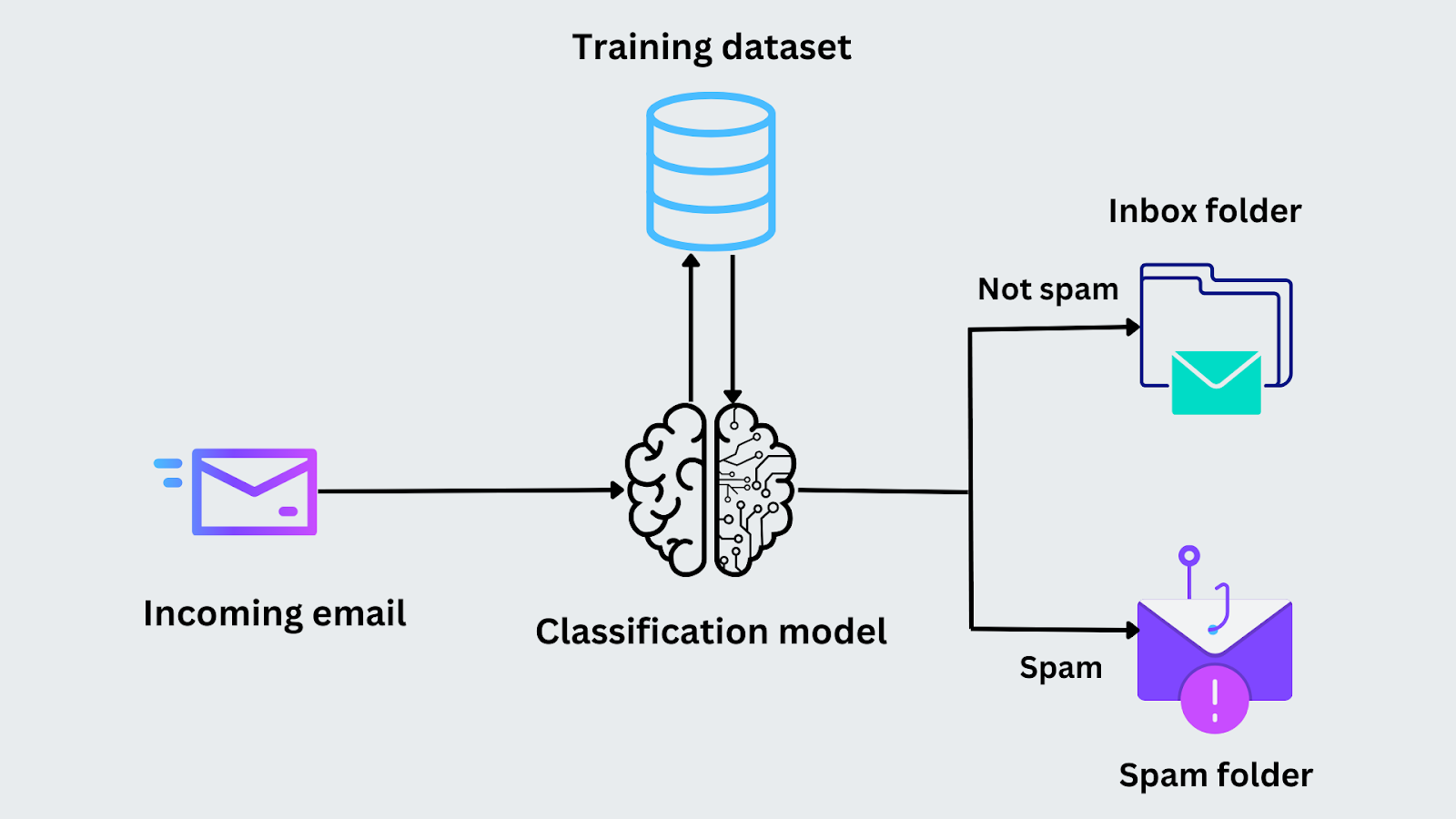 Figura- Processo di classificazione delle e-mail.png
Figura- Processo di classificazione delle e-mail.png
Figura: Processo di classificazione delle e-mail
Tipi di classificazione
I problemi di classificazione si presentano in forme diverse a seconda della natura dei dati e del numero di classi. Ecco i tipi più comuni:
Classificazione binaria
La classificazione binaria si ha quando ci sono solo due classi o risultati possibili. Il modello predice a quale delle due categorie appartiene l'input. Un esempio classico è il rilevamento di spam di e-mail. Il modello deve decidere se un'e-mail in arrivo è "spam" o "non spam". Poiché ci sono solo due opzioni, si tratta di un compito di classificazione binaria.
Classificazione multiclasse
Nella classificazione multiclasse, il modello predice un'etichetta tra più di due possibili categorie. Ogni input viene assegnato esattamente a una classe. Un buon esempio è il riconoscimento di immagini, dove il modello potrebbe classificare un'immagine come "gatto", "cane" o "uccello". A differenza della classificazione binaria, il modello ha a che fare con diverse classi distinte e deve identificare quella corretta per ogni input.
Classificazione multilingue
La classificazione multilabel è quella in cui ogni input può appartenere a più classi contemporaneamente. Per esempio, quando si etichetta una foto, questa potrebbe essere etichettata contemporaneamente con "tramonto", "spiaggia" e "persone". Ogni etichetta rappresenta una classe diversa e il modello impara a prevedere tutte le etichette pertinenti per un input. Questo differisce dalla classificazione multiclasse, perché allo stesso input possono essere assegnate più etichette.
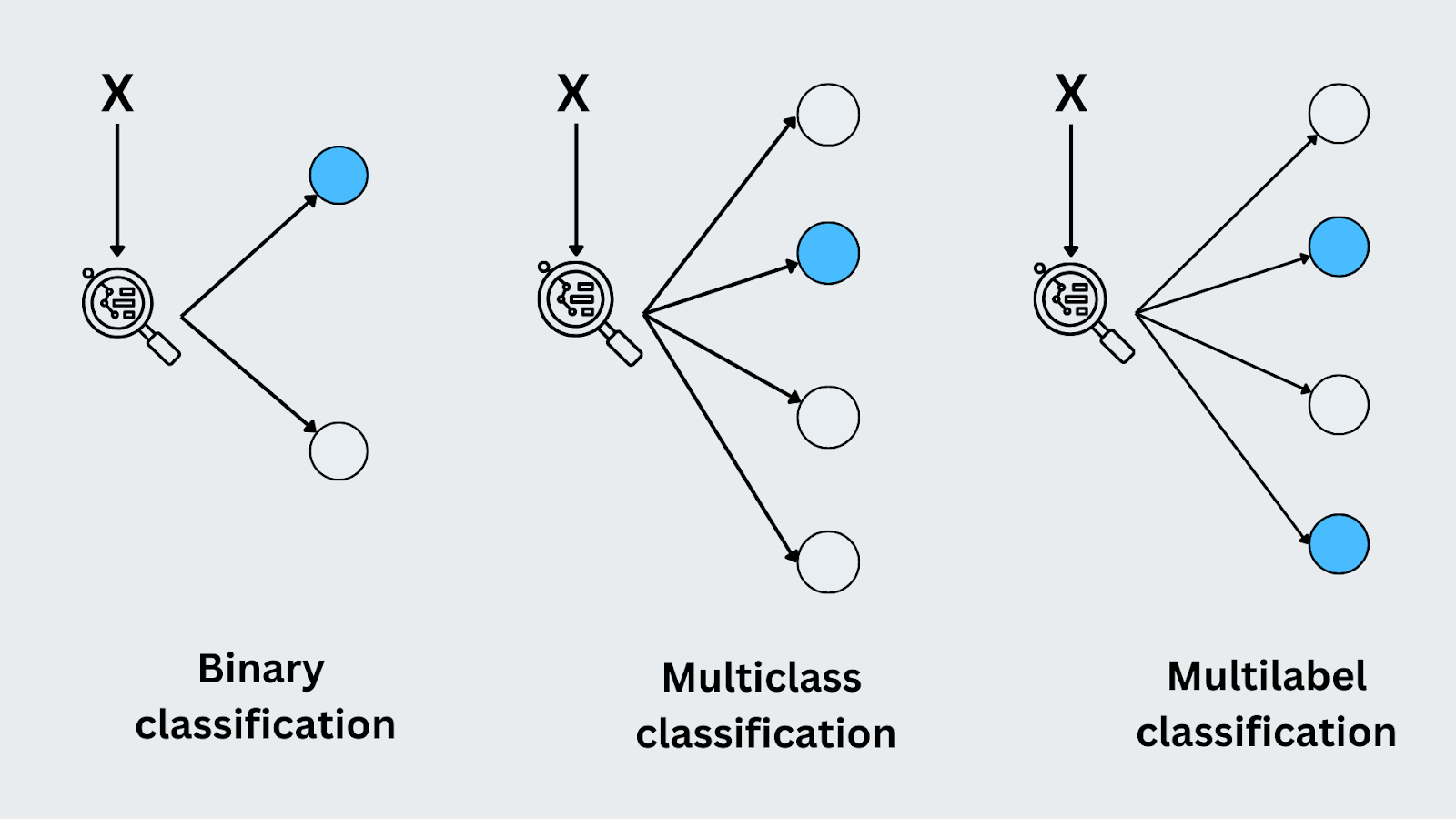 Figura- Tipi di classificazione.png
Figura- Tipi di classificazione.png
Figura: Tipi di classificazione
Apprendenti negli algoritmi di classificazione
Nell'apprendimento automatico, gli algoritmi di classificazione possono essere classificati in base al modo in cui generalizzano dai dati di addestramento. Si tratta dei Lazy Learners e degli Eager Learners. La distinzione tra questi due tipi sta nel momento e nel modo in cui elaborano i dati per fare previsioni.
Apprenditori pigri
Gli apprendisti pigri sono algoritmi che ritardano la generalizzazione fino a quando non ricevono una richiesta di predizione. Non costruiscono un modello durante la fase di addestramento, ma memorizzano i dati di addestramento ed eseguono i calcoli solo quando è necessario classificare un nuovo input.
Algoritmi di esempio: k-Nearest Neighbors (k-NN), Case-based Reasoning (CBR).
Apprendisti desiderosi
Gli Eager Learner, invece, cercano di costruire un modello generale immediatamente durante la fase di addestramento. Analizzano i dati di addestramento, imparano i modelli sottostanti e poi scartano i dati di addestramento. Una volta costruito, il modello è in grado di prevedere rapidamente i nuovi dati.
Algoritmi di esempio: Alberi decisionali, Foresta casuale, Macchine a vettori di supporto (SVM), Regressione logistica.
| Aspetto | Apprendisti pigri | Apprendisti desiderosi |
| Creazione del modello | Durante l'addestramento non viene costruito alcun modello, ma vengono memorizzati i dati. | Generalizza i dati in un modello durante l'addestramento. |
| Tempo di addestramento | Tempo di addestramento breve; non costruisce un modello. | Tempo di addestramento più lungo; costruisce un modello in base ai dati. |
| Tempo di predizione | Fa previsioni più lente perché elabora i dati al momento dell'interrogazione. | Previsioni più rapide, perché il modello è precostituito. |
| Richieste di memoria | Richieste di memoria più elevate; memorizza l'intero set di dati. | Richiede meno memoria; memorizza solo i parametri del modello. |
| Algoritmi di esempio | k-NN, Case-based Reasoning | Alberi decisionali, Regressione logistica, Random Forest |
Tabella: Apprendisti pigri vs Apprendisti impazienti
Algoritmi di classificazione
Ora discutiamo alcuni algoritmi di classificazione comunemente utilizzati.
Regressione logistica
La regressione logistica utilizza solo la probabilità per prevedere l'etichetta in un compito di classificazione binaria. A differenza della regressione lineare, che predice valori continui, la regressione logistica predice le probabilità per due classi mappando gli output in un intervallo compreso tra 0 e 1 utilizzando la funzione logistica (sigmoid). È ampiamente utilizzata per i casi con esiti binari, come gli scenari sì/no o 0/1.
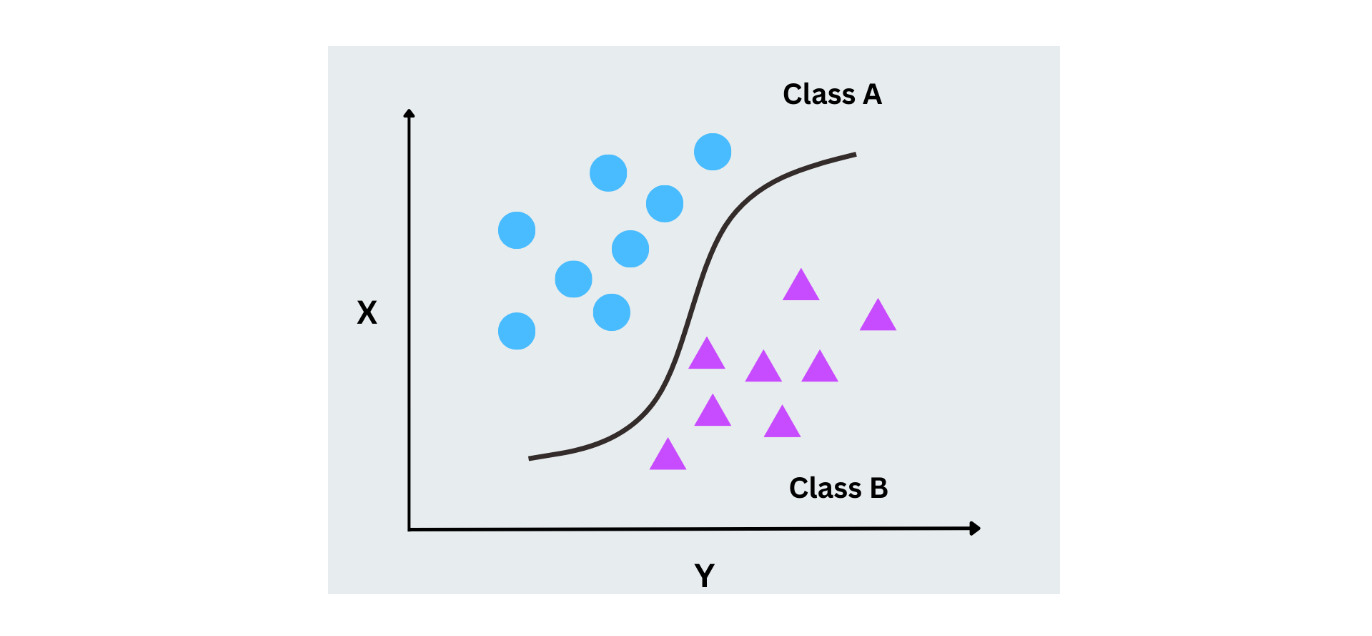 Figura- Regressione logistica funzionante.png
Figura- Regressione logistica funzionante.png
Figura- Regressione logistica funzionante
Alberi decisionali
Un albero decisionale è un modello che divide i dati in base ai valori delle caratteristiche, creando rami per ogni possibile decisione. Ogni nodo rappresenta una caratteristica e i rami rappresentano le decisioni basate sul valore di quella caratteristica. Il processo continua fino a quando l'algoritmo decide i nodi della foglia della classe prevista. Gli alberi decisionali sono facili da interpretare e possono gestire compiti di classificazione binaria e multiclasse.
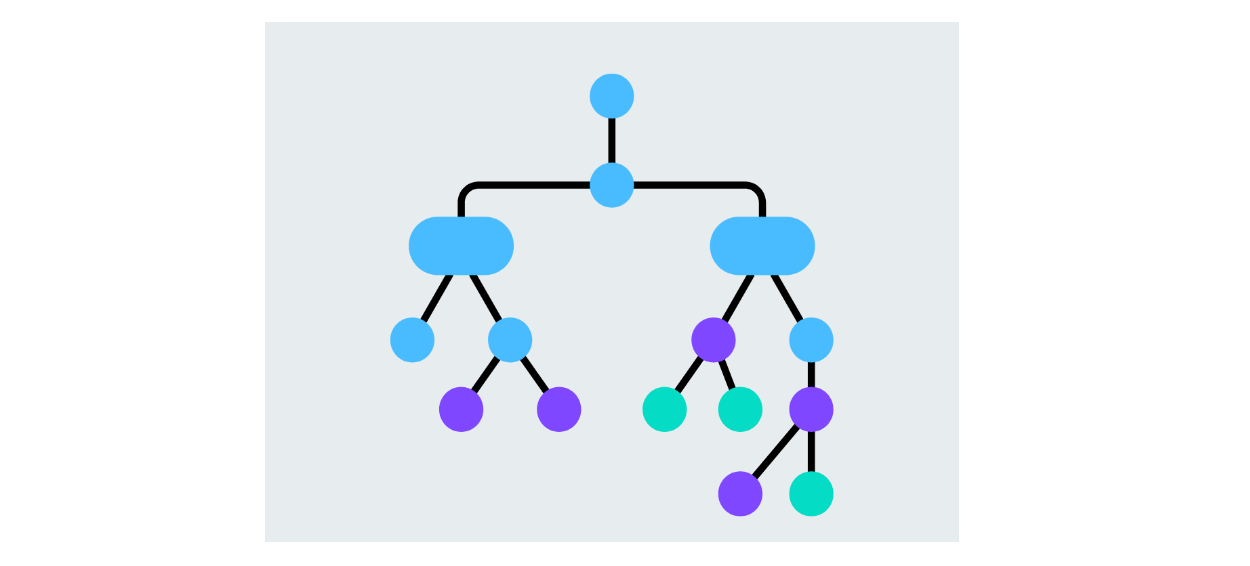 Figura- Struttura dell'albero decisionale.png
Figura- Struttura dell'albero decisionale.png
Figura: Struttura dell'albero decisionale
Foresta casuale
La foresta casuale migliora gli alberi decisionali costruendo più alberi e combinando le loro previsioni. Ogni albero della foresta è costruito a partire da un sottoinsieme casuale dei dati e delle caratteristiche. La previsione finale viene fatta facendo la media dei risultati (per i compiti di regressione) o votando a maggioranza (per i compiti di classificazione). Ciò contribuisce a ridurre l'overfitting e ad aumentare l'accuratezza.
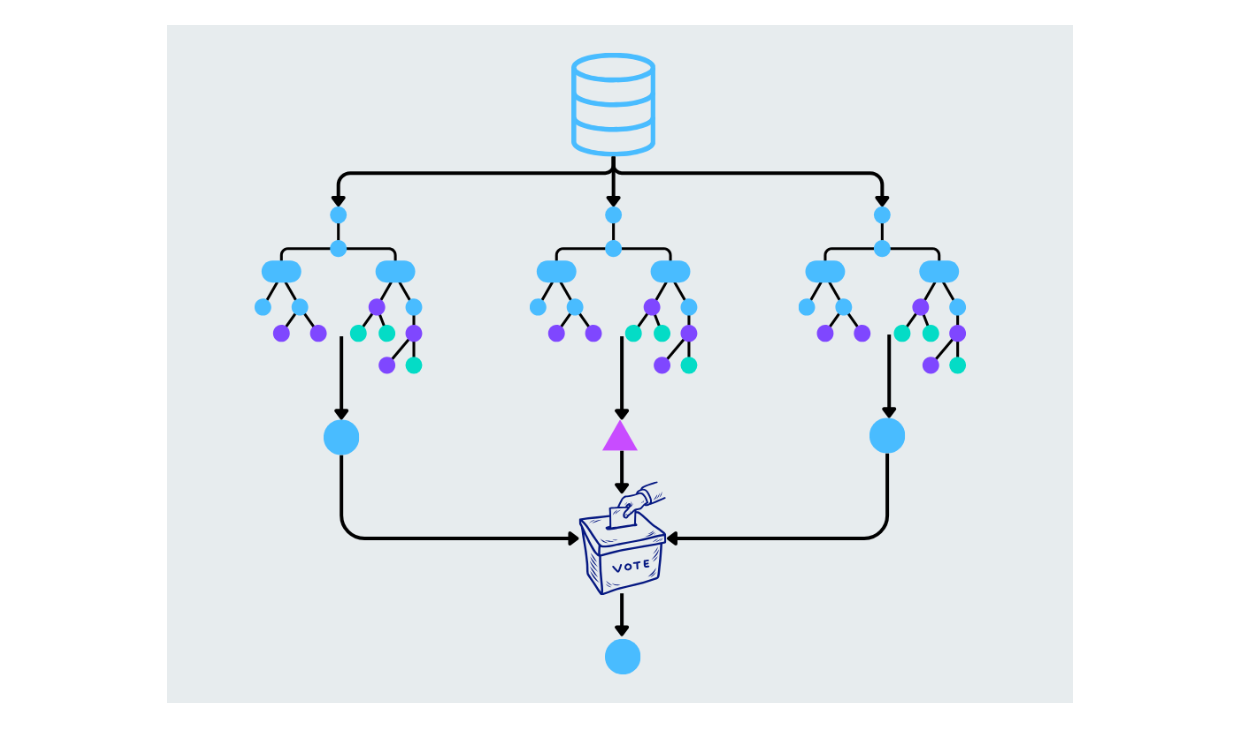 Figura- Random forest working.png
Figura- Random forest working.png
Figura: Foresta casuale in funzione
Macchine vettoriali di supporto (SVM)
Le macchine vettoriali di supporto funzionano trovando l'iperpiano ottimale che separa i punti di dati appartenenti a classi diverse. Questo iperpiano è una linea in due dimensioni, ma le SVM possono gestire anche dati ad alta densità. L'idea chiave è quella di massimizzare il margine tra i punti di dati più vicini di ciascuna classe (vettori di supporto). Le SVM funzionano bene per problemi di classificazione binaria e multiclasse, soprattutto quando i dati non sono linearmente separabili.
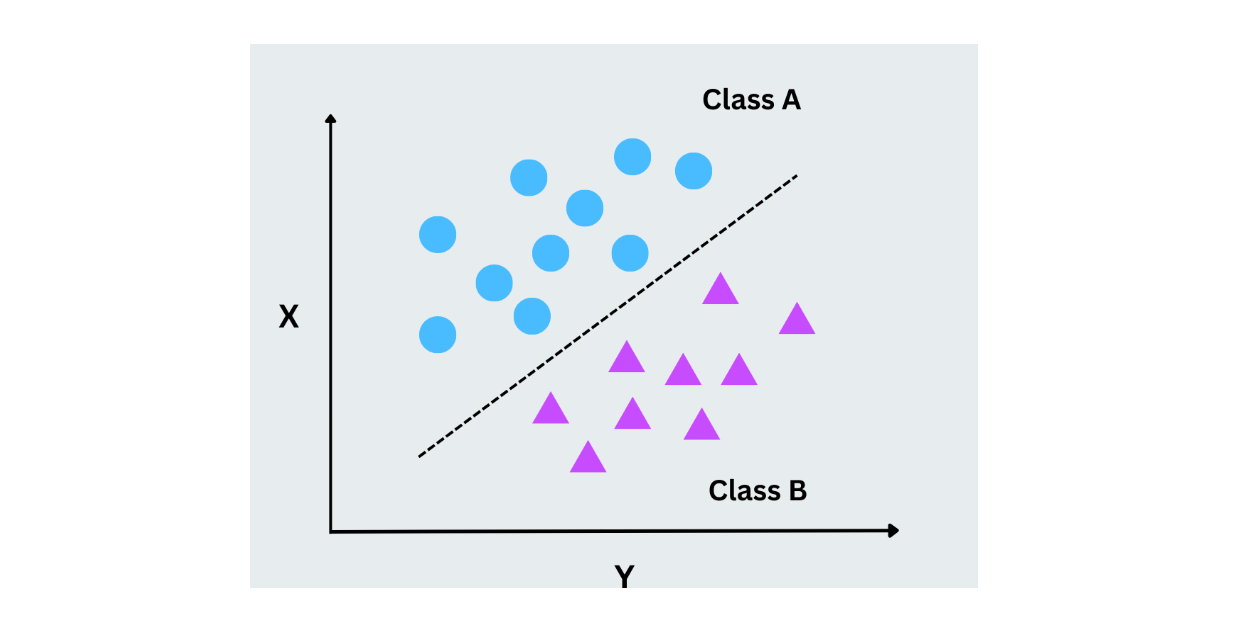 Figura- SVM working.png
Figura- SVM working.png
Figura - SVM funzionante
k-Nearest Neighbors (k-NN)
L'algoritmo k-NN classifica i punti dati in base alle classi dei k vicini più prossimi. Quando si introduce un nuovo punto di dati, l'algoritmo esamina i k punti più vicini (sulla base di una metrica di somiglianza come la distanza euclidea) e assegna al nuovo punto la classe maggioritaria. Si tratta di un semplice algoritmo di apprendimento basato sull'istanza, utile per insiemi di dati più piccoli.
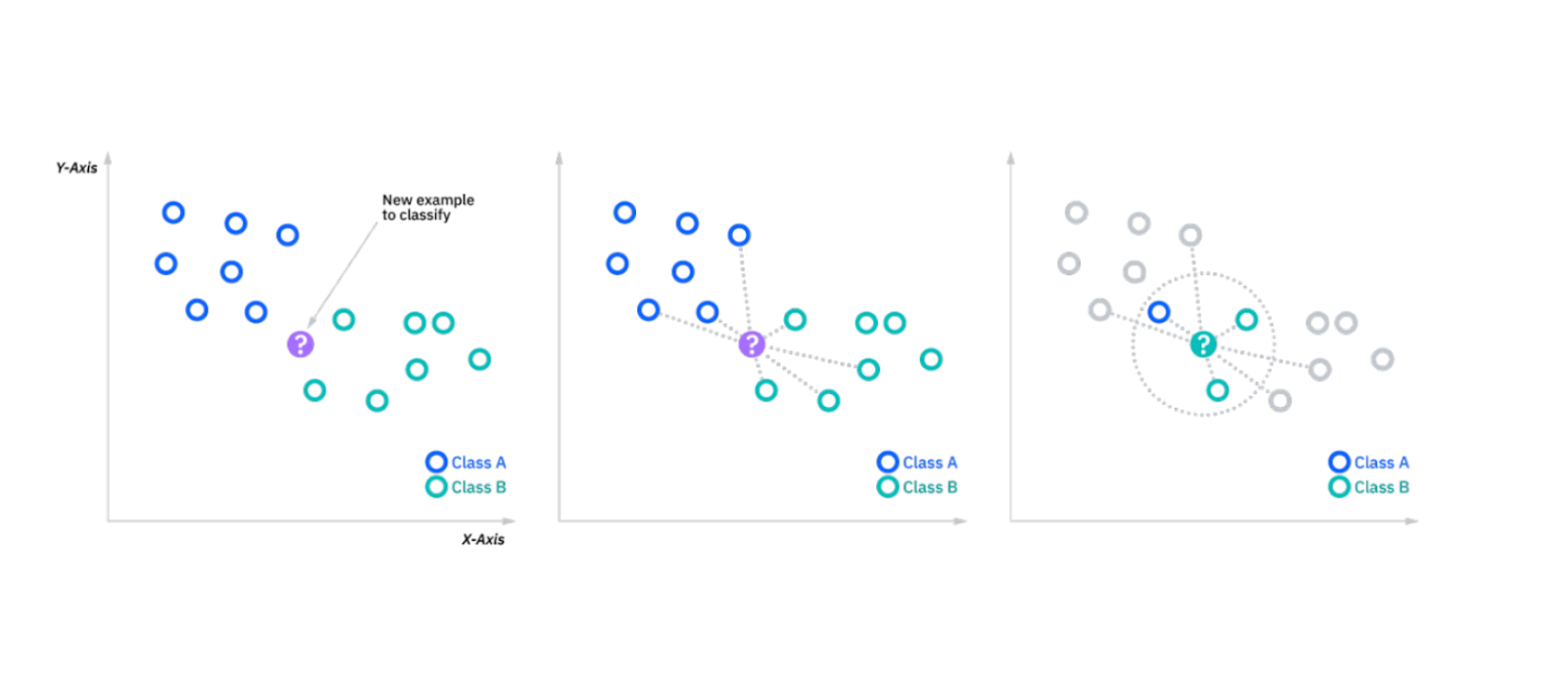 Figura- algoritmo kNN in funzione.png
Figura- algoritmo kNN in funzione.png
Figura: algoritmo kNN funzionante
Baia ingenua
L'algoritmo Naive Bayes si basa sul Teorema di Bayes e presuppone che le caratteristiche dei dati siano indipendenti tra loro (da qui il termine "naive"). Nonostante questo presupposto, si comporta bene in vari compiti del mondo reale, soprattutto quando i dati hanno caratteristiche categoriali. Funziona calcolando la probabilità di ciascuna classe in base all'input e assegnando la classe con la probabilità più alta.
P(C|X) = P(X|C) . P(C)P(X))
Qui, P(C∣X) è la probabilità posteriore della classe dato l'input, P(X∣C) è la probabilità dell'input data la classe, P(C) è la probabilità anteriore della classe e P(X) è la probabilità dell'input. Naive Bayes seleziona la classe con la probabilità posteriore più alta per la classificazione in base alle caratteristiche osservate.
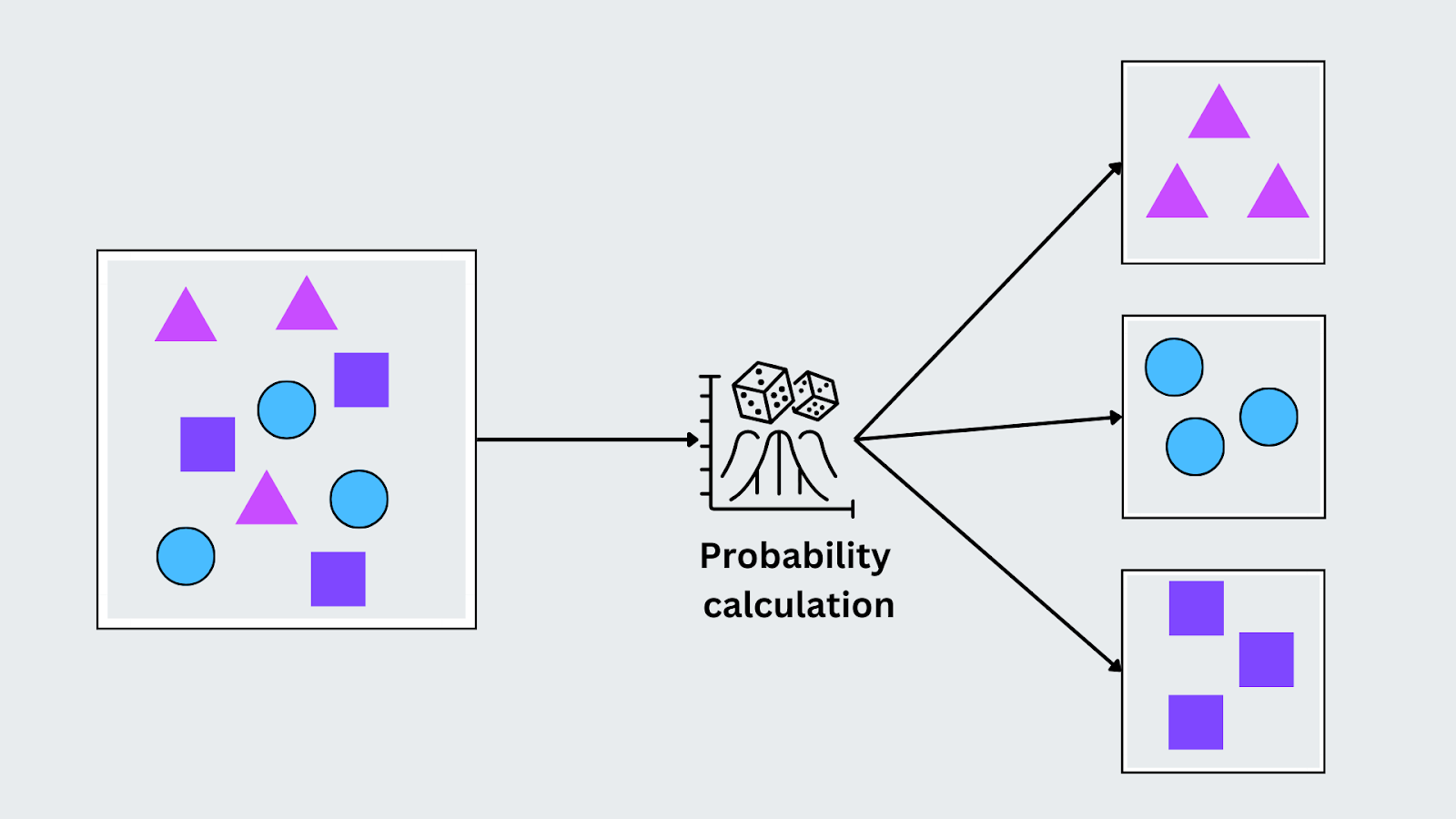 Figura- Algoritmo Naive Bayes funzionante.png
Figura- Algoritmo Naive Bayes funzionante.png
Figura: Algoritmo Naive Bayes funzionante
Metriche di valutazione nella classificazione
Precisione
L'accuratezza è la metrica più semplice e misura la frequenza con cui le previsioni del modello sono corrette. Si determina dividendo il numero di casi correttamente predetti per il numero totale di casi.
Formula:
Accuratezza = (Veri positivi + Veri negativi)/Numero totale di istanze
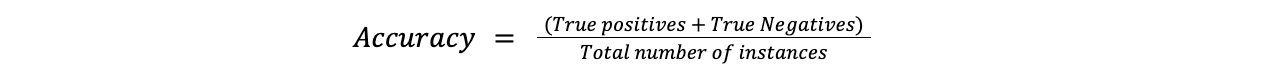 accuracy.png
accuracy.png
Precisione
La precisione misura quante delle istanze positive previste sono realmente positive. La precisione è importante in situazioni in cui i falsi positivi sono costosi. Ad esempio, prevedere una transazione normale come fraudolenta nel rilevamento delle frodi può portare all'insoddisfazione del cliente.
Formula:
Precisione = Veri positivi/(Veri positivi + Falsi positivi)
 precision.png
precision.png
Richiamo
Il richiamo misura la percentuale di casi positivi accuratamente identificati come tali. Il richiamo è utile nei casi in cui la mancanza di un'istanza positiva è costosa. Ad esempio, la mancanza di una diagnosi (falso negativo) è molto più problematica nel rilevamento delle malattie rispetto a un falso allarme.
Formula:
Richiamo = Veri positivi/(Veri positivi + Falsi negativi)
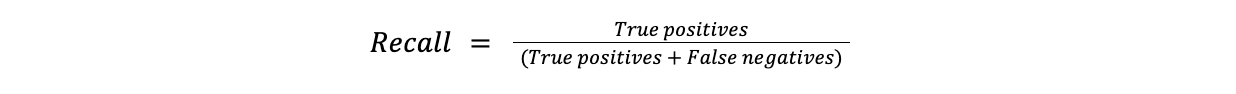 recall.png
recall.png
Punteggio F1
Il punteggio F1 è la media armonica di precisione e richiamo. È utile quando è necessario bilanciare precisione e richiamo, in particolare quando uno dei due è più importante dell'altro.
Formula:
F1Score = 2x(precisione x richiamo)/(precisione + richiamo)
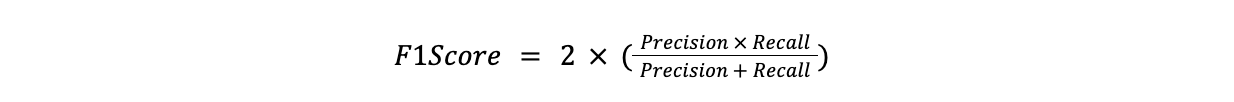 FI score.png
FI score.png
Casi d'uso della classificazione nel mondo reale
I modelli di classificazione sono ampiamente utilizzati in vari settori per risolvere i problemi del mondo reale. Ecco alcuni esempi pratici:
Diagnosi mediche: i modelli di apprendimento automatico aiutano i medici a classificare i dati dei pazienti come "malattia" o "nessuna malattia". Ad esempio, i modelli vengono utilizzati per prevedere se un paziente ha il diabete sulla base delle cartelle cliniche.
**Le aziende utilizzano l'analisi del sentiment per comprendere il feedback dei clienti. Ad esempio, un modello può analizzare le recensioni dei prodotti e classificarle come positive, negative o neutre, aiutando le aziende a migliorare le loro offerte in base al sentiment dei clienti.
**Banche e istituti finanziari utilizzano modelli di classificazione per individuare le transazioni fraudolente. Il modello apprende i modelli dai dati delle transazioni e classifica ciascuna di esse come "fraudolenta" o "legittima" per evitare perdite finanziarie.
Riconoscimento di oggetti nelle immagini: I modelli di riconoscimento degli oggetti identificano elementi specifici delle immagini in settori come la produzione e la sicurezza. Ad esempio, un modello può classificare le immagini di prodotti in una catena di montaggio, garantendo che solo gli articoli correttamente assemblati passino l'ispezione.
Riconoscimento facciale: I sistemi di riconoscimento facciale sono utilizzati per la sicurezza e l'autenticazione. Questi modelli classificano le immagini dei volti per identificare o verificare l'identità di una persona, comunemente utilizzati per sbloccare gli smartphone, i sistemi di rilevazione delle presenze digitali o i controlli di sicurezza negli aeroporti.
Riconoscimento vocale: I modelli di riconoscimento vocale convertono il linguaggio parlato in testo o comandi. Ad esempio, gli assistenti virtuali come Siri o Alexa classificano le parole pronunciate in comandi, in modo che gli utenti possano interagire con i dispositivi attraverso la voce.
Test diagnostici medici: I modelli di apprendimento automatico aiutano a interpretare test diagnostici come radiografie o risonanze magnetiche. Classificano le immagini mediche come "normali" o "anormali", aiutando i radiologi a fare diagnosi più rapide e precise.
Previsione del comportamento dei clienti: Le piattaforme di e-commerce utilizzano modelli di classificazione per prevedere il comportamento dei clienti. Questi modelli classificano gli utenti come "probabili acquirenti" o "improbabili acquirenti", per fornire raccomandazioni di marketing e prodotti personalizzati.
**I rivenditori utilizzano l'apprendimento automatico per classificare automaticamente prodotti come "elettronica", "abbigliamento" o "articoli per la casa" in base alle loro descrizioni. Questo semplifica la gestione dell'inventario e migliora l'esperienza di ricerca dei clienti.
**Nella sicurezza informatica, i modelli di classificazione individuano e classificano le minacce informatiche. Analizzando i modelli di comportamento del software, questi modelli classificano i programmi come "sicuri" o "dannosi" per proteggere i sistemi dalle minacce informatiche.
Sfide comuni nella classificazione
Quando si costruiscono modelli di classificazione, possono sorgere diverse sfide che influenzano le prestazioni del modello. Ecco tre sfide comuni:
Overfitting
[Overfitting] (https://zilliz.com/learn/understanding-regularization-in-nueral-networks) significa quando un modello funziona bene sui dati di addestramento ma non riesce a generalizzare a nuovi dati non visti. Ciò accade quando il modello diventa troppo complesso e inizia a catturare il rumore o i dettagli specifici del set di allenamento piuttosto che i modelli sottostanti.
Squilibrio dei dati
Lo sbilanciamento dei dati si verifica quando una classe supera in modo significativo le altre. Ad esempio, nel rilevamento delle frodi, le transazioni fraudolente possono rappresentare solo l'1% dei dati, portando il modello a orientarsi pesantemente verso la classe maggioritaria. Questo può portare a una scarsa rilevazione della classe di minoranza.
Rumore nei dati
Il rumore si riferisce a errori casuali o a informazioni irrilevanti nei dati che possono confondere il modello. I dati rumorosi possono includere esempi etichettati in modo errato, outlier o caratteristiche irrilevanti che non contribuiscono al compito di classificazione. La presenza di rumore può ridurre le prestazioni del modello e rendere più difficile l'individuazione di modelli.
Classificazione vs. Regressione
La classificazione e la regressione sono entrambi tipi di algoritmi di apprendimento supervisionato, ma vengono utilizzati per compiti diversi. Di seguito è riportato un confronto tra classificazione e regressione basato su vari aspetti:
| Aspetto | Classificazione | Regressione |
| Scopo | Prevede etichette o categorie discrete. | Prevede valori numerici continui. |
| Output | Categorico: classi come "spam" o "non spam". | Continuo: valori come "prezzo" o "temperatura". |
| Esempio di compito | Classificare le e-mail come "spam" o "non spam". | Prevedere i prezzi delle case in base alle loro caratteristiche. |
| Algoritmi utilizzati | Regressione logistica, alberi decisionali, foresta casuale, ecc. | Regressione lineare, regressione di Ridge, regressione polinomiale, ecc. |
| Metriche di valutazione | Accuratezza, precisione, richiamo, F1-score, ROC-AUC, ecc. | Errore quadratico medio (MSE), R-quadrato, Errore assoluto medio (MAE). |
| Natura della variabile target | Il target è categorico (ad esempio, etichette di classe). | Il target è continuo (ad esempio, numeri reali). |
| Confini dell'output | Ha confini di classe fissi (ad esempio, 0 o 1 per il binario). | Non ci sono confini fissi; l'output è un intervallo di numeri reali. |
| Casi d'uso nel mondo reale | Rilevamento dello spam, rilevamento delle frodi, classificazione delle malattie. | Previsione delle vendite, dei prezzi delle azioni e delle previsioni meteorologiche. |
| Modellazione ComplexiIt può gestire output sia binari che multiclasse. | Di solito è più semplice quando si prevede un valore continuo. |
Tabella: Classificazione vs Regressione
Come Milvus aiuta nei compiti di classificazione?
Con l'aumento del volume e della complessità dei dati, i metodi tradizionali di gestione e interrogazione di grandi insiemi di dati possono diventare lenti e inefficienti. È qui che Zilliz, con il suo database vettoriale open-source ad alte prestazioni Milvus, svolge un ruolo fondamentale.
Le attività di classificazione, come il riconoscimento di immagini, il rilevamento di oggetti, la ricerca di somiglianze tra video, il rilevamento di spam e i sistemi di raccomandazione, spesso richiedono la gestione di rappresentazioni ad alta dimensione di dati non strutturati, come embedding di testo, caratteristiche di immagini o vettori audio. Milvus è stato progettato specificamente per gestire e ricercare in modo efficiente questi grandi volumi di dati vettoriali.
Vantaggi di Milvus per la classificazione
Gestione di dati ad alta dimensionalità: Nella classificazione, i modelli si basano spesso su dati vettoriali (ad esempio, embeddings di parole o vettori di caratteristiche di immagini) per fare previsioni. Milvus è ottimizzato per memorizzare e gestire questi vettori e accedere rapidamente a grandi insiemi di dati durante l'addestramento e l'inferenza del modello.
Ricerca rapida della somiglianza: I modelli di classificazione devono spesso trovare i punti di dati più simili in un set di dati. Milvus accelera questo processo eseguendo una rapida ricerca di similarità sui dati vettoriali, facilitando la classificazione di nuovi input in base ai loro vicini più prossimi.
Scalabilità per grandi insiemi di dati: Milvus garantisce prestazioni veloci ed efficienti anche quando i dataset di classificazione crescono. Milvus è in grado di scalare senza problemi le attività di classificazione anche con grandi quantità di dati, che si tratti di milioni di vettori di prodotti, di embeddings di immagini o di migliaia di embeddings di immagini.
Conclusione
La classificazione è una tecnica di apprendimento automatico che consente di prevedere etichette o categorie per i dati in varie applicazioni del mondo reale, dall'individuazione di frodi al riconoscimento di immagini. La costruzione e l'implementazione di modelli di classificazione richiedono la gestione di grandi quantità di dati, spesso vettori ad alta dimensionalità. Milvus offre un'archiviazione efficiente, un recupero rapido e una scalabilità per i dati vettoriali. Migliora le prestazioni dei compiti di classificazione grazie alla ricerca rapida di somiglianze e si adatta senza problemi alla crescita dei set di dati. Con Milvus, gli sviluppatori possono gestire facilmente le sfide delle attività di classificazione su larga scala, diventando così uno strumento potente nel panorama dell'apprendimento automatico.
Domande frequenti sulla classificazione
**Che cos'è la classificazione nell'apprendimento automatico?
La classificazione nell'apprendimento automatico è il processo di previsione di una categoria o etichetta per un dato input basato sulle sue caratteristiche. Un modello viene addestrato utilizzando dati etichettati per apprendere modelli e quindi classificare nuovi dati non visti in classi predefinite, come "spam" o "non spam".
**Come si differenzia un algoritmo di classificazione dalla regressione?
Gli algoritmi di classificazione prevedono risultati categorici (come classi o etichette), mentre gli algoritmi di regressione prevedono valori numerici continui. Ad esempio, la classificazione può determinare se un'e-mail è spam, mentre la regressione potrebbe prevedere il prezzo di una casa.
**Perché la preparazione dei dati è importante nelle attività di classificazione?
La preparazione dei dati assicura che i dati di input siano puliti, strutturati e pronti per essere elaborati dal modello. Gestisce i valori mancanti, normalizza i dati e seleziona le caratteristiche più rilevanti. Una preparazione adeguata migliora l'accuratezza e le prestazioni del modello.
**Come Milvus aiuta nelle attività di classificazione?
Milvus è un database vettoriale open-source che memorizza e ricerca in modo efficiente dati ad alta dimensionalità, come le incorporazioni di immagini o testo. Accelera la classificazione grazie alla sua efficiente ricerca di similarità, che facilita la gestione di grandi insiemi di dati in attività come il riconoscimento di immagini e i sistemi di raccomandazione.
Quali sono le sfide comuni nella classificazione e come possono essere affrontate?
Le sfide più comuni includono l'overfitting, lo sbilanciamento dei dati e il rumore nei dati. Questi problemi possono essere affrontati utilizzando tecniche come la regolarizzazione, metodi di ricampionamento (ad esempio, SMOTE), strategie di riduzione del rumore e infrastrutture scalabili come Milvus per gestire in modo efficiente grandi insiemi di dati.
Risorse correlate
Cos'è il rilevamento di oggetti? Una guida completa](https://zilliz.com/learn/what-is-object-detection)
Cos'è l'algoritmo K-Nearest Neighbors (KNN) nell'apprendimento automatico?
- Che cos'è la classificazione?
- Come funziona la classificazione?
- Tipi di classificazione
- Apprendenti negli algoritmi di classificazione
- Algoritmi di classificazione
- Metriche di valutazione nella classificazione
- Casi d'uso della classificazione nel mondo reale
- Sfide comuni nella classificazione
- Classificazione vs. Regressione
- Come Milvus aiuta nei compiti di classificazione?
- Conclusione
- Domande frequenti sulla classificazione
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente