




Benchmark massif d’embeddings de texte (MTEB)
Benchmark massif d’embeddings de texte (MTEB)
Les embeddings de texte sont souvent testés sur un petit nombre de jeux de données issus d’une seule tâche, ce qui ne montre pas dans quelle mesure ils fonctionnent pour d’autres tâches. Il n’est pas clair si les meilleurs embeddings pour la similarité textuelle sémantique (STS) fonctionnent aussi bien pour des tâches comme le clustering ou le reranking. Cela rend difficile l’évaluation des progrès dans le domaine, car de nouveaux modèles et embeddings sont couramment évalués et constamment proposés sans tests cohérents.
Pour résoudre ce problème, des chercheurs ont créé le Massive Text Embedding Benchmark (MTEB). MTEB couvre 8 tâches d’embedding sur 58 jeux de données dans 112 langues. Les chercheurs ont testé 8 tâches d’embedding couvrant 33 modèles sur MTEB, ce qui en fait le benchmark le plus complet pour les embeddings de texte à ce jour.
Ils ont constaté qu’aucune méthode d’embedding unique n’est la meilleure pour toutes les tâches. Cela suggère qu’une méthode universelle d’embedding de texte qui fonctionne le mieux pour toutes les tâches d’embedding n’a pas encore été développée, même à grande échelle. Cela souligne également l’importance de faire preuve de diligence raisonnable pour choisir les modèles d’embedding qui correspondent le mieux à vos besoins.
MTEB est fourni avec du code open source, un classement public et une amusante MTEB Arena pour voter sur des aspects comme les modèles qui récupèrent le meilleur document, effectuent un meilleur clustering, etc., tous deux sur le site web de Hugging Face. Ce benchmark aidera la communauté à tester de nouvelles méthodes de manière cohérente et à suivre les améliorations de la technologie des embeddings de texte.
Contexte et motivation
Les embeddings de texte sont devenus un élément clé de nombreuses tâches de traitement automatique du langage naturel (NLP). Ces embeddings transforment des mots, des phrases ou des documents en représentations numériques qui capturent leur signification. Ils sont utilisés dans diverses applications comme la traduction automatique, la reconnaissance d’entités nommées, la réponse aux questions, l’analyse des sentiments et le résumé automatique.
Au fil des années, les chercheurs ont créé de nombreux jeux de données et benchmarks pour tester ces embeddings. Parmi les plus connus figurent SemEval, GLUE, SuperGLUE, Big-Bench, WordSim353 et SimLex-999. Ceux-ci se concentrent généralement sur l’évaluation des embeddings de mots standard et contextuels.
Cependant, il existe encore des lacunes dans la façon dont les embeddings de texte sont évalués :
Peu de benchmarks couvrent à la fois les embeddings de mots et les embeddings de phrases.
De nombreuses évaluations se concentrent sur des tâches NLP spécifiques, et non sur la capacité des embeddings à capturer le sens global du texte.
Les benchmarks existants ne prennent souvent pas en compte la façon dont les embeddings pourraient être utilisés dans des applications réelles.
Il existe un besoin pour un benchmark complet, capable d’évaluer un large éventail de tâches de compréhension du texte. Ce benchmark devrait être utile à la fois aux chercheurs en NLP et aux personnes travaillant sur des applications pratiques. Le Massive Text Embedding Benchmark (MTEB) vise à combler cette lacune.
Embeddings de texte
Un embedding de texte est une façon de représenter du texte sous forme de liste de nombres. Ces nombres peuvent représenter un seul mot, une phrase ou même un document entier. La liste comporte généralement des centaines de nombres.
Les plongements de texte sont utilisés dans de nombreuses tâches de NLP. Pour les mots, ils sont utilisés dans des choses comme la correction orthographique et la recherche de relations entre les mots. Pour les textes plus longs, ils sont utilisés dans des tâches comme déterminer le sentiment d’un écrit ou générer un nouveau texte.
Il existe de nombreuses façons différentes de créer des plongements de texte. Parmi les méthodes populaires, on trouve :
Les méthodes basées sur les modèles de langage comme ULMFit, GPT, BERT et PEGASUS
Les méthodes entraînées sur diverses tâches de NLP, comme ELMo
Les méthodes basées sur les mots comme word2vec et GloVe, qui sont souvent utilisées dans la recherche en vision par ordinateur
Les chercheurs ont créé de nombreux plongements différents - il y en a au moins 165 à comparer. Ils ont également créé 15 outils différents (comme les arbres de décision et les Random Forests) pour aider à comprendre les forces et les faiblesses de ces plongements.
Cependant, il n’existe pas de méthode standard pour comparer tous ces différents plongements. C’est un problème que le Massive Text Embedding Benchmark (MTEB) tente de résoudre.
Conception et mise en œuvre du Massive Text Embedding Benchmark
MTEB a été conçu avec plusieurs objectifs importants à l’esprit :
Diversité : MTEB teste les modèles de plongement sur de nombreuses tâches différentes. Il comprend 8 types de tâches différents, avec jusqu’à 15 jeux de données pour chacun. Sur les 58 jeux de données au total, 10 fonctionnent avec plusieurs langues, couvrant 112 langues au total. Le benchmark teste à la fois des textes courts (au niveau de la phrase) et longs (au niveau du paragraphe) pour voir comment les modèles se comportent avec différentes longueurs de texte.
Simplicité : MTEB est facile à utiliser. Tout modèle capable de prendre une liste de textes et de produire une liste de représentations numériques (vecteurs) peut être testé. Cela signifie que de nombreux types de modèles différents peuvent être comparés.
Extensibilité : Il est facile d’ajouter de nouveaux jeux de données à MTEB. Pour les tâches existantes, il suffit d’ajouter un fichier qui décrit la tâche et indique où les données sont stockées sur Hugging Face. L’ajout de nouveaux types de tâches demande un peu plus de travail, mais MTEB accueille les contributions de la communauté pour l’aider à se développer.
Reproductibilité : MTEB facilite la répétition des expériences. Il garde une trace des différentes versions des jeux de données et des logiciels. Les résultats de l’article MTEB sont disponibles sous forme de fichiers JSON, afin que chacun puisse les vérifier ou les utiliser.
Ces caractéristiques font de MTEB un outil complet et flexible pour évaluer les modèles de plongement de texte sur des tâches couvrant au total une très large gamme de tâches et de langues.
Tâches et évaluation dans le Massive Text Embedding Benchmark
Massive Text Embedding Benchmark comprend 8 types de tâches différents pour tester les modèles de plongement. Voici une explication simple de chaque tâche :
Exploration de bitextes : Trouver des phrases correspondantes dans deux langues différentes. La principale mesure est le score F1.
Classification : Utiliser les plongements pour classer les textes en catégories. La principale mesure est l’exactitude.
Regroupement : Regrouper des textes similaires. La principale mesure est la v-measure.
Classification par paires : Décider si deux textes sont similaires ou non. La principale mesure est la précision moyenne.
Réordonnancement : Ordonner une liste de textes selon leur correspondance avec une requête. La principale mesure est MAP (Mean Average Precision).
Recherche : Trouver des documents pertinents pour une requête donnée. La principale mesure est nDCG@10.
Similarité textuelle sémantique (STS) : Mesurer à quel point deux phrases sont similaires. La principale mesure est la corrélation de Spearman.
Résumé : Évaluer les résumés générés par machine par rapport à ceux rédigés par des humains. La principale mesure est également la corrélation de Spearman.
Pour chaque tâche, MTEB utilise le modèle d’embedding pour transformer les textes en embeddings vectoriels. Ensuite, il utilise des méthodes comme la similarité cosinus ou la régression logistique pour effectuer la tâche et calculer les scores.
MTEB inclut de nombreux jeux de données pour chaque tâche, couvrant différentes langues et longueurs de texte. Cela permet de tester dans quelle mesure les modèles d’embedding fonctionnent bien dans diverses situations.
En utilisant ces tâches et jeux de données variés, le Massive Text Embedding Benchmark fournit une méthode complète pour évaluer et comparer différents modèles d’embedding de texte.
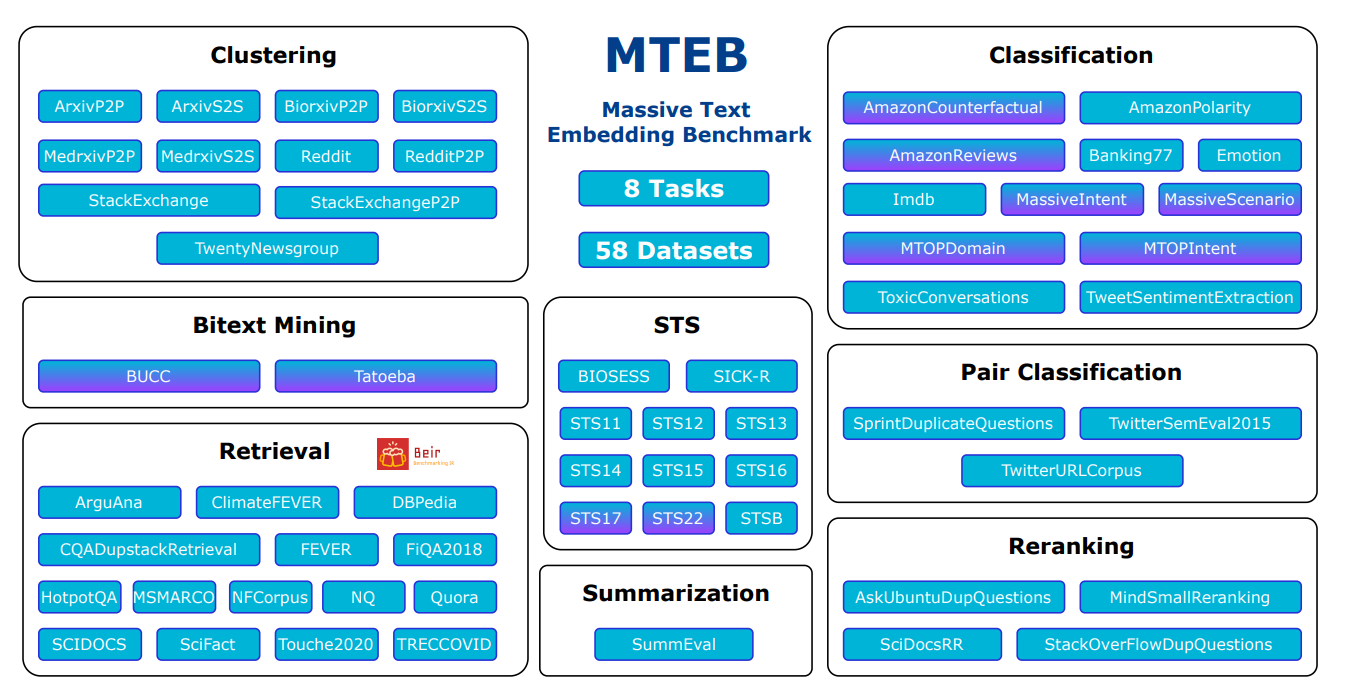 Aperçu des tâches et des jeux de données dans MTEB
Aperçu des tâches et des jeux de données dans MTEB
Source : MTEB : Massive Text Embedding Benchmark
Jeux de données dans le Massive Text Embedding Benchmark
Le Massive Text Embedding Benchmark utilise de nombreux jeux de données différents pour tester une méthode et des modèles particuliers d’embedding de texte. Ces jeux de données sont regroupés en trois principaux types en fonction de la longueur des textes comparés :
Phrase à phrase (S2S) : C’est lorsqu’une phrase est comparée à une autre. Par exemple, dans les tâches de similarité sémantique textuelle, l’objectif est de déterminer à quel point deux phrases sont similaires.
Paragraphe à paragraphe (P2P) : Cela implique de comparer des morceaux de texte plus longs. MTEB ne fixe pas de limite à leur longueur, laissant aux modèles le soin de gérer des textes plus longs si nécessaire. Certaines tâches, comme le clustering, sont effectuées à la fois en S2S (comparaison de simples titres) et en P2P (comparaison de titres et de contenu).
Phrase à paragraphe (S2P) : Cela est utilisé dans certaines tâches de recherche, où une requête courte (phrase) est comparée à des documents plus longs (paragraphes).
MTEB inclut 56 jeux de données différents. Certains de ces jeux de données sont similaires entre eux :
Certains utilisent les mêmes données textuelles sous-jacentes (comme ClimateFEVER et FEVER).
Les jeux de données pour des tâches similaires (comme différentes versions de CQADupstack ou STS) ont tendance à se ressembler.
Les versions S2S et P2P d’un même jeu de données sont souvent similaires.
Les jeux de données portant sur des sujets similaires (comme les articles scientifiques) ont tendance à se ressembler, même s’ils correspondent à des tâches différentes.
En utilisant une gamme aussi large de jeux de données, MTEB peut tester dans quelle mesure les modèles d’embedding fonctionnent avec différents types de texte et différentes tâches. Cela permet de donner une image plus complète des forces et des faiblesses de chaque modèle.
Modèles dans l’évaluation comparative initiale du Massive Text Embedding Benchmark
Pour la première série de tests avec MTEB, les chercheurs ont examiné des modèles qui prétendent être les meilleurs ainsi que ceux qui sont populaires sur le Hugging Face Hub. Cela signifie qu’ils ont testé de nombreux modèles transformer. Ils ont regroupé les modèles en trois types afin d’aider les gens à choisir celui qui convient le mieux à leurs besoins :
Modèles les plus rapides : Les modèles comme Glove sont très rapides, mais ils ne comprennent pas bien le contexte. Cela signifie qu’ils n’obtiennent pas un score global aussi élevé sur MTEB.
Modèles équilibrés : Les modèles comme all-mpnet-base-v2 ou all-MiniLM-L6-v2 sont un peu plus lents que les plus rapides, mais ils sont bien plus performants. Ils offrent un bon équilibre entre vitesse et qualité.
Modèles les plus performants : Les grands modèles comptant des milliards de paramètres, comme ST5-XXL, GTR-XXL ou SGPT-5.8B-msmarco, obtiennent les meilleurs résultats sur MTEB. Mais ils peuvent être plus lents et nécessiter davantage de stockage. Par exemple, SGPT-5.8B-msmarco crée des embeddings avec 4096 nombres, ce qui prend plus d’espace.
Il est important de noter que les performances d’un modèle peuvent beaucoup varier selon la tâche et le jeu de données spécifiques. Les chercheurs suggèrent de consulter le classement MTEB pour voir quel modèle pourrait le mieux fonctionner pour une tâche unique et vos besoins spécifiques.
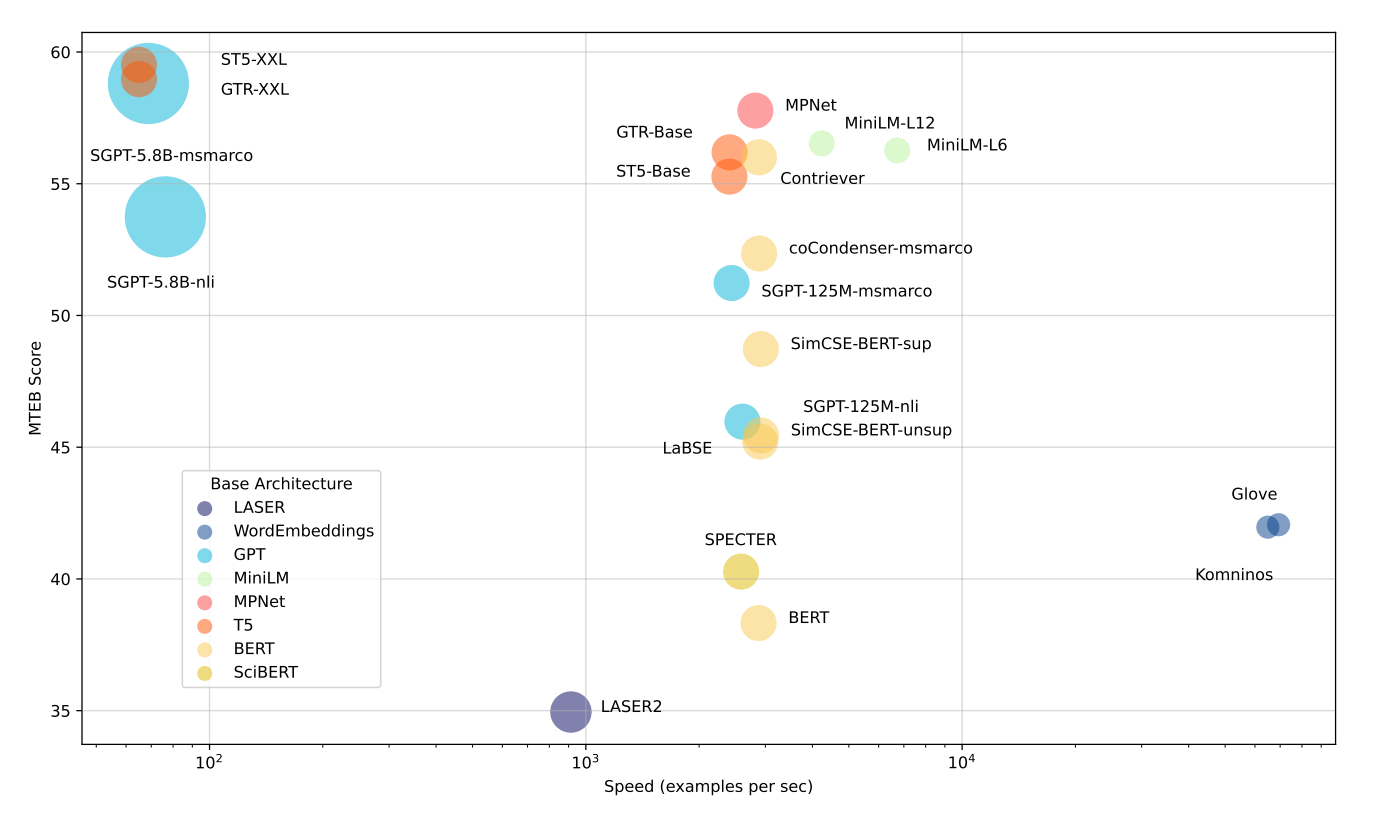 Résultats des benchmarks du test initial
Résultats des benchmarks du test initial
Source : MTEB: Massive Text Embedding Benchmark
Cette approche de test donne une vision claire des compromis entre vitesse et performance dans différents modèles d’embeddings, aidant les utilisateurs à prendre des décisions éclairées en fonction de leurs besoins spécifiques. Si vous souhaitez l’essayer vous-même, il existe un excellent blog sur Huggigng Face qui vous guide dans l’évaluation de tout modèle produisant des embeddings vectoriels.
Quand utiliser le Massive Text Embedding Benchmark
MTEB est un outil permettant de tester l’efficacité des modèles d’embeddings de texte sur de nombreuses tâches différentes. Il est utile dans plusieurs situations :
Tester votre modèle : Si vous avez créé un nouveau modèle d’embedding, vous pouvez utiliser MTEB pour voir comment il se compare à d’autres modèles. Vous pouvez ajouter vos résultats au classement public, ce qui vous aide à voir comment votre modèle se situe par rapport aux autres.
Choisir le bon modèle : Différents modèles fonctionnent mieux pour différentes tâches. Le classement de MTEB montre les performances des modèles sur diverses tâches, vous aidant à choisir le meilleur modèle pour vos besoins spécifiques.
Aider à améliorer MTEB : MTEB est open source et donc ouvert aux contributions de tous. Si vous avez créé une nouvelle tâche, un jeu de données, une méthode de mesure des performances ou un modèle, vous pouvez l’ajouter à MTEB. Cela contribue à rendre le benchmark encore meilleur.
Recherche : Si vous étudiez les embeddings de texte, MTEB vous offre une méthode approfondie pour tester les modèles. Il peut vous montrer ce que les meilleurs modèles actuels peuvent faire et où il existe une marge d’amélioration.
En fournissant une méthode standard pour tester les modèles sur de nombreuses tâches, MTEB aide les chercheurs et les développeurs à comprendre et à améliorer la technologie des embeddings de texte. C’est un outil précieux pour toute personne travaillant avec des embeddings de texte ou les étudiant.
Comment utiliser le classement du Massive Text Embedding Benchmark
Tout d’abord, ne vous laissez pas induire en erreur par les scores MTEB !
MTEB est un outil utile, mais il est important de comprendre ses limites. Bien qu’il affiche des scores, il ne vous dit pas si les différences entre les scores sont significatives. De nombreux modèles de premier plan ont des scores moyens très proches, issus de nombreuses tâches différentes, mais aucune information n’indique dans quelle mesure ces scores varient. Le meilleur modèle peut sembler supérieur, mais la différence peut ne pas être importante. Les utilisateurs peuvent obtenir les résultats bruts pour le vérifier eux-mêmes. Certains chercheurs ont constaté que plusieurs modèles de premier plan dans certains benchmarks linguistiques sont en réalité équivalents, statistiquement parlant. Au lieu de simplement regarder les scores moyens, il est préférable de se concentrer sur la façon dont les modèles se comportent sur des tâches similaires au cas d’usage prévu. Cela peut fournir plus d’informations sur la façon dont un modèle fonctionnera pour une application spécifique que le score global. Il n’est pas nécessaire d’étudier les jeux de données en détail, mais il est utile de savoir quel type de texte ils contiennent. Ces informations sont généralement disponibles dans la description du jeu de données et grâce à un rapide coup d’œil à quelques exemples. Le Massive Text Embedding Benchmark est un outil utile, mais il n’est pas parfait. Il est important de réfléchir de manière critique aux résultats et à la façon dont ils s’appliquent à des besoins spécifiques. Plutôt que de simplement choisir le modèle ayant le score global le plus élevé, il vaut mieux approfondir l’analyse pour trouver le meilleur modèle pour la tâche à accomplir.
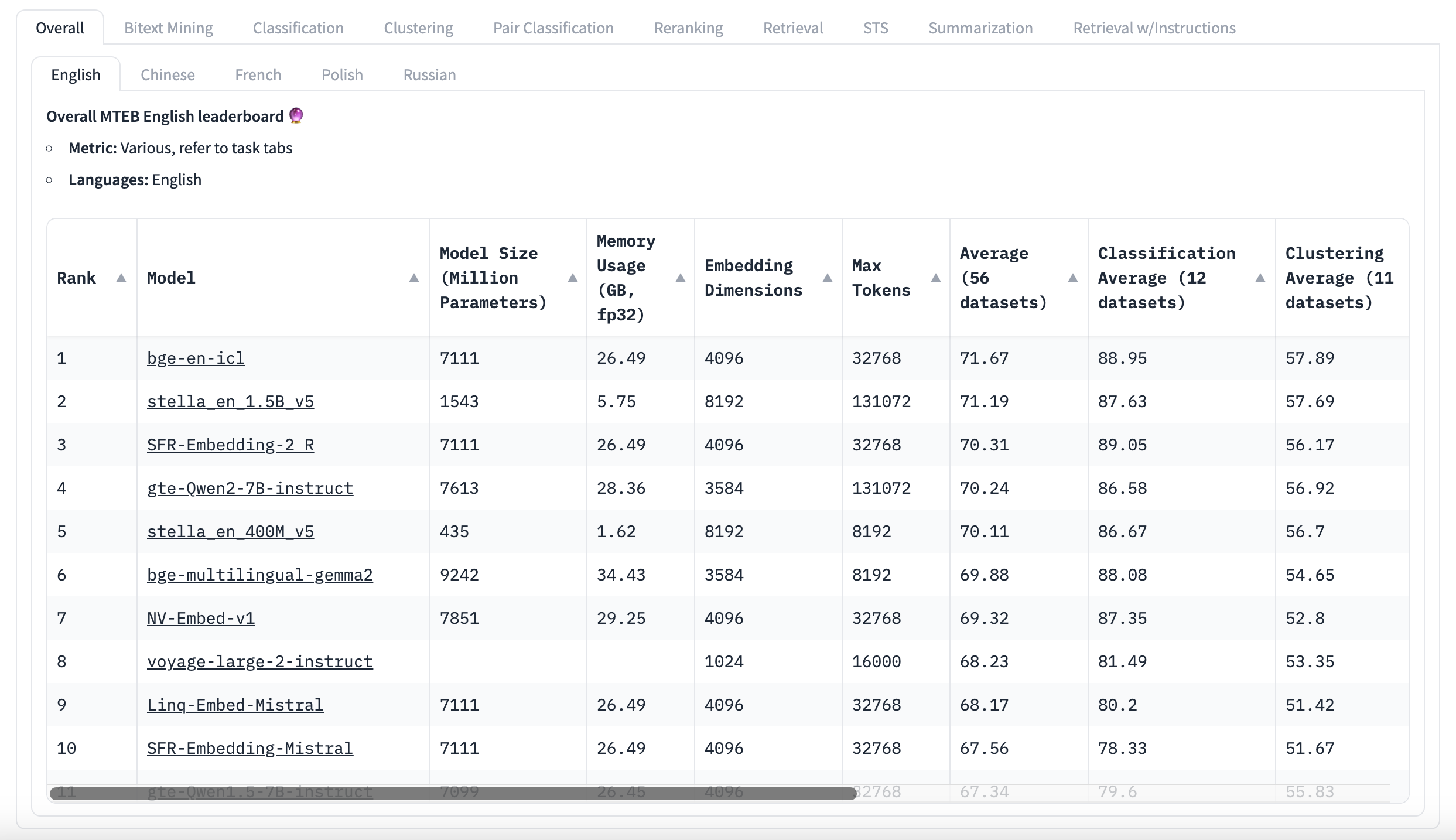 Classement MTEB anglais
Classement MTEB anglais
N’oubliez pas de prendre en compte les besoins de votre application
Il n’existe pas de modèle universel adapté à toutes les tâches. C’est pourquoi le Massive Text Embedding Benchmark existe : pour vous aider à choisir le bon modèle selon vos besoins spécifiques. Lorsque vous consultez le classement du Massive Text Embedding Benchmark, il est important de réfléchir à ce que votre application exige. Voici quelques éléments à prendre en compte :
Langue : Le modèle prend-il en charge la langue avec laquelle vous travaillez ?
Vocabulaire spécialisé : Si vous travaillez avec des textes financiers ou juridiques, vous aurez besoin d’un modèle qui comprend les termes propres au domaine.
Taille du modèle : Réfléchissez à l’endroit où vous exécuterez le modèle. Devra-t-il tenir sur un ordinateur portable ?
Utilisation de la mémoire : Quelle quantité de mémoire informatique pouvez-vous consacrer au modèle ?
Longueur maximale d’entrée : Quelle sera la longueur des textes avec lesquels vous travaillerez ?
Une fois que vous savez ce qui est important pour votre tâche, vous pouvez trier différents modèles sur le classement MTEB en fonction de ces caractéristiques. Cela facilite la recherche d’un modèle qui non seulement offre de bonnes performances, mais répond également à vos exigences pratiques.
En tenant compte à la fois des performances et des besoins pratiques, vous pouvez choisir le modèle qui convient le mieux à votre situation spécifique.
La ressource Zilliz AI Model
Maintenant que vous avez choisi votre modèle d’embedding de texte à partir du Massive Text Embedding Benchmark, mettons-le à contribution pour créer des embeddings de texte à stocker et à récupérer dans Milvus open source ou Zilliz Cloud. Sur le site web de Zilliz, vous pouvez trouver la page AI Models, qui répertorie certains des modèles multimodaux et d’embedding de texte les plus populaires.
 Page Zilliz AI Model
Page Zilliz AI Model
Une fois que vous sélectionnez un modèle sur cette page, vous pouvez voir qu’il existe quelques instructions détaillées sur la manière de créer les embeddings vectoriels à l’aide des différents SDK, de PyMilvus, et plus encore.
Conclusion
Le Massive Text Embedding Benchmark (MTEB) représente une avancée significative dans l’évaluation des modèles d’embedding de texte. Il répond aux limites des benchmarks précédents en couvrant un large éventail de tâches, de langues et de longueurs de texte. La conception de MTEB met l’accent sur la diversité, la simplicité, l’extensibilité et la reproductibilité, ce qui en fait un outil précieux pour les chercheurs comme pour les praticiens dans le domaine du traitement automatique du langage naturel.
L’approche de benchmark la plus complète de MTEB, qui teste les modèles sur 8 tâches différentes et 58 jeux de données, fournit une image plus complète des capacités d’un modèle que les benchmarks précédents. Elle révèle qu’aucune méthode d’embedding unique n’excelle dans toutes les tâches, soulignant l’importance de choisir le bon modèle pour des applications spécifiques.
Lors de l’utilisation de MTEB, il est essentiel de regarder au-delà des scores globaux et de prendre en compte les besoins spécifiques de votre application. Des facteurs tels que la prise en charge des langues, le vocabulaire spécialisé, la taille du modèle, l’utilisation de la mémoire et la longueur maximale d’entrée doivent tous jouer un rôle dans le processus de décision.
Bien que MTEB soit un outil puissant, il est important de l’utiliser avec esprit critique. Les différences de scores entre les meilleurs modèles peuvent ne pas toujours être statistiquement significatives, et les performances peuvent varier considérablement selon la tâche et le jeu de données spécifiques.
En tant que projet open source, MTEB accueille les contributions de la communauté, ce qui lui permet de se développer et de s’adapter aux besoins évolutifs du domaine. Cette approche collaborative garantit que MTEB continuera d’être une ressource pertinente et précieuse pour évaluer et améliorer la technologie d’embedding de texte.
En fournissant une manière standardisée d’évaluer les modèles d’embedding de texte sur un large éventail de tâches et de langues, MTEB contribue à faire progresser le domaine, conduisant au final à des modèles d’embedding de texte meilleurs et plus polyvalents pour diverses applications.
Références
Muennighoff, Niklas and Tazi, Nouamane and Magne, Lo{\"\i}c and Reimers, Nils. "MTEB: Massive Text Embedding Benchmark" arXiv 2022
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff. "C-Pack: Packaged Resources To Advance General Chinese Embedding" arXiv 2023
Michael Günther, Jackmin Ong, Isabelle Mohr, Alaeddine Abdessalem, Tanguy Abel, Mohammad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, Maximilian Werk, Nan Wang, Han Xiao. "Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents" arXiv 2023
Silvan Wehrli, Bert Arnrich, Christopher Irrgang. "German Text Embedding Clustering Benchmark" arXiv 2024
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, Luca Soldaini. "FollowIR : Évaluer et apprendre aux modèles de recherche d’information à suivre des instructions" arXiv 2024
Dawei Zhu, Liang Wang, Nan Yang, Yifan Song, Wenhao Wu, Furu Wei, Sujian Li. "LongEmbed : Étendre les modèles d’embedding pour la recherche en contexte long" arXiv 2024
Kenneth Enevoldsen, Márton Kardos, Niklas Muennighoff, Kristoffer Laigaard Nielbo. "The Scandinavian Embedding Benchmarks : Évaluation complète de l’embedding de texte multilingue et monolingue" arXiv 2024
- Contexte et motivation
- Embeddings de texte
- Conception et mise en œuvre du Massive Text Embedding Benchmark
- Quand utiliser le Massive Text Embedding Benchmark
- Comment utiliser le classement du Massive Text Embedding Benchmark
- La ressource Zilliz AI Model
- Conclusion
- Références
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement