




10 frameworks LLM open-source que les développeurs ne peuvent ignorer en 2025
2024 a été une année faste pour les [grands modèles de langage (LLM)] (https://zilliz.com/glossary/large-language-models-(llms)), et à l'aube de 2025, l'élan ne montre aucun signe de ralentissement. Du GPT-4 et des capacités multimodales de Gemini aux systèmes d'IA adaptatifs en temps réel, les LLM ne sont plus seulement à la pointe de la technologie, ils sont essentiels. Ils alimentent les chatbots, les moteurs de recherche, les outils de création de contenu et même l'automatisation de flux de travail que l'on pensait autrefois réservés aux humains.
Mais voilà : disposer d'un LLM puissant ne représente que la moitié de la bataille. Construire des applications LLM évolutives, efficaces et prêtes pour la production peut s'avérer difficile, et c'est là que les frameworks LLM entrent en jeu. Ils simplifient les flux de travail, améliorent les performances et s'intègrent parfaitement aux systèmes existants, aidant ainsi les développeurs à exploiter tout le potentiel de ces modèles avec moins d'efforts.
Dans ce billet, nous allons mettre en lumière 10 frameworks LLM open-source que les développeurs d'IA ne peuvent pas ignorer à l'horizon 2025. Ces frameworks sont les armes secrètes qui permettent aux développeurs de mettre à l'échelle, d'optimiser et d'innover plus rapidement que jamais. Si vous êtes prêt à améliorer vos projets d'IA, plongeons dans l'aventure !
LangChain : Alimenter des flux de travail d'IA multi-étapes tenant compte du contexte
[LangChain] (https://github.com/langchain-ai/langchain) est un cadre open-source conçu pour rationaliser le développement d'applications basées sur de grands modèles de langage (LLM). Il simplifie la création de flux de travail qui combinent les LLM avec des sources de données externes, des API ou une logique de calcul, permettant aux développeurs de créer des systèmes dynamiques et contextuels pour des tâches telles que les agents conversationnels, l'analyse de documents et le résumé.
Principales capacités
Pipelines composables** : LangChain facilite l'enchaînement de plusieurs appels LLM et fonctions externes, ce qui permet des flux de travail complexes en plusieurs étapes.
Chaînes prêtes à l'emploi** : LangChain propose des chaînes préconfigurées, des assemblages organisés de composants conçus pour accomplir des tâches spécifiques de haut niveau. Ces chaînes prêtes à l'emploi simplifient le lancement des projets.
Utilitaires pour l'ingénierie de la conception** : Comprend des outils permettant de créer, de gérer et d'optimiser des messages-guides adaptés à des tâches spécifiques.
Gestion de la mémoire** : Offre des capacités intégrées pour conserver le contexte conversationnel à travers les interactions, permettant ainsi des applications plus personnalisées.
LangChain s'est connecté à des API tierces, à des bases de données vectorielles, à des LLM et à diverses sources de données. En particulier, l'intégration de LangChain avec des [bases de données vectorielles] (https://zilliz.com/learn/what-is-vector-database) telles que [Milvus] (https://zilliz.com/what-is-milvus) et [Zilliz Cloud] (https://zilliz.com/cloud) renforce encore son potentiel. Milvus est une base de données vectorielles open-source très performante qui permet de gérer et d'interroger des vecteurs d'intégration à l'échelle du milliard. Elle complète les capacités de LangChain en permettant une récupération rapide et précise des données pertinentes. Les développeurs peuvent tirer parti de cette intégration pour créer des systèmes évolutifs [Retrieval-Augmented Generation (RAG)] (https://zilliz.com/learn/Retrieval-Augmented-Generation) dans lesquels Milvus récupère des documents pertinents sur le plan contextuel. LangChain utilise un modèle génératif pour produire des résultats précis et pertinents. Pour plus d'informations, consultez les ressources ci-dessous :
Déverrouiller le pouvoir des langues : introduction à LangChain
Comment construire un RAG multilingue avec Milvus, LangChain et OpenAI
LlamaIndex : Connecter les LLM à diverses sources de données
[LlamaIndex**] (https://github.com/run-llama/llama_index) est un cadre open-source qui permet aux grands modèles de langage (LLM) d'accéder efficacement à diverses sources de données et de les exploiter. Il simplifie l'ingestion, la structuration et l'interrogation de données non structurées, ce qui facilite la création d'applications d'IA avancées telles que la recherche de documents, le résumé et les chatbots basés sur les connaissances.
Principales capacités
Connecteurs de données** : Fournit un ensemble robuste de connecteurs pour l'acquisition de données structurées et non structurées à partir de diverses sources telles que les PDF, les bases de données SQL, les API et les magasins vectoriels.
Outils d'indexation** : Permet aux développeurs de créer des index personnalisés, y compris des structures basées sur des arbres, des listes et des graphes, afin d'optimiser l'interrogation et la récupération des données.
Optimisation des requêtes** : Offre des mécanismes d'interrogation avancés qui permettent d'obtenir des réponses précises et adaptées au contexte.
Extensibilité** : Hautement modulaire, ce qui facilite l'intégration de bibliothèques et d'outils externes pour améliorer les fonctionnalités.
Cadre optimisé pour les LLM** : Conçu pour fonctionner avec les LLM, il garantit une utilisation efficace des ressources informatiques pour les tâches à grande échelle.
LlamaIndex s'est intégré à diverses bases de données vectorielles spécialisées telles que Milvus et Zilliz Cloud pour prendre en charge des flux de travail RAG évolutifs et efficaces. Dans cette configuration, Milvus agit comme un backend de haute performance pour le stockage et l'interrogation des vecteurs d'intégration, tandis que LlamaIndex structure et organise les données récupérées pour que les LLM puissent les traiter. Cette combinaison permet aux développeurs de récupérer les points de données les plus pertinents et aux LLM de fournir des résultats plus précis et adaptés au contexte. Pour plus d'informations, consultez les ressources ci-dessous :
Docs | Documentation QA using Zilliz Cloud and LlamaIndex](https://zilliz.com/learn/milvus-notebooks)
Vidéo | Stockage vectoriel persistant avec LlamaIndex](https://www.youtube.com/watch?v=S4GmdrlqVKc)
Haystack : Rationalisation des pipelines RAG pour des applications d'IA prêtes à la production
[Haystack] (https://haystack.deepset.ai/) est un framework Python open-source conçu pour faciliter le développement d'applications alimentées par des LLM. Il permet aux développeurs de créer des solutions d'IA de bout en bout en intégrant les LLM à diverses sources de données et composants, ce qui le rend adapté à des tâches telles que le RAG, la recherche de documents, la réponse à des questions et la génération de réponses.
Principales capacités
Pipelines flexibles** : Haystack permet la création de pipelines modulaires pour des tâches telles que la recherche de documents, la réponse à des questions et le résumé. Les développeurs peuvent combiner différents composants pour adapter les flux de travail à leurs besoins spécifiques.
Architecture récupérateur-lecteur** : Combine des extracteurs pour un filtrage efficace des documents avec des lecteurs (par exemple, LLM) pour générer des réponses précises et contextuelles.
Agnostique au niveau du backend** : Prend en charge plusieurs bases de données vectorielles, y compris Milvus et [FAISS] (https://zilliz.com/learn/faiss), ce qui garantit la flexibilité du déploiement.
Intégration avec les systèmes linguistiques (LLM) : Intégration transparente avec les modèles de langage, permettant aux développeurs d'utiliser des modèles pré-entraînés et affinés pour diverses tâches.
Évolutivité et performances** : Optimisé pour traiter des ensembles de données à grande échelle et des requêtes à haut débit, il convient aux applications d'entreprise.
En mars 2024, Haystack a publié Haystack 2.0, introduisant une architecture plus flexible et personnalisable. Cette mise à jour permet de créer des pipelines complexes avec des fonctionnalités telles que le branchement parallèle et le bouclage, en améliorant la prise en charge des LLM et du comportement agentique. La nouvelle conception met l'accent sur une interface commune pour le stockage des données, offrant des intégrations avec diverses bases de données et magasins de vecteurs, y compris Milvus et Zilliz Cloud. Cette flexibilité garantit que les données peuvent être facilement accessibles et gérées dans les pipelines Haystack, ce qui favorise le développement d'applications d'IA évolutives et performantes. Pour plus d'informations, consultez les ressources ci-dessous :
Haystack GitHub : https://github.com/deepset-ai/haystack
Intégration : [Haystack et Milvus] (https://zilliz.com/product/integrations/haystack)
Tutoriel: Retrieval-Augmented Generation (RAG) avec Milvus et Haystack
Tutoriel: Construire un pipeline RAG avec Milvus et Haystack 2.0
Dify : Simplifier le développement d'applications alimentées par LLM
[Dify**] (https://github.com/langgenius/dify) est une plateforme open-source pour la création d'applications d'intelligence artificielle. Elle combine Backend-as-a-Service avec LLMOps, en prenant en charge les modèles de langage courants et en offrant une interface d'orchestration intuitive. Dify fournit des moteurs RAG de haute qualité, un cadre d'agent d'IA flexible et un flux de travail intuitif à code bas, permettant aux développeurs et aux utilisateurs non techniques de créer des solutions d'IA innovantes.
Principales capacités
Backend-as-a-Service pour les LLM** : Gère l'infrastructure dorsale, ce qui permet aux développeurs de se concentrer sur la création d'applications plutôt que sur la gestion des serveurs.
Orchestration des messages-guides** : Simplifie la création, le test et la gestion d'invites adaptées à des tâches spécifiques.
Analyse en temps réel** : Fournit des informations sur les performances des modèles, les interactions des utilisateurs et le comportement des applications afin d'optimiser les flux de travail.
Options d'intégration étendues** : Connexion avec des API tierces, des outils externes et les LLM les plus courants, offrant une grande flexibilité pour les flux de travail personnalisés.
Dify s'intègre bien aux bases de données vectorielles telles que Milvus, améliorant ainsi sa capacité à gérer des tâches complexes de recherche de données à grande échelle. En associant Dify à Milvus, les développeurs peuvent créer des systèmes qui stockent, récupèrent et traitent efficacement les embeddings pour des tâches telles que RAG.
Tutoriel : [Déploiement de Dify avec Milvus ] (https://milvus.io/docs/dify_with_milvus.md)
Documentation de Dify](https://docs.dify.ai/)
Letta (Précédemment MemGPT) : Construire des agents RAG avec une fenêtre de contexte LLM étendue
Letta est un cadre open-source conçu pour améliorer les LLM en les dotant d'une mémoire à long terme. Contrairement aux LLM traditionnels qui traitent les entrées de manière statique, Letta permet au modèle de se souvenir des interactions passées et d'y faire référence, ce qui permet de créer des applications plus dynamiques, contextuelles et personnalisées. Il intègre des techniques de gestion de la mémoire pour stocker, récupérer et mettre à jour les informations au fil du temps, ce qui le rend idéal pour créer des agents intelligents et des systèmes conversationnels qui évoluent avec les interactions de l'utilisateur.
Figure - Comment Letta fonctionne avec divers outils d'intelligence artificielle] (https://assets.zilliz.com/Figure_How_Letta_works_with_various_AI_tools_05d96d2548.png)
Principales capacités
Mémoire auto-éditrice:** Letta introduit une mémoire auto-éditrice, permettant aux agents de mettre à jour de manière autonome leur base de connaissances, d'apprendre de leurs interactions et de s'adapter au fil du temps.
Environnement de développement d'agents (ADE):** Fournit une interface graphique pour la création, le déploiement, l'interaction et l'observation d'agents d'intelligence artificielle, rationalisant ainsi le processus de développement et de débogage.
Persistance et gestion de l'état:** Garantit que les agents maintiennent une continuité entre les sessions en conservant leur état, y compris les souvenirs et les interactions, ce qui permet des réponses plus cohérentes et plus pertinentes en fonction du contexte.
Intégration d'outils:** Prend en charge l'incorporation d'outils et de sources de données personnalisés, permettant aux agents d'effectuer un large éventail de tâches et d'accéder à des informations externes si nécessaire.
Architecture agnostique:** Conçue pour fonctionner avec différents LLM et systèmes RAG, offrant une flexibilité dans le choix et l'intégration de différents fournisseurs de modèles.
Letta s'est intégré aux bases de données vectorielles les plus courantes afin d'améliorer sa mémoire et ses capacités de récupération pour les flux de travail RAG avancés. En s'appuyant sur un stockage vectoriel évolutif et une recherche de similarité efficace, Letta permet aux agents d'intelligence artificielle d'accéder à la connaissance contextuelle à long terme et de la conserver, garantissant ainsi une récupération rapide et précise des données. Cette intégration permet aux développeurs de créer des applications plus intelligentes et contextuelles adaptées à des domaines spécifiques, tels que le support client ou les recommandations personnalisées, tout en conservant une mémoire persistante et évolutive. Consultez les ressources ci-dessous pour plus d'informations.
- Tutoriel [MemGPT avec intégration Milvus] (https://milvus.io/docs/integrate_with_memgpt.md)
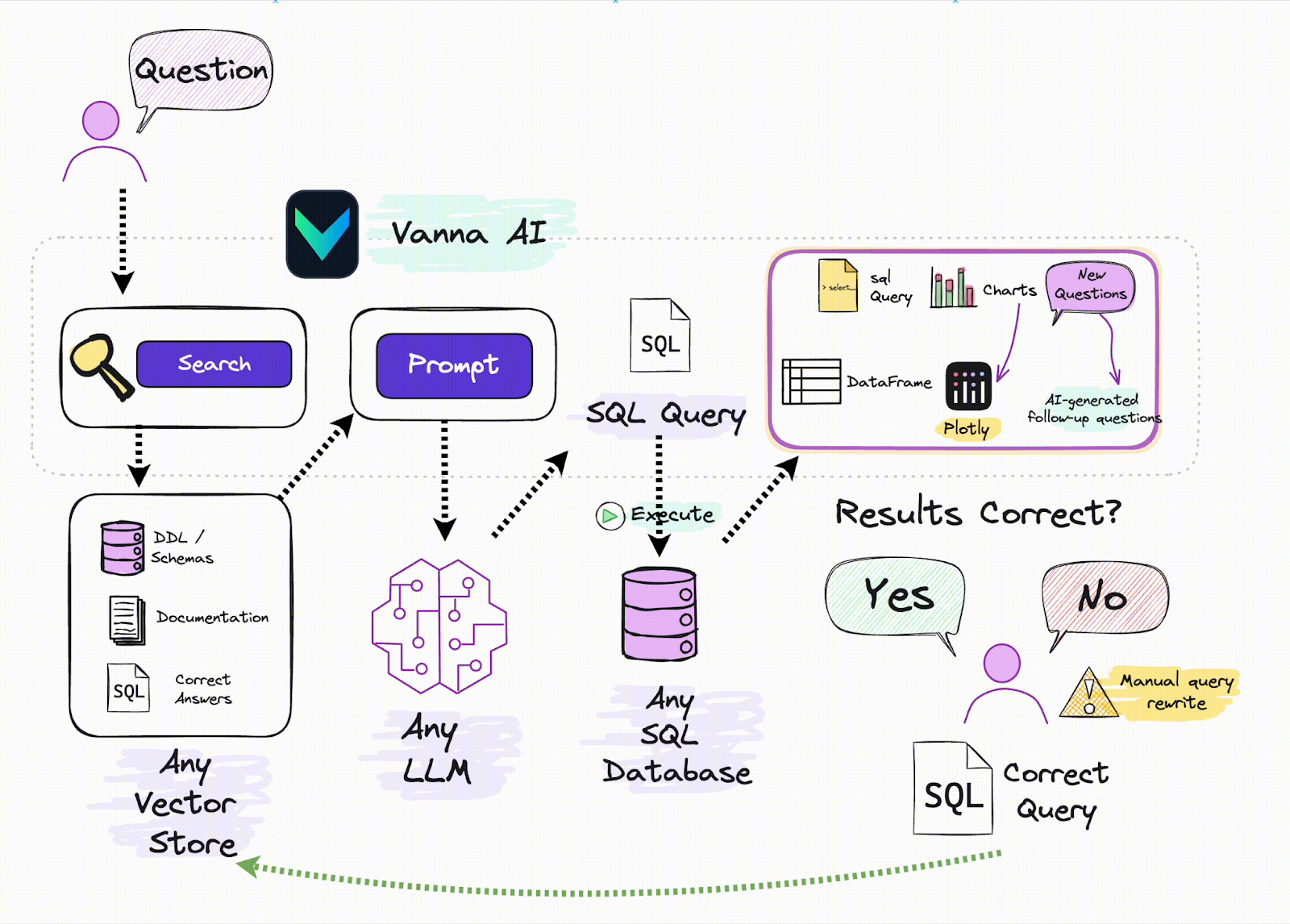
Vanna : Génération de SQL par l'IA
Vanna est un framework Python open-source conçu pour simplifier la génération de requêtes SQL à partir d'entrées en langage naturel. En s'appuyant sur les techniques RAG, Vanna permet aux utilisateurs d'entraîner des modèles sur leurs données spécifiques, ce qui leur permet de poser des questions et de recevoir des requêtes SQL précises adaptées à leurs bases de données. Cette approche simplifie le processus d'interaction avec les bases de données et le rend plus accessible aux utilisateurs qui n'ont pas de connaissances approfondies en SQL.
 Vanna
Vanna
Principales capacités
Conversion du langage naturel en langage SQL** : Vanna permet aux utilisateurs de saisir des questions en langage naturel, qu'il convertit ensuite en requêtes SQL précises exécutables sur la base de données connectée.
Prise en charge de plusieurs bases de données** : Le framework offre un support prêt à l'emploi pour diverses bases de données, notamment Snowflake, BigQuery, Postgres, et plus encore. Il permet également une intégration facile avec n'importe quelle base de données grâce à des connecteurs personnalisés.
Flexibilité de l'interface utilisateur** : Vanna offre de multiples options d'interface utilisateur, telles que Jupyter Notebooks, Slackbot, web apps et Streamlit apps, permettant aux utilisateurs de choisir l'interface frontale qui correspond le mieux à leur flux de travail.
Vanna et les bases de données vectorielles sont une excellente combinaison pour construire des systèmes RAG efficaces. Lorsqu'un utilisateur saisit une requête en langage naturel, Vanna utilise une base de données vectorielle pour récupérer les données pertinentes basées sur des encastrements vectoriels pré-enregistrés. Ces données sont ensuite utilisées pour aider Vanna à générer une requête SQL précise, facilitant ainsi l'extraction de données structurées à partir d'une base de données relationnelle. En combinant la puissance de la recherche vectorielle avec la génération de requêtes SQL, Vanna simplifie le travail avec des données non structurées et permet aux utilisateurs d'interagir avec des ensembles de données complexes sans avoir besoin de connaissances SQL avancées. Pour plus d'informations, consultez les ressources ci-dessous :
Tutoriel : Ecrire SQL avec Vanna et Milvus
Milvus + Vanna : AI-Powered SQL Generation](https://zilliz.com/product/integrations/vanna-ai)
Kotaemon : Construction d'un système d'assurance qualité de documents alimenté par l'IA
Kotaemon est une interface RAG open-source et personnalisable pour dialoguer avec vos documents. Il fournit une interface web propre et multi-utilisateurs pour l'assurance qualité des documents, prenant en charge les modèles de langage locaux et basés sur l'API. kotaemon offre un pipeline RAG hybride avec des capacités de recherche en texte intégral et vectorielle, permettant une assurance qualité multimodale pour les documents contenant des figures et des tableaux.
Conçu pour les utilisateurs finaux et les développeurs, kotaemon prend en charge des méthodes de raisonnement complexes telles que ReAct et ReWOO. Il propose des citations avancées avec des aperçus de documents, des paramètres configurables pour l'extraction et la génération, et un cadre extensible pour la construction de pipelines RAG personnalisés.
 Kotaemon
Kotaemon
Principales capacités
Déploiement facile** : Kotaemon offre des interfaces simples pour déployer les LLM en production avec une configuration minimale, permettant une mise à l'échelle et une intégration rapides.
Pipelines personnalisables** : Il permet aux développeurs de personnaliser facilement les flux de travail d'IA, en combinant les LLM avec des API externes, des bases de données et d'autres outils.
Promesses avancées** : Il comprend des outils intégrés pour l'ingénierie et l'optimisation des requêtes, ce qui permet d'affiner les résultats des modèles pour des tâches spécifiques.
Optimisation des performances** : Conçu pour des opérations de haute performance, Kotaemon garantit des réponses à faible latence et une utilisation efficace des ressources.
Support multi-modèle** : Le framework supporte différentes architectures LLM, donnant aux développeurs la flexibilité de choisir le meilleur modèle pour leur cas d'utilisation spécifique.
Kotaemon s'intègre aux bases de données vectorielles telles que Milvus, permettant la récupération rapide de données pertinentes pour des tâches telles que Retrieval-Augmented Generation (RAG). En exploitant les capacités de recherche vectorielle efficaces de Milvus, Kotaemon peut améliorer le contexte et la pertinence des résultats générés par l'IA. Cette intégration permet aux développeurs de construire des systèmes d'IA qui génèrent du contenu et récupèrent des informations pertinentes à partir de grands ensembles de données, améliorant ainsi les performances globales et la précision.
Kotaemon RAG avec Milvus | Documentation](https://milvus.io/docs/kotaemon_with_milvus.md)
Zilliz Cloud + Kotaemon : AI-Powered Document QA](https://zilliz.com/product/integrations/kotaemon)
vLLM : Inférence LLM haute performance pour les applications d'IA en temps réel
vLLM est une bibliothèque open-source développée par le SkyLab de l'UC Berkeley, conçue pour optimiser l'inférence et le service LLM. En mettant l'accent sur les performances et l'évolutivité, vLLM introduit des innovations telles que [PagedAttention] (https://zilliz.com/learn/efficient-memory-management-for-llm-serving-pagedattention), qui augmente les vitesses de service jusqu'à 24 fois tout en réduisant de moitié l'utilisation de la mémoire GPU par rapport aux approches traditionnelles. Cela change la donne pour les développeurs d'applications d'IA exigeantes qui requièrent une utilisation efficace des ressources matérielles.
Principales capacités :
Technologie PagedAttention: Améliore la gestion de la mémoire en permettant le stockage non contigu des clés et des valeurs d'attention, réduisant ainsi le gaspillage de mémoire et améliorant le débit jusqu'à 24 fois.
La mise en lot continue : regroupe les demandes entrantes en temps réel, maximise l'utilisation du GPU et minimise les temps d'inactivité, ce qui se traduit par un débit plus élevé et une latence réduite.
Streaming Outputs:** Génération de jetons en temps réel, permettant aux applications de fournir des résultats partiels immédiatement, ce qui est idéal pour les interactions en temps réel avec les utilisateurs, comme les chatbots.
Compatibilité avec de nombreux modèles:** Prend en charge les architectures LLM les plus courantes telles que GPT et LLaMA, garantissant une flexibilité pour de nombreux cas d'utilisation et une intégration transparente avec les flux de travail existants.
Serveur API compatible avec OpenAI:** Offre une interface API qui reflète celle d'OpenAI, simplifiant le déploiement et l'intégration dans les systèmes existants pour les développeurs familiarisés avec les API d'OpenAI.
vLLM devient la pierre angulaire de la construction de systèmes RAG à haute performance lorsqu'il est associé à des bases de données vectorielles telles que Milvus. Les bases de données vectorielles stockent et récupèrent de manière efficace les encastrements à haute dimension, essentiels à la récupération d'informations contextuelles pertinentes. vLLM complète ces bases de données en fournissant une inférence LLM optimisée, garantissant que les informations récupérées sont traitées de manière transparente dans des réponses précises et adaptées au contexte. Cette intégration améliore les performances des applications et permet de relever des défis tels que les hallucinations de l'IA en ancrant les résultats dans les données récupérées. Consultez les ressources ci-dessous pour plus d'informations.
Déploiement d'un système RAG multimodal avec vLLM et Milvus] (https://zilliz.com/blog/deploy-multimodal-rag-using-vllm-and-milvus)
[Création d'applications RAG avec Milvus, Qwen et vLLM] (https://zilliz.com/blog/build-rag-app-with-milvus-qwen-and-vllm)
Gestion efficace de la mémoire pour les grands modèles de langage avec PagedAttention
Unstructured : Rendre les données non structurées accessibles à la GenAI
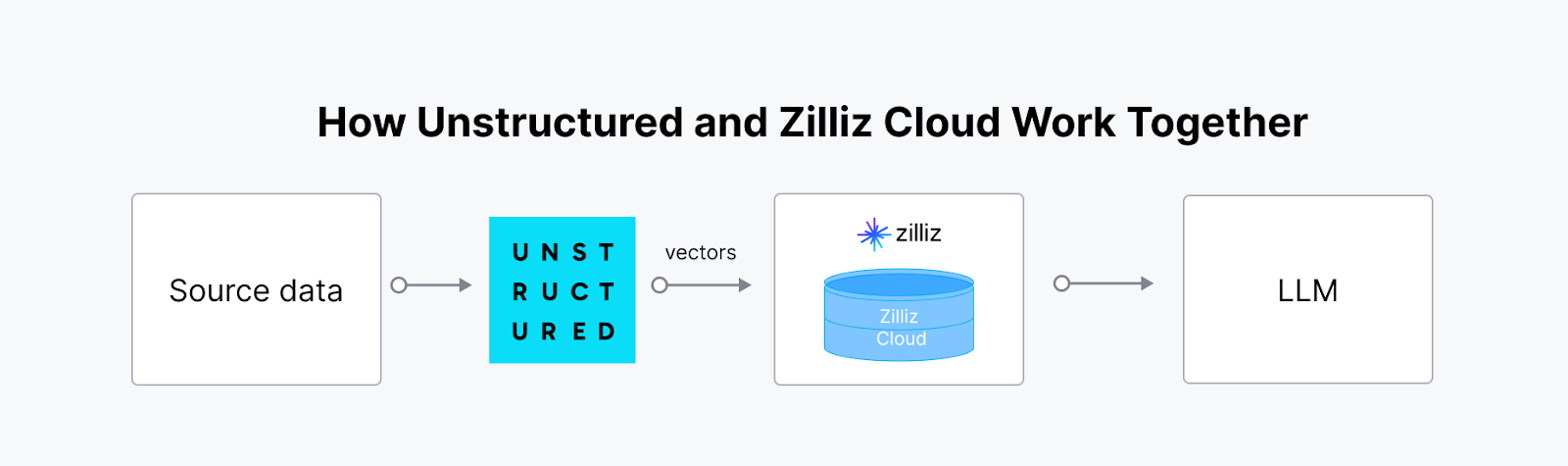
Unstructured est une bibliothèque open-source qui rationalise l'ingestion et le prétraitement des données non structurées de divers formats, y compris les PDF, HTML, les documents Word et les images. Elle offre des fonctions modulaires de partitionnement, de nettoyage, d'extraction, de mise en scène et de regroupement des documents, facilitant ainsi la transformation des données non structurées en formats structurés. Cette boîte à outils permet d'optimiser les flux de données dans les applications LLM (Large Language Model).
L'intégration d'Unstructured avec une base de données vectorielle telle que [Milvus] (https://zilliz.com/what-is-milvus) crée une solution puissante et évolutive pour la gestion et l'exploitation des données non structurées dans les applications d'intelligence artificielle. La plateforme Unstructured ingère, traite et transforme les données non structurées provenant de divers types de fichiers en [vector embeddings] (https://zilliz.com/glossary/vector-embeddings) prêts pour l'IA. Ces encastrements sont essentiels pour les flux de travail d'IA avancés, mais le stockage, l'indexation et l'interrogation efficaces nécessitent une [base de données vectorielles spécialisée] (https://zilliz.com/blog/what-is-a-real-vector-database). La synergie entre Unstructured et Milvus (ou Zilliz Cloud) permet de rationaliser le pipeline de bout en bout, ce qui est particulièrement utile pour la génération assistée par récupération (RAG) et d'autres applications pilotées par l'IA telles que les chatbots intelligents et les systèmes de recommandation personnalisés.
 Non structuré
Non structuré
Langfuse : Meilleure observabilité et analyse pour les applications LLM
Langfuse est une plateforme d'ingénierie LLM open-source qui aide les équipes à déboguer, analyser et itérer leurs applications LLM en collaboration. Elle offre des fonctionnalités telles que l'observabilité, la gestion des demandes, les évaluations et les mesures, toutes intégrées de manière native pour accélérer le flux de travail de développement.
Principales capacités
Observabilité de bout en bout** : Suivi des interactions LLM, y compris les invites, les réponses et les mesures de performance, afin de garantir la transparence et la fiabilité.
Gestion des messages-guides** : Offre des outils permettant de modifier, d'optimiser et de tester les messages-guides, afin de rationaliser le développement d'applications d'IA robustes.
Intégration flexible** : Fonctionne de manière transparente avec des frameworks populaires tels que LangChain et LlamaIndex, prenant en charge une large gamme d'architectures LLM.
Débogage en temps réel** : Fournit des informations exploitables sur les erreurs et les goulots d'étranglement, permettant aux développeurs d'itérer rapidement.
L'intégration de Langfuse avec les bases de données vectorielles améliore les flux de travail RAG en permettant d'observer la qualité et la pertinence de l'intégration. Cette intégration permet aux développeurs de surveiller et d'optimiser les performances et la précision de la recherche vectorielle grâce à des analyses détaillées, garantissant que les processus de recherche sont finement réglés et alignés sur les besoins des utilisateurs. Consultez le tutoriel suivant pour commencer.
- [Utilisation de Langfuse pour évaluer la qualité des RAG] (https://milvus.io/docs/integrate_with_langfuse.md)
Conclusion
En ce début d'année 2025, il est clair que les frameworks open-source ne sont plus seulement des compléments utiles, mais qu'ils sont essentiels à la construction d'applications LLM robustes. Des frameworks comme LangChain et LlamaIndex ont transformé la façon dont nous intégrons et interrogeons les données, tandis que vLLM et Haystack établissent de nouvelles références en matière de vitesse et d'évolutivité. Des frameworks émergents comme Langfuse et Letta apportent des forces uniques en matière d'observabilité et de mémoire, ouvrant la voie à des systèmes d'intelligence artificielle plus intelligents et plus réactifs.
Ces frameworks permettent aux développeurs de relever des défis complexes, d'expérimenter des idées audacieuses et de repousser les limites du possible. Avec ces frameworks à portée de main, 2025 est l'année où vous pourrez créer des applications GenAI plus intelligentes, plus rapides et plus percutantes.

Continuer à lire

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.

Balancing Precision and Performance: How Zilliz Cloud's New Parameters Help You Optimize Vector Search
Optimize vector search with Zilliz Cloud’s level and recall features to tune accuracy, balance performance, and power AI applications.