




10 marcos LLM de código abierto que los desarrolladores no pueden ignorar en 2025
2024 fue un año excepcional para los grandes modelos lingüísticos (LLM), y a medida que nos adentramos en 2025, el impulso no muestra signos de desaceleración. Desde GPT-4 y las [capacidades multimodales] de Gemini (https://zilliz.com/glossary/multimodal-ai) hasta los sistemas de IA adaptativa en tiempo real, los LLM ya no son sólo vanguardia: son esenciales. Están impulsando chatbots, motores de búsqueda, herramientas de creación de contenidos e incluso automatizando flujos de trabajo que antes pensábamos que solo podían manejar los humanos.
Pero la cuestión es la siguiente: tener un LLM potente es solo la mitad de la batalla. Construir aplicaciones LLM escalables, eficientes y listas para la producción puede ser todo un reto, y ahí es donde entran en juego los frameworks LLM. Simplifican los flujos de trabajo, mejoran el rendimiento y se integran a la perfección con los sistemas existentes, ayudando a los desarrolladores a liberar todo el potencial de estos modelos con menos esfuerzo.
En este artículo, destacaremos 10 marcos LLM de código abierto que los desarrolladores de IA no pueden ignorar de cara a 2025. Estos marcos son las armas secretas que ayudan a los desarrolladores a escalar, optimizar e innovar más rápido que nunca. Si estás listo para mejorar tus proyectos de IA, ¡vamos a ello!
LangChain: Flujos de trabajo de IA multipaso conscientes del contexto
LangChain** es un marco de código abierto diseñado para agilizar el desarrollo de aplicaciones basadas en grandes modelos lingüísticos (LLM). Simplifica la creación de flujos de trabajo que combinan LLM con fuentes de datos externas, API o lógica computacional, lo que permite a los desarrolladores crear sistemas dinámicos y conscientes del contexto para tareas como agentes conversacionales, análisis de documentos y resumen.
Capacidades clave
Pipelines componibles**: LangChain facilita el encadenamiento de múltiples llamadas LLM y funciones externas, permitiendo flujos de trabajo complejos de múltiples pasos.
Cadenas estándar**: LangChain ofrece cadenas preconfiguradas, conjuntos organizados de componentes diseñados para realizar tareas específicas de alto nivel. Estas cadenas listas para usar simplifican el inicio de los proyectos.
Utilidades de ingeniería de proyectos**: Incluye herramientas para crear, gestionar y optimizar instrucciones adaptadas a tareas específicas.
Gestión de la memoria**: Ofrece funciones integradas para conservar el contexto conversacional a lo largo de las interacciones, lo que permite aplicaciones más personalizadas.
LangChain se ha conectado con API de terceros, bases de datos vectoriales, LLM y diversas fuentes de datos. En particular, la integración de LangChain con bases de datos vectoriales como Milvus y Zilliz Cloud aumenta aún más su potencial. Milvus es una base de datos vectorial de código abierto y alto rendimiento para gestionar y consultar vectores de incrustación a escala de miles de millones. Complementa las capacidades de LangChain al permitir una recuperación rápida y precisa de los datos relevantes. Los desarrolladores pueden aprovechar esta integración para crear sistemas escalables Retrieval-Augmented Generation (RAG) en los que Milvus recupere documentos contextualmente relevantes. LangChain utiliza un modelo generativo para producir resultados precisos y perspicaces. Para más información, consulte los siguientes recursos:
Unlocking Language Power: Introducción a LangChain](https://zilliz.com/learn/LangChain)
Zilliz Cloud Integrations with LangChain for advanced RAG](https://zilliz.com/product/integrations/langchain)
Construir RAG con LangChainJS, Milvus y Strapi ](https://zilliz.com/blog/build-rag-with-langchain-milvus-and-strapi)
Cómo construir un RAG multilingüe con Milvus, LangChain y OpenAI](https://zilliz.com/blog/building-multilingual-rag-milvus-langchain-openai)
Retrieval Augmented Generation on Notion Docs via LangChain ](https://zilliz.com/blog/retrieval-augmented-generation-on-notion-docs-via-langchain)
LlamaIndex: Conectando LLMs a Diversas Fuentes de Datos
LlamaIndex** es un marco de trabajo de código abierto que permite a los grandes modelos lingüísticos (LLM) acceder a diversas fuentes de datos y sacarles el máximo partido. Simplifica la ingestión, estructuración y consulta de datos no estructurados, lo que facilita la creación de aplicaciones avanzadas de IA como la recuperación de documentos, el resumen y los chatbots basados en el conocimiento.
Capacidades clave
Conectores de datos**: Proporciona un sólido conjunto de conectores para la ingesta de datos estructurados y no estructurados procedentes de diversas fuentes, como PDF, bases de datos SQL, API y almacenes vectoriales.
Herramientas de indización**: Permite a los desarrolladores crear índices personalizados, incluidas estructuras de árbol, lista y basadas en gráficos, para optimizar la consulta y recuperación de datos.
Optimización de consultas**: Ofrece mecanismos avanzados de consulta que permiten obtener respuestas precisas y contextualmente relevantes.
Extensibilidad**: Altamente modular, lo que facilita la integración con bibliotecas y herramientas externas para mejorar la funcionalidad.
Marco optimizado para LLM**: Diseñado para trabajar con LLMs, asegurando un uso eficiente de los recursos computacionales para tareas a gran escala.
LlamaIndex se ha integrado con varias bases de datos vectoriales creadas específicamente, como Milvus y Zilliz Cloud, para soportar flujos de trabajo RAG escalables y eficientes. En esta configuración, Milvus actúa como backend de alto rendimiento para almacenar y consultar vectores de incrustación, mientras que LlamaIndex estructura y organiza los datos recuperados para que los procesen los LLM. Esta combinación permite a los desarrolladores recuperar los datos más relevantes y a los LLM ofrecer resultados más precisos y contextualizados. Para más información, consulte los siguientes recursos:
Documentación de control de calidad con Zilliz Cloud y LlamaIndex](https://zilliz.com/learn/milvus-notebooks)
Vídeo** | Almacenamiento vectorial persistente con LlamaIndex](https://www.youtube.com/watch?v=S4GmdrlqVKc)
Vídeo con Jerry Liu, CEO de LlamaIndex: Mejore su LLM con datos privados utilizando LlamaIndex](https://zilliz.com/event/boost-your-llm-with-private-data-using-llamaindex)
Haystack: Racionalización de las canalizaciones RAG para aplicaciones de IA listas para la producción
Haystack es un framework Python de código abierto diseñado para facilitar el desarrollo de aplicaciones basadas en LLM. Permite a los desarrolladores crear soluciones de IA de extremo a extremo integrando LLMs con varias fuentes de datos y componentes, haciéndolo adecuado para tareas como RAG, búsqueda de documentos, respuesta a preguntas y generación de respuestas.
Capacidades clave
Tuberías flexibles**: Haystack permite la creación de pipelines modulares para tareas como la recuperación de documentos, la respuesta a preguntas y el resumen. Los desarrolladores pueden combinar distintos componentes para adaptar los flujos de trabajo a sus necesidades específicas.
Arquitectura recuperador-lector**: Combina recuperadores para un filtrado eficaz de documentos con lectores (por ejemplo, LLM) para generar respuestas precisas y contextualizadas.
Agnóstico de backend**: Compatible con múltiples bases de datos vectoriales, incluidas Milvus y FAISS, lo que garantiza la flexibilidad de su implantación.
Integración con MLL**: Proporciona una integración perfecta con modelos lingüísticos, lo que permite a los desarrolladores aprovechar modelos preentrenados y ajustados para diversas tareas.
Escalabilidad y rendimiento**: Optimizado para manejar conjuntos de datos a gran escala y consultas de alto rendimiento, adecuado para aplicaciones empresariales.
En marzo de 2024, Haystack lanzó Haystack 2.0, introduciendo una arquitectura más flexible y personalizable. Esta actualización permite crear pipelines complejos con funciones como bifurcaciones y bucles paralelos, y mejora la compatibilidad con LLM y el comportamiento agéntico. El nuevo diseño hace hincapié en una interfaz común para el almacenamiento de datos, proporcionando integraciones con varias bases de datos y almacenes de vectores, incluyendo Milvus y Zilliz Cloud. Esta flexibilidad garantiza que se pueda acceder fácilmente a los datos y gestionarlos dentro de los pipelines de Haystack, apoyando el desarrollo de aplicaciones de IA escalables y de alto rendimiento. Para obtener más información, consulte los siguientes recursos:
Haystack GitHub: https://github.com/deepset-ai/haystack
Integración**: Haystack y Milvus
Tutorial:** Retrieval-Augmented Generation (RAG) with Milvus and Haystack
Tutorial:** Creación de un canal RAG con Milvus y Haystack 2.0
Dify: Simplificando el Desarrollo de Aplicaciones con LLM
Dify** es una plataforma de código abierto para crear aplicaciones de IA. Combina Backend-as-a-Service con LLMOps, soportando los principales modelos de lenguaje y ofreciendo una interfaz de orquestación intuitiva. Dify proporciona motores RAG de alta calidad, un marco de agentes de IA flexible y un flujo de trabajo intuitivo de bajo código, lo que permite tanto a desarrolladores como a usuarios no técnicos crear soluciones de IA innovadoras.
Capacidades clave
Backend-as-a-Service para LLMs**: Gestiona la infraestructura de backend, lo que permite a los desarrolladores centrarse en crear aplicaciones en lugar de gestionar servidores.
Orquestación de avisos**: Simplifica la creación, comprobación y gestión de mensajes adaptados a tareas específicas.
Análisis en tiempo real**: Proporciona información sobre el rendimiento de los modelos, las interacciones de los usuarios y el comportamiento de las aplicaciones para optimizar los flujos de trabajo.
Amplias opciones de integración**: Se conecta con API de terceros, herramientas externas y LLM populares, ofreciendo flexibilidad para flujos de trabajo personalizados.
Dify se integra bien con bases de datos vectoriales como Milvus, mejorando su capacidad para manejar tareas complejas de recuperación de datos a gran escala. Al emparejar Dify con Milvus, los desarrolladores pueden crear sistemas que almacenan, recuperan y procesan eficazmente incrustaciones para tareas como RAG.
Tutorial: Despliegue de Dify con Milvus
Documentación de Dify](https://docs.dify.ai/)
Letta (Anteriormente MemGPT): Construyendo Agentes RAG con Ventana de Contexto LLM Extendida
Letta es un framework de código abierto diseñado para mejorar los LLM dotándolos de memoria a largo plazo. A diferencia de los LLM tradicionales, que procesan las entradas de forma estática, Letta permite que el modelo recuerde y haga referencia a interacciones pasadas, permitiendo aplicaciones más dinámicas, contextualmente conscientes y personalizadas. Integra técnicas de gestión de memoria para almacenar, recuperar y actualizar información a lo largo del tiempo, lo que lo hace ideal para crear agentes inteligentes y sistemas conversacionales que evolucionan con las interacciones del usuario.
Figura - Funcionamiento de Letta con varias herramientas de IA](https://assets.zilliz.com/Figure_How_Letta_works_with_various_AI_tools_05d96d2548.png)
Capacidades clave
Memoria de auto-edición:** Letta introduce la memoria de auto-edición, permitiendo a los agentes actualizar de forma autónoma su base de conocimientos, aprender de las interacciones y adaptarse con el tiempo.
Entorno de Desarrollo de Agentes (ADE):** Proporciona una interfaz gráfica para crear, desplegar, interactuar y observar agentes de IA, agilizando el proceso de desarrollo y depuración.
Persistencia y gestión del estado:** Garantiza que los agentes mantengan la continuidad entre sesiones mediante la persistencia de su estado, incluidos los recuerdos y las interacciones, lo que permite respuestas más coherentes y contextualmente relevantes.
Integración de herramientas: Admite la incorporación de herramientas y fuentes de datos personalizadas, lo que permite a los agentes realizar una amplia gama de tareas y acceder a información externa según sea necesario.
Arquitectura agnóstica de modelos:** Diseñada para trabajar con varios LLM y sistemas RAG, proporcionando flexibilidad en la elección e integración de diferentes proveedores de modelos.
Letta se ha integrado con las principales bases de datos vectoriales para mejorar sus capacidades de memoria y recuperación para flujos de trabajo RAG avanzados. Al aprovechar el almacenamiento vectorial escalable y la búsqueda eficiente de similitudes, Letta permite a los agentes de IA acceder y retener el conocimiento contextual a largo plazo, garantizando una recuperación de datos rápida y precisa. Esta integración permite a los desarrolladores crear aplicaciones más inteligentes, conscientes del contexto y adaptadas a dominios específicos, como la atención al cliente o las recomendaciones personalizadas, manteniendo al mismo tiempo una memoria persistente y escalable. Consulte los siguientes recursos para obtener más información.
- Tutorial | Integración de MemGPT con Milvus
Vanna: Permitir la generación de SQL con IA
Vanna es un marco Python de código abierto diseñado para simplificar la generación de consultas SQL a través de entradas de lenguaje natural. Aprovechando las técnicas RAG, Vanna permite a los usuarios entrenar modelos en sus datos específicos, lo que les permite plantear preguntas y recibir consultas SQL precisas adaptadas a sus bases de datos. Este enfoque agiliza el proceso de interacción con las bases de datos, haciéndolo más accesible a los usuarios sin grandes conocimientos de SQL.
Vanna](https://assets.zilliz.com/Vanna_7fe4f049f3.png)
Capacidades Clave
Conversión de lenguaje natural a SQL**: Vanna permite a los usuarios introducir preguntas en lenguaje natural, que luego convierte en consultas SQL precisas ejecutables en la base de datos conectada.
Soporte para múltiples bases de datos**: El marco ofrece soporte listo para usar para varias bases de datos, incluyendo Snowflake, BigQuery, Postgres y más. También permite una fácil integración con cualquier base de datos a través de conectores personalizados.
Flexibilidad de la interfaz de usuario**: Vanna ofrece múltiples opciones de interfaz de usuario, como Jupyter Notebooks, Slackbot, aplicaciones web y aplicaciones Streamlit, lo que permite a los usuarios elegir el front-end que mejor se adapte a su flujo de trabajo.
Vanna y las bases de datos vectoriales son una gran combinación para crear sistemas RAG eficaces. Cuando un usuario introduce una consulta en lenguaje natural, Vanna utiliza una base de datos vectorial para recuperar datos relevantes basados en incrustaciones vectoriales almacenadas previamente. A continuación, estos datos se utilizan para ayudar a Vanna a generar una consulta SQL precisa, lo que facilita la recuperación de datos estructurados de una base de datos relacional. Al combinar la potencia de la búsqueda vectorial con la generación de SQL, Vanna simplifica el trabajo con datos no estructurados y permite a los usuarios interactuar con conjuntos de datos complejos sin necesidad de conocimientos avanzados de SQL. Si desea más información, consulte los recursos siguientes:
Tutorial: Escribir SQL con Vanna y Milvus
Milvus + Vanna: Generación de SQL con IA](https://zilliz.com/product/integrations/vanna-ai)
Kotaemon: Building AI-Powered Document QA
Kotaemon es una interfaz de usuario RAG de código abierto y personalizable para conversar con sus documentos. Proporciona una interfaz web de control de calidad de documentos limpia y multiusuario que admite modelos lingüísticos locales y basados en API. kotaemon ofrece una canalización RAG híbrida con capacidades de recuperación de texto completo y vectores, lo que permite un control de calidad multimodal para documentos con figuras y tablas.
Diseñado tanto para usuarios finales como para desarrolladores, kotaemon admite métodos de razonamiento complejos como ReAct y ReWOO. Ofrece citas avanzadas con vistas previas de documentos, ajustes configurables para la recuperación y generación, y un marco extensible para construir canalizaciones RAG personalizadas.
Kotaemon](https://assets.zilliz.com/Kotaemon_ab03ea10e7.png)
Capacidades Clave
Fácil despliegue**: Kotaemon ofrece interfaces sencillas para desplegar LLMs en producción con una configuración mínima, permitiendo un rápido escalado e integración.
Pipelines personalizables**: Permite a los desarrolladores personalizar fácilmente los flujos de trabajo de IA, combinando LLMs con APIs externas, bases de datos y otras herramientas.
Peticiones avanzadas**: Cuenta con herramientas integradas para la ingeniería y optimización de pronósticos, lo que facilita el ajuste fino de los resultados del modelo para tareas específicas.
Optimización del rendimiento**: Diseñado para operaciones de alto rendimiento, Kotaemon garantiza respuestas de baja latencia y un uso eficiente de los recursos.
Soporte multi-modelo**: El framework soporta varias arquitecturas LLM, dando a los desarrolladores la flexibilidad de elegir el mejor modelo para su caso de uso específico.
Kotaemon se integra con bases de datos vectoriales como Milvus, permitiendo la rápida recuperación de datos relevantes para tareas como Retrieval-Augmented Generation (RAG). Al aprovechar las eficientes capacidades de búsqueda vectorial de Milvus, Kotaemon puede mejorar el contexto y la relevancia de los resultados generados por la IA. Esta integración permite a los desarrolladores crear sistemas de IA que generan contenido y recuperan información relevante de grandes conjuntos de datos, mejorando el rendimiento y la precisión generales.
Kotaemon RAG con Milvus | Documentación](https://milvus.io/docs/kotaemon_with_milvus.md)
Zilliz Cloud + Kotaemon: AI-Powered Document QA](https://zilliz.com/product/integrations/kotaemon)
vLLM: Inferencia LLM de alto rendimiento para aplicaciones de IA en tiempo real
vLLM es una biblioteca de código abierto desarrollada por el SkyLab de UC Berkeley, diseñada para optimizar la inferencia y el servicio LLM. Centrada en el rendimiento y la escalabilidad, vLLM introduce innovaciones como PagedAttention, que multiplica por 24 la velocidad de servicio y reduce a la mitad el uso de memoria de la GPU en comparación con los métodos tradicionales. Esto lo convierte en una solución revolucionaria para los desarrolladores que crean aplicaciones de IA exigentes que requieren un uso eficiente de los recursos de hardware.
Funciones clave:
Tecnología PageAttention:** Mejora la gestión de la memoria al permitir el almacenamiento no contiguo de claves y valores de atención, lo que reduce el desperdicio de memoria y mejora el rendimiento hasta 24 veces.
Agrupa las peticiones entrantes en tiempo real, maximizando la utilización de la GPU y minimizando el tiempo de inactividad, lo que se traduce en un mayor rendimiento y una menor latencia.
Salidas en streaming:** Proporciona generación de tokens en tiempo real, lo que permite a las aplicaciones entregar resultados parciales inmediatamente, lo que resulta ideal para interacciones de usuario en tiempo real, como los chatbots.
Amplia compatibilidad de modelos:** Admite arquitecturas LLM populares como GPT y LLaMA, lo que garantiza la flexibilidad para muchos casos de uso y una integración perfecta con los flujos de trabajo existentes.
Servidor API compatible con OpenAI:** Ofrece una interfaz API que refleja la de OpenAI, lo que simplifica el despliegue y la integración en los sistemas existentes para los desarrolladores familiarizados con las API de OpenAI.
vLLM se convierte en la piedra angular de la creación de sistemas RAG de alto rendimiento cuando se combina con bases de datos vectoriales como Milvus. Las bases de datos vectoriales almacenan y recuperan de forma eficiente incrustaciones de alta dimensión, críticas para recuperar información contextualmente relevante. vLLM complementa esto ofreciendo una inferencia LLM optimizada, asegurando que la información recuperada se procesa sin problemas en respuestas precisas y conscientes del contexto. Esta integración mejora el rendimiento de las aplicaciones y resuelve problemas como las alucinaciones de la IA, ya que los resultados se basan en los datos recuperados. Si desea más información, consulte los siguientes recursos.
Despliegue de un sistema RAG multimodal con vLLM y Milvus](https://zilliz.com/blog/deploy-multimodal-rag-using-vllm-and-milvus)
Creación de aplicaciones RAG con Milvus, Qwen y vLLM](https://zilliz.com/blog/build-rag-app-with-milvus-qwen-and-vllm)
Gestión eficiente de la memoria para grandes servicios de modelos lingüísticos con PagedAttention](https://zilliz.com/learn/efficient-memory-management-for-llm-serving-pagedattention)
Creación de RAG con Milvus, vLLM y Meta's Llama 3.1](https://zilliz.com/blog/building-rag-milvus-vllm-llama-3-1)
Unstructured: Cómo hacer que los datos no estructurados sean accesibles para GenAI
Unstructured es una biblioteca de código abierto que agiliza la ingesta y el preprocesamiento de datos no estructurados de diversos formatos, como PDF, HTML, documentos de Word e imágenes. Ofrece funciones modulares para particionar, limpiar, extraer, organizar y agrupar documentos, facilitando la transformación de datos no estructurados en formatos estructurados. Este conjunto de herramientas es beneficioso para optimizar los flujos de trabajo de datos en aplicaciones de Large Language Model (LLM).
La integración de Unstructured con una base de datos vectorial como Milvus crea una solución potente y escalable para gestionar y aprovechar los datos no estructurados en aplicaciones de IA. La plataforma Unstructured ingiere, procesa y transforma datos no estructurados procedentes de diversos tipos de archivos en [incrustaciones vectoriales] listas para la IA (https://zilliz.com/glossary/vector-embeddings). Estas incrustaciones son cruciales para los flujos de trabajo avanzados de IA, pero almacenarlas, indexarlas y consultarlas de forma eficaz requiere una base de datos vectorial especializada. La sinergia entre Unstructured y Milvus (o Zilliz Cloud) permite agilizar el proceso de principio a fin, lo que resulta especialmente valioso para la Generación de Recuperación-Aumentada (RAG) y otras aplicaciones basadas en IA, como los chatbots inteligentes y los sistemas de recomendación personalizados.
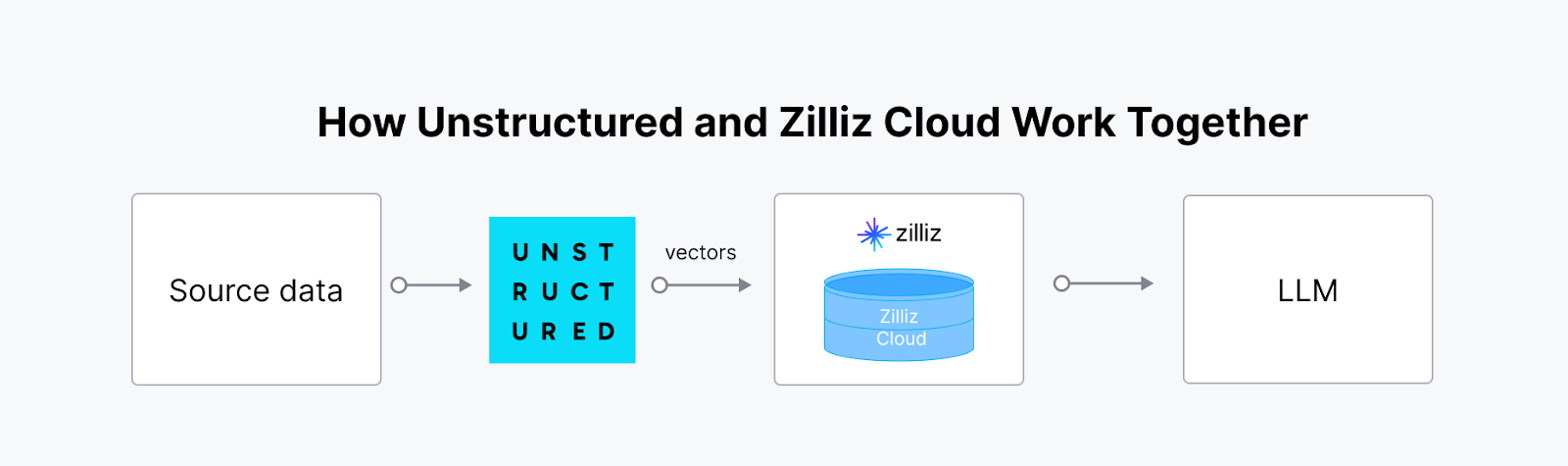 No estructurado
No estructurado
Tutorial | Construir una RAG con Milvus y Unstructured
Blog | Vectorizar y consultar contenido EPUB con Unstructured y Milvus
Langfuse: Mejor capacidad de observación y análisis para aplicaciones LLM
Langfuse es una plataforma de ingeniería LLM de código abierto que ayuda a los equipos a depurar, analizar e iterar de forma colaborativa sus aplicaciones LLM. Ofrece características tales como observabilidad, gestión de solicitudes, evaluaciones y métricas, todas ellas integradas de forma nativa para acelerar el flujo de trabajo de desarrollo.
Capacidades clave
Observabilidad de extremo a extremo**: Realiza un seguimiento de las interacciones de LLM, incluidos los avisos, las respuestas y las métricas de rendimiento, para garantizar la transparencia y la fiabilidad.
Gestión de mensajes**: Ofrece herramientas para versionar, optimizar y probar las instrucciones, agilizando el desarrollo de aplicaciones de IA robustas.
Integración flexible**: Funciona sin problemas con marcos populares como LangChain y LlamaIndex, soportando una amplia gama de arquitecturas LLM.
Depuración en tiempo real**: Proporciona información procesable sobre errores y cuellos de botella, permitiendo a los desarrolladores iterar rápidamente.
La integración de Langfuse con las bases de datos vectoriales mejora los flujos de trabajo de RAG, ya que permite observar la calidad y la relevancia de la incrustación. Esta integración permite a los desarrolladores supervisar y optimizar el rendimiento y la precisión de la búsqueda vectorial a través de análisis detallados, garantizando que los procesos de recuperación se ajustan con precisión y se alinean con las necesidades del usuario. Consulte el siguiente tutorial para empezar.
- Uso de Langfuse para evaluar la calidad de la GAR](https://milvus.io/docs/integrate_with_langfuse.md)
Conclusión
A principios de 2025, está claro que los frameworks de código abierto ya no son sólo complementos útiles, sino que son fundamentales para crear aplicaciones LLM sólidas. Frameworks como LangChain y LlamaIndex han transformado nuestra forma de integrar y consultar datos, mientras que vLLM y Haystack están estableciendo nuevos puntos de referencia en cuanto a velocidad y escalabilidad. Frameworks emergentes como Langfuse y Letta aportan puntos fuertes únicos en observabilidad y memoria, abriendo las puertas a sistemas de IA más inteligentes y con mayor capacidad de respuesta.
Estos marcos permiten a los desarrolladores afrontar retos complejos, experimentar con ideas audaces y superar los límites de lo posible. Con estos frameworks a su alcance, 2025 será su año para crear aplicaciones de GenAI más inteligentes, rápidas e impactantes.

Sigue leyendo

Zilliz Skills Breakdown: How AI Agents Master Vector Databases
Zilliz's Milvus Skill (pymilvus, 7 files) and Zilliz Cloud Skill (zilliz-cli, 14 modules) bring vector-DB dev and ops into one Claude Code session.

Migrating from S3 Vectors to Zilliz Cloud: Unlocking the Power of Tiered Storage
Learn how Zilliz Cloud bridges cost and performance with tiered storage and enterprise-grade features, and how to migrate data from AWS S3 Vectors to Zilliz Cloud.

Zilliz Cloud BYOC Upgrades: Bring Enterprise-Grade Security, Networking Isolation, and More
Discover how Zilliz Cloud BYOC brings enterprise-grade security, networking isolation, and infrastructure automation to vector database deployments in AWS