




Was ist eine NoSQL-Datenbank? Ein Leitfaden zur modernen Datenspeicherung

Was ist eine NoSQL-Datenbank? Ein Leitfaden zur modernen Datenspeicherung
Was ist eine NoSQL-Datenbank?
Eine NoSQL-Datenbank (nicht nur SQL) bietet eine flexible, schemafreie Datenspeicherung, die für die Verarbeitung unstrukturierter oder halbstrukturierter Daten wie JSON, Dokumente oder Diagramme konzipiert ist. Im Gegensatz zu herkömmlichen relationalen Datenbanken (SQL), die strukturierte Tabellen und vordefinierte Schemata verwenden, sind NoSQL-Datenbanken auf Skalierbarkeit, Leistung und Flexibilität in modernen Anwendungen ausgelegt. Sie unterstützen verschiedene Datenmodelle, darunter Schlüssel-Wert-, Dokument-, Spalten- und Diagrammformate. NoSQL-Datenbanken werden häufig in Szenarien wie Echtzeitanalysen, Content Management und IoT eingesetzt und können große Datenmengen über verteilte Systeme hinweg verarbeiten. Beliebte Beispiele sind MongoDB, Cassandra, Redis und DynamoDB.
Der Aufstieg von NoSQL-Datenbanken
NoSQL-Datenbanken wurden wichtig, weil sie Probleme lösten, die herkömmliche SQL-Datenbanken nicht bewältigen konnten. Herkömmliche Datenbanken verwenden feste Strukturen, wie Tabellen mit Zeilen und Spalten, die für organisierte Daten gut funktionieren. Heutzutage arbeiten jedoch viele Anwendungen mit [unstrukturierten] (https://zilliz.com/learn/introduction-to-unstructured-data) oder halbstrukturierten Daten, wie z. B. Beiträge in sozialen Medien und Sensordaten von IoT-Geräten. Diese Daten lassen sich nicht sauber in Tabellen einordnen, wodurch herkömmliche Datenbanken weniger effektiv sind.
Ein großes Problem für herkömmliche Datenbanken ist die Skalierbarkeit. Wenn die Daten schnell wachsen, ist es schwieriger und teurer, sie zu skalieren. NoSQL-Datenbanken lösen dieses Problem, indem sie für die horizontale Skalierung konzipiert sind, d. h. sie können Daten problemlos auf viele Server verteilen. Das macht sie perfekt für Anwendungen, die große Datenmengen verarbeiten müssen, ohne dabei langsamer zu werden.
Typen von NoSQL-Datenbanken
Es gibt verschiedene Arten von NoSQL-Datenbanken, die jeweils für die Lösung spezifischer Datenverwaltungsprobleme entwickelt wurden. Im Folgenden werden die vier Haupttypen von NoSQL-Datenbanken vorgestellt und anhand von Beispielen aus der Praxis gezeigt, wie sie funktionieren.
1. Dokument-basierte Datenbanken
Dokumentenbasierte Datenbanken speichern Daten als Dokumente, in der Regel in Formaten wie JSON, BSON oder XML. Jedes Dokument ist in sich abgeschlossen und kann eine eindeutige Struktur haben, was diese Datenbanken flexibel für die Verarbeitung unstrukturierter oder halbstrukturierter Daten macht.
Wie es funktioniert: Jedes Dokument hat Felder und Werte, die Text, Zahlen, Arrays oder sogar verschachtelte Dokumente enthalten können.
Beispiel: MongoDB, Couchbase.
Anwendungsfälle:
E-Commerce-Systeme: Speichern von Produktkatalogen, wobei jedes Dokument ein Produkt mit Feldern wie Name, Preis und Beschreibung darstellt.
Inhaltsverwaltungssysteme: Verwaltung von Artikeln, Blogs oder Multimedia-Inhalten mit unterschiedlichen Attributen.
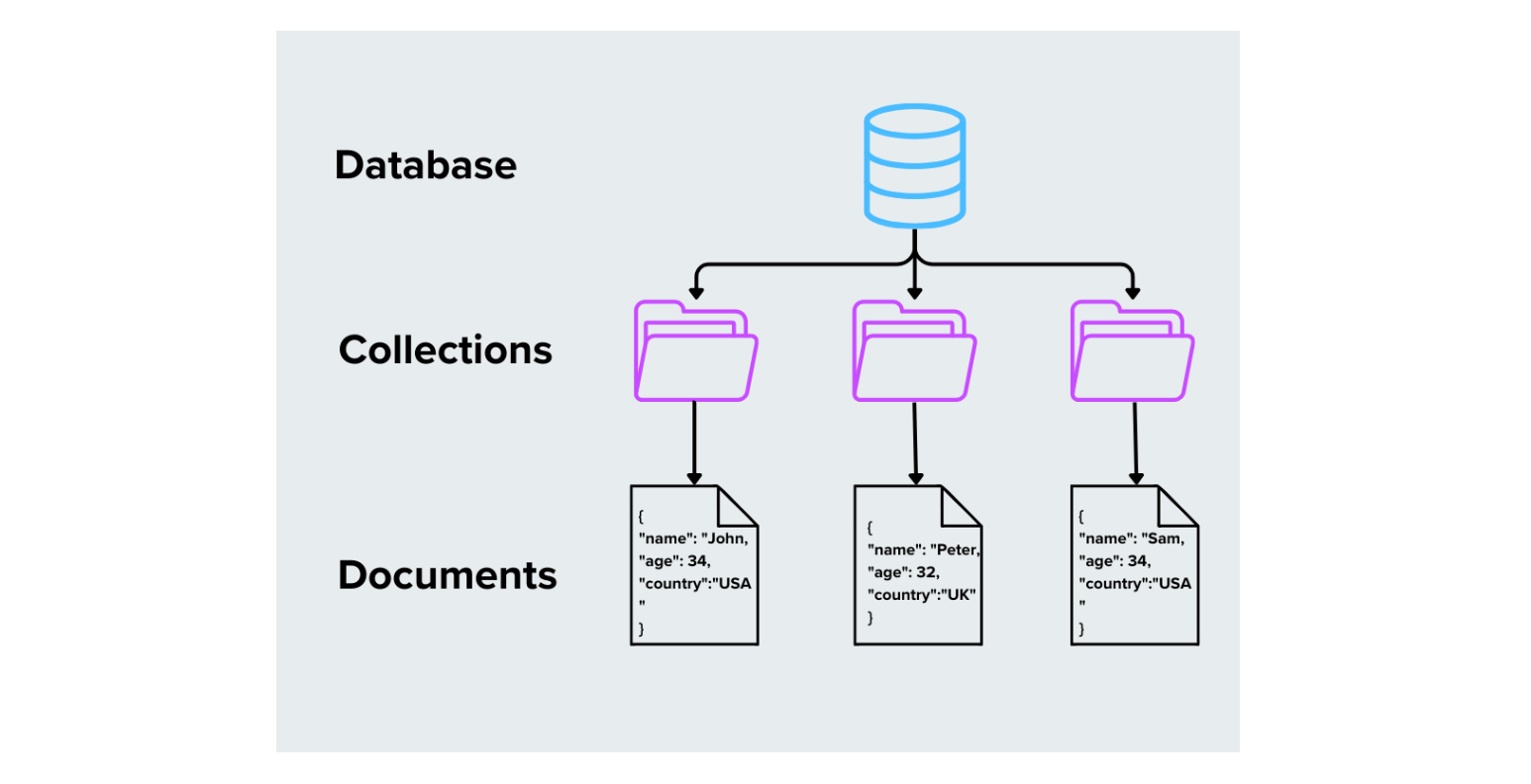 Abbildung- Dokumentenbasierte Datenbanken
Abbildung- Dokumentenbasierte Datenbanken
Abbildung: Dokumentengestützte Datenbanken
2. Key-Value-Speicher
Key-Value-Datenbanken verwenden einen eindeutigen Schlüssel zum Abrufen von Werten, die von einfachem Text bis hin zu komplexen Datenstrukturen reichen können. Dieses Konzept ist äußerst effizient für einen schnellen Datenzugriff.
Wie es funktioniert: Stellen Sie sich das System wie ein Wörterbuch vor - jeder Schlüssel wird direkt einem Wert zugeordnet.
Beispiele sind [Redis] (https://redis.io/), [Amazon DynamoDB] (https://aws.amazon.com/dynamodb/) und [Firebase] (https://firebase.google.com/).
Benutzungsfälle:
Caching: Zwischenspeicherung von Daten für den schnellen Zugriff, z. B. Benutzersitzungen oder kürzlich angesehene Produkte.
Echtzeitanwendungen: Verwaltung von Spiele-Ranglisten oder Chat-Nachrichten, bei denen es auf Geschwindigkeit ankommt.
 Abbildung - Key-Value-Speicher Datenbanken
Abbildung - Key-Value-Speicher Datenbanken
Abbildung: Datenbanken mit Schlüsselwertspeichern
3. Column-Family Stores
Spaltenfamilienspeicher organisieren Daten in Zeilen und Spalten, aber im Gegensatz zu traditionellen Datenbanken können die Spalten in Familien gruppiert werden. Diese Struktur macht sie ideal für das Lesen und Schreiben großer Datensätze.
Wie es funktioniert: Anstatt ein festes Schema zu haben, können Zeilen in einem spaltenbasierten Speicher verschiedene Sätze von Spalten haben, die je nach Relevanz in Familien gruppiert sind.
Beispiel: Apache Cassandra, HBase.
Verwendungsfälle:
Zeitreihen-Daten: Speicherung von Protokollen oder Metriken von Servern und Anwendungen, bei denen kontinuierlich neue Einträge hinzugefügt werden.
Big-Data-Anwendungen: Systeme wie Empfehlungsmaschinen oder Analyseplattformen, die große Mengen an strukturierten Daten verarbeiten.
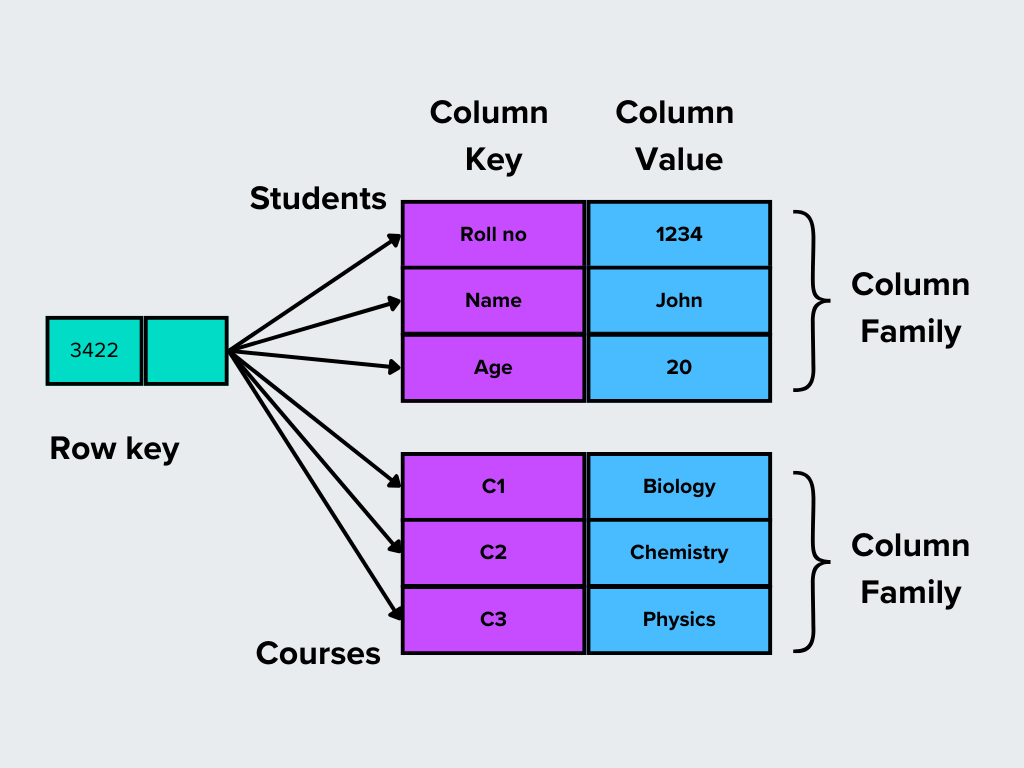 Abbildung - Spaltenbasierte Datenbanken.png
Abbildung - Spaltenbasierte Datenbanken.png
Abbildung: Säulenförmige Datenbanken
4. Graph-Datenbanken
[Graphdatenbanken (https://zilliz.com/learn/vector-database-vs-graph-database) verwenden Knoten zur Darstellung von Entitäten und Kanten zur Darstellung der Verbindungen zwischen ihnen. Dadurch eignen sie sich für Anwendungen, bei denen das Verständnis und die Analyse von Beziehungen im Vordergrund stehen.
Wie es funktioniert: Daten werden als Knoten (Entitäten), Kanten (Beziehungen) und Eigenschaften (Details über Knoten und Kanten) gespeichert.
Beispiel: Neo4j, Amazon Neptune.
Anwendungsfälle:
Soziale Netzwerke: Darstellung von Nutzern als Knoten und deren Verbindungen (Freunde, Follower) als Kanten.
Empfehlungssysteme: Identifizierung verwandter Produkte oder Inhalte auf der Grundlage von Nutzerverhalten und -präferenzen.
Betrugsermittlung: Analyse von Mustern in Finanztransaktionen zur Aufdeckung verdächtiger Beziehungen.
 Abbildung- Graph-databases.png
Abbildung- Graph-databases.png
Abbildung: Graph-Datenbanken
Die folgende Tabelle gibt einen kurzen Einblick in die Arten von NoSQL-Datenbanken sowie deren Funktionsweise, Beispiele und Anwendungsfälle.
| Typ | Arbeitsweise | Beispiele | Schlüsselanwendungsfälle |
|---|---|---|---|
| Dokumentenbasiert | Speichert Daten als flexible Dokumente. | MongoDB, Firebase, Couchbase | E-Commerce, Content Management. |
| Schlüsselwertspeicher | Ordnet Schlüssel zu Werten für schnellen Zugriff. | Redis, DynamoDB | Zwischenspeicherung von Echtzeitdaten wie Spiele oder Sitzungen. |
| Column-Family | Gruppiert Spalten in Familien. | Cassandra, HBase | Zeitreihendaten, Big Data-Analysen. |
| Graph-Datenbanken | Konzentriert sich auf Datenbeziehungen. | Neo4j, Neptune | Soziale Netzwerke, Empfehlungssysteme, Betrug. |
Tabelle: Arten von NoSQL-Datenbanken
Vorteile von NoSQL-Datenbanken
NoSQL-Datenbanken bieten mehrere Vorteile für moderne Anwendungen, die mit umfangreichen, vielfältigen und dynamischen Daten arbeiten. Zum Beispiel:
1. Skalierbarkeit
Eine der größten Stärken von NoSQL-Datenbanken ist ihre Fähigkeit zur horizontalen Skalierung. Das bedeutet, dass Sie weitere Server hinzufügen können, um die Daten und die Arbeitslast zu verteilen, anstatt sich auf einen einzigen Server mit mehr Leistung zu verlassen (vertikale Skalierung). Die horizontale Skalierung ist kostengünstig und gewährleistet, dass das System wachsende Datenmengen und Datenverkehr bewältigen kann. Anwendungen wie soziale Medien, E-Commerce oder IoT generieren riesige Datenmengen, die ohne Verlangsamung gespeichert und verarbeitet werden müssen. NoSQL-Datenbanken sind darauf ausgelegt, diese Last nahtlos auf mehrere Rechner zu verteilen.
- Beispiel: Ein Online-Händler kann Spitzeneinkaufszeiten bewältigen, indem er weitere Server zu seinem NoSQL-Datenbankcluster hinzufügt, anstatt ein Upgrade auf einen einzelnen Server vorzunehmen.
2. Flexibilität bei der Datenmodellierung
NoSQL-Datenbanken speichern Daten auf eine Weise, die den Anforderungen Ihrer Anwendung entspricht. Im Gegensatz zu [relationalen Datenbanken] (https://zilliz.com/blog/relational-databases-vs-vector-databases), die starre Tabellen und vordefinierte Spalten verwenden, können Sie in NoSQL-Datenbanken mit Daten in verschiedenen Formaten arbeiten, z. B. als Dokumente, Schlüssel-Wert-Paare, Diagramme oder Spalten.
Diese Flexibilität ist ideal für Anwendungen, bei denen sich die Datenstrukturen häufig ändern oder verschiedene Datentypen unterstützt werden müssen.
- Beispiel: Ein Content-Management-System kann Artikel, Videos und Benutzerprofile in derselben Datenbank speichern, ohne sie in ein festes Format zu zwingen.
3. Schemaloser Entwurf für dynamische Anwendungen
Herkömmliche Datenbanken erfordern ein vordefiniertes Schema, d. h. Sie müssen vor der Speicherung entscheiden, wie Ihre Daten strukturiert werden sollen. NoSQL-Datenbanken hingegen sind schemaunabhängig, d. h. Sie können Daten speichern, ohne vorher eine Struktur festzulegen. Dies erleichtert die Anpassung an Änderungen in Ihrer Anwendung. Dies ist nützlich für Startups oder sich schnell entwickelnde Anwendungen, deren Anforderungen sich häufig ändern.
- Beispiel: Eine mobile Anwendung, die neue Funktionen wie Zahlungsintegrationen oder Chat-Funktionen hinzufügt, kann problemlos neue Datentypen speichern, ohne dass die Datenbank umgestaltet werden muss.
4. Leistungsvorteile
NoSQL-Datenbanken sind für bestimmte Arten von Arbeitslasten optimiert, z. B. für schnelle Lese- und Schreibvorgänge, die Verarbeitung unstrukturierter Daten und die Echtzeitverarbeitung. Im Gegensatz zu relationalen Datenbanken, die bei starker Belastung langsamer werden können, sind NoSQL-Datenbanken auf eine gleichbleibende Leistung ausgelegt. Anwendungen, die schnelle Reaktionszeiten erfordern, wie Spiele, Finanzhandel oder Echtzeitanalysen, können sich aufgrund ihrer Geschwindigkeit und Effizienz auf NoSQL-Datenbanken verlassen.
- Beispiel: Eine Spieleplattform kann einen Key-Value-Speicher wie Redis verwenden, um die Sitzungsdaten von Millionen gleichzeitiger Spieler mit minimaler Latenz zu verarbeiten.
5. Unterstützung für groß angelegte, verteilte Systeme
NoSQL-Datenbanken sind für verteilte Systeme konzipiert, bei denen die Daten auf mehreren Servern an verschiedenen Standorten gespeichert werden. Dadurch sind sie äußerst zuverlässig und gewährleisten die Datenverfügbarkeit, selbst wenn ein Server ausfällt. Verteilte Systeme verbessern auch die Leistung, indem sie die Latenzzeit durch lokalisierten Datenzugriff verringern.
Bei groß angelegten Anwendungen wie globalen E-Commerce-Plattformen oder Content-Delivery-Netzwerken muss sichergestellt werden, dass die Daten immer zugänglich sind, egal wo sich der Benutzer befindet.
- Beispiel: Ein internationaler Video-Streaming-Dienst kann eine verteilte NoSQL-Datenbank verwenden, um einen schnellen und zuverlässigen Zugriff auf Inhalte für Nutzer in verschiedenen Regionen zu gewährleisten.
Herausforderungen und Grenzen von NoSQL-Datenbanken
Obwohl NoSQL-Datenbanken viele Vorteile bieten, sind sie nicht ohne Herausforderungen und Einschränkungen:
1. Fehlende Standardisierung
NoSQL-Datenbanken folgen keinem universellen Standard wie SQL für relationale Datenbanken. Jedes NoSQL-System hat seine eigene Abfragesprache, APIs und Designprinzipien. Die fehlende Standardisierung kann es erschweren, zwischen NoSQL-Systemen zu wechseln oder sie in andere Tools und Plattformen zu integrieren.
2. Probleme mit der Datenkonsistenz in verteilten Systemen
Viele NoSQL-Datenbanken geben der Verfügbarkeit und der Partitionstoleranz (basierend auf dem CAP-Theorem) Vorrang vor der Konsistenz. Das bedeutet, dass sie vorübergehende Dateninkonsistenzen auf verteilten Servern zulassen können. Anwendungen, die strikte Konsistenz erfordern, wie Finanzsysteme oder kritische Transaktionsplattformen, können mit NoSQL-Datenbanken Schwierigkeiten haben.
3. Lernkurve
Für Entwickler, die an die Arbeit mit relationalen Datenbanken gewöhnt sind, kann das NoSQL-Paradigma ungewohnt sein. Konzepte wie schemafreies Design, eventuelle Konsistenz oder spezifische Datenmodelle können ein Umdenken erfordern. Diese Lernkurve kann die Entwicklung verlangsamen und das Risiko von Designfehlern in NoSQL-basierten Systemen erhöhen.
4. Use-Case-Einschränkungen
NoSQL-Datenbanken sind nicht immer für Anwendungen geeignet, die komplexe, mehrstufige Transaktionen oder eine strenge ACID (Atomicity, Consistency, Isolation, Durability) Einhaltung erfordern. Relationale Datenbanken eignen sich besser für Aufgaben wie die Verwaltung von Lagerbeständen oder die Verarbeitung von Finanztransaktionen, bei denen starke Garantien für die Datenintegrität entscheidend sind.
Hybride Ansätze und Multimodell-Datenbanken
In der sich ständig weiterentwickelnden Welt der Datenverwaltung benötigen Unternehmen oft die Zuverlässigkeit und Struktur von SQL-Datenbanken neben der Flexibilität und Skalierbarkeit von NoSQL. Hybride Ansätze und Multi-Modell-Datenbanken bieten eine Lösung, indem sie die besten Funktionen kombinieren und es Entwicklern ermöglichen, mit verschiedenen Daten und Arbeitslasten zu arbeiten, ohne mehrere Datenbanksysteme zu benötigen.
Eine Multi-Modell-Datenbank ist ein einzelnes Datenbanksystem, das mehrere Arten von Datenmodellen unterstützt. So können beispielsweise relationale Daten in Tabellen gespeichert und gleichzeitig Dokumente, Schlüssel-Wert-Paare oder Diagramme verarbeitet werden - alles in ein und demselben System. Mit Multi-Modell-Datenbanken entfällt die Notwendigkeit, separate Datenbanken für verschiedene Datentypen zu unterhalten, was die Komplexität und den betrieblichen Aufwand reduziert.
Beispiele:
ArangoDB: Unterstützt Dokument-, Graph- und Key-Value-Modelle.
Couchbase**: Kombiniert Dokumenten- und Schlüsselwertspeicher mit SQL-ähnlichen Abfragen.
Oracle-Datenbank**: Bietet Unterstützung für relationale, JSON- und räumliche Daten.
Vector Database: Das Rückgrat der modernen KI-Anwendungen
Während NoSQL-Datenbanken unstrukturierte Daten wie Dokumente und Graphen verarbeiten, gehen Vektordatenbanken einen Schritt weiter und verwalten Daten über hochdimensionale Vektoren. Bei diesen Vektoren handelt es sich um mathematische Darstellungen komplexer unstrukturierter Daten wie Text, Bilder oder Audiodaten, die in der KI und beim maschinellen Lernen häufig verwendet werden. Vektordatenbanken sind speziell dafür ausgelegt, diese Einbettungen zu speichern, zu indizieren und abzufragen und ermöglichen so Aufgaben wie Ähnlichkeitssuche, Bilderkennung und natürliche Sprachverarbeitung (NLP). Im Gegensatz zu herkömmlichen Datenbanken, die auf exakte Übereinstimmungen angewiesen sind, konzentrieren sich Vektordatenbanken auf das Auffinden "ähnlicher" Daten, was sie für KI-gestützte Anwendungen wie Empfehlungsmaschinen, Chatbots und Retrieval Augmented Generation (RAG) entscheidend macht.
Milvus und Zilliz Cloud ****(managed Milvus) sind die wichtigsten Beispiele für moderne Vektordatenbanken. Milvus ist eine Open-Source-Vektordatenbank, die Vektordaten in Milliardenhöhe verarbeiten kann und eine Vielzahl von unternehmenstauglichen Funktionen bietet, wie z. B. Skalierbarkeit, Mandantenfähigkeit, hybride Suche (Volltextsuche, spärliche und dichte Vektorsuche, Vektorsuche mit Metadatenfilterung usw.) und nahtlose Integration in das KI-Ökosystem. Zilliz Cloud bietet einen vollständig verwalteten Service von Milvus, so dass Entwickler die Komplexität der Wartung und Bereitstellung eliminieren und sich auf ihre App-Entwicklung und ihr Geschäft konzentrieren können. Zilliz Cloud bietet außerdem in vielen Situationen eine 10-mal schnellere Leistung.
SQL vs. NoSQL vs. Vektordatenbanken
Die folgende Tabelle zeigt die wichtigsten Unterschiede zwischen SQL-, NoSQL- und Vektordatenbanken:
| Feature | SQL-Datenbanken | NoSQL-Datenbanken | Vektordatenbanken |
|---|---|---|---|
| Datenmodell | Relational (Tabellen mit Zeilen und Spalten). | Nicht-relational (Dokument, Schlüssel-Wert, Graph, etc.). | Vektorbasiert (hochdimensionale Vektoreinbettungen). |
| Schema | Starres, vordefiniertes Schema. | Flexibles, dynamisches Schema. | Schemalos mit Fokus auf Vektoreinbettungen. |
| Abfragesprache | Strukturierte Abfragesprache (SQL). | Variiert je nach System (NoSQL-Abfragesprachen, APIs usw.). | Vektorsuchmethoden (z. B. ANN, Kosinusähnlichkeit). |
| Datentyp-Fokus | Strukturierte Daten. | Semi-strukturierte und unstrukturierte Daten. | Unstrukturierte Daten werden als Vektoren dargestellt. |
| Skalierbarkeit | Vertikale Skalierung (begrenzte horizontale Skalierung). | Horizontale Skalierung (Hinzufügen weiterer Server). | Hochgradig skalierbar mit vertikaler und horizontaler Verteilung. (Hinweis: nicht alle Vektordatenbanken können beides bieten). |
| Anwendungsbeispiele | Transaktionssysteme, Analytik. | Big Data, Echtzeit-Webanwendungen, verteilte Systeme. | KI/ML-Anwendungen, Ähnlichkeitssuche und RAG. |
| Leistung | Optimiert für komplexe Abfragen und Joins. | Optimiert für Geschwindigkeit und Skalierbarkeit. | Optimiert für hochdimensionale Vektor-Ähnlichkeitssuche. |
| Typische Anwendungen | Banken, ERP, CRM-Systeme. | Soziale Netzwerke, IoT, Content Management. | Bildabfrage, Empfehlungsmaschinen, NLP, RAG. |
| Speicherformat | Zeilen und Spalten. | Unterschiedlich (JSON, BSON, etc.). | Hochdimensionale Vektoren. |
Tabelle: SQL vs. NoSQL vs. Vektordatenbank
Wann sollte man SQL-, NoSQL- oder Vektordatenbanken verwenden?
Die Wahl zwischen SQL-, NoSQL- und Vektordatenbanken hängt von den spezifischen Anforderungen Ihrer Anwendung ab, einschließlich der Datenstruktur, der Skalierbarkeit und der Art der Arbeitslast. In den folgenden Punkten wird erläutert, wann sich welcher Typ am besten eignet.
Wann sollte man SQL verwenden?
Anwendungen, die konsistente Daten und komplexe Beziehungen erfordern.
Systeme mit einem festen Schema und vorhersehbarem Datenbedarf.
Beispiele: Banken, ERP-Systeme und traditionelle Geschäftsanwendungen.
Wann sollte man NoSQL verwenden?
Anwendungen, die mit großen, dynamischen oder unstrukturierten Daten arbeiten.
Szenarien, die Hochgeschwindigkeitsoperationen und Skalierbarkeit erfordern.
Beispiele: Soziale Medien, IoT, Echtzeit-Analysen und Big Data-Verarbeitung.
Wann sollte man eine Vektordatenbank verwenden?
Anwendungen, die eine Ähnlichkeitssuche für hochdimensionale Daten wie Bilder, Dokumente oder Audio erfordern.
KI/ML-Workflows mit Vektoreinbettungen für Aufgaben wie NLP, Empfehlungen oder RAG.
Fortgeschrittene Suchsysteme, wie Bilderkennung oder semantische Suche, für unstrukturierte Daten.
Schlussfolgerung
NoSQL-Datenbanken haben die Datenspeicherung und -verwaltung verändert, indem sie Flexibilität, Skalierbarkeit und Geschwindigkeit für unstrukturierte und halbstrukturierte Daten bieten. Sie eignen sich hervorragend zur Bewältigung umfangreicher Arbeitslasten für Anwendungen wie IoT, Echtzeitanalysen und Big Data. Auf der anderen Seite sind Vektordatenbanken wie Milvus für spezielle Anforderungen wie die Verwaltung hochdimensionaler Vektordaten für KI- und maschinelle Lernaufgaben konzipiert. Unternehmen können die richtigen Lösungen nutzen, um robuste, zukunftssichere Systeme aufzubauen, die auf ihre spezifischen Anforderungen zugeschnitten sind, indem sie die unterschiedlichen Rollen von SQL-, NoSQL- und Vektordatenbanken verstehen.
FAQs zu NoSQL-Datenbanken
1. Was ist eine NoSQL-Datenbank?
Eine NoSQL-Datenbank ist eine nicht-relationale Datenbank, die unstrukturierte, halbstrukturierte oder strukturierte Daten verarbeitet. Im Gegensatz zu SQL-Datenbanken bietet sie Flexibilität bei der Datenmodellierung und Skalierbarkeit für moderne Anwendungen.
2. Wie unterscheiden sich NoSQL-Datenbanken von herkömmlichen SQL-Datenbanken?
NoSQL-Datenbanken stützen sich nicht auf feste Schemata oder strukturierte Tabellen. Sie sind für verteilte Systeme konzipiert und eignen sich besser für den Umgang mit großen, dynamischen und vielfältigen Daten.
3. Was ist Milvus, und wie unterscheidet es sich von NoSQL-Datenbanken?
Milvus ist eine spezialisierte Vektordatenbank, die für die Verwaltung hochdimensionaler Daten entwickelt wurde, wie z. B. Vektoren, die in der KI und im maschinellen Lernen verwendet werden. Im Gegensatz zu NoSQL-Datenbanken für allgemeine Zwecke konzentriert sich Milvus speziell auf Aufgaben wie Ähnlichkeitssuche, semantische Suche und die Verwaltung von Vektoreinbettungen für KI-gesteuerte Anwendungen.
4. Was sind die Vorteile von NoSQL-Datenbanken?
Zu den wichtigsten Vorteilen gehören Skalierbarkeit, Flexibilität bei der Datenmodellierung, ein schemafreies Design, hohe Leistung für bestimmte Arbeitslasten und Unterstützung für verteilte Systeme.
5. Wann sollte ich eine NoSQL-Datenbank verwenden?
Verwenden Sie NoSQL, wenn Sie mit großen, unstrukturierten Daten oder Anwendungen zu tun haben, die Skalierbarkeit erfordern, wie z. B. KI-Systeme, IoT-Plattformen, Echtzeit-Analysen oder Big Data-Verarbeitung.
Verwandte Ressourcen
Von Zeilen und Spalten zu Vektoren: Die evolutionäre Reise der Datenbanktechnologien](https://zilliz.com/learn/from-sql-and-nosql-to-vectors-database-evolution-journey)
Zilliz Cloud, die leistungsfähigste Vektordatenbank auf Basis von Milvus®](https://zilliz.com/cloud)
Benchmarking der Leistung von Vektordatenbanken: Techniken und Einblicke](https://zilliz.com/learn/benchmark-vector-database-performance-techniques-and-insights)
Einführung eines Open-Source-Benchmark-Tools für Vektordatenbanken zur Auswahl der idealen Vektordatenbank für Ihr Projekt](https://zilliz.com/learn/open-source-vector-database-benchmarking-your-way)
Verwendung Ihrer Vektordatenbank als JSON (oder relationaler) Datenspeicher](https://zilliz.com/blog/using-your-vector-database-as-JSON-or-relational-datastore)
Vektorisierung von JSON-Daten mit Milvus für die Ähnlichkeitssuche](https://zilliz.com/learn/vectorize-JSON-data-with-milvus-for-similarity-search)
- Was ist eine NoSQL-Datenbank?
- Der Aufstieg von NoSQL-Datenbanken
- Typen von NoSQL-Datenbanken
- Vorteile von NoSQL-Datenbanken
- Herausforderungen und Grenzen von NoSQL-Datenbanken
- Hybride Ansätze und Multimodell-Datenbanken
- Vector Database: Das Rückgrat der modernen KI-Anwendungen
- SQL vs. NoSQL vs. Vektordatenbanken
- Wann sollte man SQL-, NoSQL- oder Vektordatenbanken verwenden?
- Schlussfolgerung
- FAQs zu NoSQL-Datenbanken
- Verwandte Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren