




Skalierbar und verlässlich: Ein einfacher Leitfaden für verteiltes Rechnen
Skalierbar und verlässlich: Ein einfacher Leitfaden für verteiltes Rechnen
Beim verteilten Rechnen werden Aufgaben oder Prozesse auf mehreren verbundenen Computern ausgeführt, um die Leistung, Skalierbarkeit und Zuverlässigkeit zu erhöhen. Anstatt sich auf einen einzigen leistungsstarken Rechner zu verlassen, wird die Arbeitslast auf mehrere Knoten verteilt, die größere Datensätze und Berechnungen effizienter verarbeiten können. Dieser Ansatz bildet das Rückgrat vieler moderner datengesteuerter Anwendungen, darunter E-Commerce-Plattformen, Pipelines für maschinelles Lernen, Echtzeit-Analysen, IoT-Sensornetzwerke und Hochleistungssimulationen für die Forschung.
 Verteiltes Rechnen
Verteiltes Rechnen
Abbildung: Verteiltes Rechnen
Von einzelnen Servern zu verteilten Systemen: Die Entwicklung
Lange Zeit verließen sich viele Unternehmen auf große, zentralisierte Server - oft als monolithische Architekturen bezeichnet - um ihre Anwendungen auszuführen. Dieser Aufbau hatte jedoch einige klare Nachteile:
Beschränkte Skalierbarkeit: Um mehr Kapazität zu schaffen, mussten größere Server gekauft werden, was teuer und zeitaufwändig war.
Ein einziger Fehlerpunkt: Wenn der Hauptserver ausfiel, blieb das gesamte System stehen.
Komplexe Aktualisierungen: Änderungen oder Upgrades waren riskant, da sich alles an einem Ort befand.
Cluster, in denen kleinere Server zusammengefasst sind, brachten zwar eine gewisse Erleichterung, lösten aber die Skalierungs- und Zuverlässigkeitsprobleme noch nicht vollständig. An dieser Stelle kam das verteilte Computing ins Spiel. Durch die Aufteilung von Aufgaben und Daten auf mehrere verbundene Knoten werden verteilte Systeme geschaffen:
schneller und kostengünstiger skalieren: Sie können weitere Knoten hinzufügen, anstatt einen einzelnen großen Server zu ersetzen.
Verbesserung der Fehlertoleranz: Wenn ein Knoten ausfällt, können andere das System am Laufen halten.
Bewältigung hoher Arbeitslasten: Mehrere Knoten arbeiten zusammen und können große Datenmengen effizienter verarbeiten.
Moderne Lösungen wie Milvus von Zilliz bauen auf diesen Prinzipien auf, um große Mengen hochdimensionaler Daten zu verwalten. Milvus unterstützt umfangreiche Ähnlichkeitssuchen, indem es Daten auf mehrere Knoten verteilt und selbst unter anspruchsvollen Bedingungen eine hohe Leistung beibehält.
Wie funktioniert verteiltes Rechnen?
Verteiltes Rechnen ist ein Modell, bei dem mehrere Rechner (oder Knoten) zusammenarbeiten, um Aufgaben zu erledigen, die auf einem einzelnen Rechner nur schwer oder ineffizient zu bewältigen wären. Jeder Knoten in einem verteilten System kann bestimmte Funktionen ausführen, z. B. Daten speichern oder Berechnungen durchführen, und das System koordiniert diese Aufgaben, um als einheitliches Ganzes zu arbeiten. Daher führt dieser Ansatz zu höherer Leistung, besserer [Fehlertoleranz] (https://zilliz.com/ai-faq/how-do-distributed-databases-ensure-fault-tolerance) und flexiblen Skalierungsmöglichkeiten.
Kernprinzipien
Aufgabenverteilung: Der Grundgedanke des verteilten Rechnens besteht darin, große Aufgaben in kleinere Aufgaben aufzuteilen und sie verschiedenen Knoten zuzuweisen. Durch die Aufteilung der Arbeitslast kann jeder Knoten seinen Teil parallel bearbeiten, was die Verarbeitung beschleunigt und verhindert, dass ein einzelner Rechner überlastet wird.
Datenpartitionierung](https://zilliz.com/ai-faq/what-is-data-partitioning-and-why-is-it-important-in-distributed-databases): Die Daten werden in Segmente (oft als "Shards" bezeichnet) aufgeteilt. Jeder Knoten speichert ein oder mehrere dieser Segmente für parallele Lese- und Schreibvorgänge. Dies beschleunigt den Datenzugriff und erleichtert die Skalierung: Wenn die Daten wachsen, fügen Sie weitere Knoten hinzu und partitionieren sie weiter.
Synchronisation und Koordination](https://zilliz.com/ai-faq/how-do-you-synchronize-data-across-systems): Da Aufgaben und Daten über mehrere Knoten verteilt sind, ist es wichtig, dass die Knoten synchron bleiben, um widersprüchliche Aktualisierungen zu vermeiden. Verteilte Systeme verwenden Protokolle und Algorithmen, wie z. B. Konsensmechanismen, um sicherzustellen, dass jeder Knoten eine konsistente Datensicht beibehält. Diese Methoden helfen allen Teilen des Systems, sich auf Änderungen zu einigen, selbst wenn diese gleichzeitig auftreten.
Komponenten von verteilten Systemen
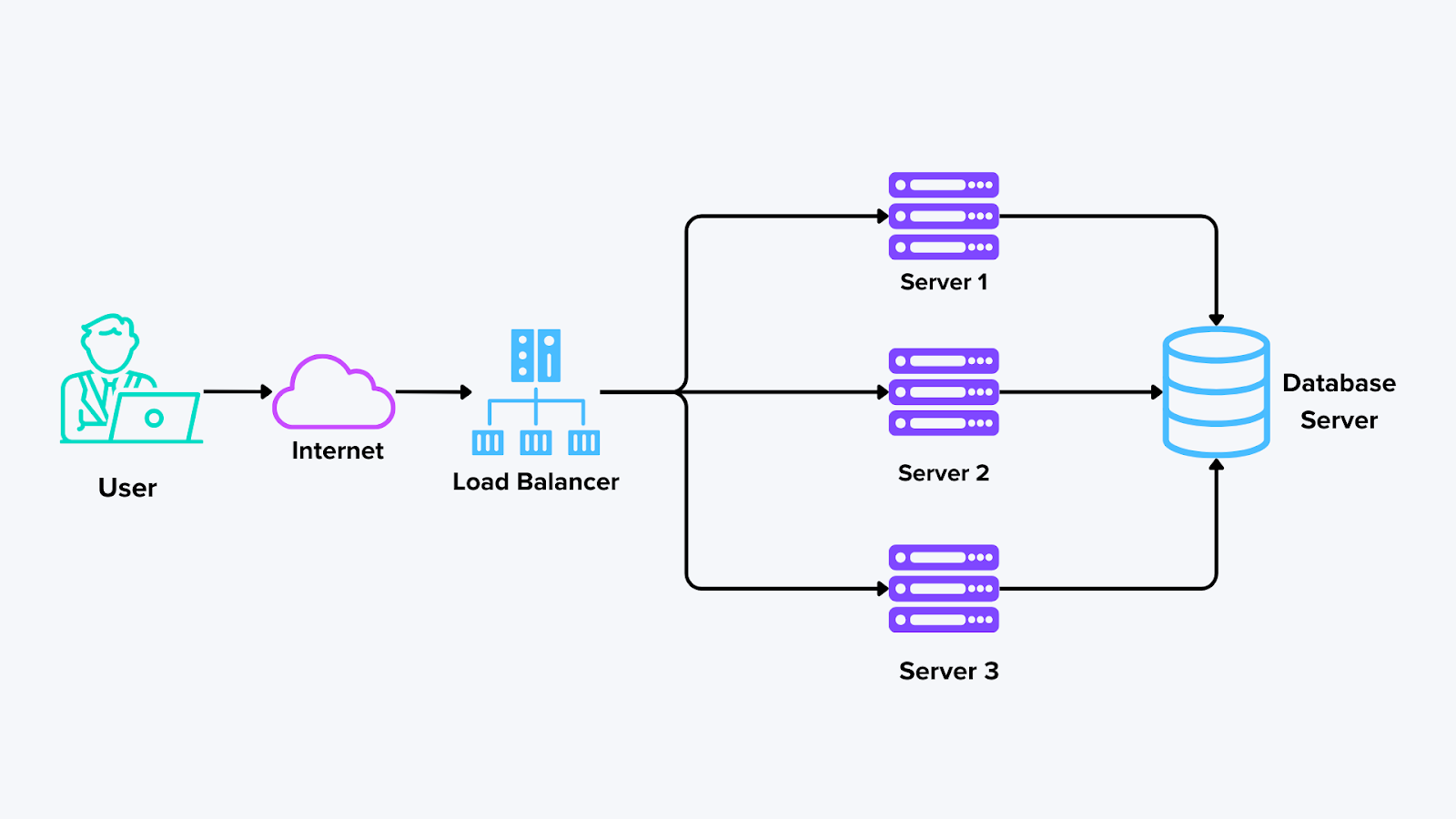 Komponenten verteilter Systeme
Komponenten verteilter Systeme
Abbildung: Komponenten eines verteilten Systems
Knoten (oder Hosts): Jeder Knoten führt Aufgaben aus oder speichert Daten. In vielen Fällen kann es sich bei den Knoten um physische Server, virtuelle Maschinen oder Container handeln. Bei einem System wie Milvus kann jeder Knoten ein Segment des Vektorindexes enthalten, was verteilte Suchvorgänge über große Datensätze ermöglicht, ohne dass ein einzelner Rechner überlastet wird.
Netzwerk: Das Netzwerk ist der Klebstoff, der alle Knoten miteinander verbindet. Es überträgt Daten und Nachrichten zwischen den Rechnern, um Ergebnisse auszutauschen und gegenseitig zu aktualisieren. Zuverlässige und schnelle Netzwerkverbindungen sind für eine nahtlose Kommunikation unerlässlich.
Load Balancer:Wenn mehrere Knoten bereit sind, eingehende Anfragen anzunehmen, verteilen Load Balancer den Datenverkehr gleichmäßig. Dadurch wird verhindert, dass ein Knoten zu viele Anfragen auf einmal bearbeiten kann. Durch die Verteilung der Last kann das System Spitzen im Datenverkehr bewältigen und die Leistung konstant halten.
Datenbank-Server: Ein Datenbankserver ist für die Speicherung, Verwaltung und Abfrage strukturierter oder unstrukturierter Daten über mehrere Knoten hinweg zuständig. In einer verteilten Architektur können Datenbanken geshared (Aufteilung der Daten in kleinere Teile über verschiedene Knoten) oder repliziert (Kopien der Daten über mehrere Knoten zur Fehlertoleranz) werden.
Nachrichtenwarteschlangen und Koordinationsdienste: Verteilte Systeme stützen sich häufig auf Messaging-Tools (wie Apache Kafka oder NATS) oder Koordinationsdienste (wie ZooKeeper), um die Knotenkommunikation zu verwalten. Diese Werkzeuge helfen bei der Planung von Aufgaben, der Verfolgung des Fortschritts und stellen sicher, dass nicht zwei Knoten gleichzeitig dieselbe Arbeit ausführen. Sie kümmern sich auch um systemweite Ankündigungen, z. B. wenn ein Knoten online oder offline geht, damit sich der Rest des Systems anpassen kann.
Arten von Architekturen für verteiltes Rechnen
Verteiltes Rechnen kann viele Formen annehmen, je nachdem, wie die Knoten interagieren und sich die Aufgaben teilen. Im Folgenden finden Sie einige gängige Architekturen und Beispiele dafür, wie sie in verschiedenen Szenarien funktionieren, darunter auch die Milvus-Datenbank. Die Wahl der richtigen verteilten Architektur hängt von der Größe der Arbeitslast, den Latenzanforderungen und den Kostenbeschränkungen ab.
Arten der verteilten Datenverarbeitung (https://assets.zilliz.com/Types_of_Distributed_Computing_524a467d73.png)
Abbildung: Arten des verteilten Rechnens
1. Client-Server-Modell
Beim Client-Server-Modell bearbeiten ein oder mehrere zentrale Server die Anfragen von mehreren Client-Geräten. Jeder Server ist in der Regel leistungsfähiger als ein einzelner Client und beherbergt die Hauptgeschäftslogik oder den Datenspeicher. Die Clients senden Anfragen (z. B. zum Abrufen von Daten oder zur Durchführung von Berechnungen), und die Server antworten mit den angeforderten Informationen oder Ergebnissen.
Profis: Klare Rollentrennung, zentrale Steuerung und vereinfachte Sicherheitsverwaltung.
Nachteil: Kunden können den Zugang zum Dienst verlieren, wenn ein Server ausfällt. Auch die Skalierung kann schwierig sein, wenn die Anfragen die Kapazität des Servers übersteigen.
2. Peer-to-Peer (P2P)-Netze
Bei Peer-to-Peer-Architekturen werden alle Knoten als gleichberechtigt behandelt. Jeder Knoten kann sowohl als Client als auch als Server fungieren und Ressourcen oder Dateien gemeinsam nutzen, ohne auf einen zentralen Server angewiesen zu sein. In dieser Architektur stellen die Knoten eine direkte Verbindung zueinander her. Anstatt Daten von einem einzigen maßgeblichen Server anzufordern, tauschen die Peers untereinander Daten aus.
Pros: Es gibt keinen einzigen Ausfallpunkt, und die Skalierung durch Hinzufügen weiterer Peers kann einfacher sein.
Nachteil: Die Verwaltung der Datenkonsistenz und der Dienstqualität kann in vollständig dezentralisierten Umgebungen schwierig sein.
3. Cluster Computing
Ein cluster ist eine Gruppe von Servern, die so eng zusammenarbeiten, dass sie wie ein einziges System erscheinen. Aufgaben können zur parallelen Verarbeitung auf verschiedene Knoten aufgeteilt werden, was das Cluster-Computing zu einem beliebten Verfahren für Hochleistungs-Workloads macht. Die Server in einem Cluster teilen sich häufig den Speicherplatz, und die Aufgaben werden von einem Planungssystem oder einem Lastausgleichssystem auf sie verteilt. Fällt ein Server aus, können die anderen weiterarbeiten.
Milvus-Architektur](https://zilliz.com/blog/introduction-to-milvus-architecture): Milvus verwendet geclusterte Knoten, um große Mengen von Vektordaten zu verwalten. Durch die Verteilung von Vektorindizes auf mehrere Rechner können Milliarden von hochdimensionalen Vektoren effizient verarbeitet werden. Dieser Clustering-Ansatz erhöht die Leistung und Ausfallsicherheit, insbesondere bei umfangreichen Such- oder Empfehlungsaufgaben.
Profis: Hervorragend geeignet für Parallelverarbeitung und Fehlertoleranz.
Nachteile: Die Verwaltung kann komplex sein und höhere Hardware-Investitionen erfordern.
4. Cloud und Edge Computing
Cloud Computing stellt Ressourcen (wie virtuelle Maschinen, Speicher und Dienste) auf Abruf über das Internet bereit. Beim Edge Computing werden Verarbeitung und Datenspeicherung näher an der Datenquelle (z. B. IoT-Geräte) platziert, um Latenzzeiten zu verringern. Beim Cloud Computing führen Unternehmen Anwendungen auf entfernten Servern aus, die von Cloud-Anbietern verwaltet werden. Die Kapazität ist in der Regel kurzfristig skalierbar. Beim Edge-Computing werden die von den Geräten erzeugten Daten lokal oder in nahe gelegenen Edge-Rechenzentren verarbeitet, so dass nicht mehr alles an eine zentrale Cloud gesendet werden muss.
Profis: Elastische Skalierung, Flexibilität und potenziell niedrigere Betriebskosten. Edge-Setups verbessern auch die Reaktionsfähigkeit bei zeitkritischen Aufgaben.
Nachteil: Erfordert stabile Netzwerkverbindungen (im Falle von Cloud Computing), und Edge-Geräte verfügen möglicherweise über begrenzte Ressourcen.
5. Microservices
Microservices unterteilen eine Anwendung in kleinere, lose gekoppelte Dienste, die über ein Netzwerk kommunizieren. Jeder Dienst übernimmt eine bestimmte Funktion, z. B. die Benutzerauthentifizierung oder die Datenindizierung. Dienste können auf separaten Rechnern oder Containern ausgeführt werden. Sie stellen APIs für die Kommunikation zur Verfügung und können unabhängig skaliert werden, um ihrer spezifischen Arbeitslast zu entsprechen.
Profis: Es vereinfacht Aktualisierungen, da jeder Dienst geändert werden kann, ohne das gesamte System zu beeinflussen. Es ermöglicht auch eine spezialisierte Skalierung, bei der nur die am stärksten genutzten Dienste zusätzliche Knoten erhalten.
Die Nachteile: Die Verwaltung vieler Dienste wird komplexer, während gleichzeitig ein reibungsloser Betrieb gewährleistet wird. Überwachung, Protokollierung und Bereitstellung von Aktualisierungen erfordern eine sorgfältige Planung.
Anwendungsfälle für verteiltes Rechnen
Für verteiltes Rechnen gibt es eine breite Palette an modernen Lösungen. Im Folgenden sind einige der häufigsten Szenarien aufgeführt, in denen Unternehmen von der Aufteilung von Arbeitslasten und Daten auf miteinander verbundene Knoten profitieren:
Big-Data-Analytik und Echtzeitverarbeitung: Unternehmen führen große Datensätze parallel über mehrere Knoten aus, um die Analyse zu beschleunigen. Die Daten fließen unaufhörlich ein, und Aktualisierungen erfolgen fast augenblicklich. Dies ist im Finanz-, Gesundheits- und E-Commerce-Sektor von entscheidender Bedeutung, wo schnelle Erkenntnisse die Grundlage für Entscheidungen bilden.
Maschinelles Lernen und KI-Modelltraining: Komplexe Modelle werden schneller trainiert, wenn die Berechnungen auf vielen Rechnern gleichzeitig laufen. Auf diese Weise können große Merkmalsmengen effizient verarbeitet und die Trainingszeit insgesamt verkürzt werden. Dies ist bei Bilderkennung, NLP und personalisierten Empfehlungen üblich.
Hochfrequentierte Webanwendungen und E-Commerce: Die Anfragen werden auf mehrere Server verteilt, so dass kein einzelner Rechner überlastet wird. Wenn ein Server ausfällt, laufen die anderen weiter, um schwere Ausfallzeiten zu vermeiden. Dank der flexiblen Skalierung sind plötzliche Spitzen wie Urlaubsverkäufe leichter zu bewältigen.
Internet der Dinge (IoT) und Sensornetzwerke: Zahlreiche Sensoren speisen Daten in verteilte Knoten ein, die sie nahe an der Quelle verarbeiten, um schneller reagieren zu können. Dieser lokalisierte Ansatz verbessert die Überwachung und hilft bei Echtzeitwarnungen. Er findet breite Anwendung in intelligenten Städten, in der Fertigung und bei vernetzten Fahrzeugen.
Wissenschaftliche Forschung und High-Performance Computing (HPC): Schwere Aufgaben wie Klimasimulationen werden in kleinere Aufträge aufgeteilt, die parallel laufen. Dadurch werden die Berechnungszeiten drastisch verkürzt und die globale wissenschaftliche Zusammenarbeit unterstützt. Forscher können Modelle schneller verfeinern und Innovationen vorantreiben.
Content Delivery Networks (CDNs): Dateien und Medien werden auf Servern in der ganzen Welt gespeichert, so dass die Nutzer vom nächstgelegenen Knotenpunkt aus auf die Inhalte zugreifen können. Durch diese Einrichtung werden Ladezeiten und Netzwerkverzögerungen reduziert, was für Streaming-Dienste, große Dateidownloads und stark frequentierte Websites unerlässlich ist.
Vorteile von verteilten Systemen
Unternehmen setzen auf verteilte Systeme, um die ständig wachsenden Datenmengen und Rechenaufgaben zu bewältigen. Nachfolgend finden Sie einige wichtige Vorteile, die Teams dabei helfen, skalierbar zu sein, stabil zu bleiben und effizienter zu arbeiten:
Skalierbarkeit und gemeinsame Nutzung von Ressourcen: Dank verteilter Architekturen können Unternehmen bei wachsender Arbeitslast weitere Rechner hinzufügen, anstatt sich auf einen einzigen großen Server zu verlassen. Das System vermeidet Engpässe und verbessert den Durchsatz durch die Aufteilung von Daten und Aufgaben auf mehrere Knoten.
Fehlertoleranz und Redundanz: Wenn kritische Daten und Aufgaben über mehrere Knoten repliziert werden, kann das System auch dann weiterlaufen, wenn ein Knoten ausfällt. Dieses Design reduziert Ausfallzeiten und erhält den Benutzerzugriff.
Flexibles und modulares Design: Verteilte Systeme unterteilen Aufgaben oft in kleinere, unabhängige Module. Jeder Knoten übernimmt bestimmte Aufgaben, was die Aktualisierung oder den Austausch von Komponenten erleichtert, ohne die gesamte Umgebung zu unterbrechen.
Balancieren von Konsistenz und Verfügbarkeit (CAP-Theorem):** Für verteilte Systeme ist es schwierig, gleichzeitig vollständig konsistent und immer verfügbar zu sein, insbesondere wenn Netzwerkprobleme auftreten. Die genaue Abwägung hängt davon ab, wie wichtig die sofortige Konsistenz für den jeweiligen Anwendungsfall ist.
Verbesserte Leistung und höherer Durchsatz: Durch die parallele Ausführung von Aufgaben können verteilte Systeme mehr Vorgänge in kürzerer Zeit verarbeiten. Dies ist für die Analyse großer Datenmengen oder die Echtzeit-Vektorsuche unerlässlich.
Herausforderungen und Überlegungen
Verteilte Systeme bieten zwar viele Vorteile, aber sie bringen auch einzigartige Komplexitäten mit sich. Im Folgenden werden einige häufige Hindernisse und Faktoren aufgeführt, die beim Aufbau und bei der Wartung verteilter Infrastrukturen zu beachten sind:
Netzwerklatenz und Bandbreitenbeschränkungen: Aufgaben, die sich über weit entfernte Server erstrecken, können sich verlangsamen, wenn die Netzwerkverbindungen schwach oder überlastet sind. Wenn die Bandbreite begrenzt ist, kann es bei großen Datenübertragungen zu Engpässen kommen. Die Platzierung von Knoten in der Nähe der Benutzer oder die Zwischenspeicherung von Daten kann dazu beitragen, die Latenz zu verringern.
Datenkonsistenz und Partitionstoleranz: Es kann eine Herausforderung sein, alles synchron zu halten, wenn Daten auf mehreren Knoten gespeichert sind. Netzwerkausfälle oder Knotenausfälle führen zu Konflikten, die eine sorgfältige Handhabung erfordern. Einige Systeme bevorzugen schnelle Aktualisierungen, während andere auf strikte Genauigkeit Wert legen.
Sicherheit und Datenschutz: Daten werden zwischen verschiedenen Rechnern verschoben, was das Risiko von Datenlecks oder unbefugtem Zugriff erhöht. Verschlüsselung und strenge Zugangskontrollen helfen, sensible Informationen zu schützen. Regelmäßige Audits und Konformitätsprüfungen sorgen dafür, dass die Nutzerdaten geschützt bleiben.
Verteilte Transaktionen verwalten: An einer einzigen Transaktion können mehrere Dienste oder Knoten beteiligt sein, was die Koordination erschwert. Protokolle wie Two-Phase-Commit oder Transaktionsmanager verfolgen diese Schritte. Sorgfältige Rollback-Strategien verhindern, dass Daten durch Teilausfälle beschädigt werden.
Einführung in Milvus: Eine verteilte, Cloud-native Vektordatenbank
Milvus wurde von Grund auf als Cloud-natives, verteiltes System für die Verwaltung hochdimensionaler Vektordaten entwickelt. Durch die Aufteilung der Daten und der Verarbeitung auf mehrere Knoten bietet Milvus die wichtigsten Vorteile der verteilten Datenverarbeitung - Skalierbarkeit, Fehlertoleranz und parallele Ausführung - und eignet sich damit hervorragend für das Training von KI-Modellen, Echtzeit-Empfehlungssysteme und komplexe Analysen.
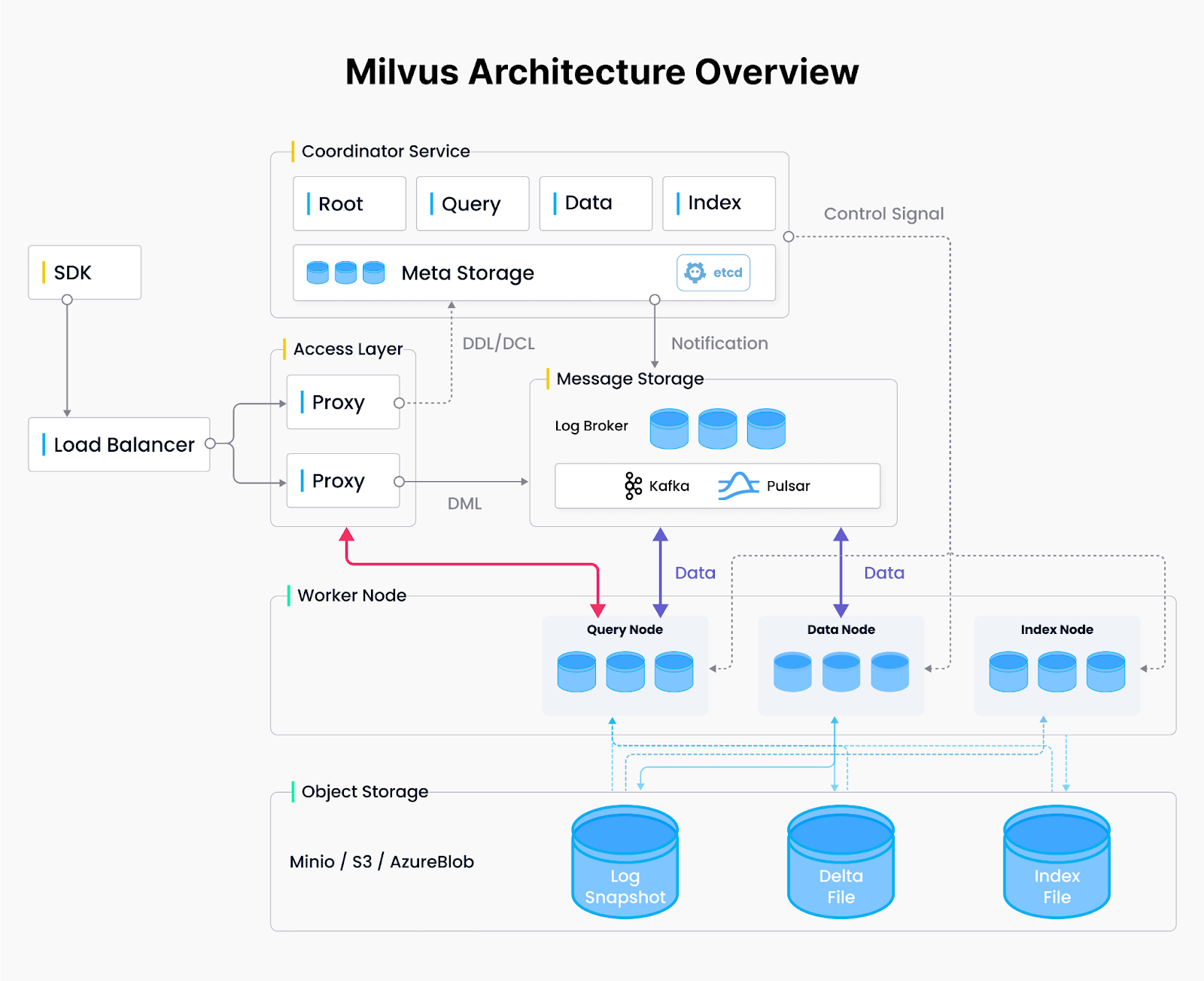 Milvus Architektur.png
Milvus Architektur.png
Abbildung: Milvus-Architektur
Verteilte Milvus-Architektur: Vier-Schichten-Design
Milvus ist eine weit verbreitete [Vektordatenbank] (https://zilliz.com/learn/what-is-vector-database), die eine verteilte Systemarchitektur mit vier Schichten verwendet, um Ressourcen dynamisch dort zuzuweisen, wo sie am meisten benötigt werden - sei es mehr Rechenleistung für eine umfangreiche Indexierung oder zusätzlicher Speicher für die parallele Bearbeitung komplexer Abfragen.
Zugangsschicht: Die zustandslosen Zugangsknoten bearbeiten eingehende Anfragen und dienen als Einstiegspunkt in das System.
Koordinationsschicht: Koordiniert die Zuweisung von Knoten und die Verwaltung von Ressourcen und schaltet je nach Bedarf Arbeiter ein oder aus.
Worker-Schicht: Führt die Kernaufgaben der Abfrage, Datenaufnahme und Indexerstellung auf skalierbaren, zustandslosen Knoten aus.
Speicherebene: Speichert Vektordaten und System-Metadaten für Fehlertoleranz und Beständigkeit der Knoten.
Skalierbarkeit und Konsistenz in der verteilten Milvus-Architektur
Milvus wendet die Prinzipien der verteilten Datenverarbeitung an, um massive Vektordatensätze zu verarbeiten und gleichzeitig die Datenkonsistenz zu gewährleisten. Nachfolgend sind die wichtigsten Designmerkmale aufgeführt, die eine horizontale Skalierung, die Minimierung von Engpässen und einstellbare Konsistenzstufen ermöglichen:
Horizontale Skalierung](https://zilliz.com/ai-faq/what-is-horizontal-scaling-in-distributed-databases): Milvus segmentiert große Datensätze in überschaubare Teile. Jedes Segment wird unabhängig indiziert, sodass Sie bei wachsenden Datenmengen weitere Knoten hinzufügen können, ohne die bestehende Infrastruktur zu überholen.
Unabhängige Knoten für Abfrage, Daten und Index: Um bestimmte Funktionen zu skalieren, werden Abfragen, Dateneingabe und Indizierung unabhängig voneinander auf separaten Knotentypen ausgeführt. Diese Trennung hilft, Engpässe zu vermeiden und stellt sicher, dass das System Milliarden von Vektoren verarbeiten kann.
Anpassbare Konsistenz und Sharding: Daten werden für gleichzeitige Schreibvorgänge auf mehrere Knoten verteilt, während die [anpassbaren Konsistenzstufen] (https://zilliz.com/blog/understand-consistency-models-for-vector-databases) von Milvus ein Gleichgewicht zwischen Leistung und Genauigkeit auf der Grundlage Ihrer Anwendungsanforderungen ermöglichen.
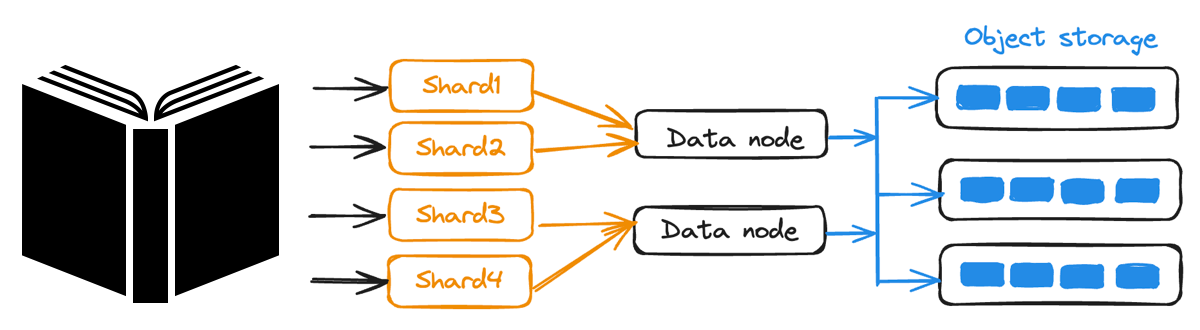 Data Sharding in Milvus
Data Sharding in Milvus
Abbildung: Data Sharding in Milvus
Mehrere Bereitstellungsmodi für unterschiedliche Bedürfnisse
Milvus bietet mehrere Bereitstellungsoptionen, um unterschiedlichen Datengrößen und Leistungsanforderungen gerecht zu werden. Ob Sie auf einem einzelnen Rechner testen oder ein umfangreiches Produktionssystem betreiben, mit diesen Modi können Sie Ressourcen und Komplexität an die Anforderungen Ihres Projekts anpassen. Unten sehen Sie eine Illustration des Grades der Datenskalierung für jede Vektordatenbank. Sie sehen, dass Milvus Distributed für die Verarbeitung von Datenmengen im zweistelligen Millionenbereich und darüber hinaus ausgelegt ist.
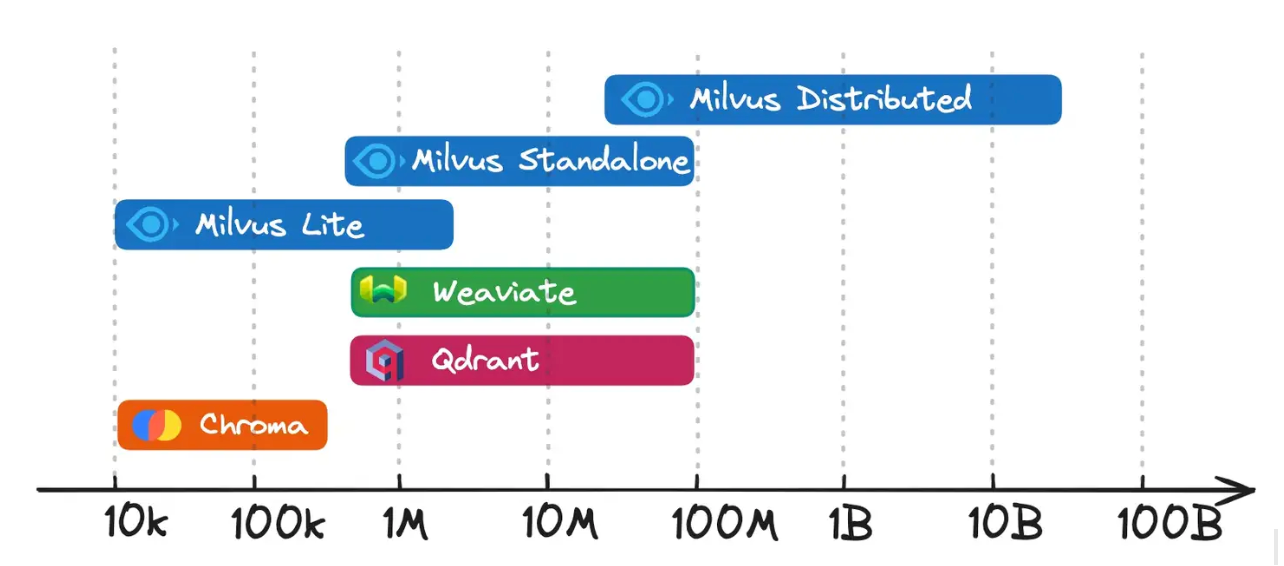 Milvus-Bereitstellungsmodi
Milvus-Bereitstellungsmodi
Abbildung: Milvus-Bereitstellungsmodi
Milvus Lite:](https://milvus.io/blog/introducing-milvus-lite.md) Eine leichtgewichtige Python-Bibliothek, die die Kernfunktionalitäten von Milvus bereitstellt, ohne dass ein separater Serverprozess erforderlich ist. Sie ist ideal für kleine Experimente, schnelles Prototyping oder schnelle Demos in lokalen Umgebungen. Mit Milvus Lite können Sie schnell und mit minimaler Einrichtung loslegen, wenn Sie ein Proof of Concept erstellen oder neue Funktionen in einem Notebook testen.
Milvus Distributed: Eine Architektur mit mehreren Knoten, die für die Anforderungen von Unternehmen ausgelegt ist. Durch die Aufteilung der Aufgaben auf Zugangsknoten, Koordinatoren, Worker und Speicherebenen können Milliarden (oder sogar mehrere zehn Milliarden) von Vektoren mit hoher Verfügbarkeit und Fehlertoleranz verarbeitet werden. Dieses Modell ist die erste Wahl für Unternehmen, die ein schnelles Wachstum ihrer Daten erwarten, eine robuste Leistung bei gleichzeitigen Abfragen benötigen und die Flexibilität haben möchten, je nach Arbeitslast Knoten hinzuzufügen oder zu entfernen.
Milvus Standalone: Eine Einzelknotenbereitstellung, die alle Milvus-Komponenten in einer Umgebung bündelt, die häufig über ein Docker-Image verteilt wird. Dies macht die Installation und Wartung einfach und bietet gleichzeitig genügend Kapazität für moderate Datenmengen. Teams, die Produktions-Workloads ausführen möchten, die keine massive Skalierbarkeit oder komplizierte Failover-Mechanismen erfordern, finden diese Option sowohl kostengünstig als auch zuverlässig.
Wenn Sie mehr über den Einsatz von Milvus erfahren möchten, lesen Sie unseren Leitfaden: [Wie Sie den richtigen Milvus-Bereitstellungsmodus für Ihre KI-Anwendungen auswählen] (https://zilliz.com/blog/choose-the-right-milvus-deployment-mode-ai-applications).
Fazit
Verteiltes Computing hat die Art und Weise, wie Unternehmen mit Daten umgehen und ihre Anwendungen skalieren, verändert: weg von monolithischen Servern, hin zu flexiblen, fehlertoleranten Clustern miteinander verbundener Knoten. Durch die Aufteilung von Aufgaben und Daten auf mehrere Rechner erreichen Teams eine schnellere Verarbeitung, eine höhere Verfügbarkeit und eine effizientere Ressourcennutzung. Moderne Lösungen wie Zilliz wenden diese Prinzipien an, um eine Cloud-native Vektordatenbank bereitzustellen, die Milliarden von Vektoren parallel verarbeiten kann. Da die Datenmengen weiter steigen und die Anwendungsfälle immer komplexer werden, bleibt die Einführung eines verteilten Ansatzes - ob für Analysen, maschinelles Lernen oder Echtzeitempfehlungen - eine Schlüsselstrategie, um in der heutigen datengesteuerten Welt wettbewerbsfähig zu bleiben.
FAQs zu verteiltem Computing
Warum ein verteiltes System einem einzelnen, leistungsstarken Server vorziehen?Mit einem verteilten System können Sie weitere Maschinen hinzufügen, wenn die Arbeitslasten wachsen, anstatt einen einzelnen Server aufzurüsten. Diese Flexibilität steigert die Leistung, senkt die Kosten und reduziert die Auswirkungen eines einzelnen Fehlerpunkts.
Wie bleiben Daten in einer verteilten Umgebung konsistent?Verteilte Systeme verwenden Protokolle und Algorithmen (z. B. Konsensmechanismen), um Daten über mehrere Knoten hinweg synchron zu halten. Der genaue Ansatz variiert von System zu System, aber das Ziel ist es, sicherzustellen, dass Aktualisierungen nicht in Konflikt geraten und jeder Knoten über die korrekte Datensicht verfügt.
Ist die Wartung verteilter Infrastrukturen schwierig?Die Komplexität verteilter Systeme kann durch den Einsatz geeigneter Tools und bewährter Verfahren verringert werden, da sie mehr bewegliche Komponenten umfassen, z. B. Netzwerkkommunikation, Knotenkoordination und Replikation. Tools wie Kubernetes und Überwachungsplattformen vereinfachen die Orchestrierung und Beobachtbarkeit.
Milvus ist eine Cloud-native, verteilte Vektordatenbank, die für groß angelegte Ähnlichkeitssuchen entwickelt wurde. Durch die Aufteilung von Daten in Segmente und die Nutzung paralleler Indizierung kann Milvus Milliarden von Vektoren über mehrere Knoten hinweg verarbeiten, ohne dabei an Geschwindigkeit oder Zuverlässigkeit einzubüßen.
Was ist, wenn meine Daten gesammelt werden müssen oder der Datenverkehr plötzlich in die Höhe schießt?Verteilte Systeme sind ideal, um plötzliche Änderungen der Nachfrage zu bewältigen. Sie können zusätzliche Knoten oder Ressourcen schnell hochfahren, so dass eine Überlastung eines Rechners vermieden wird und die Leistung auch in Spitzenzeiten konstant bleibt.
Verwandte Ressourcen
Änderungsdatenerfassung: Synchronisieren Sie Ihre Systeme in Echtzeit
Optimierung der Datenkommunikation: Milvus setzt auf NATS Messaging](https://zilliz.com/blog/optimizing-data-communication-milvus-embraces-nats-messaging)
Umfassende Überwachung und Beobachtungsmöglichkeiten in der Zilliz Cloud](https://zilliz.com/blog/introducing-monitoring-and-observability-in-zilliz-cloud)
- Von einzelnen Servern zu verteilten Systemen: Die Entwicklung
- Wie funktioniert verteiltes Rechnen?
- Arten von Architekturen für verteiltes Rechnen
- Anwendungsfälle für verteiltes Rechnen
- Vorteile von verteilten Systemen
- Herausforderungen und Überlegungen
- Einführung in Milvus: Eine verteilte, Cloud-native Vektordatenbank
- Fazit
- FAQs zu verteiltem Computing
- Verwandte Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren