




Conditional Variational Autoencoders (CVAEs): Generative Modelle mit bedingten Eingaben

Conditional Variational Autoencoders (CVAEs): Generative Modelle mit bedingten Eingaben
Haben Sie sich jemals gefragt, wie KI spezifische, realistische Bilder oder Daten auf der Grundlage einer Bedingung erzeugen kann, etwa ein Bild einer Katze in einem bestimmten Stil?
Variational Autoencoders (VAEs) sind leistungsstarke generative Modelle, bieten jedoch keine Kontrolle über Datenattribute. Conditional Variational Autoencoders (CVAEs) überwinden diese Einschränkung, indem sie Bedingungen wie Labels oder Attribute sowohl in den Encoder als auch in den Decoder integrieren. Dadurch können CVAEs Daten erzeugen, die auf spezifische Anforderungen zugeschnitten sind, was sie ideal für Aufgaben wie gezielte Bilderstellung oder personalisierte Inhaltsgenerierung macht und ihr Potenzial in verschiedenen Bereichen erweitert.
Lassen Sie uns untersuchen, wie Conditional Variational Autoencoders (CVAEs) funktionieren, welche Vorteile sie haben und wie sie die Datengenerierung in verschiedenen Domänen verändern.
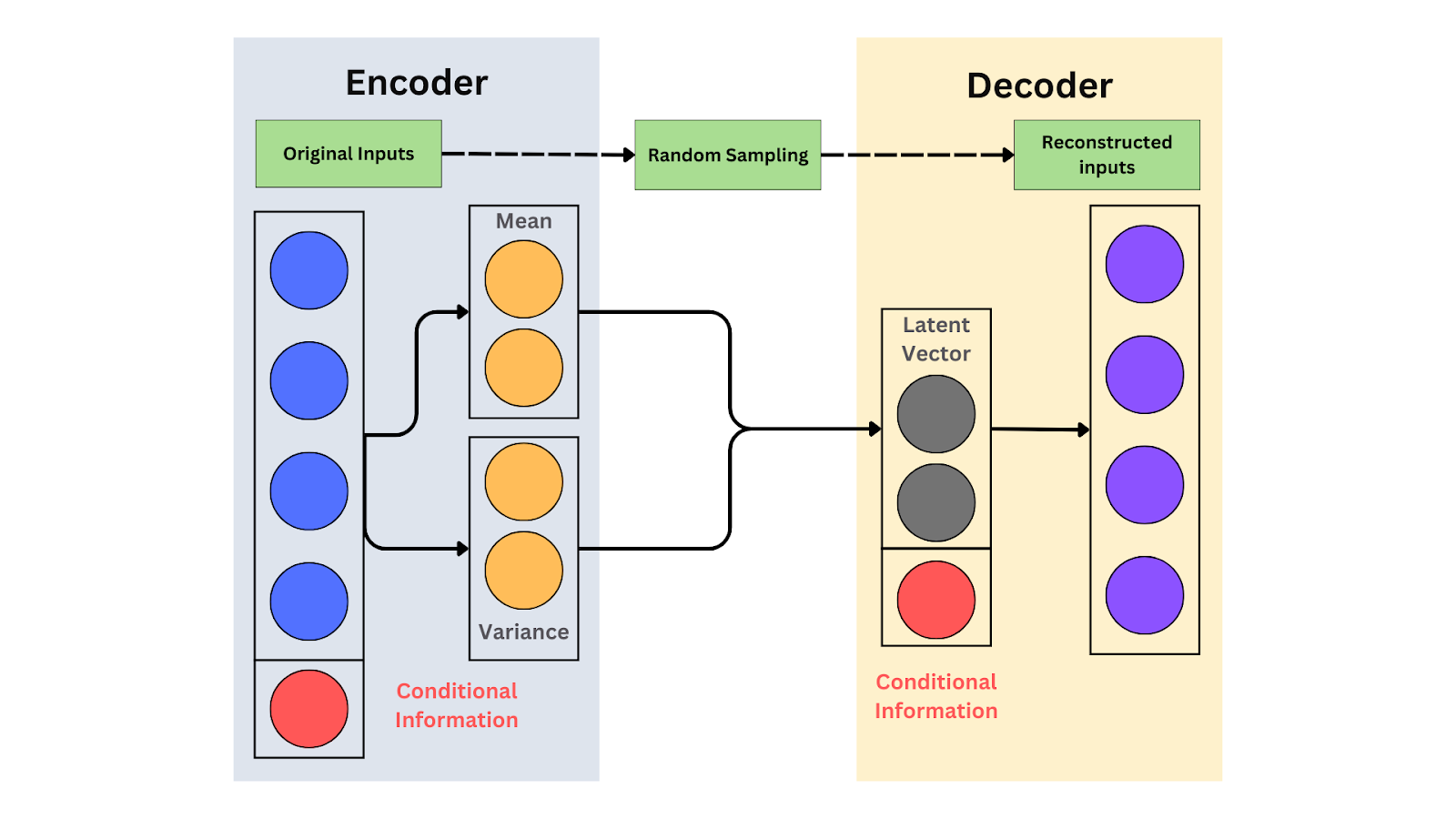 The schematic of a CVAE.png
The schematic of a CVAE.png
Das Schema eines CVAE
Was sind Conditional Variational Autoencoders (CVAE) ?
Ein Conditional Variational Autoencoder (CVAE) ist eine Erweiterung des Variational Autoencoder (VAE), die bedingte Eingaben wie Labels oder Attribute einbezieht, um den Datengenerierungsprozess zu steuern. Die generierten Daten erfüllen spezifische Anforderungen, indem das Modell konditioniert wird. Wenn Sie beispielsweise Bilder von Katzen oder Hunden erstellen möchten, können Sie das Label "cat" oder "dog" bereitstellen, um die Generierung zu steuern. Dadurch kann das Modell die gewünschte Ausgabe basierend auf der Bedingung erzeugen.
CVAEs sind wichtig, weil sie Kontrolle über die Datengenerierung bieten. Die bedingten Eingaben stellen sicher, dass die Ausgaben vordefinierten Merkmalen entsprechen. Dies macht sie nützlich für Aufgaben wie die Bilderzeugung im Modedesign, bei der Modelle Kleidungsstücke in verschiedenen Farben oder Stilen erstellen können, sowie für gezielte Simulationen, bei denen bestimmte Szenarien basierend auf bestimmten Bedingungen erzeugt werden müssen.
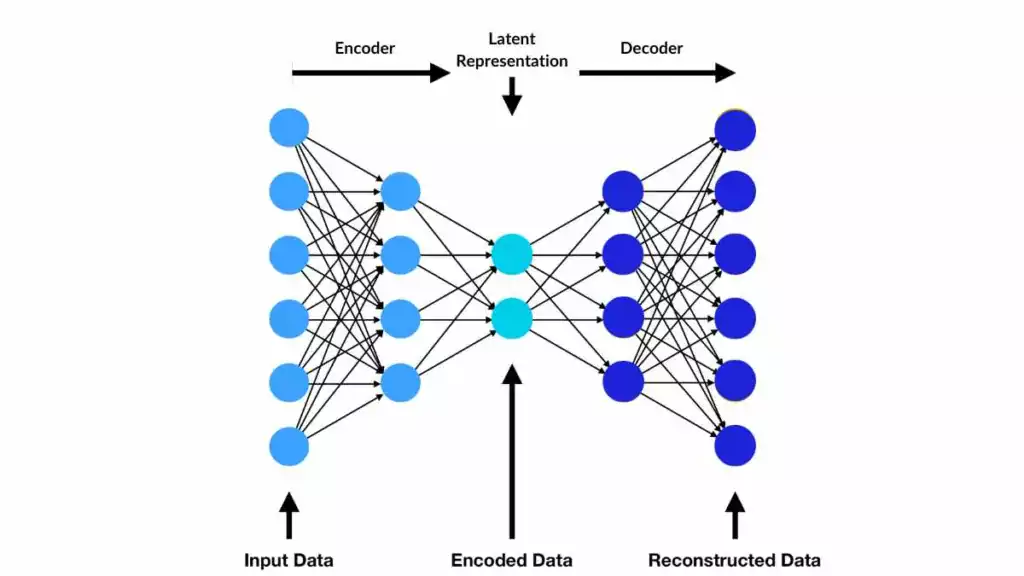 Autoencoder structure underlies VAEs and CVAEs.png
Autoencoder structure underlies VAEs and CVAEs.png
Die Autoencoder-Struktur liegt VAEs und CVAEs zugrunde | Quelle
Variational Autoencoders (VAEs) verstehen
Bevor wir tief in CVAEs eintauchen, lassen Sie uns das Konzept der Variational Autoencoders (VAEs) besprechen. VAEs sind generative Modelle, die lernen, komplexe Datenverteilungen in einem kontinuierlichen latenten Raum darzustellen, um neue Datenproben zu erzeugen.
VAEs enthalten zwei Hauptkomponenten: einen Encoder und einen Decoder. Der Encoder komprimiert Eingabedaten in einen latenten Raum und erfasst dabei deren zentrale Merkmale. Der Decoder rekonstruiert die Eingabe oder erzeugt neue Proben aus dieser latenten Darstellung. Eine Verlustfunktion spielt beim Training eine Schlüsselrolle, indem sie Rekonstruktionsgenauigkeit und Regularität des latenten Raums ausbalanciert. Regularisierung stellt sicher, dass der latente Raum glatt und strukturiert ist und so eine kohärente Datengenerierung ermöglicht.
Verlustfunktion
Die Verlustfunktion in Variational Autoencoders (VAEs) besteht aus zwei Hauptkomponenten: Rekonstruktionsverlust und KL-Divergenz.
- Rekonstruktionsverlust misst, wie gut das Modell die Eingabedaten reproduziert. Er wird typischerweise mithilfe des Mean Squared Error (MSE) oder der Binary Cross-Entropy berechnet. Die Gleichung für den Rekonstruktionsverlust lautet:
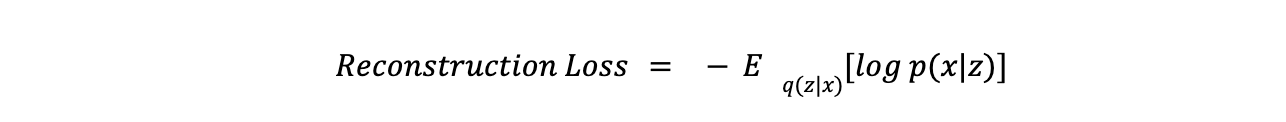
- KL-Divergenz, kurz für Kullback-Leibler-Divergenz, ist ein statistisches Maß dafür, wie stark sich eine Wahrscheinlichkeitsverteilung unterscheidet. Im Kontext von VAEs stellt sie sicher, dass die latente Verteilung 𝒒(𝔃∣𝔁) (vom Encoder gelernt) nahe an der Prior-Verteilung 𝒑(𝔃) bleibt, die typischerweise eine Standard-Gauß-Verteilung ist. Die Gleichung für die KL-Divergenz lautet:
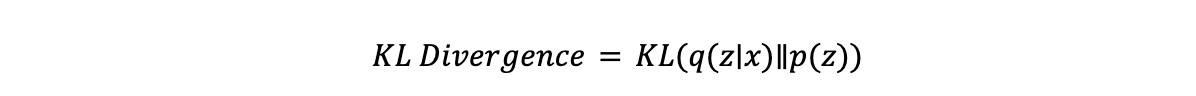
Die gesamte Verlustfunktion ist eine gewichtete Summe dieser beiden Terme:
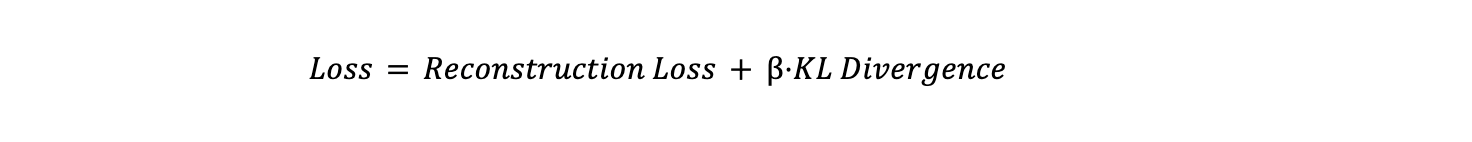
Wobei β ein Hyperparameter ist, der den Kompromiss zwischen dem Rekonstruktionsverlust und der KL-Divergenz steuert. Ein höheres β misst der Regularisierung des latenten Raums mehr Bedeutung bei, während ein niedrigerer Wert es dem Modell ermöglicht, sich stärker auf eine genaue Rekonstruktion zu konzentrieren. Dieses Gleichgewicht ist entscheidend, um sicherzustellen, dass das Modell sowohl genaue Daten generiert als auch einen sinnvollen, gut strukturierten latenten Raum lernt.
Regularisierung
Regularisierung verwendet die Kullback-Leibler-Divergenz, um den latenten Raum an die Prior-Verteilung anzupassen und sicherzustellen, dass latente Variablen einer Gauß-Verteilung folgen. Dies glättet den latenten Raum und ermöglicht Interpolation sowie sinnvolles Sampling. Punkte, die im latenten Raum nahe beieinander liegen, erzeugen ähnliche Ausgaben. Regularisierung verbessert außerdem die Generalisierung, indem sie verhindert, dass das Modell die Trainingsdaten überanpasst. In der Modedesignbranche stellt Regularisierung beispielsweise sicher, dass vielfältige Kleidungsdesigns generiert werden, während realistische Muster und Stile beibehalten werden. Sie hilft dabei, Variationen bei Kleidungsarten, Farben und Texturen zu erzeugen, ohne unrealistische Ausgaben zu produzieren. Indem der latente Raum strukturiert gehalten wird, generiert sie Designs, die aktuellen Trends entsprechen, aber auf ihre eigene Weise unterschiedlich sind.
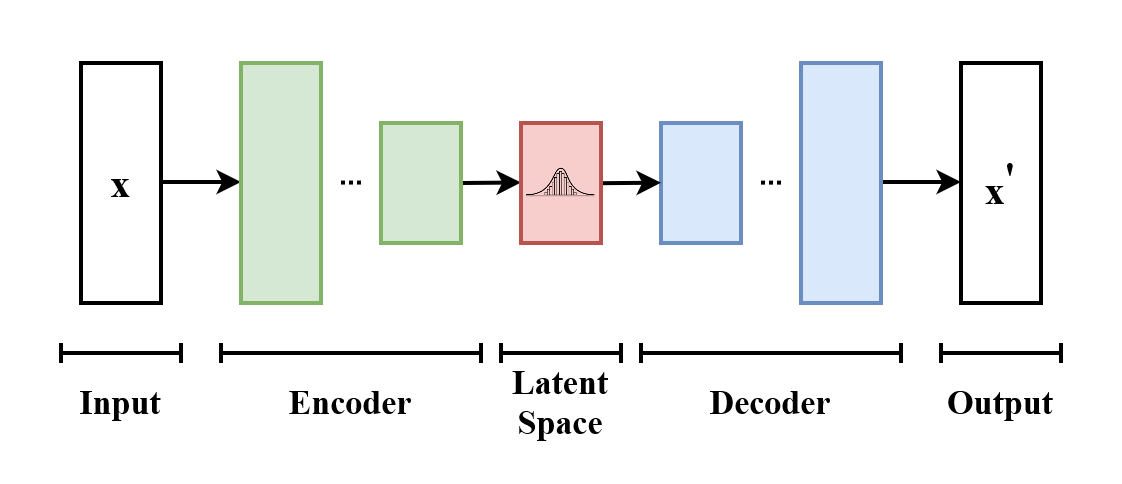 Structure of a Variational Autoencoder (VAE) |.png
Structure of a Variational Autoencoder (VAE) |.png
Struktur eines Variational Autoencoder (VAE) | Quelle
{kind=link}
Wie verbessert CVAE VAE durch bedingte Eingaben?
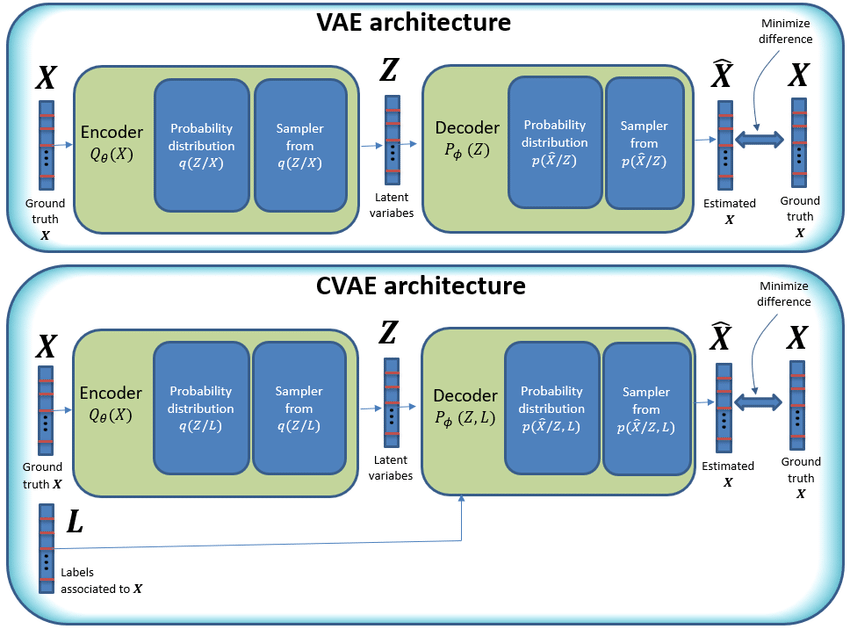
CVAEs erweitern VAEs, indem sie bedingte Eingaben wie Klassenlabels hinzufügen, um die Datengenerierung zu steuern. Der Encoder verarbeitet sowohl die Eingabedaten als auch die Bedingung. Er bildet sie in einen gemeinsamen latenten Raum ab und erfasst dabei die Daten und die Bedingung in kombinierter Form. Der Decoder verwendet dann diese latente Repräsentation, eine komprimierte Datenversion, zusammen mit der Bedingung, um neue Samples zu generieren.
Wenn die Bedingung beispielsweise „rote Sneaker“ lautet, generiert der Decoder ein Bild von roten Sneakern. Die Bedingung stellt sicher, dass die Ausgabe bestimmten Anforderungen entspricht. Wie VAEs verwenden CVAEs die KL-Divergenz, um den latenten Raum zu regularisieren und eine glatte Verteilung zu erzeugen.
VAEs verlassen sich ausschließlich auf Variationen in den Eingabedaten, was die Kontrolle über die Ausgabe einschränkt. CVAEs verwenden Labels oder Attribute, um den Generierungsprozess zu steuern. Dies ermöglicht gezielte und spezifische Ausgaben. Bei einem auf MNIST trainierten CVAE könnte die Bedingung beispielsweise ein Ziffernlabel wie „5“ sein. Mit dem Label und einer Eingabe generiert das Modell eine spezifische „5“. Ein VAE hingegen könnte je nach latentem Raum eine beliebige zufällige Ziffer generieren.
CVAEs eignen sich ideal für Aufgaben wie das Generieren von Bildern mit bestimmten Merkmalen oder die Personalisierung von Inhalten. Beispielsweise kann ein CVAE ein Sneaker-Design basierend auf den Farb-, Größen- und Stilpräferenzen eines Benutzers generieren und so die Anpassung und Benutzererfahrung verbessern.
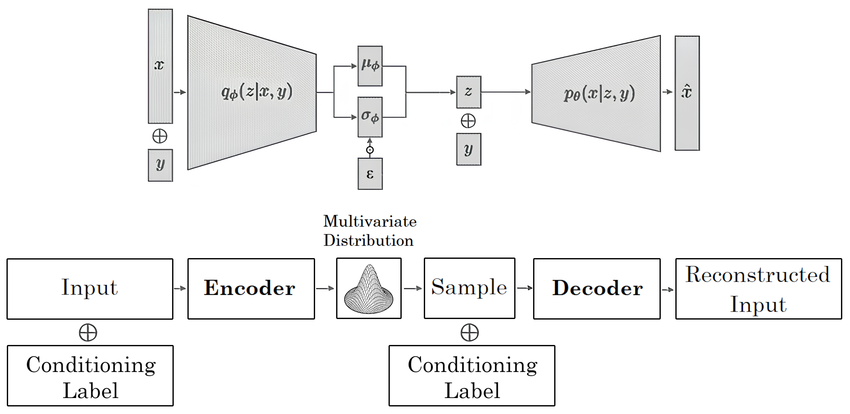 Conditional Variational Autoencoder (CVAE) Architecture.png
Conditional Variational Autoencoder (CVAE) Architecture.png
Conditional Variational Autoencoder (CVAE) Architecture | Quelle
Wichtige Begriffe:
Latenter Raum: Der latente Raum ist eine hochdimensionale, komprimierte Repräsentation von Daten. Er erfasst wesentliche Merkmale von Eingabedaten, wie Pose oder Farbe, in kompakter Form. Beispielsweise könnte ein Bild eines Gesichts in einen Vektor komprimiert werden, der Alter oder Ausdruck repräsentiert. Der Raum folgt typischerweise einer bekannten Verteilung (z. B. Gauß-Verteilung), wodurch durch Sampling aus dieser Verteilung neue, ähnliche Datenpunkte generiert werden können. Diese Repräsentation ermöglicht es dem Modell, Datenpunkte effektiv zu manipulieren oder zwischen ihnen zu interpolieren.
Encoder: Der Encoder wandelt Eingabedaten in eine probabilistische latente Darstellung um. Er bildet die Eingabe 𝔁 (wie ein Bild) auf eine Verteilung (Mittelwert 𝜇, Varianz 𝝈2) über den latenten Raum ab. Beispielsweise gibt der Encoder bei einem Katzenbild eine Verteilung von Merkmalen wie Farbe und Rasse aus. Aus dieser Verteilung wird ein latenter Vektor abgetastet. Der Encoder lernt, wie Daten effizient komprimiert werden können, während wesentliche Merkmale erhalten bleiben.
Decoder: Der Decoder nimmt eine latente Variable 𝔃 und rekonstruiert oder generiert Daten. Er bildet den latenten Vektor, eine komprimierte Version der Daten, zurück auf den ursprünglichen Datenraum ab. Zum Beispiel erzeugt der Decoder ein Bild einer Katze aus einem latenten Vektor, der Katzenmerkmale repräsentiert. Die Funktion wird als 𝒑(𝔁∣𝔃) bezeichnet, wobei 𝔁 die generierten Daten sind. Der Decoder kann vielfältige Ausgaben erzeugen, indem er aus den latenten Variablen lernt, selbst für ungesehene Daten.
Conditional Inputs: Conditional inputs stellen zusätzliche Informationen (z. B. Labels) bereit, die die Datengenerierung steuern. In CVAE helfen Labels wie "cat", spezifische Ausgaben zu erzeugen, etwa Katzenbilder. Der Encoder und der Decoder verwenden diese Eingaben, um kontrollierte Ausgaben zu erstellen. Beispielsweise wird der Encoder zu 𝒒(𝔃∣𝔁,𝔂), und der Decoder ist 𝒑(𝔁∣𝔃,𝔂). Diese Eingaben stellen sicher, dass das Modell Daten generiert, die auf die gegebenen Bedingungen zugeschnitten sind, wodurch die Flexibilität erhöht wird.
- KL Divergence: KL Divergence misst, wie unterschiedlich die vom Encoder gelernte Verteilung von der Prior-Verteilung (normalerweise einer Gauß-Verteilung) ist. Sie ermutigt den Encoder, latente Variablen nahe an der Prior-Verteilung zu generieren, wodurch ein strukturierter latenter Raum sichergestellt wird. Die Formel lautet:
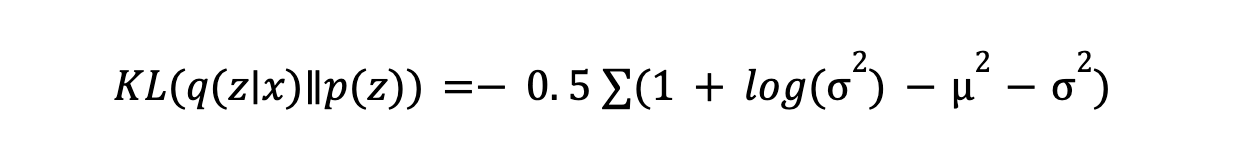
Die Minimierung der KL-Divergenz hilft, einen gut funktionierenden latenten Raum für die Datengenerierung aufrechtzuerhalten. Diese Regularisierungstechnik stellt sicher, dass die latenten Variablen so verteilt sind, dass das Sampling und die Generierung neuer Datenpunkte zuverlässig sind.
CVAEs vs. VAEs vs. GANs
Dieser Abschnitt vergleicht Variational Autoencoders (VAEs) mit Conditional Variational Autoencoders (CVAEs) und Generative Adversarial Networks (GANs). Alle sind generative Modelle, aber sie weisen mehrere wichtige Unterschiede auf.
Die folgende Tabelle hebt die Unterschiede in ihren Mechanismen, ihrer Flexibilität und ihren Anwendungsfällen hervor.
| Aspekt | VAE (Variational Autoencoder) | CVAE (Conditional Variational Autoencoder) | GANs (Generative Adversarial Networks) |
| Kernmechanismus | Kodiert Eingabedaten in einen komprimierten latenten Raum und generiert neue Daten. | Ähnlich wie VAE, integriert er bedingte Eingaben (z. B. Labels), um die Generierung zu steuern. | Besteht aus zwei Netzwerken: Ein Generator erzeugt Daten, und ein Diskriminator bewertet sie. |
| Eingabedaten | Nur die Daten selbst werden in den Encoder eingespeist. | Bedingte Daten (z. B. Klassenlabels und Attribute) werden ebenfalls im Encoder verwendet. | Verwendet zufälliges Rauschen als Eingabe für den Generator, während der Diskriminator generierte Daten bewertet. |
| Latente Repräsentation | Repräsentiert die gesamte Datenverteilung und bietet einen glatten, kontinuierlichen latenten Raum. | Der latente Raum ist durch Eingabedaten bedingt und bietet mehr Kontrolle über die generierte Ausgabe. | Der latente Raum wird während des Trainings gelernt, ohne explizite Kontrolle über bestimmte Merkmale. |
| Generierungskontrolle | Die Generierung basiert ausschließlich auf dem latenten Raum, ohne externe Steuerungen. | Bedingte Daten ermöglichen die Generierung von Daten basierend auf bestimmten Attributen (z. B. das Generieren von Bildern bestimmter Kategorien wie „Katze“ oder „Hund“). | Der Generator „konkurriert“ mit dem Diskriminator und verbessert die generierten Daten, indem er den Diskriminator „täuscht“. |
| Flexibilität | Gut für allgemeine Datengenerierung und Anomalieerkennung. | Ideal für Szenarien, in denen eine kontrollierte Generierung basierend auf bestimmten Attributen erforderlich ist. | Sehr flexibel bei der Generierung realistischer Beispiele, aber weniger Kontrolle über spezifische Ausgaben. |
| Trainingsdaten | Er kann auf einem breiten Datensatz ohne explizite Bedingungen trainiert werden. | Zusätzliche gelabelte oder bedingte Daten sind erforderlich, um den Generierungsprozess zu steuern. | Erfordert adversariales Training, bei dem Generator und Diskriminator miteinander konkurrieren. |
| Anwendungsfälle | Datengenerierung (z. B. Generieren von Gesichtern), Anomalieerkennung und Interpolation von Datenpunkten. | Kontrollierte Bildgenerierung (z. B. Generieren bestimmter Objekte oder Bedingungen wie Farbe oder Stil), semi-supervised Learning. | Hochwertige Bildgenerierung, Bild-zu-Bild-Übersetzung, Stiltransfer und Datenerweiterung. |
| Hauptvorteile | Einfacher zu trainieren, ohne Bedarf an externen Bedingungen. | Ermöglicht die Generierung hochspezifischer Ausgaben und bietet bessere Kontrolle über generierte Daten. | Generiert hochrealistische Bilder und vielfältige Daten, ohne Bedarf an expliziten Labels. |
| Beispielanwendung | Generieren zufälliger Bilder von Gesichtern. | Generieren von Bildern von Gesichtern mit bestimmten Attributen wie Alter, Geschlecht oder Ausdruck. | Generieren realistischer Bilder menschlicher Gesichter, Generieren von Kunst oder Übersetzen von Bildern von einem Stil in einen anderen. |
 Vergleich von CVAE mit einer typischen VAE-Architektur.png
Vergleich von CVAE mit einer typischen VAE-Architektur.png
Vergleich von CVAE mit einer typischen VAE-Architektur | Quelle
 Vergleich der Architekturen von (A) VAEs und (B) GANs.png
Vergleich der Architekturen von (A) VAEs und (B) GANs.png
Vergleich der Architekturen von (A) VAEs und (B) GANs | Quelle
Vorteile und Herausforderungen von Variational Autoencoders (VAEs)
Variational Autoencoders (VAEs) bieten erhebliche Vorteile in der generativen Modellierung, bringen jedoch auch Herausforderungen mit sich, die angegangen werden müssen. Lassen Sie uns zunächst die Vorteile der Verwendung von VAEs besprechen.
Bedingte Generierung: CVAEs können neue Stichproben auf Basis spezifischer Bedingungen generieren, wodurch sie für Aufgaben wie das Erzeugen von Bildern mit bestimmten Merkmalen oder das Erstellen personalisierter Inhalte nützlich sind. Dies verleiht verschiedenen Anwendungen Flexibilität und Vielseitigkeit.
Bedeutungsvolle Repräsentationen: Conditional VAEs (CVAEs) lernen bedeutungsvolle latente Repräsentationen aus der Eingabe, was ein besseres Verständnis und eine bessere Manipulation von Datenstrukturen ermöglicht. Dies ist besonders vorteilhaft für Aufgaben wie Merkmalsextraktion und Analyse.
Anpassung: CVAEs können Daten erzeugen, die auf spezifische Bedürfnisse zugeschnitten sind, und ermöglichen so maßgeschneiderte Empfehlungen und zielgerichtete Inhalte. Dadurch sind sie in Bereichen wie Werbung und personalisierten Benutzeranwendungen äußerst wertvoll.
Datenerweiterung: CVAEs können verwendet werden, um Datensätze durch die Generierung vielfältiger und realistischer synthetischer Daten zu erweitern. Diese Fähigkeit trägt dazu bei, die Leistung von Machine-Learning-Modellen zu verbessern, insbesondere in Szenarien mit begrenzten oder unausgewogenen Datensätzen.
Lassen Sie uns nun die Herausforderungen besprechen, die bei der Verwendung von VAEs auftreten.
Mode Collapse: Dies tritt auf, wenn das Modell nur wenige Arten von Stichproben generiert, was zu repetitiven statt vielfältigen Ausgaben führt. Overfitting kann dieses Problem verschärfen, indem es das Modell dazu veranlasst, spezifische Muster auswendig zu lernen, anstatt bedeutungsvolle latente Repräsentationen zu lernen. Dies geschieht häufig aufgrund einer unzureichenden Exploration des latenten Raums oder unzureichender und nicht repräsentativer Trainingsdaten. Um dies zu beheben, können Regularisierungstechniken wie Dropout und Batch-Normalisierung zusammen mit fortgeschrittenen Trainingsalgorithmen wie Importance-Weighted Autoencoders (IWAE) verwendet werden.
Erzeugung hochauflösender Bilder: CVAEs haben Schwierigkeiten, hochauflösende Bilder effektiv zu erzeugen. Der latente Raum des Modells erfasst möglicherweise nicht genügend feingranulare Details, was zu verschwommenen oder verzerrten Ausgaben führt. Diese Einschränkung ergibt sich aus der begrenzten Kapazität des latenten Raums und dem Qualitätsverlust bei hochauflösenden Ausgaben. Die Minderung dieser Herausforderung umfasst die Verwendung komplexerer latenter Räume oder hierarchischer VAEs, die Kombination von CVAEs mit Modellen wie GANs oder den Einsatz progressiver Trainingstechniken, die die Auflösung während des Trainings schrittweise erhöhen.
Anwendungsfälle von Conditional Variational Autoencoders (CVAEs)
Conditional Variational Autoencoders (CVAEs) sind vielseitige Werkzeuge im Deep Learning, mit Anwendungen in einer Vielzahl von Bereichen. Hier sind einige wichtige Anwendungsfälle:
Bilderzeugung: CVAEs erzeugen Bilder, die auf Attribute wie Stil, Pose oder Beleuchtung konditioniert sind. In Design und Mode werden sie verwendet, um Kleidung in verschiedenen Stilen oder Farben zu visualisieren. Spieleentwickler nutzen sie, um vielfältige Charaktererscheinungen zu erstellen, während Automobilhersteller sie verwenden, um Fahrzeuge mit verschiedenen Anpassungen für Kunden zu rendern.
Content-Empfehlungssysteme: CVAEs verbessern die Personalisierung, indem sie Benutzerpräferenzen lernen, um relevante Empfehlungen vorzuschlagen. Sie passen sich außerdem dynamisch an Benutzerinteraktionen an und verbessern so im Laufe der Zeit das Engagement.
Wirkstoffentdeckung: CVAEs beschleunigen medizinische Innovationen, indem sie neuartige molekulare Strukturen auf der Grundlage gewünschter Eigenschaften generieren. Sie optimieren außerdem bestehende Verbindungen für verbesserte therapeutische Ergebnisse.
Anomalieerkennung: CVAEs identifizieren ungewöhnliche Muster in kritischen Systemen. Sie markieren Abweichungen von normalen Betriebsparametern und verbessern die Cybersicherheit, indem sie ungewöhnliche Netzwerkaktivitäten erkennen.
Verarbeitung natürlicher Sprache (NLP): CVAEs tragen zu Aufgaben wie der Generierung kohärenter Texte bei, die auf Kontext, Stil oder Ton konditioniert sind. Sie erleichtern außerdem nuancierte Sprachübersetzungen, die auf stilistische Anforderungen zugeschnitten sind.
Kunst und Kreativität: CVAEs befähigen Künstler und Kreative, indem sie Stilübertragung ermöglichen, um Kunstwerke in unterschiedlichen Ästhetiken neu zu interpretieren. Sie unterstützen außerdem bei der Generierung neuartiger künstlerischer Schöpfungen auf der Grundlage spezifischer Themen oder Motive.
KI-Ethik und Rechenschaftspflicht: CVAEs unterstützen eine verantwortungsvolle KI-Entwicklung, indem sie die Interpretierbarkeit von Modellen durch kontrollierte Datengenerierung verbessern. Sie stellen sicher, dass KI-Systeme mit ethischen Standards übereinstimmen, indem sie kontrollierbare Ergebnisse ermöglichen.
Tools
Nun werden wir einige der beliebten Tools und Frameworks untersuchen, die die Implementierung und das Training von Conditional Variational Autoencoders (CVAEs) erleichtern.
TensorFlow: Es ist ein leistungsstarkes Framework zum Entwerfen von CVAEs. Es vereinfacht die Implementierung von Encoder-Decoder-Architekturen und unterstützt die Berechnung des KL-Divergenzterms durch TensorFlow Probability. Seine GPU/TPU-Unterstützung gewährleistet effizientes Training für große Datensätze.
PyTorch: Es wird aufgrund seiner Flexibilität und seines dynamischen Berechnungsgraphen häufig verwendet, was es ideal für benutzerdefinierte CVAE-Implementierungen macht. Es ermöglicht präzise Kontrolle über die Modellkomponenten, und Bibliotheken wie Pyro fügen erweiterte probabilistische Modellierungsfunktionen für CVAE-Verlustfunktionen hinzu.
JAX und Flax: JAX bietet in Kombination mit seiner neuronalen Netzwerkbibliothek Flax effiziente Berechnungen für CVAEs. Es bietet Flexibilität bei der Anpassung von Gradientenberechnungen und unterstützt skalierbare Architekturen für komplexe CVAE-Aufgaben.
FAQS
Was unterscheidet CVAEs von Standard-VAEs? CVAEs verwenden bedingte Eingaben, um Ausgabemerkmale zu steuern. Standard-VAEs generieren Daten nur auf der Grundlage der Eingabeverteilung.
Wie beeinflusst die Konditionierung den generativen Prozess in CVAEs? Die Konditionierung leitet das Modell bei der Generierung von Daten, die bestimmten Attributen entsprechen. Sie verleiht der Ausgabe Kontrolle und Präzision.
Was sind die gängigen Anwendungen von CVAEs? CVAEs erstellen angepasste Bilder, personalisierte Texte und erweiterte Datensätze. Sie eignen sich gut für Aufgaben, die die Generierung spezifischer Merkmale erfordern.
Welche Herausforderungen können beim Training von CVAEs auftreten? Das Training erfordert beschriftete Daten und sorgfältige Abstimmung. Es kann auch Probleme mit Stabilität und Komplexität geben.
Welche Einschränkungen haben CVAEs im Vergleich zu GANs? CVAEs können weniger realistische Ausgaben erzeugen. GANs erzielen oft schärfere und detailliertere Ergebnisse, bieten jedoch nicht die gleiche Kontrolle.
- Was sind Conditional Variational Autoencoders (CVAE) ?
- Variational Autoencoders (VAEs) verstehen
- Wie verbessert CVAE VAE durch bedingte Eingaben?
- CVAEs vs. VAEs vs. GANs
- Vorteile und Herausforderungen von Variational Autoencoders (VAEs)
- Anwendungsfälle von Conditional Variational Autoencoders (CVAEs)
- Tools
- FAQS
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren