




Verwendung von SelfQueryRetriever mit LangChain zur Abfrage einer Vektordatenbank
LangChain ist bekannt dafür, Interaktionen mit großen Sprachmodellen (LLMs) zu orchestrieren. Kürzlich hat LangChain eine Möglichkeit eingeführt, Self-Querying durchzuführen, wodurch sie die „chain“ oder Module selbst mithilfe einer Benutzereingabeabfrage abfragen können. Dieser Beitrag zeigt Ihnen, wie Sie Self-Querying auf Milvus, der weltweit beliebtesten Vektordatenbank, durchführen. Durch die Interpretation einer Benutzerabfrage kann das System Suchen innerhalb von Vector Stores verfeinern und so die Abrufresultate verbessern. Den Code für dieses Beispiel finden Sie hier auf CoLab.
Lassen Sie uns Self-Querying auf Milvus mit LangChain einrichten. Dieser Prozess besteht aus vier logischen Schritten.
Richten Sie die Grundlagen von LangChain und Milvus ein.
Beschaffen oder erstellen Sie die notwendigen Daten.
Informieren Sie das Modell über das erwartete Datenformat.
Demonstrieren Sie Self-Querying und erklären Sie, wie es funktioniert.
Einführung in Self-Querying
Self-Querying ist eine leistungsstarke Technik, die in der Verarbeitung natürlicher Sprache (NLP) und im Information Retrieval verwendet wird. Sie ermöglicht es einem System, sich selbst mithilfe der Eingabeabfrage eines Benutzers abzufragen, wodurch genauere und relevantere Ergebnisse ermöglicht werden. Im Kontext von LangChain wird Self-Querying verwendet, um Informationen aus einem Vector Store abzurufen, einer Datenbank, die Vektoren speichert, die Dokumente oder Datenpunkte repräsentieren. Der Self-Query Retriever ist eine Schlüsselkomponente des LangChain-Frameworks und ermöglicht die Erstellung komplexer Abfragen und Abrufe mithilfe natürlicher Sprache.
Durch die Nutzung von Self-Querying kann LangChain die Abfrage eines Benutzers in ein strukturiertes Format zerlegen, das der Vector Store verstehen kann. Dieser Prozess stellt sicher, dass die abgerufenen Dokumente für die Anfrage des Benutzers äußerst relevant sind, wodurch es einfacher wird, die benötigten Informationen zu finden. Ob Sie ein Conversational-AI-Modell oder eine Suchmaschine entwickeln, Self-Querying kann die Genauigkeit und Relevanz Ihrer Ergebnisse erheblich verbessern.
Einrichten von LangChain und Milvus
Der erste Schritt besteht darin, die notwendigen Bibliotheken einzurichten. Sie können die erforderlichen Bibliotheken mit pip install openai langchain milvus python-dotenv installieren. Wenn Sie meinen früheren Tutorials gefolgt sind, sind Sie bereits mit python-dotenv vertraut, meiner bevorzugten Bibliothek für die Verwaltung von Umgebungsvariablen. Wir verwenden die OpenAI-Bibliothek mit LangChain, um auf GPT zuzugreifen und Milvus als unseren Vector Store zu nutzen.
Sobald Sie eine Verbindung zum OpenAI-API-Schlüssel hergestellt haben, importieren Sie die notwendigen LangChain-Module. Wir benötigen die folgenden sechs Module:
Document: Ein LangChain-Datentyp zur Datenspeicherung.OpenAIundOpenAIEmbeddings: Zwei Funktionalitäten für den Zugriff auf OpenAI und seine Embeddings.Milvus: Ein Modul für den Zugriff auf Milvus von LangChain aus.SelfQueryRetriever: Ein Retriever-Modul.AttributeInfo: Ein Modul, das unsere Datenstruktur für LangChain definiert.
Nach dem Import der Module setzen wir die Variable embeddings auf die Standardfunktion von OpenAI Embeddings. Der letzte Schritt im Einrichtungsprozess besteht darin, die Bibliothek milvus zu verwenden, um eine Instanz von Milvus Lite in unserem Notebook zu starten.
Werfen wir nun einen Blick auf die Daten.
import os
from dotenv import load_dotenv
load_dotenv()
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
from langchain.schema import Document
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Milvus
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
embeddings = OpenAIEmbeddings()
from milvus import default_server
default_server.start()
Lassen Sie uns einige Daten sammeln. Sie können Ihre Daten scrapen, die bereitgestellten Daten unverändert verwenden oder sie als Vorlage verwenden, um Ihre Daten zu erstellen. Für dieses Beispiel habe ich eine Liste von Dokumenten über Filme vorbereitet, darunter Jurassic Park, Toy Story, Finding Nemo, The Unbearable Weight of Massive Talent, Lord of War und Ghost Rider. Obwohl ich die Titel nicht in unsere Daten aufnehme, möchte ich, dass Sie wissen, auf welche Filme sie sich beziehen.
Ich speichere jeden dieser Filme als LangChain Document-Objekt. Es enthält einen page_content-Schlüssel, der einer Zeichenkette entspricht, in diesem Fall der Filmbeschreibung. Außerdem enthält es Metadaten wie Jahr, Bewertung und Filmgenre.
docs = [
# jurassic park
Document(page_content="A bunch of scientists bring back dinosaurs and mayhem breaks loose",
metadata={"year": 1993, "rating": 7.7, "genre": "action"}),
# toy story
Document(page_content="Toys come alive and have a blast doing so",
metadata={"year": 1995, "genre": "animated", "rating": 9.3 }),
# finding nemo
Document(page_content="A dad teams up with a mentally disabled partner to break into a dentist\'s office to save his son.",
metadata={"year": 2003, "genre": "animated", "rating": 8.2 }),
# unbearable weight of massive talent
Document(page_content="Nicholas Cage plays Nicholas Cage in this movie about Nicholas Cage.",
metadata={"year": 2022, "genre": "comedy", "rating": 7.0 }),
# lord of war
Document(page_content="Nicholas Cage sells guns until he has enough money to marry his favorite model. Then he sells more guns.",
metadata={"year": 2005, "genre": "comedy", "rating": 7.6 }),
# ghost rider
Document(page_content="Nicholas Cage loses his skin and sets his skull on fire. Then he rides a motorcycle.",
metadata={"year": 2007, "genre": "action", "rating": 5.3 }),
]
Definieren von Self-Query-Metadaten und Self-Query-Retriever für LangChain und Milvus
Wir haben die ersten beiden Schritte des Puzzles abgeschlossen, und jetzt ist es Zeit für den dritten.
Zuerst richten wir unsere Vektordatenbank für die Ingestion ein. Wir können die LangChain-Milvus-Implementierung verwenden, um unsere Dokumente zu ingestieren und eine Vektordatenbank auf Grundlage unserer vorhandenen Dokumente zu erstellen. In diesem Schritt kommt auch die Embedding-Funktion ins Spiel, indem die zuvor erstellte Variable embeddings verwendet wird. Die Vergleichsanweisung berücksichtigt die spezifischen Formate und Richtlinien, die erforderlich sind, um Filterbedingungen zu erstellen, welche die Datenabrufprozesse steuern.
Der Parameter connection_args ist der einzige erforderliche Parameter für die Verbindung zu Milvus. In diesem Tutorial verwende ich außerdem den Parameter collection_name, um der Collection, in der wir unsere Daten speichern, einen Namen zuzuweisen. Jede Collection in Milvus muss einen Namen haben. Standardmäßig verwendet LangChain LangChainCollection.
vector_store = Milvus.from_documents(
docs,
embedding=embeddings,
connection_args={"host": "localhost", "port": default_server.listen_port},
collection_name="movies"
)
Als Nächstes definieren wir die Metadateninformationen mithilfe der AttributeInfo-Funktionalität, damit LangChain weiß, was zu erwarten ist. Dieser Abschnitt erstellt eine Liste von Attributinformationen für die Daten. Wir geben den Namen, die Beschreibung und den Datentyp jedes Attributs an. Hier wird eine logische Bedingungsanweisung wesentlich, um Vergleiche und logische Operationen innerhalb des Query-Konstruktionsprozesses zu formulieren.
metadata_field_info = [
AttributeInfo(
name="genre",
description="The genre of the movie",
type="string",
),
AttributeInfo(
name="year",
description="The year the movie was released",
type="integer",
),
AttributeInfo(
name="rating",
description="A 1-10 rating for the movie",
type="float"
),
]
Die letzten paar Teile beschreiben das Dokument, initialisieren das LLM und definieren den Self-Query Retriever. Wir definieren den Self-Query Retriever, indem wir seine Methode ‘from_llm’ aufrufen. Wir müssen diese Methode verwenden, um das LLM, den Vektorspeicher, die Beschreibung des Dokumentinhalts und die Informationen zu den Metadatenfeldern zu verbinden. In diesem Beispiel setzen wir außerdem ‘verbose = True’, um eine ausführliche Ausgabe für diesen Self-Query Retriever zu aktivieren. Der Abfragestring sollte nur relevanten Text enthalten, der mit den Dokumentinhalten übereinstimmt, wobei sichergestellt wird, dass alle Bedingungen in den Filtern klar getrennt sind und nicht im Abfragestring selbst enthalten sind.
document_content_description = "Brief summary of a movie"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm, vector_store, document_content_description, metadata_field_info, verbose=True
)
Self-Querying-Ergebnisse
Wir haben die Einrichtung für den Self-Query Retriever abgeschlossen. Sehen wir uns nun an, wie er in Aktion funktioniert. In diesem Beispiel habe ich drei Filmbeschreibungen verwendet, die sich auf Nicholas Cage beziehen. Die Frage, die wir stellen, lautet also: Welche Filme über Nicholas Cage gibt es?
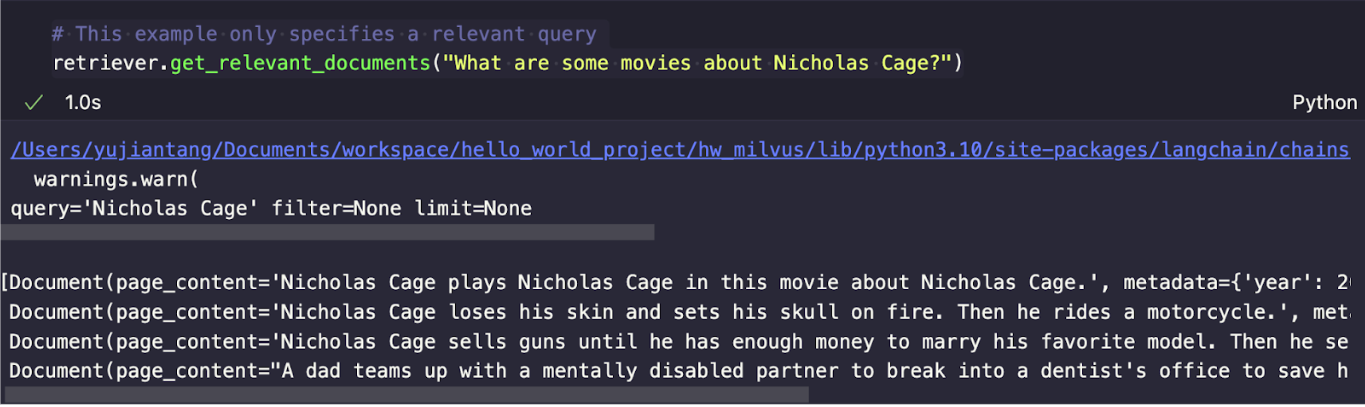
# This example only specifies a relevant query
retriever.get_relevant_documents("What are some movies about Nicholas Cage?")
Wir sollten eine Ausgabe wie die folgende erhalten.
 langchain-query-vector-database.png
langchain-query-vector-database.png
Durch das Setzen von verbose=True können wir die Abfrage, den Filter und das Limit anzeigen. Das LLM wandelt unsere Abfrage von „What are some movies about Nicholas Cage?“ in „Nicholas Cage“ um. Wenn wir uns die Ergebnisse ansehen, können wir feststellen, dass die ersten drei Ergebnisse allesamt Filme mit Nicholas Cage sind. Das vierte Ergebnis, Findet Nemo, ist jedoch irrelevant, weil der Parameter so gesetzt ist, dass vier Ergebnisse abgerufen werden.
Hoffentlich hat die Code-Durchführung das Konzept des Self-Querying auf einer Vektordatenbank verdeutlicht. Auf der LangChain-Website beschreibt LangChain Self-Querying als eine Methode, mit der ein LLM sich selbst mithilfe des zugrunde liegenden Vektorspeichers abfragt. Mit anderen Worten: LangChain entwickelt eine einfache Retrieval-Augmented-Generation-(RAG)-App im CVP-Framework, die eine Self-Querying-Funktion enthält.
In diesem Tutorial haben wir die Self-Query-Funktion von LangChain mit Milvus als zugrunde liegendem Vektorspeicher erkundet. Self-Querying ermöglicht es Ihnen, eine einfache RAG-App zu erstellen, indem Sie ein LLM und eine Vektordatenbank kombinieren. Das LLM zerlegt die Abfrage in natürlicher Sprache in einen String, der anschließend für die Abfrage vektorisiert wird.
In unserem Beispiel haben wir einige Beispieldaten zu Filmen generiert. Eine Möglichkeit, dieses Beispiel zu erweitern, besteht darin, Ihre eigenen Daten zu sammeln. Wenn Sie den Self-Query Retriever definieren, denken Sie daran, die Beschreibungen sowohl für den Vektorspeicher als auch für die Metadaten bereitzustellen.
Um loszulegen und mit der Self-Query-Funktion von LangChain zu experimentieren, sehen Sie sich das Colab-Notebook an.
Abfragen des Vektorspeichers mit logischen Operationsanweisungen
Beim Abfragen des Vektorspeichers werden logische Operationsanweisungen verwendet, um Bedingungen zum Filtern von Dokumenten festzulegen. Eine logische Operationsanweisung hat die Form op(statement1, statement2, …), wobei op ein logischer Operator wie AND, OR oder NOT ist. Jede Anweisung kann eine Vergleichsanweisung sein, die die Form comp(attr, val) hat, wobei comp ein Komparator wie EQ, LT oder GT ist und attr und val das Attribut bzw. der Wert sind, die verglichen werden.
Zum Beispiel könnte eine logische Operationsanweisung so aussehen: AND(EQ(language, “English”), GT(rating, 4)). Diese Anweisung würde Dokumente filtern, deren Sprachattribut gleich „English“ ist und deren Bewertungsattribut größer als 4 ist. Durch die Verwendung logischer Operationsanweisungen können Sie komplexe Abfragen erstellen, die mehrere Bedingungen kombinieren und so eine präzisere Filterung von Dokumenten im Vektorspeicher ermöglichen.
Umgang mit der Abfrage des Benutzers
Wenn ein Benutzer eine Abfrage eingibt, verwendet der Self-Query Retriever einen Query Constructor, um eine strukturierte Abfrage zu generieren. Die strukturierte Abfrage wird anschließend in Vector-Store-Abfragen übersetzt, die im Vector Store ausgeführt werden, um relevante Dokumente abzurufen. Der Query Constructor verwendet einen Prompt und einen Output Parser, um die strukturierte Abfrage zu generieren, die die vom Benutzer angegebenen Filter erfasst.
Wenn ein Benutzer beispielsweise die Abfrage „Find movies with a rating greater than 4 and a runtime less than 2 hours“ eingibt, könnte der Query Constructor eine strukturierte Abfrage wie diese generieren: AND(GT(rating, 4), LT(runtime, 120)). Diese strukturierte Abfrage würde anschließend in Vector-Store-Abfragen übersetzt und im Vector Store ausgeführt, um relevante Dokumente abzurufen. Indem die Anfrage des Benutzers auf diese Weise verarbeitet wird, stellt der Self-Query Retriever sicher, dass die Ergebnisse auf die spezifischen Anforderungen des Benutzers zugeschnitten sind.
Best Practices und Fazit
Bei der Verwendung des Self-Query Retrievers ist es wichtig, Best Practices zu befolgen, um genaue und relevante Ergebnisse sicherzustellen. Hier sind einige Tipps:
Verwenden Sie bei der Eingabe von Abfragen eine spezifische und prägnante Sprache.
Verwenden Sie logische Operationsanweisungen, um Bedingungen für das Filtern von Dokumenten festzulegen.
Verwenden Sie Vergleichsanweisungen, um Attribute und Werte zu vergleichen.
Verwenden Sie den EQ-Komparator, um exakte Übereinstimmungen festzulegen.
Verwenden Sie die LT- und GT-Komparatoren, um Bereichsabfragen festzulegen.
Verwenden Sie die logischen Operatoren AND und OR, um Bedingungen zu kombinieren.
Zusammenfassend ist der Self-Query Retriever ein leistungsstarkes Tool zum Erstellen konversationeller KI-Modelle, die Informationen aus verschiedenen Quellen abrufen und verarbeiten können. Durch die Verwendung logischer Operationsanweisungen und Vergleichsanweisungen können Benutzer komplexe Abfragen festlegen und relevante Dokumente aus einem Vector Store abrufen. Durch die Befolgung von Best Practices und die effektive Nutzung des Self-Query Retrievers können Entwickler genauere und relevantere KI-Modelle erstellen, die eine breite Palette von Benutzeranfragen verarbeiten können.

Weiterlesen

Stop Building AI Data Infra for the Wrong Stage
Learn how AI data infrastructure should evolve from prototype to enterprise scale, and when Vector Lakebase becomes the right architecture for AI apps.

VDBBench Adds Cost-Aware Benchmarking for Vector Databases
Compare Zilliz Cloud, Pinecone, and turbopuffer with VDBBench cost-aware vector database benchmarks across latency, freshness, multitenancy, and cold starts.

Introducing Zilliz Cloud Global Cluster: Region-Level Resilience for Mission-Critical AI
Zilliz Cloud Global Cluster delivers multi-region resilience, automatic failover, and fast global AI search with built-in security and compliance.