




VDBBench fügt kostenbewusstes Benchmarking für Vektordatenbanken hinzu
Letztes Jahr haben wir VectorDBBench 1.0 veröffentlicht, um das Benchmarking von Vektordatenbanken näher an Produktions-Workloads heranzuführen. Anstatt nur Spitzen-QPS mit festen Benchmark-Daten zu testen, ermöglicht VectorDBBench (auch bekannt als VDBBench) Teams die Bewertung von Vektordatenbanken anhand von Workload-Mustern, die ihre eigenen Produktionssysteme genauer widerspiegeln: Ingestion, Filtering, Recall, Latenz, Parallelität und benutzerdefinierte Datasets.
Die neueste Version von VDBBench fügt eine neue Dimension hinzu: Kosten.
Produktionsteams wählen eine Vektordatenbank selten allein nach Performance aus. Sie müssen wissen, was es kostet, eine Ziel-QPS zu erreichen, wie sich P99 unter diesem Kostenmodell verhält, wann eingefügte Daten durchsuchbar werden, wann sie vollständig indexiert sind, wie sich die Payload-Größe auf die Suche auswirkt, wie sich das System über viele Tenants hinweg verhält und was bei der ersten Abfrage nach Inaktivität passiert. Diese Fragen sind jetzt Teil von VDBBench.
Um zu zeigen, wie diese neuen kostenbewussten Benchmarks in der Praxis funktionieren, haben wir drei häufig evaluierte verwaltete Vektordatenbank-Produkte getestet: Zilliz Cloud, Turbopuffer und Pinecone. Die Ergebnisse werden im neuen VDBBench Cost Leaderboard, veröffentlicht, mit Diagrammen und Tabellen, die Insert-Bereitschaft, Payload-Suche, mandantenfähige Suche, Cold Latency sowie Kosten-Performance-Kompromisse vergleichen.
Das Leaderboard ist nur eine Möglichkeit, die Ergebnisse zu lesen — es ist eine Momentaufnahme von drei Produkten zu einem bestimmten Zeitpunkt. Da VDBBench Open Source ist, können Teams diese Cases auch reproduzieren, Produkte benchmarken, die nicht auf dem Leaderboard stehen, oder die Workloads an ihre eigenen produktionsähnlichen Daten anpassen.
Das Ziel ist nicht, einen universellen Sieger zu küren, sondern Teams dabei zu helfen, die Vektordatenbank auszuwählen, die am besten zu ihrem Workload, ihren Performance-Zielen und ihrem Budget passt.
- Referenzen: VectorDBBench GitHub | VDBBench Leaderboards
Was ist neu in VDBBench
Diese Version fügt vier cloudorientierte Benchmark-Cases hinzu, die Produktionsverhalten messen, das Peak-QPS-Leaderboards oft übersehen.
| Case | Was es misst | Warum es wichtig ist |
|---|---|---|
| CloudInsertCase | Abschluss des Inserts, durchsuchbarer Zustand, vollständig indexierter Zustand und Schreibkosten | Aktualität und Backfill-Kosten sind für RAG, Kataloge und Agent Memory wichtig |
| CloudPayloadSearchCase | QPS, P99-Latenz, Recall und Form des Response-Payloads | Das Zurückgeben von Vektoren oder Metadaten kann die Kostenoberfläche der Suche verändern |
| MultitenantSearchCase | Durchsatz über viele Tenants oder Namespaces hinweg | SaaS-Workloads belasten Routing- und Partitionsverhalten anders als Single-Tenant-Suche |
| CloudColdLatencyCase | Erste Abfrage nach Inaktivität vs. aufgewärmter Abfragepfad | Cold-Start-Verhalten ist für Low-Frequency-Tenants und Agent Memory wichtig |
Zusätzlich zu diesen Cases fügt das Cost Leaderboard eine Kosten-Pareto-Ansicht hinzu, die Betriebskosten bei Ziel-QPS-Niveaus unter den gemessenen Serving-Grenzen jedes Produkts modelliert — denn Kaufentscheidungen hängen in der Regel davon ab, wo sich Performance und Kosten überschneiden.
Das VDBBench Cost Leaderboard verwendet diese Cases, um verwaltete Produkte öffentlich zu vergleichen. Da die Cases in Open-Source-VDBBench enthalten sind, können Teams sie für ihre eigene Evaluation wiederverwenden, einschließlich Produkten und Workloads, die nicht auf dem Leaderboard gezeigt werden.
Wen wir getestet haben: Zilliz Cloud vs. Turbopuffer vs. Pinecone
Für diesen ersten kostenbewussten Durchlauf haben wir drei häufig evaluierte verwaltete Vektordatenbank-Produkte getestet. Alle Produkte wurden am 10. Mai 2026 in AWS US West (us-west-2) benchmarked. Ihre Betriebsmodelle unterscheiden sich, daher sollten die Ergebnisse im Hinblick auf die Workload-Passung und nicht als einzelnes Ranking interpretiert werden.
| Produkt | Rolle in diesem Benchmark |
|---|---|
| Zilliz Cloud | Verwaltete Cloud-Vektordatenbank und Vector Lakebase von den Entwicklern von Milvus, getestet über die Tiered- und Capacity-Konfigurationen hinweg |
| Turbopuffer | Serverless-Vektordatenbank, getestet in ungepinnten und gepinnten Modi |
| Pinecone Serverless | Ausgereifte, wartungsarme Serverless-Vektordatenbank, die als gängiger Produktionsreferenzpunkt verwendet wird |
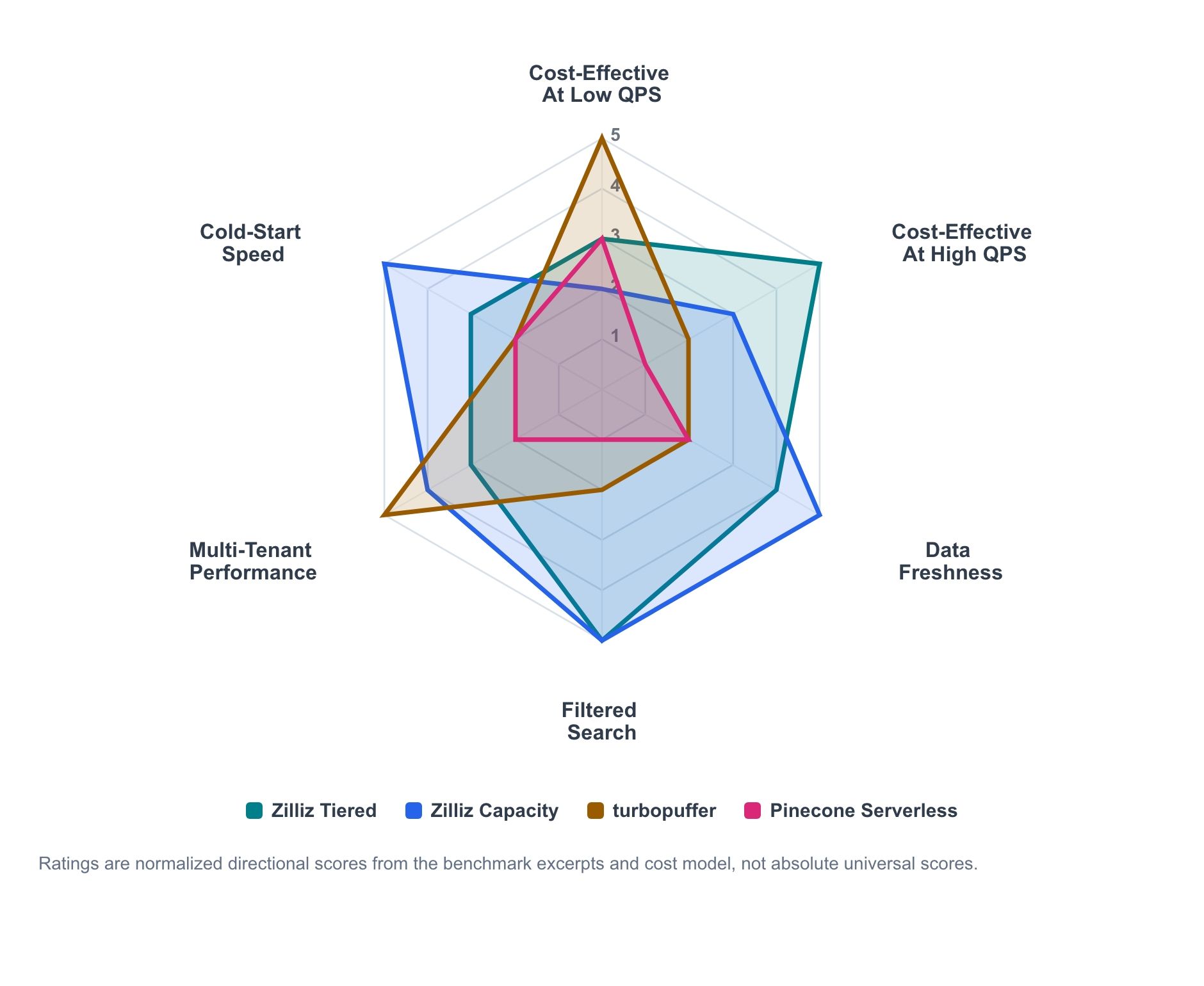
Abbildung 1. Direktionale Zusammenfassung der Workload-Eignung basierend auf Benchmark-Auszügen und Kostenmodellierung. Bewertungen sind für den Vergleich über Workload-Dimensionen hinweg normalisiert und sollten nicht als universelle absolute Ranglisten gelesen werden.
Das Radardiagramm fasst das direktionale Signal aus den Benchmark-Auszügen und dem Kostenmodell zusammen. Es ist keine absolute Scorecard; es ist eine Karte dafür, wo jedes Produkt tendenziell am stärksten ist.
- Zilliz Cloud Tiered ist die wirtschaftliche Active-Serving-Linie, die mit steigender Auslastung skaliert.
- Zilliz Cloud Capacity ist das Profil mit höherer Kontrolle für vorhersehbares Serving, Aktualität und Kaltverhalten.
- Turbopuffer ist dort am stärksten, wo nutzungsbasierte Serverless-Ökonomie und namespace-orientierter Durchsatz zur Workload passen.
- Pinecone bleibt eine nützliche wartungsarme Serverless-Baseline, auch wenn es in einem bestimmten Test nicht an der Kosten-Performance-Spitze liegt.
Das Hauptmuster ist klar. Serverless-Ökonomie kann bei niedrigen anhaltenden QPS attraktiv sein. Bereitgestellte Kapazität wird mit steigender Auslastung wettbewerbsfähiger. Aktualität, gefilterte Suche, Payload-Größe, Mandantenanzahl und Kaltverhalten können die Entscheidung alle beeinflussen.
Datensätze und Workloads
Die kostenbewussten Fälle verwenden zwei Workload-Formen.
- Single-Tenant LAION 100M: 100 Millionen 768-dimensionale dichte Vektoren. Dies repräsentiert eine große Produktionssammlung, bei der Payload-Größe, Filter, Recall und anhaltende QPS wichtig sind.
- Multitenant Cohere 10M: 10 Millionen 768-dimensionale dichte Vektoren, zufällig auf 1.000 Mandanten aufgeteilt — ungefähr 10K Vektoren pro Mandant. Dies repräsentiert SaaS-artige Workloads, bei denen jeder Mandant einen kleineren Datensatz hat, das System jedoch viele Namespaces oder Mandantenpartitionen effizient weiterleiten und bedienen muss.
Die folgenden Auszüge zeigen die Form der Ergebnisse. Das Cost Leaderboard und das VectorDBBench-Repository bleiben die Quelle für die vollständigen Matrizen, Client-Definitionen und Reproduktionsdetails.
CloudInsertCase: Eingefügt ist nicht immer bereit
Einfügeleistung ist keine einzelne Zahl. Eine verwaltete Vektordatenbank kann Daten vom Client akzeptieren, bevor diese Daten sicher über den vorgesehenen Indexpfad durchsucht werden können. Für Produktions-Workloads müssen Teams wissen, wann der Einfügevorgang abgeschlossen ist, wann die Daten durchsuchbar werden und wann die Hintergrundindizierung vollständig aufgeholt hat.
CloudInsertCase misst den Write-to-Serve-Lebenszyklus. Dies ist wichtig für RAG-Korpus-Aktualisierungen, Produktkatalog-Updates, Agent-Memory-Schreibvorgänge und Daten-Backfills. In diesen Systemen reicht "insert accepted" nicht aus. Die operative Frage ist, wann neu geschriebene Daten zuverlässig mit Produktionsleistung durchsucht werden können.
| Produkt / Modus | Batch-Größe | Einfügezeit | Wartezeit bis durchsuchbar | Wartezeit bis vollständig indiziert | Schreibkosten |
|---|---|---|---|---|---|
| Zilliz Cloud Capacity 12CU | 10,000 | 3.2 hr | 0 ms | 1.9 min | $9.50 |
| Zilliz Cloud Tiered 4CU | 10,000 | 4.1 hr | 0 ms | 10.9 min | $6.34 |
| Turbopuffer (Backpressure aus) | 10,000 | 1.8 hr | 6.4 hr | 2.0 min | $302 |
| Pinecone Serverless | 10,000 | 72.4 hr | 0 ms | 127 ms | $1,180 |
Tabelle 1. LAION 100M Batch-10k-Einfügeauszug. Kosten und Zeiten stammen aus dem aktuellen Leaderboard-Lauf. Für die bereitgestellten Zilliz-Konfigurationen sind die Schreibkosten die CU-Stunden-Kosten, die während des Lade- und Indexfensters verbraucht werden; für Turbopuffer und Pinecone handelt es sich um die gemessene Schreibgebühr. Lesen Sie die Zeitangaben zusammen mit den Client-Definitionen für die Zustände eingefügt, durchsuchbar und vollständig indiziert (pro Client in der VDBBench-Quelle definiert).
Die Batchgröße verändert die Zahlen für verschiedene Produkte.
- Turbopuffer zeigt eine starke rohe Aufnahmeleistung bei großen Batches, insbesondere bei deaktiviertem Backpressure — seinem aggressivsten Aufnahmemodus. Im Batch-10k-Pfad schließt es die Einfügung schnell ab, aber die Wartezeit bis zur Durchsuchbarkeit dominiert das gesamte Bereitschaftsfenster.
- Zilliz Cloud ist über Batchgrößen hinweg stabiler. In den getesteten Capacity- und Tiered-Konfigurationen werden Daten unmittelbar nach Abschluss der Einfügung durchsuchbar, und die verbleibende Wartezeit bis zur vollständigen Indizierung wird in Minuten gemessen.
- Pinecone Serverless ist in diesem Test die langsamere Bulk-Intake-Baseline. Sobald Daten akzeptiert wurden, ist die zusätzliche Wartezeit bis zur Durchsuchbarkeit und vollständigen Indizierung in diesen Läufen praktisch null, aber die Einfügephase selbst dauert deutlich länger.
Die Produkteinschätzung ist vom Workload geprägt.
- Zilliz eignet sich für Workflows, bei denen frische Daten schnell durchsuchbar und zu vorhersehbaren Kosten indiziert sein müssen.
- Turbopuffer eignet sich für große akzeptierte Backfills, wenn der Workload ein längeres Bereitschaftsfenster tolerieren kann.
- Pinecone eignet sich für Serverless-Ingestion-Muster mit geringerem Volumen, bei denen betriebliche Einfachheit wichtiger ist als Bulk-Load-Geschwindigkeit oder Kosten.
Bulk Loading ist auch ein Kostenereignis. In diesem LAION-100M-Einfügefall halten die Zilliz-Konfigurationen die schreibseitigen Kosten im einstelligen Dollarbereich für den getesteten Batch-10k-Pfad. Turbopuffer wird mit rund $302 modelliert. Pinecone Serverless wird mit rund $1,180 modelliert. Das macht kein Preismodell universell besser. Es bedeutet, dass die Einfügeökonomie davon abhängt, wie oft der Workload diesen Pfad ausführt.
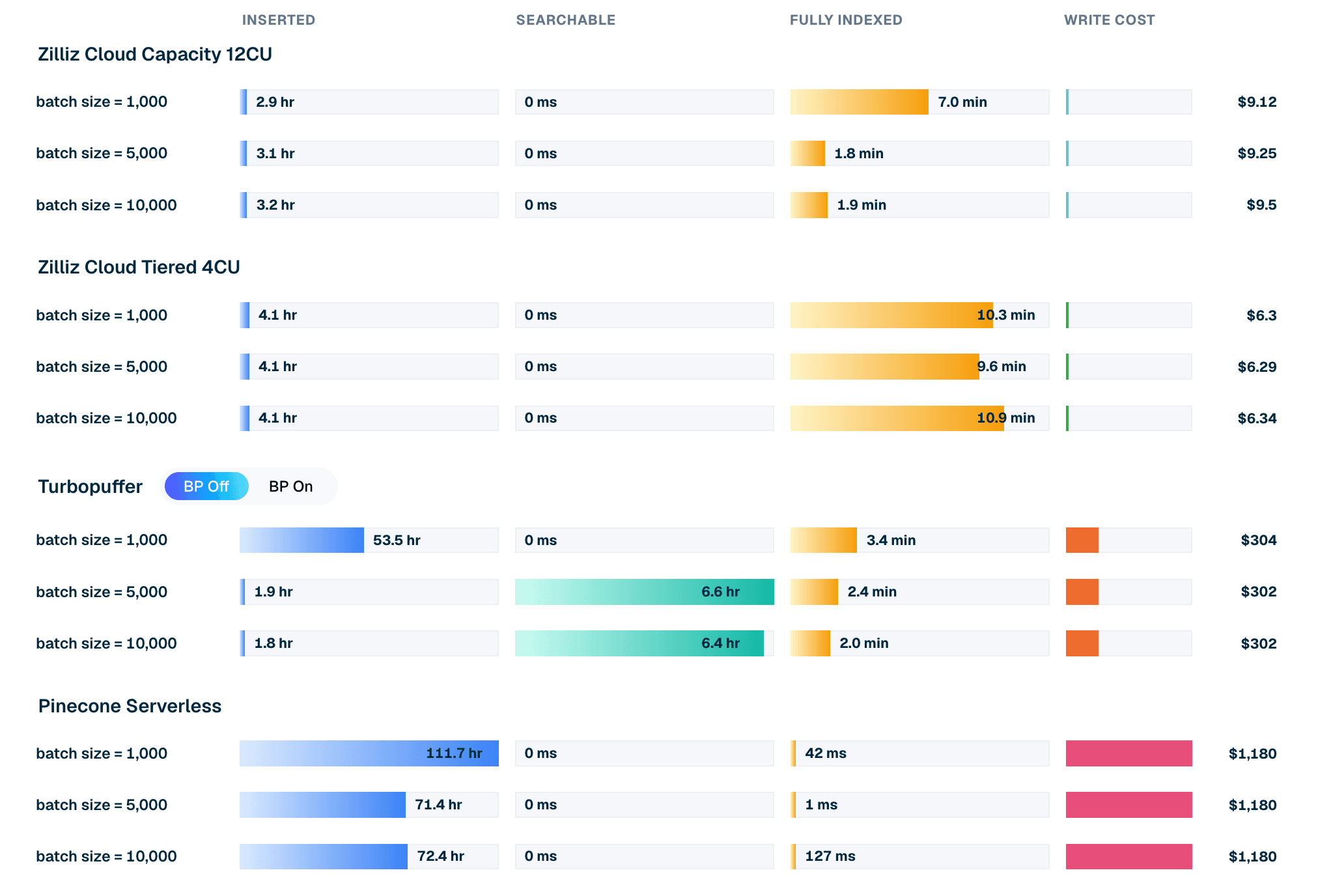
Abbildung 2. Einfüge-Lebenszyklus für LAION 100M bei Batch 10k: Einfügezeit, Wartezeit bis zur Durchsuchbarkeit, Wartezeit bis zur vollständigen Indizierung und modellierte Schreibkosten pro Produkt.
CloudPayloadSearchCase: Payload verändert die Suchoberfläche
Sobald Daten durchsuchbar sind, lautet die nächste Frage nicht nur, wie viele Abfragen pro Sekunde die Datenbank verarbeiten kann. Die Antwortform ist wichtig. Nur IDs zurückzugeben ist etwas ganz anderes als Metadaten oder Rohvektoren zurückzugeben. Ein 768-dimensionaler Vektor kann jedem Ergebnis Tausende von Bytes hinzufügen. Bei topK=100 kann die Payload-Größe zu einem wichtigen Faktor für Abfragekosten und Latenz werden.
CloudPayloadSearchCase testet Single-Tenant LAION 100M unter verschiedenen Antwort-Payloads und Filterformen. Die Auswertung kombiniert maximale gleichzeitige QPS, P99-Latenz bei dieser Parallelität, Payload-Typ und Recall, sofern verfügbar.
Ein Hinweis zum Lesen der Tabellen: P99 wird hier bei maximaler Parallelität gemessen — dem Sättigungspunkt, der die Peak-QPS jedes Produkts erzeugt — nicht an einem komfortablen Service-Level-Betriebspunkt. Es zeigt, wie sich eine Konfiguration an ihrer gemessenen Grenze verhält.
| Produkt | P99-Latenz @ maximale Parallelität | Max. QPS | recall@10 |
|---|---|---|---|
| Zilliz Cloud Capacity 32CU | 158 ms | 786.1 | 0.9728 |
| turbopuffer | 2.34 s | 395.7 | 0.9321 |
| Zilliz Cloud Capacity 12CU | 299 ms | 376.0 | 0.9723 |
| Turbopuffer pinned | 3.30 s | 68.2 | 0.9321 |
| Zilliz Cloud Tiered 4CU | 5.57 s | 49.2 | 0.9510 |
| Pinecone Serverless | 4.85 s | 4.6 | 0.9609 |
Tabelle 2. Single-Tenant LAION 100M, ungefiltert, nur IDs, topK 100. Hinweis zu Pinecone: Der Durchsatz in diesem Single-Tenant-Fall wird durch serverseitiges Read-Unit-Throttling begrenzt, sodass der Lauf bei Parallelität 4–5 endet, gegenüber 80 bei den anderen Produkten. Lesen Sie seine Zeilen als getaktete Serverless-Baseline statt als Sättigungsergebnis.
Konfiguration ist wichtig. Bei 12CU liegen Zilliz Capacity und Turbopuffer in diesem breiten IDs-only-Fall bei der rohen QPS nahe beieinander, während Zilliz bei Recall und P99-Latenz vorn liegt. Bei 32CU übertrifft Zilliz Capacity das getestete Turbopuffer-Ergebnis für diesen Single-Tenant-Workload.
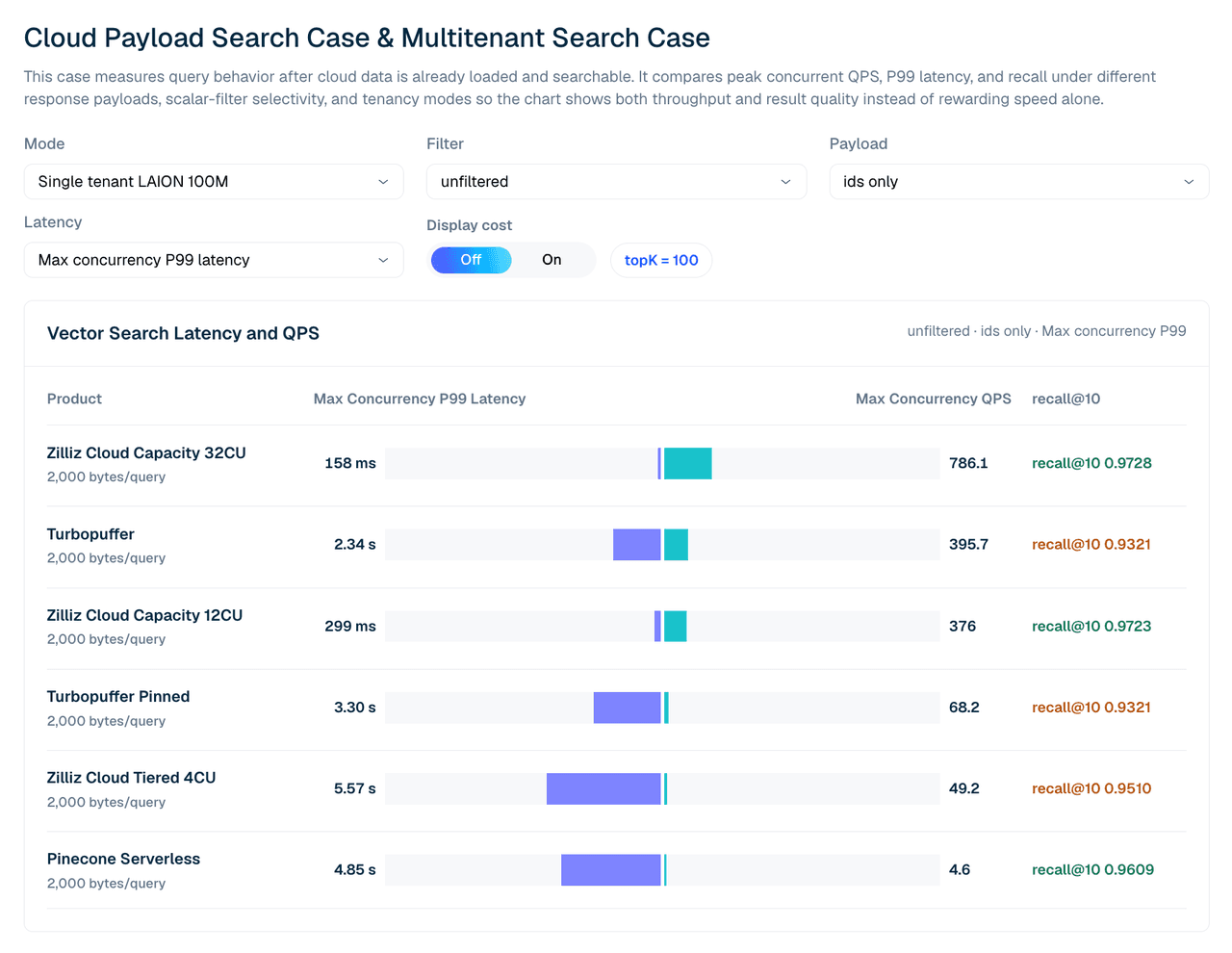
Abbildung 3. Single-Tenant LAION 100M-Suche mit IDs-only-Antworten. Diese Ansicht vergleicht maximale gleichzeitige QPS, P99-Latenz und recall@10 über die getesteten verwalteten Konfigurationen hinweg.
Die Frage ist nicht nur, welches Produkt in einer Konfiguration am schnellsten ist. Es geht darum, wie sich die Performance verändert, wenn ein Team mehr Kapazität kauft, die Payload-Form ändert oder ein Recall-Ziel benötigt. Wenn die Abfrage rohe Vektor-Payloads zurückgibt, kann sich der Durchsatz deutlich ändern.
| Produkt | Nur-IDs-QPS | Vektor-Payload-QPS | Recall |
|---|---|---|---|
| Zilliz Cloud Tiered 4CU | 49.2 | 44.0 | 0.9510 |
| Zilliz Cloud Capacity 12CU | 376.0 | 229.4 | 0.9723 |
| Zilliz Cloud Capacity 32CU | 786.1 | 531.4 | 0.9728 |
| turbopuffer | 395.7 | 382.2 | 0.9321 |
| Pinecone Serverless | 4.6 | 4.5 | 0.9609 |
Tabelle 3. Payload-Auszug für breite, ungefilterte Abfrage. Teams sollten die Payload-Form benchmarken, die ihre Anwendung tatsächlich zurückgibt, nicht nur die Nur-IDs-Suche.
Gefilterte Suche: Wo Selektivität wichtig ist
Viele produktive Vektorsuch-Workloads sind berechtigungsbasiert oder gefiltert. Ein Support-Copilot durchsucht möglicherweise nur Dokumente, die der Benutzer sehen darf. Ein Empfehlungssystem filtert möglicherweise nach Region, Kategorie, Verkäufer oder Verfügbarkeit. Eine Enterprise-Search-App wendet möglicherweise Mandanten-, Zugriffskontroll-, Aktualitäts- und Dokumenttyp-Einschränkungen an, bevor Ergebnisse gerankt werden.
Diese Filter sind nicht kosmetisch. Sie verändern den Ausführungspfad. Beim 99,9-%-Integer-Filter-plus-Vektor-Payload-Stresspunkt ändert sich das Produktverhalten stark.
| Produkt | Max. QPS | Recall | P99-Latenz |
|---|---|---|---|
| Zilliz Cloud Tiered 4CU | 955.7 | 0.9423 | 0.16 s |
| Zilliz Cloud Capacity 12CU | 933.0 | 0.9781 | 0.12 s |
| turbopuffer | 45.1 | 0.9436 | 7.03 s |
| Pinecone Serverless | 4.8 | —* | 3.30 s |
Tabelle 4. Selektiver Single-Tenant-Filter-Stresspunkt: 99,9-%-Integer-Filter mit Vektor-Payload. Der Recall für den Pinecone Serverless-Lauf an diesem Stresspunkt war zum Veröffentlichungszeitpunkt noch nicht verfügbar; QPS und Latenz stammen aus dem gemessenen Lauf.
Dies ist eines der klarsten Beispiele dafür, warum kostenbewusste Evaluation mehrere Workload-Formen benötigt. Ein Produkt, das bei breiter, ungefilterter Abfrage gut abschneidet, ist möglicherweise nicht die beste Wahl für selektive gefilterte Suche. Für berechtigungsbasierte Suche, zugriffskontrolllastiges RAG oder Workloads mit hoher Filterselektivität können die gefilterten Zeilen wichtiger sein als die ungefilterten Zeilen.
MultitenantSearchCase: Viele kleine Mandanten verhalten sich anders
Single-Tenant-Benchmarks erfassen nicht jeden Cloud-Workload.
Viele KI-Anwendungen sind SaaS-artig. Ein Produkt kann Tausende von Mandanten bedienen, jeweils mit einem kleineren Datensatz. Die operative Herausforderung ist nicht nur die Vektorsuche innerhalb einer einzigen großen Collection. Es geht um Routing, Isolation, Namespace-Verwaltung und die Aufrechterhaltung des Durchsatzes über viele kleine Partitionen hinweg.
Der Multitenant-Fall verwendet den Cohere-10M-Datensatz, aufgeteilt auf 1.000 Mandanten. Die Abfrageform verwendet topK 50 und vergleicht Nur-IDs-, Vektor-Payload- und gefilterte Zeilen.
Zwei Konfigurationshinweise prägen die Interpretation dieser Tabelle.
Erstens sind die Zilliz-Konfigurationen hier absichtlich klein — Tiered 1CU und Capacity 2CU, gerade genug, um den Cohere-10M-Datensatz zu halten. Der obige Single-Tenant-Fall zeigt bereits, dass Zilliz-QPS mit der CU-Anzahl skaliert; die Frage, die dieser Fall stellt, ist Kosteneffizienz bei einer auf die Daten zugeschnittenen Konfiguration, nicht Spitzendurchsatz.
Zweitens ist die Pinecone-Spalte ein separater Lauf mit niedriger Nebenläufigkeit (Nebenläufigkeit 4), nicht normalisiert gegen die Zeilen mit höherer Nebenläufigkeit, daher sollte sie als Kontext und nicht als direkter Vergleich betrachtet werden.
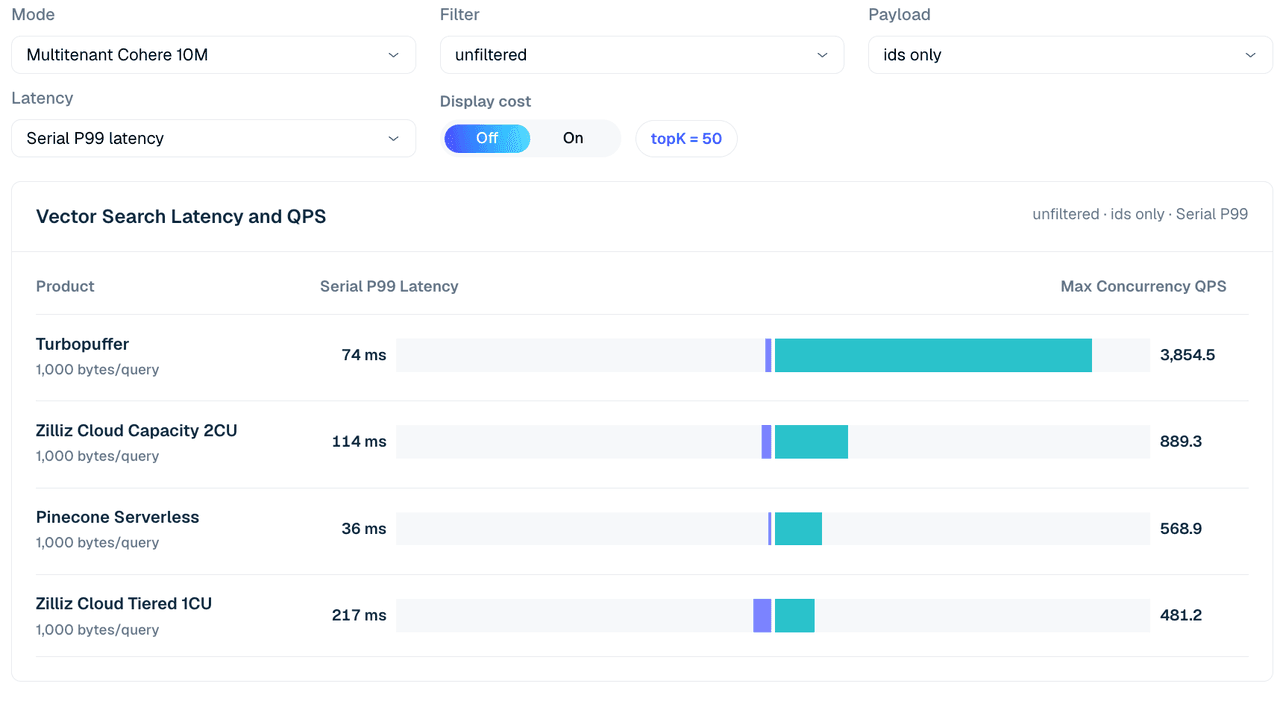
Abbildung 4. Multitenant-Cohere-10M-Suche über 1.000 Mandanten, ungefiltert, nur IDs, topK 50. Die Ansicht vergleicht serielle P99-Latenz und maximale gleichzeitige QPS über die getesteten Konfigurationen hinweg; die Tabelle darunter ergänzt Payload- und Filtervarianten.
| Fall | Zilliz Tiered 1CU | Zilliz Capacity 2CU | turbopuffer | Pinecone (c4 run) |
|---|---|---|---|---|
| Ungefiltert, nur IDs | 481 | 889 | 3,855 | 569 |
| Ungefiltert, Vektor | 34 | 371 | 1,775 | 542 |
| Integer-Filter 99,9 %, Vektor | 625 | 1,307 | 3,835 | 526 |
| Skalares Label 1 %, Vektor | 152 | 588 | 1,767 | 600 |
| Skalares Label 50 %, Vektor | 29 | 317 | 1,760 | 562 |
Tabelle 5. Auszug zur mandantenfähigen Suche über 1.000 Tenants, topK 50.
In diesem Modus ist Turbopuffer durchweg stark. Es erreicht 3,855 QPS bei einer ungefilterten Suche nur nach IDs und 3,835 QPS in der selektiven Integer-Filter/Vektor-Zeile. Zilliz Cloud Capacity 2CU bleibt in diesem Auszug das stärkere Zilliz-Profil und erreicht 889 QPS bei ungefilterten, reinen ID-Abfragen und 1,307 QPS in der 99,9%-Integer-Filter/Vektor-Zeile.
Die Produkteinschätzung ist erneut workload-abhängig. Turbopuffer eignet sich gut für viele leichtgewichtige Tenants und namespace-orientierten Durchsatz. Zilliz ist stärker, wenn Workloads gefiltert, berechtigt, recall-sensitiv oder pro Tenant schwerer sind, insbesondere wenn Teams eine Zilliz-Capacity-Konfiguration wählen können, die zum Serving-Ziel passt.
CloudColdLatencyCase: Die erste Abfrage nach Leerlauf
Warme Benchmark-Schleifen können Kaltverhalten verdecken. Für viele produktive KI-Anwendungen, insbesondere Agent Memory, Long-Tail-RAG und selten genutzte Tenant-Workloads, zählt die erste Abfrage nach Leerlauf. Ein System kann nach dem Warmup schnell wirken, aber Sekunden an Latenz hinzufügen, wenn erneut auf eine kalte Collection, einen Namespace oder einen Cache-Pfad zugegriffen wird.
CloudColdLatencyCase isoliert dieses Verhalten. Er misst die erste Abfrage gegen eine Collection, die mindestens 24 Stunden lang inaktiv war — lange genug, damit Caches und Serving-Pfade so kalt werden, wie sie realistischerweise werden — und vergleicht sie mit der ersten Abfrage auf dem aufgewärmten Pfad aus demselben Lauf.
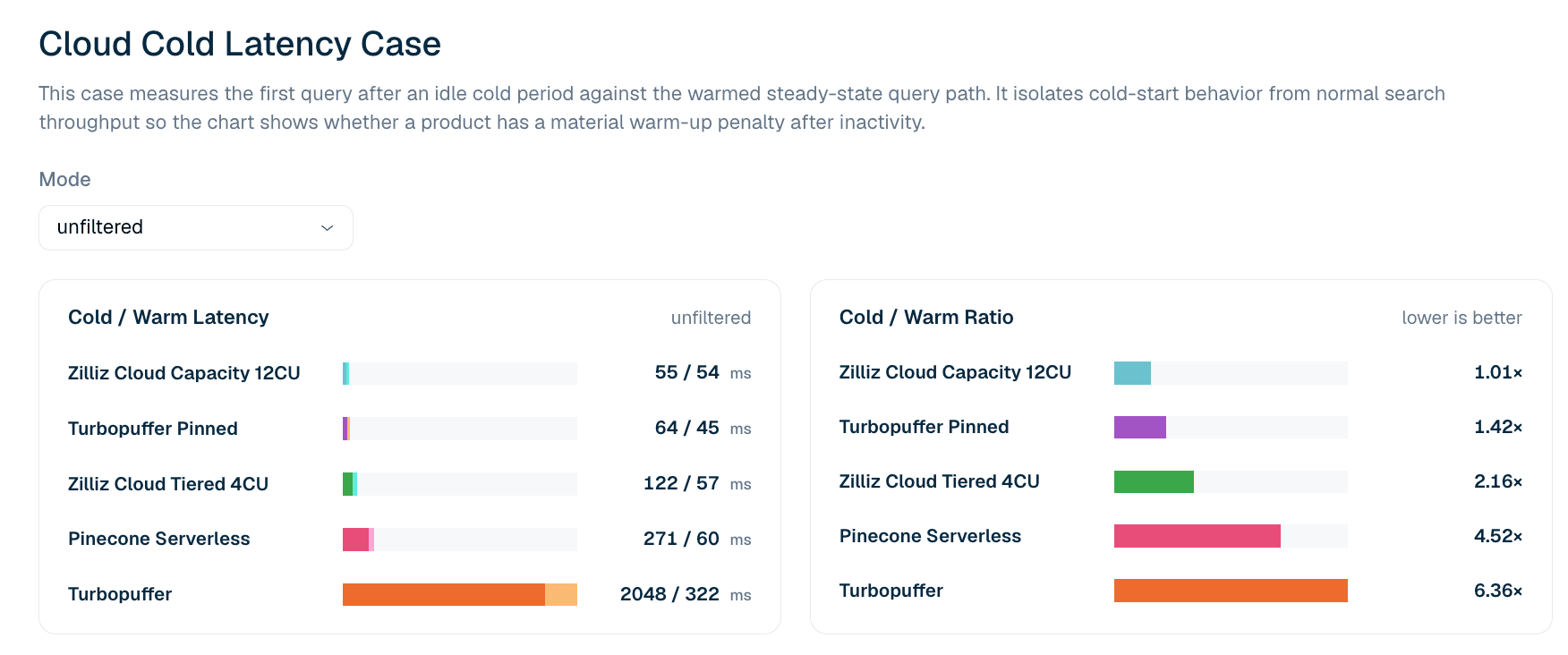
Abbildung 5. Latenz der ersten Abfrage nach Leerlauf vs. der aufgewärmte Abfragepfad für ungefilterte LAION-100M-Suche. Das Kalt/Warm-Verhältnis zeigt, ob ein Produkt nach Leerlauf eine relevante First-Query-Strafe hat.
| Produkt | Erste Abfrage nach Leerlauf | Erste warme Abfrage | Kalt/Warm-Verhältnis |
|---|---|---|---|
| Zilliz Cloud Capacity 12CU | 55 ms | 54 ms | 1.01x |
| Turbopuffer pinned | 64 ms | 45 ms | 1.42x |
| Zilliz Cloud Tiered 4CU | 122 ms | 57 ms | 2.16x |
| Pinecone Serverless | 271 ms | 60 ms | 4.52x |
| turbopuffer | 2,048 ms | 322 ms | 6.36x |
Tabelle 6. Auszug zur Kalt- und Warm-Latenz der ersten Abfrage für ungefiltertes LAION 100M. Der Fall berichtet die Latenz der ersten Abfrage statt Tail-Perzentilen: Kalt/Warm-Verhältnisse bei P99 greifen tendenziell Netzwerkrauschen in späteren Abfragen auf, das sich nicht zuverlässig reproduzieren lässt, daher verwendet das Leaderboard die strengere Definition der ersten Abfrage.
Im aktuellen ungefilterten Kaltlatenzfall zeigt Zilliz Cloud Capacity 12CU das engste Kalt-zu-Warm-Profil: 55 ms kalt und 54 ms warm, also ein Verhältnis von 1.01x. Turbopuffer pinned hat ebenfalls ein starkes Profil mit 64 ms kalt und 45 ms warm. Unpinned Turbopuffer zeigt eine größere Kaltstrafe: 2,048 ms kalt und 322 ms warm, also ein Verhältnis von 6.36x.
Kaltlatenz sollte immer zusammen mit Kosten betrachtet werden. Pinned Replicas und provisionierte Kapazität können First-Touch-Strafen reduzieren, verändern aber das wirtschaftliche Modell. Ein Produkt kann ausgezeichnetes Kaltverhalten zeigen, weil es mehr Wärme vorhält. Das kann für interaktive Anwendungen der richtige Tradeoff sein, sollte aber nicht von den Kosten getrennt werden, diesen Pfad aufrechtzuerhalten.
Kosten-Pareto-Linien: Wo Preismodelle sich überschneiden
Ein Preisblatt reicht nicht aus. Ein niedriger Stückpreis hilft nicht, wenn das Produkt die Ziel-QPS nicht erreichen kann. Eine Hochdurchsatzkonfiguration ist nicht attraktiv, wenn sie mehr kostet als ein anderes Produkt, das dieselben Anforderungen an Latenz, Recall und Payload erfüllt.
Die Kosten-Pareto-Ansicht kombiniert gemessene Benchmark-Grenzen mit Preismodellen. Für das query-only-Setting LAION 100M endet jede Produktlinie bei der maximalen QPS, die im Benchmark beobachtet wurde. Das Diagramm schätzt dann die Betriebskosten bei Ziel-QPS-Werten und markiert unter diesen gemessenen Einschränkungen Pareto-optimale Optionen.
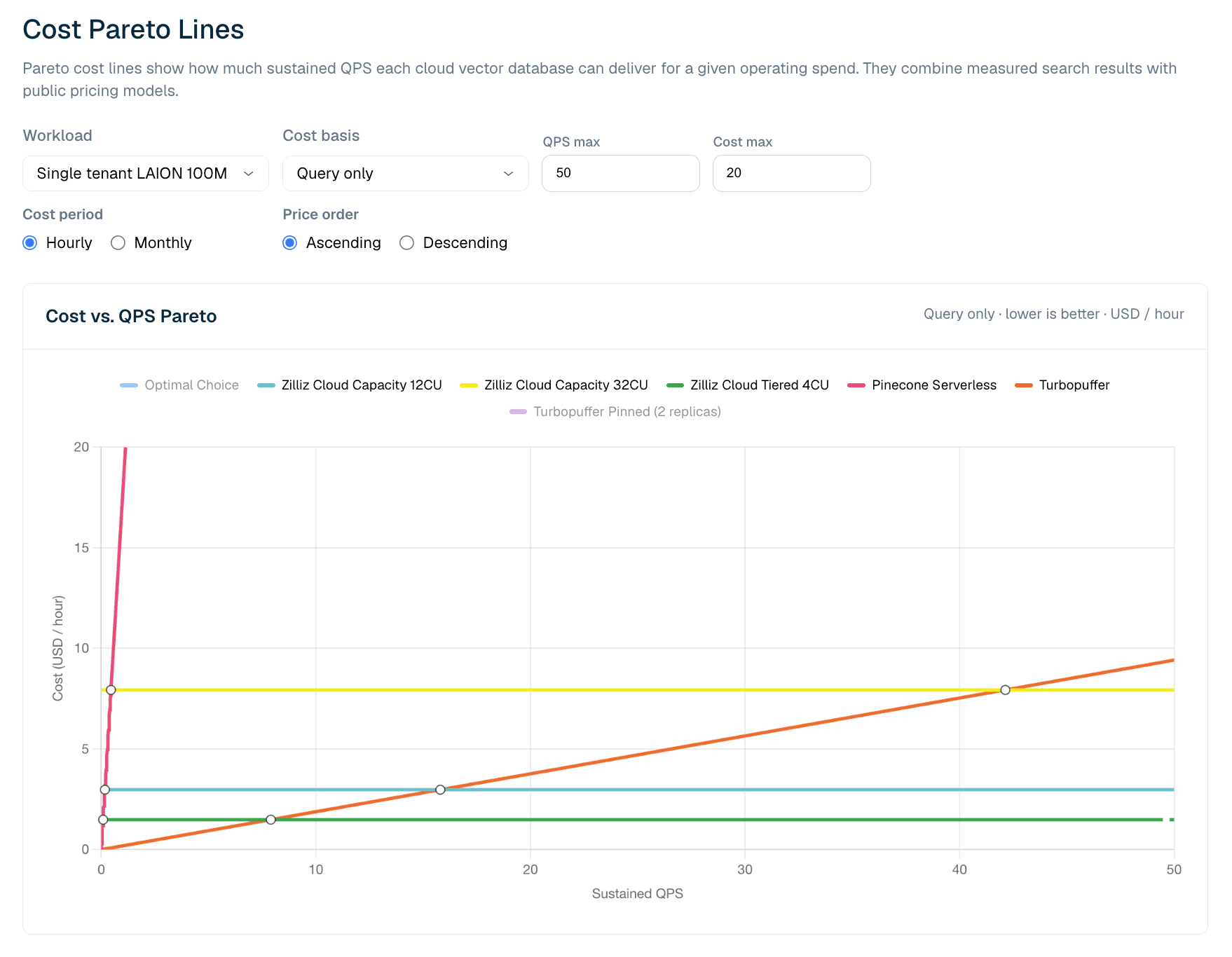
Abbildung 6. Kosten im Vergleich zu anhaltender QPS für LAION 100M query-only-Workloads. Die Pareto-Ansicht zeigt, wo serverless-Preise bei niedriger QPS effizienter sind und wo bereitgestellte Zilliz-Konfigurationen mit steigender Auslastung kosteneffizienter werden.
Im aktuellen LAION 100M query-only-Modell hat Turbopuffer bei sehr niedriger anhaltender QPS den Vorteil. Der gemessene Schnittpunkt liegt bei ungefähr 8 QPS: darunter ist turbopuffers nutzungsabhängige Abrechnung für Abfragen die günstigere Linie; darüber wird Zilliz Cloud Tiered 4CU günstiger, weil die CU-Stunden-Serving-Kosten nach der Bereitstellung weitgehend konstant sind. Wenn die QPS steigt, verbessert sich die Auslastung, und bereitgestellte Kapazität wird kosteneffizienter.
Das bedeutet nicht, dass serverless schlechter ist. Es bedeutet, dass sich die Wirtschaftlichkeit von serverless und bereitgestellten Modellen kreuzt. Für niedrige, stark schwankende oder unvorhersehbare Workloads kann nutzungsabhängiges serverless die beste Wahl sein. Für anhaltenden Produktions-Traffic kann ein flaches CU-Stunden-Modell günstiger werden, sobald die Auslastung den Schnittpunkt überschreitet. Für Teams, die stärkere Serving-Hüllen, Kaltverhalten oder operative Kontrolle benötigen, kann Zilliz Capacity das richtige Profil sein, selbst wenn Tiered die kostengünstigere Linie ist.
Zilliz Cloud vs. Turbopuffer vs. Pinecone: Beste Eignung nach Workload
| Workload-Form | Stärkstes Signal | Warum |
|---|---|---|
| Sehr niedrige anhaltende QPS | turbopuffer | Nutzungsabhängige serverless-Wirtschaftlichkeit ist vor dem Niedrig-QPS-Schnittpunkt attraktiv |
| Anhaltende QPS oberhalb des Schnittpunkts (~8 QPS in diesem Modell) | Zilliz Cloud Tiered | Flache CU-Stunden-Wirtschaftlichkeit verbessert sich mit steigender Auslastung |
| Frische Daten oder häufige Aktualisierung | Zilliz Cloud Capacity / Tiered | Insert-to-search und vollständig indizierte Bereitschaft sind im LAION 100M Insert-Fall stark |
| Hohe Kostensensitivität bei vollständigem Laden | Zilliz Cloud Capacity / Tiered | Schreibseitige Kosten sind im getesteten LAION 100M Bulk-Load-Pfad deutlich niedriger |
| Breite ungefilterte Payload-Suche | Turbopuffer und Zilliz Capacity 32CU | Turbopuffer ist stark bei breitem Retrieval; Zilliz skaliert mit mehr Kapazität |
| Selektive Filter oder berechtigungsgesteuerte Suche | Zilliz Cloud Capacity / Tiered | Zilliz zeigt am 99,9-%-Filter-Stresspunkt deutlich höhere QPS und niedrigere P99-Latenz |
| Viele leichtgewichtige Tenants | turbopuffer | Stärkste rohe QPS im 1.000-Tenant-Auszug |
| Cold-start-sensitive interaktive Apps | Zilliz Cloud Capacity; Turbopuffer pinned | Beide reduzieren First-Query-Strafen, mit unterschiedlichen Kostenmodellen |
| Low-Ops-serverless-Basislinie | Pinecone Serverless | Ausgereifter serverless-Referenzpunkt, auch wenn er in diesem Workload nicht an der Spitze liegt |
So nutzen Sie diese Benchmarking-Ergebnisse
VDBBench und sein Cost Leaderboard sind darauf ausgelegt, die Bewertung von Vektordatenbanken stärker daran auszurichten, wie Teams managed cloud-Produkte tatsächlich kaufen und betreiben. Spitzen-QPS sind weiterhin wichtig, reichen allein aber nicht mehr aus. Die nützlichere Frage ist, ob ein Produkt die Anforderungen des Workloads an Latenz, Recall, Aktualität, Payload, Mandantenfähigkeit und Kosten gleichzeitig erfüllen kann.
Ein praktischer Evaluierungsablauf sieht folgendermaßen aus:
- Verwenden Sie das Performance Leaderboard, um die rohe Serving-Fähigkeit unter kontrollierten Benchmark-Bedingungen zu verstehen.
- Verwenden Sie das Cost Leaderboard, um Kosten-Leistungs-Kompromisse über managed cloud-Produkte und Workload-Formen hinweg zu verstehen.
- Verwenden Sie VDBBench selbst, um die Fälle zu reproduzieren, andere Produkte zu testen oder den Benchmark mit produktionsähnlichen Daten und Abfrageverteilungen auszuführen.
Die aktuellen Ergebnisse sollten mit mehreren Vorbehalten gelesen werden.
- Die Produkte wurden am 10. Mai 2026 gebenchmarkt, und das Kostenmodell verwendet die AWS-us-west-2-Preise zu diesem Datum. Die Preise können je nach Datum und Region variieren.
- Konfigurationsentscheidungen wie festgelegte Modi, bereitgestellte Kapazität, Skalierungssteuerungen und serverlose Drosselung können die Ergebnisse beeinflussen.
- Bereitschaftszustände werden nicht immer auf die gleiche Weise offengelegt, daher müssen die Definitionen für eingefügt, durchsuchbar und vollständig indexiert für jeden Client überprüft werden.
- Schließlich sind die Workloads bewusst spezifisch. Kosten-Pareto-Ergebnisse sollten immer zusammen mit Latenz, Recall, Payload-Form und gemessenen Serving-Grenzen betrachtet werden.
Benchmarken Sie Ihre eigenen Workloads
Das Cost Leaderboard ist eine öffentliche Momentaufnahme der aktuellen Ergebnisse, aber die wichtigere Änderung liegt in VDBBench selbst. Es ermöglicht Teams jetzt, Performance und Kosten gemeinsam anhand workload-spezifischer Einschränkungen zu bewerten: Aktualität, Payload-Größe, Mandantenstruktur, Kaltverhalten und Betriebsmodell.
Ein serverloses Produkt kann für niedrige dauerhaft anliegende QPS gut geeignet sein. Bereitgestellte Kapazität kann kosteneffizienter werden, sobald die Auslastung steigt. Ein System kann bei breiter Retrieval führen, während ein anderes unter selektiven Filtern, häufigen Aktualisierungen oder workloads, die empfindlich auf Kaltstarts reagieren, besser abschneiden kann.
Das Ziel ist nicht die beste Schlagzeilenzahl. Es ist die beste Passung für Ihren Workload.
- Aktuelle Ergebnisse ansehen: VDBBench Cost Leaderboard
- Diese Fälle reproduzieren oder Ihre eigenen Kandidaten benchmarken: VectorDBBench on GitHub
- Fragen oder Ergebnisse zum Teilen? Öffnen Sie ein Issue auf GitHub oder beteiligen Sie sich an der Diskussion auf Discord

Weiterlesen

We spent 8 years making vector databases faster. Then we stopped.
Rarely queried embeddings still need to stay searchable. See how Vector Lakebase enables on-demand vector search without always-on compute costs.

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.