




Hören Sie auf, KI-Dateninfrastruktur für die falsche Phase aufzubauen
Die meisten Entscheidungen zur KI-Infrastruktur werden in Woche eins getroffen und bereut, wenn man im zweiten Jahr zurückblickt.
Das Problem ist fast nie das Modell und selten die Anwendungslogik. Es läuft immer wieder auf dasselbe hinaus: Die Dateninfrastruktur sollte für die Phase gebaut werden, in der sich das Team befindet.
In jeder Phase wirkt der Fehlermodus in beide Richtungen. Zu früh zu viel Engineering, und man bremst sich selbst aus. Unterschätzt man es, baut man unter Druck neu. Beides führt zum gleichen Ergebnis: Iterationsaufwand, der sich aufaddiert.
Phase 1: Der Prototyp — Es einfach zum Laufen bringen
Am Anfang zählt Geschwindigkeit viel mehr als Dateninfra — oder eigentlich braucht es überhaupt keine sogenannte „Dateninfra“.
Das Ziel ist nicht Skalierbarkeit. Das Ziel ist nicht Governance. Das Ziel ist nicht Optimierung.
Das Ziel ist schlicht, die Anwendung zum Laufen zu bringen.
Der häufigste Fehler in dieser Phase ist, Raffinesse mit Qualität zu verwechseln. Teams fügen Streaming-Ingestion-Pipelines hinzu, bevor sie Dokumente zum Ingestieren haben. Sie richten produktionsreife Replikation ein, bevor sie einen einzigen echten Nutzer haben. Sie sorgen sich um Datenkonsistenz über mehrere Systeme hinweg, bevor sie genug Daten haben, damit Konsistenz überhaupt eine Rolle spielt.
Das Ergebnis: Wochen an Infrastrukturarbeit, die auch als einfache Ideenänderung hätte ausgeliefert werden können.
Was das heiße Thema „vector database“ betrifft: Es spielt kaum eine Rolle. Milvus, Elasticsearch, pgvector oder sogar eine leichtgewichtige Suchbibliothek — jede davon wird den Job erledigen. Der Unterschied in der Retrieval-Qualität zwischen den Optionen ist vernachlässigbar im Vergleich zum Unterschied zwischen einem funktionierenden Prototyp und keinem.

Was man in dieser Phase tatsächlich braucht:
- Ihr lokales Dateisystem
- Eine beliebige leichtgewichtige Datenbank oder Suchbibliothek
Phase 2: Product-Market Fit — Mehr Datenbanken, schlimmere Probleme
Sobald echte Nutzer beginnen, mit dem System zu interagieren, verlagert sich der Fokus vom Bau einer Demo auf die kontinuierliche Verbesserung des Produkts, aber eine andere Falle taucht auf.
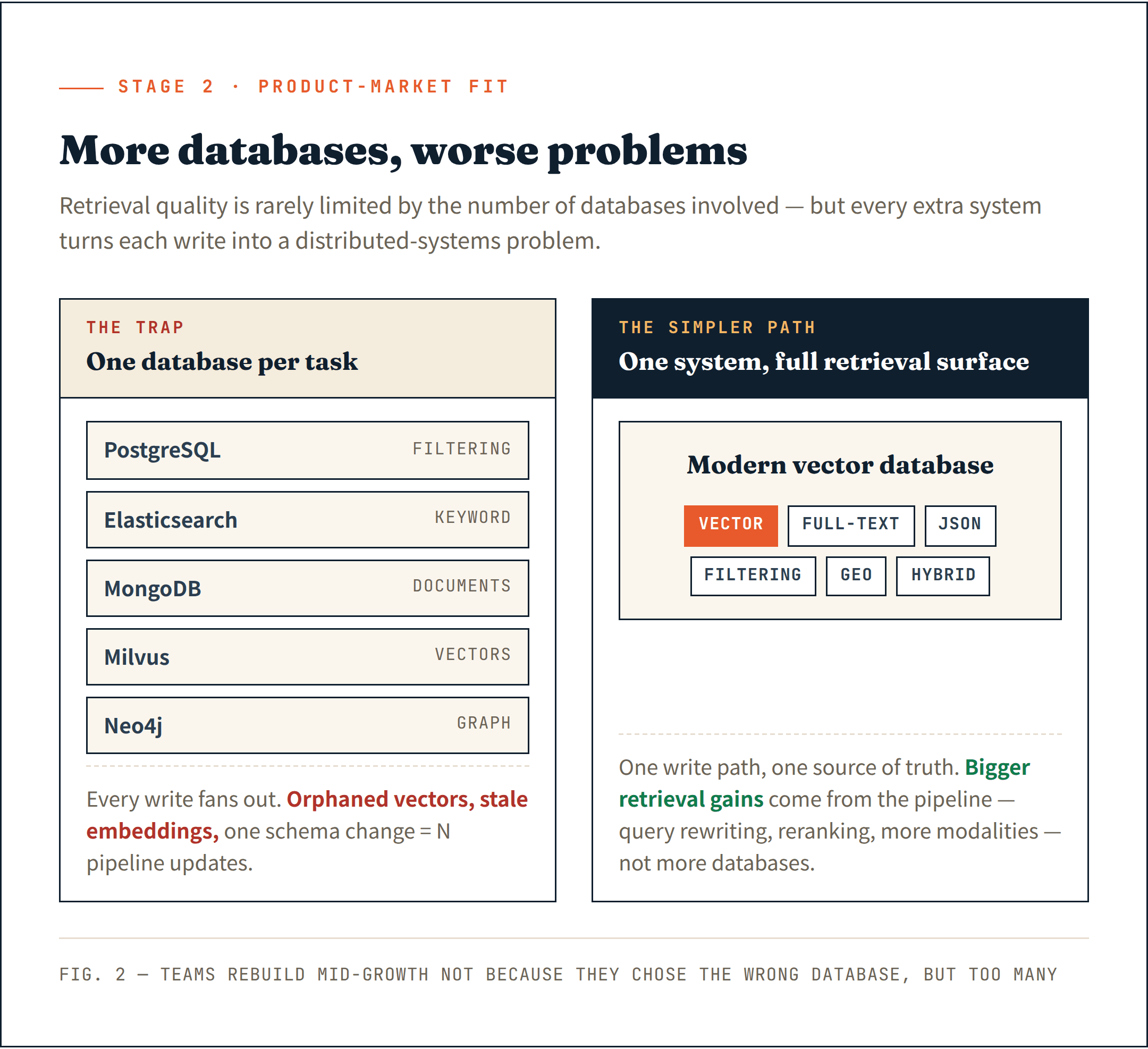
Das Missverständnis klingt plausibel: Mehr spezialisierte Datenbanktypen führen zu besserer Retrieval-Qualität.
Manche Teams beginnen, für jede Retrieval-Aufgabe ein eigenes System zusammenzustellen — PostgreSQL für Filtering, Elasticsearch für Keyword Search, MongoDB für Dokumente, Milvus für Vektoren und Neo4j für Graphbeziehungen. Der Retrieval-Stack wächst schneller als das Produkt selbst.
Dann kommt das Synchronisationsproblem.
Dokumente leben in einem System. Embeddings in einem anderen. Metadaten in einem dritten. Jeder Schreibvorgang wird zu einem Problem verteilter Systeme. Eine fehlgeschlagene Löschung hinterlässt verwaiste Vektoren. Ein partieller Insert erzeugt veraltete Embeddings. Eine Schemaänderung erfordert, mehrere Pipelines gleichzeitig zu aktualisieren.
Die harte Lektion: Retrieval-Qualität ist selten durch die Anzahl der beteiligten Datenbanken begrenzt.
Die größeren Fortschritte kommen aus der Retrieval-Pipeline selbst — dynamisches Query Rewriting, iterative Suche, progressive Offenlegung, besseres Reranking. Auf der Datenseite verbessert das Hinzufügen eines weiteren Embedding-Felds oder einer weiteren Modalität die Retrieval-Qualität häufig stärker als das Hinzufügen einer weiteren spezialisierten Datenbank.
Moderne Vektordatenbanken haben sich still und leise weit über Vektoren hinaus erweitert. Full-Text Search, JSON-Filtering, georäumliche Suche und Hybrid Retrieval — die meisten ausgereiften Systeme unterstützen dies inzwischen nativ. Die Annahme einer spezialisierten Datenbank pro Aufgabe ist zunehmend veraltet.
Ein einzelnes System, das die gesamte Retrieval-Oberfläche abdeckt, ist einfacher zu betreiben und bietet eine sauberere Grundlage für das, was als Nächstes kommt.
Ich habe zu viele Teams gesehen, die mitten im Wachstum gezwungen waren, ihre Dateninfra neu aufzubauen — nicht weil sie die falsche Datenbank gewählt hatten, sondern weil sie zu viele gewählt hatten.
Was man in dieser Phase tatsächlich braucht:
- Ein verwalteter Datenbankdienst — lassen Sie den Anbieter die Zuverlässigkeit übernehmen, während Sie sich auf das Produkt konzentrieren
- Ein einzelnes System mit breiter semantischer Unterstützung: Vektor, Volltext, JSON, Filterung, Hybrid — nicht eine Datenbank pro Aufgabe
- Genug Spielraum, um in die nächste Größenordnung hineinzuwachsen, ohne neu aufzubauen
Phase 3: Wachstum im großen Maßstab — Nicht jede Workload sollte dieselbe Rechenleistung teilen
Dies ist die Phase, in der der Kostendruck unbestreitbar wird. Der Grund ist einfach: Die Daten wachsen immer schneller als Ihr Umsatz.
Der häufigste Fehler: anzunehmen, dass die traditionelle Datenbanklösung, die Sie bis hierher gebracht hat, Sie auch weiterbringen wird.
Anders als in Phase 2 gibt es zu diesem Zeitpunkt keinen einfachen Spielraum für einen Neuaufbau. Eine groß angelegte Infrastrukturmigration unter Wachstumsdruck ist entweder extrem teuer, extrem riskant oder beides.
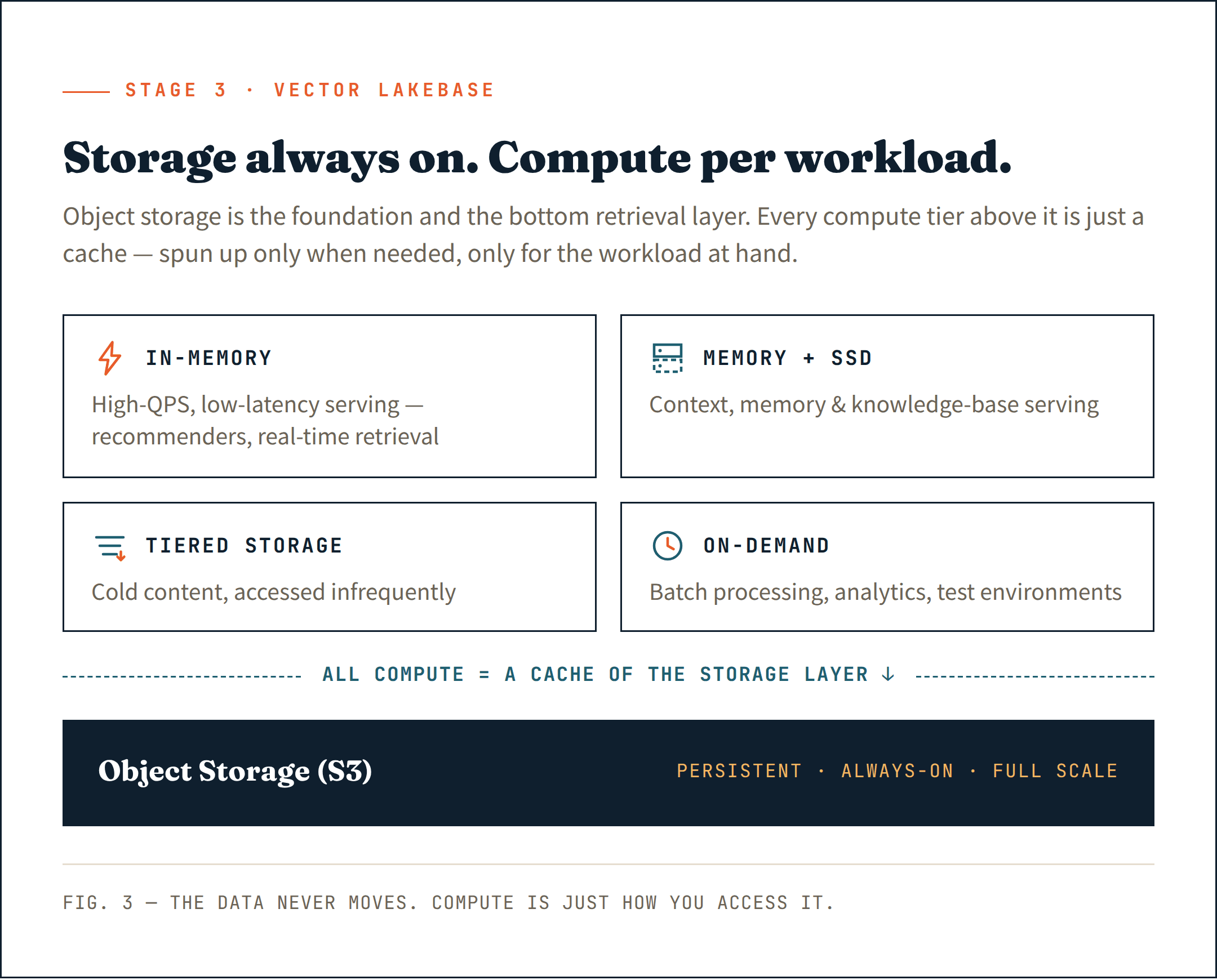
Der richtige Schritt ist, alles auf Objektspeicher (wie S3) zu legen — nicht nur als persistenten Speicher, sondern als Basisschicht Ihrer Retrieval-Architektur. Er ist die günstigste, langlebigste und skalierbarste Option, die es gibt. Behandeln Sie ihn als Fundament, nicht als nachträglichen Einfall.
Oberhalb dieser Schicht bringen Sie Rechenleistung nur dort ein, wo sie tatsächlich benötigt wird. Dauerhaft laufende Cluster für latenzsensitives Serving. Kurzlebige Rechenressourcen für Ingestion und Indexierung. On-Demand-Rechenleistung für Analysen und Batch-Jobs. Jede Workload erhält die Rechenleistung, die sie braucht — und nichts darüber hinaus.
Das ist das Wesen einer Vector Lakebase: Speicher, der immer in vollem Umfang aktiv ist, Rechenleistung, die es nicht ist — nur bei Bedarf hochgefahren, nur für die jeweilige Workload.
Am wichtigsten ist: Jede Rechenleistung — ob dauerhaft laufend oder On-Demand — fungiert als Cache der Objektspeicherschicht. Die Daten leben immer im Speicher. Rechenleistung ist nur die Art und Weise, wie Sie darauf zugreifen.
Ordnen Sie jede Workload der richtigen Rechenschicht zu:
- In-memory für Workloads mit hohem QPS und niedriger Latenz — KI-Empfehlungssysteme, Echtzeit-Retrieval
- Memory + SSD für Context-, Memory- und Knowledge-Base-Serving
- Tiered storage für kalte Inhalte, auf die selten zugegriffen wird
- On-demand compute für Batch-Verarbeitung, interne Analysen und Testumgebungen
Richtig umgesetzt senkt dieser Ansatz die Infrastrukturkosten im Vergleich zu einem einheitlichen Design um 50 % oder mehr — und liefert zugleich eine deutlich bessere Servicequalität für jede Workload.
Serverless-Lösungen brechen in dieser Phase oft zusammen — nicht technisch, sondern wirtschaftlich. Sobald Ihre Daten in den Terabyte-Bereich gelangen, beginnen Insert- und Speicherkosten zu dominieren. Der Grund ist strukturell: Serverless-Architekturen bündeln Pooling-Overhead, Indexierung und persistente Datenkosten in Aufschlägen auf Schreibvorgänge und Speicher. Sie zahlen nicht mehr für das, was Sie nutzen. Sie zahlen für die Abstraktion.
Das erste Prinzip für Dateninfrastruktur in dieser Phase ist einfach: Ihr Fundament muss mit Ihren Daten skalieren, nicht gegen sie. Eine Architektur, die gezwungen ist, jede Workload gleichermaßen gut zu bedienen, bedient am Ende keine davon gut — und die Kosten dieses Kompromisses vervielfachen sich mit jedem Gigabyte, das Sie hinzufügen.
Was Sie in dieser Phase tatsächlich brauchen:
- Objektspeicher (S3) als Fundament und unterste Retrieval-Schicht — persistent, immer in vollem Umfang aktiv, die Schicht, aus der alle Rechenleistung liest
- Eine Vector Lakebase: Daten, die sich nie bewegen, Rechenleistung, die pro Workload hochfährt und nichts darüber hinaus
- Die richtige Rechenschicht pro Workload-Typ
Phase 4: Unternehmensmaßstab — Vertrauen wird Teil des Produkts
In dieser Phase glauben die meisten Teams, dass der schwierige Teil hinter ihnen liegt. Das stimmt nicht.
Der häufige Fehler: Teams denken immer noch, das Problem sei technischer Natur.
Sie haben die Infrastruktur optimiert. Sie haben die Kosten kontrolliert. Sie gehen davon aus, dass Skalierung auf Enterprise-Niveau eine Frage davon ist, Kapazität hinzuzufügen und ein Sicherheitskästchen abzuhaken.
Das ist es nicht.
Die Fragen, die Enterprise-Deals blockieren, haben nichts mit Performance zu tun:
Wie sind unsere Daten von denen anderer Kunden isoliert?
Wer hat worauf Zugriff, und können Sie das nachweisen?
Können Sie uns in unserer Region bedienen?
Können wir dies innerhalb unseres eigenen Cloud-Kontos bereitstellen?
Aber individuelle Deal-Anforderungen sind nur ein Teil des Problems. In Stage 3 war die Inhomogenität technischer Natur — unterschiedliche Workloads, unterschiedliche Compute-Tiers. In dieser Phase ist sie strukturell: Ihre Kundenbasis erfordert eine Dateninfrastruktur auf Plattformebene, um damit umzugehen.
Sie haben kostenlose Nutzer, die kosteneffizientes Shared Serving benötigen. Sie haben zahlende Einzelkunden, die eine bessere Verfügbarkeit erwarten. Sie haben Enterprise-Kunden, die vollständige Datenisolierung, dedizierte Rechenleistung und die Möglichkeit benötigen, alles zu auditieren. Alle drei aus derselben Architektur heraus zu bedienen bedeutet, dass Sie entweder zu viel für Ihren Free Tier ausgeben, Ihre Enterprise-Kunden unzureichend bedienen oder beides.
Die richtige Antwort ist eine abgestufte Infrastruktur, die auf jedes Kundensegment abgestimmt ist:
- Shared clusters für kostenlose und individuelle Nutzer — gepoolt, kostenoptimiert
- Isolated clusters pro Enterprise-Kunde — dedizierte Rechenleistung, dedizierter Speicher, dedizierte Zugriffskontrollen
- BYOC für Kunden, die eine Bereitstellung innerhalb ihres eigenen Cloud-Kontos benötigen

Der BYOC-Punkt ist der Punkt, an dem die meisten Teams einen kritischen Fehler machen. SaaS und BYOC sehen wie zwei Produkte aus. Wenn sie sich auf Architekturebene verzweigen, pflegen Sie auf unbestimmte Zeit zwei Codebasen, zwei Deployment-Pipelines und zwei Betriebs-Runbooks. Die Teams, die das richtig gemacht haben, behandelten BYOC als Deployment-Modell und nicht als separates Produkt. Dieselbe Data Plane, dieselbe Control-Oberfläche, unterschiedliches Deployment-Ziel.
Globale Zuverlässigkeit ist das andere Element, das zu lange aufgeschoben wird. Auf Enterprise-Ebene sind Multi-Regions kein Premium-Feature — sie sind eine grundlegende Erwartung. Enterprise-Kunden in unterschiedlichen geografischen Regionen werden kein Single-Region-Deployment tolerieren, noch werden sie Ihre SLA-Zusagen akzeptieren. Ohne eine einheitliche Dateninfrastruktur-Schnittstelle über Clouds und Regionen hinweg betreiben Sie am Ende unterschiedliche Datenschichten in unterschiedlichen Umgebungen — Echtzeit-Datensynchronisierung wird zu einem eigenen Distributed-Systems-Problem, und die operative Komplexität nimmt mit jeder neuen Region, die Sie hinzufügen, weiter zu.
Die Teams, mit denen ich gesprochen habe und die ernsthafte Enterprise-Deals erreicht hatten, beschrieben dieselbe schmerzhafte Erkenntnis: Nichts davon war von Anfang an eingeplant worden. Es war später unter dem Druck eines laufenden Sales Cycles nachträglich angebaut worden. Ein Team verbrachte vier Monate damit, Datenisolierung auf Datenebene in eine Architektur nachzurüsten, die dafür nicht gebaut war. Sie lieferten es aus. Aber sie wussten genau, warum es fragil war.
Enterprise Readiness ist keine Checkliste. Sie ist eine Konsequenz architektonischer Entscheidungen, die viel früher getroffen wurden.
Was Sie in dieser Phase tatsächlich benötigen:
- Eine einheitliche Dateninfrastruktur-Schnittstelle — konsistent über Clouds hinweg, konsistent über Regionen hinweg
- Globale Cluster, die für hohe Zuverlässigkeit und Multi-Region Serving ausgelegt sind
- Abgestuftes Serving: Shared clusters für kostenlose Nutzer, Isolated clusters pro Enterprise-Kunde
- SaaS und BYOC auf derselben Architektur — eine Data Plane, unterschiedliche Deployment-Ziele
- Offene Standards und Open Source als Grundlage — kein Vendor Lock-in auf Enterprise-Ebene
Was die Teams, die gut skaliert haben, gemeinsam haben
Das Muster ist konsistent.
Jede Phase bringt eine völlig andere Problemklasse mit sich. Stage 1 ist ein Geschwindigkeitsproblem. Stage 2 ist ein Komplexitätsproblem. Stage 3 ist ein Kosten- und Architekturproblem. Stage 4 ist ein Vertrauens- und Plattformproblem.

Die Teams, die jede Phase ohne schmerzhaften Neuaufbau gemeistert haben, haben das früh verstanden. Sie hörten auf zu fragen: „Welche Datenbank brauche ich gerade jetzt?“ und begannen zu fragen: „Was wird die nächste Phase erfordern — und verschließt meine aktuelle Entscheidung diese Tür?“
In Phase 1 ist eine Vektordatenbank genau das richtige Werkzeug. Das sage ich ohne Einschränkung.
Ab Phase 3 und darüber hinaus wird etwas grundsätzlich anderes notwendig — eine Vector Lakebase. Storage immer in voller Skalierung verfügbar. Compute passend zu jeder Workload. Eine Plattform, die einen kostenlosen Nutzer, einen zahlenden Kunden und ein Enterprise-Konto aus derselben Architektur bedienen kann, ohne Forking.
Die Teams, die schneller dort ankamen, waren nicht klüger oder besser finanziert.
Sie haben nur früher verstanden, dass die Infrastrukturentscheidung keine vorübergehende Wahl war.
Sie war das Fundament, auf dem alles Weitere aufgebaut werden würde.
Zilliz Vector Lakebase ist in der Public Preview verfügbar
Wir haben die Public Preview von Zilliz Vector Lakebase gestartet — eine bedeutende Weiterentwicklung von Zilliz Cloud, von einer verwalteten Vektordatenbank zu einer einheitlichen semantischen Datenplattform, die die produktive Vektordatenbank mit einer gemeinsamen, lake-nativen Datengrundlage verbindet.
Zentrale Funktionen von Zilliz Vector Lakebase:
- Tiered Serving, optimiert für unterschiedliche Echtzeit-Abwägungen zwischen Performance und Kosten
- On-Demand-Suche für großskalige oder explorative Workloads ohne Always-on-Compute
- Suche in externen Data Lakes — direktes Indexieren und Suchen über Ihre bestehenden Lake-Daten
- Full-Spectrum-Suche über Vektoren, Text, JSON und Geodaten mit hybrider Retrieval- und Reranking-Funktionalität
- Einheitlicher lake-nativer Storage auf Basis von Vortex, einem offenen Format mit schnelleren und günstigeren Random Reads als Lance oder Parquet
Wenn Ihr aktueller Stack Serving und Discovery in getrennte Systeme aufteilt, könnte Vector Lakebase einen Blick wert sein. Testen Sie es auf Zilliz Cloud — neue Registrierungen mit geschäftlicher E-Mail-Adresse erhalten $100 Gratisguthaben — oder sprechen Sie mit uns über Ihren Anwendungsfall.
Erfahren Sie mehr über Vector Lakebases
- Von der Vektordatenbank zur Vector Lakebase
- Wir haben 8 Jahre damit verbracht, Vektordatenbanken schneller zu machen. Dann haben wir aufgehört.
- Warum wir Vector Lakebase entwickelt haben: Unstrukturierte Datenarchitektur für KI neu gedacht
- Vector Lakebase: Das KI-Datensilo beenden
- Zilliz Cloud On-Demand Compute: Zahlen Sie nur für das, was Sie nutzen
- Notions Vector Search ist ausgezeichnet. Ihr nächstes Problem ist schwieriger.

Weiterlesen

A Developer's Guide to Exploring Milvus 2.6 Features on Zilliz Cloud
Milvus 2.6 marks a shift from “vector search + glue code” to a more advanced retrieval engine, and it is now Generally Available (GA) on Zilliz Cloud (a managed Milvus service).

Migrating from S3 Vectors to Zilliz Cloud: Unlocking the Power of Tiered Storage
Learn how Zilliz Cloud bridges cost and performance with tiered storage and enterprise-grade features, and how to migrate data from AWS S3 Vectors to Zilliz Cloud.

Democratizing AI: Making Vector Search Powerful and Affordable
Zilliz democratizes AI vector search with Milvus 2.6 and Zilliz Cloud for powerful, affordable scalability, cutting costs in infrastructure, operations, and development.