




Nutzen Sie Milvus und Airbyte für die Ähnlichkeitssuche in all Ihren Daten
Milvus ist eine beliebte Open-Source-Vektordatenbank. Vektoren sind hochdimensionale Arrays von Zahlen. Bei der Arbeit mit Large Language Models (LLMs) beziehen sich „Embeddings“ speziell auf die letzte verborgene Schicht innerhalb der Encoder-Komponente eines transformerbasierten Deep Neural Network. Diese Embedding-Schicht ist eine Menge von Vektoren, die die semantische Bedeutung von Wörtern oder Pixeln (für Text oder Bilder) darstellen.
Angesichts der Fülle an Informationen in der Embedding-Schicht eines trainierten LLM ist die effiziente Speicherung und Abfrage von Vektoren entscheidend geworden. Milvus ist eine Vektordatenbank, die speziell für das Speichern, Indexieren und effiziente Durchsuchen hochdimensionaler Vektordaten entwickelt wurde. Vektordatenbanken werden typischerweise für Ähnlichkeitssuchen über unstrukturierte Daten hinweg verwendet und ermöglichen Verbesserungen bei Generative-Chat-Antworten, Produktempfehlungen und anderen Anwendungen.
Durch die Verwendung von Airbyte ist es unkompliziert, Daten aus vielen verschiedenen Quellen nach Milvus zu übertragen und dabei Vektor-Embeddings von Texten zu berechnen.
Die Stärke von Embeddings besteht darin, relevante Informationsstücke suchen zu können, selbst wenn ähnliche Konzepte unterschiedlich formuliert sind. Dieser Artikel nutzt diese Funktionalität, um ein Website-Supportformular intelligenter zu machen, indem relevante Informationen dynamisch nachgeschlagen werden. Dies wird verwendet, um den Benutzer über ähnliche Tickets zu informieren, die bereits bearbeitet wurden, und relevante Knowledge-Base-Artikel hervorzuheben, die helfen könnten, das Problem ohne die Hilfe eines Support-Mitarbeiters zu lösen.
Wir werden Zilliz Cloud als unseren Vektorspeicher verwenden, Airbyte zum Extrahieren und Laden der Daten, die OpenAI Embedding API zum Berechnen von Embeddings und Streamlit, um ein intelligentes Einreichungsformular zu erstellen, das relevante Daten anzeigt.
Sie benötigen:
Zendesk-Konto (oder eine andere Datenquelle, aus der Sie Daten synchronisieren möchten)
Airbyte-Konto oder lokale Instanz
OpenAI-API-Schlüssel
Zilliz Cloud-Konto oder lokaler Milvus-Cluster
Python 3.10 lokal installiert
Schritt 1: Milvus-Cluster einrichten
Auf cloud.zilliz.com können Sie sich für einen kostenlosen Cluster anmelden, um Ihre Embeddings Vektoren für die Ähnlichkeitssuche zu speichern. Sobald Sie ein Konto erstellt haben, müssen Sie einen neuen Cluster einrichten.
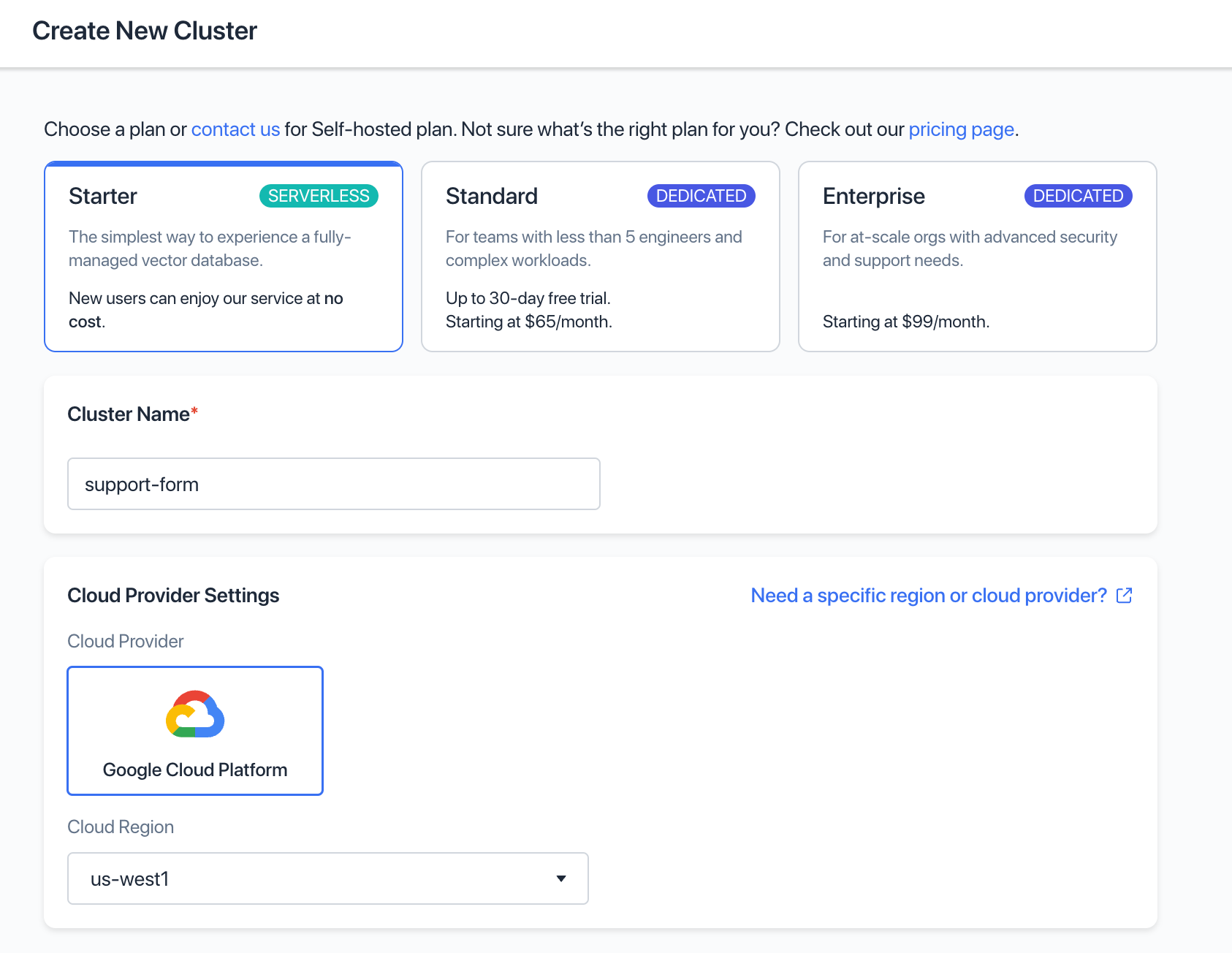
Einzelne Entitäten (in unserem Fall Support-Tickets und Knowledge-Base-Artikel) werden in einer „Collection“ gespeichert — nachdem Ihr Cluster eingerichtet ist, müssen Sie eine Collection erstellen. Wählen Sie einen passenden Namen und setzen Sie die Dimension auf 1536, damit sie der vom OpenAI Embeddings Service erzeugten Vektordimensionalität entspricht:
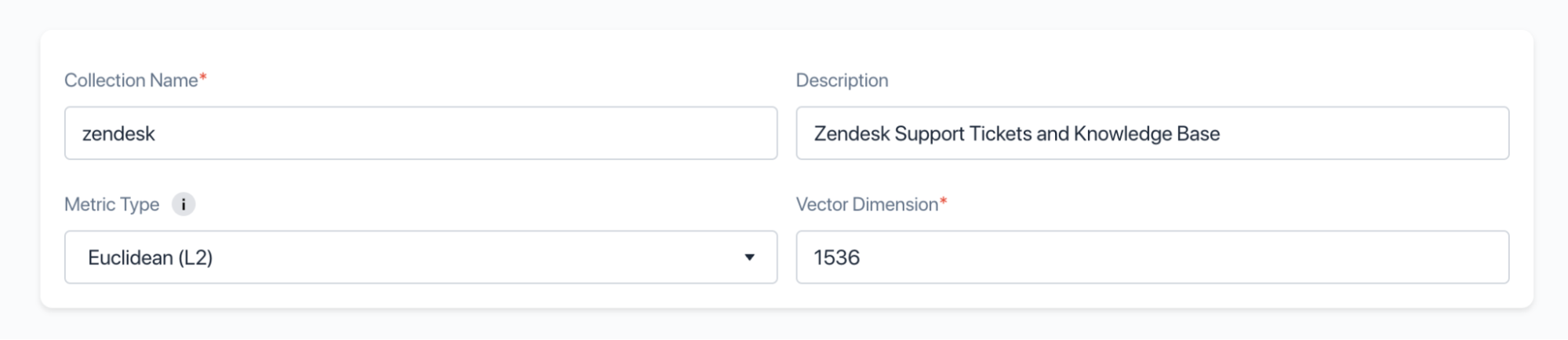
Nach der Erstellung zeigt Zilliz Ihnen den Endpunkt und den API-Schlüssel an — notieren Sie sich diese, da wir sie im nächsten Schritt benötigen.
Schritt 2: Verbindung in Airbyte einrichten
Unsere Datenbank ist bereit, lassen Sie uns einige Daten übertragen! Dazu müssen wir eine Verbindung in Airbyte konfigurieren. Registrieren Sie sich entweder für ein Airbyte-Cloud-Konto unter cloud.airbyte.com oder starten Sie eine lokale Instanz wie in der Dokumentation beschrieben.
Sobald Ihre Instanz läuft, müssen wir die Verbindung einrichten — klicken Sie auf „New connection“ und wählen Sie den „Zendesk Support“-Connector als Quelle aus.
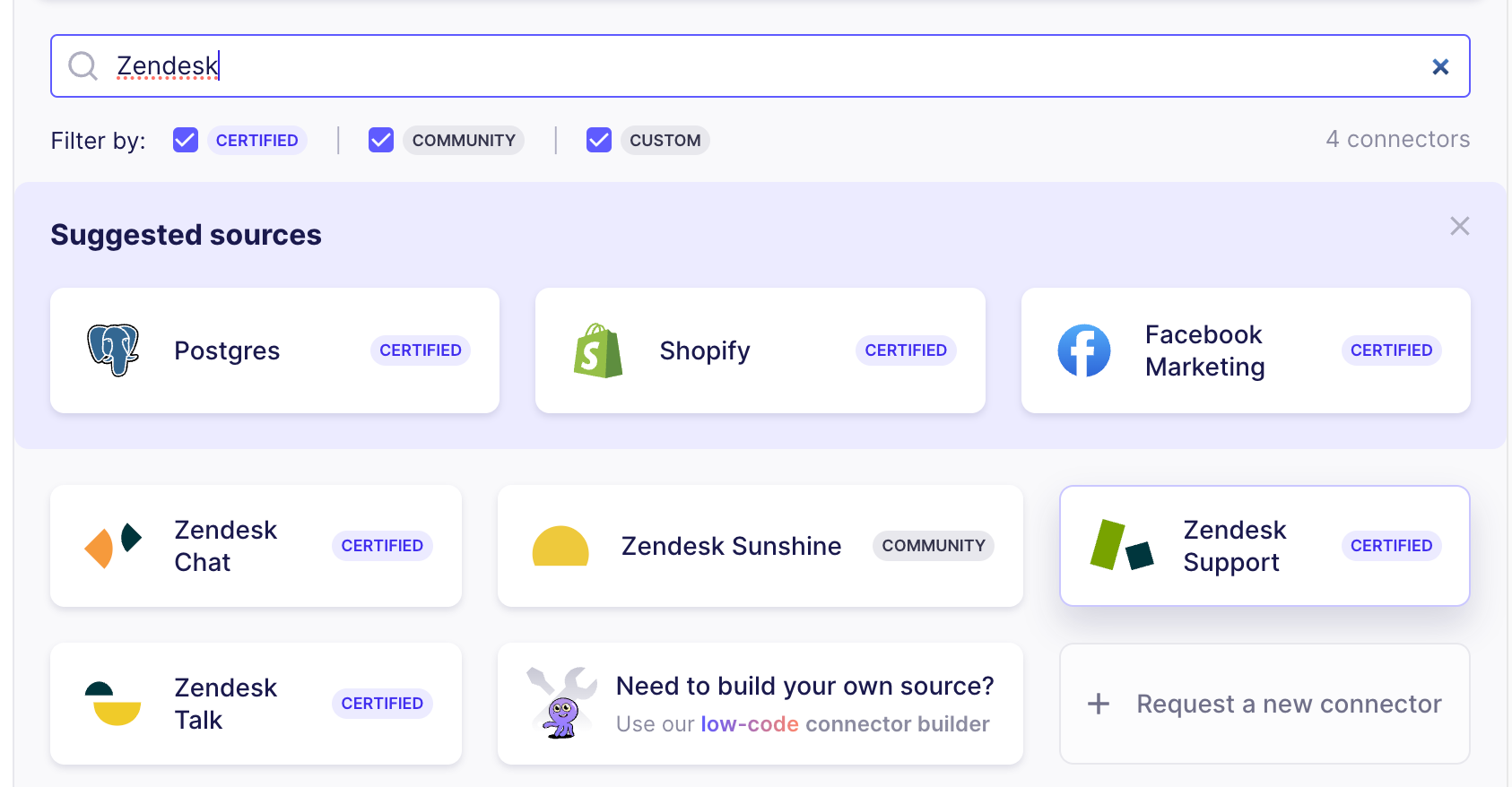
In Airbyte Cloud können Sie sich einfach authentifizieren, indem Sie auf die Schaltfläche Authenticate klicken. Wenn Sie eine lokale Airbyte-Instanz verwenden, folgen Sie den Anweisungen auf der Dokumentationsseite.
Info::
Wenn Sie eine andere Datenquelle verwenden möchten — der Rest dieses Artikels ist auf alle Arten textbasierter Quellen anwendbar
::
Nachdem Sie auf die Schaltfläche „Test and Save“ geklickt haben, prüft Airbyte, ob die Verbindung hergestellt werden kann. Wenn alles korrekt funktioniert, besteht der nächste Schritt darin, das Ziel einzurichten, zu dem die Daten verschoben werden sollen. Wählen Sie hier den „Milvus“-Connector aus.
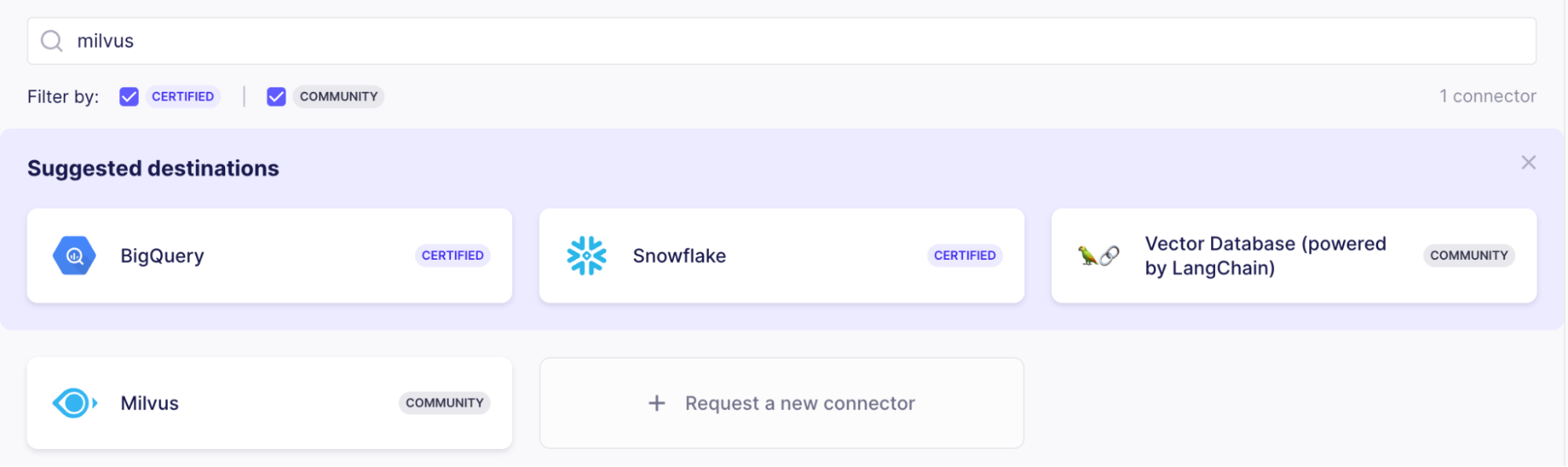
Der Milvus-Connector erledigt drei Dinge:
- Chunking und Formatierung - Zendesk-Datensätze in Text und Metadaten aufteilen. Wenn der Text größer als die angegebene Chunk-Größe ist, werden Datensätze in mehrere Teile aufgeteilt, die einzeln in die Collection geladen werden. Die Aufteilung von Text (oder Chunking) kann beispielsweise bei großen Support-Tickets oder Wissensartikeln erfolgen. Durch das Aufteilen des Textes können Sie sicherstellen, dass Suchanfragen immer nützliche Ergebnisse liefern.
Verwenden wir eine Chunk-Größe von 1000 Tokens und die Textfelder body, title, description und subject, da diese in den Daten vorhanden sein werden, die wir von Zendesk erhalten.
Embedding - Mithilfe von Machine-Learning-Modellen werden die vom Verarbeitungsteil erzeugten Text-Chunks in Vektor-Embeddings umgewandelt, nach denen Sie dann auf semantische Ähnlichkeit suchen können. Um die Embeddings zu erstellen, müssen Sie den OpenAI-API-Schlüssel bereitstellen. Airbyte sendet jeden Chunk an OpenAI und fügt den resultierenden Vektor zu den Entitäten hinzu, die in Ihren Milvus-Cluster geladen werden.
Indexierung - Sobald Sie die Chunks vektorisiert haben, können Sie sie in die Datenbank laden. Fügen Sie dazu die Informationen ein, die Sie beim Einrichten Ihres Clusters und Ihrer Collection in der Zilliz Cloud erhalten haben.
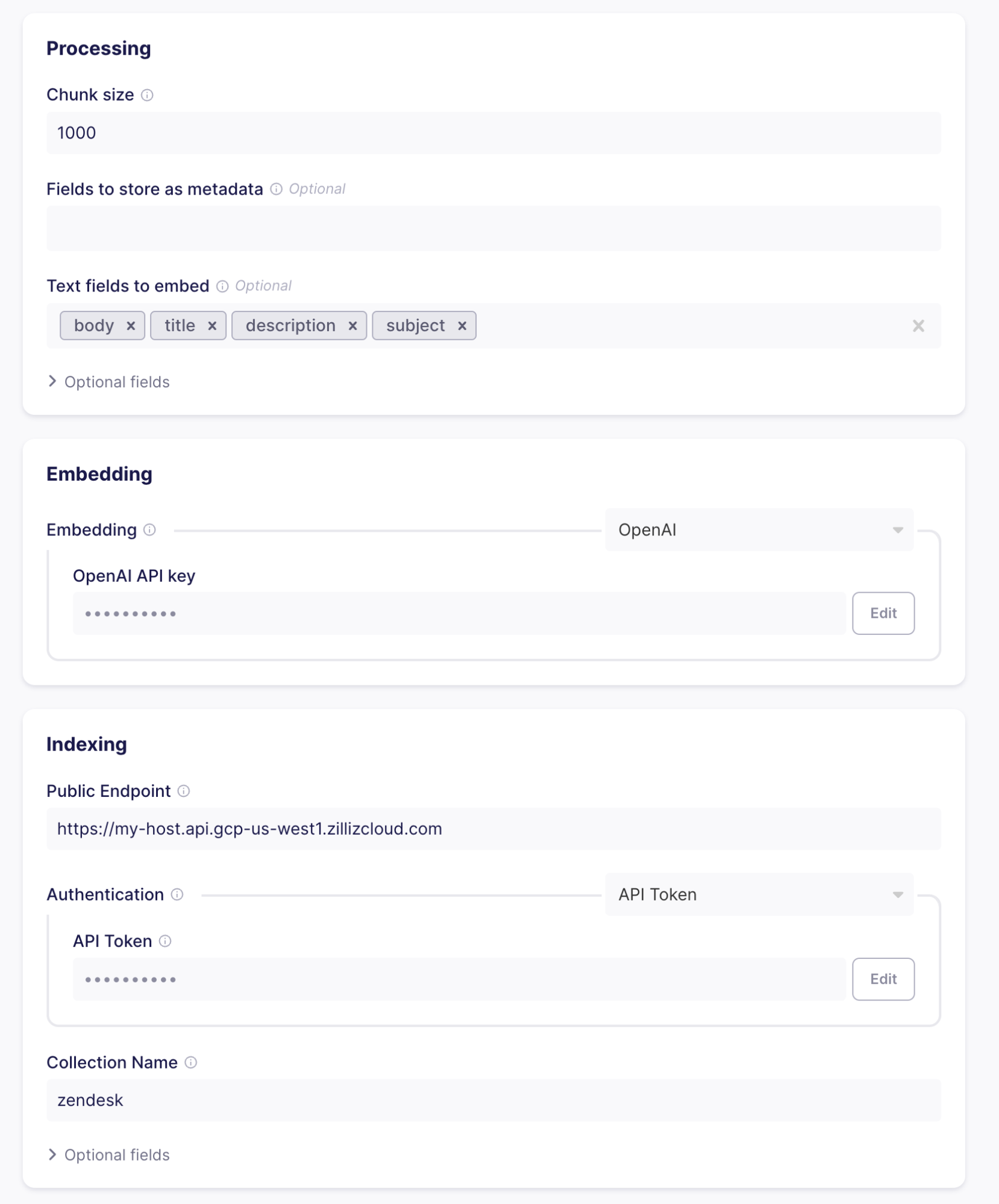
Durch Klicken auf „Test and save“ wird geprüft, ob alles korrekt aufeinander abgestimmt ist (gültige Anmeldedaten, Collection existiert und hat dieselbe Vektordimensionalität wie das konfigurierte Embedding usw.).
Der letzte Schritt, bevor Daten fließen können, besteht darin, auszuwählen, welche „Streams“ synchronisiert werden sollen. Ein Stream ist eine Sammlung von Datensätzen in der Quelle. Da Zendesk eine große Anzahl von Streams unterstützt, die für unseren Anwendungsfall nicht relevant sind, wählen wir nur „tickets“ und „articles“ aus und deaktivieren alle anderen, um Bandbreite zu sparen und sicherzustellen, dass nur die relevanten Informationen in Suchanfragen angezeigt werden:
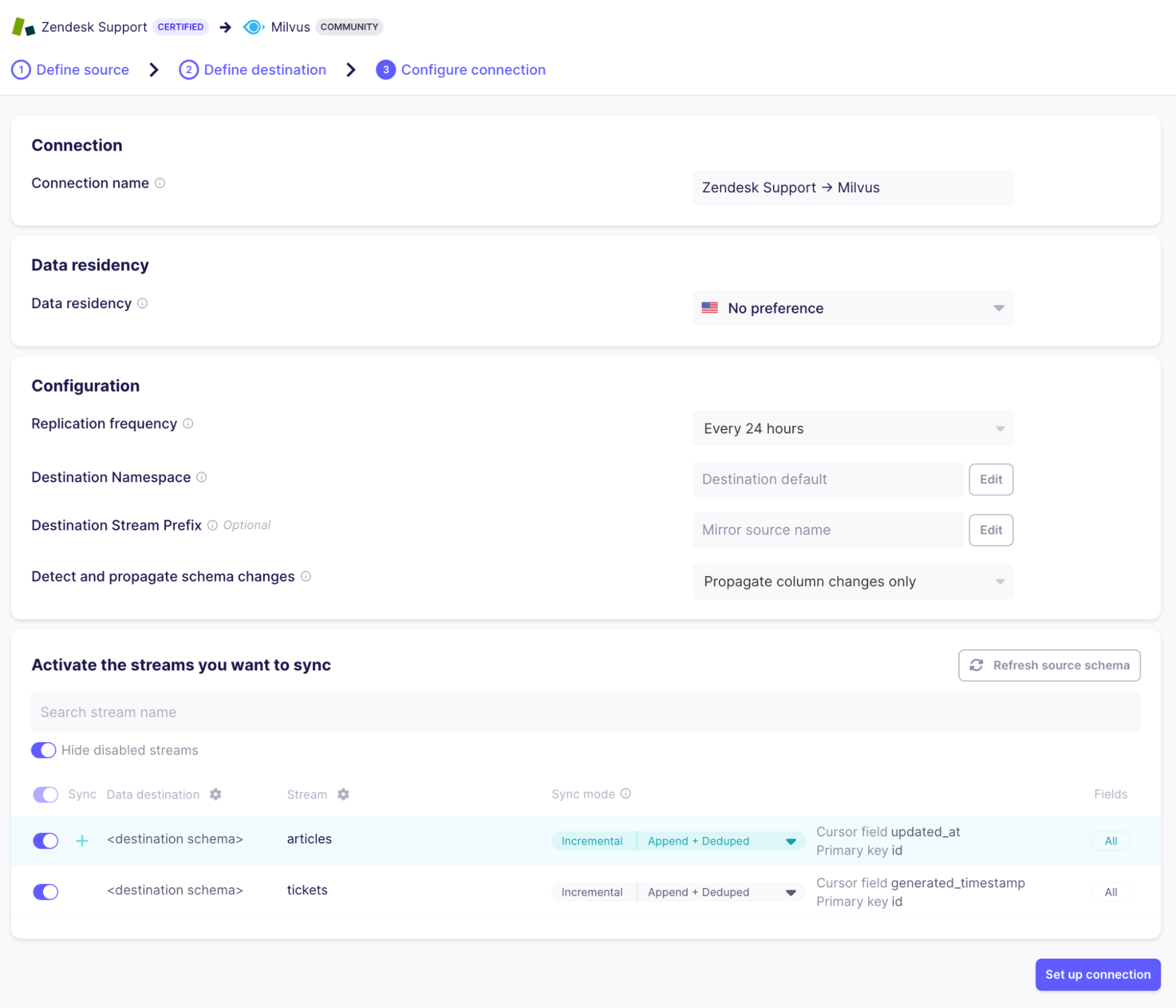
Sie können auswählen, welche Felder aus der Quelle extrahiert werden sollen, indem Sie auf den Stream-Namen klicken. Der Synchronisierungsmodus „Incremental | Append + Deduped“ bedeutet, dass nachfolgende Verbindungsläufe Zendesk und Milvus synchron halten und dabei nur minimale Daten übertragen (nur die Artikel und Tickets, die sich seit dem letzten Lauf geändert haben).
Sobald die Verbindung eingerichtet ist, beginnt Airbyte mit der Datensynchronisierung. Es kann einige Minuten dauern, bis sie in Ihrer Milvus-Collection erscheinen.
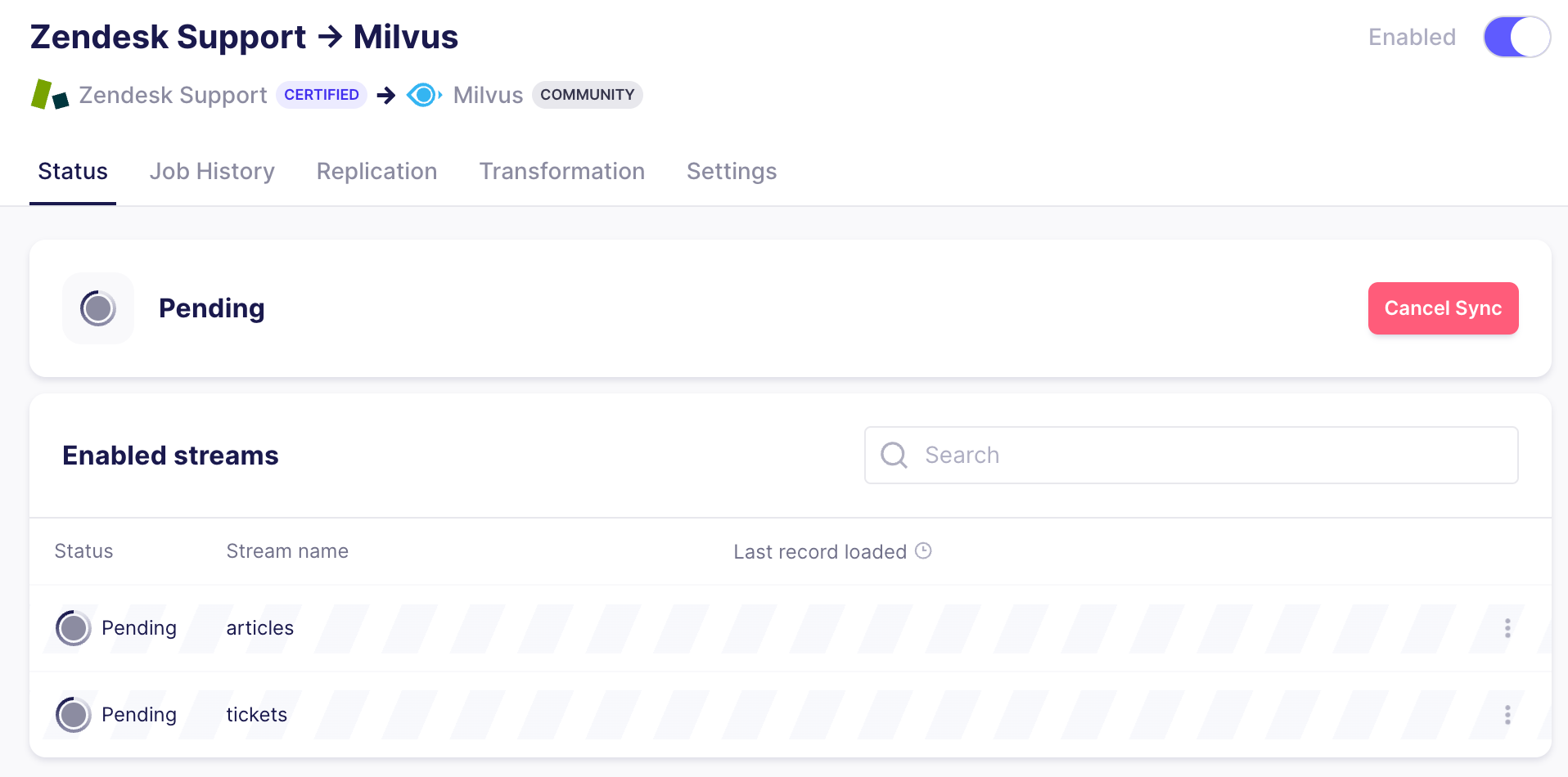
Wenn Sie eine Replikationsfrequenz auswählen, wird Airbyte regelmäßig ausgeführt, um Ihre Milvus-Collection mit Änderungen an Zendesk-Artikeln und neu erstellten Vorgängen auf dem neuesten Stand zu halten.
Sie können in der Zilliz-Cloud-Benutzeroberfläche überprüfen, wie die Daten in der Collection strukturiert sind, indem Sie zum Playground navigieren und eine „Query Data“-Abfrage mit einem Filter ausführen, der auf „_ab_stream == \”tickets\”” gesetzt ist.
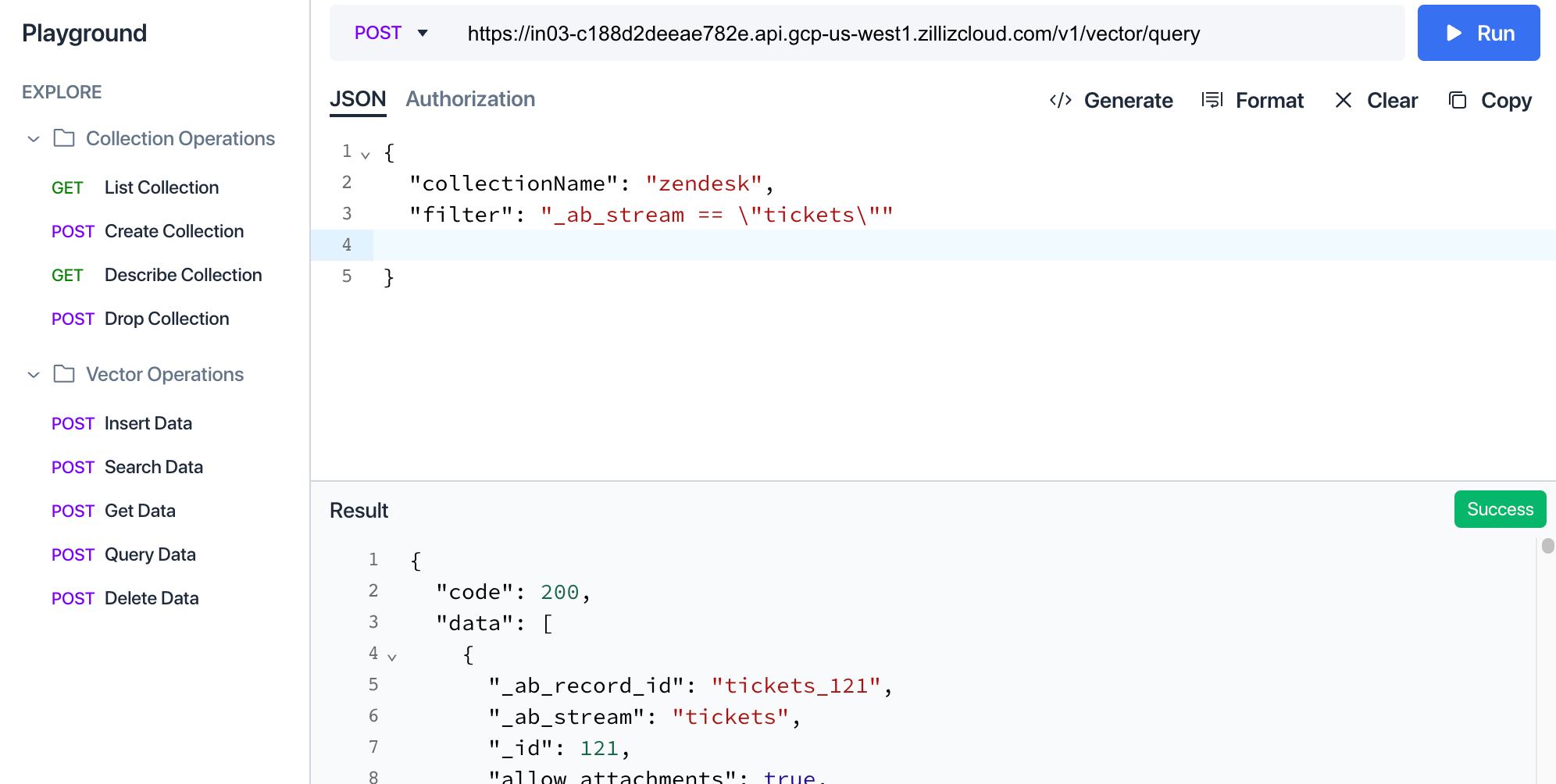
Wie Sie in der Ergebnisansicht sehen können, wird jeder von Zendesk kommende Datensatz als separate Entität in Milvus mit allen angegebenen Metadaten gespeichert. Der Text-Chunk, auf dem das Embedding basiert, wird als „text“-Eigenschaft angezeigt — dies ist der Text, der mit OpenAI eingebettet wurde und auf dem wir suchen werden.
Schritt 3: Streamlit-App erstellen, die die Collection abfragt
Unsere Daten sind bereit — jetzt müssen wir die Anwendung erstellen, um sie zu nutzen. In diesem Fall wird die Anwendung ein einfaches Support-Formular sein, über das Benutzer Support-Fälle einreichen können. Wenn der Benutzer auf „Submit“ klickt, werden wir zwei Dinge tun:
Nach ähnlichen Tickets suchen, die von Benutzern derselben Organisation eingereicht wurden
Nach Wissensdatenbank-Artikeln suchen, die für den Benutzer relevant sein könnten
In beiden Fällen nutzen wir die semantische Suche mit OpenAI-Embeddings. Dazu wird die Beschreibung des Problems, die der Benutzer eingegeben hat, ebenfalls eingebettet und verwendet, um ähnliche Entitäten aus dem Milvus-Cluster abzurufen. Wenn es relevante Ergebnisse gibt, werden sie unterhalb des Formulars angezeigt.
Sie benötigen eine lokale Python-Installation, da wir Streamlit verwenden werden, um die Anwendung zu implementieren.
Installieren Sie zunächst Streamlit, die Milvus-Clientbibliothek und die OpenAI-Clientbibliothek lokal:
pip install streamlit pymilvus openai
Um ein einfaches Support-Formular zu rendern, erstellen Sie eine Python-Datei app.py:
import streamlit as st
with st.form("my_form"):
st.write("Submit a support case")
text_val = st.text_area("Describe your problem")
submitted = st.form_submit_button("Submit")
if submitted:
# TODO check for related support cases and articles
st.write("Submitted!")
Um Ihre Anwendung auszuführen, verwenden Sie Streamlit run:
streamlit run app.py
Dies rendert ein einfaches Formular:
Der Code für dieses Beispiel ist auch auf GitHub zu finden.
Als Nächstes prüfen wir, ob es vorhandene offene Tickets gibt, die relevant sein könnten. Dazu betten wir den vom Benutzer eingegebenen Text mit OpenAI ein und führen dann eine Ähnlichkeitssuche in unserer Collection durch, wobei wir nach weiterhin offenen Tickets filtern. Wenn es eines mit einem sehr geringen Abstand zwischen dem übermittelten Ticket und dem vorhandenen Ticket gibt, informieren Sie den Benutzer und senden Sie es nicht ab:
import os
import pymilvus
import openai
org_id = 360033549136 # TODO Load from customer login data
pymilvus.connections.connect(uri=os.environ["MILVUS_URL"], token=os.environ["MILVUS_TOKEN"])
collection = pymilvus.Collection("zendesk")
embedding = openai.Embedding.create(input=text_val, model="text-embedding-ada-002")['data'][0]['embedding']
results = collection.search(data=[embedding], anns_field="vector", param={}, limit=5, output_fields=["_id", "subject", "description"], expr=f'status == "new" and organization_id == {org_id}')
st.write(results[0]) # debug output just for now
if len(results[0]) > 0 and results[0].distances[0] < 0.35:
matching_ticket = results[0][0].entity
st.write(f"This case seems very similar to {matching_ticket.get('subject')} (id #{matching_ticket.get('_id')}). Make sure it has not been submitted before")
else:
st.write("Submitted!")
Hier passieren mehrere Dinge:
Die Verbindung zum Milvus-Cluster wird eingerichtet.
Der OpenAI-Dienst wird verwendet, um ein Embedding der vom Benutzer eingegebenen Beschreibung zu erzeugen.
Eine Ähnlichkeitssuche wird durchgeführt, wobei die Ergebnisse nach dem Ticketstatus und der Organisations-ID gefiltert werden (da nur offene Tickets derselben Organisation relevant sind).
Wenn es Ergebnisse gibt und der Abstand zwischen den Embedding-Vektoren des vorhandenen Tickets und des neu eingegebenen Textes unter einem bestimmten Schwellenwert liegt, weisen Sie auf diese Tatsache hin.
Um die neue App auszuführen, müssen Sie zuerst die Umgebungsvariablen für OpenAI und Milvus setzen:
export MILVUS_TOKEN=...
export MILVUS_URL=https://...
export OPENAI_API_KEY=sk-...
streamlit run app.py
Wenn versucht wird, ein Ticket einzureichen, das bereits existiert, sieht das Ergebnis so aus:
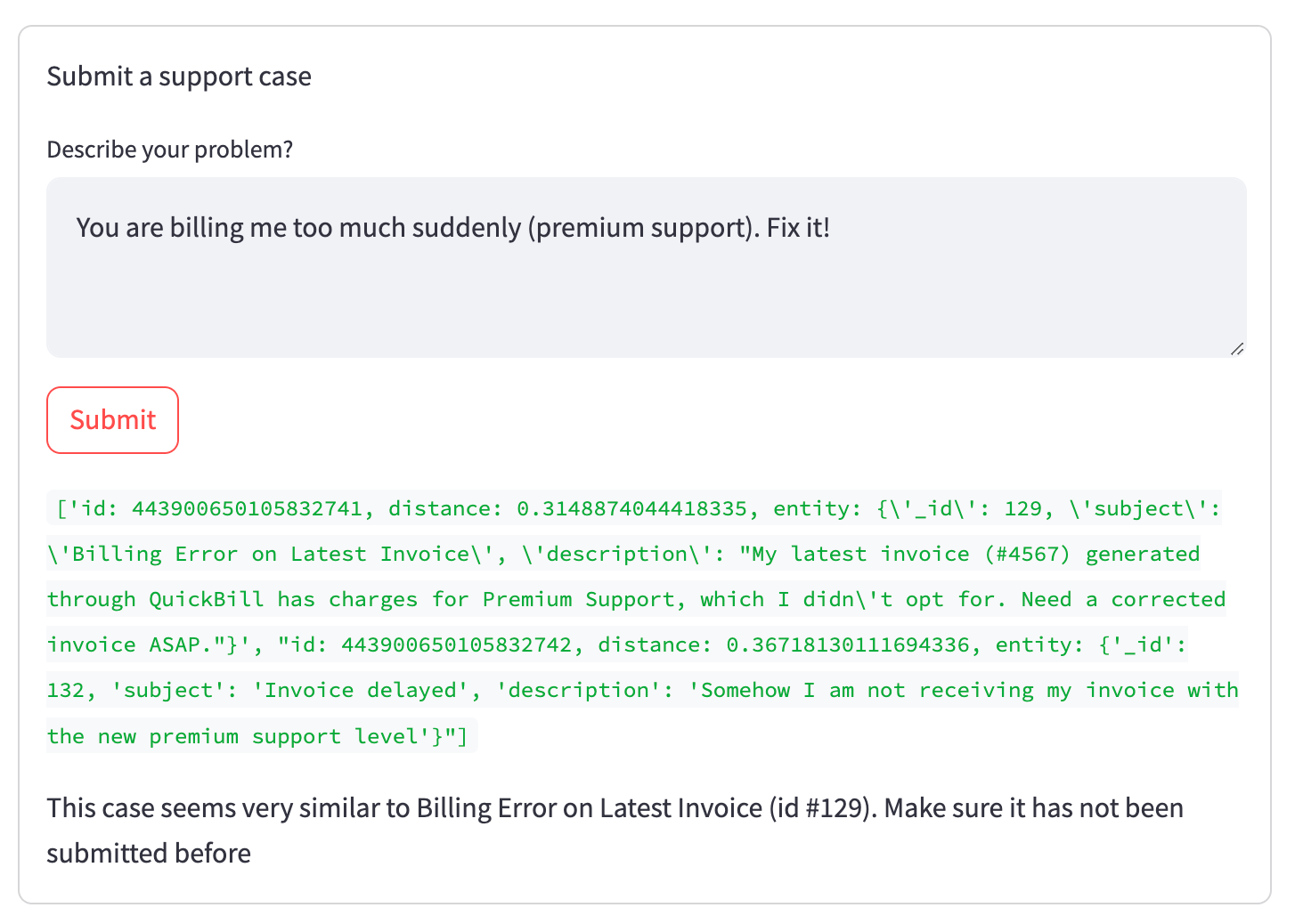
Der Code für dieses Beispiel ist auch auf GitHub zu finden.
Wie Sie in der grünen Debug-Ausgabe sehen können, die in der finalen Version ausgeblendet ist, stimmten zwei Tickets mit unserer Suche überein (im Status „new“, von der aktuellen Organisation und nahe am Embedding-Vektor). Das erste (relevante) wurde jedoch höher eingestuft als das zweite (in dieser Situation irrelevante), was sich im niedrigeren Distanzwert widerspiegelt. Diese Beziehung wird in den Embedding-Vektoren erfasst, ohne dass Wörter direkt übereinstimmen müssen, wie bei einer normalen Volltextsuche.
Zum Abschluss zeigen wir hilfreiche Informationen an, nachdem das Ticket eingereicht wurde, um dem Benutzer von Anfang an so viele relevante Informationen wie möglich zu geben.
Dazu führen wir eine zweite Suche aus, nachdem das Ticket eingereicht wurde, um die am besten passenden Knowledge-Base-Artikel abzurufen:
article_results = collection.search(data=[embedding], anns_field="vector", param={}, limit=5, output_fields=["title", "html_url"], expr=f'_ab_stream == "articles"')
st.write(article_results[0])
if len(article_results[0]) > 0:
st.write("We also found some articles that might help you:")
for hit in article_results[0]:
st.write(f"* [{hit.entity.get('title')}]({hit.entity.get('html_url')})")
Wenn es kein offenes Support-Ticket mit einem hohen Ähnlichkeitswert gibt, wird das neue Ticket eingereicht und relevante Wissensartikel werden darunter angezeigt:
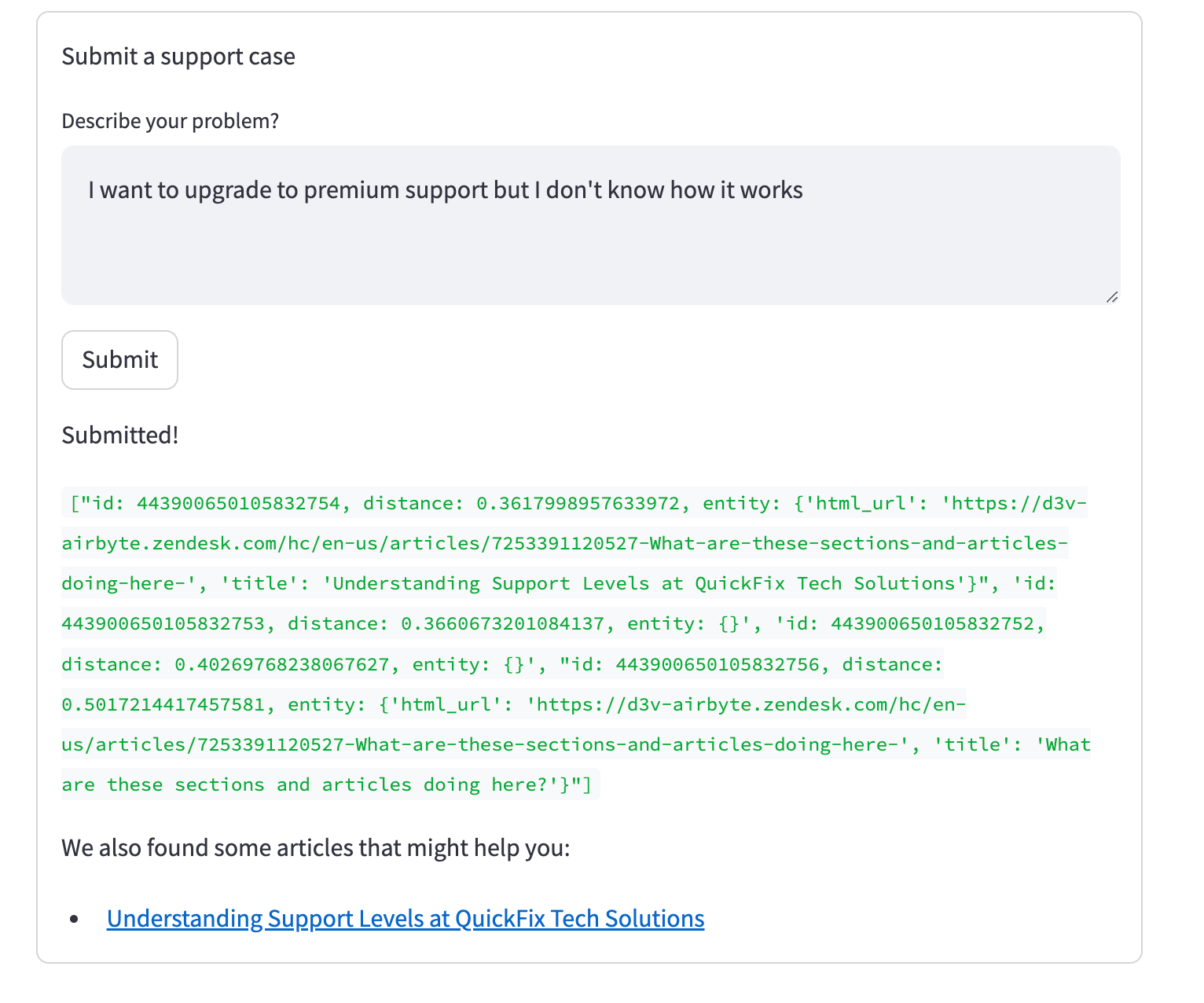
Der Code für dieses Beispiel ist auch auf Github zu finden.
Während die hier gezeigte UI kein tatsächliches Support-Formular ist, sondern ein Beispiel zur Veranschaulichung des Anwendungsfalls, ist die Kombination aus Airbyte und Milvus sehr leistungsstark — sie erleichtert das Laden von Text aus einer Vielzahl von Quellen (von Datenbanken wie Postgres über APIs wie Zendesk oder GitHub bis hin zu vollständig benutzerdefinierten Quellen, die mit Airbytes SDK oder Visual Connector Builder erstellt wurden) und seine Indexierung in eingebetteter Form in Milvus, einer leistungsstarken Vektorsuchmaschine, die auf riesige Datenmengen skalieren kann.
Airbyte und Milvus sind Open Source und auf Ihrer Infrastruktur vollständig kostenlos nutzbar, mit Cloud-Angeboten, um den Betrieb bei Bedarf auszulagern.
Über den in diesem Artikel veranschaulichten klassischen Anwendungsfall der semantischen Suche hinaus kann das allgemeine Setup auch verwendet werden, um einen Frage-Antwort-Chatbot mithilfe der RAG-Methode (Retrieval Augmented Generation), Empfehlungssysteme zu erstellen oder dabei zu helfen, Werbung relevanter und effizienter zu machen.

Weiterlesen

Zilliz Skills Breakdown: How AI Agents Master Vector Databases
Zilliz's Milvus Skill (pymilvus, 7 files) and Zilliz Cloud Skill (zilliz-cli, 14 modules) bring vector-DB dev and ops into one Claude Code session.

How Zilliz Ended Up at the Center of NVIDIA’s Unstructured Data Story at GTC 2026
If unstructured data is the context of AI, then the ceiling of AI applications will be set not just by models, but by how mature the infrastructure for unstructured data becomes.

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.