




Infrastruktur-Herausforderungen bei der Skalierung von RAG mit benutzerdefinierten KI-Modellen
Retrieval Augmented Generation (RAG) Systeme haben KI-Anwendungen erheblich verbessert, indem sie genauere und kontextbezogene Antworten liefern. Die Skalierung und der Einsatz dieser Systeme in der Produktion sind jedoch mit erheblichen Herausforderungen verbunden, da sie immer ausgefeilter werden und benutzerdefinierte KI-Modelle enthalten.
Während eines kürzlich von Zilliz veranstalteten Unstructured Data Meetup teilte Chaoyu Yang, der Gründer und CEO von BentoML, seine Erkenntnisse über die infrastrukturellen Hürden bei der Skalierung von RAG-Systemen mit benutzerdefinierten KI-Modellen und hob hervor, wie Tools wie BentoML die Bereitstellung und Verwaltung dieser Komponenten vereinfachen könnten. In diesem Beitrag werden die wichtigsten Punkte von Chaoyu Yang zusammengefasst und fortgeschrittene Inferenzmuster und Optimierungstechniken untersucht. Diese Strategien werden Ihnen helfen, RAG-Systeme aufzubauen, die nicht nur leistungsstark, sondern auch effizient und kostengünstig sind.
Sehen Sie sich die Aufzeichnung von Chaoyus Vortrag auf Youtube an
Wie RAG KI-Anwendungen stärkt
Retrieval Augmented Generation (RAG) Systeme sind entstanden, um das Problem der Halluzinationen in GenAI-Anwendungen zu lösen. Durch die Integration der Vektor-Ähnlichkeitsabfrage-Fähigkeiten von Vektor-Datenbanken wie Milvus und Zilliz Cloud mit der generativen Kraft von großen Sprachmodellen (LLMs), ermöglichen RAG-Systeme KI-Modellen, Antworten zu produzieren, die sind:
genauer sind
kontextuell relevant sind
Unglaublich informativ
Ohne Halluzinationen
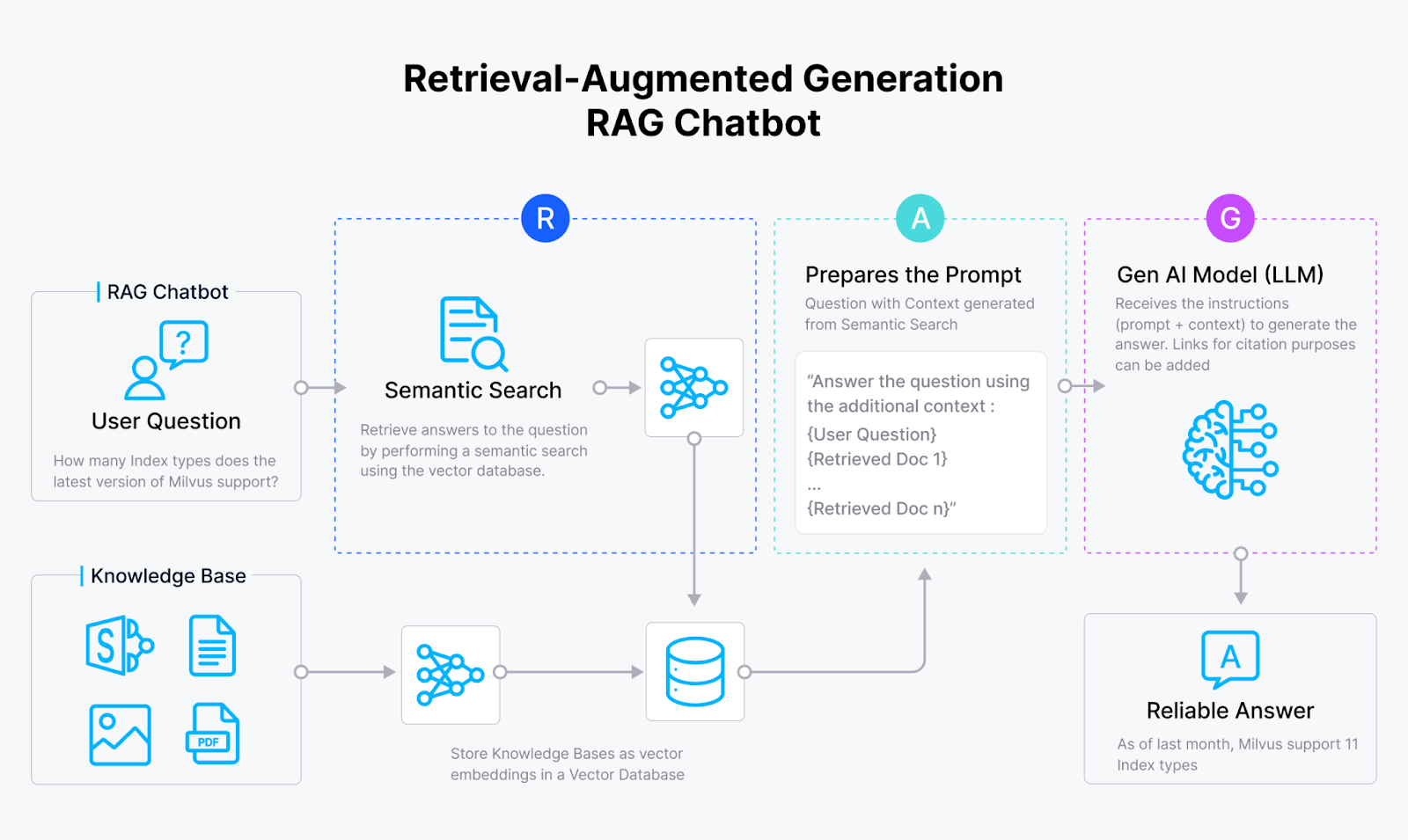
Wie ein RAG Chatbot funktioniert
Diese Systeme haben das Potenzial, eine Vielzahl von Bereichen zu verändern, darunter:
Fragebeantwortung
Zusammenfassung von Dokumenten
Personalisierte Inhaltserstellung
Und mehr.
Die RAG-Systeme erreichen dieses Ziel, indem sie wie eine Art KI-Bibliothekar das riesige Wissen anzapfen, das in externen Quellen verborgen ist!
Herausforderungen beim Einsatz von RAG-Systemen in der Produktion
RAG-Systeme haben ihre eigenen Herausforderungen zu bewältigen, bevor sie in Produktionsumgebungen zum Einsatz kommen können. Eine der größten Hürden ist die Sicherstellung einer erstklassigen Abrufleistung, was Folgendes beinhaltet:
Optimierung des Abrufs: Sicherstellung, dass alle relevanten Informationen abgerufen werden
Optimierung der Präzision: Minimierung der Menge irrelevanter Informationen
Um die Sache noch interessanter zu machen, müssen RAG-Systeme oft mit komplexen, unstrukturierten Datenquellen umgehen. Stellen Sie sich vor, Sie müssten eine PDF-Datei mit mehr Layouts, Tabellen und Bildern als ein Comic-Heft verarbeiten! Dieses Problem erfordert einige ausgefeilte Techniken zur Verarbeitung und zum Verständnis von Dokumenten.
Eine weitere Herausforderung, der sich RAG-Systeme stellen müssen, ist die Generierung von Antworten, die akkurat, kontextbezogen und auf die Absicht des Benutzers abgestimmt sind. Es ist, als würde man eine zusammenhängende Geschichte schreiben, indem man nur Ausschnitte aus verschiedenen Büchern verwendet!
Außerdem muss die Sicherheit und Vertrauenswürdigkeit der generierten Inhalte gewährleistet sein, vor allem, wenn viel auf dem Spiel steht. Wir wollen nicht, dass unsere KI-Systeme abtrünnig werden und Fehlinformationen verbreiten!
Benutzerdefinierte KI-Modelle sind der treue Helfer in dieser Geschichte. Durch die Feinabstimmung und Anpassung von KI-Modellen an bestimmte Bereiche und Datensätze können Entwickler ihren RAG-Systemen die Superkräfte verleihen, die sie benötigen, um diese Herausforderungen frontal anzugehen.
Nutzung benutzerdefinierter KI-Modelle für höhere RAG-Leistung
Um das volle Potenzial von RAG-Systemen auszuschöpfen, ist es entscheidend, benutzerdefinierte KI-Modelle zu nutzen, die auf unseren spezifischen Anwendungsfall zugeschnitten sind. Durch Feinabstimmung und Optimierung dieser Modelle können wir ihre Leistung erheblich steigern. Lassen Sie uns einige Schlüsselbereiche erkunden, in denen benutzerdefinierte KI-Modelle einen signifikanten Einfluss haben können.
Modelle zur Texteinbettung: Die Grundlage des RAG-Erfolgs
Standardmodelle für die Texteinbettung, wie "text-embedding-ada-002", sind oft nicht in der Lage, die Feinheiten unserer spezifischen Domäne zu erfassen. Dieses Modell liegt auf Platz 57 der [MTEB-Rangliste] (https://zilliz.com/glossary/massive-text-embedding-benchmark-(mteb)), was auf erheblichen Verbesserungsbedarf hinweist.
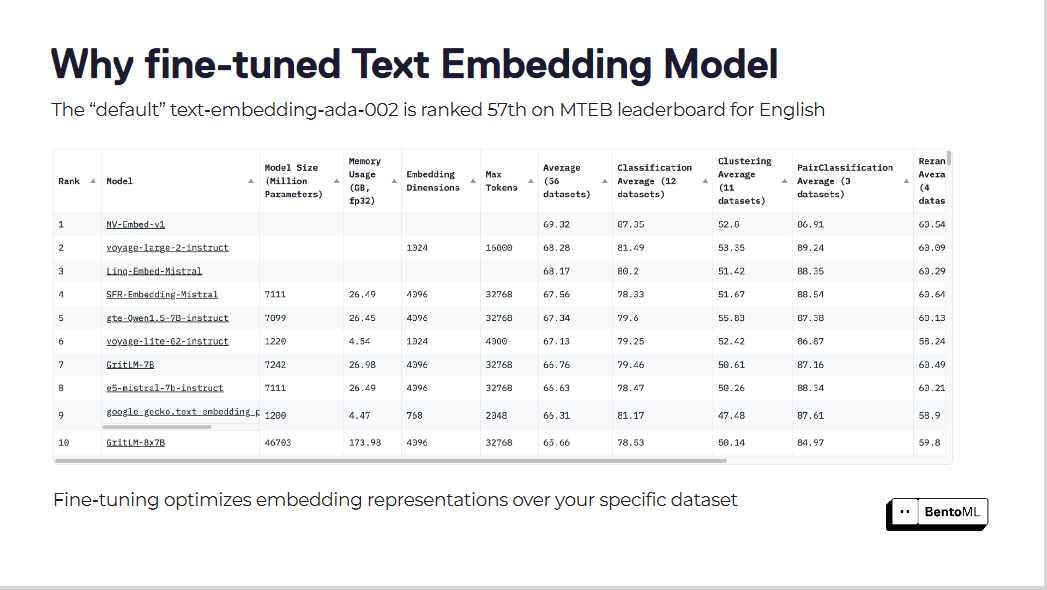
Die Feinabstimmung optimiert die Einbettungsdarstellungen für Ihren spezifischen Datensatz
Die Feinabstimmung dieser Einbettungsmodelle kann zu bemerkenswerten Verbesserungen bei den Suchergebnissen führen. Durch die Optimierung von Einbettungsmodellen für ihre spezifischen Datensätze haben RAG-Systeme erhebliche Leistungssteigerungen erfahren.
Hosting unserer LLMs: Die Kontrolle übernehmen
Proprietäre LLMs bieten Komfort, entsprechen aber nicht immer unseren Bedürfnissen oder Einschränkungen. Open-Source-LLMs ermöglichen es uns, die Modelle an unsere Bedürfnisse anzupassen und zu verändern. Wenn wir unsere LLMs hosten, sollten wir die folgenden Schlüsselfaktoren berücksichtigen:
Sicherheit und Datenschutz
Latenzzeit und Leistung
Erforderliche spezifische Fähigkeiten
Kosten und Skalierbarkeit
Wartung und Unterstützung
Dokumentenverarbeitung und -verstehen: Gewinnung von Erkenntnissen aus unstrukturierten Daten
RAG-Systeme müssen oft komplexe, unstrukturierte Dokumente wie PDFs, Bilder usw. verarbeiten und verstehen. Die Integration verschiedener Modelle und Techniken kann helfen, wertvolle Erkenntnisse zu gewinnen. Zum Beispiel können wir durchführen:
Layout-Analyse mit LayoutLM
Tabellenerkennung mit Table Transformers TATR
OCR mit EasyOCR oder Tesseract
Visuelle Dokumenten-QS mit LayoutLM v3 oder Donut
Die Feinabstimmung dieser Modelle für Ihre spezifischen Dokumenttypen kann deren Leistung erheblich verbessern.
Fortgeschrittene Techniken für verbesserte Retrieval-Genauigkeit
Um die Abrufgenauigkeit weiter zu verbessern, können wir die folgenden Techniken einsetzen:
Kontextbezogenes Chunking und globales konzeptbezogenes Chunking: Diese Methoden helfen dabei, die relevantesten Informationen für die Suche zu identifizieren, indem sie den Kontext und übergreifende Konzepte innerhalb der Dokumente berücksichtigen.
Metadatenextraktion: Die Extraktion von Metadaten aus Dokumenten kann zusätzlichen Kontext für eine verbesserte Abfrage und Antwortsynthese liefern.
Rerankermodelle: Die Feinabstimmung von Re-Rankermodellen an benutzerdefinierten Datensätzen kann zu einer um 10-30 % besseren Leistung führen als bei allgemeinen Modellen.
Durch den Einsatz kundenspezifischer KI-Modelle in diesen Schlüsselbereichen können wir die Leistung unseres RAG-Systems erheblich steigern.
Die effiziente Bereitstellung und Nutzung dieser Modelle bringt jedoch eine Reihe von Herausforderungen mit sich. Im nächsten Abschnitt werden wir einige infrastrukturelle Herausforderungen bei der Skalierung von RAG mit benutzerdefinierten Modellen diskutieren.
Infrastruktur-Herausforderungen bei der Skalierung der RAG mit benutzerdefinierten Modellen
Da RAG-Systeme immer komplexer werden und mehrere benutzerdefinierte Modelle enthalten, steigen die Anforderungen an die Rechenressourcen und die Notwendigkeit einer effizienten Bereitstellung und Verwaltung erheblich. Die Skalierung von RAG-Systemen (Retrieval Augmented Generation) mit benutzerdefinierten KI-Modellen wird zu einem dringenden Erfordernis, ist jedoch mit einer Reihe einzigartiger Infrastrukturprobleme verbunden.
Effiziente Bereitstellung von APIs für benutzerdefinierte Modellinferenzen
Eine der größten Herausforderungen ist die effiziente Bereitstellung von benutzerdefinierten Modellinferenz-APIs. RAG-Systeme erfordern oft die Integration von mehreren Modellen, wie z.B.:
Modelle zur Texteinbettung
Große Sprachmodelle (LLMs)
Modelle für die Dokumentenverarbeitung
Jedes Modell kann unterschiedliche Berechnungsanforderungen und Leistungsmerkmale haben. Die Bereitstellung dieser Modelle als Inferenz-APIs, die Echtzeitanfragen verarbeiten und mit der Nachfrage skalieren können, ist komplex.
Um diese Herausforderung zu meistern, ist eine robuste und skalierbare Infrastruktur für die Bereitstellung von Modell-Inferenz-APIs unerlässlich. Diese Infrastruktur sollte in der Lage sein, die spezifischen Anforderungen jedes Modells zu erfüllen, z. B. GPU-Zuweisung, Speicherverwaltung und Latenzbeschränkungen. Containerisierungstechnologien wie Docker können dabei helfen, Modellabhängigkeiten zu kapseln und eine konsistente Laufzeitumgebung für verschiedene Systeme zu schaffen.
Effiziente Skalierungsmechanismen
Die einfache Containerisierung von Modellen reicht jedoch nicht aus. Die Infrastruktur muss auch effiziente Skalierungsmechanismen unterstützen, um unterschiedliche Arbeitslasten zu bewältigen. Dazu gehört die automatische Skalierung der Anzahl der Modellinstanzen auf der Grundlage des eingehenden Anforderungsaufkommens, die Gewährleistung einer optimalen Ressourcennutzung und die Minimierung der Antwortzeiten.
Optimierung der Modellbereitstellung
Eine weitere wichtige Herausforderung ist die Optimierung der Modellbereitstellung im Hinblick auf Leistung und Kosteneffizienz. Benutzerdefinierte KI-Modelle, insbesondere große Sprachmodelle, können sehr rechenintensiv sein. Naive Bereitstellungsstrategien können zu einer suboptimalen Ressourcennutzung und erhöhten Kosten führen. Techniken wie die dynamische Stapelverarbeitung, bei der mehrere Anfragen gruppiert werden, um die Parallelität von Grafikprozessoren zu nutzen, können den Durchsatz erheblich verbessern und die Antwortzeiten verkürzen.
Neben der dynamischen Stapelverarbeitung können auch andere Optimierungstechniken wie Quantisierung, Pruning und Modelldestillation angewandt werden, um den Speicherbedarf und die Rechenanforderungen von benutzerdefinierten Modellen zu reduzieren. Die Implementierung dieser Optimierungen erfordert jedoch eine sorgfältige Abwägung der Kompromisse zwischen Modellleistung und Ressourceneffizienz.
Effiziente Ressourcenzuweisung und automatische Skalierung
Effiziente Ressourcenzuweisung und automatische Skalierung sind ebenfalls wichtige Aspekte bei der Skalierung von RAG-Systemen mit benutzerdefinierten Modellen. Die Infrastruktur sollte in der Lage sein, Ressourcen dynamisch zuzuweisen, basierend auf den Workload-Anforderungen der einzelnen Modelle. Dieser Ansatz umfasst die Überwachung wichtiger Metriken wie GPU-Auslastung, Speichernutzung und Anfragelatenz, um fundierte Skalierungsentscheidungen zu treffen. Die Mechanismen zur automatischen Skalierung sollten in der Lage sein, plötzliche Spitzen im Datenverkehr zu bewältigen und die Ressourcen entsprechend zu skalieren, um eine optimale Leistung zu gewährleisten.
Zusammenstellung und Orchestrierung mehrerer Modelle
Darüber hinaus muss die Infrastruktur die Komposition und Orchestrierung mehrerer Modelle innerhalb eines RAG-Systems unterstützen. RAG-Systeme beinhalten oft komplexe Pipelines, bei denen die Ausgabe eines Modells als Eingabe für ein anderes dient. Die Infrastruktur sollte Werkzeuge und Frameworks für die Definition und Verwaltung dieser Pipelines bereitstellen, um einen nahtlosen Datenfluss und eine effiziente Ausführung zu gewährleisten.
Überwachung und Beobachtbarkeit
Überwachung und Beobachtbarkeit sind entscheidend für die Aufrechterhaltung des Zustands und der Leistung von RAG-Systemen mit benutzerdefinierten Modellen. Die Infrastruktur sollte umfassende Überwachungsfunktionen bieten, um wichtige Metriken, Protokolle und Traces für alle Systemkomponenten zu verfolgen. Dies ermöglicht eine schnelle Erkennung und Diagnose von Problemen sowie die Optimierung und Feinabstimmung des Systems auf der Grundlage realer Leistungsdaten.
Kontinuierliche Integration und Bereitstellung (CI/CD)
Schließlich sollte die Infrastruktur die kontinuierliche Integration und Bereitstellung von benutzerdefinierten Modellen (CI/CD) unterstützen. Wenn Modelle aktualisiert und verfeinert werden, sollte ein rationalisierter Prozess für die Bereitstellung neuer Versionen eingerichtet werden, ohne das Gesamtsystem zu unterbrechen. Dies erfordert robuste Versionierungs-, Test- und Rollback-Mechanismen, um die Stabilität und Zuverlässigkeit des RAG-Systems zu gewährleisten.
Die Bewältigung dieser infrastrukturellen Herausforderungen erfordert eine Kombination aus Tools, Frameworks und Best Practices. Im nächsten Abschnitt werden wir untersuchen, wie BentoML, eine Plattform für die Bereitstellung und den Einsatz von Machine-Learning-Modellen, dabei helfen kann, diese Herausforderungen zu bewältigen und die Skalierung von RAG-Systemen mit benutzerdefinierten KI-Modellen zu vereinfachen.
Erstellung von Inferenz-APIs für eigene Modelle mit BentoML
BentoML vereinfacht den Prozess der Erstellung und des Einsatzes von Inferenz-APIs für benutzerdefinierte Modelle in RAG-Systemen. Es bietet einen nahtlosen Übergang von der Modellentwicklung zu produktionsreifen APIs und ermöglicht so schnellere Iterationen und eine einfachere Integration in bestehende Systeme. Schauen wir uns an, wie es uns helfen kann, die Herausforderungen der Infrastruktur für die Skalierung von RAG zu überwinden.
Vom Inferenzskript zum Serving Endpoint
Mit nur wenigen Zeilen Code können Sie Ihr Inferenzskript mit BentoML leicht in einen Serving-Endpunkt umwandeln. Werfen wir einen Blick auf ein Beispiel für die Erstellung eines BentoML-Dienstes für ein fein abgestimmtes Texteinbettungsmodell:
torch importieren
from sentence_transformers import SentenceTransformer, models
class SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model",
device="cuda"
)
def encode(
self,
sentences: t.List[str],
) -> np.ndarray:
return self.model.encode(sentences)
Dieser Codeschnipsel definiert die Klasse SentenceTransformers, um das Einbettungsmodell und seine zugehörigen Methoden zu kapseln. In der Methode __init__`` wird das Modell SentenceTransformermit einem fein abgestimmten Modell initialisiert und auf dem "cuda"-Gerät zum Laufen gebracht. Die Methode ```` _init__ nimmt eine Liste von Sätzen als Eingabe und gibt deren Einbettungen als NumPy-Array zurück.
Um dies in einen BentoML-Dienst zu verwandeln, können Sie die Dekoratoren ``` @bentoml.serviceund @bentoml.api`` hinzufügen:
importieren bentoml
@bentoml.service
class SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model",
device="cuda"
)
@bentoml.api
def encode(
self,
sentences: t.List[str],
) -> np.ndarray:
return self.model.encode(sentences)
Um das Modell bereitzustellen, können Sie die BentoML CLI verwenden:
bentoml serve .
Dieser Befehl startet den BentoML-Server und bedient das im aktuellen Verzeichnis definierte Modell. Die CLI-Ausgabe zeigt, dass der Dienst auf [http://localhost:3000](http://localhost:3000) lauscht.
Sie können dann mit dem BentoML-Client Anfragen an das bediente Modell stellen:
importieren bentoml
with bentoml.SyncHTTPClient("http://localhost:3000") as client:
result: np.NDArray = client.encode(
sentences=["Beispieleingabesatz"],
)
Optimierungen beim Servieren
BentoML bietet mehrere sofort einsatzbereite Dienstoptimierungen. Eine der leistungsfähigsten Optimierungen ist die dynamische Stapelverarbeitung. Durch Hinzufügen des Parameters ```Batchable=True`` zu Ihrer API-Definition stapelt BentoML eingehende Anforderungen automatisch, optimiert die GPU-Auslastung und verbessert den Durchsatz für die Modellbereitstellung.
@bentoml.api(batchable=True)
def encode(self, sentences: t.List[str]) -> np.ndarray:
return self.model.encode(sentences)
Die dynamische Stapelverarbeitung bildet auf intelligente Weise kleine Stapel, indem sie eingehende Anfragen gruppiert, große Stapel aufteilt und die Stapelgröße automatisch anpasst. Diese Optimierung kann eine bis zu dreifach schnellere Antwortzeit und eine Verbesserung des Durchsatzes beim Embedding Serving um bis zu 200 % bewirken.
Bereitstellung und Serving-Infrastruktur
BentoML bietet eine flexible und skalierbare Bereitstellung und Infrastruktur für die Bereitstellung. Es unterstützt verschiedene Bereitstellungsoptionen, einschließlich Containerisierung mit Docker und Orchestrierung mit Kubernetes. Sie können die Ressourcenanforderungen, z. B. die Anzahl und den Typ der GPUs, einfach festlegen und Verkehrseinstellungen wie Gleichzeitigkeit und externe Warteschlangen konfigurieren.
bentoml importieren
@bentoml.service(
resources={
"gpu": 1,
"gpu_type": "nvidia-tesla-t4",
},
traffic={
"concurrency": 512,
"external_queue": True
}
)
class SentenceTransformers:
def __init__(self):
...
@bentoml.api(batchable=True)
def encode(
...
):
...
Die adaptiven Micro-Batching- und elastischen Skalierungsfunktionen von BentoML gewährleisten eine optimale Ressourcennutzung und automatische Skalierung auf der Grundlage des eingehenden Datenverkehrs. Außerdem bietet es ein benutzerfreundliches Bereitstellungs-Dashboard, das Einblicke in die Anfragerate, die Antwortzeit und die Ressourcennutzung bietet. Als Nächstes wollen wir uns ansehen, wie LLM-Inferenz mit BentoML skaliert werden kann.
Skalierung von LLM-Inferenzdiensten mit BentoML
BentoML bietet umfassende Funktionen und Optimierungen, die Sie bei der effizienten Skalierung Ihrer LLM-Inferenzdienste unterstützen.
Strategien zur automatischen Skalierung
Die Autoskalierung stellt sicher, dass Ihre LLM-Inferenzdienste unterschiedliche Arbeitslasten bewältigen und eine optimale Leistung beibehalten können. Herkömmliche Autoskalierungsmetriken wie GPU-Auslastung und Abfragen pro Sekunde (QPS) spiegeln jedoch möglicherweise nicht genau die gewünschte Anzahl von Replikaten für LLM-Dienste wider.
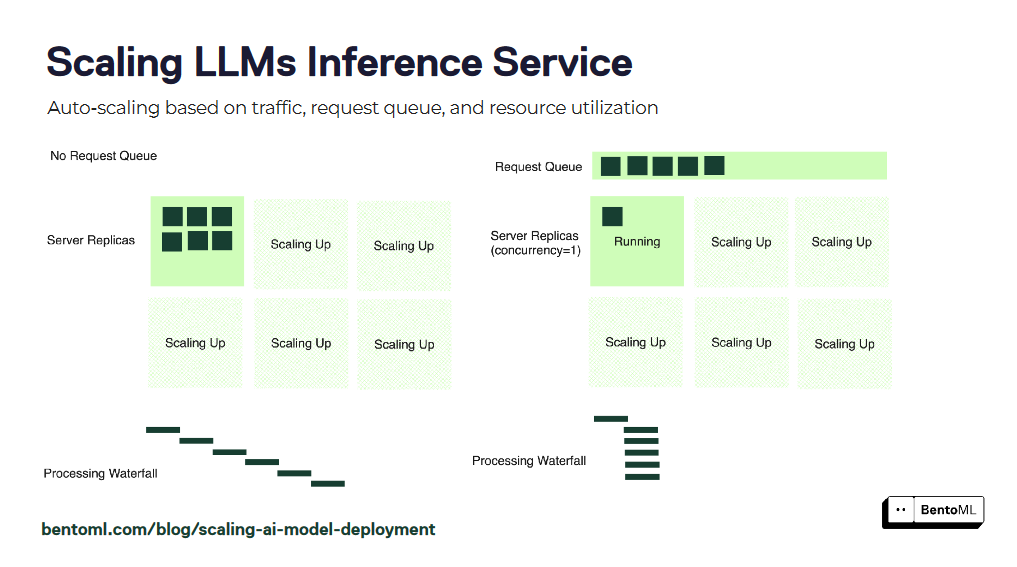
BentoML führt die nebenläufigkeitsbasierte Autoskalierung ein, einen effektiveren Ansatz zur Skalierung von LLM-Inferenzdiensten. Die nebenläufigkeitsbasierte Autoskalierung berücksichtigt die Anzahl der gleichzeitigen Anfragen, die jedes Modellreplikat verarbeiten kann, und liefert so eine genauere Darstellung der Kapazität des Dienstes.
Kaltstart-Optimierung
Kaltstarts können bei der Skalierung von LLM-Inferenzdiensten eine große Herausforderung darstellen, insbesondere bei großen Container-Images und Modelldateien. BentoML bietet mehrere Optimierungstechniken zur Verringerung der Kaltstartlatenz.
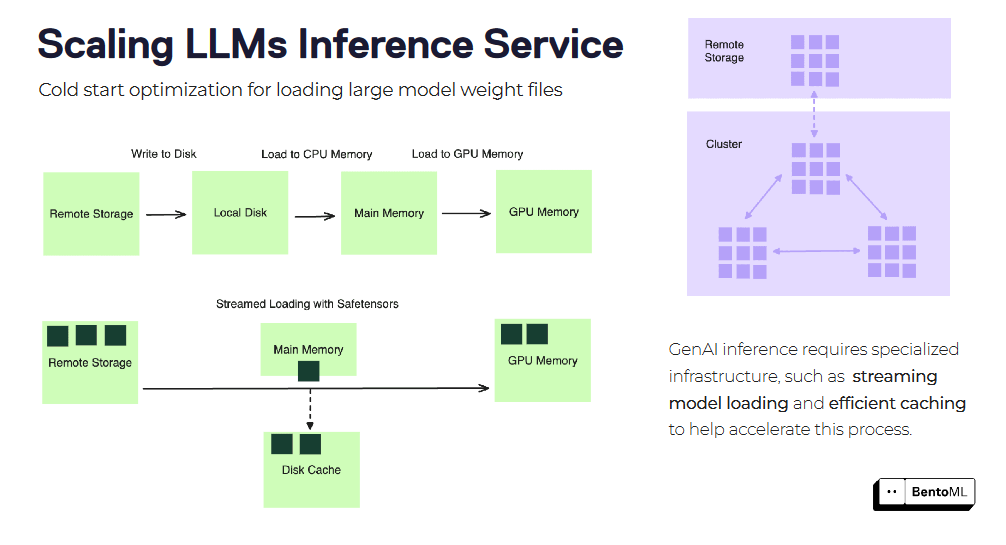
Eine dieser Techniken ist das Stream-Loading von Container-Images. Anstatt das gesamte Container-Image vor dem Start des Dienstes herunterzuladen, kann BentoML das Image per Streamload laden, wobei nur die erforderlichen Dateien bei Bedarf abgerufen werden. Dies kann die Startzeit für neue Replikate erheblich reduzieren.
Eine weitere Optimierung ist das effiziente Laden und Zwischenspeichern von Modellgewichtungsdateien. BentoML kann die geladenen Modellgewichte über die Replikate hinweg zwischenspeichern, wodurch die Zeit, die zum Laden des Modells für jede neue Anforderung benötigt wird, reduziert wird. Dies ist besonders vorteilhaft für große Sprachmodelle mit umfangreichen Gewichtungsdateien.
Durch die Nutzung der automatischen Skalierungsstrategien und Kaltstart-Optimierungen von BentoML können Sie Ihre LLM-Inferenzdienste effektiv skalieren, um die Anforderungen Ihres RAG-Systems zu erfüllen. BentoML abstrahiert die Komplexität der Infrastrukturverwaltung und ermöglicht es Ihnen, sich auf die Entwicklung und Iteration Ihrer Modelle zu konzentrieren und gleichzeitig eine optimale Leistung und Skalierbarkeit zu gewährleisten.
Erweiterte Inferenzmuster für RAG-Systeme
RAG-Systeme erfordern häufig erweiterte Inferenzmuster, um komplexe Arbeitsabläufe zu bewältigen und die Leistung zu optimieren. BentoML bietet ein flexibles und erweiterbares Framework zur Unterstützung dieser Muster, das die Erstellung anspruchsvoller RAG-Systeme mit Leichtigkeit ermöglicht.
Dokumentenverarbeitungspipelines können durch die Kombination mehrerer Modelle und Verarbeitungsschritte, wie Layoutanalyse, Tabellenextraktion und OCR, aufgebaut werden.
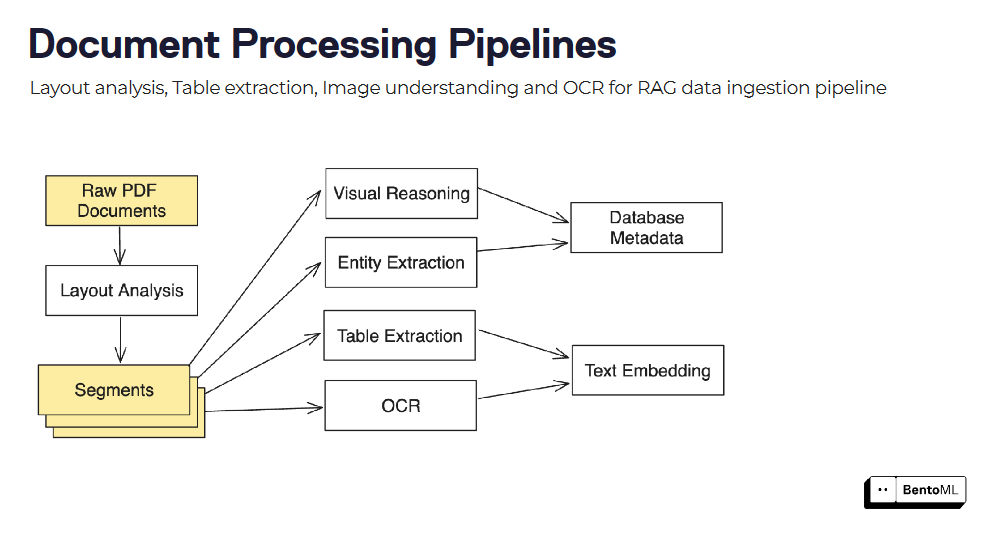
Die asynchrone Inferenzschnittstelle von BentoML bewältigt effizient langlaufende Aufgaben, während die Batch-Inferenzunterstützung die Verarbeitung großer Datensätze unter Nutzung von Parallelität und Optimierungen ermöglicht.
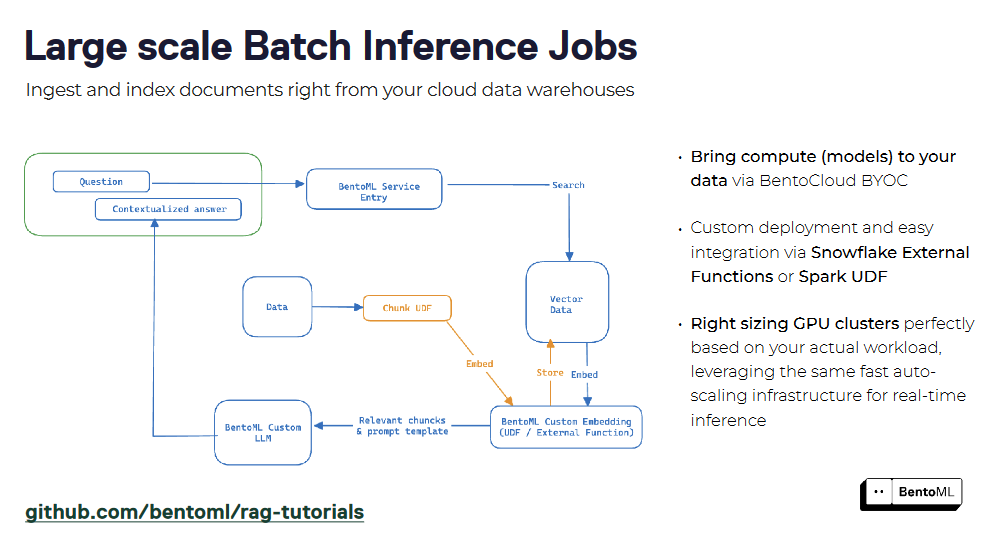
RAG-Systeme können mit BentoML als Dienst verpackt werden, wodurch eine einheitliche Schnittstelle für Abfragen und Interaktion entsteht. Durch die Kapselung von Retriever- und Generator-Komponenten können Sie einen RAG-Dienst einfach bereitstellen und in andere Anwendungen integrieren. Die Unterstützung von BentoML für Containerisierung und Orchestrierung vereinfacht die Skalierung und Verwaltung von RAG-Diensten in Produktionsumgebungen.
Diese fortschrittlichen Inferenzmuster verdeutlichen die Flexibilität und Erweiterbarkeit von BentoML beim Aufbau leistungsfähiger und effizienter RAG-Dienste, die verschiedene Aufgaben und Arbeitslasten bewältigen.
Neben der Infrastruktur zur Bereitstellung von LLMs benötigen wir auch eine robuste Vektordatenbank, um unsere Vektoreinbettungen zu speichern und eine Ähnlichkeitssuche durchzuführen. Hier hilft uns die Milvus-Vektor-Datenbank. Im nächsten Abschnitt werden wir uns mit dem Aufbau einer einfachen RAG-Anwendung mit BentoML und Milvus beschäftigen.
Integration von BentoML und der Milvus-Vektordatenbank
Milvus ist eine Open-Source-Vektordatenbank, die für eine leistungsstarke Ähnlichkeitssuche entwickelt wurde und eine zentrale Infrastrukturkomponente für den Aufbau von Retrieval Augmented Generation (RAG) darstellt.
Milvus wurde in BentoML integriert, was die Erstellung skalierbarer RAG-Anwendungen erleichtert. In diesem Abschnitt werden Sie durch die Erstellung einer RAG-Anwendung mit BentoML und der Milvus-Vektordatenbank geführt. In diesem Beispiel verwenden wir Milvus Lite, die leichtgewichtige Version von Milvus, für schnelles Prototyping.
Der von uns verwendete Datensatz ist hier zu finden: Städtedaten.
Schritt 1: Einrichten der Umgebung
Installieren Sie zunächst die erforderlichen Bibliotheken wie unten gezeigt:
# Erforderliche Bibliotheken installieren
pip install -U pymilvus bentoml
Schritt 2: Bereiten Sie Ihre Daten vor
Laden Sie die [Stadtdaten] herunter und verarbeiten Sie sie (https://github.com/ytang07/bento_octo_milvus_RAG/tree/main/data).
os importieren
importiere Anfragen
import urllib.request
# Einrichten der Datenquelle
repo = "ytang07/bento_octo_milvus_RAG"
directory = "Daten"
save_dir = "./city_data"
api_url = f "https://api.github.com/repos/{repo}/contents/{directory}"
# Dateien von GitHub herunterladen
response = requests.get(api_url)
data = response.json()
if not os.path.exists(save_dir):
os.makedirs(save_dir)
for item in data:
if item["type"] == "file":
file_url = item["download_url"]
file_path = os.path.join(save_dir, item["name"])
urllib.request.urlretrieve(file_url, file_path)
# Verarbeiten der heruntergeladenen Daten
def chunk_text(Dateiname):
with open(Dateiname, "r") as f:
text = f.read()
sentences = text.split("\n")
return [s for s in sentences if len(s) > 7]
städte = os.listdir("stadt_data")
city_chunks = []
for city in cities:
chunked = chunk_text(f "city_data/{city}")
city_chunks.append({
"stadt_name": city.split(".")[0],
"chunks": chunked
})
Schritt 3: BentoML-Clients einrichten
Nun richten wir BentoML-Clients sowohl für das Einbettungsmodell als auch für das LLM ein (siehe unten).
importieren bentoml
# Endpunkte und API-Token einrichten
EMBEDDING_ENDPOINT = "IHR_EINBETTUNGSMODELL_ENDPOINT"
LLM_ENDPOINT = "IHR_LLM_ENDPOINT"
API_TOKEN = "DEIN_API_TOKEN"
# BentoML-Clients initialisieren
embedding_client = bentoml.SyncHTTPClient(EMBEDDING_ENDPOINT, token=API_TOKEN)
llm_client = bentoml.SyncHTTPClient(LLM_ENDPOINT, token=API_TOKEN)
Ersetzen Sie die Platzhalter-Endpunkte und das Token durch Ihre tatsächlichen BentoML-Einsatzendpunkte und das API-Token. Diese Clients ermöglichen es uns, Einbettungen zu generieren und das Sprachmodell für die Texterstellung zu verwenden.
Schritt 4: Einbettungen generieren
Bevor wir Einbettungen generieren, erstellen wir eine Einbettungsfunktion wie unten gezeigt:
Einbettungsfunktion erstellen
def get_embeddings(texts):
# Große Mengen von Texten verarbeiten
if len(texts) > 25:
splits = [texts[x : x + 25] for x in range(0, len(texts), 25)]
Einbettungen = []
for split in splits:
embedding_split = embedding_client.encode(sätze=split)
Einbettungen += Einbettung_Split
return embeddings
# Kleine Stapel direkt verarbeiten
return embedding_client.encode(sätze=texte)
Diese Funktion behandelt die Stapelverarbeitung für große Textsätze, da das Einbettungsmodell möglicherweise Beschränkungen der Eingabegröße hat.
**Einbettungen für alle Chunks erzeugen.
entries = []
for city_dict in city_chunks:
# Einbettungen für die Textabschnitte jeder Stadt ermitteln
embedding_list = get_embeddings(city_dict["chunks"])
# Einträge mit Einbettungen und Metadaten erstellen
for i, Einbettung in enumerate(einbettung_liste):
entry = {
"einbettung": einbettung,
"Satz": city_dict["chunks"][i],
"Stadt": city_dict["city_name"],
}
entries.append(entry)
Hier erstellen wir eine Liste von Einträgen, die jeweils die Einbettung, den ursprünglichen Satz und den Städtenamen enthalten. Diese Struktur wird nützlich sein, wenn Sie Daten in Milvus einfügen.
Schritt 5: Milvus einrichten
Nun werden wir eine Vektordatenbank mit Milvus initialisieren, um die Einbettungen hinzuzufügen.
Milvus-Client initialisieren und Schema erstellen
von pymilvus import MilvusClient, DataType
COLLECTION_NAME = "Bento_Milvus_RAG"
DIMENSION = 384 # Dies sollte der Ausgabedimension Ihres Einbettungsmodells entsprechen
# Milvus-Client initialisieren
milvus_client = MilvusClient("milvus_demo.db")
# Schema erstellen
schema = MilvusClient.create_schema(auto_id=True, enable_dynamic_field=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("einbettung", DataType.FLOAT_VECTOR, dim=DIMENSION)
Wir verwenden hier Milvus lite, das in die Anwendung eingebettet ist. Das Schema definiert unsere Datenstruktur in Milvus, einschließlich einer automatisch generierten ID und dem Einbettungsvektor.
Vorbereiten der Index-Parameter und Erstellen einer Sammlung
# Index-Parameter vorbereiten
index_params = milvus_client.prepare_index_params()
index_params.add_index(
field_name="einbettung",
index_type="AUTOINDEX",
metric_type="COSINE",
)
# Sammlung erstellen oder neu erstellen
if milvus_client.has_collection(collection_name=COLLECTION_NAME):
milvus_client.drop_collection(collection_name=COLLECTION_NAME)
milvus_client.create_collection(
sammlung_name=sammlung_name, schema=schema, index_params=index_params
)
Wir verwenden AUTOINDEX, der automatisch den besten Indextyp auf der Grundlage der Daten auswählt. Als Abstandsmetrik für Vektorvergleiche wird Cosinus-Ähnlichkeit verwendet.
Daten in Milvus einfügen
Nun fügen wir die Daten in Milvus ein, wie unten gezeigt
# Einfügen der vorverarbeiteten Daten in Milvus
milvus_client.insert(sammlungsname=SAMMEL_NAME, daten=einträge)
Dieser Schritt fügt alle unsere vorverarbeiteten Daten (Einbettungen und Metadaten) in die Milvus-Sammlung ein.
Schritt 6: RAG implementieren
Um RAG effizient zu implementieren, werden wir drei Funktionen erstellen, um die RAG-Antwort zu generieren, den relevanten Kontext aus der Sammlung abzurufen und die Antwort zu generieren, wie unten gezeigt:
Erstellen Sie eine Funktion für den LLM, um Antworten zu generieren
def generate_rag_response(question, context):
# Prompt für den LLM vorbereiten
prompt = (
f "Sie sind ein hilfreicher Assistent. Beantworten Sie die Frage des Benutzers nur auf der Grundlage des Kontextes: {context}. \n"
f "Die Benutzerfrage lautet {question}"
)
# Erzeugen der Antwort mit Hilfe des LLM
results = llm_client.generate(max_tokens=1024, prompt=prompt)
return "".join(results)
Diese Funktion konstruiert eine Eingabeaufforderung unter Verwendung des abgerufenen Kontexts und der Frage des Benutzers und verwendet dann den LLM, um eine Antwort zu erzeugen.
Erstellen Sie eine Funktion zum Abrufen von relevantem Kontext
def retrieve_context(Frage):
# Einbettung für die Frage generieren
Einbettungen = get_embeddings([Frage])
# Suche nach ähnlichen Vektoren in Milvus
res = milvus_client.search(
collection_name=COLLECTION_NAME,
data=Einbettungen,
anns_field="einbettungen",
limit=5,
output_fields=["Satz"],
)
# Relevante Sätze extrahieren und kombinieren
sentences = [hit["entity"]["sentence"] for hits in res for hit in hits]
return ". ".join(sentences)
Diese Funktion bettet die Frage des Benutzers ein, sucht nach ähnlichen Vektoren in Milvus und ruft die entsprechenden Textabschnitte für den Kontext ab.
Kombinieren Sie die oben genannten Funktionen, um die RAG-Pipeline zu erstellen
def ask_question(question):
# Relevanten Kontext abrufen
context = retrieve_context(frage)
# Antwort auf Basis von Kontext und Frage generieren
return generate_rag_response(frage, kontext)
Diese Funktion verknüpft alles miteinander und erstellt unsere RAG-Pipeline.
Schritt 7: Verwenden Sie Ihr RAG-System
Jetzt können wir unser RAG-System zur Beantwortung von Fragen verwenden, wie unten dargestellt:
# Anwendungsbeispiel
question = "In welchem Zustand befindet sich Cambridge?"
answer = ask_question(Frage)
print(f "Frage: {Frage}")
print(f "Antwort: {Antwort}")
Dieses Beispiel zeigt, wie das RAG-System verwendet werden kann, um eine bestimmte Frage über eine Stadt zu beantworten.
Wichtige Hinweise:
Bevor Sie diesen Code ausführen, stellen Sie sicher, dass Ihre Einbettungs- und großen Sprachmodelle ordnungsgemäß in BentoML eingesetzt werden.
Die Dimension Ihrer Einbettungen (384 in diesem Beispiel) sollte der Ausgabe Ihres Einbettungsmodells entsprechen.
In diesem Setup wird Milvus Lite verwendet, das für kleinere Datensätze geeignet ist. Ziehen Sie eine vollständige Milvus-Bereitstellung auf Docker oder K8s für größere Anwendungen in Betracht.
Die Effektivität des RAG-Systems hängt von der Qualität und der Abdeckung Ihrer ursprünglichen Stadtdaten ab. Stellen Sie sicher, dass Ihr Datensatz umfassend und genau ist, um die besten Ergebnisse zu erzielen.
Durch die Integration von BentoML und Milvus entsteht ein leistungsstarkes RAG-System, das in der Lage ist, Fragen auf der Grundlage der bereitgestellten Stadtinformationen zu beantworten. Sie können dieses System erweitern, indem Sie weitere Daten hinzufügen oder es für bestimmte Anwendungsfälle feinabstimmen.
Schlussfolgerung
Der Aufbau und die Skalierung von Retrieval Augmented Generation (RAG)-Systemen mit benutzerdefinierten KI-Modellen stellt einzigartige Herausforderungen dar. Entwickler können hochperformante und skalierbare RAG-Systeme erstellen, indem sie die Leistungsfähigkeit benutzerdefinierter Modelle nutzen, die Bereitstellungs- und Serving-Infrastruktur optimieren und fortschrittliche Inferenzmuster anwenden.
BentoML ist ein wertvolles Werkzeug auf diesem Weg. Es vereinfacht den Prozess der Erstellung und Bereitstellung von Inferenz-APIs, optimiert die Serviceleistung und ermöglicht eine nahtlose Skalierung.
Durch die Integration von BentoML mit der Milvus-Vektordatenbank können Unternehmen leistungsfähigere, skalierbare RAG-Systeme aufbauen. Diese Kombination ermöglicht den effizienten Abruf relevanter Informationen und die Generierung kontextbezogener Antworten, wodurch sich Möglichkeiten für fortschrittliche KI-Anwendungen in verschiedenen Bereichen und Branchen eröffnen.
Weitere Informationen zu BentoML und RAG finden Sie in den folgenden Ressourcen
RAG ohne OpenAI: BentoML, OctoAI und Milvus - Zilliz Blog](https://zilliz.com/blog/rag-without-open-ai-bentoml-octoai-milvus)
Wie Sie die Leistung Ihrer RAG-Pipeline verbessern können - Zilliz-Blog](https://zilliz.com/learn/how-to-enhance-the-performance-of-your-rag-pipeline)
LLM-Herausforderungen meistern: Eine Erkundung von RAG - Zilliz blog](https://zilliz.com/learn/RAG-handbook)
Ingesting Chaos: The MLOps Behind Handling Unstructured Data Reliable at Scale for RAG (milvus.io)](https://milvus.io/blog/Ingesting-Chaos-MLOps-Behind-Handling-Unstructured-Data-Reliably-at-Scale-for-RAG.md)
Warum Milvus den Aufbau von RAG einfacher, schneller und kosteneffizienter macht - Zilliz Blog](https://zilliz.com/blog/why-milvus-makes-building-rag-easier-faster-cost-efficient)
Weiterlesen

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

A Developer's Guide to Exploring Milvus 2.6 Features on Zilliz Cloud
Milvus 2.6 marks a shift from “vector search + glue code” to a more advanced retrieval engine, and it is now Generally Available (GA) on Zilliz Cloud (a managed Milvus service).

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.