




Vector Lakebase: Beenden Sie das KI-Datensilo
Jedes KI-Team stößt auf dieselbe Mauer — Datenschwerkraft
Jedes moderne Datenteam hat irgendeine Version derselben Architektur aufgebaut. Ein Lakehouse — Iceberg-Tabellen auf S3, eine Spark-Pipeline und Delta Lake für Governance — steht im Zentrum. Es funktioniert gut. Dann kommen die KI-Anforderungen.
Ihre RAG-Pipeline muss Fragen zu 10 Jahren Unternehmensdokumenten beantworten, also kopieren Sie alles in eine Vektordatenbank. Ihre KI-Agenten benötigen Zugriff mit niedriger Latenz auf Produktkatalog-Embeddings — eine weitere Pipeline, ein weiterer Sync-Job. Ihr multimodales Modelltraining erfordert tägliche Deduplizierung über eine Milliarde Bild-Embeddings hinweg — ein Spark-Job, der den Index nicht sehen kann.
Sechs Monate später haben Sie fünf Systeme statt zwei. Ihr Data-Engineering-Team verbringt mehr Zeit mit der Wartung von Synchronisationspipelines als mit dem Aufbau von KI-Funktionen. Sie haben drei Kopien desselben Datensatzes, ohne Garantie, dass sie übereinstimmen. Jede Schemaänderung kaskadiert an vier verschiedene Stellen.
Das ist kein Ausführungsfehler. Es ist ein Architekturfehler — genauer gesagt eine Architektur, die ständig gegen eine grundlegende Eigenschaft von Daten ankämpft: Schwerkraft. Jedes System, das von Ihnen verlangt, zuerst Daten zu kopieren, erhebt eine Schwerkraftsteuer auf Sie. Je mehr KI-Workloads Sie hinzufügen — RAG-Pipelines, Agentenspeicher, Modelltraining, Echtzeit-Empfehlungen — desto höher wird diese Steuer.
Die richtige Lösung ist keine bessere Pipeline. Es sollte ein neues Architekturparadigma sein: Vector Lakebase.
Drei Generationen architektonischer Lösungen, zwei Sackgassen
Bevor wir in die Details von Vector Lakebase eintauchen, lohnt sich ein Blick darauf, wie sich die Vektorsucharchitektur entwickelt hat, um das Problem der Datenschwerkraft anzugehen. Grob betrachtet gab es drei Generationen von Lösungen.
Generation 1: Dedizierte Vektordatenbanken
Dedizierte Vektordatenbanken wie Milvus lösten ein echtes Problem für produktive KI-Systeme: semantische Suche mit Millisekundenlatenz sowie Recall und Performance, die Allzweckdatenbanken nicht erreichen konnten. Als Entwickler der Open-Source-Vektordatenbank Milvus konzentriert sich Zilliz seit Langem darauf, ein zuverlässiges, leistungsstarkes System zum Speichern von Embeddings, Erstellen von Indizes und Bereitstellen von Retrieval mit niedriger Latenz für RAG, Agenten, Empfehlungssysteme, semantische Suche und multimodale Anwendungen aufzubauen. Diese Grundlage ist weiterhin wichtig. Produktive KI-Systeme benötigen weiterhin Retrieval mit Datenbankgeschwindigkeit, und Vektordatenbanken bleiben für viele latenzsensitive Workloads die richtige Serving-Schicht.
Mit zunehmender Reife von KI-Workloads geht die Herausforderung jedoch immer stärker über Online-Serving hinaus. Ein Großteil der Quelldaten eines Unternehmens befindet sich bereits in Objektspeicher, Data Lakes, Lakehouses und nachgelagerten Analysesystemen. Um diese Daten in einer dedizierten Vektordatenbank zu nutzen, kopieren Teams sie typischerweise in ein separates Serving-System, bauen Ingestion-Pipelines, warten Synchronisationsjobs und verwalten die Konsistenz zwischen den Quelldaten und dem Vektorindex. Wenn sich Embedding-Modelle ändern, wie es zwangsläufig geschieht, müssen Teams Embeddings neu generieren, Indizes neu aufbauen und mehrere Systeme aufeinander abstimmen.
Dies ist keine Einschränkung der Performance von Vektordatenbanken. Es ist eine architektonische Grenze, die durch Datenbewegung entsteht. Je mehr Teams dieselben Daten für produktives Retrieval, Embedding-Experimente, Offline-Evaluierung, Governance, Lineage und Analytics nutzen möchten, desto größer wird die betriebliche Angriffsfläche. Dedizierte Vektordatenbanken haben das Problem des Online-Retrievals äußerst gut gelöst, aber für sich genommen beseitigen sie das Problem der Datenschwerkraft nicht.
Generation 2: Vector Lake
Die nächste naheliegende Reaktion bestand darin, die Vektorsuche näher an den Lake zu bringen: Vektoren direkt aus Iceberg-, Delta-Lake- oder Parquet-Dateien abfragen, ohne sie zuvor in ein dediziertes Serving-System zu verschieben. Die Motivation war richtig. Wenn die Daten bereits in Objektspeicher oder einem Lakehouse liegen, warum sie dann irgendwo anders duplizieren, nur um sie durchsuchbar zu machen?
In der Praxis bleiben Vector-Lake-Architekturen für produktive KI-Workloads jedoch aus drei Gründen unvollständig.
Erstens sind sie nicht für Serving mit niedriger Latenz ausgelegt. Die meisten Vector-Lake-Ansätze laden Daten oder Indizes bei Bedarf aus Object Storage und sind stärker auf Flexibilität als auf gleichzeitige, latenzsensitive Anfrageverarbeitung optimiert. Das mag für Offline-Exploration akzeptabel sein, reicht aber nicht für nutzerseitige RAG-, Agenten-, Empfehlungs- oder Suchanwendungen. Wenn eine Retrieval-Pipeline im kritischen Pfad eines LLM-Aufrufs liegt, benötigen Teams vorhersagbare Latenzen unter 100 ms bei hoher Parallelität. Wenn die p99-Latenz regelmäßig in den Sekundenbereich abdriftet, kann das System für Analysen zwar weiterhin nützlich sein, aber nicht als produktive Retrieval-Schicht dienen.
Zweitens enden Vector-Lake-Systeme typischerweise bei der Suchphase. Sie ermöglichen Teams, Vektordaten im Lake abzufragen, bieten aber keine umfassendere Ausführungsumgebung für KI-Datenworkflows. Moderne KI-Systeme benötigen mehr als Nearest-Neighbor Search. Sie müssen Embeddings neu generieren, die Retrieval-Qualität bewerten, Agentengedächtnis komprimieren, Frames aus Videos extrahieren, multimodale Daten verarbeiten, Metadaten verwalten und Daten für Fine-Tuning oder nachgelagerte Pipelines vorbereiten. Ein System, das lediglich Suche auf Lake-Dateien aufsetzt, adressiert nicht den vollständigen Lebenszyklus von Vektor- und multimodalen Daten.
Drittens wurde die zugrunde liegende Speicherschicht nicht für diesen Workload gebaut. Iceberg und Delta Lake wurden für strukturierte analytische Daten entwickelt — keine nativen Vektortypen, keine Indexstrukturen, jede Abfrage ist ein vollständiger Scan. KI-Workloads benötigen schnelle Point Lookups (nicht die sequenziellen Row-Group-Scans von Parquet — Formate wie Vortex und Lance existieren aus diesem Grund), integrierte Indizes, die gemeinsam mit den Daten verwaltet werden, sowie referenzbasiertes Management unstrukturierter Daten, bei dem Bilder, Audio und Video per Referenz verknüpft werden, statt als Blobs inline gespeichert zu werden. Nichts davon existiert heute im Lake. Ein auf Iceberg aufgebauter Vector Lake kämpft auf jeder Ebene gegen die Speicherschicht.
Generation 3: Vector Lakebase
Vector Lakebase entsteht, wenn man aufhört, den Lake und die Vektordatenbank als getrennte Systeme zu behandeln, die synchronisiert werden müssen, und stattdessen beginnt, sie als zwei Betriebsmodi einer einzigen vereinheitlichten Schicht zu bauen. Genauer gesagt:
Eine Vector Lakebase ist eine neue KI-native und Lake-native Architektur, die sich aus Vektordatenbanksystemen entwickelt hat. Sie kombiniert die High-QPS- und Low-Latency-Serving-Fähigkeiten von Vektordatenbanken mit der Offenheit, Skalierbarkeit und Kosteneffizienz multimodaler Data Lakes, während alle Workloads ohne Datenmigration auf derselben Source of Truth bleiben. Durch die Trennung von Compute und Storage speichert eine Vector Lakebase multimodale Daten, Vektoren, Attribute, Indizes und Metadaten direkt in kostengünstigem Object Storage unter Verwendung offener Formate. Serving-, Discovery- und Analytics-Workloads können dann unabhängig voneinander auf denselben Daten ausgeführt werden.
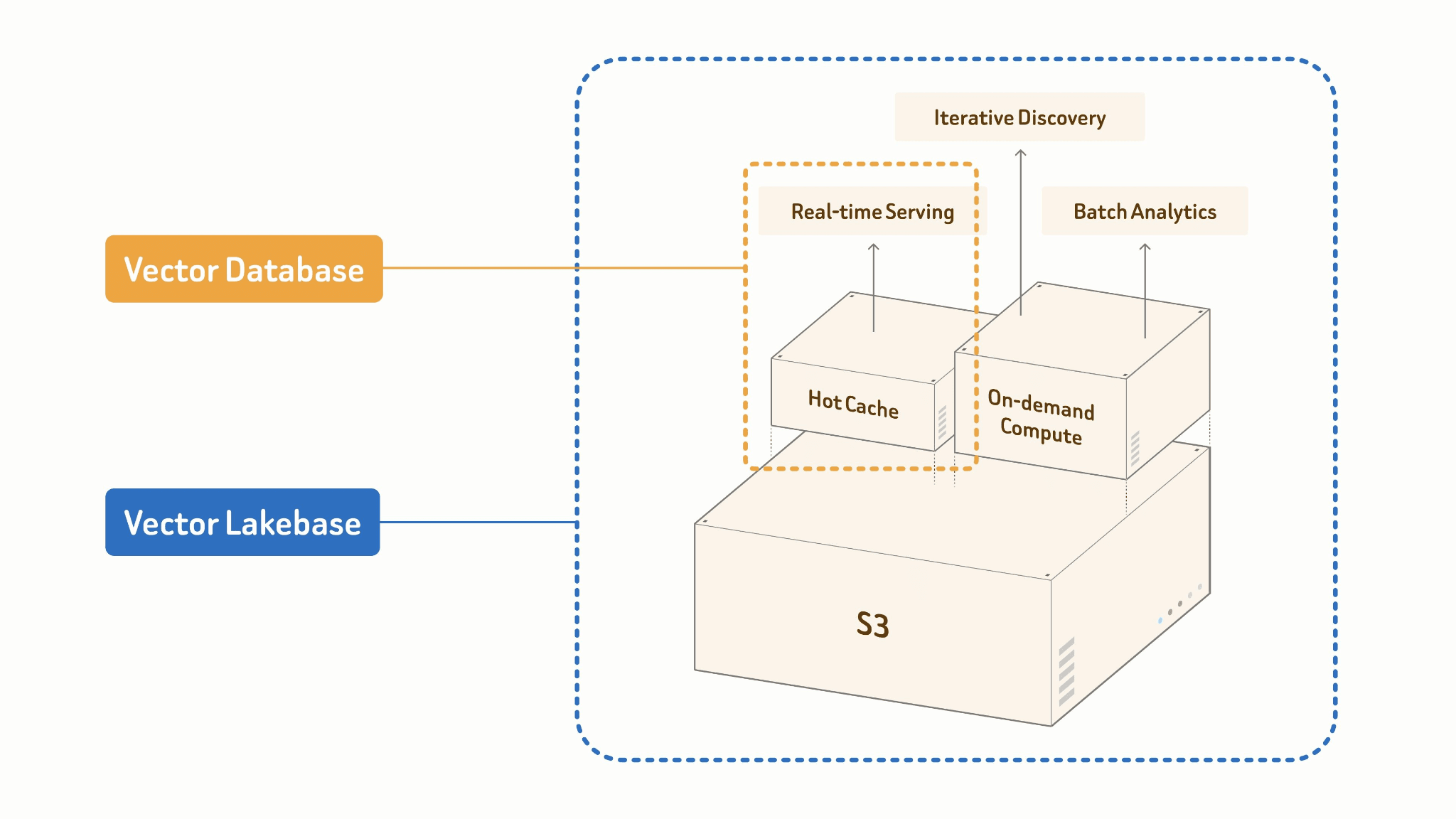
Das Kernprinzip: One Source of Truth.
Ihre Lake-Tabelle ist die einzige Source of Truth. Online-Serving und Offline-Batch-Verarbeitung teilen dieselben Daten, denselben Index und dasselbe Schema. Es gibt keine Pipeline zwischen ihnen, weil es keine Grenze zwischen ihnen gibt.
Vector DB: [Lake] ──ETL──▶ [Vector DB] # Duplizierung + Veralterung
Vector Lake: [Lake + Index] ◀── nur Batch-Abfrage # kein Serving, keine Verarbeitung
Vector Lakebase: [Lake + Index + Compute]
├── Online: Cache + High-performance Index
│ → ANN-Abfrage, <100ms p99 Serving
└── Offline: Batch Processing + Cost-efficient Index Build
→ einbetten, clustern, deduplizieren, Feature Engineering
Die beiden Modi sind notwendigerweise unterschiedlich konzipiert. Online Serving läuft gegen einen Hot Cache und einen leistungsstarken In-Memory-Index — optimiert für Parallelität und Tail Latency. Offline-Batch-Jobs erstellen Indizes kosteneffizient im großen Maßstab: spaltenorientierte Scans, GPU-beschleunigter Aufbau, gestaffelte Schreibvorgänge zurück in den Lake. Gleiche Daten, gleiches Indexformat, radikal unterschiedliche Compute-Profile.
Wie sieht das in der Praxis aus? Bei einer Iceberg-Tabelle mit 1 Milliarde Vektoren:
| Modus | Latenz | Kontext |
|---|---|---|
| Spark-Brute-Force-Scan (kein Index) | Stunden | Heutiger Standard für lakebasierte Vektorsuche |
| Vector Lakebase — kalt (Index gerade erstellt) | ~30 Sekunden | Index wird aus Iceberg in ~20 Minuten erstellt |
| Vector Lakebase — warm (Festplatten-Cache) | Zweistelliger ms-Bereich | Index auf lokaler SSD zwischengespeichert |
| Vector Lakebase — heiß (In-Memory) | Einstelliger ms-Bereich | Production RAG und Agent Serving |
| Vector Lakebase — Clustering / Deduplizierung | Stunden | KMeans mit 1 Mrd. Vektoren oder Erkennung von Fast-Duplikaten, vollständig verteilt |
Sie kommen von Stunden auf einstellige Millisekunden — und Sie kopieren die Daten nie aus dem Lake heraus.
Das ist keine Produktentscheidung. Es ist die Richtung, in die sich KI-Datenarchitektur entwickelt. Jedes System, das verlangt, dass Daten an zwei Orten existieren, erhebt eine dauerhafte Steuer — bei Speicher, bei Engineering-Stunden, bei Veralterung. Systeme, die Storage von KI-Operationen trennen, werden im Rückblick wie Übergangslösungen wirken.
Was eine Vector Lakebase tatsächlich ermöglicht
Mindestens drei Klassen von Workloads, die zuvor separate Systeme erforderten, können jetzt mit einer Vector Lakebase bewältigt werden.
Externe Collections: Machen Sie Ihren Lake durchsuchbar, ohne irgendetwas zu verschieben
Sie haben Petabytes an Embeddings in Parquet-Dateien auf S3. Sie heute für eine neue RAG-Anwendung durchsuchbar zu machen, bedeutet, sie in eine Vektordatenbank zu laden — eine Migration, die in Tagen oder Wochen gemessen wird, plus eine laufende Sync-Verpflichtung.
Die externen Collections von Vector Lakebase arbeiten mit der Data Gravity statt gegen sie. Sie verweisen auf den Bucket, definieren ein Schema-Mapping über Ihre bestehenden Spalten und erstellen einen Vektorindex vor Ort. Die Daten bleiben in S3. Der Index wird zurück nach S3 persistiert. Wenn sich Quelldaten ändern, aktualisieren Sie inkrementell — nur geänderte Dateien werden erneut verarbeitet.
# 1. Register your existing lake data as an external collection
client.create_external_collection(
collection_name="enterprise_docs",
src="s3://my-lake/docs/*.parquet", # point at your existing data
schema={"text": String, "embedding": FloatVector(768)},
)
# 2. Build a vector index — data stays in S3, index persists back to S3
client.create_index("enterprise_docs", field="embedding", index_type="HNSW")
# ~20 min for 1B vectors. Data never moves.
# 3. Search — single-digit ms with in-memory cache
results = client.search(
collection_name="enterprise_docs",
data=[query_embedding],
top_k=10,
output_fields=["text"],
)
Keine Migration, keine Pipeline, keine neuen Speicherkosten. Ihr RAG-System fragt dieselben Daten ab, die Ihr Analytics-Team bereits verwaltet — über Spark, Ray, LangChain, PyMilvus oder eine REST API. Der Index wird zu einer erstklassigen Eigenschaft der Tabelle, nicht zu einem fremden System, das daneben angeflanscht ist.
ETL, Feature Engineering und Context Engineering
Das ist der Workload, den sowohl Vector Database als auch Vector Lake ignorieren — und er wird zum wichtigsten Teil des KI-Daten-Stacks.
KI-native Datenoperationen verschieben Daten nicht nur zwischen Systemen — sie reichern sie mit semantischer Bedeutung an, vor Ort, im großen Maßstab:
- Eine Embedding-Spalte zu einer bestehenden Tabelle hinzufügen: Batch-Inferenz über 100 Mio. Zeilen, Ergebnisse zurück in dieselbe Tabelle schreiben.
- Ein Dokumentenkorpus für RAG in Chunks aufteilen und Rohdokumente sowie Chunks gemeinsam versionieren.
- Von text-embedding-3-small auf ein neueres Modell upgraden — alle 500 Mio. Vektoren direkt vor Ort backfillen, wobei alte und neue Embeddings koexistieren, bis Sie umschalten.
- Die Kontextpakete erstellen und versionieren, die Ihre KI-Agenten zur Laufzeit abrufen — was abgerufen wird, wie es strukturiert ist, wie es für ein Kontextfenster komprimiert wird.
Da Modelle zur Massenware werden, ist die Qualität dessen, womit Sie sie füttern, wichtiger als die Frage, welches Modell Sie wählen. Diese aufkommende Disziplin — Context Engineering — gehört in den Lake: nah an den Daten, gemeinsam mit ihnen versioniert, durchgängig reproduzierbar. Vector Lakebase macht daraus eine erstklassige Operation, nicht ad-hoc Skripte, die mit Cron-Jobs zusammengeklebt werden.
Clustering, Deduplizierung und Anomalieerkennung
Unverzichtbar für jedes Team, das eigene Modelle trainiert oder feinabstimmt — und im Paradigma der Vektordatenbank völlig abwesend:
- Deduplizierung: Nahezu doppelte Beispiele in Ihrem LLM-Fine-Tuning-Datensatz blähen den Trainingsverlust auf und verzerren das Verhalten des Modells. Identifizieren Sie nahezu doppelte Einträge, geben Sie eine kanonische Menge aus, schreiben Sie Deduplizierungs-Labels als Spalte zurück.
- Clustering: Verstehen Sie, was Ihr Datensatz tatsächlich enthält, bevor Sie trainieren. Clustern Sie Ihren Embedding-Raum — oft stellen Sie fest, dass 40 % eines „diversen“ Datensatzes nur geringfügige Variationen derselben wenigen Themen sind.
- Anomalieerkennung: Für autonome Fahrzeuge, Robotik oder jedes sicherheitskritische Modell — finden Sie die 0,1 % der Stichproben, die wie nichts anderes im Rest aussehen. Markieren Sie sie, priorisieren Sie sie für die Label-Erstellung und beziehen Sie sie ins Training ein. Ohne Index können Sie sie nicht finden; ohne das Zurückschreiben der Ergebnisse in den Lake können Sie nicht darauf reagieren.
Vector Lakebase behandelt diese als erstklassige verteilte Operationen: indexbewusst, parallelisiert über die Daten dort, wo sie liegen, und mit Ergebnissen in offenen Formaten. Die Ausgabe eines Deduplizierungslaufs wird zu einer Spalte in derselben Tabelle.
Wer bereits darauf aufbaut
Die frühesten Designpartner von Vector Lakebase decken zwei der schwierigsten KI-Datenprobleme in großem Maßstab ab.
Führende Unternehmen für autonomes Fahren und Elektrofahrzeuge nutzen es, um Grenzfälle aus Milliarden von Embeddings von Fahrszenen zu extrahieren — die seltenen Verkehrsszenarien, die darüber entscheiden, ob ein selbstfahrendes System sicher ist. Ein führendes Foundation-Model-Unternehmen nutzt es für die Erkennung nahezu doppelter Einträge in Pre-Training-Korpora — es dedupliziert Milliarden von Beispielen, um die Modellqualität zu verbessern, bevor auch nur eine einzige GPU-Stunde für das Training aufgewendet wird.
Wir haben bereits Databricks Lakebase. Brauchen wir noch eines?
Das ist eine berechtigte Frage, und die Antwort erfordert zu verstehen, was Databricks Lakebase tatsächlich ist.
Databricks Lakebase — aufgebaut auf der Übernahme von Neon — integriert eine serverlose PostgreSQL-Engine in die Databricks-Plattform. Das Problem, das es löst: OLTP und OLAP waren schon immer getrennte Systeme. Databricks lässt diese Grenze verschwinden. Das ist ein reales Problem, das es zu lösen lohnt. Aber es ist ein grundlegend anderes Problem.
| Databricks Lakebase | Vector Lakebase | |
|---|---|---|
| Primärer Nutzer | Backend-Entwickler, Dateningenieure | ML-Ingenieure, KI-Plattformteams |
| Primäre Daten | Zeilen, Konten, Transaktionen | Embeddings, Dokumente, multimodal |
| Speichermodell | Postgres-Speicher + Delta Lake (separat) | Einzelne Lake-Tabelle, vereinheitlicht |
| Batch-Embedding / Deduplizierung | Nicht im Umfang enthalten | Erstklassige Operation |
| Context Engineering | Nicht im Umfang enthalten | Kernfähigkeit |
| Baut auf dem bestehenden Lake auf | Teilweise | Ja — keine Migration |
| Formatoptimierung | Delta Lake, Parquet | Parquet, Vortex, Lance, Apache Iceberg, native unstrukturierte Daten |
| OLTP (Transaktionen) | ✓ | N/A |
Databricks Lakebase lässt die OLTP/OLAP-Grenze verschwinden. Vector Lakebase lässt die Grenze zwischen dem Ort, an dem Ihre KI-Daten leben, und dem Ort, an dem Ihre KI-Operationen laufen, verschwinden. Diese beiden Ansätze ergänzen sich, sie konkurrieren nicht. Viele Teams werden beide nutzen.
Die architektonische Wette
2013 fragte Databricks: Was wäre, wenn SQL-Analysen im Lake leben würden? Diese Frage war $40 Milliarden wert.
Die nächste Frage lautet: Was wäre, wenn KI-native Datenoperationen — RAG-Retrieval, Agent Memory, Batch Embedding, Kuratierung von Modelltrainingsdaten, Context Engineering — ebenfalls im Lake leben würden?
Das ist die Wette hinter Vector Lakebase. Keine neue Datenbank, zu der man migrieren muss. Keine Abfrageebene, die auf Ihren bestehenden Lake aufgesetzt wird. Eine einheitliche Grundlage, auf der Ihre Daten einmal liegen, einmal indiziert werden und jeden KI-Workload bedienen — ohne Duplizierung, ohne ETL-Overhead, ohne gegen die Schwerkraft anzukämpfen.
Das KI-Rennen belohnt Geschwindigkeit. Jede Woche, die Ihr Team damit verbringt, Sync-Pipelines zu bauen, veraltete Daten zu debuggen oder zwischen Systemen zu migrieren, ist eine Woche, in der Ihre Wettbewerber KI-Features ausliefern. Infrastruktur sollte ein Beschleuniger sein, kein Flaschenhals. Die Teams, die gewinnen, sind nicht die mit den besten Modellen — es sind die, die die Reibung zwischen ihren Daten und ihrer KI beseitigt haben.
Bauen Sie auf Ihren bestehenden Iceberg-Tabellen oder Ihrem Data Lake auf. Keine Migration. Keine Duplizierung. Bewegen Sie sich schnell — Ihre Daten bleiben, wo sie sind, und werden innerhalb von Minuten durchsuchbar, verarbeitbar und KI-bereit.
Das ist Vector Lakebase.
Zilliz Vector Lakebase ist in der öffentlichen Vorschau verfügbar
Wir haben die öffentliche Vorschau von Zilliz Vector Lakebase gestartet — eine bedeutende Weiterentwicklung von Zilliz Cloud von einer verwalteten Vektordatenbank zu einer einheitlichen semantischen Datenplattform, die latenzarmes Vector Serving mit der Offenheit, Skalierbarkeit und Wirtschaftlichkeit eines Data Lake kombiniert.
Kernfunktionen von Zilliz Vector Lakebase:
- Tiered Serving, optimiert für unterschiedliche Echtzeit-Kompromisse zwischen Performance und Kosten
- On-Demand-Suche für groß angelegte oder explorative Workloads ohne ständig aktive Compute-Ressourcen
- Externe Data-Lake-Suche — direkt über Ihre bestehenden Lake-Daten indizieren und suchen
- Vollspektrum-Suche über Vektoren, Text, JSON und Geodaten mit Hybrid Retrieval und Reranking
- Einheitlicher lake-nativer Speicher auf Basis von Vortex, einem offenen Format mit schnelleren und günstigeren Random Reads als Lance oder Parquet
Wenn Ihr aktueller Stack Serving und Discovery auf separate Systeme aufteilt, könnte Vector Lakebase einen Blick wert sein. Testen Sie es auf Zilliz Cloud — neue Registrierungen mit geschäftlicher E-Mail-Adresse erhalten $100 kostenlose Credits — oder sprechen Sie mit uns über Ihren Anwendungsfall.

Weiterlesen

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.