




So erhalten Sie die richtigen Vektor-Embeddings
Dieser Artikel wurde ursprünglich in The New Stack veröffentlicht und wird hier mit Genehmigung erneut veröffentlicht.
Eine umfassende Einführung in Vektoreinbettungen und wie man sie mit beliebten Open-Source-Modellen generiert.
 Bild von Денис Марчук from Pixabay
Bild von Денис Марчук from Pixabay
Vektoreinbettungen sind entscheidend bei der Arbeit mit semantischer Ähnlichkeit. Ein Vektor ist jedoch einfach eine Reihe von Zahlen; eine Vektoreinbettung ist eine Reihe von Zahlen, die Eingabedaten repräsentiert. Mithilfe von Vektoreinbettungen können wir unstrukturierte Daten strukturieren oder mit jeder Art von Daten arbeiten, indem wir sie in eine Reihe von Zahlen umwandeln. Dieser Ansatz ermöglicht es uns, mathematische Operationen auf den Eingabedaten durchzuführen, anstatt uns auf qualitative Vergleiche zu verlassen.
Vektoreinbettungen sind für viele Aufgaben einflussreich, insbesondere für die semantische Suche. Es ist jedoch entscheidend, die geeigneten Vektoreinbettungen zu erhalten, bevor man sie verwendet. Wenn Sie beispielsweise ein Bildmodell verwenden, um Text zu vektorisieren, oder umgekehrt, werden Sie wahrscheinlich schlechte Ergebnisse erhalten.
In diesem Beitrag erfahren wir, was Vektoreinbettungen bedeuten, wie Sie mithilfe verschiedener Modelle die richtigen Vektoreinbettungen für Ihre Anwendungen generieren und wie Sie Vektoreinbettungen mit Vektordatenbanken wie Milvus und Zilliz Cloud optimal nutzen.
Wie werden Vektoreinbettungen erstellt?
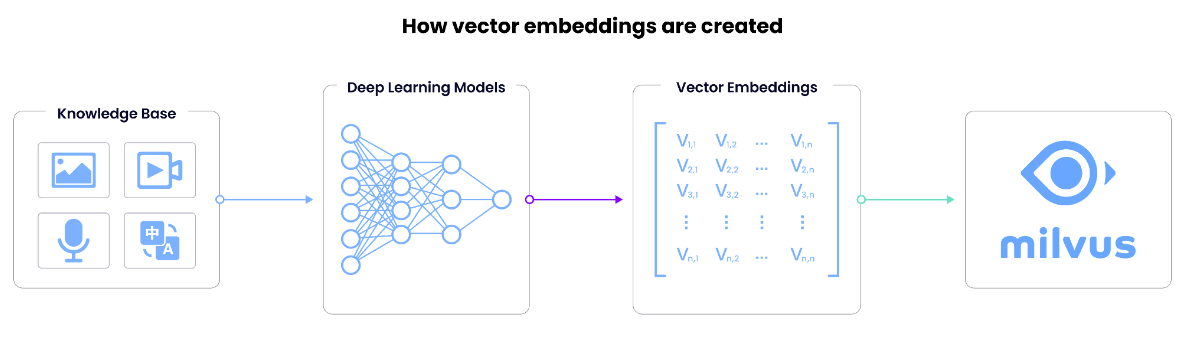
Nachdem wir nun die Bedeutung von Vektoreinbettungen verstanden haben, wollen wir lernen, wie sie funktionieren. Eine Vektoreinbettung ist die interne Repräsentation von Eingabedaten in einem Deep-Learning-Modell, auch bekannt als Einbettungsmodelle oder tiefes neuronales Netzwerk. Wie extrahieren wir also diese Informationen?
Wir erhalten Vektoren, indem wir die letzte Schicht entfernen und die Ausgabe der vorletzten Schicht verwenden. Die letzte Schicht eines neuronalen Netzwerks gibt in der Regel die Vorhersage des Modells aus, daher nehmen wir die Ausgabe der vorletzten Schicht. Die Vektoreinbettung sind die Daten, die der Vorhersageschicht eines neuronalen Netzwerks zugeführt werden.
Die Dimensionalität einer Vektoreinbettung entspricht der Größe der vorletzten Schicht im Modell und ist daher austauschbar mit der Größe oder Länge des Vektors. Übliche Vektordimensionalitäten umfassen 384 (generiert von Sentence Transformers Mini-LM), 768 (von Sentence Transformers MPNet), 1.536 (von OpenAI) und 2.048 (von ResNet-50).
Was bedeutet eine Vektoreinbettung?
Jemand fragte mich einmal nach der Bedeutung jeder Dimension in einer Vektoreinbettung. Die kurze Antwort lautet: nichts. Eine einzelne Dimension in einer Vektoreinbettung bedeutet nichts, da sie zu abstrakt ist, um ihre Bedeutung zu bestimmen. Wenn wir jedoch alle Dimensionen zusammen betrachten, liefern sie die semantische Bedeutung der Eingabedaten.
Die Dimensionen des Vektors sind abstrakte High-Level-Repräsentationen verschiedener Attribute. Die repräsentierten Attribute hängen von den Trainingsdaten und dem Modell selbst ab. Text- und Bildmodelle generieren unterschiedliche Einbettungen, weil sie für grundlegend unterschiedliche Datentypen trainiert werden. Selbst unterschiedliche Textmodelle generieren unterschiedliche Einbettungen. Manchmal unterscheiden sie sich in der Größe; ein anderes Mal unterscheiden sie sich in den Attributen, die sie repräsentieren. Beispielsweise lernt ein Modell, das mit juristischen Daten trainiert wurde, andere Dinge als eines, das mit Gesundheitsdaten trainiert wurde. Ich habe dieses Thema in meinem Beitrag Vergleich von Vektoreinbettungen untersucht.
Die richtigen Vektoreinbettungen generieren
Wie erhält man die richtigen Vektoreinbettungen? Alles beginnt damit, die Art der Daten zu identifizieren, die Sie einbetten möchten. Dieser Abschnitt behandelt die Einbettung von fünf verschiedenen Datentypen: Bilder, Text, Audio, Videos und multimodale Daten. Alle Modelle, die wir hier vorstellen, sind Open Source und stammen von Hugging Face oder PyTorch.
Bildeinbettungen
Die Bilderkennung nahm 2012 Fahrt auf, nachdem AlexNet auf den Plan trat. Seitdem hat das Gebiet der Computer Vision zahlreiche Fortschritte erlebt. Das neueste bemerkenswerte Bilderkennungsmodell ist ResNet-50, ein 50-schichtiges tiefes Residualnetzwerk, das auf der früheren ResNet-34-Architektur basiert.
Residual Neural Networks (ResNet) lösen das Problem des verschwindenden Gradienten in tiefen konvolutionalen neuronalen Netzwerken mithilfe von Shortcut-Verbindungen. Diese Verbindungen ermöglichen es der Ausgabe früherer Schichten, direkt zu späteren Schichten zu gelangen, ohne alle Zwischenschichten zu durchlaufen, wodurch das Problem des verschwindenden Gradienten vermieden wird. Dieses Design macht ResNet weniger komplex als VGGNet (Visual Geometry Group), ein zuvor führendes konvolutionales neuronales Netzwerk.
Ich empfehle zwei ResNet-50-Implementierungen als Beispiele: ResNet 50 auf Hugging Face und ResNet 50 auf PyTorch Hub. Obwohl die Netzwerke identisch sind, unterscheidet sich der Prozess zur Gewinnung von Einbettungen.
Das folgende Codebeispiel zeigt, wie man PyTorch verwendet, um Vektoreinbettungen zu erhalten. Zunächst laden wir das Modell von PyTorch Hub. Als Nächstes entfernen wir die letzte Schicht und rufen .eval() auf, um das Modell anzuweisen, sich so zu verhalten, als würde es für Inferenz ausgeführt. Dann erzeugt die Funktion embed die Vektoreinbettung.
# Load the embedding model with the last layer removed
model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet50', pretrained=True) model = torch.nn.Sequential(*(list(model.children())[:-1]))
model.eval()
def embed(data):
with torch.no_grad():
output = model(torch.stack(data[0])).squeeze()
return output
HuggingFace verwendet einen etwas anderen Aufbau. Der folgende Code zeigt, wie man eine Vektoreinbettung von Hugging Face erhält. Zunächst benötigen wir einen Feature Extractor und ein Modell aus der Bibliothek transformers . Wir verwenden den Feature Extractor, um Eingaben für das Modell zu erhalten, und verwenden das Modell, um Ausgaben zu erhalten und den letzten verborgenen Zustand zu extrahieren.
# Load model directly
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")
from PIL import Image
image = Image.open("<image path>")
# image = Resize(size=(256, 256))(image)
inputs = extractor(images=image, return_tensors="pt")
# print(inputs)
outputs = model(**inputs)
vector_embeddings = outputs[1][-1].squeeze()
Texteinbettungen
Ingenieure und Forscher experimentieren seit der Erfindung der KI mit natürlicher Sprache und KI. Zu den frühesten Experimenten gehören:
- ELIZA, der erste KI-Therapeuten-Chatbot.
- John Searles Chinese Room, ein Gedankenexperiment, das untersucht, ob die Fähigkeit, zwischen Chinesisch und Englisch zu übersetzen, ein Verständnis der Sprache erfordert.
- Regelbasierte Übersetzungen zwischen Englisch und Russisch.
Der Umgang von KI mit natürlicher Sprache hat sich seit ihren regelbasierten Einbettungen erheblich weiterentwickelt. Beginnend mit primären neuronalen Netzwerken fügten wir durch RNNs Rekurrenzbeziehungen hinzu, um Schritte in der Zeit nachzuverfolgen. Von dort aus nutzten wir Transformer, um das Sequenztransduktionsproblem zu lösen.
Transformer bestehen aus einem Encoder, der eine Eingabe in eine Matrix kodiert, die den Zustand repräsentiert, einer Aufmerksamkeitsmatrix und einem Decoder. Der Decoder dekodiert den Zustand und die Aufmerksamkeitsmatrix, um das richtige nächste Token vorherzusagen und die Ausgabesequenz zu vervollständigen. GPT-3, das bislang populärste Sprachmodell, besteht aus strikten Decodern. Sie kodieren die Eingabe und sagen das/die richtige(n) nächste(n) Token voraus.
Hier sind zwei Modelle aus der sentence-transformers Bibliothek von Hugging Face, die du zusätzlich zu OpenAI’s Embeddings verwenden kannst:
- MiniLM-L6-v2: ein 384-dimensionales Modell
- MPNet-Base-V2: ein 768-dimensionales Modell
Du kannst auf Embeddings aus beiden Modellen auf die gleiche Weise zugreifen.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("<model-name>")
vector_embeddings = model.encode(“<input>”)
Multimodale Embeddings
Multimodale Modelle sind weniger weit entwickelt als Bild- oder Textmodelle. Sie setzen Bilder oft in Beziehung zu Text.
Das nützlichste Open-Source-Beispiel ist CLIP VIT, ein Bild-zu-Text-Modell. Du kannst auf CLIP VIT’s Embeddings auf die gleiche Weise zugreifen wie auf ein Bildmodell, wie im folgenden Code gezeigt.
# Load model directly
from transformers import AutoProcessor, AutoModelForZeroShotImageClassification
processor = AutoProcessor.from_pretrained("openai/clip-vit-large-patch14")
model = AutoModelForZeroShotImageClassification.from_pretrained("openai/clip-vit-large-patch14")
from PIL import Image
image = Image.open("<image path>")
# image = Resize(size=(256, 256))(image)
inputs = extractor(images=image, return_tensors="pt")
# print(inputs)
outputs = model(**inputs)
vector_embeddings = outputs[1][-1].squeeze()
Audio-Embeddings
KI für Audio hat weniger Aufmerksamkeit erhalten als KI für Text oder Bilder. Der häufigste Anwendungsfall für Audio ist Speech-to-Text für Branchen wie Callcenter, Medizintechnik und Barrierefreiheit. Ein beliebtes Open-Source-Modell für Speech-to-Text ist Whisper from OpenAI. Der folgende Code zeigt, wie man Vektor-Embeddings aus dem Speech-to-Text-Modell erhält.
import torch
from transformers import AutoFeatureExtractor, WhisperModel
from datasets import load_dataset
model = WhisperModel.from_pretrained("openai/whisper-base")
feature_extractor = AutoFeatureExtractor.from_pretrained("openai/whisper-base")
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
inputs = feature_extractor(ds[0]["audio"]["array"], return_tensors="pt")
input_features = inputs.input_features
decoder_input_ids = torch.tensor([[1, 1]]) * model.config.decoder_start_token_id
vector_embedding = model(input_features, decoder_input_ids=decoder_input_ids).last_hidden_state
Video-Embeddings
Video-Embeddings sind komplexer als Audio- oder Bild-Embeddings. Ein multimodaler Ansatz ist notwendig, wenn mit Videos gearbeitet wird, da sie synchronisierte Audio- und Bilddaten enthalten. Ein beliebtes Videomodell ist der multimodal perceiver von DeepMind. Dieses notebook tutorial zeigt, wie man das Modell zur Klassifizierung eines Videos verwendet.
Um die Embeddings der Eingabe zu erhalten, verwende outputs[1][-1].squeeze() aus dem im Notebook gezeigten Code, anstatt die Ausgaben zu löschen. Ich hebe dieses Code-Snippet in der autoencode Funktion hervor.
def autoencode_video(images, audio):
# only create entire video once as inputs
inputs = {'image': torch.from_numpy(np.moveaxis(images, -1, 2)).float().to(device),
'audio': torch.from_numpy(audio).to(device),
'label': torch.zeros((images.shape[0], 700)).to(device)}
nchunks = 128
reconstruction = {}
for chunk_idx in tqdm(range(nchunks)):
image_chunk_size = np.prod(images.shape[1:-1]) // nchunks
audio_chunk_size = audio.shape[1] // SAMPLES_PER_PATCH // nchunks
subsampling = {
'image': torch.arange(
image_chunk_size * chunk_idx, image_chunk_size * (chunk_idx + 1)),
'audio': torch.arange(
audio_chunk_size * chunk_idx, audio_chunk_size * (chunk_idx + 1)),
'label': None,
}
# forward pass
with torch.no_grad():
outputs = model(inputs=inputs, subsampled_output_points=subsampling)
output = {k:v.cpu() for k,v in outputs.logits.items()}
reconstruction['label'] = output['label']
if 'image' not in reconstruction:
reconstruction['image'] = output['image']
reconstruction['audio'] = output['audio']
else:
reconstruction['image'] = torch.cat(
[reconstruction['image'], output['image']], dim=1)
reconstruction['audio'] = torch.cat(
[reconstruction['audio'], output['audio']], dim=1)
vector_embeddings = outputs[1][-1].squeeze()
# finally, reshape image and audio modalities back to original shape
reconstruction['image'] = torch.reshape(reconstruction['image'], images.shape)
reconstruction['audio'] = torch.reshape(reconstruction['audio'], audio.shape)
return reconstruction
return None
Speichern, Indexieren und Suchen von Vektoreinbettungen mit Vektordatenbanken
Nachdem wir nun verstehen, was Vektoreinbettungen sind und wie man sie mithilfe verschiedener leistungsstarker Einbettungsmodelle erzeugt, stellt sich als Nächstes die Frage, wie man sie speichert und nutzt. Vektordatenbanken sind die Antwort.
Vektordatenbanken wie Milvus und Zilliz Cloud sind speziell dafür entwickelt, riesige Datensätze unstrukturierter Daten über Vektoreinbettungen zu speichern, zu indexieren und zu durchsuchen. Sie gehören außerdem zu den wichtigsten Infrastrukturen für verschiedene KI-Stacks.
Vektordatenbanken verwenden in der Regel den Approximate Nearest Neighbor (ANN) -Algorithmus, um die räumliche Distanz zwischen dem Abfragevektor und den in der Datenbank gespeicherten Vektoren zu berechnen. Je näher die beiden Vektoren beieinanderliegen, desto relevanter sind sie. Anschließend findet der Algorithmus die Top-k-nächsten Nachbarn und liefert sie an den Benutzer.
Vektordatenbanken sind in Anwendungsfällen wie LLM retrieval augmented generation (RAG), Frage-Antwort-Systemen, Empfehlungssystemen, semantischen Suchen sowie Ähnlichkeitssuchen für Bilder, Videos und Audio beliebt.
Um mehr über Vektoreinbettungen, unstrukturierte Daten und Vektordatenbanken zu erfahren, sollten Sie mit der Reihe Vector Database 101 beginnen.
Zusammenfassung
Vektoren sind ein leistungsstarkes Werkzeug für die Arbeit mit unstrukturierten Daten. Mithilfe von Vektoren können wir verschiedene Teile unstrukturierter Daten mathematisch auf Grundlage semantischer Ähnlichkeit vergleichen. Die Wahl des richtigen Vektoreinbettungsmodells ist entscheidend für den Aufbau einer Vektorsuchmaschine für jede Anwendung.
In diesem Beitrag haben wir gelernt, dass Vektor-Embeddings die interne Darstellung von Eingabedaten in einem neuronalen Netzwerk sind. Daher hängen sie stark von der Netzwerkarchitektur und den Daten ab, die zum Trainieren des Modells verwendet wurden. Verschiedene Datentypen (wie Bilder, Text und Audio) erfordern spezifische Modelle. Glücklicherweise stehen viele vortrainierte Open-Source-Modelle zur Verfügung. In diesem Beitrag haben wir Modelle für die fünf häufigsten Datentypen behandelt: Bilder, Text, multimodal, Audio und Video. Wenn Sie außerdem Vektor-Embeddings optimal nutzen möchten, sind Vektordatenbanken das beliebteste Werkzeug.

Weiterlesen

How to Build an Enterprise-Ready RAG Pipeline on AWS with Bedrock, Zilliz Cloud, and LangChain
Build production-ready enterprise RAG with AWS Bedrock, Nova models, Zilliz Cloud, and LangChain. Complete tutorial with deployable code.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.