




Wie Inkeep und Milvus einen RAG-gesteuerten KI-Assistenten für intelligentere Interaktion entwickelt haben
Als Entwickler kann es mühsam sein, die technische Dokumentation verschiedener Plattformen oder Dienste zu durchsuchen. Typische technische Dokumentationen enthalten zahlreiche Abschnitte und Hierarchien, die verwirrend oder schwierig zu navigieren sein können. Daher verbringen wir oft viel Zeit mit der Suche nach den benötigten Antworten. Die Ergänzung der technischen Dokumentation durch einen KI-Assistenten kann für viele Entwickler eine Zeitersparnis bedeuten, da wir die KI einfach nach unseren Fragen fragen können und sie uns Antworten gibt oder uns zu den entsprechenden Seiten und Artikeln weiterleitet.
In einem kürzlich von Zilliz veranstalteten Unstructured Data Meetup sprach Robert Tran, der Mitbegründer und CTO von Inkeep, darüber, wie Inkeep und Zilliz einen KI-gestützten Assistenten für ihre Dokumentseite entwickelt haben. Wir können diesen KI-Assistenten jetzt auf den Dokumentations-Websites von Zilliz und Milvus in Aktion sehen.
In diesem Artikel werden wir die von Robert Tran vorgestellten technischen Details untersuchen. Beginnen wir also kurzerhand mit der Motivation für die Integration eines KI-Assistenten in technische Dokumentationsseiten.
Die Motivation hinter dem KI-Assistenten in der Technischen Dokumentation
Die technische Dokumentation ist eine wesentliche Informationsquelle, die alle Plattformen zur Unterstützung ihrer Benutzer oder Entwickler bereitstellen müssen. Sie sollte intuitiv, umfassend und hilfreich sein, um Entwickler aller Erfahrungsstufen bei der Nutzung der auf den Plattformen verfügbaren Merkmale und Funktionen anzuleiten.
Da Plattformen jedoch zahlreiche neue Funktionen einführen, kann ihre technische Dokumentation übermäßig komplex werden. Diese Komplexität kann viele Entwickler verwirren, wenn sie sich durch die technische Dokumentation einer Plattform bewegen. Die Entwickler stehen oft unter dem Druck, schnell Ergebnisse zu liefern, und die Zeit, die sie mit der Suche nach Informationen in der technischen Dokumentation verbringen, kann sie von der eigentlichen Programmier- und Entwicklungsarbeit ablenken.
Viele Plattformen bieten in ihrer technischen Dokumentation grundlegende Suchfunktionen an, um Entwicklern zu helfen, die benötigten Inhalte schnell zu finden, ähnlich wie bei der Suche auf Google (https://zilliz.com/learn/evolution-of-search-from-traditional-keyword-matching-to-vector-search-and-genai). Die Benutzer können Schlüsselwörter eingeben, und die Plattform liefert eine Liste potenziell relevanter Seiten zur Beantwortung ihrer Fragen. Diese grundlegenden Suchfunktionen verstehen jedoch oft nicht den Kontext der Anfrage eines Benutzers, was zu irrelevanten oder unvollständigen Suchergebnissen führt.
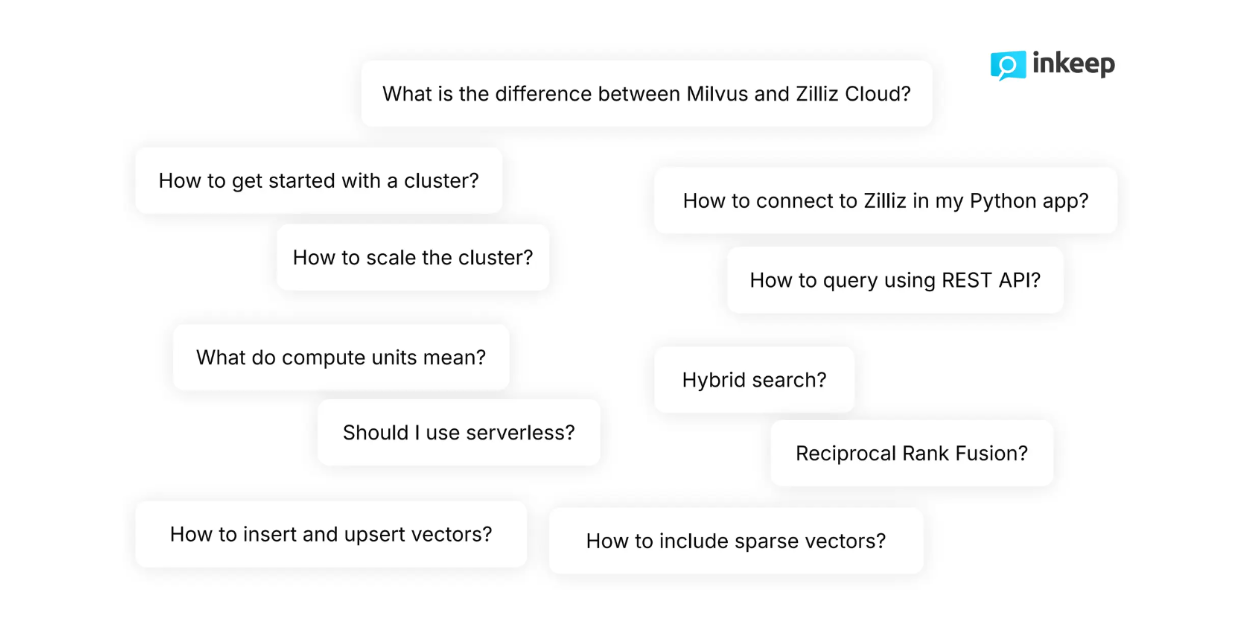 Abbildung- Typische Fragen, die von Entwicklern zu Milvus gestellt werden .png
Abbildung- Typische Fragen, die von Entwicklern zu Milvus gestellt werden .png
Abbildung: Typische Fragen, die von Entwicklern zu Milvus gestellt werden
Als Entwickler wissen wir, dass unsere Fragen oft vielschichtiger und manchmal zu komplex für einfache Suchfunktionen sind. Wenn sie zum Beispiel durch die technische Dokumentation von Zilliz navigieren, stellen Entwickler typischerweise sehr technische Fragen wie "Wie kann man spärliche Vektoren neben dichten Vektoren während des Suchprozesses einbeziehen?" oder "Wie kann man den Cluster dynamisch skalieren?" Grundlegende Suchfunktionen können solche nuancierten und komplexen Fragen oft nicht zufriedenstellend beantworten.
Die Ergänzung durch einen KI-Assistenten löst diese Probleme. Ein KI-Assistent ist in der Lage, die Absicht der Entwickler und die semantische Bedeutung ihrer Abfragen zu verstehen, so dass die Entwickler die benötigten Informationen in Sekundenschnelle erhalten. Entwickler können einfach ihre Anfrage eingeben, und der KI-Assistent gibt ihnen eine Antwort oder leitet sie zu der genau relevanten Seite weiter, anstatt eine Vielzahl von Inhalten zu durchforsten, was sowohl mühsam als auch zeitaufwändig ist.
Darüber hinaus werden KI-Assistenten in der Regel durch die neuesten Entwicklungen in der Verarbeitung natürlicher Sprache (NLP) angetrieben, wie z. B. Large Language Models (LLMs), Vektorsuche und Retrieval Augmented Generation (RAG). Der RAG-Ansatz ist das Herzstück dieses KI-Assistenten, der es ihm ermöglicht, die Nuancen hinter den Fragen der Nutzer zu verstehen und in Sekundenschnelle genaue und relevante Antworten zu geben.
Im nächsten Abschnitt werden wir die Methoden hinter einem KI-Assistenten erörtern.
Das Konzept der Retrieval Augmented Generation (RAG)
[Retrieval Augmented Generation (RAG)] (https://zilliz.com/learn/Retrieval-Augmented-Generation) ist eine Methode, die fortgeschrittene NLP-Techniken wie Vektorsuche und LLMs kombiniert, um genaue Antworten auf Benutzeranfragen zu generieren.
 Abbildung- RAG Arbeitsablauf.png
Abbildung- RAG Arbeitsablauf.png
Abbildung: RAG-Arbeitsablauf.
Der Arbeitsablauf einer RAG-Methode ist, kurz gesagt, recht einfach. Zuerst stellen wir als Benutzer eine Anfrage. Dann sucht die RAG-Methode nach relevanten Dokumenten, die möglicherweise die Antwort auf unsere Anfrage enthalten. Dann werden unsere Anfrage und die relevanten Dokumente zu einer zusammenhängenden Eingabeaufforderung kombiniert, bevor sie an einen LLM gesendet werden. Schließlich generiert der LLM die Antwort auf unsere Anfrage unter Verwendung der bereitgestellten relevanten Dokumente.
Wie wir sehen können, besteht das Hauptkonzept von RAG darin, einen LLM mit relevantem Kontext zu versorgen, um unsere Anfrage zu beantworten. Dieser Ansatz hat mindestens zwei Vorteile: Erstens verringert er das Risiko von LLM [Halluzinationen] (https://zilliz.com/glossary/ai-hallucination), d.h. die Erzeugung ungenauer und unwahrer Antworten. Zweitens ist die vom LLM generierte Antwort kontextbezogener und auf unsere Anfrage zugeschnitten. Dies ist besonders nützlich, wenn wir dem LLM Fragen über den Inhalt von internen Dokumenten stellen.
Es gibt vier RAG-Schritte, die wir bei der Implementierung von RAG berücksichtigen müssen: Ingestion, Indizierung, Retrieval und Generierung.
Ingestion: umfasst das Sammeln und Vorverarbeiten der Daten. Relevante Informationen und Metadaten zu jedem Datensatz können ebenfalls erfasst werden.
Indizierung: umfasst den Prozess der Datenspeicherung mit einer optimierten Indizierungsmethode für einen schnellen Abruf. In diesem Schritt werden die vorverarbeiteten Daten mithilfe eines Einbettungsmodells (https://zilliz.com/blog/choosing-the-right-embedding-model-for-your-data) in [Vektoreinbettungen] (https://zilliz.com/glossary/vector-embeddings) umgewandelt und dann in einer [Vektordatenbank] (https://zilliz.com/learn/what-is-vector-database) wie [Milvus] (https://zilliz.com/what-is-milvus) mit fortschrittlichen Indexierungsalgorithmen wie FLAT, [FAISS] (https://zilliz.com/learn/faiss) oder [HNSW] (https://zilliz.com/learn/hierarchical-navigable-small-worlds-HNSW) gespeichert.
Retrieval: beinhaltet Vektorsuche Operationen, um die Anfrage des Benutzers mit den gespeicherten Daten abzugleichen. In diesem Prozess wird die Anfrage des Benutzers zunächst in eine Vektoreinbettung umgewandelt, wobei dasselbe Einbettungsmodell verwendet wird, das auch für die Umwandlung der gespeicherten Daten verwendet wird. Anschließend wird eine Ähnlichkeitssuche zwischen der Benutzeranfrage und den gespeicherten Daten durchgeführt, um die relevantesten Informationen in der Vektordatenbank zu finden.
Generierung: beinhaltet die Verwendung eines LLM, um die endgültige Antwort zu erzeugen. Zunächst werden die Anfrage des Benutzers und der relevanteste Kontext aus dem Abrufschritt zu einer Eingabeaufforderung kombiniert. Anschließend generiert der LLM eine Antwort auf die Anfrage des Benutzers auf der Grundlage des in der Eingabeaufforderung angegebenen Kontexts.
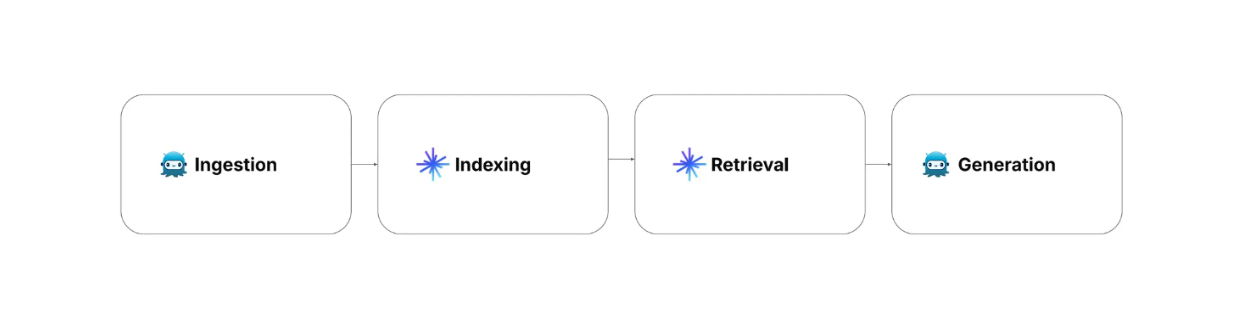 Abbildung- Schritte von RAG..png
Abbildung- Schritte von RAG..png
Abbildung: Schritte der RAG.
Bei der Implementierung der oben genannten Schritte sind mehrere Faktoren zu berücksichtigen. Während der Ingestion-Phase müssen wir zum Beispiel über die Datenquelle, den Datenbereinigungsansatz und die Chunking-Methode nachdenken. Während der Indizierungsphase müssen wir das Einbettungsmodell und die Vektordatenbank, die wir verwenden wollen, sowie die für unseren Anwendungsfall geeigneten Indizierungsalgorithmen in Betracht ziehen.
Im nächsten Abschnitt werden wir die detaillierten RAG-Implementierungen von Inkeep und Zilliz diskutieren, um einen KI-Assistenten für die Dokumentationsseiten von Zilliz und Milvus zu erstellen.
Methoden, die von Inkeep und Zilliz zur Erstellung eines KI-Assistenten verwendet werden
Um einen KI-Assistenten zu erstellen, verwenden Inkeep und Zilliz eine Kombination aus verschiedenen Techniken zur RAG-Implementierung. Inkeep kümmert sich um die Ingestion und die Generierung, während Zilliz Inkeep bei der Indizierung und dem Abruf unterstützt.
Wie im vorherigen Abschnitt erwähnt, ist der erste Schritt der RAG-Implementierung der Ingestion-Schritt. In diesem Schritt sammelt Inkeep Zilliz- und Milvus-bezogene Textdaten aus verschiedenen Quellen, wie z. B. technische [Dokumentation] (https://milvus.io/docs), Support und FAQs sowie [GitHub-Repositories] (https://github.com/milvus-io/milvus). Diese Textdaten werden dann bereinigt und gechunked, um sicherzustellen, dass die einzelnen Informationen weder zu breit noch zu granular sind.
Die Metadaten jedes gechunkten Datensatzes werden ebenfalls gesammelt, bevor mit dem nächsten Schritt begonnen wird. Zu diesen Metadaten gehören:
Art der Quelle: ob die Daten aus einem GitHub-Repositorium, einer technischen Dokumentation, einer Support- und FAQ-Seite usw. stammen.
Aufzeichnungstyp: z. B. die Version der Daten, ob es sich um Text oder Code handelt. Wenn es sich um Code handelt, wird auch die Programmiersprache angegeben.
Hierarchische Referenzen: einschließlich der Kinder, Eltern und Geschwister jedes Datenpunkts. Dies ist wichtig, da die Daten auf den Websites von Zilliz gesammelt werden.
URLs, Tags, Pfade: z. B. die URLs, von denen die Daten übernommen wurden. Diese Metadaten sind sehr nützlich für die Bereitstellung von Links zu Zitaten oder Quellen in der vom LLM generierten Antwort.
Datum: z. B. das Datum der Veröffentlichung der einzelnen Daten.
Sobald Inkeep die Daten und ihre Metadaten gesammelt hat, ist der nächste Schritt die Indizierungsmethode.
Bei der Indizierungsmethode müssen die vorverarbeiteten Daten in Vektoreinbettungen umgewandelt werden, um eine Ähnlichkeitssuche im Retrieval-Schritt zu ermöglichen. Um jeden Datenpunkt in eine Vektoreinbettung umzuwandeln, verwenden Inkeep und Zilliz drei verschiedene Einbettungsmethoden: ein traditionelles Sparse-Embedding-Modell, ein Deep-Learning-basiertes Sparse-Embedding-Modell und ein Dense-Embedding-Modell.
 Abbildung - Sparse und Dense Embeddings..png
Abbildung - Sparse und Dense Embeddings..png
Abbildung: Spärliche und dichte Einbettungen.
Die spärliche Einbettung ist besonders nützlich für einfache, schlagwortbasierte und boolesche Abgleichverfahren. Daher enthalten die relevanten Dokumente, die aus einer spärlichen Einbettung geholt werden, normalerweise die Schlüsselwörter Ihrer Anfrage. Die dichte Einbettung ist hingegen nützlicher, um die Nuancen oder die semantische Bedeutung Ihrer Anfrage zu erfassen. Die aus der dichten Einbettung abgerufenen Dokumente können die Schlüsselwörter Ihrer Suchanfrage enthalten oder auch nicht, aber der Inhalt ist in hohem Maße relevant für sie.
Es gibt zwei verschiedene Arten von Modellen, die zur Umwandlung von Daten in Sparse Embedding verwendet werden können: herkömmliche/statistische Modelle und auf Deep Learning basierende Modelle. Für den KI-Assistenten verwenden Inkeep und Zilliz [BM25] (https://zilliz.com/learn/mastering-bm25-a-deep-dive-into-the-algorithm-and-application-in-milvus) als traditionell-basiertes Modell und [SPLADE/BGE-M3] (https://zilliz.com/learn/bge-m3-and-splade-two-machine-learning-models-for-generating-sparse-embeddings) als Deep-Learning-basiertes Modell.
Für die Umwandlung von Daten in eine dichte Einbettung stehen viele Deep-Learning-Modelle zur Auswahl, wie z.B. die Einbettungsmodelle von OpenAI, Sentence-Transformers, VoyageAI, etc. Für den KI-Assistenten verwenden Inkeep und Zilliz drei verschiedene Einbettungsmodelle: MS-MARCO, MPNET und BGE-M3.
Sobald alle Daten in ihre spärlichen und dichten Einbettungsrepräsentationen umgewandelt sind, werden die Einbettungen in einer Vektordatenbank gespeichert, um einen schnellen Abruf zu ermöglichen. Für den Aufbau des KI-Assistenten verwenden Inkeep und Zilliz Milvus als Vektordatenbank. Nun stellt sich die Frage: Warum müssen wir eine Kombination aus sparsamer und dichter Einbettung verwenden, wenn es auch ausreicht, eine von beiden zu wählen?
Abbildung - Darstellung der hybriden Suche..png](https://assets.zilliz.com/Figure_Hybrid_search_illustration_d231b60be2.png)
Abbildung: Illustration der hybriden Suche.
Die Verwendung der spärlichen und der dichten Einbettung bietet Flexibilität bei der Abfrage. Wenn unsere Anfrage zum Beispiel kurz ist (weniger als 5 Wörter), kann die spärliche Einbettung ausreichend sein. Ist die Abfrage hingegen lang, führt eine dichte Einbettung in den meisten Fällen zu einer besseren Ergebnisqualität. Wenn wir Milvus als Vektordatenbank verwenden, können wir auch die Möglichkeiten der hybriden Suche nutzen, d. h. eine Ähnlichkeitssuche mit einer Kombination aus sparse und dense embedding. Wir können auch eine Ähnlichkeitssuche mit dichter oder spärlicher Einbettung mit Metadatenfilterung durchführen, falls gewünscht.
Wenn wir eine hybride Suche implementieren, um den relevantesten Inhalt für unsere Anfrage zu finden, müssen wir auch die reranking method in Betracht ziehen. Der Grund dafür ist, dass wir Ähnlichkeitsergebnisse von zwei verschiedenen Methoden erhalten werden und einen Ansatz benötigen, um diese Ergebnisse zu kombinieren. Zu diesem Zweck implementierten Inkeep und Zilliz zwei verschiedene Reranking-Methoden: gewichtetes Scoring und reziproke Rangfusion (RRF).
Das Konzept des gewichteten Scorings ist einfach: Wir weisen jeder Methode ein Gewicht zu. So kann beispielsweise das Ähnlichkeitsergebnis der dichten Einbettung mit 60 % und das der spärlichen Einbettung mit 40 % gewichtet werden. Bei der RRF werden die Werte der Kontexte durch Summierung ihrer reziproken Ränge über zwei verschiedene Methoden berechnet, oft mit einer zusätzlichen kleinen Konstante k, um eine Division durch Null zu vermeiden.
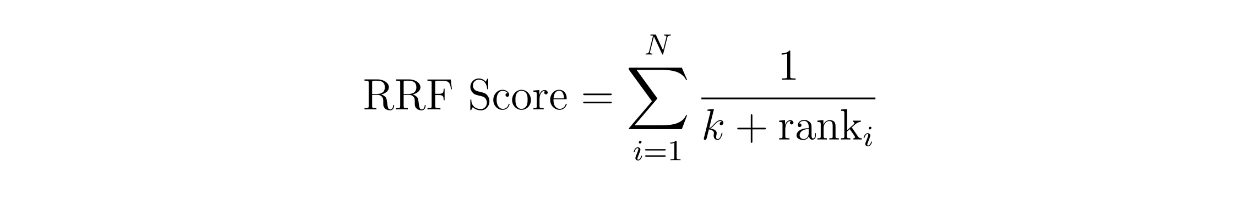 function rrf score.png
function rrf score.png
wobei N die Anzahl der Methoden ist, die zwei sein sollte, da wir eine hybride Suche zwischen einer spärlichen Einbettung und einer dichten Einbettung implementieren. Die Variable 'rank' ist der Rang eines Kontexts in Methode i, und k ist eine Konstante.
Mit Hilfe der obigen RRF-Gleichung können wir den RRF-Score für jeden Kontext berechnen. Der Kontext mit dem höchsten RRF-Score wird als der relevanteste Kontext für eine Abfrage ausgewählt.
Sobald der relevante Kontext abgerufen wurde, werden die ursprüngliche Anfrage und der relevanteste Kontext zu einer kohärenten Eingabeaufforderung kombiniert. Dieser Prompt wird dann an einen LLM gesendet, um die endgültige Antwort zu generieren. Für den LLM verwendet Inkeep Modelle von OpenAI und Anthropic.
Die Milvus AI Assistant Demo
In diesem Abschnitt geben wir eine kurze Einführung in die Verwendung des von Inkeep und Zilliz entwickelten KI-Assistenten. Wenn Sie sich weiterbilden möchten, können Sie dies auf den Dokumentationsseiten Zilliz oder Milvus nachlesen. Für diese Demo werden wir den KI-Assistenten auf der Milvus-Dokumentationsseite verwenden.
Wenn Sie die Milvus-Dokumentationsseite öffnen, sehen Sie unten rechts auf Ihrem Bildschirm die Schaltfläche "KI fragen". Klicken Sie auf diese Schaltfläche, um den KI-Assistenten aufzurufen.
 Bildschirmfoto 1.png
Bildschirmfoto 1.png
Als nächstes erscheint ein Pop-up-Fenster, in dem Sie aufgefordert werden, alles zu fragen, was Sie in der Milvus-Dokumentation finden möchten. Optional können Sie auch eine einfache Suche durchführen, indem Sie auf die Option "Suchen" oben rechts im Pop-up-Fenster klicken.
Angenommen, wir möchten wissen, wie wir unsere Daten mit BGE-M3 und dem Milvus Python SDK in Vektoreinbettungen umwandeln können. Wir können einfach unsere Frage eingeben, und der KI-Assistent wird uns eine Antwort geben.
 Bildschirmfoto 2.png
Bildschirmfoto 2.png
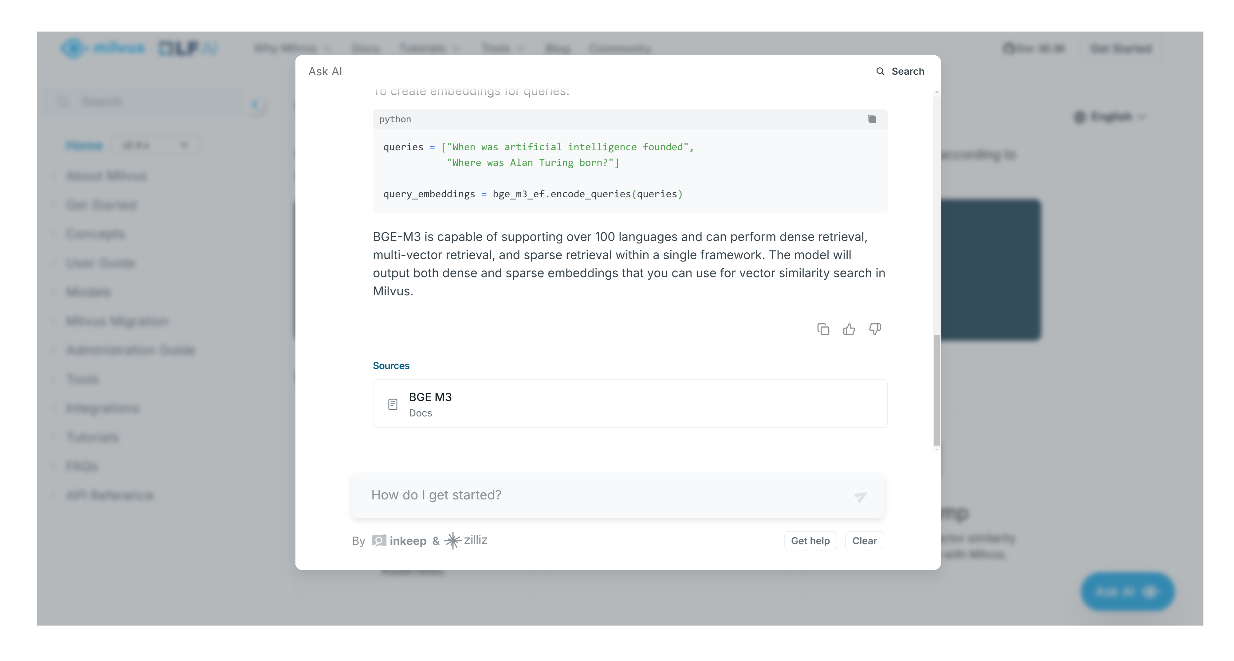
Der KI-Assistent gibt uns nicht nur eine Antwort, sondern auch Zitate oder relevante Seiten, auf denen wir weitere Informationen zu der generierten Antwort finden können.
 Bildschirmfoto 3.png
Bildschirmfoto 3.png
Schlussfolgerung
Die Integration eines KI-Assistenten in die technische Dokumentation, wie sie von Inkeep und Zilliz entwickelt wurde, zeigt, wie fortschrittliche KI-Lösungen die Produktivität der Entwickler und die Benutzererfahrung verbessern können. RAG ist die Kernkomponente hinter diesem KI-Assistenten, da diese Methode dem LLM hilft, genauere und kontextbezogene Antworten auf nuancierte und komplexe Anfragen zu geben.
RAG besteht aus vier Schlüsselschritten: Aufnahme, Indizierung, Abruf und Generierung. Vektordatenbanken wie Milvus sind eine Schlüsselkomponente in der RAG-Pipeline, da sie die Indizierungs- und Abrufschritte durchführen. Die in jedem Schritt verwendeten Methoden müssen je nach Anwendungsfall sorgfältig abgewogen werden. In diesem Artikel haben wir auch ein Beispiel dafür gesehen, wie Inkeep und Zilliz verschiedene Strategien in jedem RAG-Schritt implementiert haben, um einen hochentwickelten KI-Assistenten zu erstellen.
Um mehr darüber zu erfahren, wie Milvus und Inkeep diesen KI-Assistenten entwickelt haben, sehen Sie sich die [Aufzeichnung von Roberts Vortrag auf YouTube] (https://youtu.be/35JdjmiDvWI?list=PLPg7_faNDlT7SC3HxWShxKT-t-u7uKr--&t=2879) an.
Weitere Lektüre
Leistungsstärkste KI-Modelle für Ihre GenAI-Anwendungen | Zilliz
KI-Anwendungen mit Milvus erstellen: Tutorials & Notebooks](https://zilliz.com/learn/milvus-notebooks)
Weiterlesen

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.