




Revolutionierung autonomer KI: Nutzung von Vektordatenbanken zur Stärkung von Auto-GPT
ChatGPT, oder Chat Generative Pre-trained Transformer, war mit bahnbrechenden Fortschritten ein Wendepunkt in der KI-Technologie. Doch selbst bei großen Sprachmodellen (LLMs) wie GPT und spezialisierten KI-Anwendungen wie Midjourney ist menschliche Eingabe für Prompts weiterhin erforderlich. Diese Abhängigkeit vom Menschen wirft die Frage auf: Kann KI unabhängig funktionieren und Ziele ohne menschliches Eingreifen erreichen? Auto-GPT hat sich als beliebte Lösung für diesen Bedarf etabliert.
Was ist Auto-GPT?
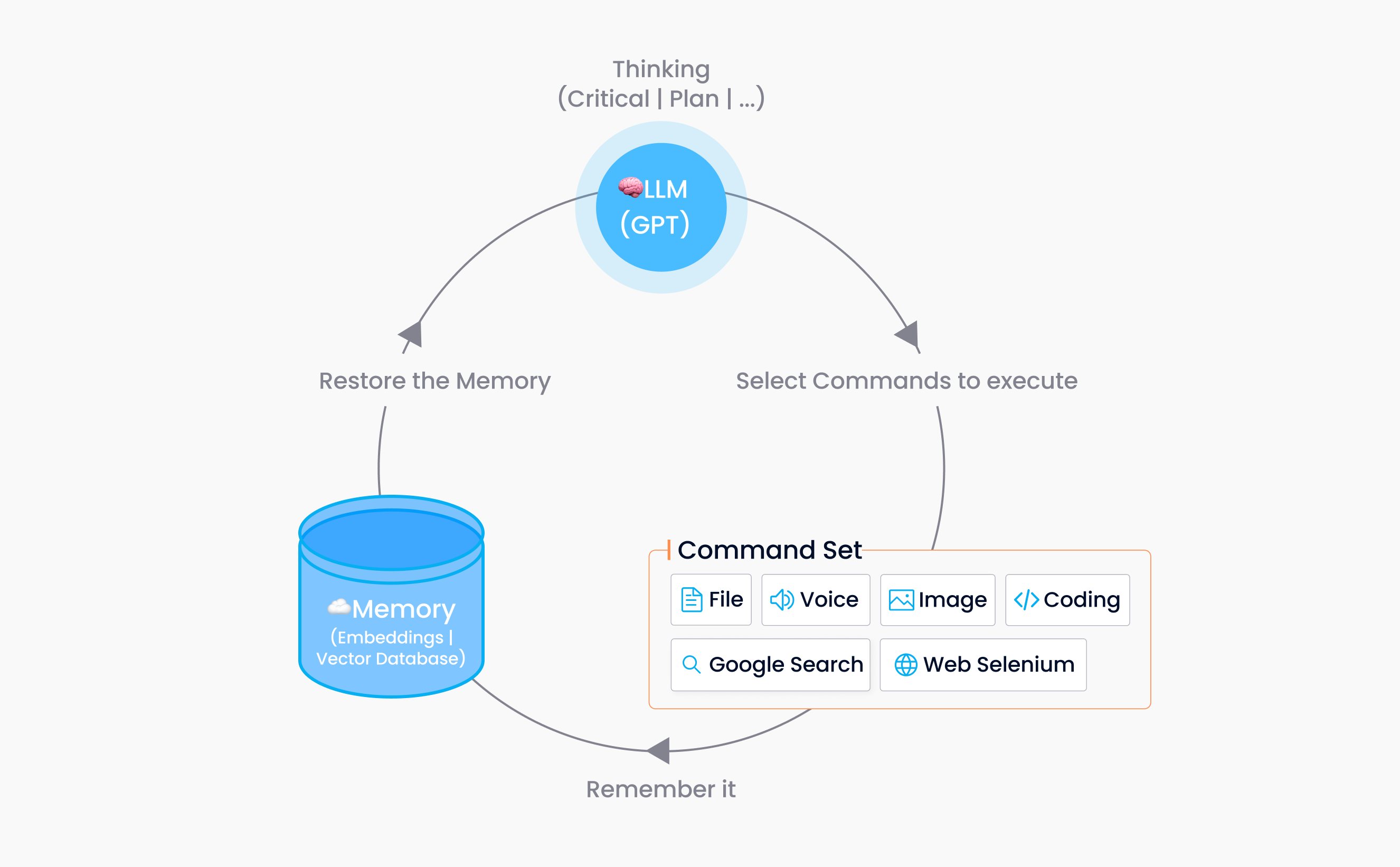
Auto-GPT ist ein experimentelles Open-Source-Projekt auf GitHub. Es kombiniert ein GPT-Sprachmodell mit anderen Tools, um ein KI-System zu schaffen, das kontinuierlich und unabhängig mit minimaler oder sogar ganz ohne menschliche Eingabe arbeiten kann.
Auto-GPT besteht aus zwei Kernteilen: einem LLM und einem Befehlssatz. Das LLM, wie GPT, dient als „Gehirn“ von Auto-GPT und übernimmt die kognitive Verarbeitung. Auto-GPT-Prompts werden also vom LLM und nicht durch traditionelle menschliche Eingabe entwickelt. Gleichzeitig führt der Befehlssatz verschiedene Aufgaben autonom aus, wie das Verwalten von Dateien, das Durchführen von Websuchen und den Zugriff auf soziale Netzwerke. Diese Fähigkeiten entsprechen den „Händen“ und „Sinnen“ von Auto-GPT.
Um den Prozess weiter zu erklären, verwendet Auto-GPT das GPT-Sprachmodell und menschliches Feedback, um große Aufgaben zu analysieren und in kleinere aufzuteilen. Anschließend weist es diesen kleineren Aufgaben spezifische Befehle zu, führt sie aus und erhält Eingaben für die nächste Runde der kognitiven Verarbeitung. Diese Abläufe wiederholen sich, bis Auto-GPT die Aufgabe abgeschlossen hat.
Einschränkungen von Auto-GPT
Da Sie Auto-GPT nun kennen, ist es wichtig, seine Fähigkeiten und Einschränkungen zu verstehen. Obwohl Auto-GPT Aufgaben automatisch ausführen kann, hat es Einschränkungen beim Verstehen und Beibehalten umfangreicher Kontextinformationen, da das von ihm genutzte GPT-Modell ein Token-Limit hat. Beispielsweise kann OpenAIs GPT-3 maximal 4.096 Tokens für den Kontext verarbeiten, was bedeutet, dass GPT-3 frühere Diskussionen möglicherweise vergisst, wenn Gespräche das Token-Limit überschreiten.
Darüber hinaus muss Auto-GPT mehrere Schritte durchführen, um eine komplexe Aufgabe abzuschließen. Sie können jedoch nicht jeden Schritt separat an das GPT-Modell senden, da dies zum Verlust des Kontexts führen könnte. Ein solcher Verlust würde es erschweren festzustellen, ob die Aktionen korrekt sind und effektiv auf das Ziel hinarbeiten. Wenn Sie aber bei jedem Schritt alle vorherigen Nachrichten an das GPT-Modell senden, überschreiten diese das Token-Limit von GPT schneller.
Eine Möglichkeit, dieses Kontextproblem zu lösen, besteht darin, auf ein Fenster historischer Nachrichten zuzugreifen, wie etwa die letzten zehn Nachrichten oder eine feste Anzahl von Tokens, ohne das Token-Limit einer einzelnen Konversation zu überschreiten. Diese Methode schränkt Auto-GPT jedoch darin ein, auf frühere Kontextinformationen zuzugreifen, was dazu führen könnte, dass Auto-GPT sein Ziel nicht erreicht.
Verbesserung der Kontextfähigkeit von Auto-GPT mit einer Vektordatenbank
Die Integration von Auto-GPT mit einer Vektordatenbank ist eine effektivere und effizientere Lösung, um das Gedächtnis und das Kontextverständnis von Auto-GPT zu verbessern. So funktioniert die Integration:
Die Integration wandelt Auto-GPT-Befehle und Ausführungsergebnisse für jeden Schritt in Embeddings um und speichert sie in einer Vektordatenbank.
Beim Generieren der nächsten Aufgabe ruft sie Nachrichten aus dem Verlaufsfenster ab und speichert sie als Eingabe für eine Vektordatenbanksuche.
Anschließend ruft sie die
top-khistorischen Nachrichten ab, um den Kontext mit einer größeren chronologischen Spanne zu verbessern.
 image
image
Zusätzlich kann das System dank der Ähnlichkeitsabruffähigkeit der Vektordatenbank feststellen, ob die letzte Aktion der aktuellen ähnelt und ob sie zur Erledigung der Aufgabe beiträgt, wodurch präzisere Informationen für den folgenden Befehl bereitgestellt werden.
So richtest du Auto-GPT mit Milvus ein
Milvus ist eine der beliebtesten Open-Source-Vektordatenbanken und in der Lage, riesige Datensätze mit Millionen, Milliarden oder sogar Billionen von Vektoren zu verarbeiten. Du kannst der folgenden Anleitung folgen, um Milvus einfach in dein Auto-GPT zu integrieren.
- Ziehe das Docker-Image von Milvus und installiere es mit Docker Compose:
https://github.com/milvus-io/milvus/releases/download/v2.2.8/milvus-standalone-docker-compose.yml
docker compose up -d
- Installiere den
pymilvus-Client in deiner Python-Umgebung:
pip install pymilvus==2.2.8
- Aktualisiere deine
.env-Datei:
MEMORY_BACKEND=milvus
Wenn dir die Bereitstellung und Wartung von Milvus schwierig erscheint, solltest du Zilliz Cloud in Betracht ziehen. Es ist ein vollständig verwalteter cloudnativer Dienst für Milvus und kann dir helfen, den Speicher von Auto-GPT einfach zu verwalten. Zilliz Cloud hat weltweit eine breite Nutzerbasis und wurde von Nvidia-CEO Jensen Huang auf der GTC 2023 empfohlen. Darüber hinaus ist Zilliz Cloud der von OpenAI benannte Anbieter des ChatGPT Retrieval plugin.
Hier ist eine Anleitung, wie du Zilliz Cloud als Speicher-Backend von Auto-GPT verwendest:
Melde dich bei Zilliz Cloud an oder registriere dich für ein Konto, falls du noch keines hast.
Erstelle eine Datenbank und erhalte den öffentlichen Cloud-Endpunkt.
Installiere
pymilvus, indem dupip install pymilvus==2.2.8ausführst, und aktualisiere deine.env-Datei mit den folgenden Befehlen:
MEMORY_BACKEND=milvus
MILVUS_ADDR=your-public-cloud-endpoint
MILVUS_USERNAME=your-db-username
MILVUS_PASSWORD=your-db-password
Durch die Nutzung von Milvus oder Zilliz Cloud als Speicher-Backend für Auto-GPT kannst du dessen Fähigkeiten erheblich verbessern und es einen Schritt näher an echte Autonomie bringen.
Einschränkungen bei der Integration von Auto-GPT mit einer Vektordatenbank
Die Einbindung einer Vektordatenbank in Auto-GPT ist äußerst vorteilhaft und notwendig, um Aufgaben zu automatisieren und Befehle zu generieren, die auf die Ziele des Nutzers abgestimmt sind. Dennoch gibt es weiterhin einige Einschränkungen.
Beim Abrufen von Nachrichten aus der Vektordatenbank werden die Top-k-Ergebnisse nicht gefiltert. Daher können Informationen mit geringer Ähnlichkeit vorhanden sein, was das GPT-Modell in die Irre führen und letztlich seinen Fortschritt bei der Erreichung des gewünschten Ergebnisses verlangsamen könnte.
Du kannst die Kontextdaten nur hinzufügen und abfragen, aber keine Daten löschen, die nicht mehr relevant oder notwendig sind.
Derzeit ist es nicht möglich, das Embedding-Modell anzupassen. Die einzige verfügbare Option besteht darin, die von OpenAI bereitgestellte Embedding-Schnittstelle zu nutzen.
Auto-GPT erklärt
Auto-GPT ist eine neue Entwicklung in der KI-Technologie, die darauf abzielt, vollständige Autonomie mit minimaler oder ganz ohne menschliche Eingabe zu erreichen. Obwohl Auto-GPT noch experimentell ist, besitzt es enormes Potenzial, insbesondere in Kombination mit Vektordatenbanken wie Milvus.
Als Anbieter von Infrastruktursoftware für KI-Technologien freuen wir uns sehr, dass Vektordatenbanken eine entscheidende Rolle bei der Entwicklung und Stärkung neuer KI-generierter Content-Systeme (AIGC) wie Auto-GPT spielen. Wir haben viele informative Artikel verfügbar, wenn du mehr über Open-Source-Vektordatenbanken und Milvus sowie verwandte Themen wie Hierarchical Navigable Small Worlds (HNSW) erfahren möchtest. Lasst uns also zusammenarbeiten, um die Grenzen der KI weiter zu verschieben und eine bessere Zukunft für AIGC zu schaffen.

Weiterlesen

How Zilliz Ended Up at the Center of NVIDIA’s Unstructured Data Story at GTC 2026
If unstructured data is the context of AI, then the ceiling of AI applications will be set not just by models, but by how mature the infrastructure for unstructured data becomes.

Milvus 2.6.x Now Generally Available on Zilliz Cloud, Making Vector Search Faster, Smarter, and More Cost-Efficient for Production AI
Milvus 2.6.x is now GA on Zilliz Cloud, delivering faster vector search, smarter hybrid queries, and lower costs for production RAG and AI applications.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.