




Wie Zilliz auf der GTC 2026 ins Zentrum von NVIDIAs Story zu unstrukturierten Daten rückte
Auf der NVIDIA GTC in diesem Jahr zeigte Jensen Huang inmitten der üblichen Lawine von Behauptungen zu Chips, Systemen und Infrastruktur eine Folie, die aus einem anderen Grund wichtig war.
Es ging nicht um die nächste GPU. Es ging nicht um Modellgröße. Es ging nicht einmal wirklich um Inferenz.
Es ging um Daten.
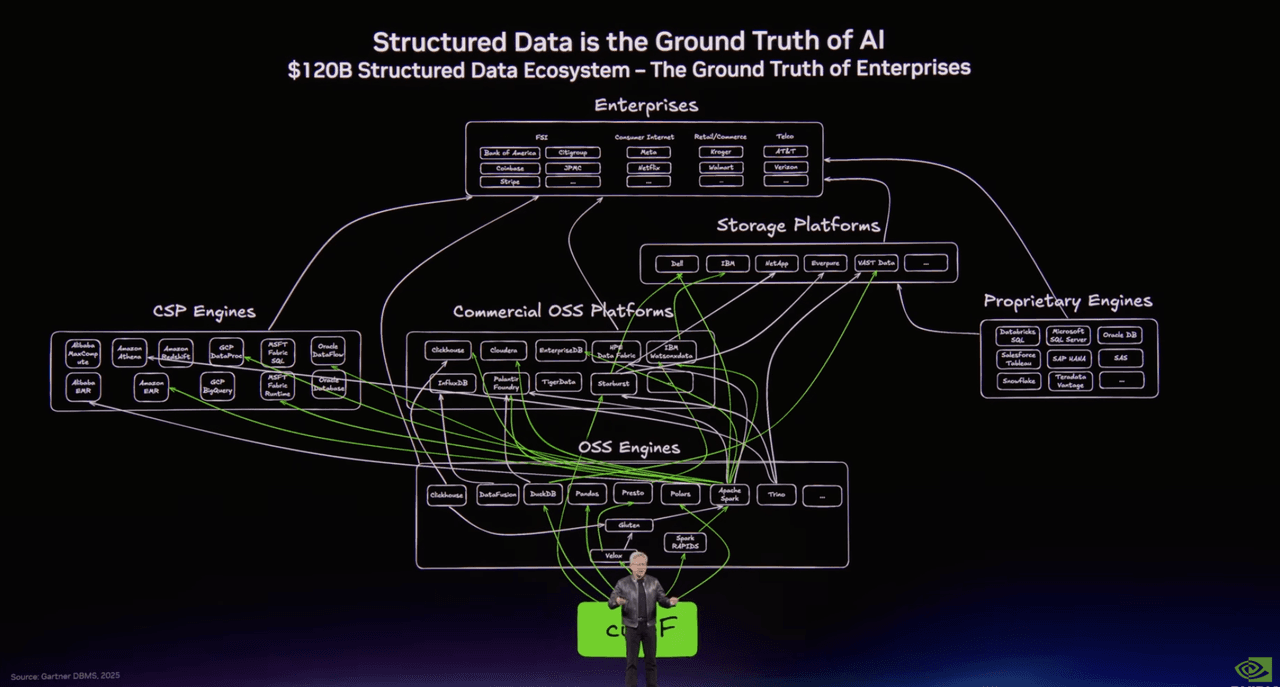
Eine Folie kartierte die Welt strukturierter Daten: Spark, Presto, DuckDB, Polars, Snowflake, Databricks, BigQuery, die vertraute Maschinerie, die Analytik und Data Engineering seit Jahrzehnten antreibt.
Eine andere kartierte den entstehenden Stack für unstrukturierte Daten. Und dort, in der Mitte dieses zweiten Bildes, standen Milvus als Open Source und Zilliz Cloud in der Enterprise-Datenbankschicht.

Der Titel auf der Folie sagte alles: Unstrukturierte Daten sind der Kontext von KI.
Dieser Aussage kann man leicht zustimmen. Natürlich braucht KI Kontext. Natürlich sind die meisten Unternehmensdaten unstrukturiert. Natürlich sind Text, Bilder, Video, Audio, Logs, PDFs und all der Rest heute wichtiger denn je. Doch sobald man über den Slogan hinausgeht, stellt sich eine schwierigere Frage: Wenn unstrukturierte Daten zum eigentlichen Substrat von KI-Systemen werden, wie sieht dann die Infrastruktur für diese Welt tatsächlich aus?
Das ist die interessantere Geschichte. Und sie ist der Grund, warum Milvus von einer spezialisierten Vektordatenbank zu einer deutlich strategischeren Position im KI-Stack aufgestiegen ist.
Warum Zilliz (Milvus) immer wieder auftaucht
Dies war nicht das erste Mal, dass Zilliz auf der GTC auftauchte, und es wird wahrscheinlich nicht das letzte Mal sein.
Lange bevor Vektordatenbanken zu einem Standardbaustein moderner KI-Systeme wurden, wurde Milvus um die Idee herum entwickelt, dass Ähnlichkeitssuche in einem ganz anderen Maßstab arbeiten müsste als traditionelle Datenbanken. GPU-Beschleunigung war kein nachträglicher Einfall. Sie war von Anfang an Teil der Designlogik.
Das wurde wichtig, als KI aufhörte, eine Forschungsgeschichte zu sein, und zu einer Infrastrukturgeschichte wurde.
Auf der GTC 2023 hob Jensen Huang bereits die tiefere Integration zwischen NVIDIAs Beschleunigungsbibliotheken und Systemen wie FAISS, Redis und Milvus hervor. Ein Jahr später, auf der GTC 2024, wurde diese Beziehung mit Milvus 2.4 konkreter, das durch die Kombination von NVIDIA-GPUs mit CAGRA aus RAPIDS cuVS vollständige GPU-Beschleunigung für Vektorindexierung und -suche brachte. Das Ergebnis war keine kosmetische Beschleunigung. In einigen Benchmark-Szenarien verbesserte sich die Suchleistung gegenüber HNSW um bis zu das 50-Fache.
Als Milvus 2.6 erschien, hatte sich die Diskussion erneut weiterentwickelt. Die Frage war nicht mehr, ob GPU-Beschleunigung wichtig ist. Es ging darum, wie man sie kosteneffizient nutzt. Milvus 2.6 führte flexiblere Bereitstellungsmuster für CAGRA ein, darunter hybride GPU-CPU-Architekturen, die die GPU für den Graphaufbau und die CPU für den Abruf nutzen. Das ist wichtig, weil die meisten Unternehmen nicht das schnellstmögliche System um jeden Preis wollen. Sie wollen ein System, das schnell genug bleibt und zugleich wirtschaftlich vernünftig ist.
Dieses Detail ist es wert, kurz innezuhalten, denn es sagt etwas Größeres darüber aus, warum Milvus wichtig geworden ist. Dies ist nicht nur eine Geschichte über die Leistung der Vektorsuche. Es ist eine Geschichte darüber, was passiert, wenn Vektorabruf aufhört, ein experimentelles Feature zu sein, und Teil der Produktionsinfrastruktur wird.
Was nötig ist, damit Vektorsuche in der Produktion funktioniert
Geschwindigkeit allein ist nicht mehr die Geschichte.
Aber sobald die Vektorsuche den Bereich von Demos verlässt und in reale Systeme einzieht, ist Geschwindigkeit allein nicht mehr die ganze Geschichte.
Die schwierigere Frage ist, was nötig ist, um Retrieval im Enterprise-Maßstab praktikabel zu machen, ohne den umgebenden Stack in ein Durcheinander aus fragilen Pipelines, hohem Speicherdruck und steigenden Infrastrukturkosten zu verwandeln.
Ein Teil dieser Herausforderung beginnt vorgelagert. Im alten Modell bedeutete es in der Regel, eine separate Parsing-Schicht, Chunking-Logik, Embedding-Services und Datenbankschreibvorgänge miteinander zu verbinden, um ein PDF, ein Bild oder ein Dokument in etwas Durchsuchbares zu verwandeln. Das Retrieval-System begann erst zu arbeiten, nachdem eine langwierige Vorverarbeitungskette ihre Arbeit bereits abgeschlossen hatte. Milvus 2.6 begann, diese Grenze mit einem Data-in, Data-out-Ansatz aufzulösen, der es ermöglicht, Rohinhalte direkt in das System zu schreiben und innerhalb der Datenbank selbst einzubetten.
Ein Teil davon liegt innerhalb der Retrieval-Schicht. Unterschiedliche Workloads erfordern unterschiedliche Kompromisse, daher werden mehrere Indextypen unterstützt, statt jeder Anwendung eine einzige Retrieval-Strategie aufzuzwingen. Auch Kompression wird Teil der Gleichung. Funktionen wie Int8 und RaBitQ sind keine auffälligen Ergänzungen, aber sie adressieren ein wichtigeres Ziel: Speicherdruck und Kosten zu senken, ohne die Retrieval-Qualität zu beeinträchtigen.
Und ein Teil davon ist schlicht operativ. Milvus führte eine neu gestaltete Write-ahead-Logging-Architektur ein, die Kafka und Pulsar aus dem Stack überflüssig machte und sowohl Komplexität als auch Overhead reduzierte. Diese Art von Engineering macht selten Schlagzeilen, aber genau sie entscheidet darüber, ob Infrastruktur in der Theorie interessant bleibt oder in der Praxis nutzbar wird.
Storage turns out to be another fault line.
Mit dem Wachstum von KI-Systemen steigen auch die Kosten der Annahme, dass alle Daten jederzeit gleich behandelt werden müssen. Auf einer großen Multi-Tenant-Plattform ist an einem bestimmten Tag möglicherweise nur ein kleiner Teil der Daten tatsächlich aktiv. Der Großteil liegt kalt. Traditionelle Full-Load-Architekturen behandeln jedoch weiterhin alles so, als verdiene es dieselbe lokale Verfügbarkeit, dieselbe Performance-Haltung und denselben Kostenfußabdruck.
In kleinem Maßstab wirkt das ineffizient. Im Enterprise-Maßstab wird es schwer zu rechtfertigen.
Milvus 2.6 adressierte dies mit Tiered Storage. Hot Data bleibt lokal, wo Latenz zählt. Cold Data wird bei Bedarf aus kostengünstigerem Object Storage geladen. Und die Grenze zwischen beiden verschiebt sich dynamisch, während das System tatsächlich genutzt wird. Das klingt nach einer bescheidenen Systemoptimierung. In der Praxis verändert es die Ökonomie des Retrievals. Wenn die richtigen Daten in der richtigen Ebene liegen, können die Speicherkosten um mehr als 70 Prozent sinken.
Nichts davon ist besonders glamourös. Aber so reift Infrastruktur in der Regel: nicht durch einen einzigen dramatischen Durchbruch, sondern durch eine Reihe von Designentscheidungen, die das System schneller, günstiger und leichter handhabbar machen.
Und all diese Funktionen sind in Zilliz Cloud, dem vollständig verwalteten Service von Milvus, verfügbar.
Das eigentliche Problem mit unstrukturierten Daten
Die größere Verschiebung dreht sich jedoch nicht wirklich nur um Milvus. Es geht um die Art von Daten, von denen KI-Systeme heute abhängen.
Strukturierte Daten haben sich auf lange, geordnete Weise entwickelt. Zeilen, Spalten, Schemata, Indizes, Warehouses, Query Engines. Die Werkzeuge reiften über Jahrzehnte, weil die Daten selbst zu den Annahmen passten, auf denen diese Systeme aufgebaut waren. Man wusste, wie ein Datensatz aussah. Man wusste, welche Felder abzufragen waren. Man wusste, wie man sie indiziert.
Unstrukturierte Daten durchbrechen dieses Modell.
Ein Vertrag ist keine Zeile. Ein medizinisches Bild, ein Support-Transkript, ein Code-Repository oder ein Überwachungs-Feed sind es ebenfalls nicht. Diese Objekte können gespeichert werden, aber sie zu speichern ist der einfache Teil. Der schwierige Teil besteht darin, sie auf eine Weise durchsuchbar zu machen, die Bedeutung versteht statt exakter Feldübereinstimmungen.
Deshalb haben Embeddings alles verändert. Sobald Text, Bilder, Audio und andere Inhaltsformen in einen hochdimensionalen Vektorraum abgebildet werden konnten, musste Retrieval nicht länger von exakter symbolischer Übereinstimmung abhängen. Systeme konnten nach Ähnlichkeit, Absicht und Kontext abrufen.
Das war der Durchbruch.
Es war auch der Beginn eines neuen Infrastrukturproblems.
Sobald unstrukturierte Daten abfragbar werden, stehen Unternehmen unmittelbar vor der Ökonomie der Skalierung. Millionen von Dokumenten werden zu Hunderten Millionen Embeddings. Ein Modell-Upgrade bedeutet, den historischen Korpus neu einzubetten. Die Retrieval-Qualität hängt von der Indexqualität ab. Latenz ist in der Produktion wichtig. Speicherkosten ebenso. Genauso die operative Belastung, all dies synchron zu halten.
Mit anderen Worten: Semantisches Retrieval löste das Zugriffsproblem, legte aber das Systemproblem offen.
Das ist der Kontext, in dem Milvus Sinn ergibt.
Warum eine Vektordatenbank nicht genug war
Für die erste Welle KI-nativer Unternehmen war die Antwort unkompliziert: eine Vektordatenbank als Retrieval-Schicht verwenden, sie mit einem Modell verbinden und darauf aufbauend die Anwendung entwickeln. Dieses Modell funktionierte, und es funktioniert immer noch, insbesondere wenn semantische Suche den Kern des Produkts bildet.
Große Unternehmen stoßen jedoch meist auf eine andere Grenze.
Die Frage ist nicht, ob sie Vektorsuche zum Laufen bringen können. Die Frage ist, was danach passiert.
Rohdateien liegen in Object Storage oder Data Lakes. Embeddings liegen in einer Vektordatenbank. Metadaten liegen in einem relationalen System. Offline-Verarbeitung findet anderswo statt. Suchprotokolle häufen sich in einer weiteren Pipeline an. Dann ändert sich das Embedding-Modell, oder die Ranking-Logik ändert sich, oder die Wissensbasis muss kuratiert werden, oder jemand möchte nachvollziehen, warum ein Retrieval-System bei Grenzfällen immer wieder versagt. Plötzlich ist das System kein einziges System mehr. Es ist ein Flickwerk.
Dieses Flickwerk erzeugt drei vertraute Probleme.
- Das erste sind Datensilos. Die Daten, die zum Betreiben eines einzelnen KI-Features erforderlich sind, sind über mehrere Systeme verteilt, jedes mit seinem eigenen Format, Lebenszyklus und Betriebsmodell.
- Das zweite sind die Iterationskosten. Wenn sich ein Embedding-Modell ändert, ist das Neuschreiben standardmäßig nicht inkrementell. Es kann zu einem monatelangen Reindexierungs- und Migrationsaufwand werden.
- Das dritte ist die unterbrochene Schleife zwischen Online-Bereitstellung und Offline-Verbesserung. Das System bedient Abfragen in der Produktion, aber die Signale, die es verbessern könnten, Deduplication-Ausgaben, Clustering-Labels, Qualitätswerte und Fehleranalysen, liegen oft in separaten Umgebungen und fließen nie sauber zurück in die Retrieval-Schicht.
Das ist der Punkt, an dem der Kauf einer Vektordatenbank sich nicht mehr wie die Antwort anfühlt, sondern wie der Beginn einer größeren Architekturfrage.
Wenn das eigentliche Problem kontinuierliche Verbesserung in großem Maßstab ist, dann muss sich die Architektur ändern.
Von der Vektordatenbank zur AI Lakebase
Vor dem KI-Boom trug Databricks dazu bei, das Lakehouse-Modell populär zu machen, indem es die umständliche Trennung zwischen Data Lakes und Data Warehouses aufhob. Anstatt separate Systeme für Speicherung, Analytik und groß angelegte Verarbeitung zu betreiben, konnten Unternehmen von einer einheitlicheren Grundlage aus arbeiten.
Die KI-Ära erzwingt ein ähnliches Umdenken, jedoch rund um unstrukturierte Daten.
Wenn man sich die Infrastrukturdiagramme genau ansieht, die Jensen Huang verwendet, verschiebt sich der Schwerpunkt. In der Ära strukturierter Daten standen Frameworks wie Spark im Zentrum der Pipeline. In der Ära unstrukturierter Daten beginnt Vektorinfrastruktur wie Milvus, diese Rolle auszufüllen. Nicht weil Vektorsuche das Einzige ist, was zählt, sondern weil sie zunehmend an der Schnittstelle zwischen Rohdaten, Embeddings, Indizes und Anwendungs-Retrieval sitzt.
Das eröffnet eine größere Möglichkeit: Was wäre, wenn Vektor-Retrieval nicht als separate Serving-Schicht behandelt würde, die seitlich an den Stack angeflanscht ist? Was wäre, wenn es direkt in den Enterprise Data Lake und die umliegenden Daten-Workflows integriert wäre?
AI-Lakebase-Architektur
Das ist die Idee hinter AI Lakebase.
Der Zweck von AI Lakebase ist nicht, einem ohnehin schon überfüllten Markt noch eine weitere Produktkategorie hinzuzufügen. Der Zweck ist, ein fragmentiertes Muster durch ein kohärenteres zu ersetzen.
- Ganz unten befindet sich eine einheitliche Speicherschicht. Ein Teil dieser Daten liegt in Zilliz-nativen Collections, die für leistungsstarkes Vektor-Retrieval optimiert sind. Ein anderer Teil verbleibt in offenen Formaten, die das Unternehmen bereits nutzt, Iceberg, Lance, Paimon und Rohdateien im Objektspeicher. Wichtig ist, dass die Daten nicht in fünf verschiedene Systeme kopiert werden müssen, nur damit sie nutzbar werden.
- Darüber befindet sich die Production-Serving-Schicht, gebaut für Echtzeit-Retrieval. In Zilliz Cloud bedeutet das Cardinal-gestützte Serving-Cluster, optimiert für Latenzen im Millisekundenbereich, mit unterschiedlichen Modi für Performance, Kapazität und gestufte Hot-Cold-Datenplatzierung. In der Praxis bedeutet das, dass häufig abgerufene Daten lokal bleiben, während kalte Daten bei Bedarf aus günstigerem Speicher geladen werden. Das Ergebnis ist nicht nur ein besseres Systemdesign. Es ist Kostenkontrolle.
- Dann gibt es die elastische Compute-Schicht: On-Demand-Cluster für ETL, Deduplizierung, Clustering, Datenqualitätsanalyse, Re-Embedding, Evaluierung und interaktive Untersuchung. Das sind keine später angeklebten Nebensysteme. Sie sind Teil derselben Grundlage.
Alle drei Schichten teilen sich dieselben Daten, anstatt mehrere voneinander getrennte Kopien zu pflegen.
Das klingt nach einer Geschichte über architektonisches Aufräumen, und das ist es auch. Aber es ist mehr als das.
Der größere Punkt ist jedoch, was diese Architektur möglich macht.
AI Lakebase ist mehr als ein architektonisches Aufräumen
Die meisten KI-Systeme können heute bereitstellen. Deutlich weniger können sich systematisch verbessern.
Das liegt normalerweise nicht daran, dass das Modell falsch ist. Es liegt daran, dass die Infrastruktur darum herum Feedback teuer macht.
Ein Produktionssystem erzeugt ständig Signale. Jede Abfrage sagt Ihnen etwas. Jeder fehlgeschlagene Retrieval-Vorgang sagt Ihnen etwas. Jede qualitativ schwache Antwort, jedes wiederholte Ergebnis, jede Sackgassen-Interaktion, jeder Cluster ähnlicher Dokumente, jeder verrauschte Chunk im Korpus, all das sind Informationen, die genutzt werden könnten, um das System zu verbessern.
In den meisten Stacks sind diese Signale jedoch über Serving-Logs, Offline-Pipelines, Notebooks, Dashboards und einmalige Skripte verstreut. Das System läuft, aber es lernt nicht wirklich aus seiner eigenen Erfahrung.
Der Ansatz von AI Lakebase zur Lösung dieses Problems ist Continuous Serving/Continuous Discovery (AI CS/CD).
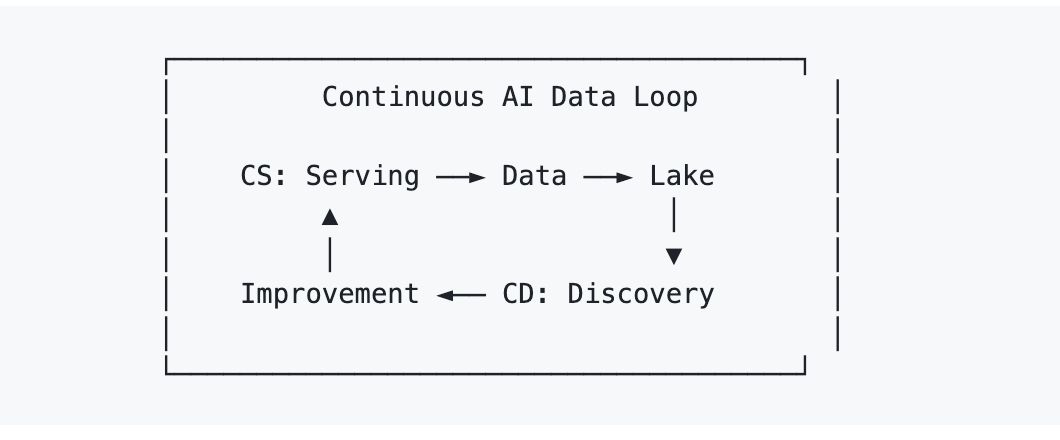
- Continuous Serving ist der offensichtliche Teil: Das Live-System übernimmt Retrieval und Generierung in der Produktion.
- Continuous Discovery ist der weniger offensichtliche Teil: Das System analysiert kontinuierlich, was es angesammelt hat, Abdeckungslücken, Fehlermodi, Cluster-Strukturen, Datenqualitätsprobleme, und schreibt die daraus resultierenden Verbesserungen zurück in dieselbe operative Umgebung.
Das ist wichtig, denn sobald Serving und Discovery dieselbe Datengrundlage teilen, sehen Verbesserungen nicht mehr wie Migrationen aus, sondern wie Iterationen. Deduplizierungsergebnisse können zurück in das Live-Retrieval fließen. Qualitätsbewertungen können das Produktions-Ranking beeinflussen. Cluster-Labels können zu Retrieval-Signalen werden. Re-Embedding kann inkrementell über elastische Compute-Ressourcen erfolgen, statt als riesiges Alles-auf-einmal-Ereignis.
Die Architektur beginnt, sich weniger wie eine statische Datenbank und mehr wie eine lebendige Verbesserungsschleife zu verhalten.
Das ist eine weitaus folgenreichere Verschiebung als „Vektordatenbank, aber schneller“.
Schnell skalieren und schnell iterieren mit AI Lakebase
Viele Infrastrukturunternehmen können Skalierung für sich beanspruchen. Viele können Geschwindigkeit für sich beanspruchen. Weniger können glaubhaft sowohl Skalierung als auch kontinuierliche Iteration im selben System für sich beanspruchen.
Zilliz argumentiert, dass die nächste Phase der Enterprise-KI-Infrastruktur beides erfordert.
- Scale Fast bedeutet eine Multi-Region-, Multi-Cloud-Infrastruktur, die Produktions-Workloads in sehr großem Maßstab unterstützen kann, nicht nur Benchmark-Läufe oder Demo-Umgebungen.
- Iterate Fast bedeutet, dass das System so konzipiert ist, dass Offline-Discovery und Online-Serving Teil derselben operativen Schleife sind. Verbesserung ist integriert, nicht nachträglich angefügt.
Diese Unterscheidung ist wichtig, weil Produktions-KI auf zwei gegensätzliche Arten scheitert. Manche Systeme skalieren, stagnieren aber. Sie werden groß, teuer und zunehmend schwer zu verbessern. Andere iterieren schnell in kleinen Umgebungen, werden aber nie zu robusten Produktionssystemen. Das eigentliche Ziel ist keines von beidem. Es ist ein System, das gleichzeitig wachsen und lernen kann.
Das ist das Versprechen hinter dem Wandel von der Vektordatenbank zur AI Lakebase.
Die Vektordatenbank verschwindet bei diesem Übergang nicht. Sie bleibt wichtig. Sie ist weiterhin die Serving-Engine für Echtzeit-Retrieval. Aber sie hört auf, der Endpunkt der Architektur zu sein. Sie wird zu einer Schicht in einem umfassenderen System, so wie relationale Datenbanken in einer Lakehouse-Welt weiterhin existieren, ohne selbst die gesamte Architektur zu definieren.
Und das könnte die nützlichste Art sein, Jensen Huangs Aussage von der GTC zu verstehen.
Wenn unstrukturierte Daten der Kontext von KI sind, dann wird die Obergrenze von KI-Anwendungen nicht nur durch Modelle bestimmt, sondern auch dadurch, wie ausgereift die Infrastruktur für unstrukturierte Daten wird.
Diese Infrastruktur ist noch nicht fertig. Der Markt steckt noch in den Anfängen. Aber die Konturen werden allmählich sichtbar.
Und zunehmend sitzt Milvus genau in ihrer Mitte.
Bleiben Sie dran!
AI Lakebase wird das architektonische Upgrade hinter Milvus 3.0 und eine bedeutende Weiterentwicklung von Zilliz Cloud sein. Wenn Sie einen frühen Einblick erhalten möchten, wohin die Reise geht, kontaktieren Sie uns für Early Access.
Weiterlesen

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.

DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Discover DeepRAG, an advanced retrieval-augmented generation (RAG) model that improves LLM accuracy by retrieving only essential data through step-by-step reasoning.