




Verbesserung der Intelligenz und Effizienz von ChatGPT: Die Stärke von LangChain und Milvus
Dieser Beitrag wurde ursprünglich in TheSequence veröffentlicht und wird hier mit Genehmigung erneut veröffentlicht.
Obwohl ChatGPT erheblich an Popularität gewonnen hat und viele Einzelpersonen seine API nutzen, um ihre Chatbots zu entwickeln oder Langchain zu erkunden, ist es nicht ohne Herausforderungen.
ChatGPT kann oft die Illusion von Intelligenz erzeugen. Nutzer können mit einem Chatbot interagieren, der komplexen Fachjargon verwendet, nur um später festzustellen, dass der Bot unsinnige Antworten generiert oder nicht existierende 404-Links erfindet.
Die Kontextspeicherung ist eine weitere Hürde. ChatGPT speichert nur Aufzeichnungen aus der laufenden Sitzung, was bedeutet, dass ein Bot, der erst vor wenigen Tagen trainiert wurde, so tun kann, als hätte er keine Erinnerung an die Sitzung. Diese „Amnesie“ verdeutlicht die Notwendigkeit eines Chatbots, der Daten speichern und abrufen kann.
Kosten und Leistung sind wichtige Überlegungen bei der Verwendung von ChatGPT oder sogar kleineren Open-Source-Modellen für Inferenz. In vielen Fällen kann dies kostspielig sein und mehrere A100s sowie beträchtliche Zeit erfordern. Entwicklungen müssen die Leistungsengpässe beheben, bevor große Sprachmodelle (LLMs) in Echtzeitanwendungen integriert werden.
Die Verbesserung der Intelligenz von ChatGPT ist der Punkt, an dem die Kombination aus LangChain und Milvus ins Spiel kommt. Mit der Integration von LangChain und Milvus können LLMs die Leistungsfähigkeit von Vector Stores nutzen, um Intelligenz und Effizienz zu steigern. Wie funktioniert das alles? Tauchen wir ein in die Leistungsfähigkeit von LangChain und Milvus in LLM-Anwendungen und erkunden anschließend, wie Sie Ihre eigene Anwendung für KI-generierte Inhalte (AIGC) erstellen und verbessern können.
LangChain für LLM-gestützte Anwendungen
LangChain ist ein Framework zur Entwicklung von Anwendungen, die von Sprachmodellen unterstützt werden. Das LangChain-Framework ist nach den folgenden Prinzipien konzipiert:
- Datenbewusst: ein Sprachmodell mit anderen Datenquellen verbinden
- Agentisch: einem Sprachmodell ermöglichen, mit seiner Umgebung zu interagieren
Das robuste Framework von LangChain besteht aus einer Reihe von Modulen, wie Models, Prompts, Memory, Indexes, Chains, Agents und Callbacks, die die zentralen Abstraktionen sind, die als Bausteine jeder LLM-gestützten Anwendung betrachtet werden können. Für jedes Modul stellt LangChain standardisierte, erweiterbare Schnittstellen bereit. LanghChain bietet außerdem externe Integrationen und sogar End-to-End-Implementierungen für die sofortige Nutzung.
Der LLM-Wrapper steht im Mittelpunkt der LangChain-Funktionalität und bietet eine Vielzahl von LLM-Anbietern wie OpenAI, Cohere, Hugging Face usw. Er bietet eine Standardschnittstelle zu allen LLMs und umfasst gängige Tools für die Arbeit mit ihnen.
Vektordatenbank für LLMs
LangChain bietet eine beeindruckende Auswahl an Large Language Models (LLMs), um unterschiedlichen Anforderungen gerecht zu werden. Aber das ist noch nicht alles. LangChain geht über die Grundlagen hinaus, indem es verschiedene Vektordatenbanken wie Milvus, Faiss und andere integriert, um die semantische Suchfunktionalität zu ermöglichen. Über seinen VectorStore Wrapper standardisiert LangChain die notwendigen Schnittstellen, um das Laden und Abrufen von Daten zu vereinfachen. Beispielsweise ermöglicht LangChain mit der Milvus-Klasse die Speicherung von Feature-Vektoren, die Dokumente darstellen, mithilfe der Methode from_text. Die Methode similarity_search ruft dann Vektoren der Abfrageanweisung ab, um die am besten passenden Dokumente zur Abfrage im Einbettungsraum zu finden, und erleichtert so die semantische Suche.
Wenn wir tiefer in das Thema eintauchen, erkennen wir, dass Vektordatenbanken eine bedeutende Rolle in LLM-Anwendungen spielen, wie aus dem chatgpt-retrieval-plugin ersichtlich ist. Doch damit endet ihr Nutzen nicht. Vektordatenbanken haben eine Fülle weiterer Anwendungsfälle, was sie zu einem unverzichtbaren Bestandteil von LLM-Anwendungen macht:
- Vektordatenbanken erleichtern die kontextbasierte Speicherung, eine hilfreiche Funktion in LLM-Plattformen wie Auto-GPT und BabyAGI. Diese Fähigkeit verbessert das kontextuelle Verständnis und die Speicherung von Erinnerungen.
- Vektordatenbanken bieten semantisches Caching für LLM-Plattformen wie GPTCache, was die Leistung optimiert und Kosteneinsparungen ermöglicht.
- Vektordatenbanken ermöglichen Dokumentenwissensfunktionen, wie etwa OSSChat, die Halluzinationen beheben.
- Und vieles mehr.
Wenn Sie mehr über Milvus und Auto-GPT erfahren möchten, können Sie diesen Artikel darüber lesen, wie Milvus Auto-GPT antreibt. Im folgenden Abschnitt erfahren Sie, wie LangChain und Milvus Halluzinationen beheben können.
Warum LangChain + Milvus Halluzinationen beheben können
In der künstlichen Intelligenz gibt es die Redensart, dass das System häufig „Halluzinationen“ erzeugt, was bedeutet, Fakten zu erfinden, die nichts mit der Realität zu tun haben. Manche beschreiben ChatGPT sogar als „einen selbstbewussten Typen, der sehr überzeugenden Unsinn schreiben kann“, und das Halluzinationsproblem untergräbt die Glaubwürdigkeit von ChatGPT.
Vektordatenbanken, die im folgenden Diagramm dargestellt sind, gehen das Problem der Halluzinationen an. Zunächst werden die offiziellen Dokumente als Textvektoren in Milvus gespeichert, und als Antwort auf die Frage wird nach relevanten Dokumenten gesucht (die orangefarbene Linie im Diagramm). Chatgpt beantwortet die Frage auf Grundlage des richtigen Kontexts, was zur erwarteten Antwort führt (die grüne Linie im Diagramm).
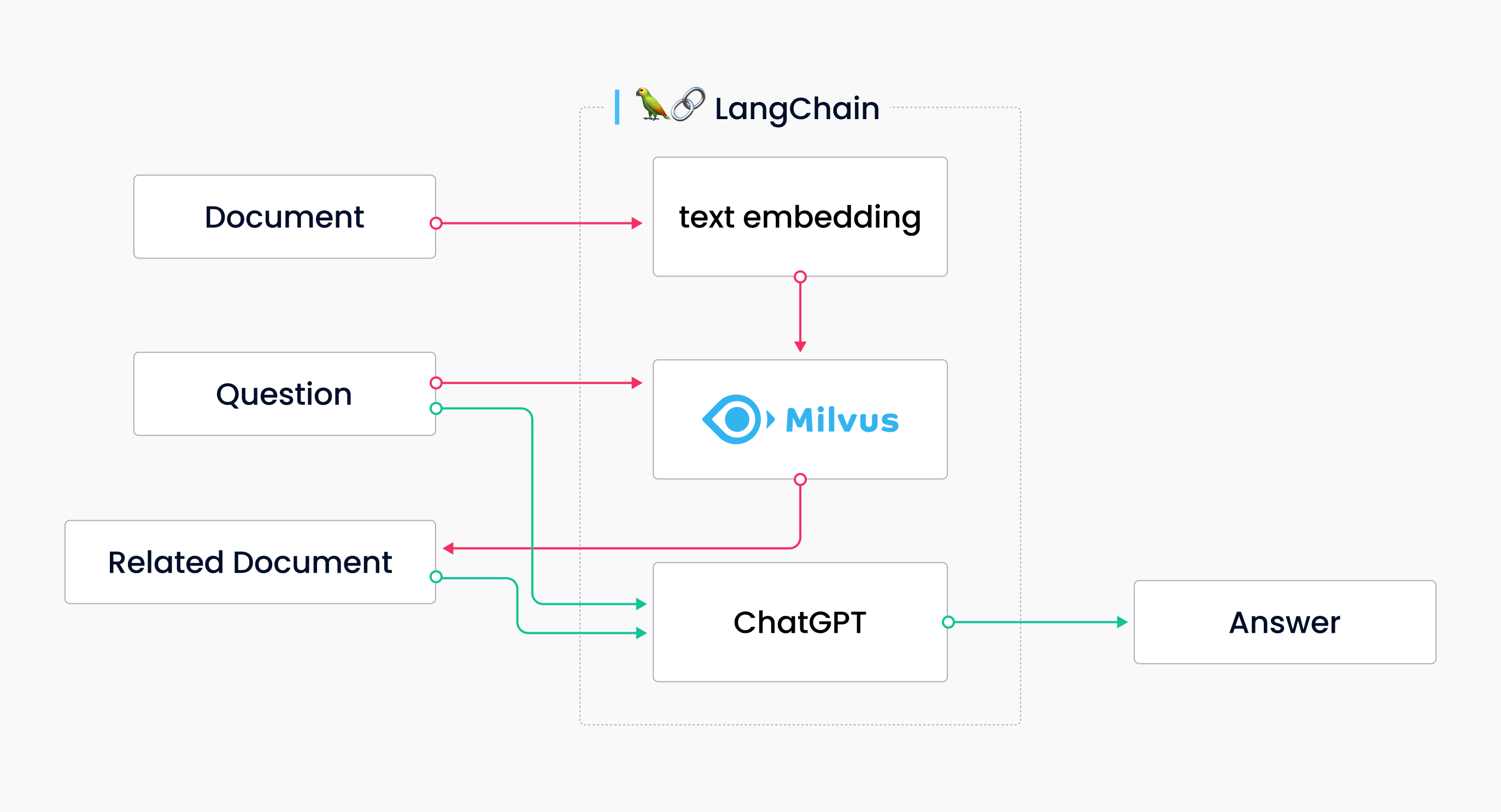 Diagramm mit Langchain, Milvus und ChatGPT
Diagramm mit Langchain, Milvus und ChatGPT
Das obige Beispiel zeigt, dass die Kombination von Milvus und ChatGPT sehr einfach ist. Es ist nicht erforderlich, Daten zu labeln, sie zu trainieren oder zu entwickeln oder sie feinzujustieren – Sie müssen Textdaten in Vektordaten umwandeln und in Milvus einfügen. Die Langchain-Milvus-ChatGPT-Kombination erstellt eine Textspeicherung, und die endgültige Antwort wird aus der Referenzierung des Inhalts in der Dokumentenbibliothek abgeleitet.
Dadurch wird sichergestellt, dass der Chatbot mit dem richtigen Wissen versorgt wird, wodurch die Wahrscheinlichkeit von Fehlern effektiv reduziert wird. Wenn ich beispielsweise als Community-Administrator communitybezogene Fragen beantworten muss, kann ich alle Dokumente aus der offiziellen Dokumentation von Milvus speichern.
Wenn ein Benutzer fragt: „Wie verwendet man Milvus, um einen Chatbot zu erstellen“, beantwortet der Chatbot die Frage auf Grundlage der offiziellen Dokumentation und teilt dem Benutzer mit, dass sie Beispiele für die Erstellung von Anwendungen und das Extrahieren relevanter Dokumente bereitstellt. Diese Art von Antwort ist zuverlässig. Kurz gesagt: Wir müssen nicht alles neu trainieren oder verarbeiten; wir müssen ChatGPT das notwendige Kontextwissen zuführen. Wenn wir eine Anfrage senden, kann der Roboter Kontext liefern, der sich auf die offiziellen Inhalte bezieht.
Sind Sie begeistert, nachdem Sie die Leistungsfähigkeit von Milvus und Langchain für ChatGPT entdeckt haben? Wenn ja, dann machen Sie sich bereit, Ihre Anwendungsentwicklung voranzubringen. Lassen Sie uns zusammenarbeiten und einen verbesserten Chatbot erstellen, indem wir die unglaublichen Fähigkeiten von LangChain und Milvus kombiniert nutzen!
Erstellen Sie Ihre eigene Anwendung mit LangChain und Milvus
0. Voraussetzungen
Installieren Sie zunächst LangChain mit dem Befehl pip install langchain. Für Milvus stehen Ihnen zwei Optionen zur Verfügung. Installieren und starten Sie entweder das Open-Source Milvus auf Ihrem lokalen System oder entscheiden Sie sich für die Cloud-Option, um Zilliz auszuprobieren – einen cloudnativen Dienst für Milvus, der eine kostenlose Testversion anbietet. Zilliz ist ein einfacher, zugänglicher und robuster Dienst, daher werden wir uns damit befassen, wie man Zilliz Cloud für die Anwendung verwendet, und LangChain erleichtert die Nutzung.
1. Daten für die Wissensdatenbank laden
Zunächst müssen wir Daten in ein Standardformat laden. Zusätzlich zum Laden des Textes müssen wir ihn in kleine Teile aufteilen. Dies ist notwendig, um sicherzustellen, dass wir nur die kleinsten, relevantesten Textstücke an das Sprachmodell übergeben.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Milvus
from langchain.document_loaders import TextLoader
loader = TextLoader('state_of_the_union.txt')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
Als Nächstes müssen wir, da wir nun kleine Textabschnitte haben, Einbettungen für jedes Textstück erstellen und sie in einem Vektorspeicher ablegen. Das Erstellen von Einbettungen erfolgt, damit wir die Einbettungen verwenden können, um nur die relevantesten Textstücke zu finden, die an das Sprachmodell gesendet werden sollen. Dies geschieht mit den folgenden Zeilen. Hier verwenden wir die Einbettungen von OpenAI und Zilliz Cloud.
embeddings = OpenAIEmbeddings()
vector_db = Milvus.from_documents(
docs,
embeddings,
connection_args={
"uri": "YOUR_ZILLIZ_CLOUD_URI",
"user": "YOUR_ZILLIZ_CLOUD_USERNAME",
"password": "YOUR_ZILLIZ_CLOUD_PASSWORD",
"secure": True
}
)
2. Daten abfragen
Da wir die Daten nun geladen haben, können wir sie in einer Frage-Antwort-Kette verwenden.
Sieh dir den folgenden Codeausschnitt an, der Teil 3, „Halluzinationen beheben“, dieses Artikels behandelt. Er kann dir helfen, das Konzept vollständig zu verstehen.
Dabei wird in der Wissensdatenbank nach Dokumenten gesucht, die mit unserer angegebenen Abfrage zusammenhängen. Verwende dazu die Methode similarity_search, um den Merkmalsvektor für die Abfrage zu generieren und anschließend die Vektoren in Zilliz Cloud nach ähnlichen Übereinstimmungen sowie den zugehörigen Dokumentinhalten zu durchsuchen.
query = "What did the president say about Ketanji Brown Jackson"
docs = vector_db.similarity_search(query)
Führe dann load_qa_chain aus, um die endgültige Antwort zu erhalten. Sie bietet die allgemeinste Schnittstelle zur Beantwortung von Fragen. Sie lädt eine Kette, die QA für die Eingabedokumente durchführen kann und den GESAMTEN Text in den Dokumenten verwendet.
Der folgende Code verwendet OpenAI als LLM. Beim Ausführen erhält die QAChain input_documents und question als Eingabe. input_documents ist das Dokument, das mit der query in der Datenbank zusammenhängt. Anschließend organisiert das LLM die Antwort basierend auf dem Inhalt dieser Dokumente und der gestellten Frage.
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
chain = load_qa_chain(llm, chain_type="stuff")
chain.run(input_documents=docs, question=query)
Warum Milvus für die AIGC-Anwendung besser ist
Wenn du also deine Anwendungen für durch künstliche Intelligenz generierte Inhalte (AIGC) zuverlässiger machen möchtest, ist eine Vektordatenbank, die Text repräsentiert, notwendig. Aber warum die Milvus-Vektordatenbank wählen?
- Semantische Suche: Milvus speichert die extrahierten semantischen Merkmalsvektoren und ermöglicht so eine intelligente und bequeme semantische Suche, die für traditionelle Datenbanken schwierig ist. Vektordatenbanken machen die semantische Suche intelligenter und bequemer.
- Skalierbarkeit: Die Unterstützung von Cluster- und Cloud-Skalierung ermöglicht es, Milliarden von Entitäten problemlos zu speichern und abzurufen. Skalierbarkeit ist für Anwendungen unerlässlich, bei denen Geschwindigkeit und Effizienz von größter Bedeutung sind.
- Hybride Suche: Milvus unterstützt die Suche mit gemischten Vektor- und Skalardaten, wodurch unterschiedliche Suchszenarien und Anforderungen erfüllt werden können.
- Umfangreiche APIs: Milvus bietet mehrsprachige APIs, darunter Python, Java, Go, Restful und mehr; Milvus lässt sich leicht in verschiedene Anwendungen integrieren und nutzen.
- LLMs integrieren: Integrationen mit mehreren LLMs, darunter OpenAI Plugin, Langchain und LLamaIndex, ermöglichen es Benutzern, ihre Anwendungen noch weiter zu personalisieren.
- Mehrere Setups: Wir haben Milvus so entwickelt, dass es viele Anwendungsfälle unterstützt, von Ihrem lokalen Laptop bis hin zu Cloud-Produkten wie Milvus-lite, Docker-Containern, verteilten Bereitstellungen und Cloud-Nutzung. Dadurch lässt sich Milvus leicht an unterschiedliche Anwendungsgrößen anpassen und unterstützt alles von kleinen Projekten bis hin zur Datenabfrage auf Unternehmensebene.
Nächster Schritt für Ihre Anwendung
Im Bereich der KI können ständig neue Fortschritte und bahnbrechende Technologien Ihre Anwendung auf die nächste Stufe heben. Hier gehen wir auf zwei Möglichkeiten ein, Ihre Anwendung zu verbessern: die Implementierung von GPTCache und die Abstimmung von Embedding-Modellen und Prompts. Dies kann die Leistung und Suchqualität verbessern, Ihre Anwendung hervorheben und eine bessere Benutzererfahrung bieten.
Verbessern Sie die Leistung Ihrer AIGC-Anwendung – GPTCache
Wenn Sie die Leistung optimieren und Kosten für Ihre AIGC-Anwendung sparen möchten, sehen Sie sich GPTCache an. Dieses innovative Projekt wurde entwickelt, um einen semantischen Cache zum Speichern von LLM-Antworten zu erstellen.
Wie hilft das also? Durch das Zwischenspeichern von Antworten an LLMs und eine Vektordatenbank, die ähnliche Fragen abrufen kann, um die zwischengespeicherte Antwort zu erhalten, kann Ihre Anwendung Benutzer schnell und präzise beantworten. Mit GPTCache wird der Zugriff auf zwischengespeicherte Antworten zum Kinderspiel – keine redundanten Antwortgenerierungen mehr, was letztlich Zeit und Rechenressourcen spart. GPTCache geht noch einen Schritt weiter, indem es die gesamte Benutzererfahrung verbessert. Schnellere und genauere Antworten zufriedenzustellen, wird Ihre Antwort verbessern, und Ihre Anwendung wird erfolgreicher sein.
Verbessern Sie Ihre Suchqualität – stimmen Sie Ihre Embedding-Modelle und Prompts ab
Neben der Nutzung von GPTCache kann die Feinabstimmung Ihrer Embedding-Modelle und Prompts die Qualität Ihrer Suchergebnisse verbessern. Embedding-Modelle sind eine entscheidende Komponente von KI-Anwendungen, da sie die Bausteine sind, die Text in numerische Vektoren übersetzen, die Deep Learning verarbeiten kann. Durch die Abstimmung Ihrer Embedding-Modelle können Sie die Genauigkeit und Relevanz Ihrer semantischen Suchergebnisse verbessern. Dazu gehört, die Modelle so anzupassen, dass bestimmte Keywords und Phrasen priorisiert werden, und ihre Gewichtungs- und Bewertungsmechanismen zu optimieren, damit sie die Bedürfnisse und Präferenzen Ihrer Zielgruppe besser widerspiegeln. Mit einem gut trainierten Embedding-Modell kann Ihre AIGC-Anwendung Benutzereingaben präzise interpretieren und kategorisieren, was zu genaueren Suchergebnissen führt.
Abgesehen davon spielen die in den Anwendungen verwendeten Prompts eine wesentliche Rolle bei der Verbesserung der Qualität der Suchergebnisse. Prompts sind die Formulierungen, die Ihre KI verwendet, um Nutzer zur Eingabe aufzufordern, wie etwa „Wie kann ich Ihnen heute helfen?“ oder „Was geht Ihnen durch den Kopf?“. Durch das Testen und Anpassen dieser Prompts können Sie die Qualität und Relevanz Ihrer Suchergebnisse verbessern. Wenn Ihre Anwendung beispielsweise auf eine bestimmte Branche oder Zielgruppe ausgerichtet ist, können Sie Ihre Prompts so anpassen, dass sie die von dieser Gruppe verwendete Sprache und Terminologie widerspiegeln. Dies hilft dabei, die Nutzer zu relevanteren Suchanfragen zu führen, was zu einer zufriedenstellenderen Erfahrung führt, indem ihre Bedürfnisse genauer erfüllt werden. Indem Sie Prompts verfeinern, um die Anforderungen der Nutzer zu erfüllen, können Sie ihnen helfen, erfolgreichere Suchen durchzuführen, was wiederum zu einer zufriedeneren Nutzerbasis führt.
Am Ende
Zusammenfassend lässt sich sagen, dass LangChain und Milvus die perfekten Zutaten für Entwickler sind, die LLM-gestützte Anwendungen von Grund auf erstellen. LangChain bietet eine standardisierte und benutzerfreundliche Schnittstelle für LLMs, während Milvus bemerkenswerte Speicher- und Abruffunktionen bereitstellt. LangChain und Milvus können die Intelligenz und Effizienz von ChatGPT verbessern, was Ihnen hilft, die Hürden von Halluzinationen zu überwinden. Noch besser: Mit GPTCache-, Prompt- und Modell-Tuning-Technologien können wir unsere KI-Anwendungen auf eine Weise verbessern, die zuvor undenkbar war.
Während wir weiterhin die Grenzen der KI erweitern, lassen Sie uns zusammenarbeiten und eine bessere Zukunft für AIGC schaffen, um das grenzenlose Potenzial der künstlichen Intelligenz zu erkunden.

Weiterlesen

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

Zilliz Cloud BYOC Now Available Across AWS, GCP, and Azure
Zilliz Cloud BYOC is now generally available on all three major clouds. Deploy fully managed vector search in your own AWS, GCP, or Azure account — your data never leaves your VPC.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.