




How Zilliz Ended Up at the Center of NVIDIA’s Unstructured Data Story at GTC 2026
At NVIDIA GTC this year, amid the usual avalanche of chip, system, and infrastructure claims, Jensen Huang put up a slide that mattered for a different reason.
It was not about the next GPU. It was not about model size. It was not even really about inference.
It was about data.
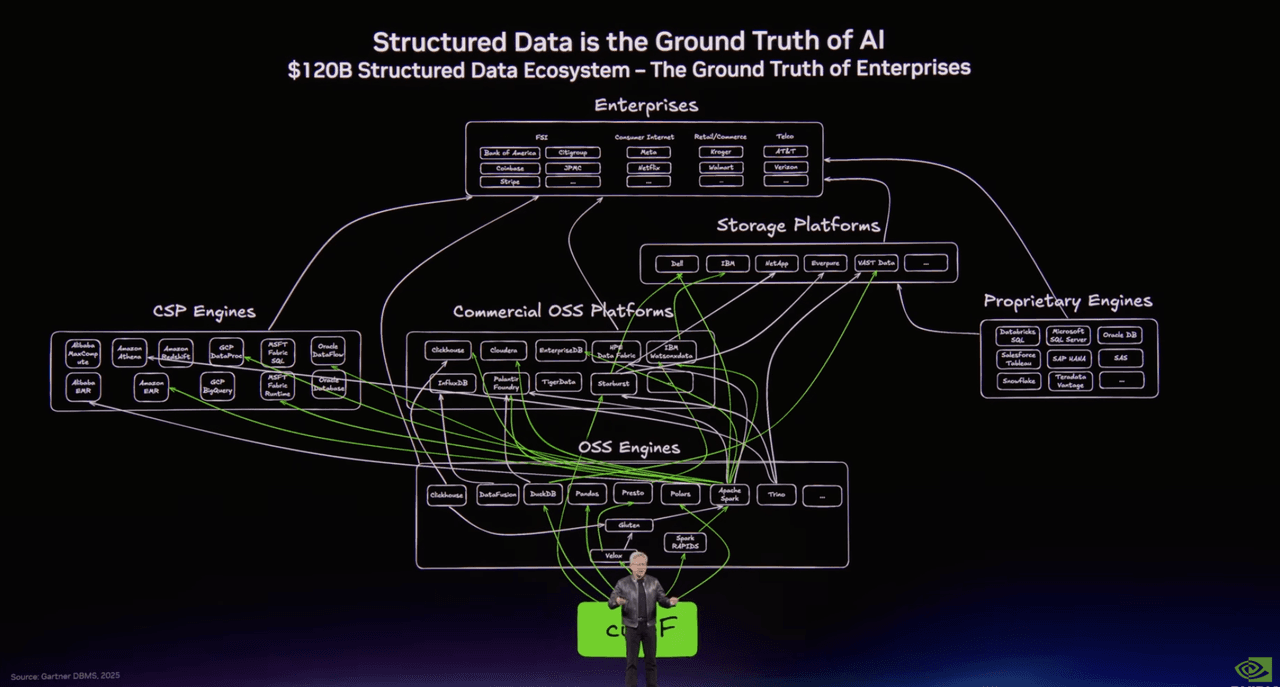
One slide mapped the world of structured data: Spark, Presto, DuckDB, Polars, Snowflake, Databricks, BigQuery, the familiar machinery that has powered analytics and data engineering for decades.
Another mapped the emerging stack for unstructured data. And there, in the middle of that second picture, sat Milvus in open source and Zilliz Cloud in the enterprise database layer.

The title on the slide said everything: Unstructured Data is the Context of AI.
That line is easy to nod along with. Of course, AI needs context. Of course, most enterprise data is unstructured. Of course, text, images, video, audio, logs, PDFs, and all the rest now matter more than ever. But once you get past the slogan, a harder question appears: if unstructured data is becoming the real substrate of AI systems, what does the infrastructure for that world actually look like?
That is the more interesting story. And it is the reason Milvus has gone from a specialized vector database to a much more strategic position in the AI stack.
Why Zilliz (Milvus) Keeps Showing Up
This was not the first time Zilliz showed up at GTC, and it probably will not be the last.
Long before vector databases became a default building block in modern AI systems, Milvus was built around the idea that similarity search would need to operate at a very different scale from traditional databases. GPU acceleration was not an afterthought. It was part of the design logic from the start.
That mattered once AI stopped being a research story and became an infrastructure story.
At GTC 2023, Jensen Huang was already calling out the deeper integration between NVIDIA’s acceleration libraries and systems like FAISS, Redis, and Milvus. A year later, at GTC 2024, that relationship became more concrete with Milvus 2.4, which brought full GPU acceleration to vector indexing and search by combining NVIDIA GPUs with CAGRA from RAPIDS cuVS. The result was not a cosmetic speedup. In some benchmark settings, search performance improved by as much as 50x over HNSW.
By the time Milvus 2.6 arrived, the conversation had evolved again. The question was no longer whether GPU acceleration mattered. It was how to use it cost-efficiently. Milvus 2.6 introduced more flexible deployment patterns for CAGRA, including hybrid GPU-CPU architectures that use the GPU for graph construction and the CPU for retrieval. That matters because most enterprises do not want the fastest possible system at any price. They want a system that stays fast enough while remaining economically sane.
That detail is worth pausing on, because it says something larger about why Milvus has become important. This is not just a story about vector search performance. It is a story about what happens when vector retrieval stops being an experimental feature and becomes part of the production infrastructure.
What It Takes to Make Vector Search Work in Production
Speed alone stops being the story.
But once vector retrieval moves out of demos and into real systems, speed alone stops being the story.
The harder question is what it takes to make retrieval practical at enterprise scale, without turning the surrounding stack into a mess of brittle pipelines, high memory pressure, and rising infrastructure costs.
Part of that challenge starts upstream. In the old model, turning a PDF, image, or document into something searchable usually meant stitching together a separate parsing layer, chunking logic, embedding services, and database writes. The retrieval system only began working after a lengthy preprocessing chain had already completed its work. Milvus 2.6 started collapsing that boundary with a Data-in, Data-out approach, allowing raw content to be written directly into the system and embedded inside the database itself.
Part of it sits inside the retrieval layer. Different workloads require different trade-offs, so support multiple index types rather than forcing a single retrieval strategy on every use case. Compression becomes part of the equation too. Features such as Int8 and RaBitQ are not flashy additions, but they address a more important goal: reducing memory pressure and costs without sacrificing retrieval quality.
And part of it is simply operational. Milvus introduced a redesigned write-ahead logging architecture that eliminated the need for Kafka and Pulsar from the stack, reducing both complexity and overhead. That kind of engineering rarely gets headlines, but it is exactly the kind that determines whether infrastructure remains interesting in theory or becomes usable in practice.
Storage turns out to be another fault line.
As AI systems grow, so does the cost of pretending that all data must be treated the same way, all the time. On a large multi-tenant platform, only a small portion of data may actually be active on a given day. Most of it sits cold. But traditional full-load architectures still treat everything as if it deserves the same local residency, the same performance posture, and the same cost footprint.
At a small scale, that looks inefficient. At enterprise scale, it becomes hard to justify.
Milvus 2.6 addressed that with tiered storage. Hot data stays local, where latency matters. Cold data is loaded on demand from lower-cost object storage. And the boundary between the two shifts dynamically as the system is actually used. That sounds like a modest systems optimization. In practice, it changes the economics of retrieval. When the right data lives in the right tier, storage costs can fall by more than 70 percent.
None of this is especially glamorous. But that is usually how infrastructure matures: not through a single dramatic breakthrough, but through a series of design decisions that make the system faster, cheaper, and easier to live with.
And all these features have been available in Zilliz Cloud, Milvus's fully managed service.
The Real Problem With Unstructured Data
The bigger shift, though, is not really about Milvus alone. It is about the kind of data AI systems now depend on.
Structured data evolved in a long, orderly manner. Rows, columns, schemas, indexes, warehouses, query engines. The tooling matured over decades because the data itself fit the assumptions on which those systems were built. You knew what a record looked like. You knew what fields to query. You knew how to index them.
Unstructured data breaks that model.
A contract is not a row. Neither is a medical image, a support transcript, a code repository, or a surveillance feed. These objects can be stored, but storing them is the easy part. The hard part is making them searchable in a way that understands meaning rather than exact field matches.
That is why embeddings changed everything. Once text, images, audio, and other forms of content could be mapped into a high-dimensional vector space, retrieval no longer had to depend on exact symbolic matching. Systems could retrieve by similarity, intent, and context.
That was the breakthrough.
It was also the beginning of a new infrastructure problem.
Once unstructured data becomes queryable, enterprises immediately face the economics of scale. Millions of documents become hundreds of millions of embeddings. A model upgrade means re-embedding the historical corpus. Retrieval quality depends on index quality. Latency matters in production. So does storage cost. So does the operational burden of keeping all of this in sync.
In other words, semantic retrieval solved the access problem, but exposed the systems problem.
That is the context in which Milvus makes sense.
Why a Vector Database Was Not Enough
For the first wave of AI-native companies, the answer was straightforward: use a vector database as the retrieval layer, connect it to a model, and build the application from there. That model worked, and it still works, especially when semantic search is the core of the product.
But large enterprises tend to hit a different wall.
The issue is not whether they can get vector search working. The issue is what happens after that.
Raw files live in object storage or data lakes. Embeddings live in a vector database. Metadata lives in a relational system. Offline processing happens elsewhere. Search logs pile up in another pipeline. Then the embedding model changes, or the ranking logic changes, or the knowledge base needs curation, or someone wants to trace why a retrieval system keeps failing on edge cases. Suddenly, the system is not one system anymore. It is a patchwork.
That patchwork creates three familiar problems.
- The first is data silos. The data required to run one AI feature is spread across multiple systems, each with its own format, lifecycle, and operational model.
- The second is the iteration cost. When an embedding model changes, the rewrite is not incremental by default. It can become a months-long reindexing and migration effort.
- The third is the broken loop between online serving and offline improvement. The system serves queries in production, but the signals that could make it better, deduplication outputs, clustering labels, quality scores, and failure analyses, often live in separate environments and never cleanly flow back into the retrieval layer.
That is the point where buying a vector database stops feeling like the answer and starts feeling like the beginning of a larger architectural question.
If the real problem is continuous improvement at scale, then the architecture has to change.
From Vector Database to AI Lakebase
Before the AI boom, Databricks helped popularize the Lakehouse model by collapsing the awkward split between data lakes and data warehouses. Instead of maintaining separate systems for storage, analytics, and large-scale processing, enterprises could work from a more unified foundation.
The AI era is forcing a similar rethink, but around unstructured data.
If you look closely at the infrastructure diagrams Jensen Huang has been using, the center of gravity is moving. In the structured data era, frameworks like Spark sat at the heart of the pipeline. In the era of unstructured data, vector infrastructure like Milvus is beginning to fill that role. Not because vector search is the only thing that matters, but because it increasingly sits at the junction between raw data, embeddings, indexes, and application retrieval.
That opens up a larger possibility: what if vector retrieval were not treated as a separate serving layer bolted onto the side of the stack? What if it were integrated directly with the enterprise data lake and the surrounding data workflows?
AI Lakebase Architecture
That is the idea behind AI Lakebase.
The point of AI Lakebase is not to add yet another product category to an already crowded market. The point is to replace a fragmented pattern with a more coherent one.
- At the bottom sits a unified storage layer. Some of that data lives in Zilliz-native collections optimized for high-performance vector retrieval. Some of it remains in open formats the enterprise already uses, Iceberg, Lance, Paimon, and raw files in object storage. The important part is that the data does not need to be copied into five different systems just to become usable.
- On top of that sits the production serving layer, built for real-time retrieval. In Zilliz Cloud, that means Cardinal-powered serving clusters optimized for millisecond-level latency, with different modes for performance, capacity, and tiered hot-cold data placement. In practice, that means frequently accessed data stays local while cold data is loaded on demand from cheaper storage. The result is not just better system design. It is cost control.
- Then there is the elastic compute layer: on-demand clusters for ETL, deduplication, clustering, data quality analysis, re-embedding, evaluation, and interactive investigation. These are not side systems glued on later. They are part of the same foundation.
All three layers share the same data rather than maintaining multiple disconnected copies.
That sounds like an architectural clean-up story, and it is. But it is more than that.
But the bigger point is what that architecture makes possible.
AI Lakebase is more than an architectural cleanup
Most AI systems today can serve. Far fewer can improve systematically.
That is not usually because the model is wrong. It is because the infrastructure around it makes feedback expensive.
A production system generates signals constantly. Every query tells you something. Every failed retrieval tells you something. Every low-quality answer, every repeated result, every dead-end interaction, every cluster of similar documents, every noisy chunk in the corpus, that is all information that could be used to improve the system.
But in most stacks, those signals are scattered across serving logs, offline pipelines, notebooks, dashboards, and one-off scripts. The system runs, but it does not really learn from its own experience.
The AI Lakebase's framing for solving that is Continuous Serving/Continuous Discovery (AI CS/CD).
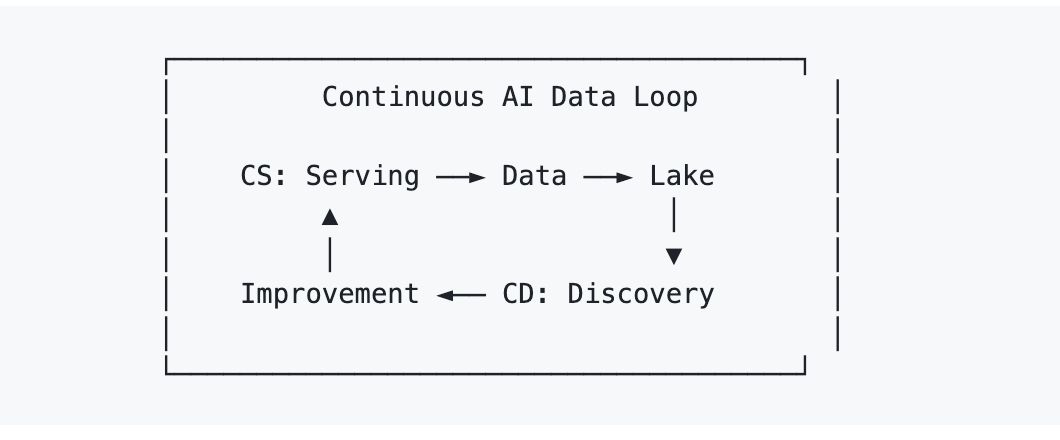
- Continuous Serving is the obvious part: the live system handles retrieval and generation in production.
- Continuous Discovery is the less obvious part: the system continuously analyzes what it has accumulated, coverage gaps, failure modes, cluster structure, data quality issues, and writes the resulting improvements back into the same operational environment.
That matters because once serving and discovery share the same data foundation, improvements stop looking like migrations and start looking like iterations. Deduplication results can flow back into live retrieval. Quality scores can influence production ranking. Cluster labels can become retrieval signals. Re-embedding can happen incrementally via elastic compute rather than as a giant all-at-once event.
The architecture starts to behave less like a static database and more like a living improvement loop.
That is a much more consequential shift than “vector database, but faster.”
Scale Fast and Iterate Fast with AI Lakebase
Many infrastructure companies can claim scale. A lot can claim speed. Fewer can plausibly claim both scale and continuous iteration in the same system.
Zilliz argues that the next phase of enterprise AI infrastructure requires both.
- Scale Fast means multi-region, multi-cloud infrastructure that can support production workloads at very large scale, not just benchmark runs or demo environments.
- Iterate Fast means the system is designed so that offline discovery and online serving are part of the same operational loop. Improvement is built in, not bolted on.
That distinction matters because production AI fails in two opposite ways. Some systems scale but stagnate. They become large, expensive, and increasingly hard to improve. Others iterate quickly in small environments but never become durable production systems. The real goal is neither. It is a system that can grow and learn simultaneously.
That is the promise behind the move from vector database to AI Lakebase.
The vector database does not disappear in that transition. It still matters. It is still the serving engine for real-time retrieval. But it stops being the architecture's endpoint. It becomes one layer in a broader system, just as relational databases still exist in a Lakehouse world without defining the entire architecture themselves.
And that may be the most useful way to read Jensen Huang’s line from GTC.
If unstructured data is the context of AI, then the ceiling of AI applications will be set not just by models, but by how mature the infrastructure for unstructured data becomes.
That infrastructure is still unfinished. The market is still early. But the outline is starting to come into view.
And increasingly, Milvus is sitting right in the middle of it.
Stay tuned!
AI Lakebase will be the architectural upgrade behind Milvus 3.0 and a major evolution of Zilliz Cloud. If you want an early look at where this is heading, contact us for early access.
Keep Reading

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.