




Read AI масштабирует разговорный интеллект с помощью Milvus для миллионов активных пользователей

Менее 20-50 мс
задержка извлечения данных для миллионов пользователей в месяц
ускорение в 5 раз
в агентном поиске
Миллионного масштаба
поддержка активных арендаторов
Улучшенный пользовательский опыт
обеспечивая переход от реактивного поиска к проактивному
We've got millions of monthly active users and all of the underlying data when we're trying to go find related conversations, find updates to an action item, find referenced documents...Milvus serves as the central repository and powers our information retrieval among billions of records.
Rob Williams
Резюме
Read AI требовалась высокопроизводительная векторная база данных для поддержки поиска корпоративного масштаба по неструктурированным источникам коммуникаций, включая встречи, чаты, электронные письма и внутренние базы знаний. Выбрав Milvus в качестве основы своей инфраструктуры семантического поиска, Read AI смогла индексировать и запрашивать насыщенные повествовательными данными эмбеддинги в масштабе, обеспечив быстрый и точный поиск по миллиардам записей.
Задержка поиска менее 20–50 мс для миллионов ежемесячных пользователей
Высокая масштабируемость для обслуживания миллионов активных арендаторов
Значительный рост продуктивности разработчиков
«У нас миллионы ежемесячных активных пользователей и все базовые данные, когда мы пытаемся найти связанные разговоры, найти обновления по пункту действий, найти упомянутые документы... Milvus служит центральным репозиторием и обеспечивает наш поиск информации среди миллиардов записей».--Роб Уильямс, сооснователь и CTO Read AI
О Read AI
Read AI — ведущая компания в области продуктивного ИИ, помогающая миллионам людей уделять больше времени работе, которая имеет наибольшее значение. Первоначально сосредоточенная на снижении усталости от встреч, компания превратилась в полнофункциональную интеллектуальную платформу, которая также предлагает прогнозируемые следующие шаги, корпоративный поиск и коучинг в реальном времени, бесшовно интегрирующийся с инструментами в календарях (Google Calendar, Outlook 365, Zoom Calendar), CRM (Salesforce, HubSpot), платформах для совместной работы (Jira, Confluence, Notion), приложениях для обмена сообщениями (Slack, Microsoft Teams), инструментах для заметок (Google Docs, OneNote), электронной почте (Gmail, Outlook) и видеоконференциях (Zoom, Google Meet, Microsoft Teams). Она загружает и контекстуализирует данные из этих источников, превращая пассивные взаимодействия в структурированные, доступные для запросов и пригодные к действию повествования.
Созданная с ориентацией на потребителя, Read AI поддерживает миллионы пользователей через модель самообслуживания, работая в настоящем интернет-масштабе с миллиардами событий разговоров, обработанных в бесчисленных предприятиях.
Техническая задача
Из-за стремительного роста Read AI столкнулась с фундаментальной задачей организации и извлечения неструктурированных коммуникационных данных из широкого спектра источников — от встреч и чатов до обновлений CRM, календарей, цепочек электронных писем и обращений в поддержку. Каждый источник несет ценные сигналы, но существует в изолированных хранилищах, не имеет единообразной структуры и с трудом поддается эффективному поиску. Ожидание: предоставлять интеллектуальные, контекстные результаты в течение 20 минут после любого взаимодействия.
Для этого требовались почти в реальном времени загрузка, преобразование и индексирование данных в различных форматах. От хорошо структурированных внутренних встреч до разреженных сторонних платформ, таких как Slack, Gmail и HubSpot. По мере роста использования Read AI необходимо было поддерживать миллиарды записей среди миллионов арендаторов, тысячи запросов в секунду и задержку менее 20–50 мс. Ранние решения, включая внутренне разработанные хранилища и другие векторные базы данных, такие как Pinecone и Faiss, не смогли удовлетворить эти требования из-за слабой поддержки мультиарендности, ограниченных возможностей фильтрации или недостаточной отзывчивости сообщества.
Архитектура решения с Milvus
Новая архитектура Read AI разработана для высокопроизводительного поиска с низкой задержкой по разнообразным коммуникационным источникам, таким как Slack, Zoom, электронная почта и Salesforce. Эти входные данные проходят через слой эмбеддингов и нарративизации, который преобразует необработанные данные в структурированные повествования и представления с учетом тональности. Все хранится в векторной базе данных Milvus, фактически служащей центральным репозиторием информации.
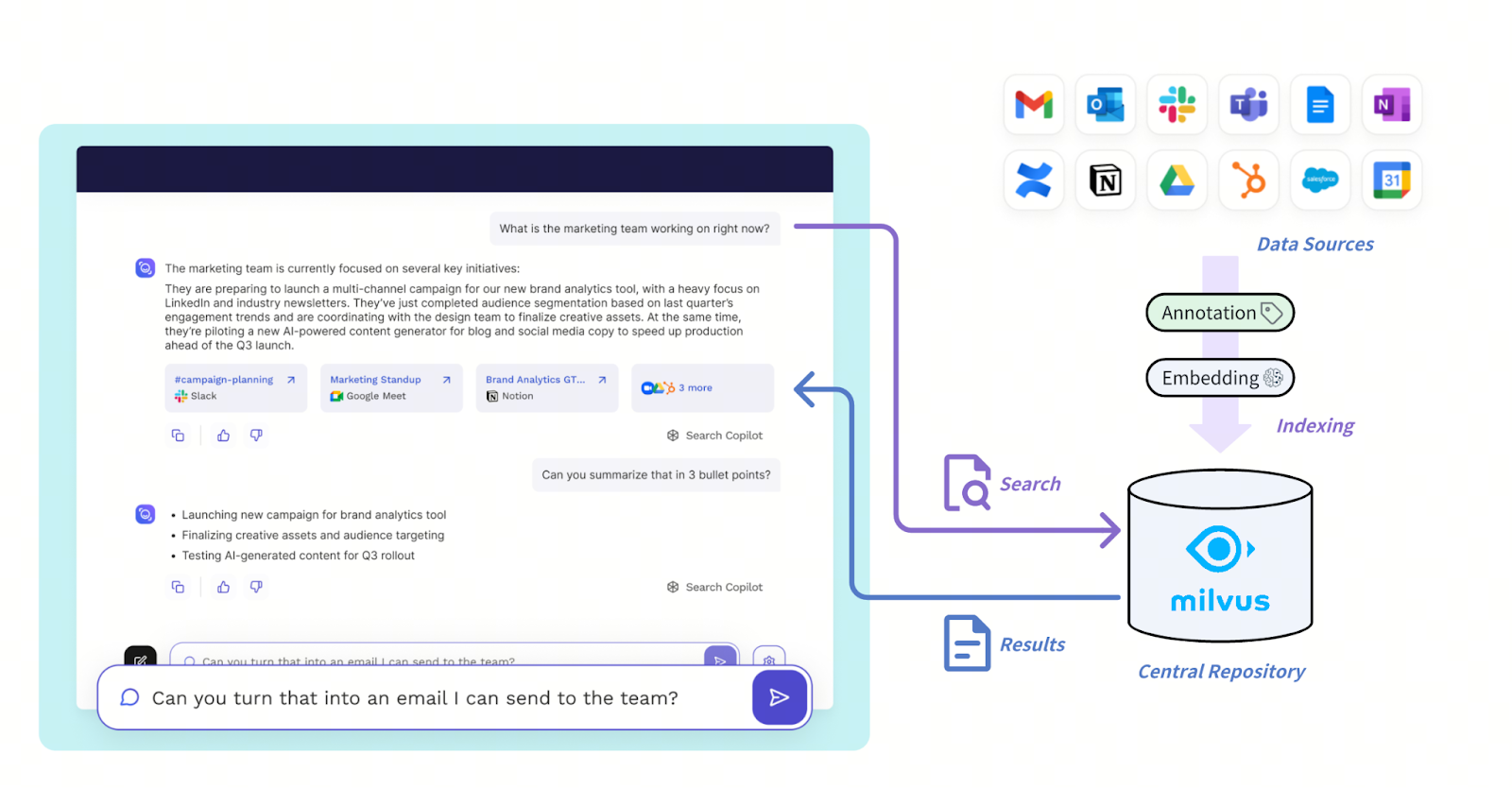 Архитектура решения с Milvus
Архитектура решения с Milvus
Рисунок: Как Mivus поддерживает систему Read AI
Read AI использует фильтрованный векторный поиск, который сочетает векторное сходство с фильтрацией на основе структурированных метаданных, например, ограничивая запросы встречами один на один, конкретными сотрудниками или временными окнами, тем самым обеспечивая нюансированный поиск, такой как «самые незаинтересованные звонки отдела продаж» или «положительная обратная связь на встречах один на один». Оптимизированная фильтрация метаданных в Milvus критически важна для достижения задержки менее 20–50 мс в таком масштабе.
"Milvus дает нам слой хранения, учитывающий нарратив, — не просто текстовые эмбеддинги, а полноценный контекстно-осознанный поиск." — Rob Williams, Co-Founder and CTO at Read AI
Благодаря нативной поддержке мультитенантности в Milvus, Read AI развертывает один кластер Milvus для эффективного обслуживания миллионов арендаторов. Запросы оркестрируются через внутренние агентные фреймворки, которые анализируют намерение поиска и маршрутизируют запросы в Milvus, а затем постобрабатывают результаты для доставки через чат-интерфейсы, сводки или оповещения. Такая архитектура дает Read AI масштабируемость и гибкость для объединения разрозненных типов контента при сохранении скорости и точности, которые критически важны для поиска в реальном времени и ретроспективного анализа.
Техническая оценка и процесс принятия решения
Перед внедрением Milvus команда Read AI оценила несколько альтернатив. FAISS был исключен из-за отсутствия встроенной мультитенантности и ограниченных возможностей фильтрации. Pinecone не предлагал гибкости, необходимой для поддержки поискового паттерна и масштаба Read AI. Полностью самостоятельно размещаемое внутреннее решение также рассматривалось, но не смогло соответствовать требованиям масштабируемости и зрелости для их сценария использования. Milvus выделился по нескольким ключевым факторам:
Способность масштабироваться до миллионов пользователей и миллиардов записей
Стабильная задержка менее 20–50 мс на больших векторных коллекциях
Поддержка гибридных поисковых рабочих процессов
Изоляция на уровне арендатора
Опыт разработчика стал еще одним решающим фактором: понятная документация, отзывчивые мейнтейнеры и практическая инженерная поддержка, особенно во время proof-of-concept. Этап PoC продемонстрировал быструю обработку тестовых нагрузок и предоставил помощь команды Milvus в отладке в реальном времени, что дало Read AI уверенность для перехода в продакшен.
Результаты и преимущества выбора Milvus
С момента развертывания Milvus и наряду с запуском корпоративного поискового инструмента Search Copilot компания Read AI достигла 5-кратного ускорения агентного поиска по разнообразным источникам данных, поддерживая стабильную задержку извлечения около 20–50 мс даже при обработке запросов со сложными фильтрами. Платформа без сбоев подключила миллионы индивидуальных пользовательских аккаунтов к гигантскому кластеру, продемонстрировав надежность распределенной архитектуры Milvus и возможности мультитенантности.
Milvus обеспечивает единый поисковый слой по всем каналам коммуникации — встречам, чатам, электронной почте и CRM. Эластичное масштабирование упрощает эксплуатацию для обработки корпоративных когорт или всплесков трафика. Такие функции, как bulk import, обеспечивают плавный опыт при загрузке больших объемов исторических данных по мере подключения новых предприятий к сервису.
Что еще важнее, Milvus обеспечивает переход от реактивного к проактивному поиску: выводит релевантные инсайты, задачи и риски еще до того, как пользователи спросят, благодаря низколатентному векторному поиску по динамическим мультимодальным контекстам. Эта возможность не только улучшает пользовательский опыт, но и открывает новые бизнес-возможности, поскольку Read AI продолжает фокусироваться на расширении платформы за счет постоянных улучшений в прогнозных рекомендациях и следующих шагах.
"Мы хотели донести интеллект до пользователя еще до того, как он спросит. Именно Milvus сделал это осуществимым." —Rob Williams, Co-Founder and CTO at Read AI
Эти технические достижения напрямую превращаются в бизнес-ценность: пользователи бесплатного тарифа получают значимые инсайты в течение нескольких минут, что повышает удержание, а корпоративные клиенты получают более глубокое извлечение знаний и долгосрочный контекст, укрепляя доверие пользователей и поддерживая возможности премиального апсейла.
Инсайты для разработчиков и инженеров
Уроки, извлеченные из реализации:
Структурированная аннотация может обеспечивать более насыщенные выходные данные LLM на последующих этапах
Векторный поиск должен сохранять свою скорость даже при фильтрации по структурированным метаданным, чтобы соответствовать ожиданиям пользователей от поиска
Изоляция в мультиарендной среде и динамическое масштабирование не подлежат обсуждению на потребительском масштабе
Команда проводит постоянные эксперименты, отслеживая производительность запросов, удовлетворенность пользователей и поведенческие метрики, чтобы непрерывно совершенствовать то, как агенты ищут, фильтруют и ранжируют результаты.
Read AI обрабатывает разговорные данные не только с помощью моделей эмбеддингов, но и с использованием уникального слоя наррации. Эта семантическая абстракция выходит за рамки стенограмм, фиксируя тон, намерение и ключевые события, такие как продвижение сделки или спад вовлеченности. В результате пользователи могут искать по нарративам на естественном языке, например "кто был не вовлечен во время демо", а не просто сопоставлять ключевые слова.
Дорожная карта
В перспективе Read AI сосредоточена на улучшении баланса между нагрузками в реальном времени и офлайн-нагрузками, планируя создать более динамическую оркестрацию между данными live streaming и долгосрочным хранилищем. Они изучают использование предстоящего Milvus Vector Lake для снижения затрат на поиск путем переноса офлайн-запросов с менее строгими ожиданиями по задержке на слой в стиле хранилища данных, поддерживаемый объектным хранилищем.
Еще одно ключевое направление разработки — автоматическое обнаружение пробелов в знаниях: выявление случаев, когда критически важная информация отсутствует или разрознена, и проактивное предоставление инсайтов пользователям еще до того, как они спросят. Все эти улучшения поддерживают долгосрочное видение Read AI: создать “движок действий” для предприятия — контекстно-ориентированную, постоянно работающую платформу на базе ИИ, которая интеллектуально расширяет возможности работников умственного труда во всех каналах коммуникации.
Сохраняя разговорный контекст и исторические инсайты в Milvus, Read AI расширяет доступность институциональных знаний, предоставляя критически важную информацию даже тогда, когда исходный участник офлайн или больше не работает в компании.
Заключение
Путь Read AI от инструмента аналитики встреч к полноформатной интеллектуальной платформе для массовой аудитории требовал инфраструктуры, способной справляться с огромным масштабом, разнородными данными и сложными запросами в реальном времени. Milvus оказался правильным выбором — не только благодаря своей высокой производительности и масштабируемости, но и благодаря гибкости в поддержке аннотированных эмбеддингов, фильтрации метаданных и изоляции в мультиарендной среде.
Используя Milvus как основу своей инфраструктуры векторного поиска, Read AI предоставляет быстрые, надежные и глубоко контекстуальные результаты и рекомендации миллионам пользователей. По мере того как они движутся к созданию постоянно работающего интеллектуального движка действий для предприятия, Milvus продолжает поддерживать их потребности в экономической эффективности, архитектурной гибкости и масштабировании с заделом на будущее, доказывая, что хорошо спроектированная векторная база данных — это больше, чем просто хранилище; это основа современного понимания информации.
What we wanted was to push intelligence to the user before they even asked. Milvus is what made that viable.
Rob Williams