




VDBBench добавляет учитывающий стоимость бенчмаркинг для векторных баз данных
В прошлом году мы выпустили VectorDBBench 1.0, чтобы сделать бенчмаркинг векторных баз данных ближе к производственным нагрузкам. Вместо тестирования только пикового QPS на фиксированных бенчмарк-данных VectorDBBench (также известный как VDBBench) позволяет командам оценивать векторные базы данных с использованием паттернов нагрузки, которые более точно отражают их собственные производственные системы: загрузку данных, фильтрацию, полноту выдачи, задержку, параллелизм и пользовательские наборы данных.
В последнем выпуске VDBBench добавлено новое измерение: стоимость.
Производственные команды редко выбирают векторную базу данных только по производительности. Им нужно знать, сколько стоит достижение целевого QPS, как ведёт себя P99 в рамках этой стоимостной модели, когда вставленные данные становятся доступными для поиска, когда они полностью индексируются, как размер полезной нагрузки влияет на поиск, как система ведёт себя при большом количестве арендаторов и что происходит с первым запросом после простоя. Теперь эти вопросы являются частью VDBBench.
Чтобы показать, как эти новые бенчмарки с учётом стоимости работают на практике, мы протестировали три часто оцениваемых управляемых продукта для векторных баз данных: Zilliz Cloud, Turbopuffer и Pinecone. Результаты опубликованы в новом VDBBench Cost Leaderboard, с графиками и таблицами, которые сравнивают готовность вставленных данных, поиск с полезной нагрузкой, мультитенантный поиск, задержку после холодного старта и компромиссы между стоимостью и производительностью.
Лидерборд — лишь один из способов интерпретации результатов: это снимок трёх продуктов в определённый момент времени. Поскольку VDBBench имеет открытый исходный код, команды также могут воспроизвести эти сценарии, провести бенчмаркинг продуктов, которых нет в лидерборде, или адаптировать нагрузки к собственным данным, похожим на производственные.
Цель состоит не в том, чтобы объявить универсального победителя, а в том, чтобы помочь командам выбрать векторную базу данных, которая лучше всего соответствует их нагрузке, целевым показателям производительности и бюджету.
- Ссылки: VectorDBBench GitHub | Лидерборды VDBBench
Что нового в VDBBench
В этом выпуске добавлены четыре ориентированных на облака бенчмарк-сценария, которые измеряют поведение в production, часто упускаемое лидербордами пикового QPS.
| Сценарий | Что измеряет | Почему это важно |
|---|---|---|
| CloudInsertCase | Завершение вставки, состояние доступности для поиска, состояние полной индексации и стоимость записи | Актуальность и стоимость backfill важны для RAG, каталогов и памяти агентов |
| CloudPayloadSearchCase | QPS, задержку P99, полноту выдачи и форму полезной нагрузки ответа | Возврат векторов или метаданных может изменить стоимостной профиль поиска |
| MultitenantSearchCase | Пропускную способность по множеству арендаторов или пространств имён | SaaS-нагрузки иначе нагружают маршрутизацию и поведение партиций по сравнению с одноарендаторским поиском |
| CloudColdLatencyCase | Первый запрос после простоя по сравнению с прогретым путём запроса | Поведение при холодном старте важно для низкочастотных арендаторов и памяти агентов |
Помимо этих сценариев, Cost Leaderboard добавляет представление cost-Pareto, которое моделирует операционные затраты при целевых уровнях QPS с учётом измеренных пределов обслуживания каждого продукта — потому что решения о покупке обычно зависят от того, где пересекаются производительность и стоимость.
VDBBench Cost Leaderboard использует эти сценарии для публичного сравнения управляемых продуктов. Поскольку сценарии поставляются в VDBBench с открытым исходным кодом, команды могут повторно использовать их для собственной оценки, включая продукты и нагрузки, не показанные в лидерборде.
Кого мы тестировали: Zilliz Cloud vs. Turbopuffer vs. Pinecone
Для этого первого запуска с учётом стоимости мы протестировали три часто оцениваемых управляемых продукта для векторных баз данных. Все продукты были протестированы 10 мая 2026 года в AWS US West (us-west-2). Их операционные модели различаются, поэтому результаты следует интерпретировать с точки зрения соответствия нагрузке, а не как единый рейтинг.
| Продукт | Роль в этом бенчмарке |
|---|---|
| Zilliz Cloud | Управляемая облачная векторная база данных и векторный lakebase от создателей Milvus, протестированная в конфигурациях Tiered и Capacity |
| Turbopuffer | Serverless-векторная база данных, протестированная в режимах unpinned и pinned |
| Pinecone Serverless | Зрелая low-ops serverless-векторная база данных, используемая как распространенная производственная точка отсчета |
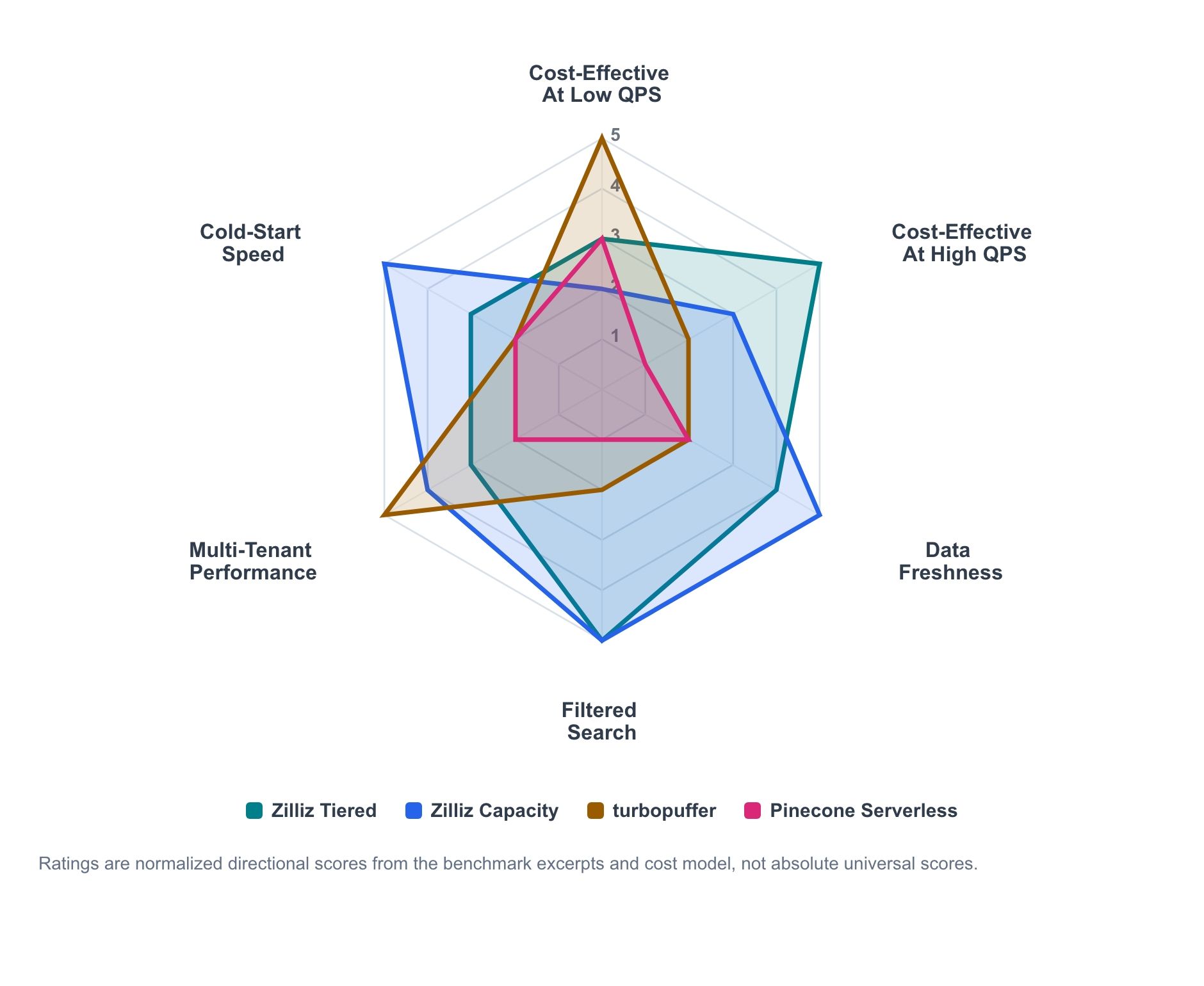
Рисунок 1. Направленное резюме соответствия рабочим нагрузкам на основе выдержек из бенчмарка и моделирования затрат. Оценки нормализованы для сравнения по измерениям рабочих нагрузок и не должны восприниматься как универсальные абсолютные рейтинги.
Радарная диаграмма суммирует направленный сигнал из выдержек бенчмарка и модели затрат. Это не абсолютная таблица оценок; это карта того, где каждый продукт, как правило, наиболее силен.
- Zilliz Cloud Tiered — экономичная линия для активного обслуживания, которая масштабируется по мере роста утилизации.
- Zilliz Cloud Capacity — профиль с более высоким уровнем контроля для предсказуемого обслуживания, свежести и холодного поведения.
- Turbopuffer наиболее силен там, где serverless-экономика с тарификацией по использованию и пропускная способность, ориентированная на пространства имен, соответствуют рабочей нагрузке.
- Pinecone остается полезным low-ops serverless-бейзлайном, даже когда он не является границей соотношения стоимости и производительности в конкретном тесте.
Основная закономерность ясна. Serverless-экономика может быть привлекательной при низком устойчивом QPS. Выделенная мощность становится более конкурентоспособной по мере роста утилизации. Свежесть, поиск с фильтрами, размер полезной нагрузки, количество арендаторов и холодное поведение — все это может повлиять на решение.
Наборы данных и рабочие нагрузки
Кейсы с учетом затрат используют два профиля рабочих нагрузок.
- Single-tenant LAION 100M: 100 миллионов плотных векторов размерности 768. Это представляет крупную производственную коллекцию, где важны размер полезной нагрузки, фильтры, recall и устойчивый QPS.
- Multitenant Cohere 10M: 10 миллионов плотных векторов размерности 768, случайно разделенных между 1 000 арендаторов — примерно по 10K векторов на арендатора. Это представляет рабочие нагрузки в стиле SaaS, где у каждого арендатора меньший набор данных, но система должна эффективно маршрутизировать и обслуживать множество пространств имен или арендаторских разделов.
Выдержки ниже показывают характер полученных результатов. Cost Leaderboard и репозиторий VectorDBBench остаются источником полных матриц, определений клиентов и деталей воспроизведения.
CloudInsertCase: Вставлено — не всегда значит готово
Производительность вставки — это не одно число. Управляемая векторная база данных может принять данные от клиента до того, как эти данные станут безопасными для поиска через предполагаемый путь индекса. Для производственных рабочих нагрузок командам нужно знать, когда операция вставки завершена, когда данные становятся доступными для поиска и когда фоновая индексация полностью догнала.
CloudInsertCase измеряет жизненный цикл от записи до обслуживания. Это важно для обновлений корпусов RAG, обновлений каталогов продуктов, записей памяти агентов и обратной загрузки данных. В таких системах "вставка принята" недостаточно. Операционный вопрос заключается в том, когда недавно записанные данные можно надежно искать с производственной производительностью.
| Продукт / режим | Размер батча | Время вставки | Ожидание доступности для поиска | Ожидание полной индексации | Стоимость записи |
|---|---|---|---|---|---|
| Zilliz Cloud Capacity 12CU | 10,000 | 3.2 ч | 0 мс | 1.9 мин | $9.50 |
| Zilliz Cloud Tiered 4CU | 10,000 | 4.1 ч | 0 мс | 10.9 мин | $6.34 |
| Turbopuffer (backpressure off) | 10,000 | 1.8 ч | 6.4 ч | 2.0 мин | $302 |
| Pinecone Serverless | 10,000 | 72.4 ч | 0 мс | 127 мс | $1,180 |
Таблица 1. Выдержка по вставке LAION 100M с батчем 10k. Затраты и времена взяты из текущего запуска leaderboard. Для выделенных конфигураций Zilliz стоимость записи — это стоимость CU-часов, потребленных в течение окна загрузки и индексации; для Turbopuffer и Pinecone — это тарифицируемая плата за запись. Рассматривайте времена вместе с определениями клиентов для состояний inserted, searchable и fully indexed (определены для каждого клиента в исходном коде VDBBench).
Размер батча меняет показатели для разных продуктов.
- Turbopuffer показывает сильный сырой прием данных в больших батчах, особенно при отключенном backpressure — своем самом агрессивном режиме приема. В пути batch-10k он быстро завершает вставку, но ожидание доступности для поиска доминирует в полном окне готовности.
- Zilliz Cloud более стабилен при разных размерах батча. В протестированных конфигурациях Capacity и Tiered данные становятся доступными для поиска сразу после завершения вставки, а оставшееся ожидание полной индексации измеряется минутами.
- Pinecone Serverless в этом тесте является более медленным базовым вариантом массового приема данных. После того как данные приняты, дополнительное ожидание доступности для поиска и полной индексации в этих прогонах фактически равно нулю, но сам этап вставки занимает значительно больше времени.
Оценка продукта зависит от рабочей нагрузки.
- Zilliz подходит для рабочих процессов, где свежие данные должны быстро становиться доступными для поиска и индексироваться с предсказуемой стоимостью.
- Turbopuffer подходит для больших принятых backfill-загрузок, когда рабочая нагрузка может допустить более длинное окно готовности.
- Pinecone подходит для шаблонов serverless-приема данных меньшего объема, где операционная простота важнее скорости или стоимости массовой загрузки.
Массовая загрузка также является событием затрат. В этом случае вставки LAION 100M конфигурации Zilliz удерживают стоимость на стороне записи в диапазоне единиц долларов для протестированного пути batch-10k. Turbopuffer моделируется примерно на уровне $302. Pinecone Serverless моделируется примерно на уровне $1,180. Это не делает одну модель ценообразования универсально лучше. Это означает, что экономика вставки зависит от того, как часто рабочая нагрузка проходит этот путь.
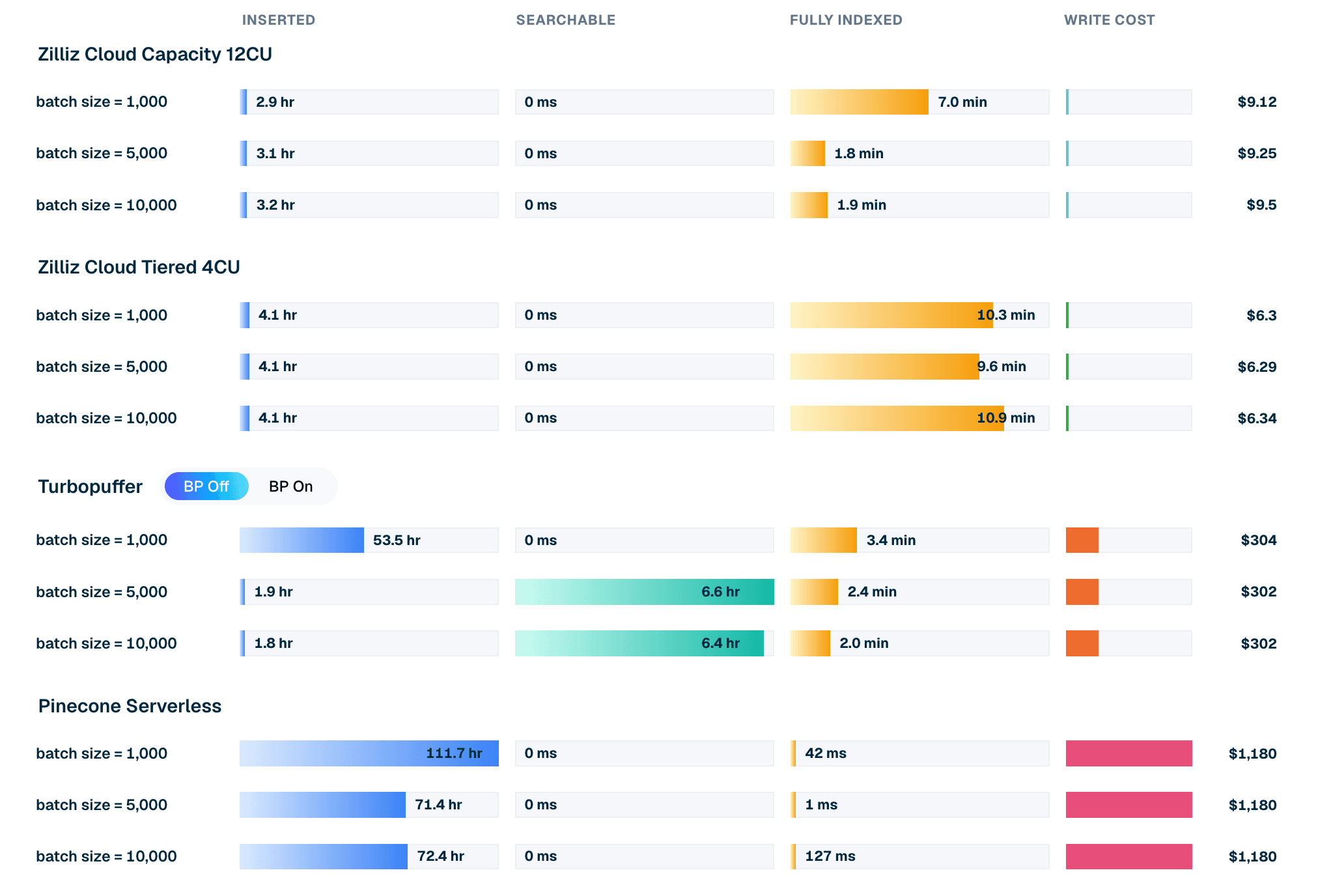
Рисунок 2. Жизненный цикл вставки для LAION 100M при batch 10k: время вставки, ожидание доступности для поиска, ожидание полной индексации и смоделированная стоимость записи для каждого продукта.
CloudPayloadSearchCase: Payload меняет поверхность поиска
После того как данные доступны для поиска, следующий вопрос заключается не только в том, сколько запросов в секунду может обработать база данных. Важна форма ответа. Возврат только ID сильно отличается от возврата метаданных или сырых векторов. 768-мерный вектор может добавить тысячи байтов к каждому результату. При topK=100 размер payload может стать значительным фактором стоимости запроса и задержки.
CloudPayloadSearchCase тестирует single-tenant LAION 100M при разных payload ответа и формах фильтров. Вывод объединяет максимальный конкурентный QPS, задержку P99 при этой конкурентности, тип payload и recall, где доступно.
Одно замечание по чтению таблиц: P99 здесь измеряется при максимальной конкурентности — точке насыщения, которая дает пиковый QPS каждого продукта, — а не в комфортной рабочей точке уровня сервиса. Это показывает, как конфигурация ведет себя на своем измеренном пределе.
| Продукт | Задержка P99 @ максимальная конкурентность | Макс. QPS | recall@10 |
|---|---|---|---|
| Zilliz Cloud Capacity 32CU | 158 мс | 786.1 | 0.9728 |
| turbopuffer | 2.34 с | 395.7 | 0.9321 |
| Zilliz Cloud Capacity 12CU | 299 мс | 376.0 | 0.9723 |
| Turbopuffer pinned | 3.30 с | 68.2 | 0.9321 |
| Zilliz Cloud Tiered 4CU | 5.57 с | 49.2 | 0.9510 |
| Pinecone Serverless | 4.85 с | 4.6 | 0.9609 |
Таблица 2. Single-tenant LAION 100M, без фильтров, ответы только с ID, topK 100. Примечание по Pinecone: его пропускная способность в этом single-tenant случае ограничена server-side троттлингом read-unit, поэтому прогон достигает предела при конкурентности 4–5, против 80 для других продуктов. Читайте его строки как регулируемый serverless-базовый вариант, а не как результат насыщения.
Конфигурация имеет значение. При 12CU Zilliz Capacity и Turbopuffer близки по сырому QPS в этом широком случае только с ID, тогда как Zilliz опережает по recall и задержке P99. При 32CU Zilliz Capacity превышает протестированный результат Turbopuffer для этой single-tenant рабочей нагрузки.
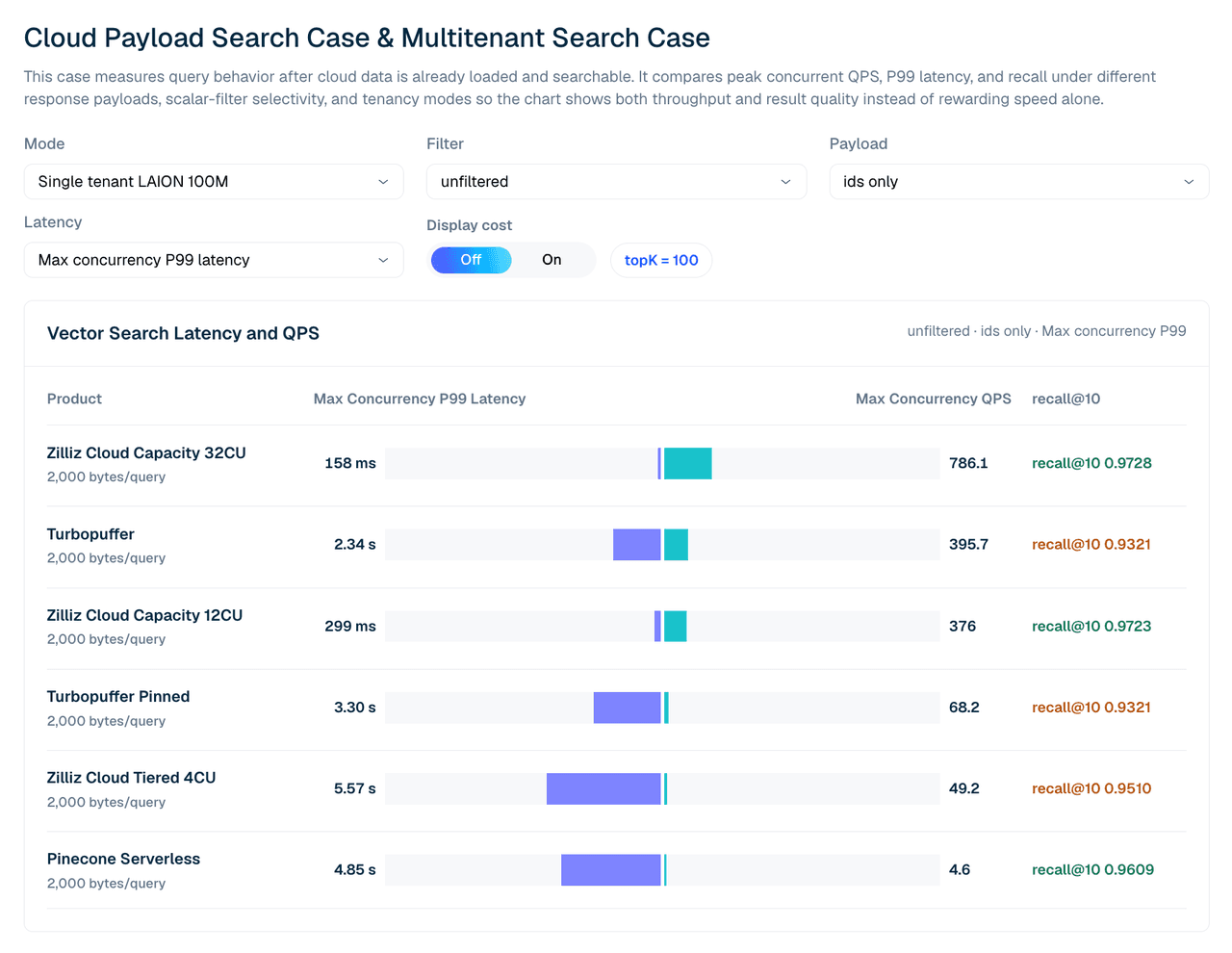
Рисунок 3. Поиск single-tenant LAION 100M с ответами только с ID. Этот вид сравнивает максимальный конкурентный QPS, задержку P99 и recall@10 по протестированным управляемым конфигурациям.
Вопрос не только в том, какой продукт самый быстрый в одной конфигурации. Он в том, как меняется производительность, когда команда покупает больше мощности, изменяет форму payload или нуждается в целевом recall. Когда запрос возвращает raw vector payloads, пропускная способность может заметно измениться.
| Product | IDs-only QPS | Vector payload QPS | Recall |
|---|---|---|---|
| Zilliz Cloud Tiered 4CU | 49.2 | 44.0 | 0.9510 |
| Zilliz Cloud Capacity 12CU | 376.0 | 229.4 | 0.9723 |
| Zilliz Cloud Capacity 32CU | 786.1 | 531.4 | 0.9728 |
| turbopuffer | 395.7 | 382.2 | 0.9321 |
| Pinecone Serverless | 4.6 | 4.5 | 0.9609 |
Таблица 3. Фрагмент payload для широкого нефильтрованного retrieval. Командам следует бенчмаркать ту форму payload, которую их приложение действительно возвращает, а не только поиск IDs-only.
Фильтрованный поиск: где важна избирательность
Многие производственные нагрузки vector search являются permissioned или фильтрованными. Support copilot может искать только документы, которые пользователю разрешено видеть. Рекомендательная система может фильтровать по региону, категории, продавцу или доступности. Enterprise search app может применять ограничения tenant, access control, freshness и document type перед ранжированием результатов.
Эти фильтры не косметические. Они меняют путь выполнения. В стрессовой точке 99.9% integer-filter плюс vector-payload поведение продукта резко меняется.
| Product | Max QPS | Recall | P99 latency |
|---|---|---|---|
| Zilliz Cloud Tiered 4CU | 955.7 | 0.9423 | 0.16 s |
| Zilliz Cloud Capacity 12CU | 933.0 | 0.9781 | 0.12 s |
| turbopuffer | 45.1 | 0.9436 | 7.03 s |
| Pinecone Serverless | 4.8 | —* | 3.30 s |
Таблица 4. Стрессовая точка selective filter для single-tenant: 99.9% integer filter с vector payload. Recall для запуска Pinecone Serverless в этой стрессовой точке на момент публикации еще не был доступен; его QPS и latency взяты из измеренного запуска.
Это один из самых ясных примеров того, почему cost-aware evaluation требует нескольких форм нагрузок. Продукт, который хорошо показывает себя на широком нефильтрованном retrieval, может оказаться не лучшим выбором для selective filtered search. Для permissioned search, access-control-heavy RAG или нагрузок с высокой избирательностью фильтра отфильтрованные строки могут быть важнее нефильтрованных строк.
MultitenantSearchCase: множество малых tenants ведут себя иначе
Single-tenant бенчмарки не охватывают каждую cloud workload.
Многие AI-приложения имеют SaaS-форму. Продукт может обслуживать тысячи tenants, у каждого из которых меньший dataset. Операционная задача заключается не только в vector search внутри одной большой collection. Она включает routing, isolation, namespace management и поддержание throughput во множестве малых partitions.
Multitenant case использует dataset Cohere 10M, разделенный между 1,000 tenants. Форма запроса использует topK 50 и сравнивает IDs-only, vector payload и filtered rows.
Два замечания по конфигурации определяют, как читать эту таблицу.
Во-первых, конфигурации Zilliz здесь намеренно малы — Tiered 1CU и Capacity 2CU, ровно достаточно, чтобы разместить dataset Cohere 10M. Single-tenant case выше уже показывает, что QPS Zilliz масштабируется с числом CU; вопрос, который задает этот case, — cost-effectiveness в конфигурации, подобранной под объем данных, а не пиковый throughput.
Во-вторых, столбец Pinecone — это отдельный запуск с низкой concurrency (concurrency 4), не нормализованный относительно строк с более высокой concurrency, поэтому рассматривайте его как контекст, а не как прямое сравнение.
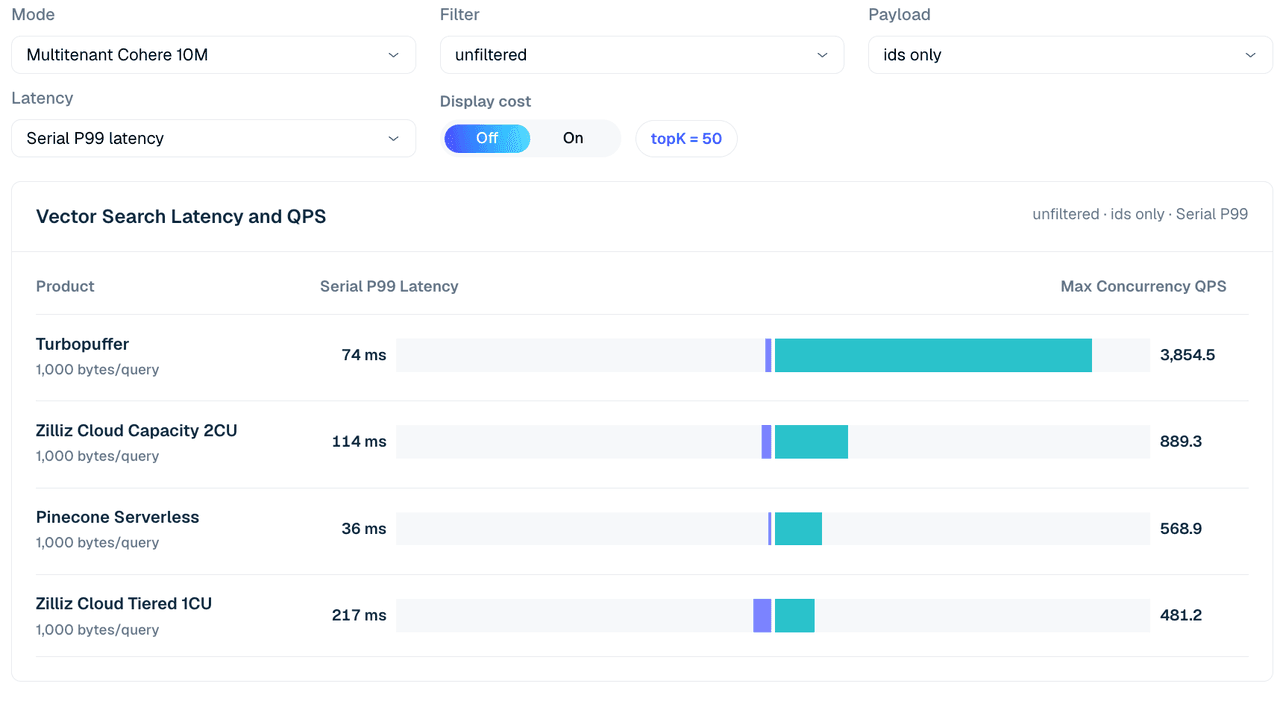
Рисунок 4. Multitenant-поиск Cohere 10M по 1,000 tenants, нефильтрованный IDs-only, topK 50. Представление сравнивает serial P99 latency и max concurrent QPS по протестированным конфигурациям; таблица ниже добавляет варианты payload и filter.
| Сценарий | Zilliz Tiered 1CU | Zilliz Capacity 2CU | turbopuffer | Pinecone (c4 run) |
|---|---|---|---|---|
| Без фильтрации, только ID | 481 | 889 | 3,855 | 569 |
| Без фильтрации, вектор | 34 | 371 | 1,775 | 542 |
| Целочисленный фильтр 99.9%, вектор | 625 | 1,307 | 3,835 | 526 |
| Скалярная метка 1%, вектор | 152 | 588 | 1,767 | 600 |
| Скалярная метка 50%, вектор | 29 | 317 | 1,760 | 562 |
Таблица 5. Фрагмент мультитенантного поиска по 1,000 тенантам, topK 50.
В этом режиме Turbopuffer демонстрирует высокие результаты по всем направлениям. Он достигает 3,855 QPS при поиске без фильтрации только по ID и 3,835 QPS в строке с выборочным целочисленным фильтром/вектором. Zilliz Cloud Capacity 2CU остается более сильным профилем Zilliz в этом фрагменте, достигая 889 QPS при поиске без фильтрации только по ID и 1,307 QPS в строке с целочисленным фильтром 99.9%/вектором.
Продуктовая интерпретация снова определяется рабочей нагрузкой. Turbopuffer хорошо подходит для множества легковесных тенантов и пропускной способности, ориентированной на пространства имен. Zilliz сильнее, когда рабочие нагрузки фильтруются, ограничены правами доступа, чувствительны к recall или тяжелее в расчете на тенанта, особенно когда команды могут выбрать конфигурацию Zilliz Capacity, соответствующую целевому обслуживанию.
CloudColdLatencyCase: первый запрос после простоя
Циклы теплых бенчмарков могут скрывать поведение в холодном состоянии. Для многих производственных AI-приложений, особенно памяти агентов, long-tail RAG и низкочастотных тенантных рабочих нагрузок, важен первый запрос после простоя. Система может выглядеть быстрой после прогрева, но добавлять секунды задержки, когда к холодной коллекции, пространству имен или пути кеша снова обращаются.
CloudColdLatencyCase изолирует это поведение. Он измеряет первый запрос к коллекции, которая простаивала не менее 24 часов — достаточно долго, чтобы кеши и пути обслуживания стали настолько холодными, насколько это реалистично возможно, — и сравнивает его с первым запросом на прогретом пути из того же запуска.
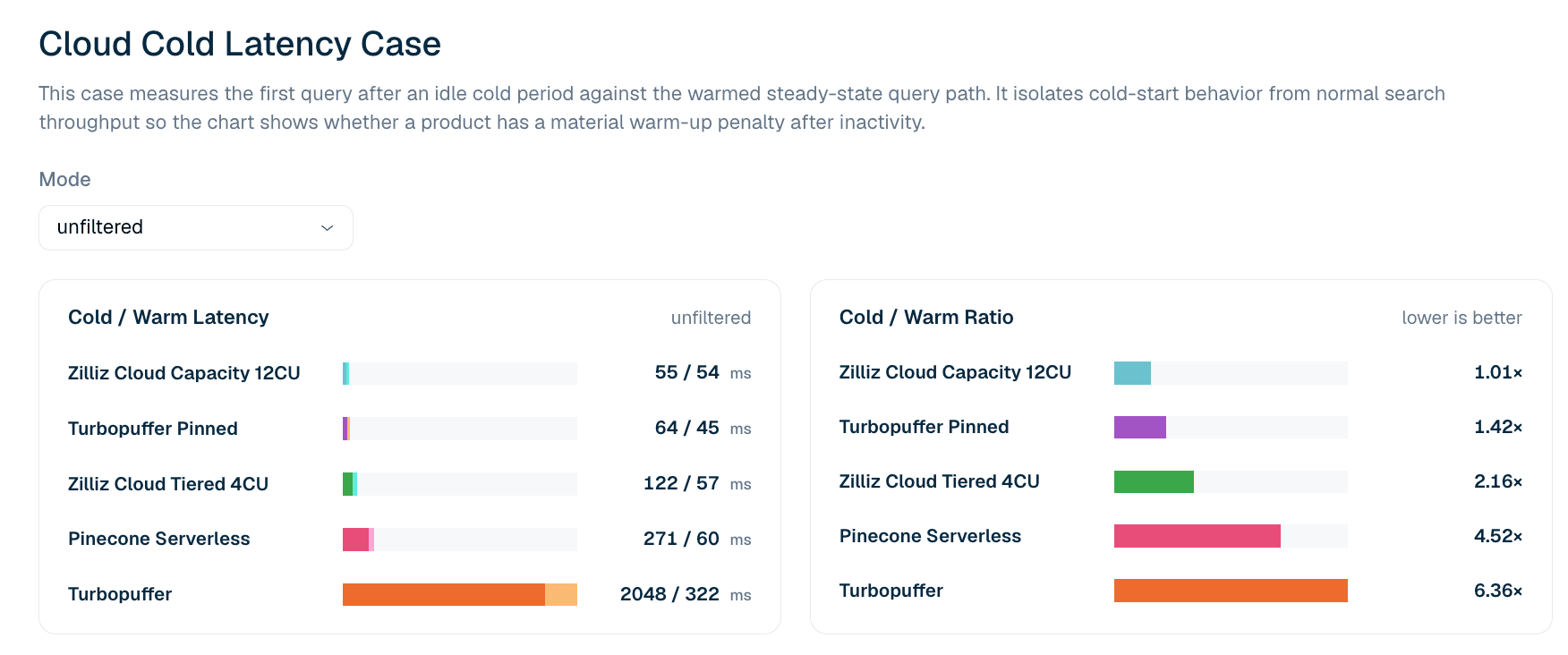
Рисунок 5. Задержка первого запроса после простоя по сравнению с прогретым путем запроса для поиска LAION 100M без фильтрации. Соотношение cold/warm показывает, есть ли у продукта существенный штраф первого запроса после простоя.
| Продукт | Первый запрос после простоя | Первый теплый запрос | Соотношение cold/warm |
|---|---|---|---|
| Zilliz Cloud Capacity 12CU | 55 ms | 54 ms | 1.01x |
| Turbopuffer pinned | 64 ms | 45 ms | 1.42x |
| Zilliz Cloud Tiered 4CU | 122 ms | 57 ms | 2.16x |
| Pinecone Serverless | 271 ms | 60 ms | 4.52x |
| turbopuffer | 2,048 ms | 322 ms | 6.36x |
Таблица 6. Фрагмент задержки первого запроса в холодном и теплом состоянии для LAION 100M без фильтрации. Этот сценарий сообщает задержку первого запроса, а не хвостовые процентили: соотношения cold/warm на P99 обычно подхватывают сетевой шум в последующих запросах, который надежно не воспроизводится, поэтому рейтинг использует более строгое определение первого запроса.
В текущем сценарии задержки в холодном состоянии без фильтрации Zilliz Cloud Capacity 12CU показывает самый плотный профиль cold-to-warm: 55 ms в холодном состоянии и 54 ms в теплом, или соотношение 1.01x. Turbopuffer pinned также имеет сильный профиль: 64 ms в холодном состоянии и 45 ms в теплом. Незафиксированный Turbopuffer показывает более высокий штраф холодного состояния: 2,048 ms в холодном состоянии и 322 ms в теплом, или соотношение 6.36x.
Задержку в холодном состоянии всегда следует рассматривать вместе со стоимостью. Закрепленные реплики и выделенная емкость могут снижать штрафы первого обращения, но они меняют экономическую модель. Продукт может демонстрировать отличное поведение в холодном состоянии, потому что сохраняет больше «тепла». Это может быть правильным компромиссом для интерактивных приложений, но его не следует отделять от стоимости поддержания такого пути.
Линии Парето по стоимости: где модели ценообразования пересекаются
Одного прайс-листа недостаточно. Низкая цена за единицу не помогает, если продукт не может достичь целевого QPS. Высокопроизводительная конфигурация непривлекательна, если стоит дороже другого продукта, который удовлетворяет тем же требованиям к задержке, recall и payload.
Представление Cost Pareto объединяет измеренные границы бенчмарка с моделями ценообразования. Для сценария LAION 100M только с запросами каждая продуктовая линейка останавливается на максимальном QPS, наблюдавшемся в бенчмарке. Затем диаграмма оценивает операционные затраты при целевых уровнях QPS и отмечает Парето-оптимальные варианты в рамках этих измеренных ограничений.
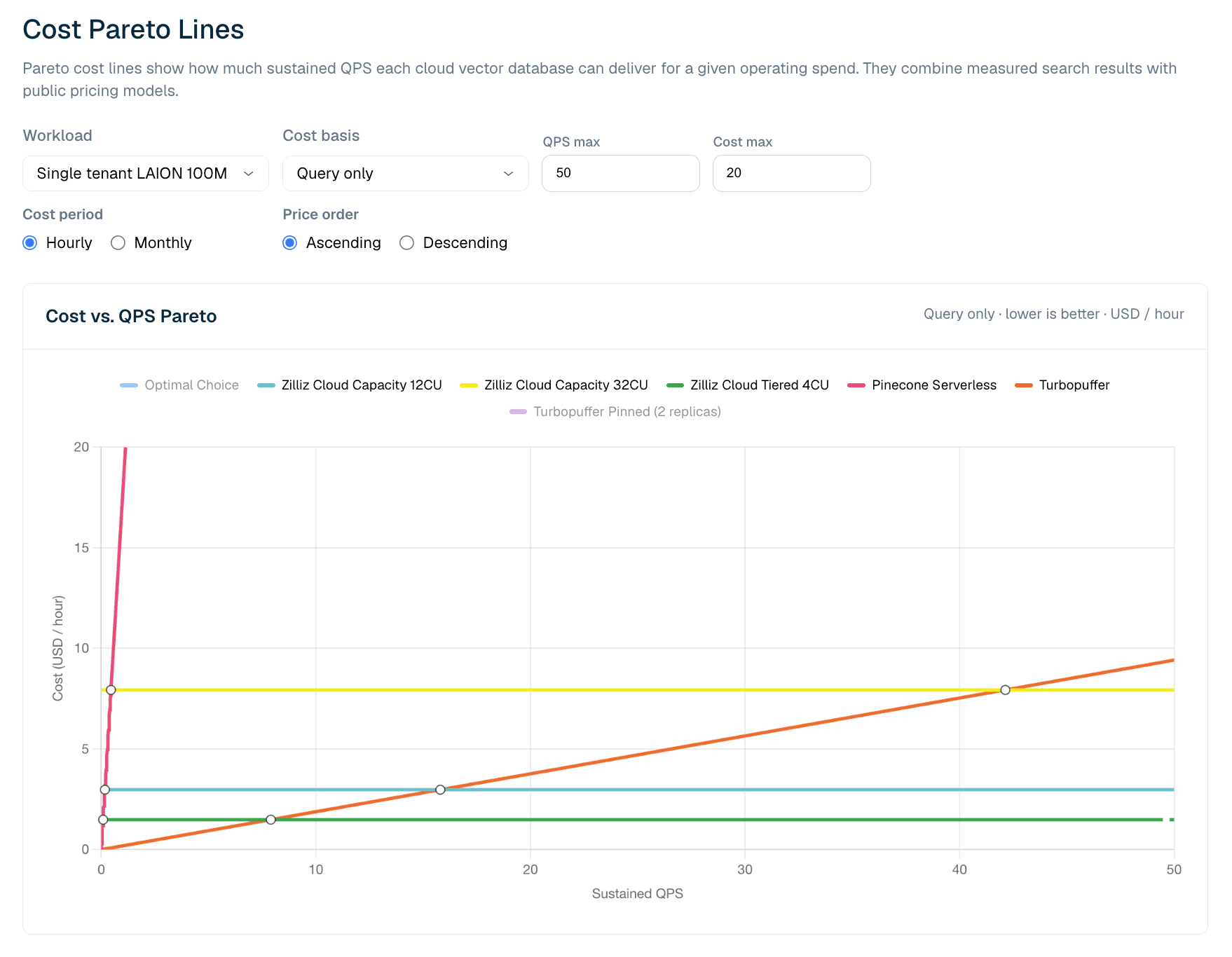
Рисунок 6. Стоимость в сравнении с устойчивым QPS для нагрузок LAION 100M только с запросами. Представление Pareto показывает, где serverless-ценообразование эффективнее при низком QPS и где выделенные конфигурации Zilliz становятся более экономичными по мере роста утилизации.
В текущей модели LAION 100M только с запросами Turbopuffer имеет преимущество при очень низком устойчивом QPS. Измеренная точка пересечения находится примерно на уровне 8 QPS: ниже нее usage-metered ценообразование turbopuffer за запросы является более дешевой линией; выше нее Zilliz Cloud Tiered 4CU становится дешевле, поскольку его стоимость обслуживания в CU-часах в основном фиксирована после выделения ресурсов. По мере роста QPS утилизация улучшается, а выделенная емкость становится более экономичной.
Это не означает, что serverless хуже. Это означает, что экономика serverless и выделенных ресурсов пересекается. Для низких, всплесковых или непредсказуемых нагрузок usage-metered serverless может быть оптимальным вариантом. Для устойчивого production-трафика фиксированная модель CU-часов может стать дешевле, как только утилизация пройдет точку пересечения. Для команд, которым нужны более сильные параметры обслуживания, поведение при холодном запуске или операционный контроль, Zilliz Capacity может быть подходящим профилем, даже когда Tiered является более дешевой линией.
Zilliz Cloud vs. Turbopuffer vs. Pinecone: оптимальное соответствие по нагрузке
| Форма нагрузки | Самый сильный сигнал | Почему |
|---|---|---|
| Очень низкий устойчивый QPS | turbopuffer | Экономика usage-metered serverless привлекательна до точки пересечения при низком QPS |
| Устойчивый QPS выше точки пересечения (~8 QPS в этой модели) | Zilliz Cloud Tiered | Экономика фиксированных CU-часов улучшается по мере роста утилизации |
| Свежие данные или частое обновление | Zilliz Cloud Capacity / Tiered | Время от вставки до поиска и готовность полностью проиндексированных данных сильны в сценарии вставки LAION 100M |
| Чувствительность к стоимости большой полной загрузки | Zilliz Cloud Capacity / Tiered | Стоимость записи намного ниже в протестированном пути массовой загрузки LAION 100M |
| Широкий поиск по payload без фильтрации | Turbopuffer and Zilliz Capacity 32CU | Turbopuffer силен в широком извлечении; Zilliz масштабируется при увеличении емкости |
| Селективные фильтры или поиск с правами доступа | Zilliz Cloud Capacity / Tiered | Zilliz показывает гораздо более высокий QPS и более низкую задержку P99 в стресс-точке фильтра 99.9% |
| Много легковесных tenants | turbopuffer | Самый высокий raw QPS во фрагменте с 1,000 tenants |
| Интерактивные приложения, чувствительные к холодному запуску | Zilliz Cloud Capacity; Turbopuffer pinned | Оба снижают штрафы первого запроса, с разными моделями стоимости |
| Базовый serverless с низкими операционными затратами | Pinecone Serverless | Зрелая serverless-ориентир, даже если не является лидером в этой нагрузке |
Как использовать эти результаты бенчмаркинга
VDBBench и его Cost Leaderboard созданы, чтобы оценка векторных баз данных более точно отражала то, как команды на самом деле покупают и эксплуатируют управляемые облачные продукты. Пиковый QPS по-прежнему важен, но сам по себе он уже недостаточен. Более полезный вопрос — может ли продукт одновременно удовлетворить требования нагрузки по задержке, recall, свежести, payload, tenancy и стоимости.
Практический процесс оценки выглядит так:
- Используйте Performance Leaderboard, чтобы понять raw возможности обслуживания в контролируемых условиях бенчмарка.
- Используйте Cost Leaderboard, чтобы понять компромиссы стоимости и производительности между управляемыми облачными продуктами и формами нагрузок.
- Используйте сам VDBBench, чтобы воспроизвести сценарии, протестировать другие продукты или запустить бенчмарк на данных и распределениях запросов, похожих на production.
Текущие результаты следует читать с несколькими оговорками.
- Продукты были протестированы 10 мая 2026 года, а модель затрат использует цены AWS us-west-2 по состоянию на эту дату. Цены могут меняться в зависимости от даты и региона.
- Выбор конфигурации, такой как закрепленные режимы, выделенная емкость, элементы управления масштабированием и троттлинг serverless, может влиять на результаты.
- Состояния готовности не всегда отображаются одинаковым образом, поэтому определения вставленных, доступных для поиска и полностью проиндексированных данных необходимо проверять для каждого клиента.
- Наконец, рабочие нагрузки намеренно являются специфичными. Результаты Парето по затратам всегда следует рассматривать вместе с задержкой, полнотой поиска, формой полезной нагрузки и измеренными лимитами обслуживания.
Тестируйте собственные рабочие нагрузки
Cost Leaderboard — это публичный снимок текущих результатов, но более важное изменение находится в самом VDBBench. Теперь он позволяет командам оценивать производительность и затраты вместе с учетом ограничений, специфичных для рабочей нагрузки: свежести, размера полезной нагрузки, структуры арендаторов, поведения при холодном старте и операционной модели.
Serverless-продукт может хорошо подходить для низкого устойчивого QPS. Выделенная емкость может стать более экономически эффективной, когда загрузка возрастет. Одна система может лидировать в широком поиске, тогда как другая может показывать лучшие результаты при селективных фильтрах, частых обновлениях или рабочих нагрузках, чувствительных к холодному старту.
Цель — не лучший заголовочный показатель. Цель — наилучшее соответствие вашей рабочей нагрузке.
- Посмотреть текущие результаты: VDBBench Cost Leaderboard
- Воспроизвести эти сценарии или протестировать собственных кандидатов: VectorDBBench on GitHub
- Есть вопросы или результаты, которыми хотите поделиться? Откройте issue на GitHub или присоединяйтесь к обсуждению в Discord

Читать далее

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

What Exactly Are AI Agents? Why OpenAI and LangChain Are Fighting Over Their Definition?
AI agents are software programs powered by AI that can perceive their environment, make decisions, and take actions to achieve a goal—often autonomously.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.