




Classificação na aprendizagem automática: Tudo o que deve saber

Classificação na aprendizagem automática: Tudo o que deve saber
O que é Classificação?
Classificação é uma abordagem supervisionada de aprendizado de máquina que categoriza dados em classes predefinidas. Dada uma entrada, um modelo de classificação prevê a categoria ou rótulo a que a entrada pertence. É uma das tarefas mais comuns na aprendizagem automática e é utilizada em muitas aplicações do mundo real, desde a deteção de spam por correio eletrónico a diagnósticos médicos.
Por exemplo, se tiver um conjunto de dados de e-mails, um modelo de classificação pode aprender a rotular cada e-mail como "spam" ou "não spam".
Como é que a classificação funciona?
Na classificação, um modelo de aprendizado de máquina é treinado em um conjunto de dados para categorizar dados em classes predefinidas com base em recursos de entrada. O modelo é treinado usando um conjunto de dados rotulado, onde cada entrada é associada a um rótulo de saída. O modelo aprende os padrões nos dados durante o treino e utiliza esses padrões para prever as etiquetas de dados novos e não vistos.
Por exemplo, imagine que tem a tarefa de classificar se uma mensagem de correio eletrónico é spam. Durante a fase de treino, o modelo é alimentado com mensagens de correio eletrónico juntamente com as suas etiquetas ("spam" ou "não spam"). Analisa caraterísticas como a presença de determinadas palavras-chave ou o endereço do remetente para identificar padrões. Depois de o modelo ser treinado, analisa as mesmas caraterísticas e prevê se pertence à categoria "spam" ou "não spam" quando chega um novo correio eletrónico.
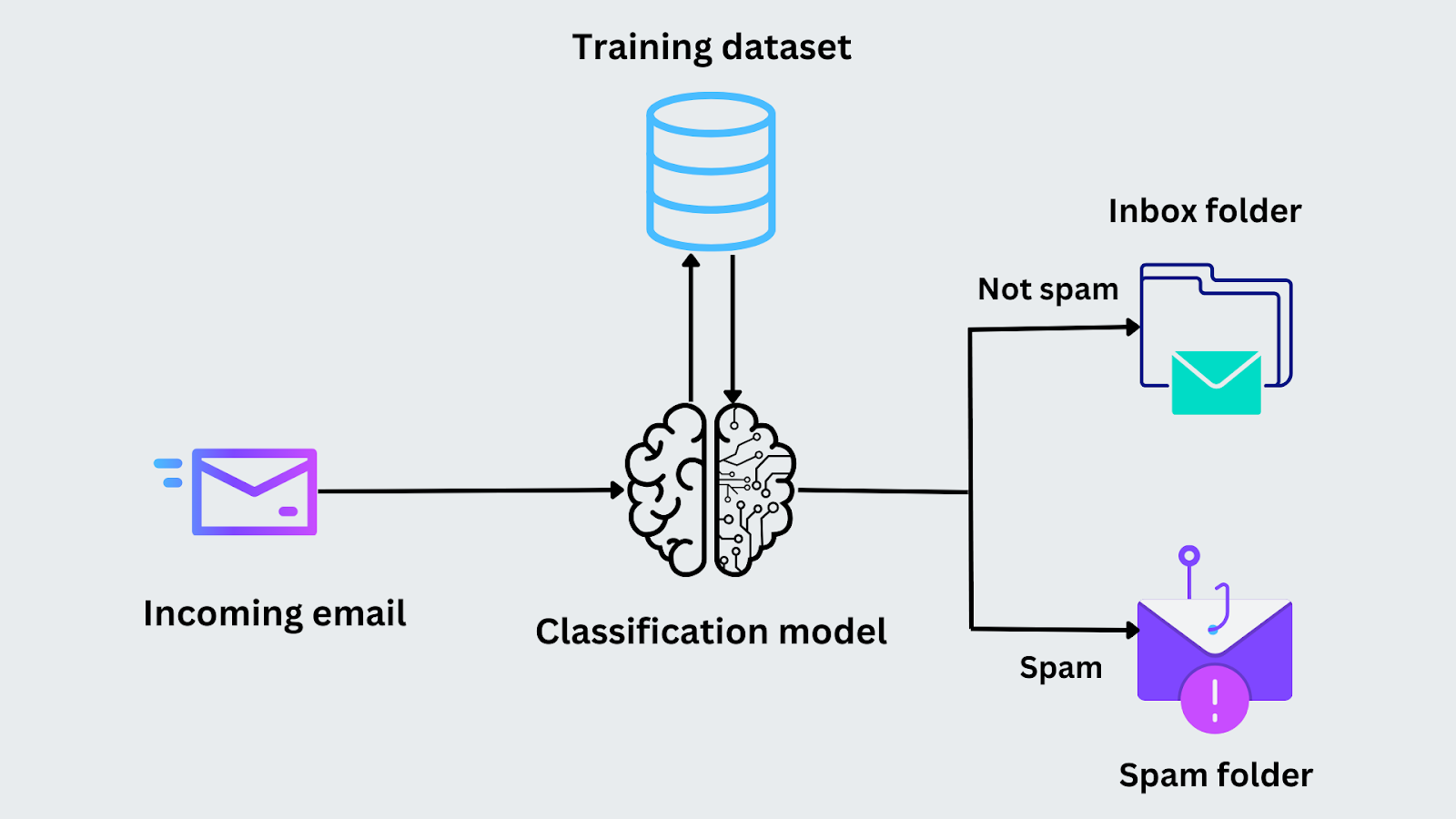 Figura - Processo de classificação de correio eletrónico.png
Figura - Processo de classificação de correio eletrónico.png
Figura: Processo de classificação de correio eletrónico
Tipos de classificação
Os problemas de classificação apresentam-se de diferentes formas, dependendo da natureza dos dados e do número de classes. Aqui estão os tipos mais comuns:
Classificação Binária
A classificação binária ocorre quando há apenas duas classes ou resultados possíveis. O modelo prevê a qual das duas categorias a entrada pertence. Um exemplo clássico é a deteção de spam de e-mail. O modelo tem de decidir se uma mensagem de correio eletrónico recebida é "spam" ou "não é spam". Uma vez que existem apenas duas opções, esta é uma tarefa de classificação binária.
Classificação multiclasse
Na classificação multiclasse, o modelo prevê um rótulo de mais de duas categorias possíveis. Cada entrada é atribuída a exatamente uma classe. Um bom exemplo é o reconhecimento de imagens, onde o modelo pode classificar uma imagem como "gato", "cão" ou "pássaro". Ao contrário da classificação binária, o modelo lida com várias classes distintas e tem de identificar a correta para cada entrada.
Classificação multirrótulo
A classificação multirrótulo é aquela em que cada entrada pode pertencer a várias classes simultaneamente. Por exemplo, ao etiquetar uma fotografia, esta pode ser etiquetada com "pôr do sol", "praia" e "pessoas" em simultâneo. Cada etiqueta representa uma classe diferente e o modelo aprende a prever todas as etiquetas relevantes para uma entrada. Isto difere da classificação multiclasse porque podem ser atribuídas várias etiquetas à mesma entrada.
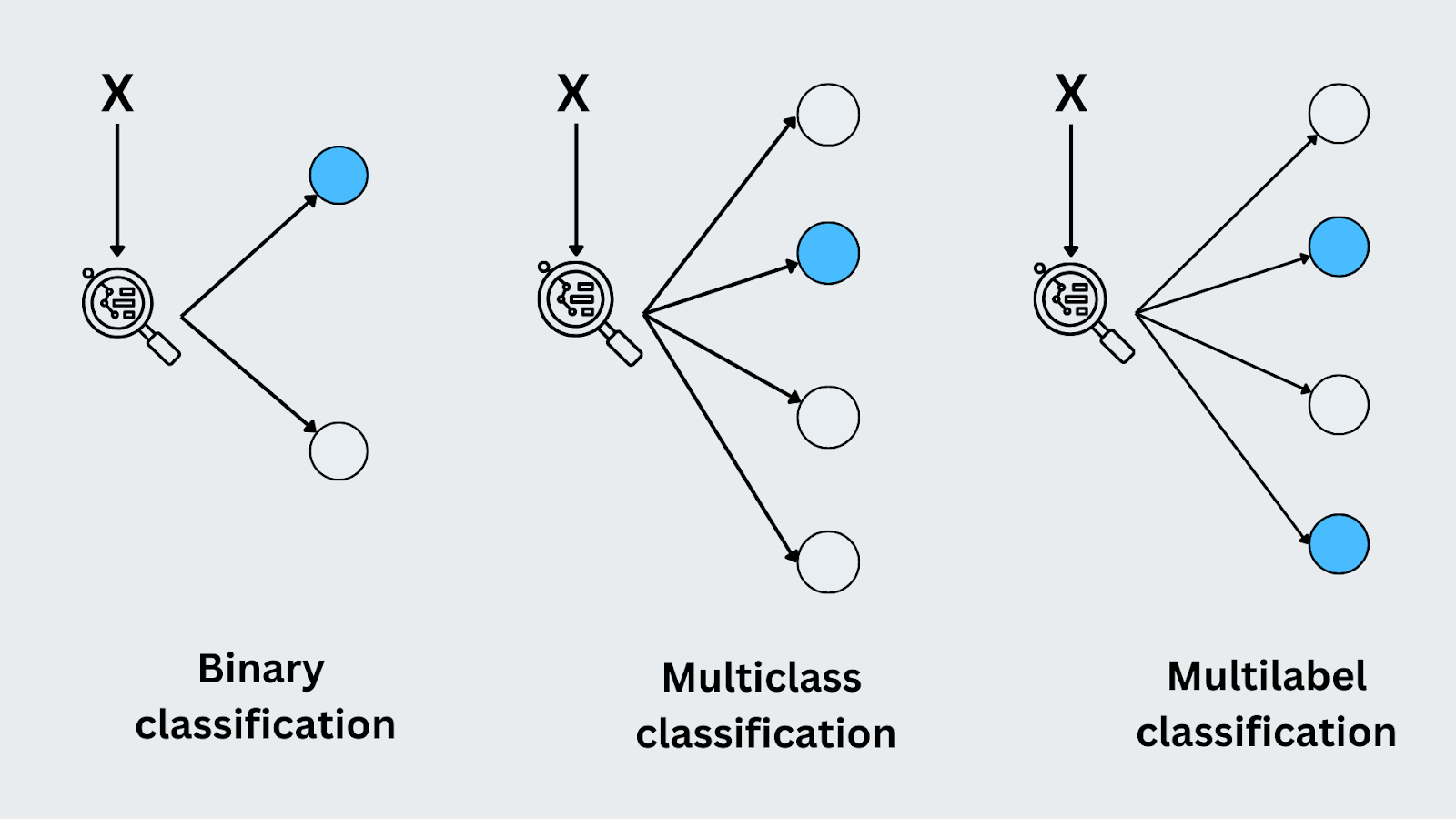 Figura- Tipos de classificação.png
Figura- Tipos de classificação.png
Figura: Tipos de classificação
Aprendizes em algoritmos de classificação
Na aprendizagem automática, os algoritmos de classificação podem ser categorizados com base na forma como generalizam a partir dos dados de treino. Estes são Lazy Learners e Eager Learners. A distinção entre estes dois tipos reside em quando e como processam os dados para efetuar previsões.
Aprendizes preguiçosos
Os aprendizes preguiçosos são algoritmos que atrasam a generalização até receberem uma consulta de previsão. Eles não constroem um modelo durante a fase de treinamento; em vez disso, armazenam os dados de treinamento e só realizam cálculos quando uma nova entrada precisa ser classificada.
Algoritmos de exemplo: k-Nearest Neighbors (k-NN), Case-based Reasoning (CBR).
Aprendizes Ansiosos
Os aprendizes ansiosos, em contraste, tentam construir um modelo geral imediatamente durante a fase de treinamento. Eles analisam os dados de treinamento, aprendem os padrões subjacentes e, em seguida, descartam os dados de treinamento. Uma vez que o modelo é construído, ele pode prever rapidamente novos dados.
Algoritmos de exemplo: Árvores de Decisão, Floresta Aleatória, Máquinas de Vectores de Suporte (SVM), Regressão Logística.
| Aprendizes preguiçosos** | Aprendizes ansiosos** | |
| Criação de modelo | Nenhum modelo é construído durante o treinamento; ele memoriza os dados. | Generaliza os dados para um modelo durante o treinamento. |
| Tempo de treinamento | Tempo de treinamento curto; não constrói um modelo. | Tempo de treinamento mais longo; cria um modelo com base nos dados. |
| Tempo de previsão | Faz previsões mais lentas, pois processa os dados no momento da consulta. | Previsões mais rápidas, pois o modelo é pré-construído. |
| Necessidade de memória Maior necessidade de memória; armazena todo o conjunto de dados. | Menor necessidade de memória; armazena apenas os parâmetros do modelo. | |
| Algoritmos de exemplo | k-NN, Raciocínio baseado em casos | Árvores de decisão, Regressão logística, Floresta aleatória |
Tabela: Aprendizes preguiçosos vs Aprendizes ansiosos
Algoritmos de classificação
Agora, vamos discutir alguns algoritmos de classificação comumente usados.
Regressão logística
A regressão logística usa a probabilidade apenas para prever o rótulo em uma tarefa de classificação binária. Ao contrário da regressão linear, que prevê valores contínuos, a regressão logística prevê probabilidades para duas classes mapeando as saídas para um intervalo entre 0 e 1 utilizando a função logística (sigmoid). É amplamente utilizada para casos com resultados binários, como cenários sim/não ou 0/1.
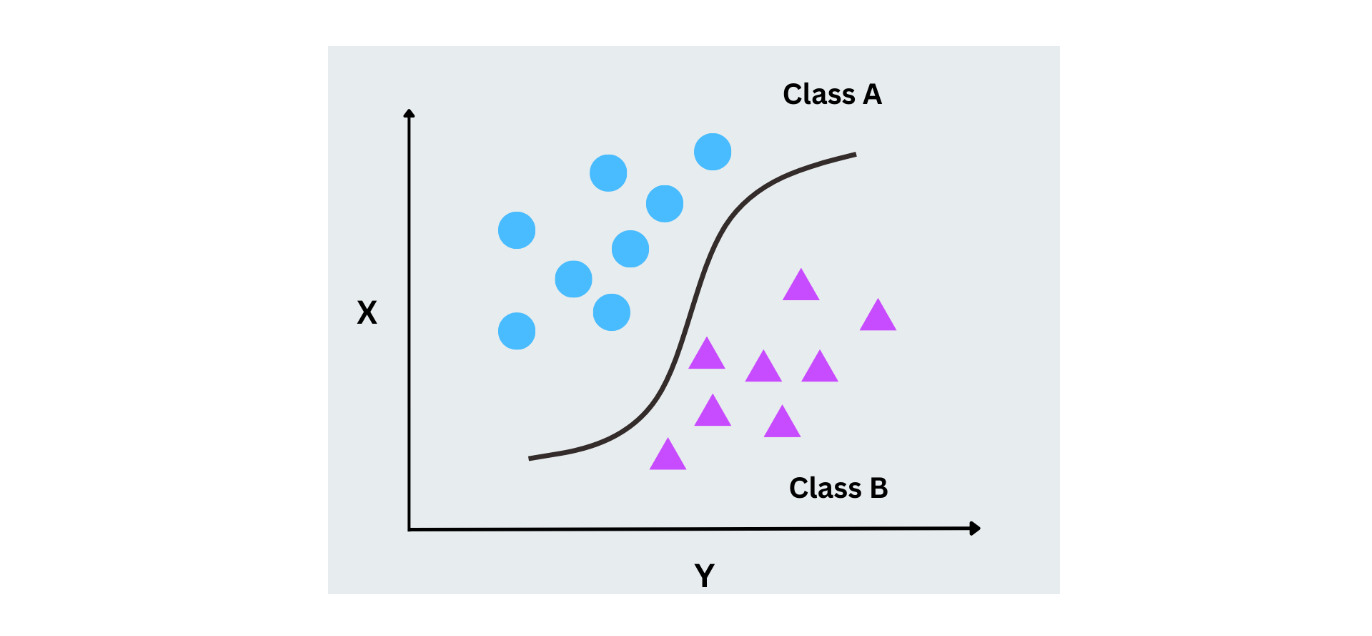 Figura - Regressão logística em funcionamento.png
Figura - Regressão logística em funcionamento.png
Figura- Funcionamento da regressão logística
Árvores de decisão
Uma árvore de decisão é um modelo que divide os dados com base nos valores das caraterísticas, criando ramos para cada decisão possível. Cada nó representa uma caraterística, e os ramos representam decisões baseadas no valor dessa caraterística. O processo continua até que o algoritmo decida sobre os nós de folha da classe prevista. As árvores de decisão são fáceis de interpretar e podem lidar com tarefas de classificação binária e multiclasse.
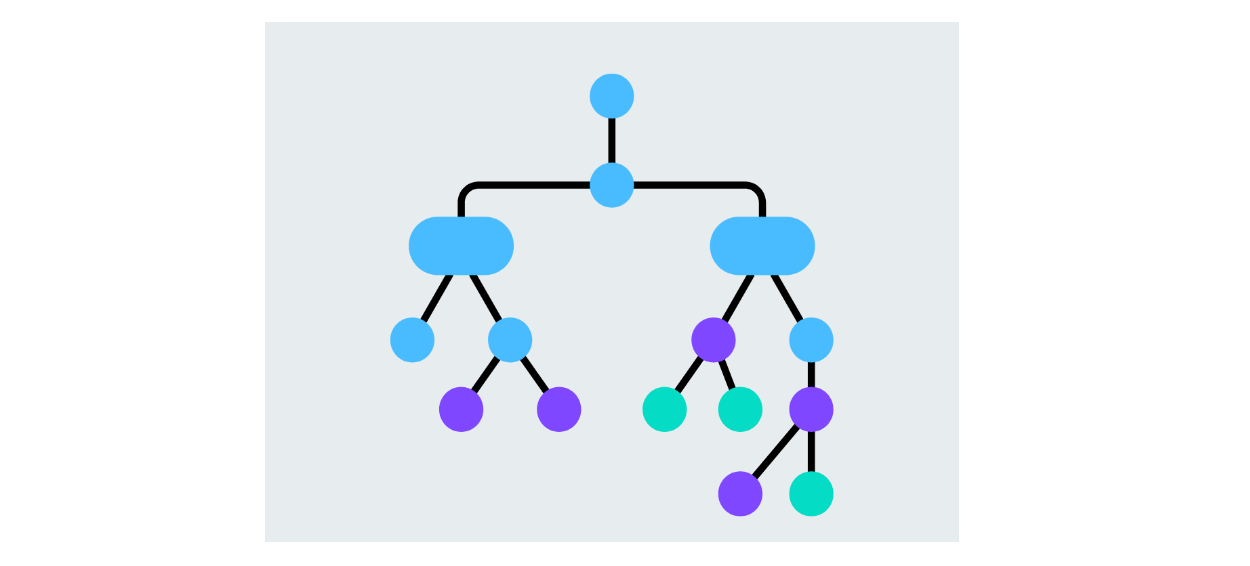 Figura - Estrutura da árvore de decisão.png
Figura - Estrutura da árvore de decisão.png
Figura: Estrutura da árvore de decisão
Floresta aleatória
A floresta aleatória melhora as árvores de decisão, construindo várias árvores e combinando suas previsões. Cada árvore na floresta é construída a partir de um subconjunto aleatório de dados e recursos. A previsão final é feita pela média dos resultados (para tarefas de regressão) ou pela votação por maioria (para tarefas de classificação). Isto ajuda a reduzir o sobreajuste e aumenta a precisão.
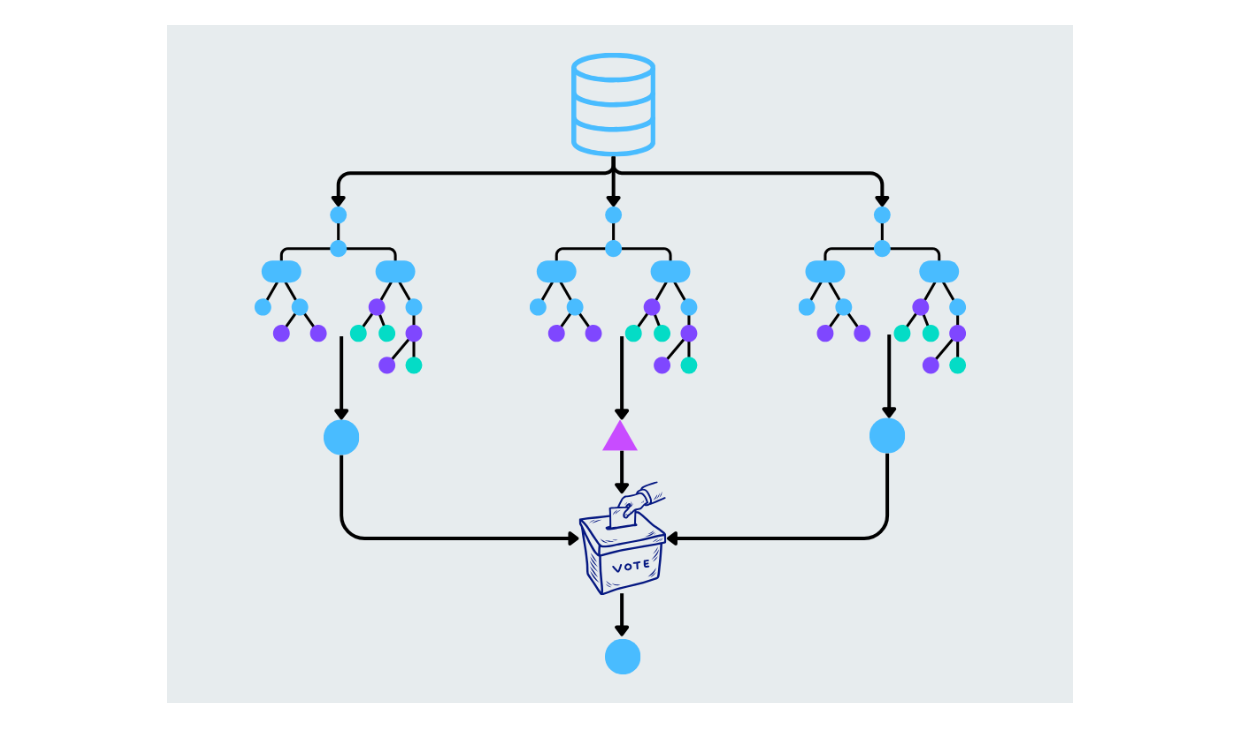 Figura- Floresta aleatória a funcionar.png
Figura- Floresta aleatória a funcionar.png
Figura: Floresta aleatória a funcionar
Máquinas de vectores de suporte (SVM)
As máquinas de vectores de suporte funcionam encontrando o hiperplano ideal que separa os pontos de dados de diferentes classes. Esse hiperplano é uma linha em duas dimensões, mas as SVMs também podem lidar com dados de alta dimensão. A ideia principal é maximizar a margem entre os pontos de dados mais próximos de cada classe (vectores de apoio). As SVMs funcionam bem para problemas de classificação binária e multiclasse, especialmente quando os dados não são linearmente separáveis.
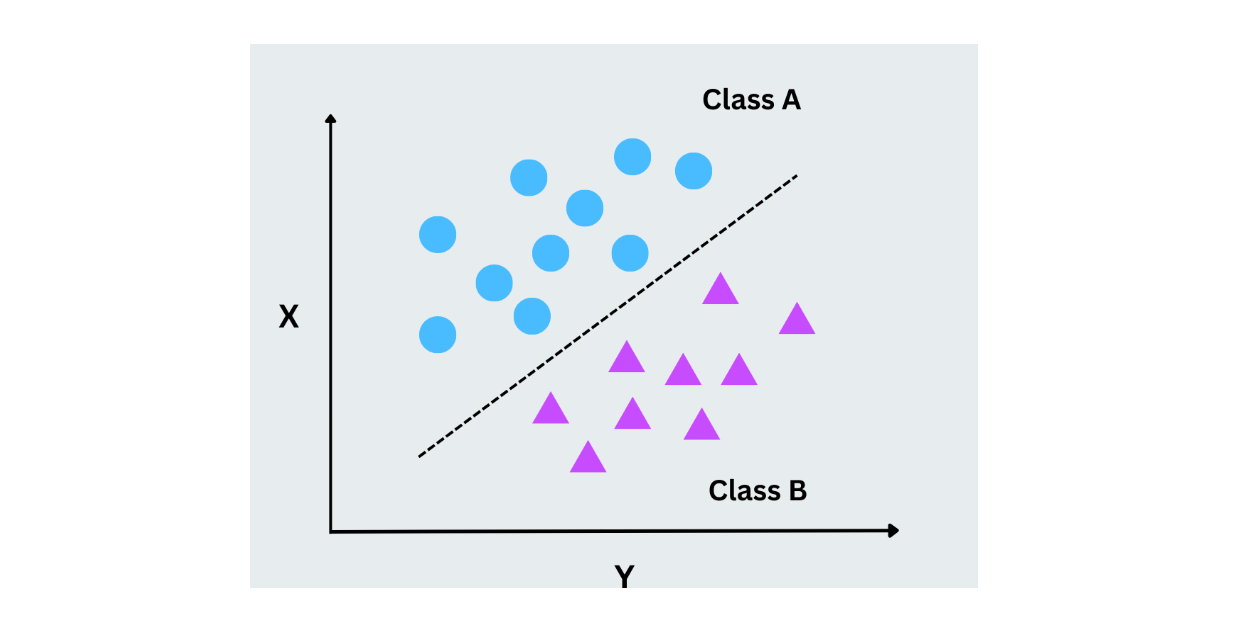 Figura - SVM em funcionamento.png
Figura - SVM em funcionamento.png
Figura- SVM em funcionamento
k-Nearest Neighbors (k-NN)
O algoritmo k-NN classifica os pontos de dados com base nas classes dos k vizinhos mais próximos. Ao introduzir um novo ponto de dados, o algoritmo analisa os k pontos mais próximos (com base numa métrica de similaridade como a distância euclidiana) e atribui ao novo ponto a classe maioritária. Trata-se de um algoritmo de aprendizagem simples, baseado em instâncias, útil para conjuntos de dados mais pequenos.
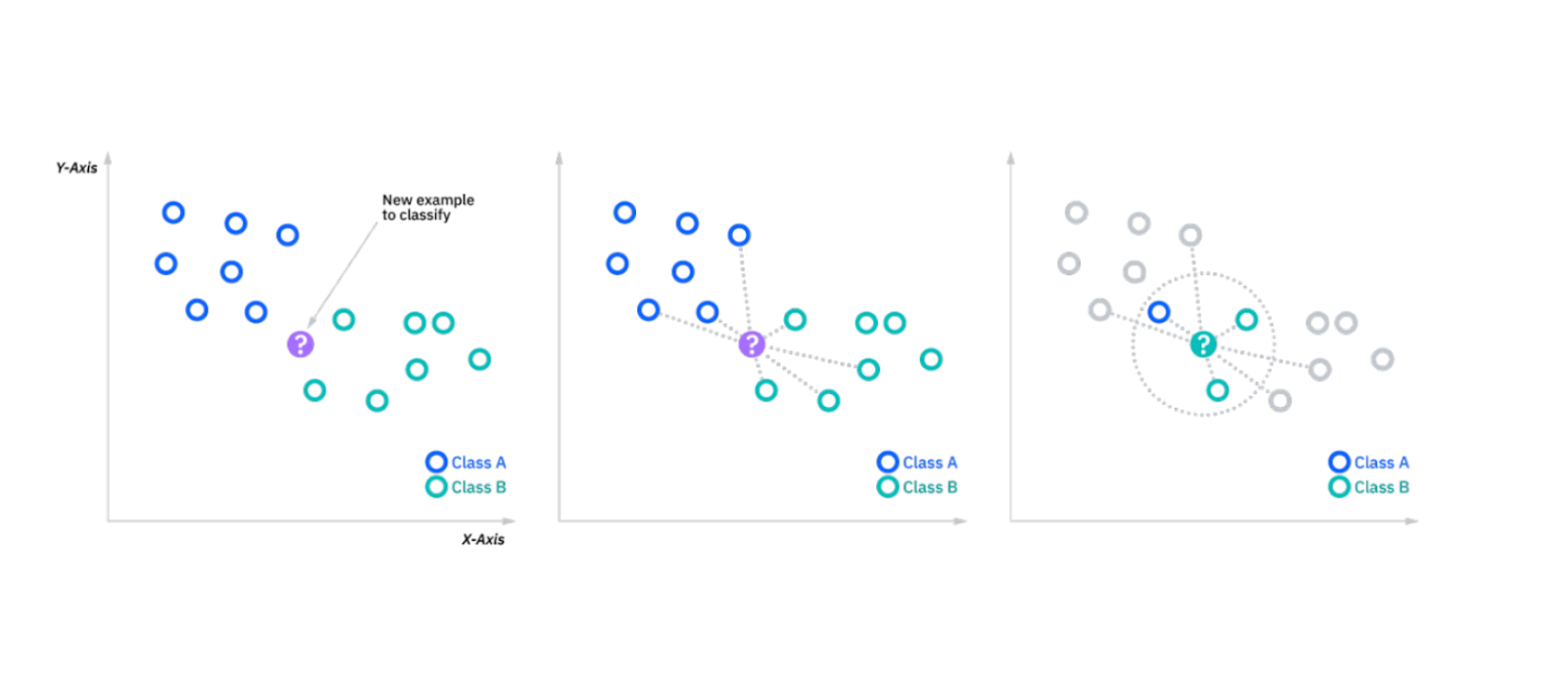 Figura- algoritmo kNN em funcionamento.png
Figura- algoritmo kNN em funcionamento.png
Figura: Algoritmo kNN em funcionamento
Naive Bayes
O Naive Bayes baseia-se no Teorema de Bayes e assume que as caraterísticas dos dados são independentes umas das outras (daí o termo "naive"). Apesar deste pressuposto, tem um bom desempenho em várias tarefas do mundo real, especialmente quando os dados têm caraterísticas categóricas. Funciona calculando a probabilidade de cada classe dada a entrada e atribuindo a classe com a maior probabilidade.
P(C|X) = P(X|C) . P(C)P(X))
Aqui, P(C∣X) é a probabilidade posterior da classe dada a entrada, P(X∣C) é a probabilidade da entrada dada a classe, P(C) é a probabilidade prévia da classe e P(X) é a probabilidade da entrada. O Naive Bayes seleciona a classe com a maior probabilidade posterior para classificação com base nas caraterísticas observadas.
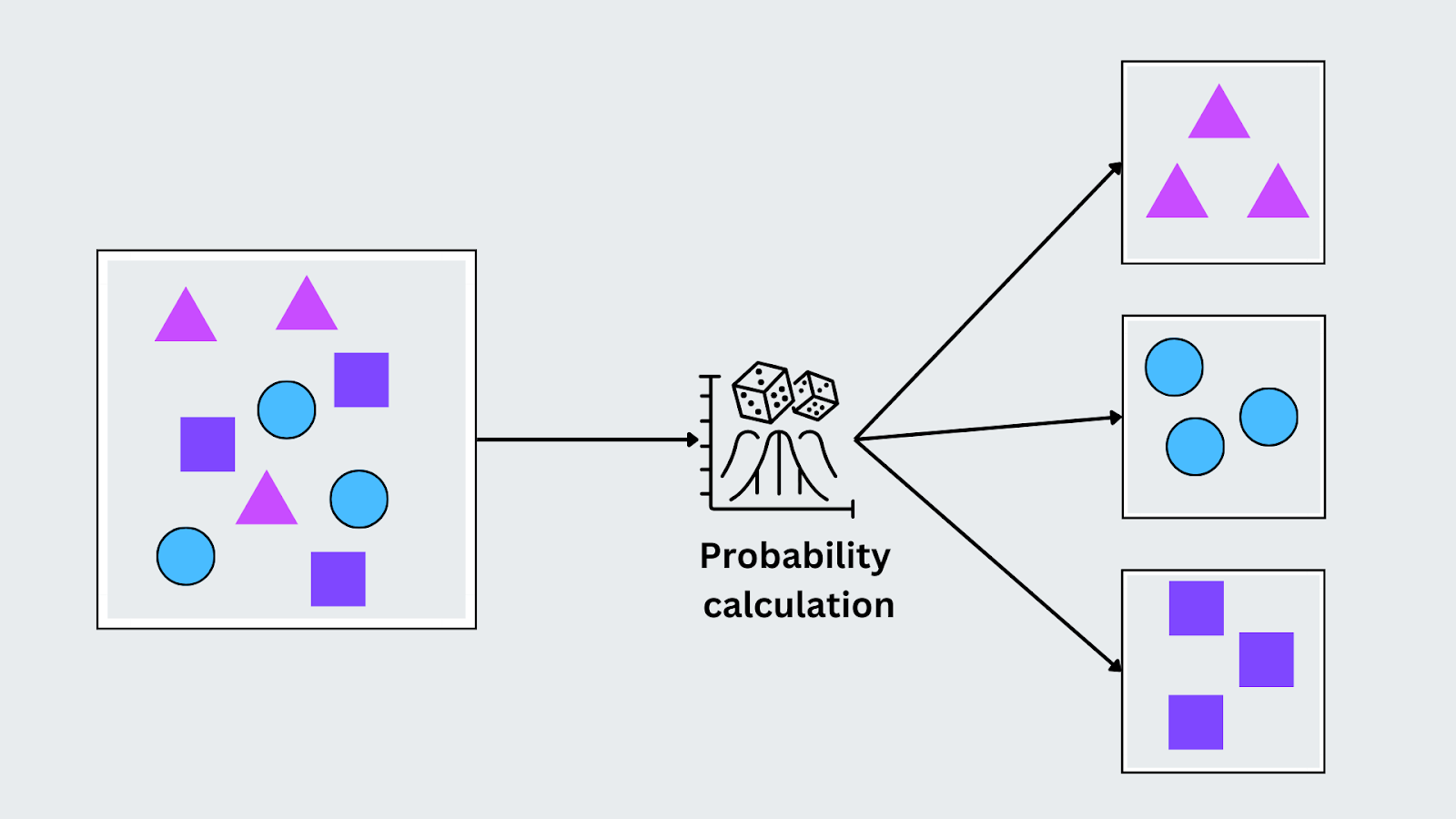 Figura - Algoritmo de Naive Bayes em funcionamento.png
Figura - Algoritmo de Naive Bayes em funcionamento.png
Figura: Algoritmo de Naive Bayes em funcionamento
Métricas de avaliação na classificação
Precisão
A precisão é a métrica mais simples e mede a frequência com que as previsões do modelo estão corretas. É determinada pela divisão do número de casos corretamente previstos pelo número total de casos.
Fórmula:
Exatidão = (Verdadeiros positivos + Verdadeiros negativos)/Número total de instâncias
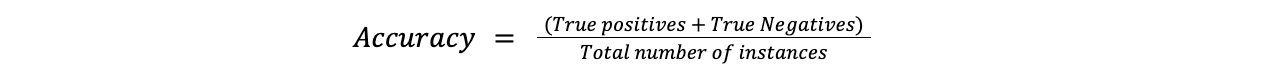 accuracy.png
accuracy.png
Precisão
A precisão mede quantas das instâncias positivas previstas são verdadeiramente positivas. A precisão é importante em situações em que os falsos positivos são dispendiosos. Por exemplo, prever uma transação normal como fraudulenta na deteção de fraude pode levar à insatisfação do cliente.
Fórmula:
Precisão = Verdadeiros positivos/(Verdadeiros positivos + Falsos positivos)
 precision.png
precision.png
Recuperação
A recuperação mede a proporção de casos positivos identificados com exatidão como positivos. A recuperação é útil nos casos em que a falta de uma instância positiva é dispendiosa. Por exemplo, a falta de um diagnóstico (falso negativo) é muito mais problemática na deteção de doenças do que um falso alarme.
Fórmula:
Recuperação = Verdadeiros positivos/(Verdadeiros positivos + Falsos negativos)
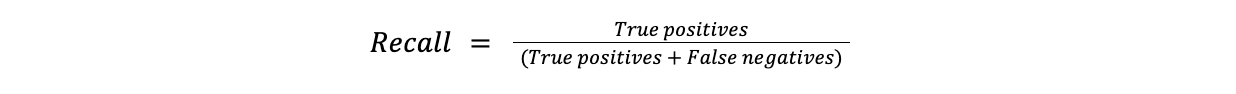 recall.png
recall.png
F1-Score
O F1-Score é a média harmónica da precisão e da recuperação. É útil quando há necessidade de equilibrar a precisão e a recuperação, especificamente quando uma é mais importante do que a outra.
Fórmula:
F1Score = 2x(Precisão x Recuperação)/(Precisão + Recuperação)
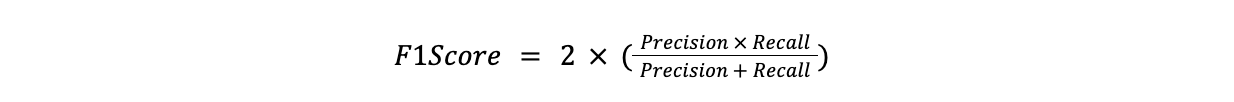 FI score.png
FI score.png
Casos de uso de classificação no mundo real
Os modelos de classificação são amplamente utilizados em vários sectores para resolver problemas do mundo real. Aqui estão alguns exemplos práticos:
Diagnóstico médico: Os modelos de aprendizagem automática ajudam os médicos a classificar os dados dos pacientes como "doença" ou "sem doença". Por exemplo, os modelos são utilizados para prever se um doente tem diabetes com base nos registos médicos.
Análise de sentimentos: As empresas utilizam a análise de sentimentos para compreender o feedback dos clientes. Por exemplo, um modelo pode analisar críticas de produtos e classificá-las como positivas, negativas ou neutras, ajudando as empresas a melhorar as suas ofertas com base no sentimento do cliente.
Deteção de fraudes: Os bancos e as instituições financeiras utilizam modelos de classificação para detetar transacções fraudulentas. O modelo aprende padrões a partir dos dados das transacções e classifica cada uma como "fraudulenta" ou "legítima" para evitar perdas financeiras.
Reconhecimento de objectos em imagens: Os modelos de reconhecimento de objectos identificam itens específicos de imagens em sectores como a indústria transformadora e a segurança. Por exemplo, um modelo pode classificar imagens de produtos numa linha de montagem, garantindo que apenas os itens corretamente montados passam na inspeção.
Reconhecimento facial: Os sistemas de reconhecimento facial são utilizados na segurança e na autenticação. Estes modelos classificam imagens de rostos para identificar ou verificar a identidade de uma pessoa, sendo normalmente utilizados para desbloquear smartphones, sistemas de atendimento digital ou controlos de segurança nos aeroportos.
Reconhecimento de voz: Os modelos de reconhecimento de voz convertem a linguagem falada em texto ou comandos. Por exemplo, assistentes virtuais como a Siri ou a Alexa classificam palavras faladas em comandos para que os utilizadores possam interagir com dispositivos através da voz.
Testes de diagnóstico médico: Os modelos de aprendizagem automática ajudam a interpretar testes de diagnóstico, como radiografias ou exames de ressonância magnética. Classificam as imagens médicas como "normais" ou "anormais", ajudando os radiologistas a efetuar diagnósticos mais rápidos e mais precisos.
Previsão do comportamento do cliente: As plataformas de comércio eletrónico utilizam modelos de classificação para prever o comportamento do cliente. Estes modelos classificam os utilizadores como "propensos a comprar" ou "pouco propensos a comprar" para fazer marketing personalizado e recomendações de produtos.
Categorização de produtos: Os retalhistas utilizam a aprendizagem automática para classificar automaticamente produtos como "eletrónica", "vestuário" ou "artigos para o lar" com base nas suas descrições. Isto simplifica a gestão do inventário e melhora as experiências de pesquisa dos clientes.
Classificação de malware: Na cibersegurança, os modelos de classificação detectam e classificam o malware. Ao analisar padrões no comportamento do software, estes modelos classificam os programas como "seguros" ou "maliciosos" para proteger os sistemas contra ciberameaças.
Desafios comuns na classificação
Ao criar modelos de classificação, podem surgir vários desafios que afectam o desempenho do modelo. Aqui estão três desafios comuns:
Sobreajuste
Overfitting significa quando um modelo tem um bom desempenho nos dados de treino mas não consegue generalizar para dados novos e não vistos. Isto acontece quando o modelo se torna demasiado complexo e começa a captar ruído ou detalhes específicos do conjunto de treino em vez dos padrões subjacentes.
Desequilíbrio de dados
O desequilíbrio de dados ocorre quando uma classe supera significativamente as outras. Por exemplo, na deteção de fraudes, as transacções fraudulentas podem representar apenas 1% dos dados, o que leva o modelo a inclinar-se fortemente para a classe maioritária. Isto pode resultar numa deficiente deteção da classe minoritária.
Ruído nos dados
O ruído refere-se a erros aleatórios ou informações irrelevantes nos dados que podem confundir o modelo. Os dados ruidosos podem incluir exemplos mal rotulados, outliers ou caraterísticas irrelevantes que não contribuem para a tarefa de classificação. A presença de ruído pode reduzir o desempenho do modelo e dificultar a deteção de padrões.
Classificação vs. Regressão
Classificação e regressão são ambos tipos de algoritmos de aprendizagem supervisionada, mas são utilizados para diferentes tipos de tarefas. Segue-se uma comparação entre a classificação e a regressão com base em vários aspectos:
| Classificação** | Regressão | Aspeto | Classificação | Regressão |
| Objetivo | Prediz etiquetas ou categorias discretas. | Previsão de valores numéricos contínuos. | ||
| Saída | Categórica: classes como "spam" ou "não spam". | Contínuos: valores como "preço" ou "temperatura". | ||
| Exemplo de tarefa: classificar emails como "spam" ou "não spam". | Prever preços de casas com base em suas caraterísticas. | |||
| Algoritmos usados: regressão logística, árvores de decisão, floresta aleatória, etc. | Regressão linear, regressão Ridge, regressão polinomial, etc. | |||
| Métricas de avaliação: exatidão, precisão, recuperação, pontuação F1, ROC-AUC, etc. | Erro médio quadrático (MSE), R-quadrado, erro médio absoluto (MAE). | |||
| Natureza da variável-alvo | O alvo é categórico (por exemplo, rótulos de classe). | O alvo é contínuo (por exemplo, números reais). | ||
| Limites de saída | Tem limites de classe fixos (por exemplo, 0 ou 1 para binário). | Sem limite fixo; a saída é um intervalo de números reais. | ||
| Casos de uso no mundo real | Deteção de spam, deteção de fraude, classificação de doenças. | Previsão de vendas, preços de ações e previsão do tempo. | ||
| Modelagem Complexa Pode lidar com saídas binárias e multiclasse. | Geralmente é mais simples quando se prevê um valor contínuo. |
Tabela: Classificação vs Regressão
Como é que o Milvus ajuda nas tarefas de classificação?
À medida que o volume e a complexidade dos dados aumentam, os métodos tradicionais de gestão e consulta de grandes conjuntos de dados podem tornar-se lentos e ineficientes. É aqui que o Zilliz, com a sua base de dados vetorial de alto desempenho e de código aberto [Milvus] (https://zilliz.com/what-is-milvus), desempenha um papel vital.
As tarefas de classificação, como o reconhecimento de imagens, a deteção de objectos, a pesquisa de semelhanças em vídeo, a deteção de spam e os sistemas de recomendação, requerem frequentemente o tratamento de representações de alta dimensão de dados não estruturados, como texto incorporado, caraterísticas de imagem ou vectores de áudio. O Milvus foi especificamente concebido para gerir e pesquisar eficazmente estes grandes volumes de dados vectoriais.
Benefícios do Milvus para classificação
Manipulação de dados de alta dimensão: Na classificação, os modelos dependem muitas vezes de dados vectorizados (por exemplo, palavra embeddings ou vectores de caraterísticas de imagem) para fazer previsões. O Milvus está optimizado para armazenar e gerir estes vectores para aceder rapidamente a grandes conjuntos de dados durante a formação e inferência de modelos.
Busca rápida de similaridade: Os modelos de classificação precisam frequentemente de encontrar os pontos de dados correspondentes mais próximos num conjunto de dados. O Milvus acelera este processo realizando pesquisas de semelhança rápidas em dados vectoriais, facilitando a classificação de novas entradas com base nos seus vizinhos mais próximos.
Escalabilidade para grandes conjuntos de dados: O Milvus garante que o desempenho se mantém rápido e eficiente à medida que os conjuntos de dados de classificação aumentam. O Milvus é perfeitamente escalável para que as tarefas de classificação decorram sem problemas, mesmo com grandes quantidades de dados, quer se trate de milhões de vectores de produtos, de imagens incorporadas ou de milhares de imagens incorporadas.
Conclusão
A classificação é uma técnica de aprendizado de máquina para prever rótulos ou categorias para dados em várias aplicações do mundo real, desde a deteção de fraudes até o reconhecimento de imagens. Para construir e implementar modelos de classificação com sucesso, é necessário lidar com grandes quantidades de dados, muitas vezes vectores de alta dimensão. O Milvus fornece armazenamento eficiente, recuperação rápida e escalabilidade para dados vectoriais. Melhora o desempenho das tarefas de classificação através de pesquisas rápidas de semelhança e é escalável à medida que os conjuntos de dados crescem. Com o Milvus, os programadores podem lidar facilmente com os desafios das tarefas de classificação em grande escala, o que o torna uma ferramenta poderosa no panorama da aprendizagem automática.
FAQs sobre classificação
**O que é classificação em aprendizado de máquina?
A classificação no aprendizado de máquina é o processo de prever uma categoria ou rótulo para uma determinada entrada com base em seus recursos. Um modelo é treinado usando dados rotulados para aprender padrões e, em seguida, classificar dados novos e não vistos em classes predefinidas, como "spam" ou "não spam".
- Como é que um algoritmo de classificação difere da regressão?
Os algoritmos de classificação prevêem resultados categóricos (como classes ou rótulos), enquanto os algoritmos de regressão prevêem valores numéricos contínuos. Por exemplo, a classificação pode determinar se um e-mail é spam, enquanto a regressão pode prever o preço de uma casa.
- Por que a preparação de dados é importante em tarefas de classificação?
A preparação de dados garante que os dados de entrada estejam limpos, estruturados e prontos para serem processados pelo modelo. Ela lida com valores ausentes, normaliza os dados e seleciona os recursos mais relevantes. A preparação adequada melhora a precisão e o desempenho do modelo.
- Como é que o Milvus ajuda nas tarefas de classificação?
O Milvus é uma base de dados vetorial de código aberto que armazena e pesquisa eficientemente dados de elevada dimensão, como imagens ou texto incorporados. Acelera a classificação através da sua eficiente pesquisa de semelhanças, que facilita o tratamento de grandes conjuntos de dados em tarefas como o reconhecimento de imagens e sistemas de recomendação.
Quais são os desafios comuns na classificação e como podem ser resolvidos?
Os desafios comuns incluem sobreajuste, desequilíbrio de dados e ruído nos dados. Estes podem ser abordados usando técnicas como regularização, métodos de reamostragem (por exemplo, SMOTE), estratégias de redução de ruído e infraestrutura escalável como Milvus para gerenciar grandes conjuntos de dados de forma eficiente.
Recursos relacionados
O que é a deteção de objectos? Um guia completo](https://zilliz.com/learn/what-is-object-detection)
O que é o algoritmo K-Nearest Neighbors (KNN) na aprendizagem automática?](https://zilliz.com/blog/k-nearest-neighbor-algorithm-for-machine-learning)
- O que é Classificação?
- Como é que a classificação funciona?
- Tipos de classificação
- Aprendizes em algoritmos de classificação
- Algoritmos de classificação
- Métricas de avaliação na classificação
- Casos de uso de classificação no mundo real
- Desafios comuns na classificação
- Classificação vs. Regressão
- Como é que o Milvus ajuda nas tarefas de classificação?
- Conclusão
- FAQs sobre classificação
- Recursos relacionados
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis