




Melhorar o seu RAG com gráficos de conhecimento utilizando o KnowHow
A Retrieval Augmented Generation (RAG) é uma técnica popular que fornece ao LLM conhecimento adicional e memórias de longo prazo através de uma base de dados vetorial como o Milvus e o Zilliz Cloud (o Milvus totalmente gerido). Um RAG básico pode resolver muitos problemas do LLM, mas é insuficiente se tiver requisitos mais avançados, como a personalização ou um maior controlo dos resultados obtidos.
No nosso recente Unstructured Data Meetup, Chris Rec, o cofundador da WhyHow, partilhou a forma como incorpora Gráficos de Conhecimento (Knowledge Graphs - KG) no pipeline RAG para um melhor desempenho e precisão. O blogue abordará os pontos-chave da sua palestra, incluindo uma visão geral dos gráficos de conhecimento, RAG e como integrar gráficos de conhecimento em sistemas RAG para obter um melhor desempenho.
Se quiser saber mais sobre este tópico, recomendamos que assista a toda a palestra no [YouTube] (https://www.youtube.com/watch?v=6pjObdJdyFs).
Uma visão geral do RAG e dos seus desafios
O RAG é um método que aproveita os pontos fortes dos sistemas de inteligência artificial generativos e baseados na recuperação. Um RAG simples inclui normalmente uma base de dados vetorial como Milvus, um modelo de incorporação e um modelo de linguagem de grande dimensão (LLM).
Um sistema RAG começa por utilizar o modelo de incorporação para transformar os documentos em incorporação vetorial e armazená-los numa base de dados vetorial. Em seguida, recupera informações de consulta relevantes desta base de dados vetorial e fornece os resultados recuperados ao LLM. Finalmente, o LLM utiliza a informação recuperada como contexto para gerar resultados mais exactos.
Fluxo de trabalho RAG](https://assets.zilliz.com/RAG_chatbot_2f1ff9ec07.png)
Figura 1: Funcionamento das RAG
Embora um RAG simples seja excelente para gerar resultados mais actualizados e precisos, continua a ter várias limitações.
**Por exemplo, o termo "capacidade veicular" pode referir-se tanto ao número de passageiros que um carro pode transportar como ao número de carros que cabem numa estrada, criando ambiguidade.
**Por exemplo, responder a consultas baseadas na localização, como "Quero ir a Londres", é muito diferente de responder a consultas mais abstractas relacionadas com o bem-estar, como "Estou stressado no trabalho e quero tirar férias".
**Por exemplo, pode ser difícil distinguir entre uma "casa de praia" a uma milha da costa e uma "casa à beira-mar" diretamente na areia.
**Recuperar todas as informações relevantes para perguntas abrangentes pode ser um desafio, especialmente para consultas complexas, como listar todos os sócios limitados (LPs) de um fundo que investiram pelo menos 10 milhões de dólares e têm direitos especiais de acesso aos dados.
Por fim, as consultas multi-hop acrescentam outra camada de complexidade, uma vez que exigem a combinação exacta de várias informações. Esta abordagem requer a decomposição de uma consulta em várias subconsultas, cada uma com condições específicas, garantindo que a resposta final é exacta e completa.
Embora soluções como a melhoria imediata, estratégias avançadas de fragmentação, melhores modelos de incorporação e nova classificação possam resolver muitos dos desafios associados ao RAG, a WhyHow adopta uma abordagem diferente, incorporando gráficos de conhecimento no pipeline do RAG.
O que são gráficos de conhecimento (KGs)?
Um Knowledge Graph (KG) é um tipo de estrutura de dados que não só armazena dados, mas também liga dados semelhantes ou diferentes com base na sua relação. Esta abordagem permite ter uma coleção de coisas (que podem ser qualquer tipo de dados) ligadas de uma forma que pode fornecer informações relacionadas ou relevantes.
Um gráfico de conhecimento é constituído por nós, arestas e propriedades.
Fig. 2 - Blocos de construção de um gráfico de conhecimentos] (https://assets.zilliz.com/Fig_2_Building_Blocks_of_a_Knowledge_Graph_3a3c13c822.png)
Fig 2: Blocos de construção de um gráfico de conhecimento
Nós:
Representam as entidades ou objectos no gráfico.
Os valores de armazenamento destas entidades podem ser qualquer tipo de dados.
Bordas:
Representam as relações entre as entidades.
Contêm informações sobre a natureza do relacionamento entre os nós conectados.
Propriedades: Caraterísticas ou caraterísticas associadas a entidades individuais.
Ao contrário das bases de dados tabulares tradicionais, os gráficos de conhecimento utilizam uma estrutura gráfica para uma representação flexível das relações e centram-se na compreensão semântica. Esta abordagem permite consultas complexas e uma extração mais fácil de informações específicas.
Benefícios da integração de gráficos de conhecimento em sistemas RAG
Ao incorporar gráficos de conhecimento no pipeline RAG, podemos melhorar significativamente as capacidades de recuperação do sistema e a qualidade das respostas, resultando num desempenho superior, precisão, rastreabilidade e exaustividade. Eis as principais vantagens de um sistema RAG baseado em gráficos de conhecimento:
Compreensão contextual aprimorada
Os gráficos de conhecimento fornecem uma representação rica e interligada de informações, permitindo que o sistema RAG compreenda relações complexas entre entidades. Esta compreensão contextual mais profunda leva a respostas mais matizadas e relevantes.
Precisão e consistência factual melhoradas
A natureza estruturada dos gráficos de conhecimento ajuda a manter a consistência factual em todo o conteúdo gerado. Ao ancorar respostas a informações verificadas dentro do gráfico, o sistema pode reduzir erros e alucinações comuns em modelos de linguagem tradicionais.
Capacidades de Raciocínio Multi-hop
Os gráficos de conhecimento permitem que o sistema RAG efectue um raciocínio multi-hop, ligando peças de informação díspares através de caminhos lógicos. Esta capacidade permite responder a consultas e gerar inferências de forma mais sofisticada.
Recuperação eficiente de informações
A estrutura do gráfico facilita a recuperação rápida e precisa de informações, mesmo para consultas complexas. Esta eficiência traduz-se em tempos de resposta mais rápidos e na geração de conteúdos mais relevantes. Além disso, os sistemas RAG baseados em grafos de conhecimento permitem uma abordagem de recuperação híbrida, combinando a travessia de grafos com [pesquisas vectoriais e por palavra-chave] (https://zilliz.com/blog/a-review-of-hybrid-search-in-milvus), capacidades fornecidas por bases de dados vectoriais como Milvus e Zilliz Cloud.
Para ser mais específico, esta abordagem híbrida permite:
Correspondência exacta de entidades e relações através da passagem pelo grafo
Correspondência de similaridade semântica utilizando vetor embeddings
Pesquisa tradicional baseada em palavras-chave para conteúdos com muito texto
Esta estratégia de recuperação multifacetada aumenta a capacidade do sistema para encontrar as informações mais relevantes em vários tipos e estruturas de dados, conduzindo a respostas mais abrangentes e precisas.
Resultados transparentes e rastreáveis
Com os gráficos de conhecimento, o sistema pode fornecer uma proveniência clara para as informações utilizadas na geração de respostas. Esta rastreabilidade aumenta a confiança do utilizador e permite uma verificação e verificação mais fácil dos factos.
Síntese de conhecimento entre domínios
Ao representar diversos domínios numa única estrutura gráfica, os sistemas RAG baseados em gráficos de conhecimento podem sintetizar mais facilmente informações de diferentes campos, conduzindo a conhecimentos mais abrangentes e interdisciplinares.
Tratamento melhorado da ambiguidade
A estrutura relacional dos gráficos de conhecimento ajuda a desambiguar entidades e conceitos, reduzindo a confusão em situações em que os termos ou nomes podem ter vários significados ou referências.
Ao aproveitar estes benefícios, as aplicações RAG melhoradas com gráficos de conhecimento podem fornecer respostas mais precisas, contextualmente relevantes e abrangentes às consultas dos utilizadores.
O que é o WhyHow? Como é que ele melhora o RAG com gráficos de conhecimento?
WhyHow é uma plataforma para construir e gerir gráficos de conhecimento para apoiar a recuperação de dados complexos. A construção de gráficos de conhecimento abrangentes é um desafio e consome muito tempo. O WhyHow resolve este problema criando pequenos gráficos de conhecimento e repetindo-os várias vezes até obter um gráfico de conhecimento satisfatório para um domínio específico. Esta abordagem ajuda a torná-lo altamente específico do domínio, mais simples e fácil de trabalhar, uma vez que os KGs são complexos.
O WhyHow também fornece aos programadores os blocos de construção para organizar, contextualizar e recuperar de forma fiável dados não estruturados para executar RAG complexos. Ao integrar o WhyHow nos seus pipelines RAG existentes alimentados por uma base de dados vetorial, pode tornar o seu sistema RAG com melhor estrutura, consistência e controlo. O diagrama abaixo mostra como funciona um RAG melhorado por um Knowledge Graph.
Fig 3- Integração de RAG com WhyHow] (https://assets.zilliz.com/Fig_3_Integration_of_RAG_with_Why_How_b893400b28.png)
Fig 3: Integração do RAG com o WhyHow
Ao incorporar o WhyHow no seu fluxo de trabalho RAG, pode adotar uma abordagem híbrida de gráficos e vectores, tirando partido do melhor dos gráficos de conhecimento e das capacidades de pesquisa vetorial proporcionadas pelas bases de dados vectoriais.
Para obter um guia mais detalhado sobre como criar um RAG melhorado com o Knowledge Graph com o WhyHow, recomendamos que veja a demonstração ao vivo partilhada por Chris durante o Unstructured Data Meetup organizado por Zilliz.
Ter mais controlo sobre os seus fluxos de trabalho de recuperação no RAG utilizando o WhyHow e o Zilliz Cloud
Além de tornar as aplicações RAG mais eficientes e rastreáveis, muitos programadores também esperam ter um maior controlo sobre o que o seu RAG recupera. Isto porque as aplicações RAG por vezes não conseguem recuperar consistentemente os blocos de dados corretos quando os utilizadores enviam consultas mal formuladas ou quando os utilizadores precisam de incluir dados contextualmente relevantes mas semanticamente diferentes nas respostas.
Para resolver estes problemas, o WhyHow cria um Rule-based Retrieval Package através da integração com o Zilliz Cloud. Este pacote Python permite que os programadores criem fluxos de trabalho de recuperação mais precisos com capacidades de filtragem avançadas, dando-lhes mais controlo sobre o fluxo de trabalho de recuperação dentro dos pipelines RAG. Este pacote integra-se no OpenAI para geração de texto e no Zilliz Cloud para armazenamento e pesquisa de semelhanças vectoriais eficiente com filtragem de metadados.
A solução de recuperação baseada em regras executa estas tarefas:
**Criação de um armazém de vectores: Cria uma coleção Milvus para armazenar fragmentos de embeddings.
Splitting, Chunking, and Embedding: Automaticamente divide, divide em pedaços e cria embeddings para documentos carregados usando o PyPDFLoader e RecursiveCharacterTextSplitter do LangChain, e suporta o modelo text-embedding-3-small do OpenAI.
Inserção de dados: Carrega embeddings e metadados para Milvus ou Zilliz Cloud.
Filtragem automática: Constrói um filtro de metadados com base em regras definidas pelo utilizador para refinar as consultas no armazenamento de vectores.
O fluxo de trabalho é o seguinte:
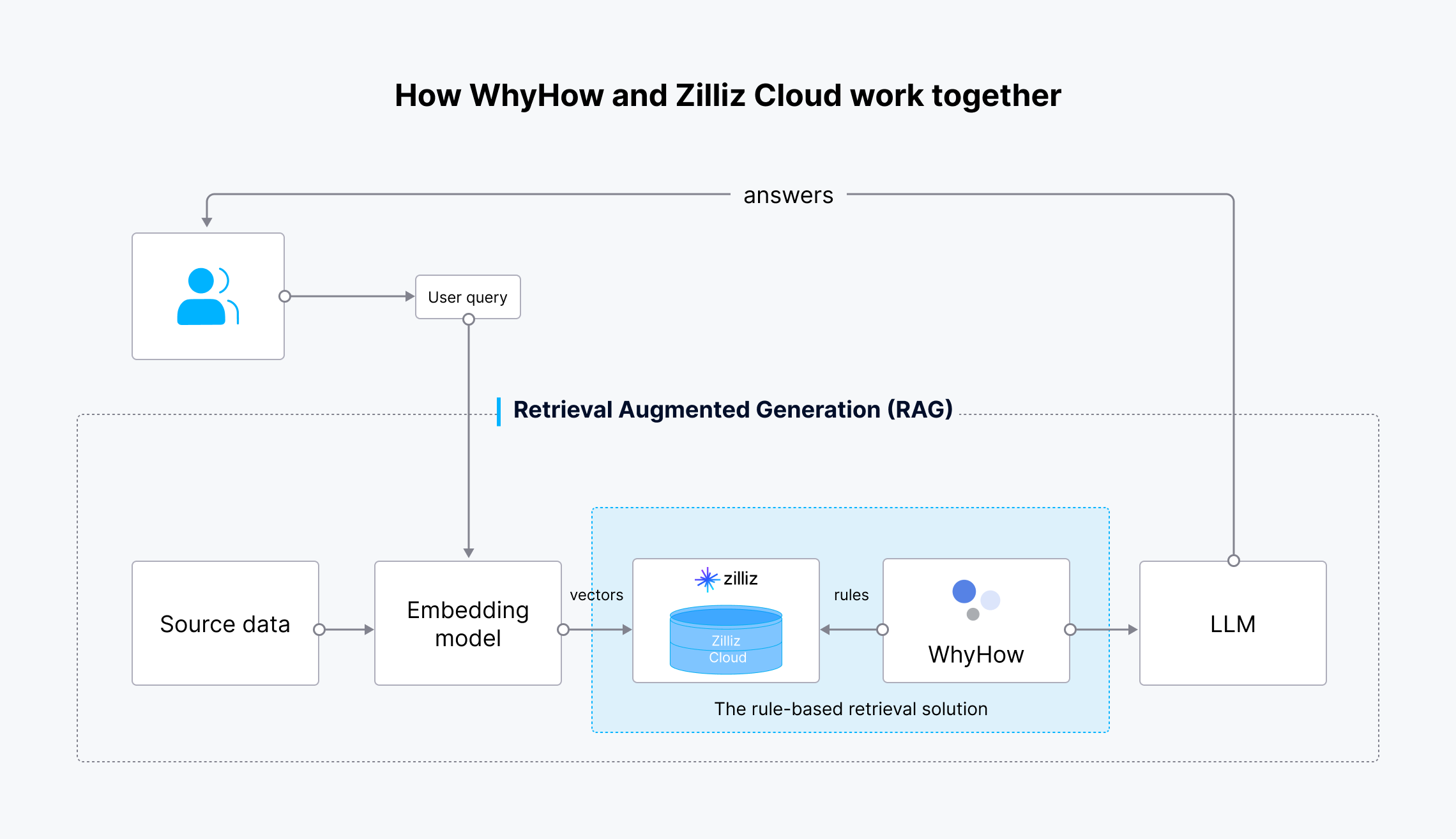 Como o WhyHow e o Zilliz Cloud trabalham em conjunto
Como o WhyHow e o Zilliz Cloud trabalham em conjunto
Fig 4: Fluxo de trabalho da solução de recuperação baseada em regras
Os dados de origem são transformados em vectores de incorporação utilizando o modelo de incorporação da OpenAI e ingeridos no Zilliz Cloud para armazenamento e recuperação. Quando é feita uma consulta pelo utilizador, esta é também transformada em embeddings vectoriais e enviada para o Zilliz Cloud para procurar os resultados mais relevantes. O WhyHow define regras e adiciona filtros à pesquisa vetorial. Os resultados recuperados, juntamente com a consulta original do utilizador, são então enviados para o LLM, que gera resultados mais precisos e os envia ao utilizador.
Conclusão
Os LLM realmente aliviaram nosso fardo de encontrar respostas para vários problemas. São suficientemente inteligentes para compreender a consulta fornecida, mas alucinam, e é difícil mantê-las actualizadas devido a limitações de recursos. Assim, a técnica de geração aumentada de recuperação (RAG) dá-lhes poder ao fornecer contexto à consulta; no entanto, os sistemas RAG também têm limitações, como discutido.
A WhyHow identificou essas limitações, salientando que a solução reside na incorporação de grafos de conhecimento nos pipelines RAG. Ao melhorar o RAG com gráficos de conhecimento, os seus sistemas RAG podem recuperar informações mais relevantes e contextuais e gerar respostas mais determináveis com menos alucinações e elevada precisão.
Se quiser aprofundar este tópico, assista à [apresentação do Chris no YouTube] (https://www.youtube.com/watch?v=6pjObdJdyFs).
Outros recursos
RAG completo: uma arquitetura moderna para hiperpersonalização
Construir aplicações RAG inteligentes com LangServe, LangGraph e Milvus
Construindo RAG com serviços de contentores Milvus e Snowpark auto-implantados
Explorando o DSPy e sua integração com o Milvus para criar pipelines RAG altamente eficientes

Continue lendo

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.