




Como a Zilliz acabou no centro da história de dados não estruturados da NVIDIA na GTC 2026
Na NVIDIA GTC deste ano, em meio à avalanche habitual de alegações sobre chips, sistemas e infraestrutura, Jensen Huang mostrou um slide que importava por um motivo diferente.
Não era sobre a próxima GPU. Não era sobre o tamanho do modelo. Nem era realmente sobre inferência.
Era sobre dados.
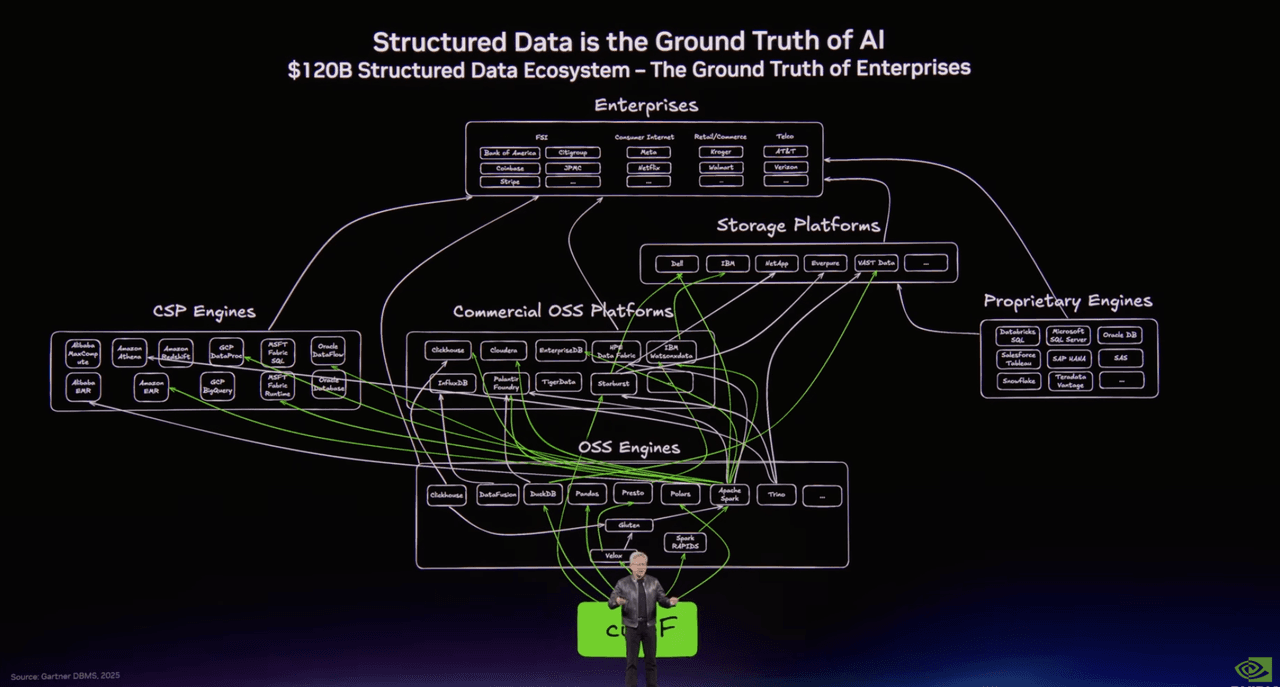
Um slide mapeava o mundo dos dados estruturados: Spark, Presto, DuckDB, Polars, Snowflake, Databricks, BigQuery, a maquinaria familiar que impulsionou a análise de dados e a engenharia de dados por décadas.
Outro mapeava a pilha emergente para dados não estruturados. E ali, no meio dessa segunda imagem, estava Milvus em código aberto e Zilliz Cloud na camada de banco de dados empresarial.

O título no slide dizia tudo: Dados Não Estruturados são o Contexto da IA.
É fácil concordar com essa frase. Claro, a IA precisa de contexto. Claro, a maior parte dos dados empresariais é não estruturada. Claro, texto, imagens, vídeo, áudio, logs, PDFs e todo o restante agora importam mais do que nunca. Mas, depois que você passa do slogan, surge uma pergunta mais difícil: se os dados não estruturados estão se tornando o substrato real dos sistemas de IA, como é, de fato, a infraestrutura para esse mundo?
Essa é a história mais interessante. E é a razão pela qual o Milvus passou de um banco de dados vetorial especializado para uma posição muito mais estratégica na pilha de IA.
Por que a Zilliz (Milvus) Continua Aparecendo
Esta não foi a primeira vez que a Zilliz apareceu na GTC, e provavelmente não será a última.
Muito antes de bancos de dados vetoriais se tornarem um bloco de construção padrão nos sistemas modernos de IA, o Milvus foi criado em torno da ideia de que a busca por similaridade precisaria operar em uma escala muito diferente da dos bancos de dados tradicionais. A aceleração por GPU não foi uma consideração posterior. Ela fazia parte da lógica de design desde o início.
Isso importou quando a IA deixou de ser uma história de pesquisa e se tornou uma história de infraestrutura.
Na GTC 2023, Jensen Huang já destacava a integração mais profunda entre as bibliotecas de aceleração da NVIDIA e sistemas como FAISS, Redis e Milvus. Um ano depois, na GTC 2024, essa relação se tornou mais concreta com o Milvus 2.4, que trouxe aceleração completa por GPU para indexação e busca vetorial ao combinar GPUs NVIDIA com CAGRA do RAPIDS cuVS. O resultado não foi uma aceleração cosmética. Em alguns cenários de benchmark, o desempenho da busca melhorou em até 50 vezes em relação ao HNSW.
Quando o Milvus 2.6 chegou, a conversa já havia evoluído novamente. A questão não era mais se a aceleração por GPU importava. Era como usá-la de forma economicamente eficiente. O Milvus 2.6 introduziu padrões de implantação mais flexíveis para o CAGRA, incluindo arquiteturas híbridas GPU-CPU que usam a GPU para construção de grafos e a CPU para recuperação. Isso importa porque a maioria das empresas não quer o sistema mais rápido possível a qualquer preço. Elas querem um sistema que permaneça rápido o suficiente enquanto continua economicamente sensato.
Vale a pena fazer uma pausa nesse detalhe, porque ele diz algo maior sobre por que o Milvus se tornou importante. Esta não é apenas uma história sobre desempenho de busca vetorial. É uma história sobre o que acontece quando a recuperação vetorial deixa de ser um recurso experimental e se torna parte da infraestrutura de produção.
O Que É Necessário para Fazer a Busca Vetorial Funcionar em Produção
Só velocidade deixa de ser a história.
Mas quando a recuperação vetorial sai das demonstrações e entra em sistemas reais, a velocidade por si só deixa de ser a história.
A pergunta mais difícil é o que é necessário para tornar a recuperação prática em escala empresarial, sem transformar a pilha ao redor em uma confusão de pipelines frágeis, alta pressão de memória e custos crescentes de infraestrutura.
Parte desse desafio começa a montante. No modelo antigo, transformar um PDF, imagem ou documento em algo pesquisável geralmente significava costurar uma camada separada de parsing, lógica de chunking, serviços de embeddings e gravações no banco de dados. O sistema de recuperação só começava a funcionar depois que uma longa cadeia de pré-processamento já havia concluído seu trabalho. O Milvus 2.6 começou a derrubar essa fronteira com uma abordagem Data-in, Data-out, permitindo que conteúdo bruto fosse escrito diretamente no sistema e incorporado dentro do próprio banco de dados.
Parte disso fica dentro da camada de recuperação. Diferentes cargas de trabalho exigem diferentes trade-offs, por isso oferecer suporte a vários tipos de índice em vez de impor uma única estratégia de recuperação a todos os casos de uso. A compressão também entra na equação. Recursos como Int8 e RaBitQ não são adições chamativas, mas atendem a um objetivo mais importante: reduzir a pressão de memória e os custos sem sacrificar a qualidade da recuperação.
E parte disso é simplesmente operacional. O Milvus introduziu uma arquitetura redesenhada de write-ahead logging que eliminou a necessidade de Kafka e Pulsar da pilha, reduzindo tanto a complexidade quanto a sobrecarga. Esse tipo de engenharia raramente ganha manchetes, mas é exatamente o tipo que determina se a infraestrutura permanece interessante na teoria ou se torna utilizável na prática.
O armazenamento acaba sendo outra linha de falha.
À medida que os sistemas de IA crescem, também cresce o custo de fingir que todos os dados devem ser tratados da mesma forma, o tempo todo. Em uma grande plataforma multi-tenant, apenas uma pequena parte dos dados pode de fato estar ativa em um determinado dia. A maior parte fica fria. Mas arquiteturas tradicionais de carregamento completo ainda tratam tudo como se merecesse a mesma residência local, a mesma postura de desempenho e a mesma pegada de custo.
Em pequena escala, isso parece ineficiente. Em escala empresarial, torna-se difícil de justificar.
O Milvus 2.6 abordou isso com armazenamento em camadas. Dados quentes permanecem locais, onde a latência importa. Dados frios são carregados sob demanda a partir de armazenamento de objetos de menor custo. E a fronteira entre os dois se desloca dinamicamente conforme o sistema é de fato usado. Isso soa como uma otimização de sistemas modesta. Na prática, muda a economia da recuperação. Quando os dados certos vivem na camada certa, os custos de armazenamento podem cair em mais de 70%.
Nada disso é especialmente glamouroso. Mas é geralmente assim que a infraestrutura amadurece: não por meio de uma única descoberta dramática, mas por uma série de decisões de design que tornam o sistema mais rápido, mais barato e mais fácil de conviver.
E todos esses recursos estão disponíveis no Zilliz Cloud, o serviço totalmente gerenciado do Milvus.
O Verdadeiro Problema Com Dados Não Estruturados
A mudança maior, porém, não é realmente sobre o Milvus sozinho. É sobre o tipo de dados do qual os sistemas de IA agora dependem.
Dados estruturados evoluíram de maneira longa e ordenada. Linhas, colunas, esquemas, índices, data warehouses, mecanismos de consulta. As ferramentas amadureceram ao longo de décadas porque os próprios dados se encaixavam nas premissas sobre as quais esses sistemas foram construídos. Você sabia como era um registro. Você sabia quais campos consultar. Você sabia como indexá-los.
Dados não estruturados quebram esse modelo.
Um contrato não é uma linha. Tampouco é uma imagem médica, uma transcrição de suporte, um repositório de código ou um feed de vigilância. Esses objetos podem ser armazenados, mas armazená-los é a parte fácil. A parte difícil é torná-los pesquisáveis de uma forma que entenda significado, em vez de correspondências exatas de campos.
É por isso que os embeddings mudaram tudo. Uma vez que texto, imagens, áudio e outras formas de conteúdo puderam ser mapeados em um espaço vetorial de alta dimensão, a recuperação não precisou mais depender de correspondência simbólica exata. Os sistemas puderam recuperar por similaridade, intenção e contexto.
Esse foi o avanço.
Também foi o começo de um novo problema de infraestrutura.
Uma vez que dados não estruturados se tornam consultáveis, as empresas imediatamente enfrentam a economia da escala. Milhões de documentos se tornam centenas de milhões de embeddings. Uma atualização de modelo significa reembutir o corpus histórico. A qualidade da recuperação depende da qualidade do índice. A latência importa em produção. O custo de armazenamento também. Assim como a carga operacional de manter tudo isso sincronizado.
Em outras palavras, a recuperação semântica resolveu o problema de acesso, mas expôs o problema dos sistemas.
Esse é o contexto em que o Milvus faz sentido.
Por que um Banco de Dados Vetorial Não Era Suficiente
Para a primeira onda de empresas nativas de IA, a resposta era direta: usar um banco de dados vetorial como camada de recuperação, conectá-lo a um modelo e construir a aplicação a partir daí. Esse modelo funcionou, e ainda funciona, especialmente quando a busca semântica é o núcleo do produto.
Mas grandes empresas tendem a encontrar uma barreira diferente.
A questão não é se elas conseguem fazer a busca vetorial funcionar. A questão é o que acontece depois disso.
Arquivos brutos vivem em armazenamento de objetos ou data lakes. Embeddings vivem em um banco de dados vetorial. Metadados vivem em um sistema relacional. O processamento offline acontece em outro lugar. Logs de busca se acumulam em outro pipeline. Então o modelo de embeddings muda, ou a lógica de ranqueamento muda, ou a base de conhecimento precisa de curadoria, ou alguém quer rastrear por que um sistema de recuperação continua falhando em casos extremos. De repente, o sistema não é mais um único sistema. É uma colcha de retalhos.
Essa colcha de retalhos cria três problemas conhecidos.
- O primeiro são os silos de dados. Os dados necessários para executar um único recurso de IA estão espalhados por vários sistemas, cada um com seu próprio formato, ciclo de vida e modelo operacional.
- O segundo é o custo de iteração. Quando um modelo de embeddings muda, a reescrita não é incremental por padrão. Ela pode se tornar um esforço de reindexação e migração que dura meses.
- O terceiro é o ciclo quebrado entre o atendimento online e a melhoria offline. O sistema atende consultas em produção, mas os sinais que poderiam melhorá-lo, resultados de desduplicação, rótulos de agrupamento, pontuações de qualidade e análises de falhas, muitas vezes vivem em ambientes separados e nunca fluem de forma limpa de volta para a camada de recuperação.
Esse é o ponto em que comprar um banco de dados vetorial deixa de parecer a resposta e começa a parecer o início de uma questão arquitetônica maior.
Se o problema real é a melhoria contínua em escala, então a arquitetura precisa mudar.
De Banco de Dados Vetorial a AI Lakebase
Antes do boom da IA, a Databricks ajudou a popularizar o modelo Lakehouse ao eliminar a divisão incômoda entre data lakes e data warehouses. Em vez de manter sistemas separados para armazenamento, análise e processamento em larga escala, as empresas podiam trabalhar a partir de uma base mais unificada.
A era da IA está forçando uma reconsideração semelhante, mas em torno de dados não estruturados.
Se você observar de perto os diagramas de infraestrutura que Jensen Huang tem usado, o centro de gravidade está mudando. Na era dos dados estruturados, frameworks como Spark ficavam no coração do pipeline. Na era dos dados não estruturados, infraestruturas vetoriais como o Milvus estão começando a preencher esse papel. Não porque a busca vetorial seja a única coisa que importa, mas porque ela cada vez mais se situa na junção entre dados brutos, embeddings, índices e recuperação de aplicações.
Isso abre uma possibilidade maior: e se a recuperação vetorial não fosse tratada como uma camada de serviço separada, acoplada à lateral da stack? E se ela fosse integrada diretamente ao data lake empresarial e aos fluxos de trabalho de dados ao redor?
Arquitetura do AI Lakebase
Essa é a ideia por trás do AI Lakebase.
O objetivo do AI Lakebase não é adicionar mais uma categoria de produto a um mercado já congestionado. O objetivo é substituir um padrão fragmentado por um mais coerente.
- Na base fica uma camada de armazenamento unificada. Parte desses dados reside em coleções nativas da Zilliz otimizadas para recuperação vetorial de alto desempenho. Parte permanece nos formatos abertos que a empresa já usa, Iceberg, Lance, Paimon e arquivos brutos em armazenamento de objetos. O ponto importante é que os dados não precisam ser copiados para cinco sistemas diferentes apenas para se tornarem utilizáveis.
- Acima disso fica a camada de serviço de produção, criada para recuperação em tempo real. No Zilliz Cloud, isso significa clusters de serviço impulsionados pelo Cardinal, otimizados para latência em nível de milissegundos, com diferentes modos para desempenho, capacidade e posicionamento de dados em camadas quentes e frias. Na prática, isso significa que dados acessados com frequência permanecem locais, enquanto dados frios são carregados sob demanda a partir de armazenamento mais barato. O resultado não é apenas um design de sistema melhor. É controle de custos.
- Depois há a camada de computação elástica: clusters sob demanda para ETL, deduplicação, clustering, análise de qualidade de dados, re-embedding, avaliação e investigação interativa. Esses não são sistemas paralelos colados depois. Eles fazem parte da mesma base.
Todas as três camadas compartilham os mesmos dados, em vez de manter várias cópias desconectadas.
Isso soa como uma história de limpeza arquitetural, e é. Mas é mais do que isso.
Mas o ponto maior é o que essa arquitetura torna possível.
AI Lakebase é mais do que uma limpeza arquitetural
A maioria dos sistemas de IA hoje consegue servir. Muito menos conseguem melhorar sistematicamente.
Isso geralmente não acontece porque o modelo está errado. Acontece porque a infraestrutura ao redor dele torna o feedback caro.
Um sistema de produção gera sinais constantemente. Cada consulta diz algo. Cada recuperação malsucedida diz algo. Cada resposta de baixa qualidade, cada resultado repetido, cada interação sem saída, cada cluster de documentos semelhantes, cada chunk ruidoso no corpus, tudo isso é informação que poderia ser usada para melhorar o sistema.
Mas, na maioria das stacks, esses sinais ficam espalhados por logs de serviço, pipelines offline, notebooks, dashboards e scripts pontuais. O sistema roda, mas não aprende de fato com a própria experiência.
O enquadramento do AI Lakebase para resolver isso é Continuous Serving/Continuous Discovery (AI CS/CD).
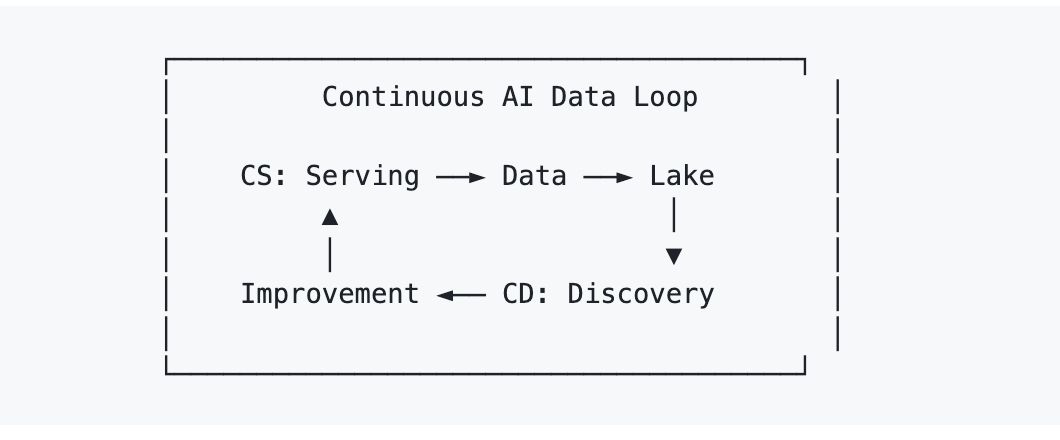
- Continuous Serving é a parte óbvia: o sistema em operação lida com recuperação e geração em produção.
- Continuous Discovery é a parte menos óbvia: o sistema analisa continuamente o que acumulou, lacunas de cobertura, modos de falha, estrutura de clusters, problemas de qualidade de dados, e escreve as melhorias resultantes de volta no mesmo ambiente operacional.
Isso importa porque, quando serviço e descoberta compartilham a mesma base de dados, as melhorias deixam de parecer migrações e passam a parecer iterações. Resultados de deduplicação podem fluir de volta para a recuperação em operação. Pontuações de qualidade podem influenciar o ranqueamento em produção. Rótulos de clusters podem se tornar sinais de recuperação. Re-embedding pode acontecer incrementalmente por meio de computação elástica, em vez de como um evento gigante de uma só vez.
A arquitetura começa a se comportar menos como um banco de dados estático e mais como um loop vivo de melhoria.
Essa é uma mudança muito mais consequente do que “banco de dados vetorial, mas mais rápido.”
Escale rápido e itere rápido com o AI Lakebase
Muitas empresas de infraestrutura podem alegar escala. Muitas podem alegar velocidade. Menos conseguem alegar de forma plausível escala e iteração contínua no mesmo sistema.
A Zilliz argumenta que a próxima fase da infraestrutura de IA empresarial exige ambas.
- Escalar Rapidamente significa uma infraestrutura multirregional e multicloud capaz de suportar cargas de trabalho de produção em escala muito grande, não apenas execuções de benchmark ou ambientes de demonstração.
- Iterar Rapidamente significa que o sistema é projetado para que a descoberta offline e o serviço online façam parte do mesmo ciclo operacional. A melhoria é incorporada, não anexada posteriormente.
Essa distinção importa porque a IA em produção falha de duas maneiras opostas. Alguns sistemas escalam, mas estagnam. Tornam-se grandes, caros e cada vez mais difíceis de melhorar. Outros iteram rapidamente em ambientes pequenos, mas nunca se tornam sistemas de produção duráveis. O verdadeiro objetivo não é nenhum dos dois. É um sistema que pode crescer e aprender simultaneamente.
Essa é a promessa por trás da mudança de banco de dados vetorial para AI Lakebase.
O banco de dados vetorial não desaparece nessa transição. Ele ainda importa. Ainda é o mecanismo de serviço para recuperação em tempo real. Mas deixa de ser o ponto final da arquitetura. Torna-se uma camada em um sistema mais amplo, assim como os bancos de dados relacionais ainda existem em um mundo Lakehouse sem definir toda a arquitetura por si próprios.
E essa pode ser a maneira mais útil de interpretar a frase de Jensen Huang na GTC.
Se os dados não estruturados são o contexto da IA, então o teto das aplicações de IA será definido não apenas pelos modelos, mas pelo grau de maturidade da infraestrutura para dados não estruturados.
Essa infraestrutura ainda está inacabada. O mercado ainda está no início. Mas o contorno começa a ficar visível.
E, cada vez mais, o Milvus está bem no centro disso.
Fique ligado!
AI Lakebase será a atualização arquitetônica por trás do Milvus 3.0 e uma grande evolução do Zilliz Cloud. Se quiser ter uma visão antecipada de para onde isso está caminhando, entre em contato conosco para acesso antecipado.
Continue lendo

Zilliz Cloud On-Demand Compute: Pay Only for What You Use
The customer case behind Zilliz Cloud On-Demand: how a $10K vector search bill came down to under $500, and the engineering changes that made it possible.

Build for the Boom: Why AI Agent Startups Should Build Scalable Infrastructure Early
Explore strategies for developing AI agents that can handle rapid growth. Don't let inadequate systems undermine your success during critical breakthrough moments.

How to Build RAG with Milvus, QwQ-32B and Ollama
Hands-on tutorial on how to create a streamlined, powerful RAG pipeline that balances efficiency, accuracy, and scalability using the QwQ-32B and Milvus.