




Milvus를 사용하여 10배 더 스마트한 검색 환경을 구축한 토코피디아의 사례
10배 더 스마트한
검색 환경
개선됨
사용자 경험
향상된
확장성 및 안정성
Our search system has been much more intelligent, stable, and reliable using Milvus.
Rahul Yadav
토코피디아 소개
Tokopedia는 인도네시아 최대의 전자상거래 플랫폼으로, 월간 활성 사용자 수가 9천만 명에 달하고 860만 명의 판매자 네트워크를 자랑합니다. 인도네시아 행정구역의 98%에 이르는 지역을 커버하는 Tokopedia는 인도네시아에서 온라인 쇼핑을 위해 가장 많이 찾는 곳이 되었습니다.
Tokopedia는 광범위한 제품 카탈로그의 가치를 구매자가 자신의 취향에 맞는 제품을 손쉽게 찾을 수 있도록 하는 데에 있다고 생각합니다. 검색 결과의 관련성을 높이기 위한 끊임없는 노력의 일환으로 Tokopedia에 유사도 검색을 도입했습니다.
사용자가 모바일 기기에서 검색 결과 페이지로 이동하면 눈에 잘 띄지 않는 '...' 버튼이 표시됩니다. 이 버튼을 클릭하면 사용자가 보고 있는 상품과 가장 유사한 상품을 탐색할 수 있는 메뉴에 액세스할 수 있습니다.
키워드 기반 검색의 문제점 ## 키워드 기반 검색의 과제
과거에 Tokopedia Search는 상품 검색 및 순위를 매기는 기본 엔진으로 Elasticsearch를 활용했습니다. 각 검색 요청은 사용자의 검색 키워드를 기반으로 제품의 순위를 매기는 Elasticsearch에 쿼리를 보냈습니다. Elasticsearch는 키워드를 숫자 값의 시퀀스로 저장하며, 개별 문자에 대해 ASCII 또는 UTF 코드로 나타냅니다. 사용자 쿼리의 단어가 포함된 문서를 신속하게 식별하기 위해 역 인덱스를 구성한 다음, 다양한 점수 알고리즘을 사용해 가장 잘 일치하는 문서를 결정합니다.
하지만 이러한 채점 알고리즘은 일반적으로 검색된 키워드의 의미를 고려하지 않습니다. 대신, 문서에서 단어가 얼마나 자주 나타나는지, 단어가 서로 얼마나 가까운지, 기타 통계 정보와 같은 요소에 중점을 둡니다. 인간은 단어의 ASCII 표현 이면의 의미를 이해할 수 있지만, 컴퓨터는 ASCII로 인코딩된 단어의 의미를 비교하기 위해 신뢰할 수 있는 알고리즘이 필요합니다.
벡터 표현
토코피디아 팀이 찾은 문제 해결 방법 중 하나는 단어의 문자를 표시하고 그 의미에 대한 정보를 제공하는 새로운 키워드 표현 방법을 만드는 것이었습니다. 예를 들어, 검색 키워드와 함께 일반적으로 사용되는 단어를 인코딩하여 가능한 문맥을 제공할 수 있습니다. 이를 통해 유사한 문맥이 유사한 개념을 나타낸다고 가정하고 수학적 기법을 사용하여 비교할 수 있습니다. 심지어 문장의 의미에 따라 전체 문장을 인코딩하는 것도 가능합니다.
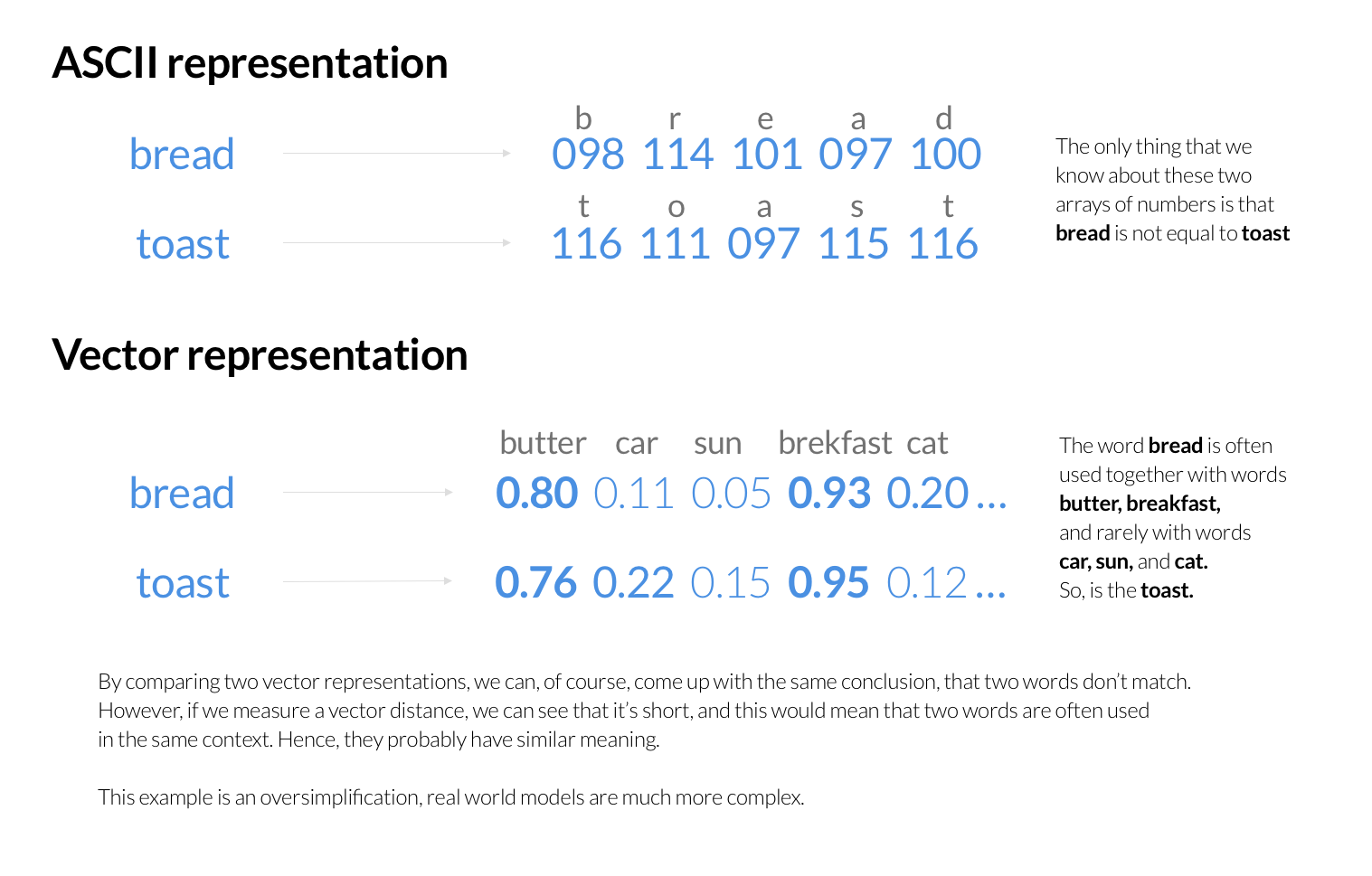
벡터 유사도 검색 엔진으로 Milvus 선택하기
이제 토코피디아가 특징 벡터를 보유하게 되었으니, 남은 과제는 방대한 데이터 세트에서 목표 벡터와 가장 일치하는 벡터를 효율적으로 검색하는 것입니다. 벡터 검색 엔진을 탐색하는 과정에서 저희는 FAISS, Vearch, Milvus 등 GitHub에서 제공되는 여러 벡터 검색 스택에 대한 개념 증명(POC) 평가를 실시했습니다.
부하 테스트 결과에 따라 Milvus를 선호하는 편입니다. Milvus에 비해 FAISS는 기본 라이브러리로 더 많이 운영되며 결과적으로 사용자 친화성이 떨어집니다. Milvus에 대해 자세히 알아본 결과 다음과 같은 이유로 채택하게 되었습니다:
- Milvus는 놀라울 정도로 사용자 친화적인 것으로 판명되었습니다**. Docker 이미지를 가져와서 특정 사용 사례에 맞게 매개변수를 조정하기만 하면 된다는 것을 알게 되었습니다.
- Milvus는 더 넓은 범위의 지원 인덱스를 제공합니다. FAISS, HSNW, DISK_ANN, ScaNN 외에도 11개의 인덱스 중에서 선택할 수 있습니다.
- Milvus는 사용자의 구현을 돕기 위해 포괄적인 설명서를 제공합니다**.
간단히 말해, Milvus는 사용자 친화적이며, 명확한 문서와 발생할 수 있는 모든 문제에 대한 신뢰할 수 있는 커뮤니티 지원을 제공합니다.
Milvus 사용 중
피처 벡터 검색 엔진으로 Milvus를 구현한 후, 광고 서비스에서 낮은 게재율 키워드와 높은 게재율 키워드를 매칭하는 데 활용했습니다. 개발(DEV) 환경에서 독립형 노드를 구성하고 실행한 결과, 원활하게 실행되어 클릭률(CTR)과 전환율(CVR)이 10배 이상 향상되었습니다.
하지만 한 가지 잠재적인 문제가 발생했습니다. 독립형 노드에 충돌이 발생하면 전체 서비스에 액세스할 수 없게 됩니다. 따라서 토코피디아 팀은 Milvus의 HA 구현으로 전환했습니다.
Milvus는 두 가지 도구를 제공합니다: 클러스터 샤딩 미들웨어인 Mishards와 간소화된 구성을 위한 Milvus-Helm이 그것입니다. 토코피디아에서는 인프라 설정에 Ansible 플레이북을 사용하여 인프라를 오케스트레이션하기 위한 플레이북을 생성하도록 유도합니다. 아래 다이어그램은 Mishards의 작동 방식을 보여줍니다.
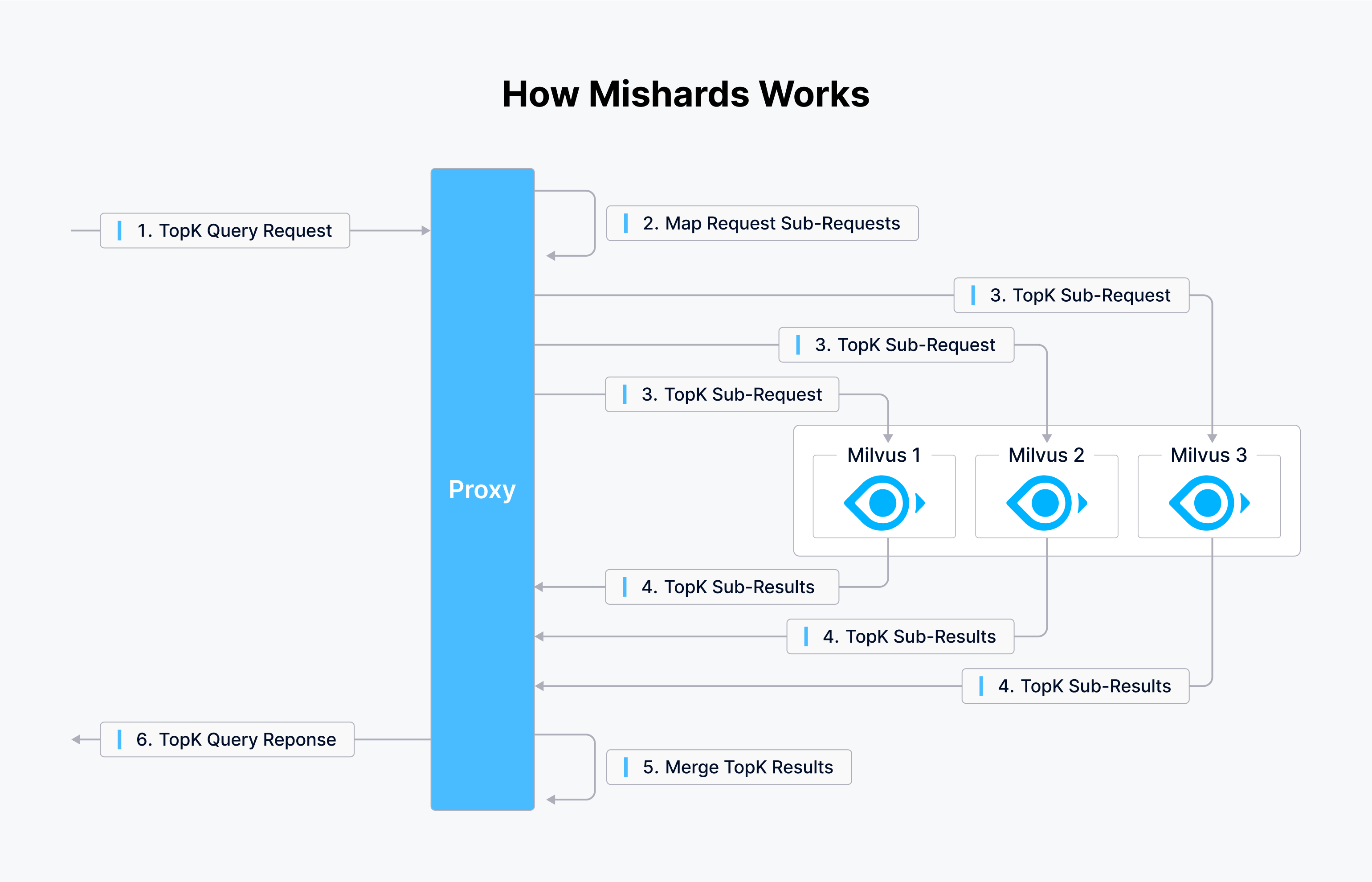
Mishards는 업스트림에서 다운스트림으로 요청을 원활하게 전달하여 업스트림 요청을 하위 모듈로 나누고 하위 서비스에서 결과를 수집한 다음 이러한 결과를 다시 업스트림 소스로 전달합니다.
미샤드 기반 클러스터 솔루션의 아키텍처는 아래와 같습니다.
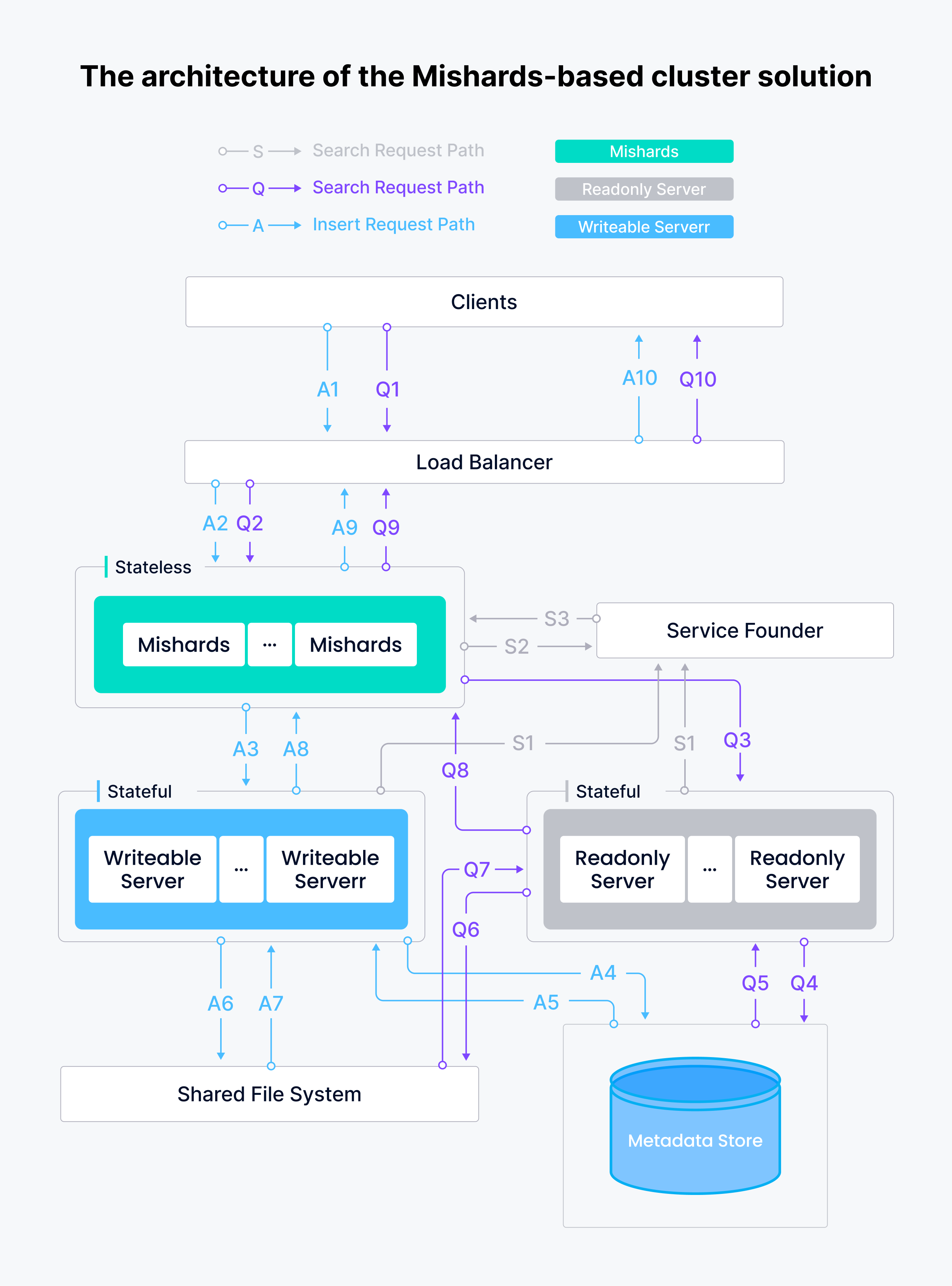
토코피디아 시맨틱 검색 서비스 시스템에는 쓰기 가능한 노드 1개, 읽기 전용 노드 2개, 미샤즈 미들웨어 인스턴스 1개가 있으며, 모두 Milvus Ansible을 사용하여 GCP에 배포되었습니다. 이 시스템은 상당히 스마트하고 안정적이며 신뢰할 수 있습니다.
벡터 인덱싱은 유사도 검색을 어떻게 가속화하나요?
유사도 검색 엔진에서 대규모 벡터 데이터 세트를 효율적으로 쿼리하려면 적절한 인덱싱이 필요합니다. 이 프로세스는 데이터를 정리하고 검색 프로세스의 속도를 높여주므로 수백만, 수십억, 심지어 수조 개의 벡터가 포함된 데이터 세트를 처리하는 데 필수적입니다. 대규모 벡터 데이터세트를 색인한 후에는 입력 쿼리와 유사한 벡터를 포함할 가능성이 가장 높은 데이터의 클러스터나 하위 집합으로 쿼리를 유도할 수 있습니다. 그러나 이 접근 방식은 대규모 벡터 데이터에 대한 빠른 쿼리를 달성하기 위해 정확도를 희생할 수 있습니다.
이해를 돕기 위해 인덱싱을 사전에서 단어를 알파벳순으로 정렬하는 것으로 생각해 보세요. 키워드를 검색할 때 첫 글자가 같은 단어만 포함된 섹션으로 빠르게 이동하여 입력 단어의 정의를 찾는 속도를 획기적으로 높일 수 있습니다.
요약
우수한 검색 기능에 대한 토코피디아의 탐구는 시맨틱 검색의 판도를 바꾼 Milvus로 이어졌습니다. Milvus를 통해 벡터 표현의 강력한 기능을 활용하고 10배 더 스마트한 검색 시스템을 구축하여 사용자 경험을 획기적으로 향상시켰습니다. 또한 검색 서비스의 가용성도 높아져 원활한 운영을 보장합니다. Milvus와 함께한 이 여정은 Tokopedia의 검색을 혁신하여 개인화되고 의미 있는 검색 결과의 미래를 약속하고 있습니다. Milvus와 함께 인도네시아를 비롯한 전 세계 이커머스에 혁신을 일으키고 있습니다.
*이 글은 Tokopedia의 소프트웨어 엔지니어인 라훌 야다브가 작성했습니다. 허가를 받아 여기에 편집 및 재게시되었습니다. *