




Exa, Zilliz Cloud로 AI 에이전트를 위한 엔티티 검색 엔진 구축
<200ms 검색 지연 시간
Exa의 신경망 검색 지연 시간이 Zilliz의 하이브리드 검색으로 몇 초에서 200ms 미만으로 감소
높은 신뢰성
운영 사고를 거의 제로에 가깝게 줄여 엔지니어링 시간을 제품 작업에 투입할 수 있도록 함
스키마 변경을 위한 무중단 처리
인덱스를 다시 빌드하거나 컬렉션을 오프라인으로 전환하지 않고도 새로운 필터링 가능한 필드와 메타데이터를 추가할 수 있습니다
We believe AI agents will become a fundamental interface for how people work, learn, and make decisions, and that only happens if those systems can access real-world information with speed, precision, and trust. That’s what we’re building at Exa. Aside from web search, Exa also operates entity search, and Zilliz Cloud has been an important part of that journey, giving us the retrieval performance and operational simplicity we need to scale our entity search product quickly and confidently.
Jeffrey Wang
AI 에이전트를 위한 검색은 웹 검색의 자연스러운 확장처럼 들리지만, 실제로는 다른 제품 기준을 요구합니다. 에이전트에는 단순한 링크가 필요한 것이 아니라, 음성 상호작용부터 심층 리서치 작업까지 실제 워크플로를 지원할 수 있을 만큼 빠르게 제공되는, 근거 있고 최신이며 구조화된 정보가 필요합니다.
Exa는 AI를 위한 바로 그런 검색 엔진을 구축하고 있습니다. Exa의 Search API는 개발자에게 음성 에이전트를 위한 즉시 검색부터 구조화된 출력 및 보강 기능을 갖춘 더 깊이 있는 리서치까지, 다양한 컴퓨트-레이턴시 범위에 걸쳐 고품질의 낮은 지연 시간 웹 검색을 제공합니다. Exa는 Cursor와 Lovable 같은 AI 네이티브 스타트업부터 AWS와 같은 엔터프라이즈 기업까지 다양한 고객에게 서비스를 제공하며, 이들 모두는 에이전트 기반 워크플로를 위해 근거 있는 실제 세계의 맥락에 의존합니다.
Exa가 기업, 사람, 코드에 대한 엔티티 검색으로 확장하면서, 더 특화된 인프라 과제에 직면했습니다. 핵심 검색 엔진에서 엔지니어링 역량을 분산시키지 않으면서 하이브리드 검색, 풍부한 메타데이터 필터링, 빈번한 업데이트, 밀리초 수준의 지연 시간을 어떻게 지원할 것인가 하는 문제였습니다. 아래 이야기에서 Zilliz Cloud(완전 관리형 Milvus)가 맡는 역할이 바로 이것입니다.
| 200ms의 낮은 검색 지연 시간 | 단일 API 호출에서 dense vector, sparse vector, RRF 재랭킹, 메타데이터 필터를 결합한 하이브리드 검색. Exa Instant는 neural search 지연 시간을 수 초에서 200ms 미만으로 줄였습니다 |
| 높은 안정성 | 관리형 서비스는 운영 사고를 거의 0에 가깝게 유지해, 엔지니어링 시간을 제품 작업에 집중할 수 있게 했습니다 |
| 스키마 변경 시 다운타임 없음 | 인덱스를 재구축하거나 컬렉션을 오프라인으로 전환하지 않고도 새로운 필터 가능 필드와 메타데이터를 추가할 수 있습니다 |
아래는 Exa와 제품 미션, 일반 웹 검색에서 엔티티 검색으로의 전환, 그리고 Zilliz Cloud가 그 진화에 어떻게 맞아 들어가는지에 대해 나눈 대화의 스크립트입니다.
1. Exa의 제품 약속: AI 에이전트를 위한 근거 있는 검색
우리는 Exa에게 구축 중인 제품과 서비스를 제공하는 고객에 대해 설명해 달라고 요청하는 것으로 시작했습니다. 그 맥락이 왜 검색 품질과 지연 시간이 이 회사에 부차적인 문제가 아닌지를 설명해 주기 때문입니다.
Q: Exa는 어떤 제품이나 서비스를 제공하며, 주요 고객은 누구인가요?
Exa: Exa는 AI를 위한 검색 엔진을 구축하고 있습니다. 우리는 개발자가 자신의 에이전트 전반에서 고품질의 낮은 지연 시간 웹 검색에 접근할 수 있게 해주는 검색 API를 만들었습니다. 우리의 API는 음성 에이전트를 위한 즉시(<200ms) 검색부터 구조화된 출력 및 보강 기능을 갖춘 심층 리서치까지, 컴퓨트 지연 시간 스펙트럼 전반의 검색을 제공합니다. 우리는 코드 검색, 낮은 지연 시간, 사람/회사 검색에 특화되어 있으며, 토큰 효율성을 보장하는 하이라이트 기능을 제공합니다.
우리는 기존 검색 엔진에 의존하는 대신, 새로운 신경망 아키텍처를 사용해 검색 엔진을 처음부터 구축했습니다. 자체 검색 엔진을 구축하려면 임베딩 모델과 재랭커 학습부터 수십억 개의 웹 페이지 크롤링 및 인덱싱까지 모든 것이 필요합니다. 이러한 엔드투엔드 소유권 덕분에 우리는 스택의 모든 계층을 품질과 속도에 맞게 최적화할 수 있습니다. 예를 들어 최근 Exa Instant 출시에서는 <200ms 검색 지연 시간을 달성했습니다. 이는 neural search를 AI 에이전트를 위한 실시간 프리미티브로 실현 가능하게 만드는 중요한 개선입니다. 품질, 속도, 맞춤화 가능성의 조합은 핵심 차별화 요소입니다.
우리 고객은 Cursor와 Lovable 같은 AI 네이티브 기업부터 대기업까지 다양합니다. 지식 업무를 추진하기 위해 에이전트를 사용하는 모든 회사는 실제 세계에 응답하기 위한 근거 있는 맥락이 필요하므로, 회사 규모와 관계없이 우리는 에이전트 기반 워크플로를 우선시하는 팀들과 협력합니다.
2. 변곡점: 웹 검색에서 엔티티 검색으로
이 제품 맥락은 또한 Exa의 데이터베이스 결정이 핵심 검색 스택을 대체하는 문제가 아니었다는 점을 분명히 해줍니다. Vector search는 이미 회사의 기반이었습니다. 실제 변화는 엔티티 검색이 새로운 제약 조건을 도입했을 때 찾아왔습니다.
Q: 제품 여정의 어느 시점에 벡터 데이터베이스가 필요하다는 것을 깨달으셨나요?
Exa: 저희 검색 엔진이 임베딩과 벡터 유사도를 기반으로 구축되었다는 점을 고려하면, 벡터 검색은 Exa의 기술 스택에서 필수적인 부분이었습니다. 엔티티 검색으로 확장하면서, 저희가 이제 제공하는 구조화된 출력과 보강 데이터를 수용하기 위해 벡터 데이터베이스 인프라를 업데이트해야 했습니다.
엔티티 검색에는 풍부한 메타데이터 스키마, 빈번한 데이터 업데이트, 관리형 확장성이 필요합니다. 저희 내부 데이터베이스는 이러한 업데이트된 제약 조건에 최적화되어 있었지만, 이 엔티티 검색 레이어 전반의 반복 속도를 더욱 개선하고자 했고, 그 결과 Zilliz Cloud를 사용하게 되었습니다. 저희 핵심 웹 인덱스는 내부 인프라에 그대로 남아 있으며, Zilliz Cloud는 특히 이 엔티티 검색 레이어를 구동하기 위해 도입되었습니다.
Q: 이전 솔루션에서 어떤 과제나 요구 사항에 직면하셨나요?
Exa: 엔티티 검색을 구축하기 시작했을 때 요구 사항은 매우 달랐습니다. 밀집 벡터와 희소 벡터를 결합한 하이브리드 검색, 풍부하고 자주 변경되는 메타데이터 스키마, 여러 전문 컬렉션을 관리하는 운영 오버헤드가 있었습니다. 저희는 엔지니어들이 빠르게 반복하고 대규모에서도 빠른 응답을 지원할 수 있게 해주는 관리형 솔루션을 찾고 있었습니다.
Q: 벡터 검색/벡터 데이터베이스로 어떤 구체적인 사용 사례를 해결하고 있나요?
Exa: 오늘날 Zilliz Cloud는 저희 엔티티 검색 레이어를 구동하며, 엔티티 컬렉션 전반에서 기본 인덱스이자 최신성 캐시 역할을 하는 반면, 메인 웹 인덱스는 별도의 내부 인프라에서 실행됩니다. 각 버티컬은 자주 업데이트되는 데이터에 대해 낮은 지연 시간의 필터링 검색을 요구하며, Zilliz의 관리형 하이브리드 검색 및 핫 업서트 기능은 인덱스를 재구축하지 않고도 결과를 최신 상태로 유지합니다. 이러한 버티컬은 저희 Search API로 직접 이어지므로, 속도와 재현율은 비즈니스에 매우 중요합니다.
3. 관리형 벡터 검색 레이어에 대해 Exa가 필요로 했던 것
엔티티 검색이 별도의 레이어가 되자, 평가는 실제로 적합성에 관한 것이었습니다. 관리형 시스템이 팀의 속도를 늦추거나 아키텍처상의 타협을 강요하지 않으면서 Exa의 검색 품질 기준을 지원할 수 있는가?
Q: Zilliz Cloud를 선택하기 전에 어떤 벡터 데이터베이스를 평가하셨나요? 평가에서 핵심 기준은 무엇이었나요?
Exa: 엔티티 검색을 구축하기 시작했을 때 요구 사항은 매우 달랐습니다. 밀집 벡터와 희소 벡터를 결합한 하이브리드 검색, 풍부하고 자주 변경되는 메타데이터 스키마, 여러 전문 컬렉션을 관리하는 운영 오버헤드가 있었습니다. 저희는 엔지니어들이 빠르게 반복하고 대규모에서도 빠른 응답을 지원할 수 있게 해주는 관리형 솔루션을 찾고 있었습니다.
저희는 이 분야의 주요 벡터 데이터베이스 옵션을 모두 조사했습니다. 핵심 기준은 다음과 같았습니다:
하이브리드 검색 지원: 내장 리랭킹을 통해 단일 쿼리에서 밀집 의미 벡터와 희소 키워드 벡터를 결합할 수 있는 네이티브 기능
쿼리 지연 시간: 수천만 개의 벡터를 가진 컬렉션 전반에서 일관되게 빠른 응답
풍부한 메타데이터 필터링: 검색 성능을 저하시키지 않으면서 구조화된 필드에 대한 복잡한 필터 지원
확장성: 새로운 버티컬과 데이터 소스를 추가할 때 원활한 확장
Zilliz Cloud는 모든 기준을 충족했으며, 하이브리드 검색 벤치마크에서의 성능은 분명히 경쟁 제품보다 앞서 있었습니다.
Q: Zilliz Cloud / Milvus에 대해 처음 어떻게 알게 되셨나요?
Exa: 저희는 Milvus를 오랫동안 알고 있었습니다. 가장 성숙한 오픈소스 벡터 데이터베이스 중 하나이고, 벡터 검색에 깊이 몰두하는 팀으로서 놓치기 어렵기 때문입니다. 엔티티 검색 인프라 범위를 정하기 시작했을 때, Zilliz Cloud는 엔터프라이즈급 성능 향상을 갖춘 Milvus 기반의 자연스러운 관리형 제품으로 두드러졌습니다.
Q: 평가 과정에서 Zilliz Cloud의 어떤 점이 두드러졌나요? Zilliz Cloud를 선택하게 된 주요 이유는 무엇이었나요?
Exa: 몇 가지가 곧바로 눈에 띄었습니다.
네이티브 하이브리드 검색: Zilliz Cloud는 단일 API 호출에서 밀집 및 희소 벡터 검색을 지원하며, 내장 재랭킹 전략(RRF, weighted)을 제공합니다. 이는 여러 경쟁업체에게 강력한 요구사항이었고, 우리는 이를 네이티브로 지원하지 않았습니다.
대규모 성능 - Zilliz Cloud의 Cardinal 인덱싱 엔진은 컬렉션이 수억 개의 벡터로 성장하더라도 일관되게 빠른 쿼리 시간을 제공합니다.
성숙한 필터링 - 성능 급락 없이 단일 요청에서 벡터 검색과 복잡한 메타데이터 필터를 결합할 수 있는 기능.
도입을 결정한 요인 측면에서:
속도 - Zilliz Cloud의 쿼리 지연 시간은 프로덕션 검색에 대한 우리의 엄격한 요구사항을 충족했습니다. 우리 사용자는 밀리초 단위의 결과를 기대하며, Zilliz는 이를 지원할 수 있습니다.
하이브리드 검색 기능 - 밀집 의미 검색과 희소 BM25 키워드 매칭을 융합하고 단일 API 호출에서 Reciprocal Rank Fusion (RRF) 재랭킹을 적용할 수 있는 기능은 검색 품질에 중요했습니다.
운영 단순성 - 완전 관리형 서비스로서, Zilliz Cloud는 우리 팀이 더 나은 검색 경험을 구축하고 대규모 벡터 데이터베이스 인프라 개선을 빠르게 반복하는 데 집중할 수 있게 해줍니다.
4. Zilliz와 Exa 아키텍처가 함께 맞물리는 방식
Q: Zilliz Cloud는 귀사의 아키텍처에 어떻게 맞물리나요?
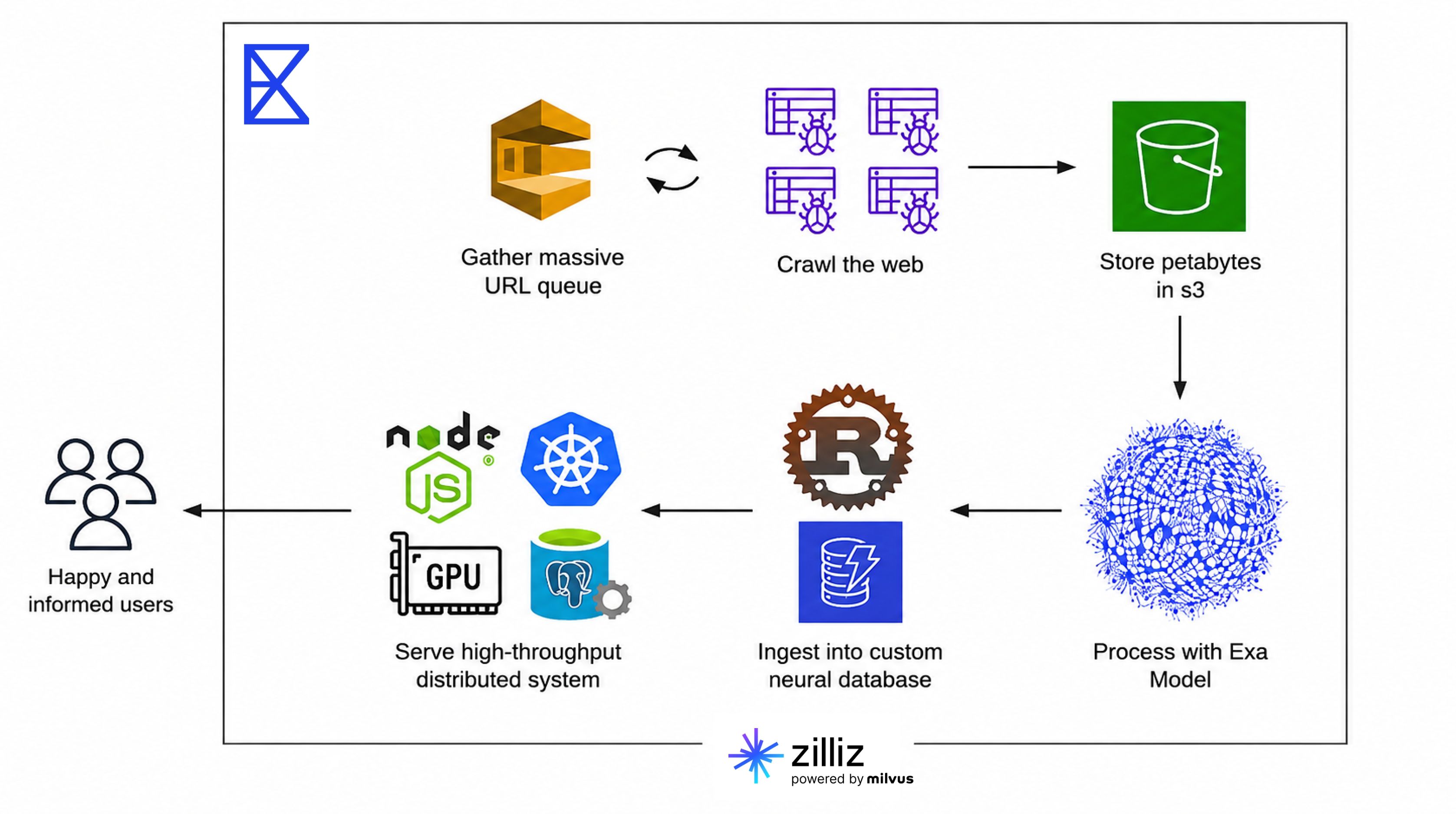
Exa: 우리의 엔티티 검색 아키텍처는 수집, 검색, API의 세 계층으로 구성됩니다.
수집 단계에서는 자체 ML 파이프라인을 사용해 엔티티 데이터를 보강하고 임베딩한 다음, 밀집 및 희소 벡터를 Zilliz Cloud에 업서트합니다.
검색 단계에서는 백엔드가 사용자 쿼리에서 임베딩을 생성하고 Zilliz Cloud로 하이브리드 검색 요청을 보내며, 의미 및 키워드 매칭을 RRF 재랭킹과 결합합니다.
API 계층에서는 결과가 구조화된 메타데이터로 보강되어 Search API와 Websets 제품을 통해 제공됩니다. Zilliz Cloud는 이 워크플로의 검색 핵심에 위치합니다. 모든 엔티티 벡터와 메타데이터를 저장하고 저지연 검색을 처리합니다. 우리의 기본 웹 인덱스는 별도의 사내 인프라에서 구축 및 관리됩니다.
Q: 귀사 팀은 Zilliz Cloud 또는 Milvus를 사용하면서 어떤 경험을 했나요?
Exa: API는 직관적이고, 문서는 탄탄하며, 시스템은 프로덕션에서 안정적이었습니다. Milvus 개념인 collections, indexes, search params가 우리가 이미 벡터 검색을 생각하는 방식과 잘 맞아 학습 곡선은 최소한이었습니다. Zilliz Cloud의 관리형 특성 덕분에 처리해야 할 운영 사고가 매우 적었습니다.
Q: Zilliz Cloud를 AWS 또는 다른 클라우드 서비스와 통합한 경험은 어땠나요?
Exa: 매끄러웠습니다. 우리는 인프라를 주로 AWS에서 운영하며, Zilliz Cloud는 그 AWS 네이티브 스택에 깔끔하게 맞아 들어갑니다. AWS에서 실행되기 때문에 EKS 서비스와 Zilliz Cloud 간의 네트워크 지연 시간이 최소화됩니다.
5. 도입 후 달라진 점
Q: 확인한 상위 3가지 이점은 무엇인가요? 측정 가능한 지표나 개선 사항을 공유해 주실 수 있나요?
Exa: 첫 번째 이점은 개발자 속도였습니다. 관리형 서비스와 깔끔한 API 덕분에 우리 팀은 추가 인프라를 구축하거나 관리하지 않고도 새로운 엔티티 검색 버티컬을 빠르게 출시할 수 있었습니다.
그 외에도 이러한 버티컬 데이터셋이 발전함에 따라 스키마 유연성과 적응성이 매우 중요했으며, autoindex를 통한 검색 품질도 실제로 가치가 있었습니다.
Q: Zilliz Cloud의 어떤 기능이 가장 가치 있다고 생각하시나요?
Exa: 일상적인 사용에서 두 가지가 가장 두드러집니다.
성능 급락 없는 필터링: 벡터 검색 위에 복잡한 메타데이터 필터를 계층화해도 지연 시간 영향이 거의 없습니다.
빠른 버티컬 출시: 관리형 확장 덕분에 매번 새로운 인프라를 세우지 않고도 새로운 검색 버티컬을 빠르게 출시할 수 있습니다.
Zilliz Cloud 시작하기
Zilliz는 세계에서 가장 인기 있는 오픈 소스 벡터 데이터베이스인 Milvus와 Milvus 기반으로 구축된 완전 관리형 벡터 데이터베이스 서비스인 Zilliz Cloud의 개발사입니다. Zilliz Cloud는 고성능 벡터 검색, 하이브리드 검색, 엔터프라이즈급 보안 및 규정 준수를 통해 조직이 프로덕션에 바로 사용할 수 있는 AI 애플리케이션을 구축할 수 있도록 지원합니다.
- 비즈니스 이메일로 등록 시 $100 크레딧을 받고 Zilliz Cloud를 무료로 시작하세요