




Airtable이 Milvus로 벡터 인프라를 구축하고 확장한 방법

저지연 쿼리
예측 가능한 성능은 사용자 신뢰에 매우 중요합니다
높은 처리량의 쓰기
베이스는 끊임없이 변하고, 임베딩은 동기화 상태를 유지해야 합니다
수평적 확장성
시스템은 수백만 개의 독립적인 베이스를 지원해야 합니다
이 게시물은 원래 the Airtable Medium 채널에 게시되었으며 허가를 받아 여기에 재게시되었습니다.
Airtable의 시맨틱 검색이 개념에서 핵심 제품 기능으로 발전하면서, Data Infrastructure 팀은 이를 확장해야 하는 과제에 직면했습니다. Building the Embedding System에 대한 이전 게시물에서 자세히 설명했듯이, 우리는 이미 임베딩 수명 주기를 처리하기 위해 견고하고 최종적으로 일관성을 갖춘 애플리케이션 계층을 설계했습니다. 하지만 아키텍처 다이어그램에는 여전히 중요한 한 조각이 빠져 있었습니다. 바로 벡터 데이터베이스 자체였습니다.
우리는 수십억 개의 임베딩을 인덱싱하고 제공할 수 있으며, 대규모 멀티테넌시를 지원하고, 분산 클라우드 환경에서 성능 및 가용성 목표를 유지할 수 있는 스토리지 엔진이 필요했습니다. 이것은 우리가 벡터 검색 플랫폼을 설계하고, 강화하고, 발전시켜 Airtable 인프라 스택의 핵심 축으로 만든 과정에 대한 이야기입니다.
배경
Airtable에서 우리의 목표는 고객이 강력하고 직관적인 방식으로 데이터를 다룰 수 있도록 돕는 것입니다. 점점 더 강력하고 정확한 LLM의 등장으로, 데이터의 의미론적 의미를 활용하는 기능이 우리 제품의 핵심이 되었습니다.
시맨틱 검색을 사용하는 방식
대규모 데이터셋의 실제 질문에 답하는 Omni(Airtable의 AI Chat)
50만 개의 행이 있는 base(데이터베이스)에 자연어 질문을 하고, 정확하며 맥락이 풍부한 답변을 얻는다고 상상해 보세요. 예를 들어:
“최근 배터리 수명에 대해 고객들은 뭐라고 말하고 있나요?”
작은 데이터셋에서는 모든 행을 LLM으로 직접 보내는 것이 가능합니다. 규모가 커지면 이는 빠르게 불가능해집니다. 대신, 우리는 다음을 수행할 수 있는 시스템이 필요했습니다.
- 쿼리의 의미론적 의도 이해
- 벡터 유사도 검색을 통해 가장 관련성 높은 행 검색
- 해당 행들을 LLM에 컨텍스트로 제공
이 요구사항은 뒤따른 거의 모든 설계 결정을 형성했습니다. Omni는 매우 큰 base에서도 즉각적이고 지능적으로 느껴져야 했습니다.
연결된 레코드 추천: 정확한 일치보다 의미
시맨틱 검색은 Airtable의 핵심 기능인 연결된 레코드도 향상시킵니다. 사용자는 정확한 텍스트 일치가 아니라 맥락에 기반한 관계 제안이 필요합니다. 예를 들어, 프로젝트 설명이 해당 특정 문구를 전혀 사용하지 않더라도 “Team Infrastructure”와의 관계를 암시할 수 있습니다.
이러한 온디맨드 제안을 제공하려면 일관되고 예측 가능한 지연 시간을 갖춘 고품질 의미론적 검색이 필요합니다.
설계 우선순위
이러한 기능과 그 이상을 지원하기 위해, 우리는 시스템을 4가지 목표를 중심으로 잡았습니다.
- 저지연 쿼리(500ms p99): 예측 가능한 성능은 사용자 신뢰에 매우 중요합니다
- 고처리량 쓰기: base는 끊임없이 변경되며, 임베딩은 동기화 상태를 유지해야 합니다
- 수평적 확장성: 시스템은 수백만 개의 독립적인 base를 지원해야 합니다
- 자체 호스팅: 모든 고객 데이터는 Airtable이 통제하는 인프라 내부에 남아 있어야 합니다
이러한 목표는 이후의 모든 아키텍처 결정을 형성했습니다.
벡터 데이터베이스 벤더 평가
2024년 말, 우리는 여러 벡터 데이터베이스 옵션을 평가했고, 최종적으로 세 가지 핵심 요구사항을 기준으로 Milvus를 선택했습니다.
- 첫째, 데이터 프라이버시를 보장하고 인프라를 세밀하게 제어하기 위해 자체 호스팅 솔루션을 우선시했습니다.
- 둘째, 쓰기 중심 워크로드와 버스트성 쿼리 패턴에는 낮고 예측 가능한 지연 시간을 유지하면서 탄력적으로 확장할 수 있는 시스템이 필요했습니다.
- 마지막으로, 우리의 아키텍처에는 수백만 고객 테넌트 전반에 걸친 강력한 격리가 필요했습니다.
Milvus 는 가장 적합한 선택지로 떠올랐습니다. 분산 특성 덕분에 대규모 멀티테넌시를 지원하고 수집, 인덱싱, 쿼리 실행을 독립적으로 확장할 수 있어, 비용을 예측 가능하게 유지하면서 성능을 제공합니다.
아키텍처 설계
기술을 선택한 후, 우리는 Airtable의 고유한 데이터 형태, 즉 서로 다른 고객이 소유한 수백만 개의 개별 “base”를 표현할 아키텍처를 결정해야 했습니다.
파티셔닝 과제
우리는 두 가지 주요 데이터 파티셔닝 전략을 평가했습니다:
옵션 1: 공유 파티션
여러 base가 하나의 파티션을 공유하고, 쿼리는 base id로 필터링하여 범위가 지정됩니다. 이는 리소스 활용도를 향상시키지만, 추가적인 필터링 오버헤드를 도입하고 base 삭제를 더 복잡하게 만듭니다.
옵션 2: 파티션당 하나의 Base
각 Airtable base는 Milvus의 자체 물리 파티션에 매핑됩니다. 이는 강력한 격리를 제공하고, 빠르고 간단한 base 삭제를 가능하게 하며, 쿼리 후 필터링으로 인한 성능 영향을 피합니다.
최종 전략
우리는 단순성과 강력한 격리 때문에 옵션 2를 선택했습니다. 그러나 초기 테스트에서 단일 Milvus collection에 10만 개의 파티션을 생성하면 상당한 성능 저하가 발생한다는 것을 확인했습니다:
- 파티션 생성 지연 시간이 ~20 ms에서 ~250 ms로 증가했습니다
- 파티션 로드 시간이 30초를 초과했습니다
이를 해결하기 위해, 우리는 collection당 파티션 수에 상한을 두었습니다. 각 Milvus cluster마다 400개의 collection을 생성하고, 각 collection은 최대 1,000개의 파티션을 가집니다. 이는 cluster당 총 base 수를 40만 개로 제한하며, 추가 고객이 온보딩되면 새로운 cluster가 프로비저닝됩니다.
인덱싱 및 재현율
인덱스 선택은 우리 시스템에서 가장 중요한 트레이드오프 중 하나로 드러났습니다. 파티션이 로드되면 해당 인덱스는 메모리나 디스크에 캐시됩니다. 재현율, 인덱스 크기, 성능 사이의 균형을 맞추기 위해 여러 인덱스 유형을 벤치마크했습니다.
- IVF-SQ8: 작은 메모리 사용량을 제공했지만 재현율은 낮았습니다.
- HNSW: 최고의 재현율(99%-100%)을 제공하지만 메모리를 많이 사용합니다.
- DiskANN: HNSW와 유사한 재현율을 제공하지만 쿼리 지연 시간이 더 높습니다
궁극적으로, 우리는 뛰어난 재현율과 성능 특성 때문에 HNSW를 선택했습니다.
애플리케이션 계층
상위 수준에서, Airtable의 시맨틱 검색 파이프라인은 두 가지 핵심 흐름으로 구성됩니다:
- 수집 흐름: Airtable row를 embedding으로 변환하고 Milvus에 저장합니다
- 쿼리 흐름: 사용자 쿼리를 embedding하고, 관련 row ID를 검색하며, LLM에 컨텍스트를 제공합니다
두 흐름 모두 규모에 맞게 지속적이고 안정적으로 운영되어야 하며, 아래에서 각각을 살펴보겠습니다. 아래에서 각각을 살펴보겠습니다.
수집 흐름: Milvus를 Airtable과 동기화 상태로 유지하기
사용자가 Omni를 열면, Airtable은 해당 base를 Milvus에 동기화하기 시작합니다. 우리는 파티션을 생성한 다음 row를 청크 단위로 처리하여 embedding을 생성하고 Milvus에 upsert합니다. 그 이후에는 base에 발생한 모든 변경 사항을 캡처하고, 해당 row를 다시 embedding하고 upsert하여 데이터를 일관되게 유지합니다.
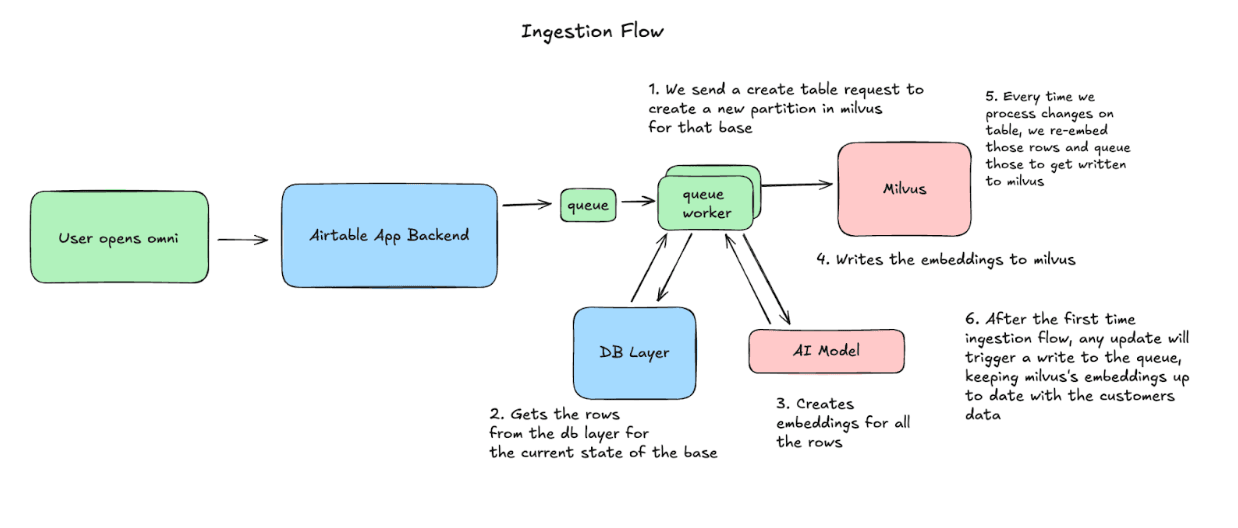
쿼리 흐름: 데이터를 사용하는 방법
쿼리 측면에서는 사용자의 요청을 embedding하고 이를 Milvus로 보내 가장 관련성이 높은 row ID를 검색합니다. 그런 다음 해당 row의 최신 버전을 가져와 LLM에 대한 요청의 컨텍스트로 포함합니다.
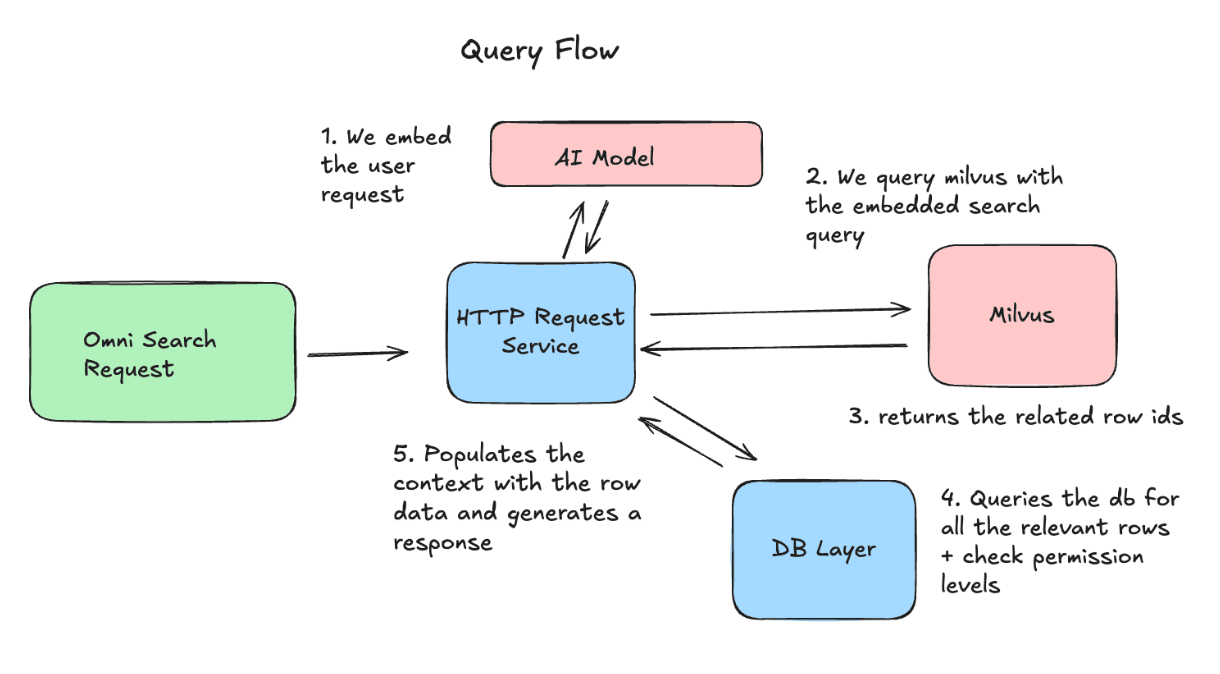
운영상의 과제 및 해결 방법
시맨틱 검색 아키텍처를 구축하는 것도 하나의 과제이지만, 수십만 개의 base에 대해 이를 안정적으로 운영하는 것은 또 다른 과제입니다. 아래는 그 과정에서 우리가 배운 몇 가지 주요 운영상의 교훈입니다.
배포
우리는 Milvus operator를 사용하여 Kubernetes CRD를 통해 Milvus를 배포함으로써 cluster를 선언적으로 정의하고 관리할 수 있게 합니다. 구성 업데이트, 클라이언트 개선, Milvus 업그레이드 등 모든 변경 사항은 사용자에게 롤아웃되기 전에 프로덕션 트래픽을 시뮬레이션하는 단위 테스트와 온디맨드 부하 테스트를 거칩니다.
버전 2.5에서 Milvus cluster는 다음 핵심 구성 요소로 이루어져 있습니다:
- Query Node는 벡터 인덱스를 메모리에 보관하고 벡터 검색을 실행합니다
- Data Node는 수집과 컴팩션을 처리하고 새 데이터를 스토리지에 영구 저장합니다
- Index Node는 데이터가 증가해도 검색 속도를 빠르게 유지하기 위해 벡터 인덱스를 구축하고 유지합니다
- Coordinator Node는 모든 클러스터 활동과 샤드 할당을 오케스트레이션합니다
- Proxy 노드는 API 트래픽을 라우팅하고 노드 전반의 부하를 분산합니다
- Kafka는 내부 메시징과 데이터 흐름을 위한 로그/스트리밍 백본을 제공합니다
- Etcd는 클러스터 메타데이터와 조정 상태를 저장합니다
CRD 기반 자동화와 엄격한 테스트 파이프라인을 통해 업데이트를 빠르고 안전하게 배포할 수 있습니다.
관측 가능성: 시스템 상태를 엔드투엔드로 이해하기
시맨틱 검색이 빠르고 예측 가능하게 유지되도록 시스템을 두 가지 수준에서 모니터링합니다.
인프라 수준에서는 모든 Milvus 구성 요소 전반의 CPU, 메모리 사용량, pod 상태를 추적합니다. 이러한 신호는 클러스터가 안전한 한계 내에서 운영되고 있는지 알려주며, 리소스 포화나 비정상 노드와 같은 문제가 사용자에게 영향을 미치기 전에 포착하는 데 도움이 됩니다.
서비스 계층에서는 각 base가 수집 및 쿼리 워크로드를 얼마나 잘 따라가고 있는지에 집중합니다. 컴팩션 및 인덱싱 처리량과 같은 메트릭은 데이터가 얼마나 효율적으로 수집되고 있는지에 대한 가시성을 제공합니다. 쿼리 성공률과 지연 시간은 사용자가 데이터를 쿼리할 때의 경험을 이해하게 해주며, 파티션 증가는 데이터가 어떻게 증가하고 있는지 알려주므로 확장이 필요한 경우 알림을 받을 수 있습니다.
노드 교체
보안 및 규정 준수상의 이유로 Kubernetes 노드를 정기적으로 교체합니다. 벡터 검색 클러스터에서는 이것이 간단하지 않습니다:
- 쿼리 노드가 교체될 때 coordinator는 쿼리 노드 간의 인메모리 데이터를 재분산합니다
- Kafka와 Etcd는 상태 저장 정보를 저장하며 quorum과 지속적인 가용성이 필요합니다
우리는 엄격한 disruption budget과 한 번에 하나의 노드만 교체하는 정책으로 이를 해결합니다. 다음 노드를 순환하기 전에 Milvus coordinator가 재분산할 시간을 갖도록 합니다. 이러한 신중한 오케스트레이션은 속도를 늦추지 않으면서도 신뢰성을 유지합니다.
콜드 파티션 오프로딩
가장 큰 운영상 성과 중 하나는 데이터에 뚜렷한 hot/cold 접근 패턴이 있다는 점을 인식한 것이었습니다. 사용량을 분석한 결과, Milvus에 있는 데이터 중 특정 주에 쓰기 또는 읽기가 발생하는 것은 약 25%에 불과하다는 사실을 발견했습니다. Milvus를 사용하면 전체 파티션을 오프로드하여 Query Node의 메모리를 확보할 수 있습니다. 해당 데이터가 나중에 필요해지면 몇 초 내에 다시 로드할 수 있습니다. 이를 통해 hot 데이터를 메모리에 유지하고 나머지는 오프로드하여 비용을 줄이고 시간이 지남에 따라 더 효율적으로 확장할 수 있습니다.
데이터 복구
Milvus를 광범위하게 배포하기 전에, 어떤 장애 시나리오에서도 빠르게 복구할 수 있다는 확신이 필요했습니다. 대부분의 문제는 클러스터의 내장 장애 허용 기능으로 처리되지만, 데이터가 손상되거나 시스템이 복구 불가능한 상태에 들어갈 수 있는 드문 경우에도 대비했습니다.
이러한 상황에서 우리의 복구 경로는 간단합니다. 먼저 새로운 Milvus 클러스터를 띄워 거의 즉시 트래픽 서비스를 재개할 수 있도록 합니다. 새 클러스터가 활성화되면 가장 자주 사용되는 base를 선제적으로 다시 임베딩한 다음, 나머지는 접근될 때 지연 처리합니다. 이를 통해 시스템이 일관된 시맨틱 인덱스를 점진적으로 재구축하는 동안 가장 많이 접근되는 데이터의 다운타임을 최소화합니다.
다음 단계
Milvus를 활용한 우리의 작업은 Airtable에서 시맨틱 검색을 위한 강력한 기반을 마련했습니다: 대규모로 빠르고 의미 있는 AI 경험을 구동합니다. 이 시스템이 마련됨에 따라, 이제 제품 전반에서 더 풍부한 검색 파이프라인과 더 깊은 AI 통합을 탐색하고 있습니다. 앞으로 흥미로운 일이 많이 남아 있으며, 우리는 이제 막 시작했습니다.
이 프로젝트에 기여한 Data Infrastructure 및 조직 전반의 모든 전·현직 Airtablets에게 감사드립니다: Alex Sorokin, Andrew Wang, Aria Malkani, Cole Dearmon-Moore, Nabeel Farooqui, Will Powelson, Xiaobing Xia.
Airtable 소개
Airtable는 조직이 맞춤형 앱을 구축하고, 워크플로를 자동화하며, 엔터프라이즈 규모로 공유 데이터를 관리할 수 있게 해주는 선도적인 디지털 운영 플랫폼입니다. 복잡한 교차 기능 프로세스를 지원하도록 설계된 Airtable은 팀이 단일 신뢰 소스를 기반으로 계획, 조정, 실행을 위한 유연한 시스템을 구축하도록 돕습니다. Airtable이 AI 기반 플랫폼을 확장함에 따라, Milvus와 같은 기술은 더 빠르고 스마트한 제품 경험을 제공하는 데 필요한 검색 인프라를 강화하는 데 중요한 역할을 합니다.