




Vector Lakebase: AI 데이터 사일로를 종식하다
모든 AI 팀이 같은 장벽에 부딪힙니다 — 데이터 중력
모든 현대 데이터 팀은 동일한 아키텍처의 어떤 버전인가를 구축해 왔습니다. 레이크하우스 — S3의 Iceberg 테이블, Spark 파이프라인, 거버넌스를 위한 Delta Lake — 가 중심에 자리합니다. 잘 작동합니다. 그러다가 AI 요구사항이 등장합니다.
RAG 파이프라인은 10년 치 엔터프라이즈 문서에 대해 질문에 답해야 하므로, 모든 것을 벡터 데이터베이스로 복사합니다. AI 에이전트는 제품 카탈로그 임베딩에 대한 저지연 접근이 필요합니다 — 또 다른 파이프라인, 또 다른 동기화 작업입니다. 멀티모달 모델 학습에는 10억 개의 이미지 임베딩에 대한 일일 중복 제거가 필요합니다 — 인덱스를 볼 수 없는 Spark 작업입니다.
6개월 후, 두 개가 아니라 다섯 개의 시스템을 갖게 됩니다. 데이터 엔지니어링 팀은 AI 기능을 구축하는 것보다 동기화 파이프라인을 유지 관리하는 데 더 많은 시간을 씁니다. 동일한 데이터셋의 사본이 세 개 있지만 서로 일치한다는 보장은 없습니다. 모든 스키마 변경은 네 곳의 서로 다른 위치로 연쇄적으로 퍼집니다.
이것은 실행의 실패가 아닙니다. 아키텍처의 실패입니다 — 구체적으로, 데이터의 근본적인 속성인 중력과 계속 싸우는 아키텍처의 실패입니다. 먼저 데이터를 복사하도록 요구하는 모든 시스템은 당신에게 중력세를 부과하고 있습니다. 추가하는 AI 워크로드가 많아질수록 — RAG 파이프라인, 에이전트 메모리, 모델 학습, 실시간 추천 — 그 세금은 더 높아집니다.
올바른 해결책은 더 나은 파이프라인이 아닙니다. 새로운 아키텍처 패러다임이어야 합니다: Vector Lakebase.
세 세대의 아키텍처 솔루션, 두 개의 막다른 길
Vector Lakebase의 세부 사항으로 들어가기 전에, 벡터 검색 아키텍처가 데이터 중력 문제를 해결하기 위해 어떻게 진화해 왔는지 살펴볼 가치가 있습니다. 크게 보면, 세 세대의 솔루션이 있었습니다.
1세대: 전용 벡터 데이터베이스
Milvus와 같은 전용 벡터 데이터베이스는 프로덕션 AI 시스템의 실제 문제를 해결했습니다: 범용 데이터베이스가 따라올 수 없는 재현율과 성능을 갖춘 밀리초 지연 시간의 의미 검색입니다. 오픈 소스 Milvus 벡터 데이터베이스의 제작자로서, Zilliz는 임베딩을 저장하고, 인덱스를 구축하며, RAG, 에이전트, 추천 시스템, 의미 검색, 멀티모달 애플리케이션을 위한 저지연 검색을 제공하는 신뢰할 수 있는 고성능 시스템을 구축하는 데 오랫동안 집중해 왔습니다. 그 기반은 여전히 중요합니다. 프로덕션 AI 시스템에는 여전히 데이터베이스 속도의 검색이 필요하며, 벡터 데이터베이스는 많은 지연 시간에 민감한 워크로드에 적합한 서빙 계층으로 남아 있습니다.
그러나 AI 워크로드가 성숙해지면서, 과제는 점점 온라인 서빙을 넘어 확장됩니다. 조직의 원천 데이터 대부분은 이미 객체 스토리지, 데이터 레이크, 레이크하우스, 다운스트림 분석 시스템에 존재합니다. 그 데이터를 전용 벡터 데이터베이스에서 사용하려면, 팀은 일반적으로 별도의 서빙 시스템으로 복사하고, 수집 파이프라인을 구축하며, 동기화 작업을 유지 관리하고, 원천 데이터와 벡터 인덱스 간의 일관성을 관리해야 합니다. 임베딩 모델이 변경되면, 필연적으로 그렇듯이, 팀은 임베딩을 재생성하고, 인덱스를 재구축하며, 여러 시스템을 정렬된 상태로 유지해야 합니다.
이것은 벡터 데이터베이스 성능의 한계가 아닙니다. 데이터 이동으로 인해 만들어진 아키텍처적 경계입니다. 더 많은 팀이 동일한 데이터를 프로덕션 검색, 임베딩 실험, 오프라인 평가, 거버넌스, 계보, 분석에 사용하려 할수록 운영 표면적은 커집니다. 전용 벡터 데이터베이스는 온라인 검색 문제를 매우 잘 해결했지만, 그 자체만으로는 데이터 중력 문제를 제거하지 못합니다.
2세대: Vector Lake
다음의 자연스러운 대응은 벡터 검색을 레이크에 더 가깝게 가져오는 것이었습니다: 벡터를 전용 서빙 시스템으로 먼저 이동하지 않고 Iceberg, Delta Lake 또는 Parquet 파일에서 직접 쿼리하는 것입니다. 동기는 옳았습니다. 데이터가 이미 객체 스토리지나 레이크하우스에 있다면, 검색 가능하게 만들기 위해 왜 다른 곳에 복제해야 할까요?
하지만 실제로 벡터 레이크 아키텍처는 세 가지 이유로 프로덕션 AI 워크로드에 아직 완전하지 않습니다.
첫째, 저지연 서빙을 위해 설계되지 않았습니다. 대부분의 벡터 레이크 접근 방식은 필요할 때 객체 스토리지에서 데이터나 인덱스를 로드하며, 동시적이고 지연 시간에 민감한 요청 처리보다는 유연성에 더 최적화되어 있습니다. 오프라인 탐색에는 괜찮을 수 있지만, 사용자 대면 RAG, 에이전트, 추천 또는 검색 애플리케이션에는 충분하지 않습니다. 검색 파이프라인이 LLM 호출의 핵심 경로에 위치할 때, 팀은 높은 동시성에서 예측 가능한 100ms 미만의 지연 시간이 필요합니다. p99 지연 시간이 정기적으로 초 단위로 밀려난다면, 그 시스템은 분석에는 여전히 유용할 수 있지만 프로덕션 검색 계층으로 기능할 수는 없습니다.
둘째, 벡터 레이크 시스템은 일반적으로 검색 단계에서 멈춥니다. 팀이 레이크의 벡터 데이터를 쿼리할 수 있게 해주지만, AI 데이터 워크플로를 위한 더 넓은 실행 환경은 제공하지 않습니다. 현대 AI 시스템에는 최근접 이웃 검색 이상의 것이 필요합니다. 임베딩을 재생성하고, 검색 품질을 평가하고, 에이전트 메모리를 압축하고, 비디오에서 프레임을 추출하고, 멀티모달 데이터를 처리하고, 메타데이터를 관리하며, 파인튜닝 또는 다운스트림 파이프라인을 위한 데이터를 준비해야 합니다. 레이크 파일 위에 검색만 추가하는 시스템은 벡터 및 멀티모달 데이터의 전체 수명 주기를 해결하지 못합니다.
셋째, 기반 스토리지 계층이 이 워크로드를 위해 만들어지지 않았습니다. Iceberg와 Delta Lake는 구조화된 분석 데이터를 위해 설계되었습니다 — 네이티브 벡터 타입도 없고, 인덱스 구조도 없으며, 모든 쿼리는 전체 스캔입니다. AI 워크로드에는 빠른 포인트 룩업(Parquet의 순차적 row-group 스캔이 아니라 — Vortex와 Lance 같은 포맷이 존재하는 이유입니다), 데이터와 함께 공동 관리되는 내장 인덱스, 그리고 이미지, 오디오, 비디오가 blob으로 인라인되는 것이 아니라 참조로 연결되는 참조 기반 비정형 데이터 관리가 필요합니다. 오늘날 레이크에는 이 중 어느 것도 존재하지 않습니다. Iceberg 위에 구축된 Vector Lake는 모든 수준에서 스토리지 계층과 싸우고 있습니다.
Generation 3: Vector Lakebase
Vector Lakebase는 레이크와 벡터 데이터베이스를 동기화해야 하는 별개의 시스템으로 취급하는 것을 멈추고, 단일 통합 계층의 두 가지 운영 모드로 구축하기 시작할 때 얻게 되는 것입니다. 더 구체적으로 말하면:
벡터 레이크베이스는 벡터 데이터베이스 시스템에서 진화한 새로운 AI 네이티브 및 레이크 네이티브 아키텍처입니다. 벡터 데이터베이스의 높은 QPS, 저지연 서빙 기능과 멀티모달 데이터 레이크의 개방성, 확장성, 비용 효율성을 결합하는 동시에, 데이터 마이그레이션 없이 모든 워크로드를 동일한 단일 진실 공급원에 유지합니다. 컴퓨트와 스토리지를 분리함으로써, 벡터 레이크베이스는 오픈 포맷을 사용해 저비용 객체 스토리지에 멀티모달 데이터, 벡터, 속성, 인덱스, 메타데이터를 직접 저장합니다. 그런 다음 서빙, 발견, 분석 워크로드는 동일한 데이터 위에서 독립적으로 실행될 수 있습니다.
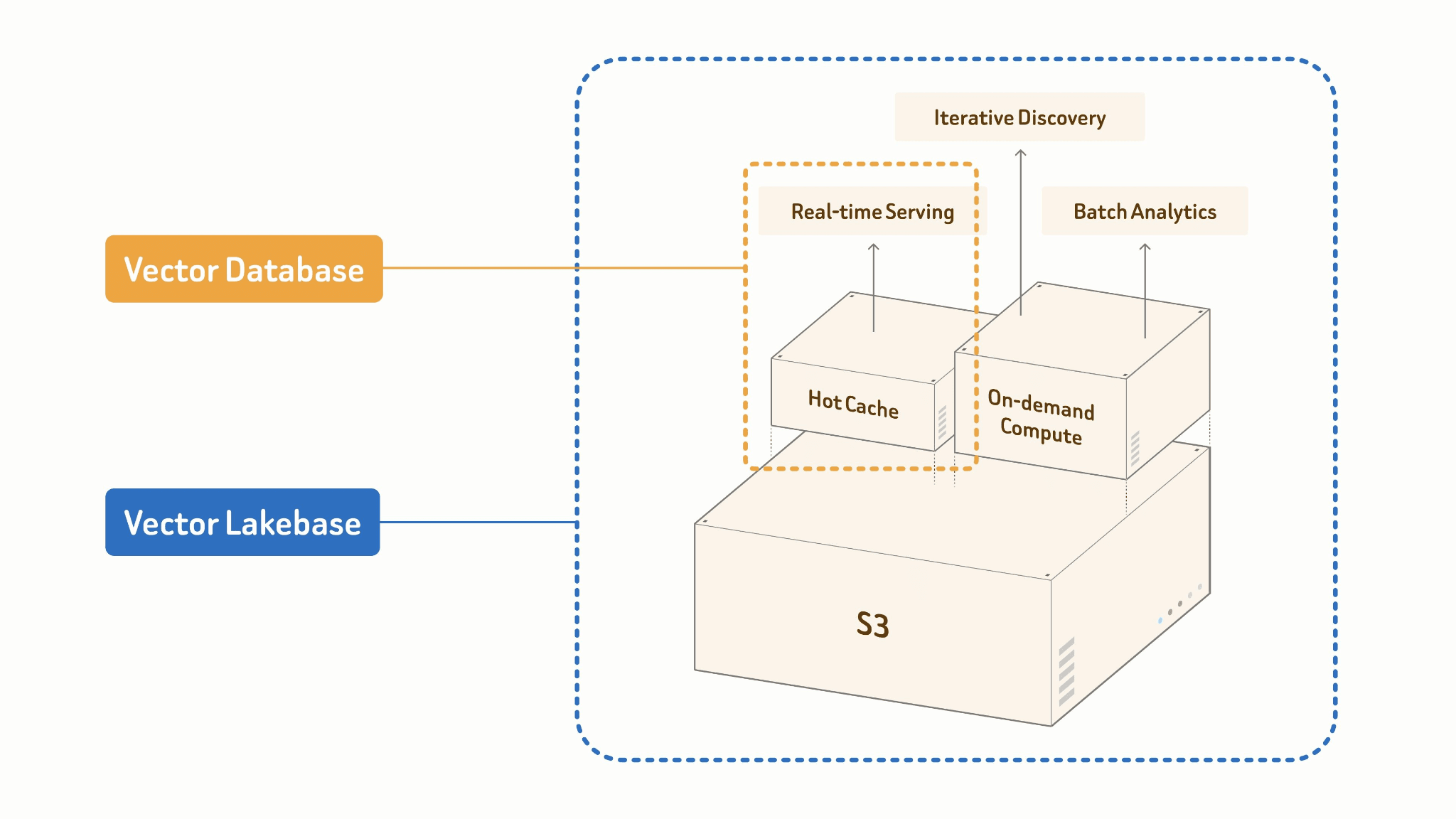
핵심 원칙: 단일 진실 공급원.
레이크 테이블이 단일 진실 공급원입니다. 온라인 서빙과 오프라인 배치 처리는 동일한 데이터, 인덱스, 스키마를 공유합니다. 둘 사이에 파이프라인이 없는 이유는 둘 사이에 경계가 없기 때문입니다.
Vector DB: [Lake] ──ETL──▶ [Vector DB] # duplication + staleness
Vector Lake: [Lake + Index] ◀── batch query only # no serving, no processing
Vector Lakebase: [Lake + Index + Compute]
├── Online: Cache + High-performance Index
│ → ANN query, <100ms p99 serving
└── Offline: Batch Processing + Cost-efficient Index Build
→ embed, cluster, dedup, feature engineering
두 가지 모드는 필연적으로 다르게 설계됩니다. 온라인 서빙은 핫 캐시와 고성능 인메모리 인덱스를 기반으로 실행되며 — 동시성과 tail latency에 최적화되어 있습니다. 오프라인 배치 작업은 대규모로 비용 효율적으로 인덱스를 구축합니다: 컬럼형 스캔, GPU 가속 구축, 레이크로의 단계적 쓰기. 동일한 데이터, 동일한 인덱스 형식이지만, 컴퓨팅 프로파일은 근본적으로 다릅니다.
실제로는 어떤 모습일까요? 10억 벡터 Iceberg 테이블에서:
| 모드 | 지연 시간 | 컨텍스트 |
|---|---|---|
| Spark 브루트포스 스캔 (인덱스 없음) | 몇 시간 | 오늘날 레이크 기반 벡터 검색의 기본값 |
| Vector Lakebase — 콜드 (인덱스 방금 구축됨) | ~30초 | Iceberg에서 ~20분 만에 인덱스 구축 |
| Vector Lakebase — 웜 (디스크 캐시) | 두 자릿수 ms | 로컬 SSD에 인덱스 캐시됨 |
| Vector Lakebase — 핫 (인메모리) | 한 자릿수 ms | 프로덕션 RAG 및 에이전트 서빙 |
| Vector Lakebase — 클러스터링 / 중복 제거 | 몇 시간 | 10억 벡터 KMeans 또는 근사 중복 탐지, 완전 분산 처리 |
몇 시간에서 한 자릿수 밀리초로 단축됩니다 — 그리고 데이터를 레이크 밖으로 복사할 필요가 전혀 없습니다.
이것은 제품 선택의 문제가 아닙니다. AI 데이터 아키텍처가 수렴해 가는 방향입니다. 데이터가 두 곳에 존재해야 하는 모든 시스템은 스토리지, 엔지니어링 시간, 최신성 저하 측면에서 영구적인 세금을 부과합니다. 스토리지와 AI 운영을 분리하는 시스템은 시간이 지나면 과도기적인 것으로 보이게 될 것입니다.
Vector Lakebase가 실제로 가능하게 하는 것
이전에는 별도의 시스템이 필요했던 최소 세 가지 유형의 워크로드를 이제 vector lakebase로 처리할 수 있습니다.
외부 컬렉션: 아무것도 이동하지 않고 레이크를 검색 가능하게 만들기
S3의 Parquet 파일에 페타바이트 규모의 임베딩이 있다고 가정해 보겠습니다. 오늘날 새로운 RAG 애플리케이션을 위해 이를 검색 가능하게 만들려면 벡터 데이터베이스로 로드해야 합니다 — 며칠 또는 몇 주가 걸리는 마이그레이션에 더해 지속적인 동기화 의무가 발생합니다.
Vector Lakebase의 external collections는 데이터 중력에 맞서기보다 이를 활용합니다. 버킷을 지정하고, 기존 컬럼에 대한 스키마 매핑을 정의한 뒤, 그 자리에서 벡터 인덱스를 구축합니다. 데이터는 S3에 그대로 남아 있습니다. 인덱스도 S3에 다시 영속화됩니다. 소스 데이터가 업데이트되면 증분 방식으로 새로 고칩니다 — 변경된 파일만 재처리됩니다.
# 1. Register your existing lake data as an external collection
client.create_external_collection(
collection_name="enterprise_docs",
src="s3://my-lake/docs/*.parquet", # point at your existing data
schema={"text": String, "embedding": FloatVector(768)},
)
# 2. Build a vector index — data stays in S3, index persists back to S3
client.create_index("enterprise_docs", field="embedding", index_type="HNSW")
# ~20 min for 1B vectors. Data never moves.
# 3. Search — single-digit ms with in-memory cache
results = client.search(
collection_name="enterprise_docs",
data=[query_embedding],
top_k=10,
output_fields=["text"],
)
마이그레이션도, 파이프라인도, 새로운 스토리지 비용도 없습니다. RAG 시스템은 분석 팀이 이미 거버넌스하는 동일한 데이터를 쿼리합니다 — Spark, Ray, LangChain, PyMilvus 또는 REST API를 통해서 말입니다. 인덱스는 테이블의 일급 속성이 되며, 옆에 덧붙여진 외부 시스템이 아닙니다.
ETL, 피처 엔지니어링, 컨텍스트 엔지니어링
이것은 Vector Database와 Vector Lake가 모두 무시하는 워크로드입니다 — 그리고 AI 데이터 스택에서 가장 중요한 부분이 되어 가고 있습니다.
AI 네이티브 데이터 운영은 단지 시스템 간에 데이터를 이동하는 것이 아니라 — 그 자리에서, 대규모로, 의미론적 의미를 부여해 데이터를 풍부하게 만듭니다:
- 기존 테이블에 임베딩 컬럼 추가: 1억 개 행 전체에 대해 배치 추론을 수행하고, 결과를 같은 테이블에 다시 기록.
- RAG를 위해 문서 코퍼스를 청크화하되, 원문 문서와 청크를 함께 버전 관리.
- text-embedding-3-small에서 더 새로운 모델로 업그레이드 — 5억 개 벡터 전체를 제자리에서 백필하고, 전환할 때까지 기존 임베딩과 새 임베딩이 공존.
- AI 에이전트가 런타임에 검색하는 컨텍스트 패키지를 구축하고 버전 관리 — 무엇이 검색되는지, 어떻게 구조화되는지, 컨텍스트 윈도우에 맞게 어떻게 압축되는지.
모델이 상품화될수록, 어떤 모델을 선택하느냐보다 그 모델에 무엇을 먹이느냐 의 품질이 더 중요해집니다. 이 새롭게 부상하는 분야 — Context Engineering — 는 레이크 안에 있어야 합니다: 데이터와 가까이, 데이터와 함께 버전 관리되고, 엔드투엔드로 재현 가능하게. Vector Lakebase는 이를 cron 작업으로 엮어 붙인 임시 스크립트가 아니라, 일급 작업으로 만듭니다.
클러스터링, 중복 제거, 이상 탐지
자체 모델을 학습하거나 파인튜닝하는 모든 팀에 필수적이지만 — 벡터 데이터베이스 패러다임에는 완전히 빠져 있는 기능입니다:
- 중복 제거: LLM 파인튜닝 데이터셋의 근접 중복 예시는 학습 손실을 부풀리고 모델 동작에 편향을 만듭니다. 근접 중복을 식별하고, 표준 세트를 내보내며, 중복 제거 라벨을 컬럼으로 다시 기록합니다.
- 클러스터링: 학습 전에 데이터셋이 실제로 무엇을 포함하는지 이해합니다. 임베딩 공간을 클러스터링하면 — "다양한" 데이터셋의 40%가 동일한 몇 가지 주제의 사소한 변형이라는 사실을 자주 발견하게 됩니다.
- 이상 탐지: 자율주행차, 로보틱스, 또는 어떤 안전 필수 모델이든 — 나머지와 전혀 닮지 않은 0.1%의 샘플을 찾아냅니다. 이를 플래그하고, 라벨링 우선순위를 높이며, 학습에 포함합니다. 인덱스 없이는 찾을 수 없고, 결과를 레이크에 다시 쓰지 않고서는 조치를 취할 수 없습니다.
Vector Lakebase는 이를 일급 분산 작업으로 다룹니다: 인덱스를 인식하고, 데이터가 있는 곳에서 병렬화되며, 오픈 포맷으로 결과를 기록합니다. 중복 제거 실행의 출력은 같은 테이블의 컬럼이 됩니다.
이미 이를 기반으로 구축 중인 곳
Vector Lakebase의 초기 설계 파트너들은 대규모에서 가장 어려운 AI 데이터 문제 두 가지에 걸쳐 있습니다.
선도적인 자율주행 및 EV 기업들은 수십억 개의 주행 장면 임베딩에서 코너 케이스를 채굴하는 데 이를 사용합니다 — 자율주행 시스템이 안전한지를 결정하는 드문 도로 시나리오들입니다. 한 최상위 foundation model 기업은 사전 학습 코퍼스 전반의 근접 중복 탐지에 이를 사용합니다 — 단 한 시간의 GPU 학습 시간을 쓰기 전에 수십억 개 예시를 중복 제거하여 모델 품질을 개선합니다.
이미 Databricks Lakebase가 있습니다. 또 하나가 필요할까요?
타당한 질문이며, 답하려면 Databricks Lakebase가 실제로 무엇인지 이해해야 합니다.
Databricks Lakebase — Neon 인수를 기반으로 구축 — 는 서버리스 PostgreSQL 엔진을 Databricks 플랫폼에 통합합니다. 이것이 해결하는 문제는: OLTP와 OLAP가 항상 별도 시스템이었다는 점입니다. Databricks는 그 경계를 허물고 있습니다. 이는 해결할 가치가 있는 실제 문제입니다. 하지만 근본적으로 다른 문제입니다.
| Databricks Lakebase | Vector Lakebase | |
|---|---|---|
| 주요 사용자 | 백엔드 엔지니어, 데이터 엔지니어 | ML 엔지니어, AI 플랫폼 팀 |
| 주요 데이터 | 행, 계정, 트랜잭션 | 임베딩, 문서, 멀티모달 |
| 스토리지 모델 | Postgres 스토리지 + Delta Lake (분리) | 단일 레이크 테이블, 통합 |
| 배치 임베딩 / 중복 제거 | 범위 외 | 일급 작업 |
| Context Engineering | 범위 외 | 핵심 역량 |
| 기존 레이크 기반 구축 | 부분적 | 예 — 마이그레이션 없음 |
| 포맷 최적화 | Delta Lake, Parquet | Parquet, Vortex, Lance, Apache Iceberg, 네이티브 비정형 데이터 |
| OLTP (트랜잭션) | ✓ | N/A |
Databricks Lakebase는 OLTP/OLAP 경계를 허뭅니다. Vector Lakebase는 AI 데이터가 존재하는 곳과 AI 작업이 실행되는 곳 사이의 경계를 허뭅니다. 이 둘은 경쟁 관계가 아니라 상호 보완적입니다. 많은 팀이 둘 다 사용할 것입니다.
아키텍처적 베팅
2013년, Databricks는 물었습니다: SQL 분석이 레이크 안에 있다면 어떨까? 그 질문의 가치는 $400억이었습니다.
다음 질문은 이것입니다: AI 네이티브 데이터 운영 — RAG 검색, 에이전트 메모리, 배치 임베딩, 모델 학습 데이터 큐레이션, 컨텍스트 엔지니어링 — 도 레이크 안에 있다면 어떨까?
이것이 Vector Lakebase의 베팅입니다. 마이그레이션해야 하는 새로운 데이터베이스가 아닙니다. 기존 레이크에 덧붙인 쿼리 계층도 아닙니다. 데이터가 한 번만 존재하고, 한 번만 인덱싱되며, 모든 AI 워크로드를 지원하는 통합 기반입니다 — 중복 없이, ETL 오버헤드 없이, 데이터 중력과 싸우지 않고.
AI 경쟁은 속도에 보상합니다. 팀이 동기화 파이프라인을 구축하고, 오래된 데이터를 디버깅하거나, 시스템 간 마이그레이션에 쓰는 매주가 경쟁사에게는 AI 기능을 출시하는 한 주입니다. 인프라는 병목이 아니라 가속기가 되어야 합니다. 승리하는 팀은 최고의 모델을 가진 팀이 아닙니다 — 데이터와 AI 사이의 마찰을 제거한 팀입니다.
기존 Iceberg 테이블 또는 데이터 레이크 위에 구축하세요. 마이그레이션 없음. 중복 없음. 빠르게 움직이세요 — 데이터는 제자리에 머물면서 몇 분 만에 검색 가능하고, 처리 가능하며, AI 준비 상태가 됩니다.
그것이 Vector Lakebase입니다.
Zilliz Vector Lakebase가 공개 프리뷰로 제공됩니다
우리는 Zilliz Vector Lakebase의 공개 프리뷰를 출시했습니다 — Zilliz Cloud가 관리형 벡터 데이터베이스에서 통합 시맨틱 데이터 플랫폼으로 크게 진화한 것으로, 저지연 벡터 서빙과 데이터 레이크의 개방성, 확장성, 경제성을 결합합니다.
Zilliz Vector Lakebase의 핵심 기능:
- 다양한 실시간 성능-비용 트레이드오프에 최적화된 계층형 서빙
- 상시 가동 컴퓨트 없이 대규모 또는 탐색형 워크로드를 위한 온디맨드 검색
- 외부 데이터 레이크 검색 — 기존 레이크 데이터 위에서 직접 인덱싱하고 검색
- 하이브리드 검색 및 리랭킹을 통한 벡터, 텍스트, JSON, 지리공간 데이터 전반의 풀 스펙트럼 검색
- Lance 또는 Parquet보다 더 빠르고 저렴한 랜덤 읽기를 제공하는 오픈 포맷 Vortex 기반의 통합 레이크 네이티브 스토리지
현재 스택이 서빙과 디스커버리를 별도 시스템으로 분리하고 있다면, Vector Lakebase를 살펴볼 가치가 있을 수 있습니다. Zilliz Cloud에서 사용해 보세요 — 업무용 이메일로 새로 가입하면 $100 무료 크레딧을 받을 수 있습니다 — 또는 사용 사례에 대해 문의하세요.

계속 읽기

Milvus 2.6.x Now Generally Available on Zilliz Cloud, Making Vector Search Faster, Smarter, and More Cost-Efficient for Production AI
Milvus 2.6.x is now GA on Zilliz Cloud, delivering faster vector search, smarter hybrid queries, and lower costs for production RAG and AI applications.

Will Amazon S3 Vectors Kill Vector Databases—or Save Them?
AWS S3 Vectors aims for 90% cost savings for vector storage. But will it kill vectordbs like Milvus? A deep dive into costs, limits, and the future of tiered storage.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.