




올라마, 라마 3.2, 밀버스로 함수 호출하기
*2024년 9월 25일 Llama 3.2.2로 업데이트됨
LLM으로 함수를 호출하는 것은 AI에 세상과 연결할 수 있는 힘을 부여하는 것과 같습니다. LLM을 사용자 정의 함수나 API와 같은 외부 도구와 통합하면 실제 문제를 해결하는 애플리케이션을 구축할 수 있습니다.
이 블로그 게시물에서는 Llama 3.2를 Milvus 및 API와 같은 외부 도구와 통합하여 강력한 컨텍스트 인식 애플리케이션을 구축하는 방법을 살펴봅니다.
함수 호출 소개
이제 GPT-4, 미스트랄 네모, 라마 3.2와 같은 LLM은 함수를 호출해야 하는 시점을 감지한 다음 해당 함수를 호출하기 위한 인수가 포함된 JSON을 출력할 수 있습니다. 이를 통해 AI 애플리케이션을 더욱 다양하고 강력하게 만들 수 있습니다.
함수 호출을 통해 개발자가 만들 수 있습니다:
데이터 추출 및 태깅을 위한 LLM 기반 솔루션(예: Wikipedia 문서에서 사람 이름 추출)
자연어를 API 호출 또는 유효한 데이터베이스 쿼리로 변환하는 데 도움이 되는 애플리케이션
지식 기반과 상호 작용하는 대화형 지식 검색 엔진
도구
올라마**: LLM의 강력한 기능을 노트북으로 가져와 로컬 작업을 간소화합니다.
밀버스**: 효율적인 데이터 저장 및 검색을 위한 벡터 데이터베이스입니다.
라마 3.2-3B**: 3.1 모델의 업그레이드 버전으로, 다국어를 지원하며 컨텍스트 길이가 128K로 훨씬 길어지고 도구 사용을 활용할 수 있습니다.
라마 3.2 및 올라마 사용하기
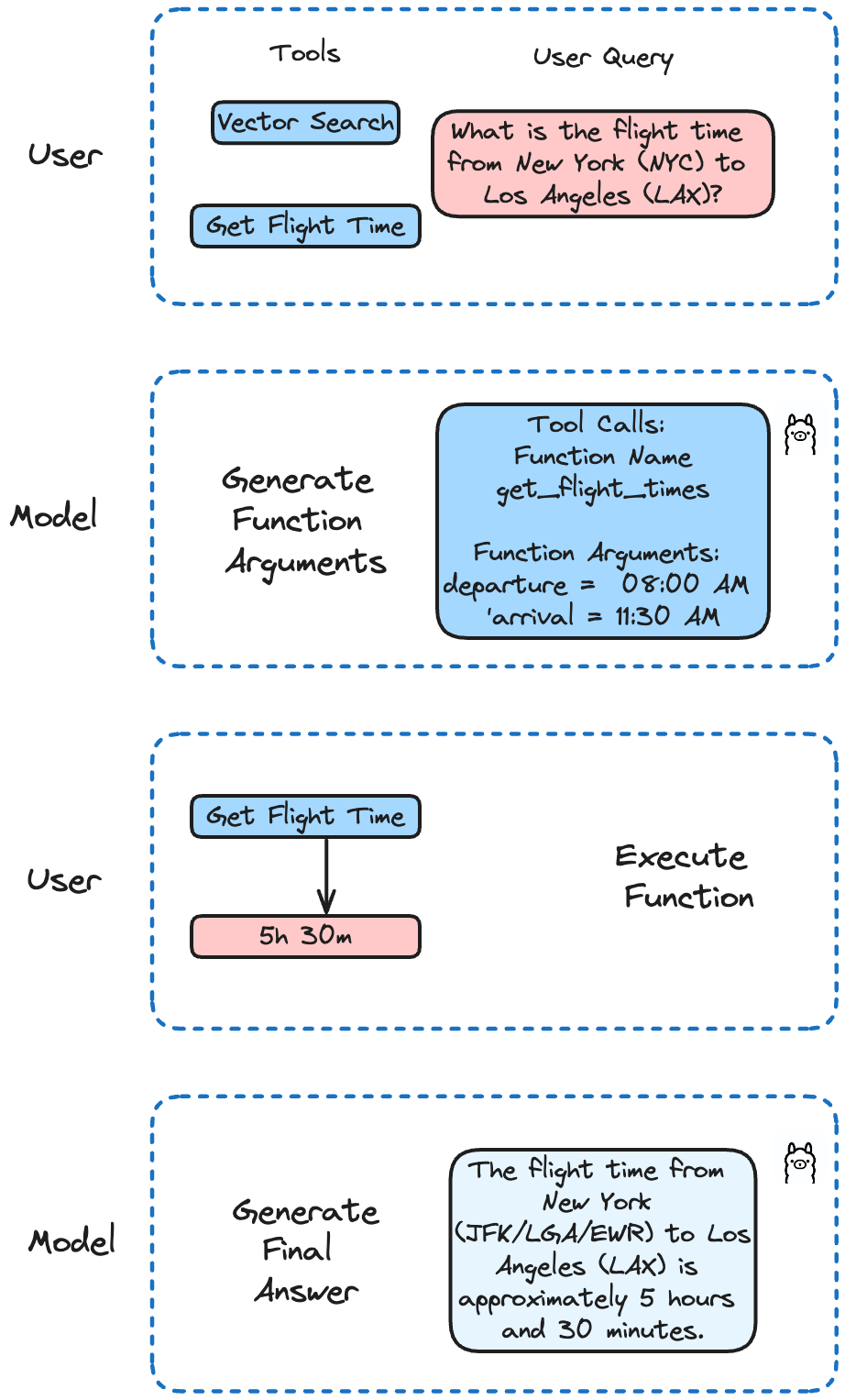
Llama 3.2는 함수 호출에 대한 미세 조정이 이루어졌습니다. 단일, 중첩, 병렬 함수 호출은 물론 다중 턴 함수 호출도 지원합니다. 즉, 여러 단계 또는 병렬 프로세스가 포함된 복잡한 작업을 AI가 처리할 수 있습니다.
이 예제에서는 Milvus에서 비행 시간을 얻고 검색을 수행하기 위한 API 호출을 시뮬레이션하기 위해 다양한 함수를 구현해 보겠습니다. Llama 3.2는 사용자의 쿼리에 따라 어떤 함수를 호출할지 결정합니다.
설치 종속성
먼저 모든 것을 설정해 봅시다. Ollama를 사용하여 Llama 3.2를 다운로드합니다:
올라마 실행 라마3.2
그러면 모델이 노트북에 다운로드되어 Ollama에서 사용할 준비가 됩니다. 다음으로 필요한 종속성을 설치합니다:
파이프 인스톨 올라마 오픈AI "파이밀버스[모델]"
Milvus에서 사용 가능한 모델을 사용하여 데이터를 임베드할 수 있는 모델 확장 기능이 있는 Milvus Lite를 설치합니다.
Milvus에 데이터 삽입
이제 Milvus에 데이터를 삽입해 보겠습니다. 이 데이터는 나중에 Llama 3.2가 관련성이 있다고 판단되면 검색하기로 결정할 데이터입니다!
데이터 생성 및 삽입
pymilvus에서 MilvusClient, model을 가져옵니다.
embedding_fn = model.DefaultEmbeddingFunction()
docs = [
"인공 지능은 1956년에 학문 분야로 설립되었습니다.",
"앨런 튜링은 인공지능에 대해 실질적인 연구를 수행한 최초의 인물입니다.",
"런던의 메이다 베일에서 태어난 튜링은 영국 남부에서 자랐습니다.",
]
벡터 = embedding_fn.encode_documents(docs)
# 출력 벡터는 방금 만든 컬렉션과 일치하는 768개의 차원을 가집니다.
print("Dim:", embedding_fn.dim, vectors[0].shape) # Dim: 768 (768,)
# 각 엔티티에는 ID, 벡터 표현, 원시 텍스트 및 제목 레이블이 있습니다.
data = [
{"id": i, "vector": vectors[i], "text": docs[i], "subject": "history"}
for i in range(len(vectors))
]
print("데이터에는", len(data), "엔티티, 각각 필드가 있습니다: ", data[0].keys())
print("벡터 dim:", len(data[0]["vector"]))
# 컬렉션을 생성하고 데이터를 삽입합니다.
client = MilvusClient('./milvus_local.db')
client.create_collection(
collection_name="demo_collection",
dimension=768, # 이 데모에서 사용할 벡터는 768개의 차원을 가집니다.
)
client.insert(collection_name="demo_collection", data=data)
그러면 새 컬렉션에 3개의 요소가 있어야 합니다.
사용할 함수 정의
이 예제에서는 두 개의 함수를 정의합니다. 첫 번째 함수는 비행 시간을 얻기 위한 API 호출을 시뮬레이션합니다. 두 번째 함수는 Milvus에서 검색 쿼리를 실행합니다.
pymilvus에서 모델 가져오기
import json
import ollama
embedding_fn = model.DefaultEmbeddingFunction()
# 비행 시간을 얻기 위한 API 호출을 시뮬레이션합니다.
# 실제 애플리케이션에서는 라이브 데이터베이스 또는 API에서 데이터를 가져옵니다.
def get_flight_times(출발: str, 도착: str) -> str:
flights = {
'NYC-LAX': {'출발': '08:00 AM', '도착': '11:30 AM', 'duration': '5h 30m'},
'LAX-NYC': {'출발': '오후 02:00', '도착': '오후 10:30', '지속시간': '5시간 30분'},
'LHR-JFK': {'출발': '10:00 AM', '도착': '01:00 PM', '지속시간': '8시간 00분'},
'JFK-LHR': {'출발': '09:00 PM', '도착': '09:00 AM', '지속시간': '7시간 00분'},
'CDG-DXB': {'출발': '11:00 AM', '도착': '08:00 PM', '지속시간': '6시간 00분'},
'DXB-CDG': {'출발': '03:00 AM', '도착': '07:30 AM', 'duration': '7h 30m'},
}
key = f'{출발}-{도착}'.upper()
return json.dumps(flights.get(key, {'error': '항공편을 찾을 수 없음'}))
# 벡터 데이터베이스에서 인공지능 관련 데이터 검색하기
def search_data_in_vector_db(query: str) -> str:
query_vectors = embedding_fn.encode_queries([query])
res = client.search(
collection_name="demo_collection",
data=query_vectors,
limit=2,
output_fields=["text", "subject"], # 반환할 필드 지정
)
print(res)
return json.dumps(res)
해당 함수를 사용할 수 있도록 LLM에 지침을 제공하세요.
이제 우리가 정의한 함수를 사용할 수 있도록 LLM에 인스트럭션을 전달해 봅시다.
def run(model: str, question: str):
client = ollama.Client()
# 사용자 쿼리로 대화 초기화하기
messages = [{"role": "user", "content": question}]
# 첫 번째 API 호출: 쿼리와 함수 설명을 모델에 전송합니다.
response = client.chat(
모델=모델,
messages=메시지,
tools=[
{
"type": "function",
"function": {
"name": "get_flight_times",
"설명": "두 도시 사이의 비행 시간을 가져옵니다.",
"매개변수": {
"type": "객체",
"속성": {
"출발": {
"type": "문자열",
"설명": "출발 도시(공항 코드)",
},
"도착": {
"type": "문자열",
"설명": "도착 도시(공항 코드)",
},
},
"필수": ["출발", "도착"],
},
},
},
{
"type": "function",
"function": {
"name": "search_data_in_vector_db",
"설명": "벡터 데이터베이스에서 인공 지능 데이터에 대한 검색",
"매개변수": {
"type": "객체",
"속성": {
"query": {
"type": "문자열",
"설명": "검색 쿼리",
},
},
"필수": ["쿼리"],
},
},
},
],
)
# 대화 기록에 모델의 응답을 추가합니다.
messages.append(response["message"])
# 모델이 제공된 함수를 사용하기로 결정했는지 확인합니다.
if not response["message"].get("tool_calls"):
print("모델이 함수를 사용하지 않았습니다. 응답은 다음과 같습니다.")
print(response["message"]["content"])
반환
# 모델이 호출한 함수 처리
if response["message"].get("tool_calls"):
available_functions = {
"get_flight_times": get_flight_times,
"SEARCH_DATA_IN_VECTOR_DB": SEARCH_DATA_IN_VECTOR_DB,
}
응답["메시지"]["tool_calls"]의 도구에 대해:
function_to_call = available_functions[tool["function"]["name"]]
function_args = tool["function"]["arguments"]
function_response = function_to_call(**function_args)
# 대화에 함수 응답 추가
messages.append(
{
"role": "tool",
"content": function_response,
}
)
# 두 번째 API 호출: 모델로부터 최종 응답 가져오기
final_response = client.chat(모델=모델, 메시지=메시지)
print(final_response["message"]["content"])
사용 예
특정 항공편의 시간을 확인할 수 있는지 확인해 보겠습니다:
question = "뉴욕(NYC)에서 로스앤젤레스(LAX)까지 비행 시간이 어떻게 되나요?"
run('llama3.2', question)
결과는 다음과 같습니다:
뉴욕(JFK/LGA/EWR)에서 로스앤젤레스(LAX)까지의 비행 시간은 약 5시간 30분입니다. 그러나 이 시간은 항공사, 항공편 일정 및 경유지 또는 지연 가능성에 따라 달라질 수 있습니다. 가장 최신의 정확한 항공편 정보는 항상 이용하시는 항공사에 확인하시기 바랍니다.
이제 Llama 3.2가 Milvus를 사용하여 벡터 검색을 수행할 수 있는지 확인해 보겠습니다.
question = "인공 지능은 언제 설립되었나요?"
run("llama3.2", question)
밀버스 검색을 반환합니다:
데이터: ["[{'id': 0, 'distance': 0.5738513469696045, 'entity': {'text': '인공 지능은 1956년에 학문으로 설립되었습니다.', 'subject': 'history'}}, {'id': 1, 'distance': 0.4090226888656616, '엔티티': {'text': '앨런 튜링은 인공지능 분야에서 실질적인 연구를 수행한 최초의 인물입니다.', 'subject': 'history'}}]"]
인공 지능은 1956년에 학문 분야로 설립되었습니다.
결론
LLM을 사용한 함수 호출은 가능성의 세계를 열어줍니다. Llama 3.2를 Milvus 및 API와 같은 외부 도구와 통합하면 특정 사용 사례와 실제 문제에 맞는 강력한 컨텍스트 인식 애플리케이션을 구축할 수 있습니다.
Milvus](https://zilliz.com/what-is-milvus), Github에서 코드를 확인하고, Discord에 가입하여 커뮤니티와 경험을 공유해 주세요.

계속 읽기

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.

1 Table = 1000 Words? Foundation Models for Tabular Data
TableGPT2 automates tabular data insights, overcoming schema variability, while Milvus accelerates vector search for efficient, scalable decision-making.