




Milvus, vLLM, Llama 3.1로 RAG 구축하기
캘리포니아 대학교 버클리 캠퍼스에서는 2024년 7월 인큐베이션 단계의 프로젝트로 LLM 추론 및 서빙을 위한 빠르고 사용하기 쉬운 라이브러리인 vLLM을 LF AI & Data Foundation에 기증했습니다. 동료 멤버 프로젝트로서 LF AI & Data의 가족이 된 vLLM을 환영합니다! 🎉
대규모 언어 모델(LLM)과 벡터 데이터베이스는 일반적으로 AI 환각을 해결하기 위해 널리 사용되는 AI 애플리케이션 아키텍처인 검색 증강 생성(RAG)을 구축하기 위해 짝을 이룹니다. 이 블로그에서는 Milvus, vLLM 및 Llama 3.1을 사용하여 RAG를 구축하고 실행하는 방법을 보여드리겠습니다. 좀 더 구체적으로 Milvus에서 텍스트 정보를 벡터 임베딩으로 임베딩하여 저장하고, 이 벡터 저장소를 지식 베이스로 사용하여 사용자 질문과 관련된 텍스트 청크를 효율적으로 검색하는 방법을 보여드리겠습니다. 마지막으로, 검색된 텍스트로 증강된 답변을 생성하기 위해 Meta의 Llama 3.1-8B 모델을 제공하는 데 vLLM을 활용합니다. 시작해 보겠습니다!
Milvus, vLLM 및 Meta의 Llama 3.1 소개
Milvus 벡터 데이터베이스
Milvus**는 생성형 AI(GenAI) 워크로드를 위한 벡터를 저장, 색인 및 검색하기 위한 오픈 소스 전용 분산형 벡터 데이터베이스입니다. 하이브리드 검색,](https://zilliz.com/blog/a-review-of-hybrid-search-in-milvus) 메타데이터 필터링, 재랭킹을 수행하고 수조 개의 벡터를 효율적으로 처리할 수 있는 Milvus는 AI 및 머신 러닝 워크로드를 위한 최고의 선택입니다. Milvus는 로컬, 클러스터에서 실행하거나 완전 관리형 Zilliz Cloud에서 호스팅할 수 있습니다.
vLLM
vLLM**은 UC 버클리 스카이랩에서 시작된 오픈 소스 프로젝트로, LLM 서비스 성능 최적화에 중점을 두고 있습니다. PagedAttention, 연속 배칭, 최적화된 CUDA 커널을 통한 효율적인 메모리 관리를 사용합니다. 기존 방식에 비해 vLLM은 GPU 메모리 사용량을 절반으로 줄이면서 서빙 성능을 최대 24배까지 향상시킵니다.
논문 "페이지어텐션으로 대규모 언어 모델 서비스를 위한 효율적인 메모리 관리에 따르면 KV 캐시는 GPU 메모리의 약 30%를 사용하므로 잠재적인 메모리 문제가 발생할 수 있습니다. KV 캐시는 인접 메모리에 저장되지만 크기가 변경되면 메모리 조각화가 발생하여 계산에 비효율적일 수 있습니다.

이미지 1. 기존 시스템에서의 KV 캐시 메모리 관리(2023년 페이징 주의 페이퍼)_
KV 캐시에 가상 메모리를 사용함으로써 vLLM은 필요에 따라 물리적 GPU 메모리만 할당하여 메모리 조각화를 제거하고 사전 할당을 방지합니다. 테스트에서 vLLM은 HuggingFace Transformers(HF) 및 Text Generation Inference(TGI)보다 뛰어난 성능을 발휘하여 NVIDIA A10G 및 A100 GPU에서 HF보다 최대 24배, TGI보다 3.5배 더 높은 처리량을 달성했습니다.
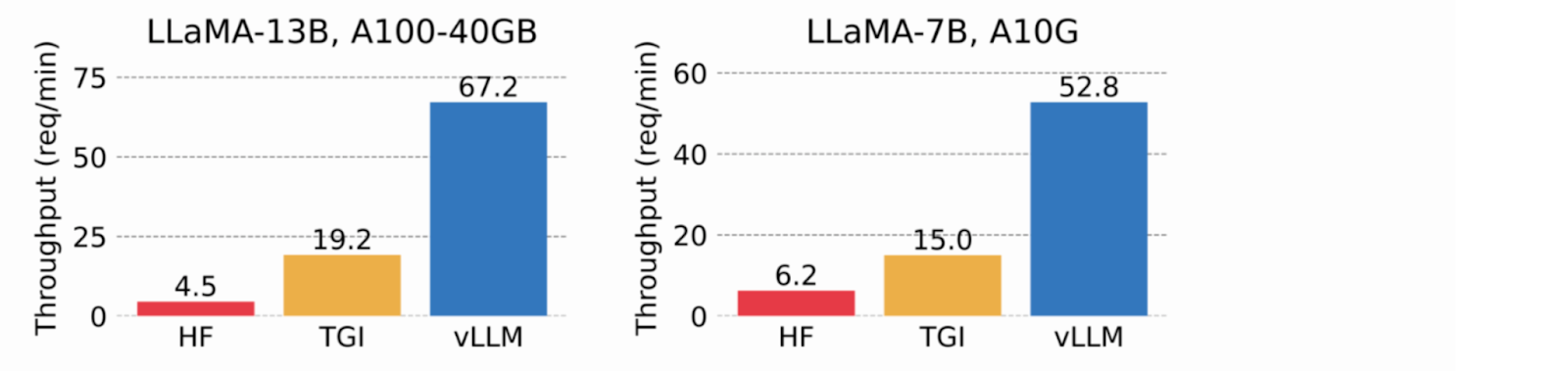
이미지 2. 각 요청이 3개의 병렬 출력 완료를 요청할 때의 처리량. vLLM은 HF보다 8.5배-15배, TGI보다 3.3배-3.5배 높은 처리량을 달성합니다(2023 vLLM 블로그)..
메타의 라마 3.1
메타의 라마 3.1**은 2024년 7월 23일에 발표되었습니다. 405B 모델은 여러 공개 벤치마크에서 최첨단 성능을 제공하며, 다양한 상업적 사용이 허용되는 128,000개의 입력 토큰 컨텍스트 창을 가지고 있습니다. 메타는 405억 개의 파라미터 모델과 함께 Llama3 70B(700억 개의 파라미터)와 8B(80억 개의 파라미터)의 업데이트 버전을 출시했습니다. 모델 가중치는 [메타 웹사이트에서] 다운로드할 수 있습니다(https://info.deeplearning.ai/e3t/Ctc/LX+113/cJhC404/VWbMJv2vnLfjW3Rh6L96gqS5YW7MhRLh5j9tjNN8BHR5W3qgyTW6N1vHY6lZ3l8N8htfRfqP8DzW72mhHB6vwYd2W77hFt886l4_PV22X226RPmZbW67mSH08gVp9MW2jcZvf24w97BW207Jmf8gPH0yW20YPQv261xxjW8nc6VW3jj-nNW6XdRhg5HhZk_W1QS0yL9dJZb0W818zFK1w62kdW8y-_4m1gfjfNW2jswrd3xbv-yW5mrvdk3n-KqyW45sLMF21qDrwW5TR3vr2MYxZ9W2hWhq23q-nQdW4blHqh3JlZWfW937hlZ58-KJCW82Pgv9384MbYW7yp56M6pvzd6f77wnH004).
핵심 인사이트는 생성된 데이터를 미세 조정하면 성능을 향상시킬 수 있지만, 품질이 좋지 않은 예제는 성능을 저하시킬 수 있다는 것이었습니다. Llama 팀은 모델 자체, 보조 모델 및 기타 도구를 사용하여 이러한 불량 예제를 식별하고 제거하기 위해 광범위하게 작업했습니다.
Milvus로 RAG 검색 구축 및 수행하기
데이터 세트 준비
이 데모의 데이터셋은 공식 Milvus 문서를 다운로드하여 로컬에 저장한 것을 사용했습니다.
langchain.document_loaders에서 디렉터리로더를 가져옵니다.
# 로컬 디렉토리에 이미 저장된 HTML 파일을 로드합니다.
path = "../../RAG/rtdocs_new/"
global_pattern = '*.html'
loader = 디렉터리로더(경로=경로, glob=글로벌_패턴)
docs = loader.load()
# 문서 수와 미리 보기를 인쇄합니다.
print(f"loaded {len(docs)} documents")
print(docs[0].page_content)
pprint.pprint(docs[0].메타데이터)
 로드된 22개 문서
로드된 22개 문서
임베딩 모델 다운로드
다음으로 HuggingFace에서 무료 오픈소스 임베딩 모델을 다운로드합니다.
import torch
에서 문장_트랜스포머를 가져옵니다.
# 디바이스에 구애받지 않는 코드에 대한 토치 설정을 초기화합니다.
N_GPU = torch.cuda.device_count()
DEVICE = torch.device('cuda:N_GPU' if torch.cuda.is_available() else 'cpu')
# 허깅페이스 모델 허브에서 모델을 다운로드합니다.
model_name = "BAAI/bge-large-en-v1.5"
encoder = SentenceTransformer(model_name, device=DEVICE)
# 모델 파라미터를 가져와 나중에 사용할 수 있도록 저장합니다.
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# 모델 매개변수를 검사합니다.
print(f"model_name: {model_name}")
print(f"EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f"MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH}")

사용자 정의 데이터를 벡터로 청크하고 인코딩합니다.
10% 겹치는 고정 길이 512자를 사용하겠습니다.
langchain.text_splitter에서 재귀 문자 텍스트 스플리터 가져오기
chunk_size = 512
chunk_overlap = np.round(CHUNK_SIZE * 0.10, 0)
print(f"chunk_size: {CHUNK_SIZE}, chunk_overlap: {chunk_overlap}")
# 스플리터를 정의합니다.
child_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
청크_오버랩=청크_오버랩)
# 문서를 청크화합니다.
chunks = child_splitter.split_documents(docs)
print(f"{len(docs)} 문서가 {len(chunks)} 하위 문서로 분할되었습니다.")
# 인코더 입력은 doc.page_content를 문자열로 입력합니다.
list_of_strings = [hasattr(doc, 'page_content') if 청크의 doc에 대해 doc.page_content]
# HuggingFace 인코더를 사용한 임베딩 추론.
embeddings = torch.tensor(encoder.encode(list_of_strings))
# 임베딩을 정규화합니다.
embeddings = np.array(embeddings / np.linalg.norm(embeddings))
# Milvus는 `numpy.float32` 숫자의 `numpy.ndarray` 목록을 기대합니다.
converted_values = list(map(np.float32, embeddings))
# 밀버스 삽입을 위한 dict_list를 생성합니다.
dict_list = []
for chunk, vector in zip(chunks, converted_values):
# 임베딩 벡터, 원본 텍스트 청크, 메타데이터를 조립합니다.
chunk_dict = {
'청크': 청크.페이지_콘텐츠,
'source': chunk.metadata.get('source', ""),
'벡터': 벡터,
}
dict_list.append(chunk_dict)

밀버스에서 벡터 저장하기
인코딩된 벡터 임베딩을 Milvus 벡터 데이터베이스에 저장합니다.
# 밀버스 라이트 서버에 클라이언트를 연결합니다.
pymilvus에서 MilvusClient를 가져옵니다.
mc = MilvusClient("milvus_demo.db")
# 유연한 스키마와 자동 인덱스를 사용하여 컬렉션을 생성합니다.
COLLECTION_NAME = "MilvusDocs"
mc.create_collection(COLLECTION_NAME,
EMBEDDING_DIM,
일관성_레벨="결국",
auto_id=True,
overwrite=True)
# Milvus 컬렉션에 데이터를 삽입합니다.
print("엔티티 삽입 시작")
start_time = time.time()
mc.insert(
collection_name,
data=dict_list,
progress_bar=True)
end_time = time.time()
print(f"{len(dict_list)} 벡터에 대한 밀버스 삽입 시간: ", end="")
print(f"{라운드(끝_시간 - 시작_시간, 2)} 초")

벡터 검색 수행
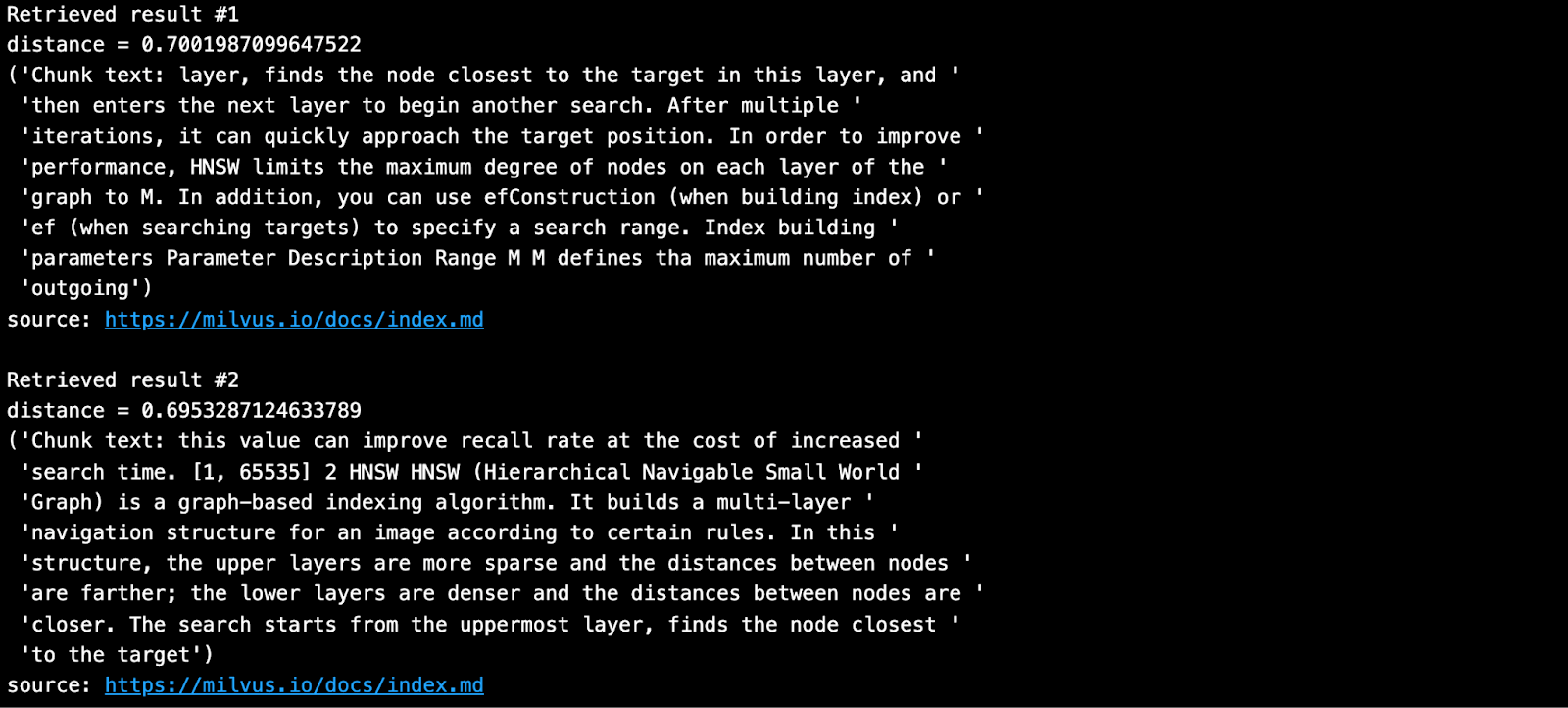
Milvus의 지식창고에서 질문을 하고 가장 가까운 이웃 청크를 검색합니다.
SAMPLE_QUESTION = "HNSW의 매개 변수는 무엇을 의미하나요?"
# 동일한 인코더를 사용하여 질문을 임베드합니다.
query_embeddings = torch.tensor(encoder.encode(SAMPLE_QUESTION))
# 임베딩을 단위 길이로 정규화합니다.
query_embeddings = F.normalize(query_embeddings, p=2, dim=1)
# 임베딩을 np.float32 목록으로 변환합니다.
query_embeddings = list(map(np.float32, query_embeddings))
# 필터링할 수 있는 메타데이터 필드를 정의합니다.
OUTPUT_FIELDS = list(dict_list[0].keys())
OUTPUT_FIELDS.remove('vector')
# 검색할 상위 k 결과 수를 정의합니다.
TOP_K = 2
# 쿼리와 벡터 데이터베이스를 사용하여 시맨틱 벡터 검색을 실행합니다.
results = mc.search(
collection_name,
data=query_embedings,
output_fields=OUTPUT_FIELDS,
limit=TOP_K,
일관성_레벨="결국")
검색된 결과는 아래와 같습니다.
vLLM 및 Llama 3.1-8B로 RAG 생성 빌드 및 수행하기
HuggingFace에서 vLLM 및 모델 설치하기
vLLM은 기본적으로 HuggingFace에서 대용량 언어 모델을 다운로드합니다. 일반적으로 허깅페이스에서 새로운 모델을 사용하려면 항상 pip 설치-업데이트 또는 -U를 수행해야 합니다. 또한 vLLM으로 Meta의 Llama 3.1 모델 추론을 실행하려면 GPU가 필요합니다.
vLLM이 지원되는 모든 모델의 전체 목록은 이 문서 페이지를 참조하세요.
# (권장) 새 conda 환경을 만듭니다.
conda create -n myenv python=3.11 -y
콘다 내엔브 활성화
# CUDA 12.1로 vLLM을 설치합니다.
pip install -U vllm transformers torch
import vllm, torch
vllm에서 LLM, SamplingParams를 가져옵니다.
# GPU 메모리 캐시를 지웁니다.
torch.cuda.empty_cache()
# GPU를 확인합니다.
!nvidia-smi
vLLM 설치 방법에 대한 자세한 내용은 설치 페이지를 참조하세요.
허깅페이스 토큰 받기
메타 라마 3.1과 같은 허깅페이스의 일부 모델은 사용자가 라이선스를 수락해야 가중치를 다운로드할 수 있습니다. 따라서 허깅페이스 계정을 생성하고 모델의 라이선스를 수락한 다음 토큰을 생성해야 합니다.
허깅페이스의 Llama3.1 페이지를 방문하면 약관에 동의할지 묻는 메시지가 표시됩니다. 모델 가중치를 다운로드하기 전에 "라이선스 동의"를 클릭하여 메타 약관에 동의합니다. 승인은 보통 하루도 채 걸리지 않습니다.
**승인을 받은 후에는 새로운 허깅페이스 토큰을 생성해야 합니다. 기존 토큰은 새 권한으로 작동하지 않습니다.
vLLM을 설치하기 전에 새 토큰으로 허깅페이스에 로그인하세요. 아래에서는 Colab 시크릿을 사용하여 토큰을 저장했습니다.
# 새 토큰을 사용하여 허깅페이스에 로그인합니다.
에서 허깅페이스_허브 로그인 가져오기
google.colab에서 userdata를 가져옵니다.
hf_token = userdata.get('HF_TOKEN')
login(token = hf_token, add_to_git_credential=True)
RAG 생성 실행
데모에서는 'Llama-3.1-8B' 모델을 실행하여 GPU와 상당한 크기의 메모리가 필요합니다. 다음 예제는 A100 GPU를 사용하는 Google Colab Pro(월 $10)에서 실행되었습니다. vLLM 실행 방법에 대한 자세한 내용은 빠른 시작 문서에서 확인할 수 있습니다.
# 1. 모델 선택
모델 실행 = "메타-라마/메타-라마-3.1-8B-인스트럭트"
# 2. GPU 메모리 캐시를 모두 지우세요!
torch.cuda.empty_cache()
# 3. vLLM 모델 인스턴스를 인스턴스화합니다.
llm = LLM(model=MODELTORUN,
enforce_eager=True,
dtype=torch.bfloat16,
GPU_MEMORY_UTILIZATION=0.5,
max_model_len=1000,
seed=415,
max_num_batched_tokens=3000)

Milvus에서 검색한 컨텍스트와 소스를 사용하여 프롬프트를 작성합니다.
# 모든 컨텍스트를 공백으로 구분합니다.
contexts_combined = ' '.join(contexts)
# LangChain의 Lance Martin은 가장 좋은 컨텍스트를 마지막에 넣으라고 말합니다.
contexts_combined = ' '.join(reversed(contexts))
# 모든 고유 소스를 쉼표로 구분합니다.
source_combined = ' '.join(reversed(list(dict.fromkeys(sources))))
SYSTEM_PROMPT = f"""먼저 제공된 컨텍스트가 사용자의 질문과 관련이 있는지
관련성이 있는지 확인합니다. 둘째, 제공된 컨텍스트가 관련성이 높은 경우에만 해당 컨텍스트를 사용하여 질문에 답변합니다. 그렇지 않으면 문맥이 관련성이 높지 않은 경우 문맥을 사용하지 않고 질문에 답변합니다.
명확하고 간결하며 관련성 있게 답변하세요. 2문장 이내로 명확하게 답변하세요.
근거 출처: {소스_결합}
컨텍스트: 컨텍스트: {컨텍스트_결합}
사용자의 질문: {샘플_질문}
"""
프롬프트 = [SYSTEM_PROMPT]
이제 검색된 청크와 프롬프트에 채워진 원래 질문을 사용하여 답변을 생성합니다.
# 샘플링 매개변수
샘플링_파람 = 샘플링파람(온도=0.2, top_p=0.95)
# vLLM 모델을 호출합니다.
출력 = llm.generate(프롬프트, 샘플링_파람)
# 출력을 인쇄합니다.
출력을 출력합니다:
prompt = output.prompt
generated_text = output.outputs[0].text
# !r은 따옴표 안에 문자열을 인쇄하는 repr()을 호출합니다.
print()
print(f"Question: {SAMPLE_QUESTION!r}")
pprint.pprint(f"생성된 텍스트: {generated_text!r}")

위의 답변이 저에게는 완벽해 보입니다!
이 데모에 관심이 있으시다면 직접 사용해 보시고 의견을 알려주세요. 또한 Discord의 Milvus 커뮤니티에 가입하여 모든 GenAI 개발자와 직접 대화를 나눌 수도 있습니다.
참조
레이 서밋에서 2023 vLLM 프레젠테이션
vLLM 블로그: vLLM: 페이징어텐션으로 쉽고, 빠르고, 저렴한 LLM 서비스
vLLM 서버 실행에 대한 유용한 블로그: vLLM 배포: 단계별 가이드

계속 읽기

Zilliz Cloud Delivers Better Performance and Lower Costs with Arm Neoverse-based AWS Graviton
Zilliz Cloud adopts Arm-based AWS Graviton3 CPUs to cut costs, speed up AI vector search, and power billion-scale RAG and semantic search workloads.

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.