




Milvus 2.4, 차세대 GPU 인덱싱으로 벡터 검색을 향상시키는 CAGRA 공개
GPU 기반 인덱스란 무엇인가요?
벡터 검색은 본질적으로 계산 집약적입니다. 가장 성능이 뛰어난 벡터 데이터베이스로 선두에 서 있는 Milvus는 컴퓨팅 리소스의 80% 이상을 벡터 데이터베이스와 검색 엔진인 [Knowhere에 할당하고 있습니다. 고성능 컴퓨팅의 연산 수요를 고려할 때, GPU는 특히 벡터 검색 영역에서 벡터 데이터베이스 플랫폼의 중추적인 요소로 부상하고 있습니다.
Milvus는 2021년에 Milvus 버전 1.1을 통해 GPU 가속을 활용하는 최초의 벡터 데이터베이스가 됨으로써 선례를 남겼습니다. 버전 2.3](https://zilliz.com/blog/getting-started-with-gpu-powered-milvus-unlocking-10x-higher-performance)에서는 벡터 검색을 위해 NVIDIA의 RAFT 라이브러리를 활용함으로써 Milvus는 GPU 가속 인덱스와 추천 시스템 구축에 사용되는 NVIDIA Merlin 추천 프레임워크와의 통합을 도입했습니다. 이 버전에서는 IVFFLAT 및 IVFPQ 인덱스의 도입으로 놀라운 [성능 향상]을 선보였습니다.
이러한 발전에도 불구하고, 소규모 배치 쿼리에 대한 성능 최적화 및 GPU 기반 인덱스의 비용 효율성 향상과 같은 과제는 여전히 남아 있어 혁신적인 솔루션에 대한 지속적인 탐색이 요구되고 있습니다. IVF 기반 방식에 비해 우수한 성능을 인정받은 그래프 기반 벡터 검색 알고리즘으로의 업계 전환은 중요한 진화를 의미합니다. 그러나 이러한 알고리즘은 순차적 실행과 무작위 메모리 액세스 패턴으로 인해 GPU에 적용하는 것이 간단하지 않기 때문에 GGNN 및 SONG 같은 알고리즘의 효율적인 GPU 구현에 어려움을 겪고 있습니다.
이러한 문제를 해결하기 위해 엔비디아의 최신 혁신 기술인 GPU 기반 그래프 인덱스 CAGRA는 중요한 이정표가 될 것입니다. 밀버스는 엔비디아의 지원으로 2.4 버전에 CAGRA를 통합 지원하여 벡터 검색에서 효율적인 GPU 구현의 장애물을 극복하는 데 큰 진전을 이루었습니다.
CAGRA란?
CAGRA 구축
CAGRA(CUDA Anns GRAph 기반)는 CPU의 계층적 탐색 가능한 작은 세계(HNSW) 그래프에서 사용하는 반복 삽입 업데이트 방식에서 벗어나 그래프 구성에 새로운 접근 방식을 도입했습니다. 이러한 변화는 CPU 기반 HNSW 구축 프로세스에서는 활용하지 못하는 GPU의 고도로 병렬화된 그래프 구축 기능을 완전히 활용해야 하는 문제를 해결합니다. CAGRA는 각 노드가 수많은 이웃 노드에 연결되는 IVFPQ 또는 NN-DESCENT를 사용해 초기 그래프를 생성하는 것으로 시작합니다. 다음 단계에서는 이러한 연결을 중요도별로 정렬하고, 덜 중요한 가장자리를 잘라내고, 방향이 지정된 그래프를 병합하여 구조를 완성하고 초기 그래프를 구축합니다. 초기 그래프에서 각 노드는 많은 수의 이웃 노드를 가지고 있습니다. 그런 다음 CAGRA는 초기 그래프를 기반으로 중요도에 따라 인접한 모든 에지를 정렬하고 중요하지 않은 에지를 잘라냅니다.
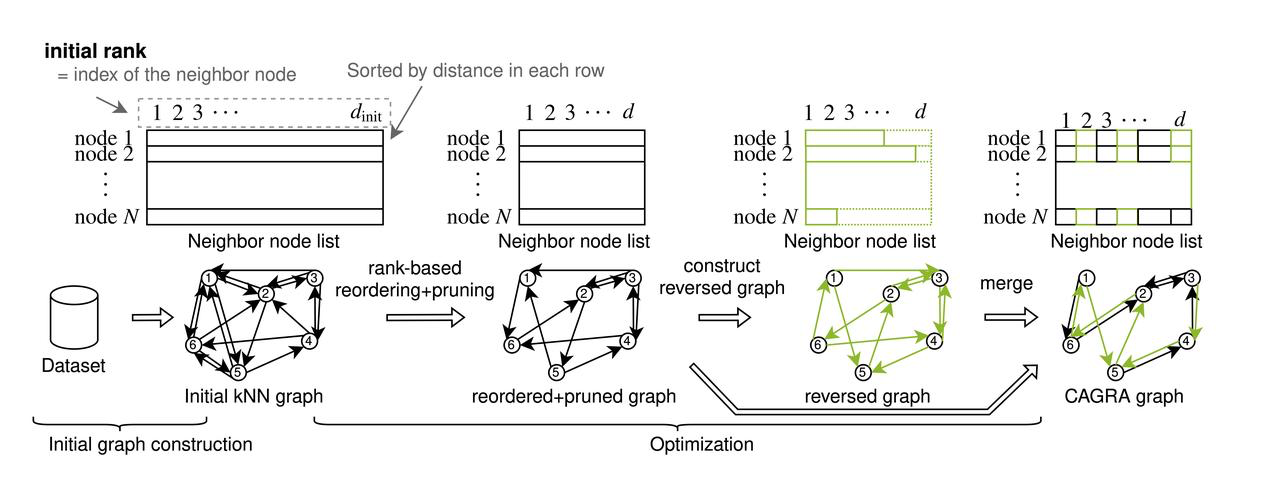 CAGRA의 빌드 과정
CAGRA의 빌드 과정
초기 그래프 구성
IVFPQ
IVFPQ 모드에서 CAGRA는 비디오 메모리 사용량을 최소화하기 위해 제품 양자화 (PQ) 인덱스의 양자화 기능을 활용하여 데이터 세트를 활용하여 IVFPQ 인덱스를 구축합니다. 이 인덱스가 생성된 후, CAGRA는 데이터 세트의 각 지점에 대한 검색을 수행하며, IVFPQ 인덱스에 의해 식별된 대략적인 가장 가까운 이웃을 인접점 가장 가까운 이웃 검색으로 사용합니다. 이 프로세스는 초기 그래프를 구성하기 위한 기초를 형성하여 메모리를 크게 차지하지 않으면서도 효율적인 설정을 보장합니다.
NN-DESCENT
CAGRA는 다음과 같은 세부 단계를 포함하는 초기 그래프 구성에 대한 또 다른 접근 방식으로 NN-DESCENT 알고리즘을 사용합니다:
**초기화: **데이터 세트 v에서 k 점을 무작위로 선택하여 초기 인접성 목록 B[v]를 생성합니다.
반전 및 병합: B[v]의 역을 취하여 반전된 인접성 목록 R[v]를 생성한 다음 B와 R을 병합하여 H[v]를 형성합니다.
**이웃 확장: 데이터 세트의 모든 노드 v에 대해 H[v]를 기준으로 이웃의 모든 이웃을 식별하여 가장 가까운 상위 k 노드를 새로운 이웃으로 선택합니다.
**반복: B가 안정화되어 더 이상 변경되지 않거나 미리 설정한 반복 임계값에 도달할 때까지 반전 및 병합과 이웃 확장 과정을 반복합니다.
HNSW에 비해 NN-Descent는 병렬화가 더 쉽고 작업 간 데이터 상호 작용이 적어 GPU에서 CAGRA 인접 그래프의 그래프 구성 시간과 효율성이 크게 향상됩니다. 그러나 NN-DESCENT의 초기 그래프 품질은 IVFPQ 모드에서 달성한 것보다 약간 뒤처질 수 있다는 점에 유의해야 합니다.
CAGRA 최적화
CAGRA의 그래프 최적화 전략은 두 가지 주요 가정을 기반으로 합니다:
**중요도 정렬: 에지의 중요도를 결정할 때 기존의 거리 기반 정렬보다 경로 기반 정렬을 선호합니다. 이 방법은 그래프 연결성이 거리 기반 중요도 정렬의 이점을 반드시 누릴 수 있는 것은 아니라고 주장합니다.
역 그래프 병합: 한 노드에 중요하다고 간주되는 노드가 다른 노드에도 중요할 수 있다는 원칙은 역 그래프 병합 전략의 근간을 이룹니다.
최적화 프로세스에는 두 가지 주요 단계가 포함됩니다:
- 가지치기: 초기에는 각 노드의 인접한 에지에 거리에 따라 다양한 가중치('w')가 할당됩니다. CAGRA는 '최대(w_{x에서 z},w_{z에서 y}) < w_{x에서 y}' 조건에 따라 가장 '우회 가능한' 노드를 연결하는 경우 에지를 잘라내는 트리밍 전략을 사용합니다. 이는 그래프를 간소화하기 위해 덜 중요한 연결을 제거하는 데 중점을 둡니다.
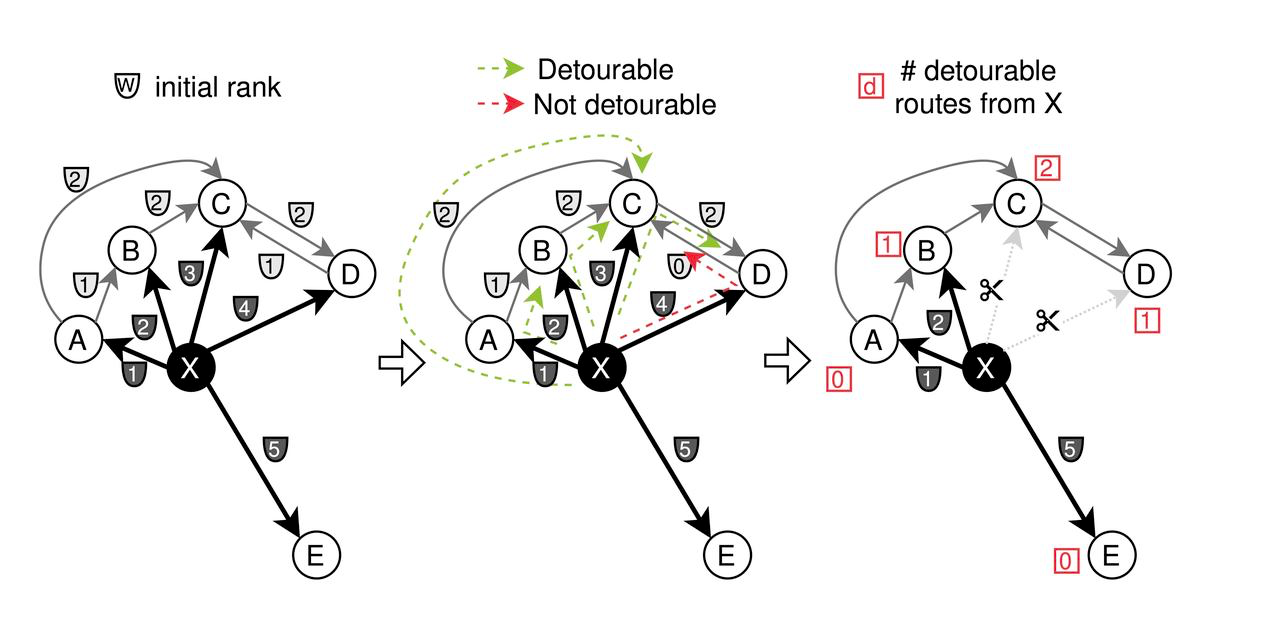 CAGRA 최적화를 위한 프루닝 프로세스
CAGRA 최적화를 위한 프루닝 프로세스
- **병합: 경로 중요도에 따라 순방향 그래프를 가지치기한 후, 에지를 반전하여 병합합니다. 구체적으로 순방향 그래프와 역방향 그래프 모두에서 에지의 절반을 선택해 최종적으로 최적화된 CAGRA 그래프를 생성합니다.
그래프 구성과 최적화에 대한 이러한 세부적인 접근 방식은 그래프 기반 검색 알고리즘에 내재된 문제를 해결하면서 GPU의 고유한 기능을 활용하여 벡터 검색 작업에서 CAGRA의 효율성과 효과를 보장합니다.
CAGRA로 검색하기
CAGRA 검색 메커니즘은 효율적인 그래프 탐색을 위해 고정된 크기의 정렬된 우선순위 큐를 사용하는 체계적인 접근 방식을 채택하고 있습니다. 이 세부 프로세스는 구조화된 프레임워크 내에서 일련의 단계를 통해 설명됩니다:
CAGRA 검색 프레임워크
CAGRA는 내부 상위-M 목록과 후보 목록으로 구성된 순차적 메모리 버퍼로 작동합니다. 내부 상위-M 리스트는 우선순위 큐 역할을 하며, 그 길이가 M(여기서 M ≥ k)으로 설정되어 가장 관련성이 높은 결과를 원하는 수의 가장 가까운 이웃인 k까지 저장할 수 있습니다. 후보 리스트의 크기는 p × d로 결정되며, 여기서 p는 각 반복에서 탐색되는 소스 노드의 수를 나타내고 d는 그래프의 차수를 나타냅니다. 이러한 목록 내의 각 요소는 노드 인덱스와 쿼리와의 거리를 쌍으로 연결하여 효율적인 검색 관리를 가능하게 합니다.
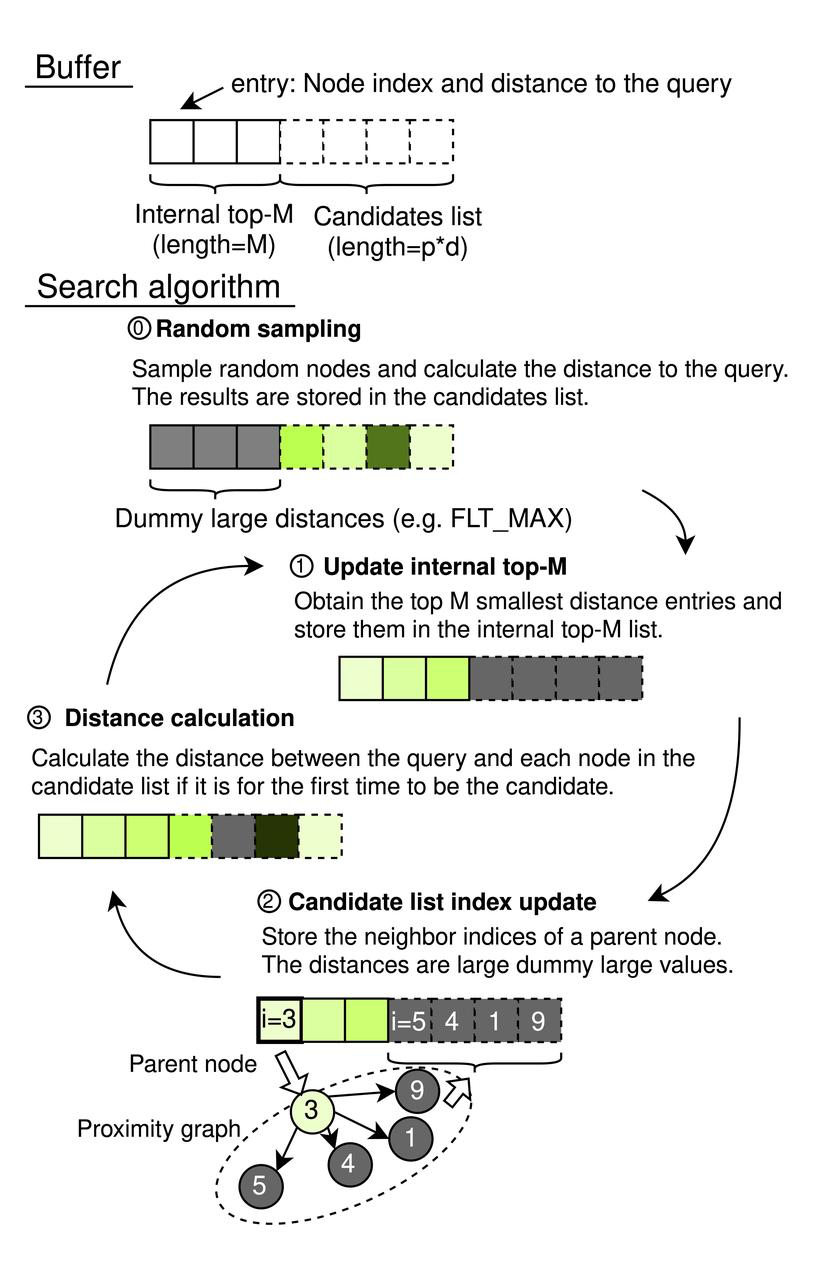 CAGRA 검색 프로세스
CAGRA 검색 프로세스
검색 프로세스 단계
- 랜덤 샘플링(초기화)
- 의사 난수 생성기를 사용하여 각 노드와 쿼리 사이의 거리를 계산하여 p × d 무작위 노드 인덱스를 선택합니다.
- 결과는 후보 목록을 채우고, 내부 상위-M 목록은 초기 정렬 결과에 영향을 미치지 않도록 가상 항목(FLT_MAX로 설정)으로 초기화합니다.
**내부 상위-M 목록 업데이트: ** 내부 상위-M 목록에 포함할 전체 버퍼에서 가장 작은 거리를 기준으로 상위-M 노드를 선택합니다.
후보 목록 인덱스 업데이트(그래프 탐색):
- 해시 테이블 필터를 통해 이전에 사용된 노드를 제외하고 내부 top-M 목록에서 상위 p 노드의 모든 인접 노드를 식별합니다.
- 이 단계에서는 거리를 다시 계산하지 않고 이러한 이웃 노드를 후보 목록에 추가합니다.
- 거리 계산:
- 후보 목록에 새로 나타나는 노드에 대해 거리 계산을 수행하여 이전 반복에서 평가된 노드에 대한 중복 계산을 방지합니다.
- 노드가 속하기에는 충분히 작은지 또는 고려하기에는 너무 큰지에 따라 거리가 관련성을 정당화하는 경우에만 노드를 상위-M 목록에 추가합니다.
알고리즘은 이러한 단계를 반복적으로 처리하여 내부 상위-M 목록의 모든 노드가 모두 검색의 시작점이 될 때까지 순환합니다. 검색은 내부 상위-M 목록에서 상위 k 개 항목을 추출하여 근사 이웃 검색(ANNS) 결과를 제공하는 것으로 마무리됩니다.
성능
GPU 인덱스를 활용하기로 결정한 것은 주로 성능을 고려했기 때문입니다. 저희는 오픈 소스 벡터 데이터베이스 벤치마크 툴을 활용하여 Milvus의 성능을 종합적으로 평가했으며, HNSW, GPU 기반 IVFFLAT, CAGRA 인덱스 간의 비교에 중점을 두었습니다.
벤치마킹 설정
현실적인 평가를 위해 테스트 환경이 일반적으로 사용 가능한 리소스를 반영할 수 있도록 NVIDIA T4 및 A10G GPU가 장착된 AWS 호스팅 머신에서 벤치마킹을 수행했습니다. 선택된 머신은 비슷한 가격대의 머신으로 성능 평가를 위한 공평한 경쟁의 장을 제공했습니다. 모든 테스트의 목표는 상위 100@98% 리콜을 달성하는 것이었으며, 클라이언트로 AWS m6i.4xlarge 인스턴스(16C64G)를 사용했습니다.
 선택한 머신의 기본 정보
선택한 머신의 기본 정보
성능 인사이트
소규모 배치 성능:
일반적으로 GPU의 활용도가 낮은 소규모 검색 배치(배치 크기 1)의 상황에서는 CAGRA가 다른 방법보다 훨씬 뛰어난 성능을 보였습니다. 테스트 결과, CAGRA는 이러한 조건에서 기존 방법보다 거의 10배에 가까운 성능을 제공하는 것으로 나타났습니다.
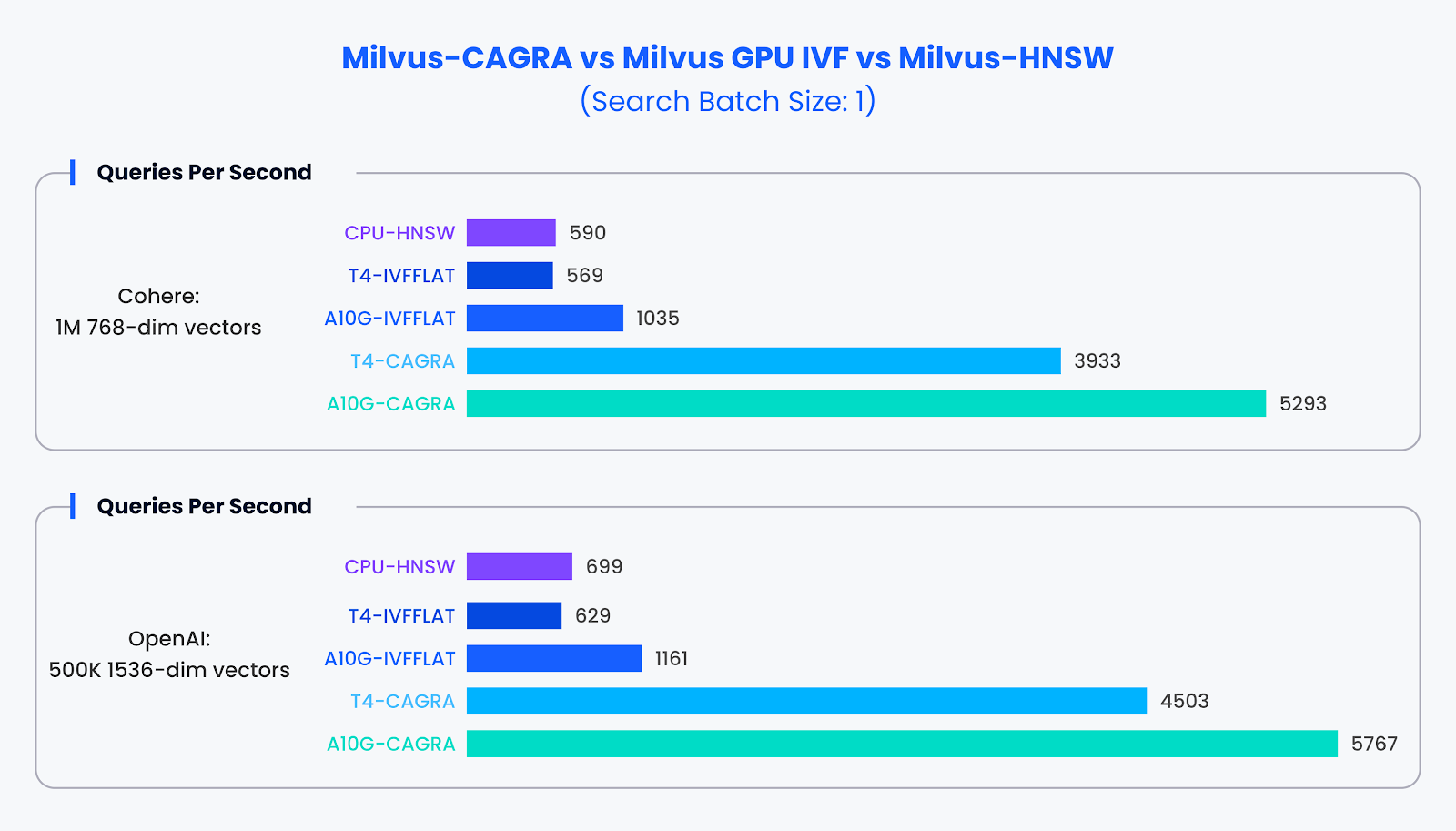 소규모 배치 데이터 세트의 성능 비교
소규모 배치 데이터 세트의 성능 비교
대규모 배치 성능:
대규모 검색 배치(10개 및 100개 크기)를 조사할 때, CAGRA의 우위는 더욱 뚜렷해졌습니다. HNSW에 비해 CAGRA는 극적인 성능 향상을 보여주며 검색 효율성을 수십 배까지 향상시켰습니다.
대용량 데이터 세트의 성능 비교](https://assets.zilliz.com/Performance_Comparison_for_Large_Batch_Data_Set_ef371476c6.png)
인덱스 구축 효율성:
검색 기능 외에도 CAGRA는 인덱스 구축에도 능숙합니다. GPU 가속을 통해 CAGRA는 다른 방법보다 약 10배 더 빠르게 인덱스를 구축할 수 있음을 입증했습니다.
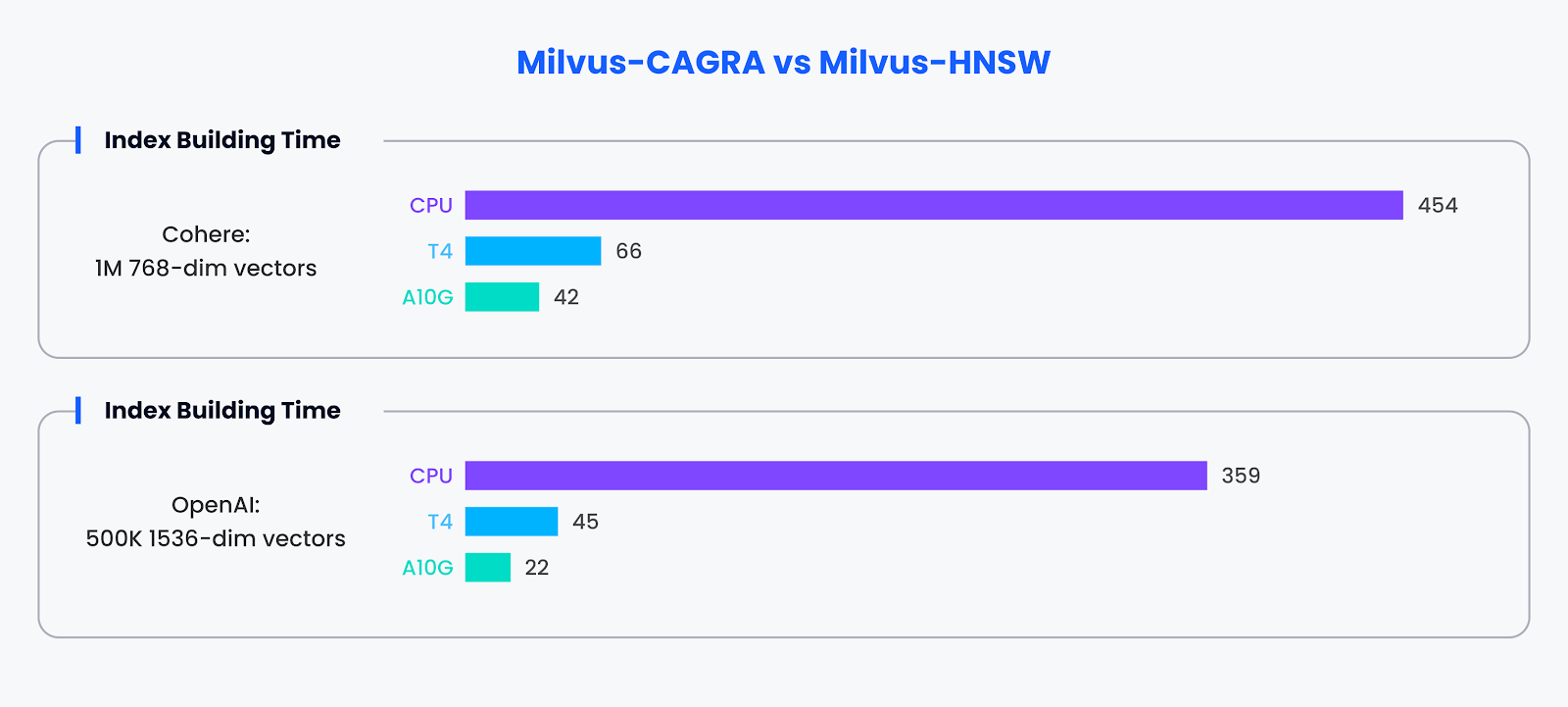 인덱스 구축 성능 비교
인덱스 구축 성능 비교
이 벤치마크 결과는 Milvus에서 CAGRA와 같은 GPU 가속 인덱스를 채택함으로써 얻을 수 있는 상당한 성능상의 이점을 보여줍니다. 배치 크기 전반에 걸쳐 검색 작업을 가속화하는 데 탁월할 뿐만 아니라 인덱스 구축 속도도 크게 향상되어 벡터 데이터베이스 성능을 최적화하는 데 있어 GPU의 가치를 확인할 수 있습니다.
다음 단계는?
CAGRA는 벡터 검색의 경계를 재정의하려는 노력의 중요한 도약으로, 가장 까다로운 프로덕션 과제를 해결할 수 있는 GPU 기반 검색의 잠재력을 보여주었습니다. 앞으로 밀버스는 벡터 검색의 높은 리콜, 짧은 지연 시간, 비용 효율성, 확장성 측면을 더욱 심도 있게 탐구해 나갈 것입니다. 현재의 성과를 넘어 더욱 유연한 데이터 관리, 풍부한 검색 기능, 획기적인 성능 최적화를 실현하기 위해 노력하고 있습니다.
이러한 비전을 바탕으로 밀버스는 지속적인 혁신을 통해 비정형 데이터에 대한 가속화된 검색의 미래를 선도하고 개척해 나가고 있습니다. 현재 가능한 것의 한계를 뛰어넘어 미래의 새로운 가능성을 열어 벡터 검색을 더욱 강력하고 효율적이며 접근하기 쉽게 만드는 것을 목표로 합니다.
 벡터 데이터베이스를 사용하는 개발자를 위한 실용적인 팁과 요령.png
솔루션에 어떤 인덱스를 선택해야 할지 잘 모르시겠어요? 올바른 선택을 도와주는 블로그가 있습니다!
벡터 데이터베이스를 사용하는 개발자를 위한 실용적인 팁과 요령.png
솔루션에 어떤 인덱스를 선택해야 할지 잘 모르시겠어요? 올바른 선택을 도와주는 블로그가 있습니다!

계속 읽기

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.