




Tokenizzazione: Capire il testo scomponendolo

Tokenizzazione: Capire il testo scomponendolo
TL; DR
La tokenizzazione è il processo di scomposizione del testo in unità più piccole chiamate token, come parole, frasi o sottoparole, per prepararlo ai modelli di apprendimento automatico. Per esempio, la frase "La tokenizzazione in Milvus è potente" potrebbe essere suddivisa in tokens come ["Tokenizzazione", "in", "Milvus", "è", "potente"]. Questi tokens sono trasformati in embeddings numerici che catturano il loro significato per compiti come la ricerca semantica. Nel database vettoriale Milvus, la tokenizzazione è integrata con analizzatori integrati che elaborano il testo in modo efficiente per l'indicizzazione e il recupero. Questa caratteristica semplifica i flussi di lavoro, consentendo agli sviluppatori di gestire direttamente il testo grezzo e di alimentare applicazioni di ricerca avanzate con elevata precisione e scalabilità;
Introduzione
Il cuore di molti sistemi di intelligenza artificiale (AI) e elaborazione del linguaggio naturale (NLP) è costituito da un processo che trasforma il testo grezzo in "dati strutturati": la tokenizzazione. Ma cos'è esattamente la tokenizzazione e perché è così importante per le macchine scomporre il testo in parti più piccole?
La tokenizzazione è il processo di scomposizione del testo in unità più piccole, che consente alle macchine di analizzare e comprendere meglio il linguaggio. Questa fase essenziale consente ai computer di gestire ed elaborare il linguaggio umano per varie attività di NLP, come l'analisi del sentiment, la traduzione linguistica e la generazione di testi.
 tokenization
tokenization
Cos'è la tokenizzazione?
La tokenizzazione divide i testi, come parole o caratteri, in unità più piccole chiamate tokens. È una fase fondamentale della PNL, che consente alle macchine di elaborare e comprendere meglio il linguaggio umano.
Perché abbiamo bisogno della tokenizzazione?
La tokenizzazione è come imparare una nuova lingua: si inizia con la scomposizione delle frasi in unità più piccole per comprenderne il significato e la struttura. Allo stesso modo, i computer dividono un blocco di testo in unità più piccole e gestibili per elaborarlo. La tokenizzazione insegna al computer a identificare questi componenti fondamentali, come parole o sottoparole, consentendogli di comprendere e analizzare il testo.
Tecnicamente, la tokenizzazione converte il testo non strutturato in un formato strutturato che il computer può elaborare. Ad esempio, quando si inserisce una frase in un modello NLP, il tokenizer la divide in token, ai quali vengono assegnati valori numerici. Questi valori consentono ai computer di eseguire operazioni matematiche, identificare relazioni ed estrarre il significato dai dati. Senza la tokenizzazione, il testo rimarrebbe una stringa di caratteri incomprensibile per la macchina, rendendo impossibile un'ulteriore analisi.
Concetti chiave della tokenizzazione
Qui esploreremo i concetti chiave da capire sulla tokenizzazione.
Token
Un token è un'unità di base del testo considerata significativa per l'analisi. I token possono essere caratteri, parole o sottoparole che servono come input primario per le successive operazioni di elaborazione del testo.
Tokenizzatore
I tokenizer sono gli strumenti fondamentali che consentono ai computer di analizzare e interpretare il linguaggio umano suddividendo il testo in token. Applica regole specifiche, come la suddivisione per spazi o l'uso di tecniche a livello di sottoparola, per definire la granularità della rappresentazione del testo.
Analizzatore
Un analizzatore va oltre la semplice tokenizzazione per elaborare e comprendere profondamente il testo. Dopo la tokenizzazione, i filtri vengono applicati ai token per perfezionarli ulteriormente, applicando ulteriori elaborazioni, come la minuscola, lo stemming, la lemmatizzazione o la rimozione delle stopword.
Vocabolario
Il vocabolario è l'insieme dei token unici (parole, sottoparole o caratteri) che un modello può elaborare. Viene costruito a partire dai token prodotti durante la tokenizzazione. Il vocabolario è il riferimento del modello per la comprensione del testo. Il suo design e le sue dimensioni influenzano la capacità del modello di gestire il linguaggio, in particolare le parole rare o non viste.
Figura - Tokenizzatore e analizzatore in Milvus](https://assets.zilliz.com/Figure_Tokenizer_and_Analyzer_in_Milvus_2f283b3046.png)
Figura: Tokenizer e analizzatore in Milvus
Questo diagramma illustra il flusso di elaborazione del testo, dove il testo grezzo viene tokenizzato. Successivamente, un analizzatore applica dei filtri per convertire i token in minuscolo e rimuovere le stop words, ottenendo un elenco raffinato di token significativi.
Tipi di tokenizzazione
I metodi di tokenizzazione variano in base alla granularità della scomposizione del testo e ai requisiti specifici dell'attività da svolgere. Ecco i tipi più comuni di tokenizzazione:
1. Tokenizzazione dei caratteri: Scompone il testo in singoli caratteri. Può essere utile per le lingue con morfologia complessa e per compiti come la correzione ortografica o la gestione di testo rumoroso.
Figura - Tokenizzazione dei caratteri](https://assets.zilliz.com/Figure_Character_tokenization_c7c185282c.png)
Figura: Totalizzazione dei caratteri
2. Tokenizzazione delle parole: È il tipo più comune di tokenizzazione, che divide il testo in singole parole. È utile per la modellazione linguistica, il part-of-speech tagging e il riconoscimento di entità denominate, che si basano sull'analisi a livello di parola.
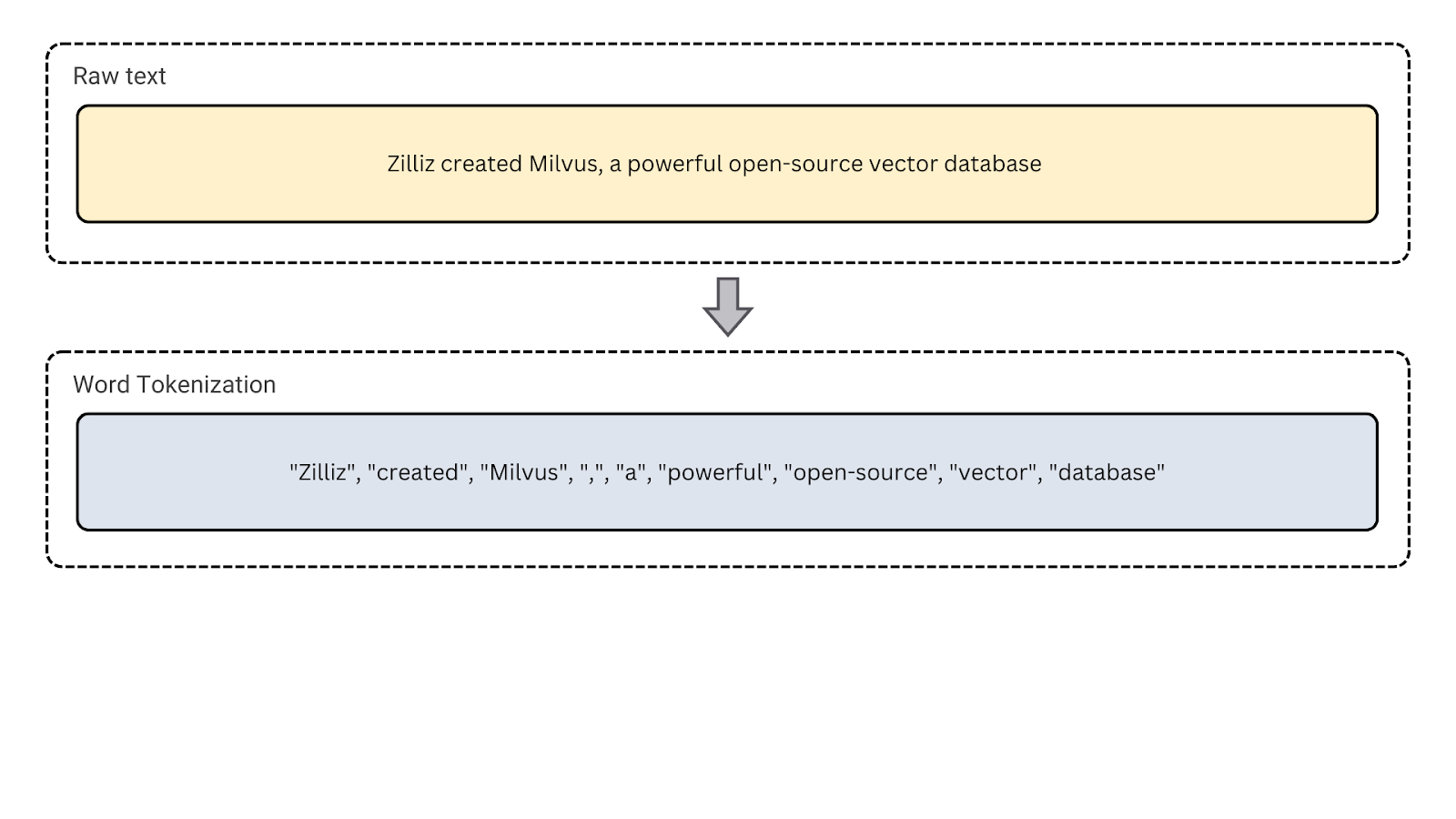 Figura - Tokenizzazione delle parole
Figura - Tokenizzazione delle parole
Figura: La tokenizzazione delle parole.
3. Tokenizzazione delle frasi: Questo tipo segmenta il testo in frasi. Separa paragrafi o lunghi blocchi di testo in frasi distinte. Si utilizza per compiti come l'analisi del sentiment e la sintesi del testo, dove è richiesta l'analisi della struttura a livello di frase.
Figura - Tokenizzazione delle frasi] (https://assets.zilliz.com/Figure_Sentence_tokenization_c0dadf08e4.png)
Figura: Totalizzazione delle frasi.
4. Tokenizzazione delle sottoparole: Questo metodo spezza le parole in unità più piccole e significative (ad esempio, prefissi, suffissi o steli). Aiuta a ridurre le dimensioni del vocabolario ed è particolarmente utile per compiti come la generazione di testi.
 Figura - Tokenizzazione delle sottoparole
Figura - Tokenizzazione delle sottoparole
Figura: Totalizzazione delle sottoparole
La tokenizzazione delle sottoparole ha suddiviso la frase in token di sottoparole. Parole rare come "Zilliz" e "Milvus" vengono suddivise in unità più piccole. Inoltre, "open-source" viene suddiviso in ["open", "-", "source"], trattando il trattino come un token separato.
Esempio di codice
Ecco un esempio Python che utilizza il [tokenizer BERT] di Hugging Face (https://huggingface.co/docs/transformers/v4.47.1/en/model_doc/bert#transformers.BertTokenizer). Dimostra come la frase viene tokenizzata utilizzando la tokenizzazione delle sottoparole con l'algoritmo WordPiece:
da transformers import AutoTokenizer
# Carica un tokenizer pre-addestrato
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# Tokenizzare una frase
frase = "Zilliz ha creato Milvus, un potente database vettoriale open-source"
tokens = tokenizer.tokenize(frase)
print(tokens)
Output
['z', '##ill', '##iz', 'created', 'mil', '##vus', ',', 'a', 'powerful', 'open', '-', 'source', 'vector', 'database'].
Confronto tra tokenizzazione e incorporazione di parole
La tokenizzazione e il word embedding sono entrambe tecniche fondamentali nell'elaborazione del linguaggio naturale (NLP), ma hanno scopi diversi. La tokenizzazione suddivide il testo in unità più piccole, mentre l'embedding converte queste unità in forma numerica.
Figura - Relazione semantica tra le parole nello spazio vettoriale](https://assets.zilliz.com/Figure_Semantic_Relationship_Between_Words_in_Vector_Space_948e78f299.png)
Figura: Relazione semantica tra le parole nello spazio vettoriale
Ecco un confronto tra la tokenizzazione e il Word Embedding:
| Aspetto | Tokenization | Word Embedding |
|---|---|---|
| Definizione | Il processo di suddivisione del testo in unità più piccole (token) | Un metodo per rappresentare i token come vettori densi in uno spazio vettoriale ad alta dimensione. |
| Scopo | Spezzare il testo in unità che possono essere elaborate | Catturare il significato semantico e la relazione tra le parole nella rappresentazione vettoriale |
| Esempi | Frase: "La tokenizzazione è fondamentale "Gettoni: ["Tokenization", "is", "crucial"] | Parola: "Milvus "Incorporamento: [0.23, 0.56, -0.12, ...] |
| Vantaggi | Converte il testo non strutturato in un formato strutturato che un computer può elaborare | Cattura la semantica delle parole, le relazioni e il contesto |
| Limitazioni | Non cattura la semantica dei token | Richiede una grande potenza di calcolo per generare embeddings |
Vantaggi e sfide della tokenizzazione
La tokenizzazione è fondamentale nell'elaborazione dei testi. Offre diversi vantaggi per la modellazione e l'analisi del linguaggio, ma presenta anche delle sfide. Esaminiamo entrambi gli aspetti.
Vantaggi
Elaborazione efficace del testo:** La tokenizzazione è fondamentale per preparare i dati di testo per le attività di NLP. Rende il testo più adatto ai modelli di apprendimento automatico.
Controllo della granularità:** La tokenizzazione permette di controllare il livello di granularità, consentendo al modello di lavorare con parole, sottoparole o persino caratteri in base all'attività da svolgere. Compiti diversi hanno requisiti diversi e una granularità specifica può migliorare le prestazioni.
Indipendenza dalla lingua: Le tecniche di tokenizzazione possono adattarsi a lingue e scritture diverse.
Facilita la modellazione del linguaggio: La tokenizzazione è fondamentale per la modellazione del linguaggio. Definisce le unità di base (token) che il modello elabora, consentendo una migliore comprensione e generazione del testo.
Sfide
Ambiguità: La tokenizzazione deve affrontare sfide dovute all'ambiguità del linguaggio. Ad esempio, la parola "banca" potrebbe riferirsi a un istituto finanziario o alla riva di un fiume, a seconda del contesto. Allo stesso modo, frasi come "scuola superiore" possono essere tokenizzate come due parole separate o come un'unica unità, influenzando l'interpretazione.
Alcuni metodi di tokenizzazione possono perdere informazioni, suddividendo le parole in token più piccoli, rendendo più difficile per i modelli comprendere il contesto o il significato completo del testo originale.
Gestione della punteggiatura: La segmentazione dei token che includono punteggiatura, come apostrofi o trattini, può talvolta essere difficile per gli algoritmi NLP.
La tokenizzazione può essere particolarmente difficile in lingue che non hanno confini chiari tra le parole, come il cinese o il giapponese, dove gli spazi non sempre separano le parole. Queste lingue richiedono metodi di tokenizzazione più sofisticati per dividere accuratamente il testo.
Casi d'uso della tokenizzazione
La tokenizzazione è ampiamente utilizzata in varie attività di NLP, per aiutare i sistemi a elaborare e analizzare i dati testuali. Di seguito sono riportati alcuni dei principali casi d'uso della tokenizzazione:
Motori di ricerca:** La tokenizzazione consente ai motori di ricerca di indicizzare e recuperare rapidamente i contenuti rilevanti, scomponendo i termini e i documenti delle query in token, garantendo risultati accurati per le query degli utenti.
Traduzione automatica:** La tokenizzazione è fondamentale nella traduzione automatica, in quanto aiuta a scomporre le lingue di partenza e di arrivo in token che un modello può mappare e tradurre efficacemente tra le lingue.
Riconoscimento vocale:** La tokenizzazione aiuta a convertire il linguaggio parlato in testo segmentando l'input audio in token da elaborare, consentendo ai sistemi di comprendere le parole pronunciate in modo strutturato.
La tokenizzazione è essenziale per l'analisi del sentiment, in quanto scompone il testo in token da elaborare ulteriormente per determinare se il sentiment espresso è positivo, negativo o neutro.
La tokenizzazione consente ai chatbot e agli assistenti virtuali di comprendere ed elaborare le richieste degli utenti suddividendo il testo in unità gestibili. Ciò consente loro di rispondere in modo intelligente in base all'input.
Strumenti per la tokenizzazione
Diversi strumenti sono comunemente utilizzati per la tokenizzazione in NLP:
NLTK: È una potente libreria Python per l'elaborazione del linguaggio naturale, che fornisce strumenti per la tokenizzazione, lo stemming, la lemmatizzazione, il POS tagging e altro ancora.
SpaCy: Una libreria NLP veloce con un potente tokenizer per parole e frasi e una tokenizzazione personalizzabile, che la rende uno strumento indispensabile per le applicazioni industriali.
Hugging Face Tokenizer: Tokenizza modelli basati su trasformatori come BERT e GPT con gestione delle sottoparole.
Gensim: Popolare per la modellazione di argomenti, include funzioni di preelaborazione e tokenizzazione del testo.
Tokenizzazione nel database vettoriale Milvus
Un database vettoriale è progettato per memorizzare, indicizzare e cercare dati non strutturati - come testo, immagini e video - utilizzando incorporazioni vettoriali ad alta dimensione. Queste incorporazioni consentono un rapido recupero delle informazioni semantiche e ricerche basate sulla similarità, rendendo i database vettoriali essenziali per applicazioni come i sistemi di raccomandazione, i motori di ricerca e i flussi di lavoro dell'intelligenza artificiale.
La tokenizzazione è il primo passo di questo processo. Scompone il testo grezzo in unità più piccole, come parole, frasi o sottoparole, che vengono poi convertite in rappresentazioni numeriche (embeddings vettoriali) da modelli di apprendimento automatico. Milvus, un database vettoriale open-source sviluppato da Zilliz, memorizza queste incorporazioni in uno spazio ad alta dimensione dove possono essere interrogate in modo efficiente per verificare la similarità.
Tokenizzazione integrata in Milvus
Milvus semplifica la tokenizzazione con i suoi analizzatori incorporati, che si adattano a lingue e casi d'uso diversi. Questi analizzatori integrano tokenizer e filtri per elaborare i dati di testo per un'indicizzazione e un recupero efficienti:
Analizzatore standard: L'analizzatore predefinito per l'elaborazione generale del testo. Esegue una tokenizzazione basata sulla grammatica, converte i token in minuscolo e supporta ricerche senza distinzione tra maiuscole e minuscole.
Analizzatore inglese**: Progettato specificamente per il testo inglese. Include l'attenuazione (riduzione delle parole alla loro forma radicale) e la rimozione delle più comuni stop words, concentrandosi sui termini significativi.
Analizzatore cinese**: Ottimizzato per l'elaborazione del testo cinese, con tokenizzazione progettata per gestire le strutture linguistiche uniche.
Questi analizzatori integrati consentono agli sviluppatori di inserire il testo grezzo direttamente in Milvus senza dover ricorrere a una pre-elaborazione esterna, semplificando i flussi di lavoro e riducendo la complessità.
Come Milvus gestisce la tokenizzazione
A partire da Milvus 2.5, il database include capacità integrate di full-text search, che gli consentono di elaborare internamente gli input di testo grezzo. Quando si inseriscono dati di testo, Milvus utilizza l'analizzatore specificato per tokenizzare il testo in singoli termini ricercabili. Questi termini vengono poi convertiti in rappresentazioni vettoriali rade utilizzando algoritmi come BM25 e memorizzati per un recupero efficiente.
Questo approccio ibrido consente a Milvus di gestire sia vettori densi (embeddings semantici) sia vettori radi (rappresentazioni basate su parole chiave). Di conseguenza, Milvus supporta scenari di ricerca ibridi avanzati che combinano la comprensione semantica con la precisione delle parole chiave, il tutto gestendo la tokenizzazione e la vettorizzazione senza soluzione di continuità all'interno del database.
Vantaggi della tokenizzazione integrata in Milvus
Flusso di lavoro semplificato**: Gli analizzatori integrati di Milvus eliminano la necessità di strumenti di tokenizzazione esterni, facilitando l'inserimento diretto di dati testuali grezzi.
Capacità di ricerca migliorate: Combinando la ricerca full-text con la [ricerca per similarità vettoriale] (https://zilliz.com/learn/vector-similarity-search), Milvus offre risultati altamente accurati e pertinenti per diverse applicazioni.
Scalabilità: La gestione interna della tokenizzazione e della vettorizzazione garantisce che Milvus possa elaborare in modo efficiente dati testuali su larga scala in una varietà di casi d'uso.
Grazie a queste caratteristiche, Milvus consente agli sviluppatori di creare più facilmente applicazioni di ricerca e analisi intelligenti, concentrandosi sull'innovazione piuttosto che sulle complessità della preelaborazione del testo. Che si tratti di ricerca in linguaggio naturale, di raccomandazioni guidate dall'intelligenza artificiale o di sistemi di recupero ibridi, Milvus offre una piattaforma robusta e facile da sviluppare per alimentare le vostre applicazioni.
Domande frequenti sulla tokenizzazione
**01. Perché la tokenizzazione è importante in NLP?
La tokenizzazione converte il testo non strutturato in unità gestibili, consentendo ai computer di elaborare il linguaggio. Aiuta i modelli NLP ad assegnare rappresentazioni numeriche ai token, consentendo operazioni matematiche ed estraendo modelli significativi.
**02. Qual è la differenza tra tokenizzazione di parole e caratteri?
La tokenizzazione delle parole divide il testo in singole parole, trattando ogni parola come un token separato. La tokenizzazione dei caratteri, invece, scompone il testo in singoli caratteri.
**03. Che cosa sono la lemmatizzazione e la tokenizzazione?
La tokenizzazione divide il testo in unità più piccole, come parole o frasi, facilitando l'elaborazione da parte dei computer. La lemmatizzazione riduce le parole alla loro forma base, come ad esempio la conversione di "running" in "run", assicurando coerenza nella comprensione del linguaggio.
**04. Come influisce la tokenizzazione sulle prestazioni del modello?
La tokenizzazione influisce sul modo in cui il testo viene scomposto e compreso da un modello. Una corretta tokenizzazione può migliorare le prestazioni del modello catturando relazioni accurate tra le parole, mentre una tokenizzazione inadeguata può portare a interpretazioni errate o alla perdita di significato.
**05. Quale ruolo svolge la tokenizzazione nella sentiment analysis o nella classificazione del testo?
Nell'analisi del sentiment e nella classificazione del testo, la tokenizzazione spezza il testo in unità più piccole, come parole o frasi, che possono essere analizzate per individuare modelli o sentimenti. Questo processo consente agli algoritmi di elaborare i singoli token e di classificare o assegnare il sentiment al testo in modo accurato.
Risorse correlate
- TL; DR
- Introduzione
- Cos'è la tokenizzazione?
- Perché abbiamo bisogno della tokenizzazione?
- Concetti chiave della tokenizzazione
- Tipi di tokenizzazione
- Confronto tra tokenizzazione e incorporazione di parole
- Vantaggi e sfide della tokenizzazione
- Casi d'uso della tokenizzazione
- Strumenti per la tokenizzazione
- Tokenizzazione nel database vettoriale Milvus
- Domande frequenti sulla tokenizzazione
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente