




SuperGLUE: un benchmark completo per la valutazione avanzata di NLP
SuperGLUE: un benchmark completo per la valutazione avanzata di NLP
TL; DR
SuperGLUE (Super General Language Understanding Evaluation) è un benchmark progettato per valutare le prestazioni dei modelli di comprensione del linguaggio naturale (NLU). Basandosi sul suo predecessore, GLUE, introduce compiti più impegnativi per valutare la capacità di un modello di gestire ragionamenti linguistici complessi, come la risposta a domande, la risoluzione di coreferenze e l'inferenza. SuperGLUE include una serie di set di dati e metriche diverse, oltre a testare abilità come la comprensione contestuale, il recupero della conoscenza e l'apprendimento multi-task. Sviluppato per superare i limiti dell'NLU, riflette compiti più vicini al ragionamento umano. Ottenere punteggi elevati in SuperGLUE indica la robustezza e l'efficacia di un modello nell'affrontare le sfide linguistiche del mondo reale.
Introduzione
L'elaborazione del linguaggio naturale (NLP) ha trasformato il modo in cui le macchine interagiscono con gli esseri umani, dai chatbot ai sistemi di raccomandazione. Modelli come ELMo, BERT e GPT hanno ridefinito la soglia di comprensione del linguaggio, migliorando la modellazione e la comprensione del linguaggio umano. Queste trasformazioni hanno aperto la strada al benchmark GLUE , un mezzo di valutazione sistematico che valuta la competenza dei modelli linguistici in vari compiti.
Tuttavia, man mano che i modelli NLP diventano più intelligenti, diventa chiaro che ci troviamo di fronte a una sfida più difficile. È qui che entra in gioco ****SuperGLUE che, con obiettivi più ambiziosi e impegnativi, propone una nuova serie di compiti basati sul ragionamento, sulla comprensione del senso comune e sull'interpretazione contestuale sfumata. SuperGLUE mette alla prova la capacità di qualsiasi modello di risolvere i problemi linguistici del mondo reale, mettendo quindi a dura prova i modelli NLP.
In questo articolo esploreremo le caratteristiche uniche di SuperGLUE, i compiti che include e come sta guidando lo sviluppo di modelli NLP ancora più sofisticati e affidabili.
Che cos'è SuperGLUE?
SuperGLUE, acronimo di Super General Language Understanding Evaluation, è un benchmark creato per verificare la capacità dei modelli NLP di gestire un'ampia gamma di compiti complessi di comprensione del linguaggio. Si tratta essenzialmente di una versione aggiornata di GLUE, progettata per alzare l'asticella. Mentre GLUE si concentra su compiti più semplici, SuperGLUE include sfide più sofisticate che richiedono un ragionamento più approfondito, conoscenze di senso comune e comprensione del contesto. Per esempio, mentre un compito GLUE può valutare se due frasi sono semanticamente simili, un compito SuperGLUE come la Winograd Schema Challenge (WSC) richiede di risolvere pronomi ambigui usando il ragionamento di senso comune.
SuperGLUE conserva due dei compiti più impegnativi di GLUE (RTE e WNLI) e introduce sei compiti completamente nuovi, progettati per spingere i modelli al di là della semplice corrispondenza di schemi e per entrare nella conoscenza semantica e pragmatica.
Quali sono gli obiettivi di SuperGLUE?
SuperGLUE va oltre l'elaborazione linguistica di base: è stato progettato per verificare se i modelli sono in grado di ragionare, fare inferenze e utilizzare le conoscenze di senso comune in scenari complessi.
Incoraggiare i progressi dell'NLP:** Introducendo compiti più difficili, SuperGLUE motiva i ricercatori a sviluppare tecniche di apprendimento automatico più avanzate e capaci.
A differenza di GLUE, che si concentra su sfide più semplici, SuperGLUE offre un modo più realistico e completo per testare le prestazioni dei modelli con input complessi e reali.
SuperGLUE è stato costruito pensando al futuro: è abbastanza impegnativo da consentire anche ai migliori modelli di oggi di migliorare, il che lo rende uno strumento prezioso per monitorare i progressi nel campo dell'NLP.
Come funziona SuperGLUE
SuperGLUE valuta i modelli NLP mettendo alla prova le loro capacità linguistiche. Questi compiti richiedono ai modelli di fare molto di più che classificare frasi o prevedere singole parole: devono affrontare le complessità del mondo reale. Tra questi, la risoluzione di coreferenze (capire quali parole o frasi si riferiscono alla stessa cosa), il ragionamento (trarre conclusioni logiche dal testo) e la comprensione delle relazioni tra entità nel contesto. Ogni compito misura la capacità dei modelli di gestire le richieste sofisticate e ricche di sfumature del linguaggio umano.
Una panoramica dettagliata dei compiti
SuperGLUE è un superset di molti compiti, che tratteremo in questa sezione. Prima di ciò, vedremo le diverse metriche di valutazione necessarie per assegnare un punteggio alle prestazioni del modello.
Metriche di valutazione
SuperGLUE impiega diverse metriche di valutazione a seconda del compito:
Corrispondenza esatta (EM): Utilizzata per i compiti che devono valutare se la risposta prevista corrisponde esattamente alla risposta attesa.
Punteggio 1: Misura la precisione e il richiamo quando sono possibili più risposte corrette.
Accuracy: La percentuale di esempi predetti correttamente, utilizzata in compiti di classificazione più semplici come BoolQ.
Macro-Averaged F1: Una media dei punteggi F1 delle varie classi, che assicura una valutazione equilibrata anche in caso di squilibrio tra le classi.
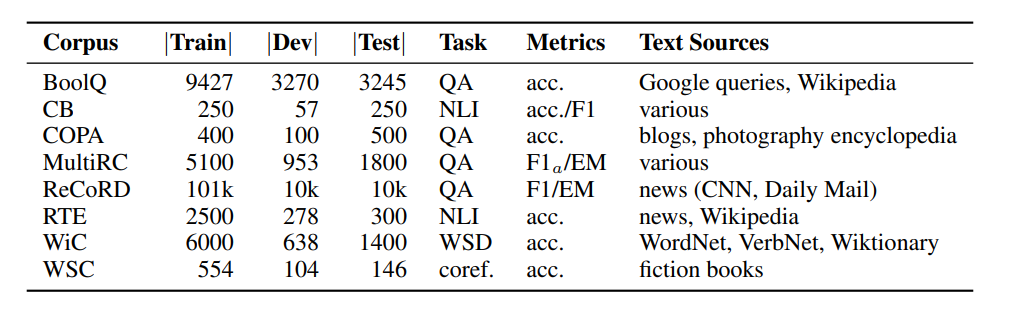 Figura- SuperGLUE Benchmark- Tabella riassuntiva dei compiti di SuperGLUE, comprese le dimensioni del corpus, le metriche e le fonti di testo per ogni compito..png
Figura- SuperGLUE Benchmark- Tabella riassuntiva dei compiti di SuperGLUE, comprese le dimensioni del corpus, le metriche e le fonti di testo per ogni compito..png
Figura: Benchmark SuperGLUE: Tabella riassuntiva dei compiti di SuperGLUE, comprese le dimensioni del corpus, le metriche e le fonti di testo per ogni compito.
Esploriamo la panoramica dettagliata dei compiti di SuperGLUE per comprendere la profondità e la varietà delle sue sfide.
- BoolQ (Domande booleane)
BoolQ è un compito di risposta a domande binarie in cui il modello determina se una domanda sì/no è vera sulla base di un dato passaggio. Ecco l'input, l'output e la metrica del compito:
| Input | Output | Metrica |
|---|---|---|
| Un brano e una domanda sì/no sul brano. | Un valore booleano (Vero per il sì, Falso per il no). | Accuratezza |
Ecco un esempio:
Passaggio: "Barq's è una bevanda analcolica che contiene caffeina ed è imbottigliata dalla Coca-Cola".
Domanda: "La root beer di Barq's contiene caffeina?".
Output: True
- CB (CommitmentBank)
CB consiste nel valutare se una clausola incorporata in un testo è probabilmente vera (implicazione), falsa (contraddizione) o indeterminata (neutrale).
| Input | Output | Metrica |
|---|---|---|
| Una premessa e un'ipotesi. | Un'etichetta (implicita, neutra o di contraddizione). | Accuratezza e F1 macro-mediata. |
Ecco un esempio:
Premessa: "Ha detto che potrebbe partecipare alla riunione".
Ipotesi: "È certo che parteciperà alla riunione".
Output: Contraddizione
- COPA (Scelta di alternative plausibili)
COPA è un compito di ragionamento causale in cui il modello determina la causa o l'effetto più plausibile di una data premessa tra due alternative.
| Input | Output | Metrica |
|---|---|---|
| Una premessa e due alternative (causa/effetto). | L'alternativa più plausibile (1 o 2). | Precisione |
Vediamo un esempio:
Premessa: "L'erba è bagnata".
Alternativa 1: "Ieri sera ha piovuto".
Alternativa 2: "Il sole splendeva luminoso".
Uscita: 1
- MultiRC (Comprensione della lettura di più frasi)
MultiRC consiste nel rispondere a domande basate su un brano, dove ogni domanda può avere più risposte corrette.
| Input | Output | Metric |
|---|---|---|
| Un brano, una domanda e un insieme di possibili risposte. | Un'etichetta binaria (Vero o Falso) per ogni risposta. | F1 e corrispondenza esatta. |
Ecco un semplice esempio:
Passaggio: "Susan ha invitato i suoi amici a una festa. Uno dei suoi amici era malato, ma poi ha partecipato".
Domanda: "L'amico malato ha partecipato alla festa?".
Risposte: "Sì", "No"
Uscita: Sì
- ReCoRD (Reading Comprehension with Commonsense Reasoning Dataset)
ReCoRD è un compito di comprensione della lettura in stile Cloze che richiede un ragionamento di senso comune per prevedere entità mascherate in un brano.
| Input | Output | Metrica |
|---|---|---|
| Un brano con entità mascherate e un'interrogazione. | L'entità corretta da un elenco di candidati. | F1 e EM. |
Ecco un semplice esempio:
Passaggio: "Tesla è stata fondata da
Domanda: "Chi ha fondato Tesla?".
Candidati: "Elon Musk", "Nikola Tesla", "Thomas Edison".
Uscita: Elon Musk
- RTE (Riconoscimento del dettaglio testuale)
RTE determina se un'ipotesi è vera, falsa o indeterminata sulla base di una premessa data.
| Input | Output | Metrica |
|---|---|---|
| Una premessa e un'ipotesi. | Un'etichetta (implicita, neutra o di contraddizione). | Accuratezza |
Ecco un esempio:
Premessa: "Dana Reeve, la vedova di Christopher Reeve, è morta a 44 anni".
Ipotesi: "Dana Reeve aveva 44 anni quando è morta".
Output: Descrizione
- WiC (Parola nel contesto)
WiC verifica la disambiguazione del senso delle parole determinando se una parola è usata con lo stesso significato in due contesti diversi.
| Input | Output | Metrica |
|---|---|---|
| Due frasi contenenti la stessa parola target. | Un'etichetta binaria (Vero per lo stesso senso, Falso per un senso diverso). | Accuratezza |
Vediamo un esempio:
Frase 1: "Inchiodò le tavole al muro".
Frase 2: "La scacchiera era ben realizzata".
Parola obiettivo: "scacchiera"
Uscita: Falso
- WSC (Winograd Schema Challenge)
WSC è un compito di risoluzione delle coreferenze in cui il modello identifica il referente corretto di un pronome ambiguo usando un ragionamento di senso comune.
| Input | Output | Metrico |
|---|---|---|
| Una frase contenente un pronome ambiguo. | Il referente corretto. | Accuratezza |
Ecco un esempio:
Sentenza: "Mark ha dato un libro a Ted, ma non gli è piaciuto".
Pronome: "lui"
Uscita: Ted
I compiti sopra descritti in SuperGLUE mettono alla prova i modelli NLP al di là della semplice comprensione del linguaggio, per la quale ogni sistema dovrebbe costruire ragionamenti ricchi di sfumature e risolvere i problemi del mondo reale. Pertanto, SuperGLUE valuta il modello in base alla comprensione, al ragionamento e all'applicazione efficace della conoscenza del senso comune. Fornisce un quadro di valutazione completo che cattura sia la precisione che il richiamo dei modelli in diverse sfide di comprensione del linguaggio.
Esempio di implementazione
Di seguito è riportato un esempio di caricamento e interazione con il task ReCoRD di SuperGLUE utilizzando la libreria Hugging Face:
da datasets import load_dataset
# Carica il task ReCoRD da SuperGLUE
dataset = load_dataset("super_glue", "record", trust_remote_code = True
)
# Accedere ai dati di addestramento
train_data = dataset['train']
# Punto di dati di esempio
esempio = train_data[0]
print(f "Passaggio: {esempio['passaggio']}")
print(f "Query con entità mascherata: {esempio['query']}")
La funzioneload_dataset carica il task ReCoRD. L'input include un passaggio e una query con un'entità mascherata che deve essere risolta. Il modello mira a prevedere correttamente l'entità mascherata, dimostrando la sua capacità di comprendere il brano e di applicare il ragionamento di senso comune.
 Figura- Output dell'esempio implementato.png
Figura- Output dell'esempio implementato.png
Figura: Output dell'esempio implementato
SuperGLUE vs. GLUE: differenze chiave
SuperGLUE migliora GLUE introducendo compiti significativamente più impegnativi che riflettono la comprensione del linguaggio del mondo reale.
| Caratteristiche | GLUE | SuperGLUE |
|---|---|---|
| Complessità del compito | Compiti linguistici di base (ad esempio, sentiment analysis) | Compiti complessi che richiedono ragionamento e buon senso |
| Saturazione del dataset** | Prestazioni vicine al livello umano | Ampio margine per il miglioramento dei modelli |
| Ragionamento richiesto | Ragionamento minimo richiesto | Ragionamento e inferenza di alto livello sono necessari |
| Diversità dei compiti | Principalmente compiti di classificazione e somiglianza delle frasi | Include QA, coreferenza e comprensione della lettura |
| Applicazione al mondo reale | Riflessione limitata al mondo reale | Compiti progettati per emulare le sfide linguistiche del mondo reale |
Vantaggi e sfide di SuperGLUE
SuperGLUE sostituisce il modo in cui i modelli NLP sono stati valutati, spostando l'attenzione sulla loro capacità di risolvere compiti del mondo reale con sfumature che richiedono ragionamento e contesto avanzato. Discutiamo alcuni vantaggi concreti che SuperGLUE conferisce alla PNL e le sfide che i ricercatori devono affrontare per utilizzarlo al massimo delle sue potenzialità.
Benefici
SuperGLUE include compiti che richiedono ai modelli di utilizzare le conoscenze di senso comune. Ad esempio, la Winograd Schema Challenge (WSC) mette alla prova la risoluzione dei pronomi usando il senso comune, mentre il compito COPA valuta il ragionamento causale scegliendo la causa o l'effetto più plausibile in un determinato scenario. Questi compiti li rendono più capaci di affrontare gli scenari del mondo reale.
SuperGLUE supera la saturazione di GLUE, dove i modelli raggiungevano prestazioni quasi umane su compiti più semplici, rendendolo meno efficace per distinguere i progressi.
Promuove la spiegabilità dei modelli: i compiti complessi di SuperGLUE incoraggiano lo sviluppo di modelli che hanno buone prestazioni e forniscono risultati più interpretabili, aiutando i ricercatori a capire come e perché i modelli fanno previsioni specifiche.
I compiti di SuperGLUE sono progettati per riflettere i problemi che i modelli incontrano in applicazioni come la comprensione della lettura e i sistemi di dialogo. Per esempio, il compito ReCoRD verifica il ragionamento di senso comune per dedurre le informazioni mancanti, mentre WSC valuta la risoluzione di pronomi ambigui, capacità fondamentali per gli assistenti virtuali e l'intelligenza artificiale conversazionale.
SuperGLUE permette ai ricercatori di esaminare come e dove i modelli falliscono, fornendo compiti diversi e impegnativi che mettono in evidenza punti deboli specifici. Questa analisi dettagliata degli errori aiuta a identificare le aree in cui i modelli hanno difficoltà, come il ragionamento, la comprensione del senso comune o la comprensione del contesto, consentendo miglioramenti mirati per rendere i modelli più robusti e affidabili.
Sfide
Elevati costi computazionali: L'addestramento dei modelli su SuperGLUE può essere computazionalmente costoso a causa della complessità dei compiti. L'utilizzo di architetture ottimizzate e di infrastrutture basate su cloud può aiutare a gestire efficacemente la richiesta di risorse.
Ogni attività di SuperGLUE può richiedere diverse strategie di messa a punto. Gli approcci di apprendimento multi-task e l'apprendimento per trasferimento possono aiutare a semplificare questo processo. L'apprendimento multi-task addestra un modello su attività correlate per migliorare la generalizzazione, mentre l'apprendimento per trasferimento applica le conoscenze di un'attività per migliorare le prestazioni su un'altra, riducendo al minimo la necessità di dati e addestramento estesi.
Alcune attività di SuperGLUE sono dotate di dati limitati, il che aumenta il rischio di overfitting dei modelli durante l'addestramento. Questa sfida può essere affrontata impiegando tecniche come l'aumento dei dati per creare campioni di formazione più diversificati e la regolarizzazione per migliorare la generalizzazione del modello.
Sebbene le classifiche dei leader mostrino le prestazioni dei modelli, concentrarsi esclusivamente su questi punteggi può sminuire il valore pratico dei modelli. Spostare l'attenzione sulle applicazioni del mondo reale aiuta a garantire che i modelli siano competitivi e di impatto in scenari pratici.
La variabilità delle implementazioni, dell'hardware e degli iperparametri può rendere difficile un confronto equo dei risultati tra i gruppi di ricerca. Standardizzando i protocolli di valutazione, condividendo le basi di codice e utilizzando benchmark comuni, possiamo ottenere confronti più coerenti ed equi.
Casi d'uso di SuperGLUE
SuperGLUE è un importante benchmark che aiuta a migliorare l'NLP mettendo alla prova i modelli con compiti basati sulle complessità del mondo reale. Gli esempi di utilizzo possono spaziare dal miglioramento dell'IA conversazionale e dei sistemi di ragionamento alla ricerca semantica.
SuperGLUE ha numerose applicazioni in NLP e non solo:
SuperGLUE migliora lo sviluppo degli assistenti virtuali fornendo parametri di riferimento che mettono alla prova la capacità dei modelli di comprendere le richieste più complesse con un ragionamento migliore e con buon senso.
Sistemi di ragionamento avanzato: SuperGLUE favorisce la creazione di strumenti di supporto alle decisioni valutando e migliorando le capacità di inferenza logica dei modelli.
Comprensione della lettura: SuperGLUE consente ai modelli NLP di analizzare e riassumere accuratamente documenti lunghi, sfidandoli con compiti che richiedono una comprensione avanzata e contestuale, aiutando la ricerca e l'istruzione.
Rappresentazione e inferenza della conoscenza: SuperGLUE aiuta a costruire grafi di conoscenza più robusti, testando la capacità dei modelli di comprendere le relazioni e di applicare ragionamenti di senso comune, a supporto dei motori di ricerca e dei sistemi di raccomandazione.
Ricerca semantica e database vettoriali: SuperGLUE migliora l'accuratezza della ricerca semantica consentendo ai modelli di gestire efficacemente attività di recupero di informazioni complesse e su larga scala.
Strumenti che supportano SuperGLUE
I compiti e i benchmark avanzati di SuperGLUE hanno portato allo sviluppo di altri strumenti e piattaforme progettati per facilitarne l'implementazione e la valutazione. Questi strumenti aiutano i ricercatori e gli sviluppatori a prendere decisioni migliori per quanto riguarda l'accesso ai dati, la formazione dei modelli e l'analisi dei risultati.
Vediamo gli strumenti che supportano e migliorano l'adozione e l'interazione con SuperGLUE.
Strumenti
Fornisce un modo semplice per caricare e interagire con le attività di SuperGLUE, semplificando lo sviluppo e la verifica dei modelli.
Offre versioni preformattate delle attività di SuperGLUE, che si integrano bene con i modelli basati su [TensorFlow] (https://www.tensorflow.org/datasets/catalog/super_glue).
AllenNLP: Fornisce moduli e componenti per compiti NLP, semplificando la sperimentazione con SuperGLUE.
Valutare i modelli di intelligenza artificiale con SuperGLUE e migliorarli con RAG
I benchmark come SuperGLUE sono essenziali per valutare le capacità dei modelli linguistici di grandi dimensioni (LLMs. Essi forniscono un quadro standardizzato per misurare le prestazioni di un modello in diversi compiti e facilitano il confronto diretto tra i modelli. Evidenziando i punti di forza, come il ragionamento, ed esponendo i punti deboli, come le difficoltà nel ragionamento complesso o i compiti specifici del dominio, SuperGLUE aiuta i ricercatori a identificare le aree di miglioramento. Queste intuizioni consentono di perfezionare la messa a punto, migliorando le capacità di comprensione e di generazione di contenuti di un modello.
Tuttavia, anche se SuperGLUE è prezioso per migliorare gli LLM, non è una panacea. Gli LLM hanno dei limiti intrinseci, a prescindere dalle loro prestazioni nei benchmark. Sono addestrati su insiemi di dati statici e offline e non hanno accesso a informazioni in tempo reale o specifiche del dominio. Questo può portare a allucinazioni, in cui i modelli generano risposte imprecise o inventate. Queste carenze diventano ancora più problematiche quando si affrontano query proprietarie o altamente specializzate.
Introduzione di RAG: una soluzione per migliorare le risposte dei LLM
Per affrontare queste sfide, Retrieval-Augmented Generation (RAG) offre una potente soluzione. RAG migliora i modelli linguistici di grandi dimensioni (LLM) combinando le loro capacità generative con la capacità di recuperare informazioni specifiche del dominio da basi di conoscenza esterne memorizzate in un database vettoriale come Milvus o Zilliz Cloud. Quando un utente pone una domanda, il sistema RAG cerca nel database le informazioni pertinenti e le utilizza per generare una risposta più accurata. Vediamo come funziona il processo RAG.
 Figura - Flusso di lavoro RAG.png
Figura - Flusso di lavoro RAG.png
Un sistema RAG è solitamente costituito da tre componenti chiave: un embedding model, un vector database e un LLM.
Il modello di embedding converte i documenti in embeddings vettoriali, che vengono memorizzati in un database vettoriale come Milvus.
Quando un utente pone una domanda, il sistema trasforma la richiesta in un vettore utilizzando lo stesso modello di embedding.
Il database vettoriale esegue quindi una [ricerca di similarità] (https://zilliz.com/learn/vector-similarity-search) per recuperare le informazioni più rilevanti. Le informazioni recuperate vengono combinate con la domanda originale per formare una "domanda con contesto", che viene poi inviata al LLM.
L'LLM elabora questo input arricchito per generare una risposta più accurata e pertinente al contesto.
Questo approccio colma il divario tra gli LLM statici e le esigenze specifiche del dominio in tempo reale.
FAQ di SuperGLUE
**SuperGLUE si basa su GLUE introducendo compiti di ragionamento e di buon senso che vanno ben oltre quelli presenti in GLUE.
**I modelli basati sui trasformatori eccellono in SuperGLUE grazie al loro meccanismo di autoattenzione, che cattura il contesto e le dipendenze a lungo raggio, al preallenamento esteso su grandi insiemi di dati, alla scalabilità e all'adattabilità attraverso l'apprendimento per trasferimento.
**L'addestramento dei modelli su SuperGLUE richiede risorse computazionali significative a causa della complessità dei compiti, che richiedono un'ampia potenza di elaborazione per la messa a punto, il ragionamento e la gestione efficace di grandi insiemi di dati.
**Sebbene si concentri sulla generalizzazione, la personalizzazione per domini specifici è possibile con un'ulteriore messa a punto con dati specifici.
**In che modo SuperGLUE è rilevante per le moderne applicazioni di IA? ** Stabilisce uno standard per la valutazione dei modelli in applicazioni reali come la ricerca semantica e l'IA conversazionale.
Risorse correlate
- TL; DR
- Introduzione
- Che cos'è SuperGLUE?
- Come funziona SuperGLUE
- SuperGLUE vs. GLUE: differenze chiave
- Vantaggi e sfide di SuperGLUE
- Casi d'uso di SuperGLUE
- Strumenti che supportano SuperGLUE
- Valutare i modelli di intelligenza artificiale con SuperGLUE e migliorarli con RAG
- FAQ di SuperGLUE
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente