




Scalabile e affidabile: Una semplice guida al calcolo distribuito

Scalabile e affidabile: Una semplice guida al calcolo distribuito
L'informatica distribuita è la pratica di eseguire attività o processi su più computer collegati per aumentare le prestazioni, la scalabilità e l'affidabilità. Invece di affidarsi a un'unica macchina potente, il carico di lavoro viene suddiviso tra più nodi, che possono gestire in modo più efficiente set di dati e calcoli più grandi. Questo approccio costituisce la spina dorsale di molte applicazioni moderne basate sui dati, tra cui piattaforme di e-commerce, pipeline di apprendimento automatico, analisi in tempo reale, reti di sensori IoT e simulazioni di ricerca ad alte prestazioni.
 Informatica distribuita
Informatica distribuita
Figura: Informatica distribuita
Da singoli server a sistemi distribuiti: L'evoluzione
Per molto tempo, molte organizzazioni si sono affidate a grandi server centralizzati, spesso chiamati architetture monolitiche, per eseguire le loro applicazioni. Tuttavia, questa configurazione presentava alcuni evidenti svantaggi:
Scalabilità limitata: Aggiungere più capacità significava acquistare server più grandi, il che era costoso e richiedeva molto tempo.
Punto di guasto unico: L'intero sistema si arrestava se il server principale si guastava.
Aggiornamenti complessi: Apportare modifiche o aggiornamenti era rischioso perché tutto era ospitato in un unico luogo.
I cluster, che raggruppano server più piccoli, hanno dato un po' di sollievo, ma non hanno risolto completamente i problemi di scaling e di affidabilità. È qui che è intervenuto il calcolo distribuito. Dividendo le attività e i dati su più nodi collegati, i sistemi distribuiti:
scalano più velocemente e in modo più conveniente: È possibile aggiungere altri nodi invece di sostituire un singolo server di grandi dimensioni.
Migliorano la tolleranza ai guasti**: Se un nodo si guasta, gli altri possono mantenere il sistema online.
Gestire carichi di lavoro pesanti**: Più nodi che lavorano insieme possono elaborare grandi volumi di dati in modo più efficiente.
Soluzioni moderne come Milvus di Zilliz si basano su questi principi per gestire grandi quantità di dati ad alta dimensionalità. Milvus supporta ricerche di similarità su larga scala distribuendo i dati su più nodi e mantenendo prestazioni elevate anche in condizioni difficili.
Come funziona l'informatica distribuita?
L'informatica distribuita è un modello in cui più macchine (o nodi) lavorano insieme per svolgere compiti che sarebbero difficili o inefficienti da gestire su una singola macchina. Ogni nodo di un sistema distribuito può svolgere funzioni specifiche, come l'archiviazione di dati o l'elaborazione di calcoli, e il sistema coordina questi compiti per operare come un insieme unificato. Questo approccio consente quindi di ottenere prestazioni più elevate, una migliore [tolleranza ai guasti] (https://zilliz.com/ai-faq/how-do-distributed-databases-ensure-fault-tolerance) e opzioni di scalabilità flessibili.
Principi fondamentali
L'idea principale alla base dell'elaborazione distribuita è quella di suddividere i lavori di grandi dimensioni in attività più piccole e assegnarle ai vari nodi. Dividendo i carichi di lavoro, ogni nodo può lavorare sul proprio pezzo in parallelo, il che accelera l'elaborazione e impedisce a una macchina di sovraccaricarsi.
Data Partitioning: I dati vengono suddivisi in segmenti (spesso chiamati "shard"). Ogni nodo memorizza uno o più di questi segmenti per letture e scritture parallele. Questo accelera l'accesso ai dati e facilita la scalabilità: quando i dati crescono, si aggiungono altri nodi e si partizionano ulteriormente.
Sincronizzazione e coordinamento: Poiché le attività e i dati sono distribuiti, diventa fondamentale che i nodi rimangano sincronizzati per evitare aggiornamenti in conflitto. I sistemi distribuiti utilizzano protocolli e algoritmi, come i meccanismi di consenso, per garantire che ogni nodo mantenga una visione coerente dei dati. Questi metodi aiutano tutte le parti del sistema a concordare le modifiche, anche quando avvengono contemporaneamente.
Componenti dei sistemi distribuiti
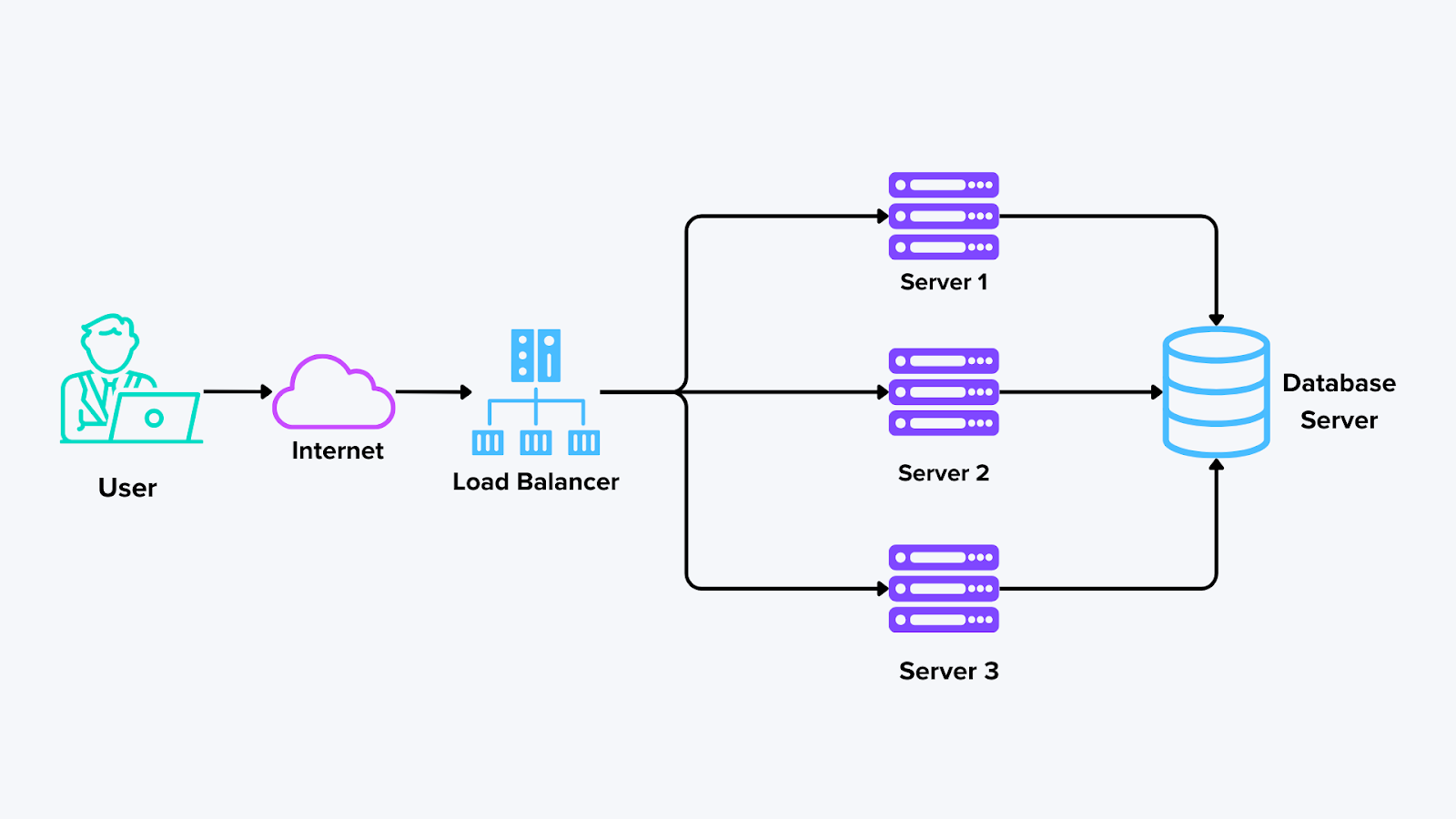 Componenti di sistemi distribuiti
Componenti di sistemi distribuiti
Figura: Componenti di un sistema distribuito
Nodi (o Host): Ogni nodo esegue attività o memorizza dati. In molti casi, i nodi possono essere server fisici, macchine virtuali o container. Quando si utilizza un sistema come Milvus, ogni nodo può contenere un segmento dell'indice vettoriale, consentendo ricerche distribuite su grandi insiemi di dati senza sovraccaricare una singola macchina.
Rete: La rete è il collante che collega tutti i nodi. Trasporta dati e messaggi tra le macchine per condividere i risultati e aggiornarsi a vicenda. Le connessioni di rete affidabili e veloci sono fondamentali per una comunicazione senza interruzioni.
Quando più nodi sono pronti ad accettare le richieste in arrivo, i [bilanciatori di carico] (https://zilliz.com/ai-faq/how-do-distributed-databases-perform-load-balancing) distribuiscono il traffico in modo uniforme. In questo modo si evita che un nodo gestisca troppe richieste contemporaneamente. Distribuendo il carico, il sistema può gestire i picchi di traffico e mantenere prestazioni costanti.
Server di database: Un server di database è responsabile dell'archiviazione, della gestione e del recupero di dati strutturati o non strutturati su più nodi. In un'architettura distribuita, i database possono essere shardati (dividendo i dati in parti più piccole tra i vari nodi) o replicati (mantenendo copie dei dati tra i nodi per la tolleranza ai guasti).
Code di messaggi e servizi di coordinamento: I sistemi distribuiti spesso si affidano a strumenti di messaggistica (come Apache Kafka o NATS) o a servizi di coordinamento (come ZooKeeper) per gestire la comunicazione tra i nodi. Questi strumenti aiutano a programmare le attività, a tenere traccia dei progressi e ad assicurarsi che due nodi non stiano eseguendo lo stesso lavoro contemporaneamente. Inoltre, gestiscono gli annunci a livello di sistema, ad esempio quando un nodo diventa online o va offline, in modo che il resto del sistema possa adattarsi.
Tipi di architetture di calcolo distribuito
L'informatica distribuita può assumere diverse forme, a seconda di come i nodi interagiscono e condividono le responsabilità. Di seguito sono riportate alcune architetture comuni, insieme ad esempi di funzionamento in diversi scenari, tra cui il database Milvus. La scelta della giusta architettura distribuita dipende dalle dimensioni del carico di lavoro, dai requisiti di latenza e dai vincoli di costo.
Tipi di calcolo distribuito](https://assets.zilliz.com/Types_of_Distributed_Computing_524a467d73.png)
Figura: Tipi di elaborazione distribuita
1. Modello client-server
Nel modello client-server, uno o più server centrali gestiscono le richieste provenienti da più dispositivi client. Ogni server è in genere più potente di un singolo client e ospita la logica aziendale principale o l'archiviazione dei dati. I client inviano richieste (come l'acquisizione di dati o l'esecuzione di calcoli) e i server rispondono con le informazioni o i risultati richiesti.
Pro: Chiara separazione dei ruoli, controllo centralizzato e gestione semplificata della sicurezza.
Cons: I clienti possono perdere l'accesso al servizio se un server va in tilt. Anche la scalabilità può essere problematica se le richieste superano la capacità del server.
2. Reti Peer-to-Peer (P2P)
Le architetture peer-to-peer trattano tutti i nodi come uguali. Ogni nodo può agire sia come client che come server, condividendo risorse o file senza dipendere da un server centrale. In questa architettura, i nodi si connettono direttamente tra loro. Invece di richiedere dati a un singolo server autorevole, i peer si scambiano dati tra loro.
Pro: Non esiste un singolo punto di guasto e la scalabilità con l'aggiunta di altri peer può essere più semplice.
Cons: La gestione della coerenza dei dati e della qualità del servizio può essere difficile in ambienti completamente decentralizzati.
3. Cluster Computing
Un cluster è un gruppo di server che lavorano insieme in modo così stretto da sembrare un unico sistema. I compiti possono essere suddivisi tra i nodi per l'elaborazione in parallelo, rendendo il cluster computing popolare per i carichi di lavoro ad alte prestazioni. I server di un cluster spesso condividono lo storage e le attività sono suddivise tra loro da un sistema di pianificazione o da un bilanciatore di carico. Se un server si guasta, gli altri possono continuare a funzionare.
Architettura Milvus: Milvus utilizza nodi in cluster per gestire grandi volumi di dati vettoriali. Distribuendo gli indici vettoriali su più macchine è possibile gestire in modo efficiente miliardi di vettori ad alta dimensionalità. Questo approccio di clustering aumenta le prestazioni e la resilienza, soprattutto quando si tratta di carichi di lavoro massicci di ricerca o di raccomandazione.
Pro: Ottimo per l'elaborazione parallela e la tolleranza ai guasti.
Cons: Può essere complesso da gestire e richiede investimenti hardware più elevati.
4. Cloud e Edge Computing
Il cloud computing fornisce risorse on-demand (come macchine virtuali, storage e servizi) tramite Internet. L'Edge computing colloca l'elaborazione e l'archiviazione dei dati più vicino alla fonte dei dati (ad esempio, i dispositivi IoT) per ridurre la latenza. Nel cloud computing, le organizzazioni eseguono le applicazioni su server remoti gestiti da fornitori di cloud. La capacità è in genere scalabile con breve preavviso. Nell'edge computing, i dati generati dai dispositivi vengono elaborati localmente o in centri dati periferici vicini, riducendo la necessità di inviare tutto a un cloud centrale.
Pro: Scalabilità elastica, flessibilità e costi operativi potenzialmente inferiori. Le configurazioni edge migliorano anche la reattività per le attività sensibili al tempo.
Cons: Richiede connessioni di rete stabili (nel caso del cloud computing) e i dispositivi edge possono avere risorse limitate.
5. Microservizi
I microservizi suddividono un'applicazione in servizi più piccoli e non strettamente accoppiati che comunicano in rete. Ogni servizio gestisce una funzione specifica, come l'autenticazione dell'utente o l'indicizzazione dei dati. I servizi possono essere eseguiti su macchine o contenitori separati. Espongono API per la comunicazione e possono scalare in modo indipendente per adattarsi al loro carico di lavoro specifico.
Pro: Semplifica gli aggiornamenti, poiché ogni servizio può essere modificato senza influenzare l'intero sistema. Consente inoltre una scalabilità specializzata, in cui solo i servizi più utilizzati ricevono nodi aggiuntivi.
I contro**: aggiunge complessità alla gestione di molti servizi, garantendo al contempo un funzionamento regolare. Il monitoraggio, la registrazione e la distribuzione degli aggiornamenti richiedono un'attenta pianificazione.
Casi d'uso dell'informatica distribuita
L'informatica distribuita offre un'ampia gamma di soluzioni moderne. Di seguito sono riportati alcuni degli scenari più comuni in cui le organizzazioni traggono vantaggio dalla suddivisione dei carichi di lavoro e dei dati tra nodi interconnessi:
Le organizzazioni eseguono grandi insiemi di dati in parallelo su più nodi per accelerare l'analisi. I dati continuano ad affluire e gli aggiornamenti avvengono quasi istantaneamente. Questo è fondamentale nei settori della finanza, della sanità e dell'e-commerce, dove le decisioni vengono prese in tempi rapidi.
Apprendimento automatico e formazione di modelli di intelligenza artificiale:** I modelli complessi vengono formati più rapidamente quando i calcoli vengono eseguiti su più macchine contemporaneamente. Questa configurazione gestisce in modo efficiente grandi insiemi di funzioni e riduce il tempo complessivo di addestramento. È comune nel riconoscimento delle immagini, nell'NLP e nelle raccomandazioni personalizzate.
Le richieste vengono distribuite su più server, in modo da non sovraccaricare una singola macchina. Se un server si guasta, gli altri continuano a funzionare per evitare pesanti tempi di inattività. Grazie alla scalabilità flessibile, è più facile gestire i picchi improvvisi, come le vendite natalizie.
Internet degli oggetti (IoT) e reti di sensori:** Numerosi sensori alimentano i dati in nodi distribuiti, che li elaborano vicino alla fonte per ottenere risposte più rapide. Questo approccio localizzato migliora il monitoraggio e aiuta a ricevere avvisi in tempo reale. È ampiamente adottato nelle città intelligenti, nella produzione e nei veicoli connessi.
Ricerca scientifica e calcolo ad alte prestazioni (HPC): compiti pesanti come le simulazioni climatiche vengono suddivisi in lavori più piccoli che vengono eseguiti in parallelo. Questo riduce drasticamente i tempi di calcolo e supporta le collaborazioni scientifiche globali. I ricercatori possono perfezionare i modelli più velocemente e portare avanti l'innovazione.
Reti di distribuzione dei contenuti (CDN):** Memorizzano file e media su server in tutto il mondo, consentendo agli utenti di accedere ai contenuti dal nodo più vicino. Questa configurazione riduce i tempi di caricamento e i ritardi di rete, rendendola fondamentale per i servizi di streaming, i download di file di grandi dimensioni e i siti web ad alto traffico.
Vantaggi dei sistemi distribuiti
Le organizzazioni si rivolgono ai sistemi distribuiti per gestire dati e attività di calcolo in continua crescita. Ecco alcuni vantaggi chiave che aiutano i team a scalare, a mantenere la resilienza e a lavorare in modo più efficiente:
Scalabilità e condivisione delle risorse: Le architetture distribuite consentono alle organizzazioni di aggiungere altre macchine man mano che i carichi di lavoro crescono, anziché affidarsi a un unico grande server. Il sistema evita i colli di bottiglia e migliora il throughput suddividendo i dati e le attività su più nodi.
Tolleranza agli errori e ridondanza: Quando i dati e le attività critiche vengono replicati su più nodi, il sistema può continuare a funzionare anche se un nodo si guasta. Questo design riduce i tempi di inattività e preserva l'accesso degli utenti.
Design flessibile e modulare:** I sistemi distribuiti spesso dividono le attività in moduli più piccoli e indipendenti. Ogni nodo gestisce compiti specifici, facilitando l'aggiornamento o la sostituzione dei componenti senza interrompere l'intero ambiente.
Bilanciamento tra coerenza e disponibilità (Teorema CAP):** È difficile per i sistemi distribuiti essere completamente coerenti e sempre disponibili allo stesso tempo, soprattutto quando si verificano problemi di rete. L'esatto compromesso dipende da quanto sia critica la coerenza immediata per ogni caso d'uso.
Miglioramento delle prestazioni e del throughput:** Grazie all'esecuzione di attività in parallelo, i sistemi distribuiti possono elaborare più operazioni in meno tempo. Questo è essenziale per l'analisi dei big data o per le ricerche vettoriali in tempo reale.
Sfide e considerazioni
I sistemi distribuiti offrono molti vantaggi, ma introducono anche complessità uniche. Di seguito sono riportati alcuni ostacoli e fattori comuni da tenere a mente quando si costruiscono e si mantengono infrastrutture distribuite:
Latenza di rete e limiti di larghezza di banda: Le attività che si estendono su server distanti possono rallentare se le connessioni di rete sono deboli o sovraccariche. Quando la larghezza di banda è limitata, i trasferimenti di dati di grandi dimensioni possono incontrare dei colli di bottiglia. Posizionare i nodi più vicini agli utenti o memorizzare i dati nella cache può aiutare a ridurre la [latenza] (https://zilliz.com/ai-faq/what-is-the-role-of-network-latency-in-distributed-databases).
Mantenere tutto sincronizzato può essere difficile quando i dati sono archiviati su più nodi. I guasti alla rete o le interruzioni dei nodi introducono conflitti che richiedono una gestione attenta. Alcuni sistemi privilegiano gli aggiornamenti rapidi, mentre altri danno la priorità a un'accuratezza rigorosa.
Sicurezza e privacy dei dati:** I dati si spostano da una macchina all'altra, aumentando il rischio di fughe di notizie o di accessi non autorizzati. La crittografia e i rigorosi controlli di accesso aiutano a salvaguardare le informazioni sensibili. Controlli regolari e verifiche di conformità assicurano che i dati degli utenti rimangano protetti.
Gestione delle transazioni distribuite:** Una singola transazione può coinvolgere diversi servizi o nodi, complicando il coordinamento. Protocolli come il commit a due fasi o i transaction manager tengono traccia di questi passaggi. Attente strategie di rollback impediscono che fallimenti parziali corrompano i dati.
Introduzione a Milvus: un database vettoriale distribuito e cloud-nativo
Milvus è stato progettato da zero come un sistema distribuito cloud-native per la gestione di dati vettoriali ad alta dimensionalità. Suddividendo i dati e l'elaborazione su più nodi, Milvus offre i vantaggi fondamentali dell'elaborazione distribuita: scalabilità, tolleranza ai guasti ed esecuzione parallela, rendendolo adatto all'addestramento di modelli di intelligenza artificiale, ai sistemi di raccomandazione in tempo reale e alle analisi complesse.
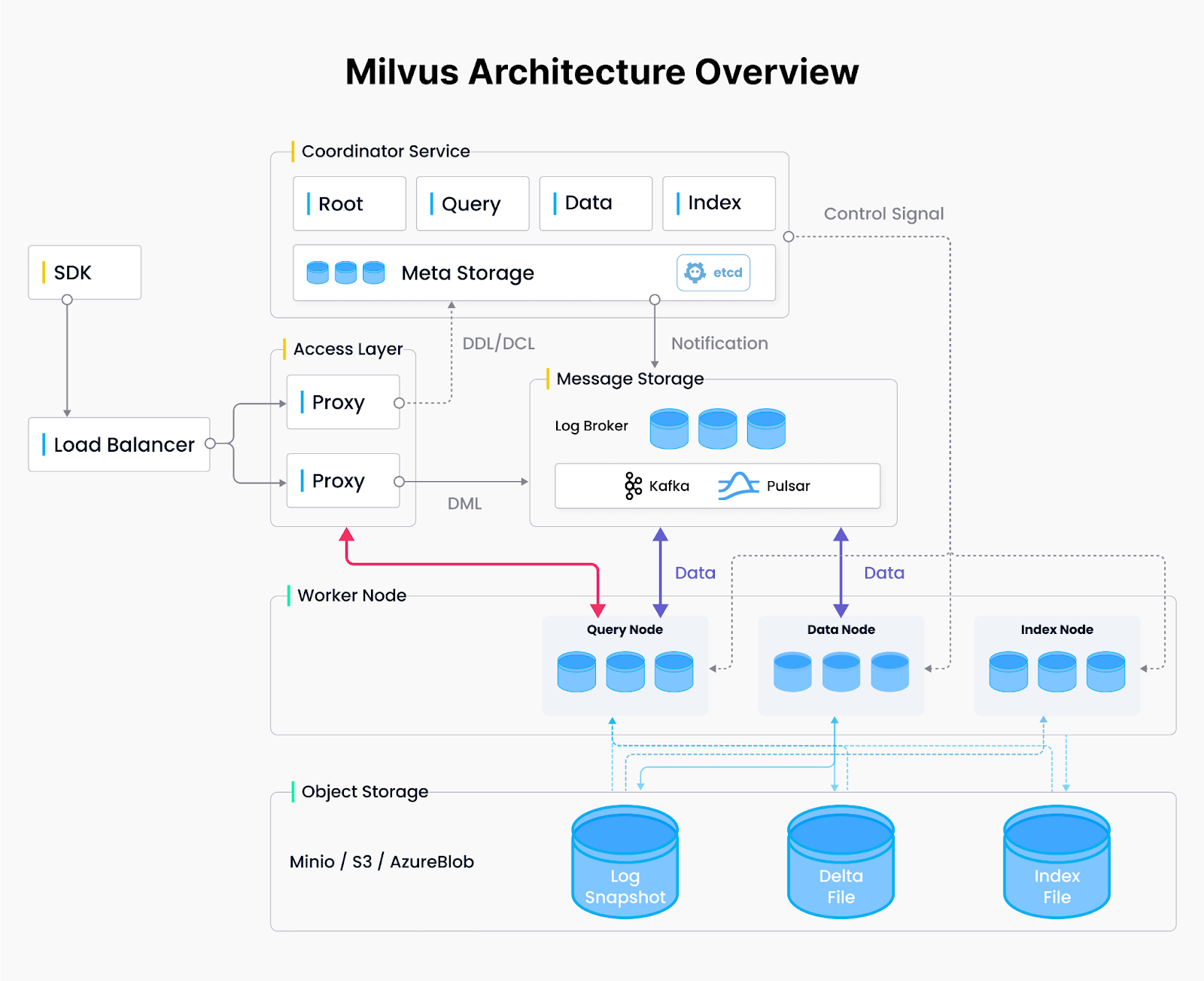 Milvus Architecture.png
Milvus Architecture.png
Figura: Architettura Milvus
Architettura distribuita Milvus: Design a quattro livelli
Milvus è un [database vettoriale] (https://zilliz.com/learn/what-is-vector-database) molto diffuso che adotta un'architettura di sistema distribuita composta da quattro livelli per allocare dinamicamente le risorse dove sono più necessarie, che si tratti di maggiore potenza di calcolo per l'indicizzazione su larga scala o di memoria aggiuntiva per gestire query complesse in parallelo.
Livello di accesso:** I nodi di accesso stateless gestiscono le richieste in arrivo, fungendo da punto di ingresso al sistema.
Coordination Layer:** Coordina l'assegnazione dei nodi e la gestione delle risorse, attivando o disattivando i lavoratori secondo le necessità.
Layer di lavoro:** Esegue le attività principali di interrogazione, ingestione dei dati e creazione di indici su nodi scalabili e stateless.
Strato di archiviazione:** Mantiene i dati vettoriali e i metadati di sistema per la tolleranza ai guasti e la persistenza dei nodi.
Scalabilità e coerenza nell'architettura distribuita Milvus
Milvus applica i principi dell'elaborazione distribuita per gestire enormi insiemi di dati vettoriali mantenendo la coerenza dei dati. Di seguito sono riportate le principali caratteristiche di progettazione che lo aiutano a scalare orizzontalmente, a ridurre al minimo i colli di bottiglia e a offrire livelli di coerenza regolabili:
Scala orizzontale: Milvus segmenta grandi insiemi di dati in parti gestibili. Ogni segmento è indicizzato in modo indipendente, per cui, man mano che i dati crescono, è possibile aggiungere altri nodi senza rivedere l'infrastruttura esistente.
Per scalare funzioni specifiche, le query, l'ingestione dei dati e l'indicizzazione vengono eseguite indipendentemente su tipi di nodi separati. Questa separazione aiuta a evitare i colli di bottiglia e garantisce che il sistema possa gestire miliardi di vettori.
Consistenza e Sharding** sintonizzabili:** I dati sono shardati su più nodi per le scritture simultanee, mentre i livelli di consistenza regolabili di Milvus consentono di bilanciare prestazioni e precisione in base alle esigenze dell'applicazione.
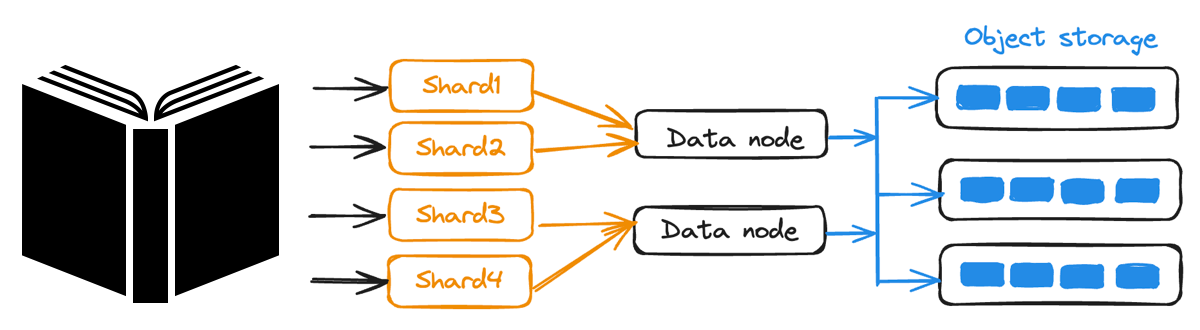 Sharding dei dati in Milvus
Sharding dei dati in Milvus
Figura: Sharding dei dati in Milvus
Modalità di distribuzione multiple per esigenze diverse
Milvus offre diverse opzioni di distribuzione per adattarsi a diverse scale di dati e requisiti di prestazioni. Che si tratti di test su una singola macchina o di un sistema di produzione su larga scala, queste modalità consentono di adattare le risorse e la complessità alle esigenze del progetto. Di seguito è illustrato il livello di scalabilità dei dati per ciascun database vettoriale. Si può notare che Milvus distribuito è progettato per gestire scale di dati di decine di milioni e oltre.
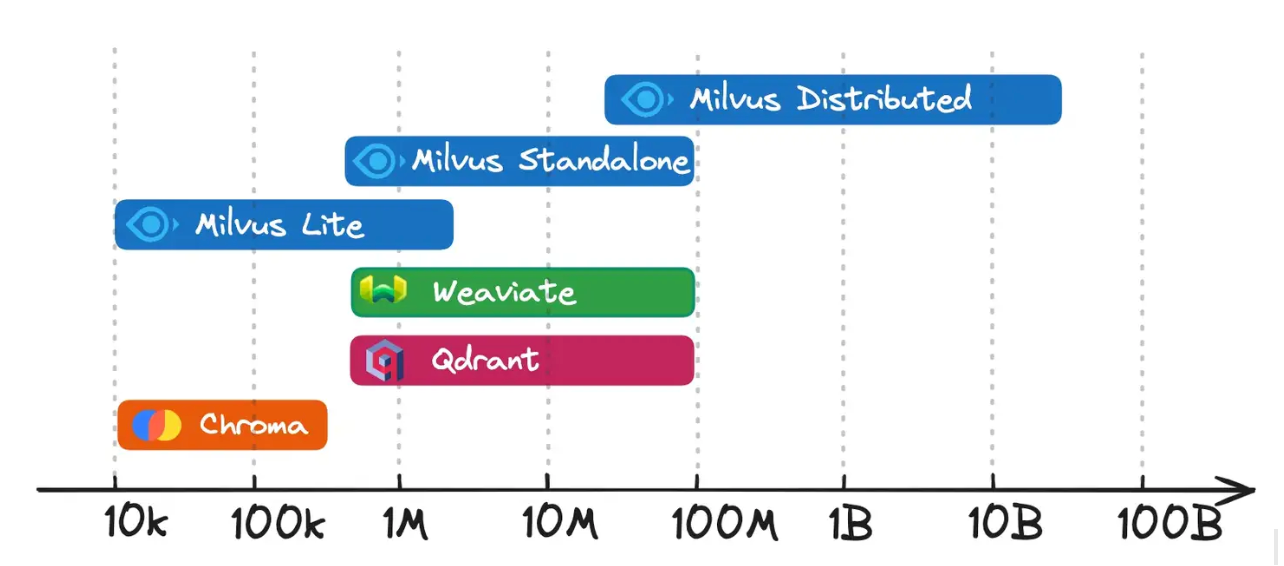 Modalità di distribuzione di Milvus
Modalità di distribuzione di Milvus
Figura: Modalità di distribuzione di Milvus
Milvus Lite: Una libreria Python leggera che fornisce le funzionalità principali di Milvus senza bisogno di un processo server separato. È ideale per esperimenti su piccola scala, prototipi rapidi o dimostrazioni veloci in ambienti locali. Milvus Lite consente di iniziare rapidamente con una configurazione minima se si sta costruendo un proof of concept o si stanno testando nuove funzionalità in un notebook.
Milvus Distributed:** Un'architettura completamente multi-nodo progettata per le esigenze di scala aziendale. Separando le attività tra nodi di accesso, coordinatori, lavoratori e livelli di archiviazione, gestisce miliardi (o addirittura decine di miliardi) di vettori con un'elevata disponibilità e tolleranza ai guasti. Questo modello è la scelta ideale per le organizzazioni che si aspettano una rapida crescita dei dati, che necessitano di prestazioni solide in caso di query simultanee e che vogliono la flessibilità di aggiungere o rimuovere nodi in base al carico di lavoro.
Un'implementazione a singolo nodo che raggruppa tutti i componenti di Milvus in un unico ambiente, spesso distribuito tramite un'immagine Docker. Questo rende semplice l'installazione e la manutenzione, fornendo al contempo una capacità sufficiente per volumi di dati moderati. I team che desiderano eseguire carichi di lavoro di produzione che non richiedono una scalabilità massiccia o intricati meccanismi di failover troveranno questa opzione conveniente e affidabile.
Per saperne di più sulla distribuzione di Milvus, leggete la nostra guida: [Come scegliere la giusta modalità di distribuzione di Milvus per le vostre applicazioni AI] (https://zilliz.com/blog/choose-the-right-milvus-deployment-mode-ai-applications).
Conclusione
L'informatica distribuita ha ridisegnato il modo in cui le organizzazioni gestiscono i dati e scalano le loro applicazioni, abbandonando i server monolitici per passare a cluster flessibili e tolleranti ai guasti di nodi interconnessi. Suddividendo le attività e i dati su più macchine, i team ottengono un'elaborazione più rapida, una maggiore disponibilità e un uso più efficiente delle risorse. Le soluzioni moderne, come Zilliz, applicano questi principi per offrire un database vettoriale cloud-native in grado di gestire miliardi di vettori in parallelo. Poiché i volumi di dati continuano a crescere e i casi d'uso diventano sempre più complessi, l'adozione di un approccio distribuito - sia per l'analisi, l'apprendimento automatico o le raccomandazioni in tempo reale - rimane una strategia chiave per rimanere competitivi nel mondo odierno guidato dai dati.
Domande frequenti sull'informatica distribuita
Perché scegliere un sistema distribuito invece di un singolo e potente server? **Con un sistema distribuito, è possibile aggiungere altre macchine in base all'aumento dei carichi di lavoro, invece di aggiornare un singolo server. Questa flessibilità aumenta le prestazioni, riduce i costi e l'impatto di un singolo punto di guasto.
Come fanno i dati a rimanere coerenti in un ambiente distribuito? **I sistemi distribuiti utilizzano protocolli e algoritmi (come i meccanismi di consenso) per mantenere i dati sincronizzati tra più nodi. L'approccio esatto varia a seconda del sistema, ma l'obiettivo è garantire che gli aggiornamenti non vadano in conflitto e che ogni nodo abbia la visione corretta dei dati.
Sebbene i sistemi distribuiti introducano un maggior numero di parti in movimento, come la comunicazione di rete, il coordinamento dei nodi e la replica, gli strumenti e le best practice possono mitigare la complessità. Strumenti come Kubernetes e piattaforme di monitoraggio semplificano l'orchestrazione e l'osservabilità.
Milvus è un database vettoriale distribuito e cloud-native, progettato per ricerche di similarità su larga scala. Suddividendo i dati in segmenti e sfruttando l'indicizzazione parallela, Milvus può gestire miliardi di vettori su più nodi senza sacrificare la velocità o l'affidabilità.
Cosa succede se i miei dati devono essere raccolti o se il traffico aumenta improvvisamente? **I sistemi distribuiti sono ideali per gestire le variazioni improvvise della domanda. È possibile attivare rapidamente nodi o risorse aggiuntive, evitando il sovraccarico di qualsiasi macchina e mantenendo prestazioni costanti anche durante i picchi di utilizzo.
Risorse correlate
Modelli AI più performanti per le vostre applicazioni GenAI | Zilliz
Acquisizione dei dati sulle modifiche: mantenere i sistemi sincronizzati in tempo reale
Ottimizzazione della comunicazione dei dati: Milvus abbraccia la messaggistica NATS
Introduzione del monitoraggio e dell'osservabilità completi in Zilliz Cloud
- Da singoli server a sistemi distribuiti: L'evoluzione
- Come funziona l'informatica distribuita?
- Tipi di architetture di calcolo distribuito
- Casi d'uso dell'informatica distribuita
- Vantaggi dei sistemi distribuiti
- Sfide e considerazioni
- Introduzione a Milvus: un database vettoriale distribuito e cloud-nativo
- Conclusione
- Domande frequenti sull'informatica distribuita
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente